【Web SEO】前端性能优化+SEO具体实践手册
一、前言
本文章主要介绍如何通过前端的技术手段去解决性能优化和SEO问题
核心目标是为了利于搜索引擎数据抓取和提高流量
二、测试工具
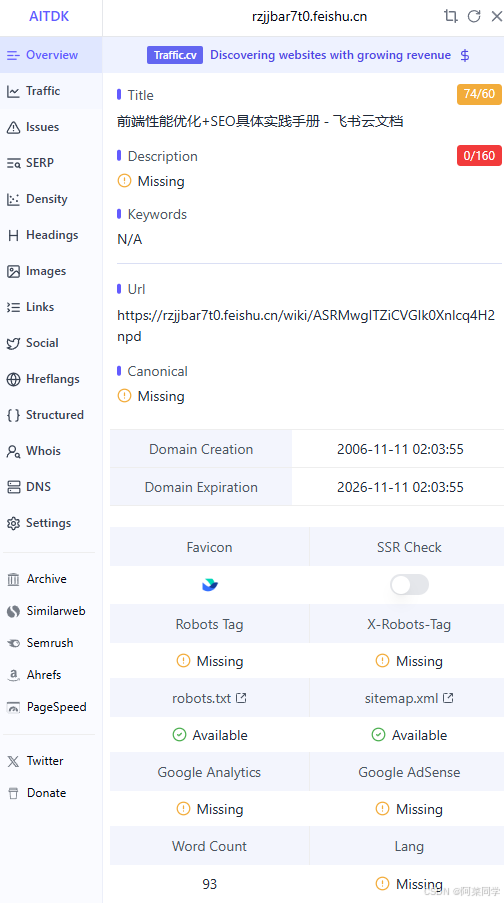
AI TDK SEO Extension
作为Google的插件扩展使用,用于检测当前站点的各项指标是否满足搜索引擎要求
官方地址
https://chromewebstore.google.com/detail/hhfkpjffbhledfpkhhcoidplcebgdgbk?utm_source=item-share-cb
Lighthouse
在网站中使用F12呼出浏览器检查面板,在检查面板中的一项功能,主要用于分析网页的加载情况,但受本地环境影响比较大,存在不准确的情况,仅供参考

Google PageSpeed Insights
该网站是基于浏览器之外的环境进行检测,相比Lighthouse相比,受本地环境影响较小,但同样会受服务器影响,且需要外部域名,适合上线项目测试
官方地址
https://chromewebstore.google.com/detail/pnibhbifpoiplpgkaajjejeigfchahpl?utm_source=item-share-cb
三、SE0关键指标以及执行流程
下面具体阐述SEO优化中的关键指标以及如何通过前端手段进行优化
✔Headings
一句话
用来组织和构建网页内容结构的重要HTML元素,更重要的是向浏览器和搜索引擎传达文档的层级和重要性。
可以理解为是当前网站的目录
作用
- 语义化和结构化: Headings 为内容提供语义结构,帮助浏览器和辅助技术(如屏幕阅读器)理解页面内容的组织方式。
- 搜索引擎优化 (SEO**):** 搜索引擎会根据headings来判断页面的主题和重要内容。
- 用户体验: 清晰的标题结构可以帮助用户快速浏览页面,理解内容层次,找到他们感兴趣的部分。
- 可访问性: 对于使用屏幕阅读器的用户,headings允许他们快速跳过不同的章节,从而提高浏览效率。
当前Headings结构
推荐直接使用AI TDK SEO Extension ,点击插件弹出看板,在Headings中,可以清晰的看到当前站点的结构
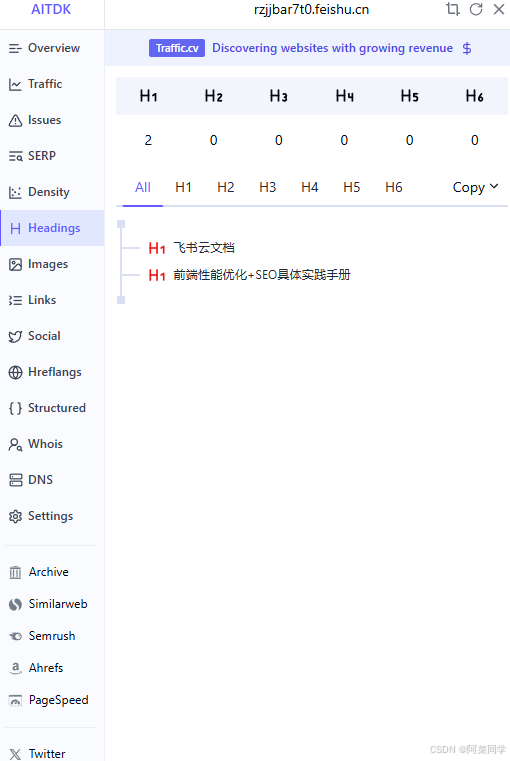
记住,Headings并不是必须要对用户可见的,更多的是有利于搜索引擎的
因此可以通过前端的手段去隐藏 相应的配置,用户不可见但是搜素引擎可见
层级越多越好 ❓
关键点在于:搜索引擎是如何识别到当前的网站结构的?
<body><header><h1>前端开发入门指南</h1></header><main><section><h2>HTML基础</h2><p>HTML是构建网页内容的骨架。</p><h3>什么是HTML元素?</h3><p>HTML元素是页面的基本构建块,例如段落、图片、链接等。</p><h3>常用HTML标签</h3><ul><li>`<p>` (段落)</li><li>`<a>` (链接)</li><li>`<img>` (图片)</li></ul></section><section><h2>CSS样式</h2><p>CSS用于美化网页,控制布局和视觉效果。</p><h3>选择器</h3><p>CSS选择器用于选中HTML元素并应用样式。</p></section></main><footer><p>© 2023 我的博客</p></footer>
</body>
HTML提供了六个等级的标题,从<h1>到<h6>:
<h1>:最高等级的标题,代表页面最重要的主题或标题。一个页面通常只有一个<h1>。<h2>:次高等级的标题,用于页面的主要章节或子主题。<h3>:更次一级的标题,用于<h2>标题下的子章节。<h4>、<h5>、<h6>:依次类推,用于更细致的页面内容划分。
但是层级并不是越多越好
- 过多的层级导致内容碎片化,难以把握重点
- 太深的层级会增加认知负担
- 搜索引擎重点关注h1到h3
- 可维护性,简单的结构更容易维护和更新
上述的代码中,最高等级就是最低等级到H3,也是最推荐的层级数,就是h1到h3即可
搜索引擎会自动去扫描当前的等级标题,形成Headings,前端要做的就是去构建这样的结构
如何实现?🏃🏃
如果在编写网页的时候,能够一开始就形成上述的网页结构是最快的方式,但是往往受限于业务需求
- 更新迭代频繁,前期考虑不充分
- 改动难度大
- 样式改动难度大
Headings并不是必须要对用户可见的,但要有利于搜索引擎
我们可以使用不可见的方式去构建这样的结构
编写一个不可见的前端CSS样式
{position: absolute !important;width: 1px;height: 1px;padding: 0;margin: -1px;overflow: hidden;clip: rect(0, 0, 0, 0);white-space: nowrap;border: 0;
}
<h1 class="visually-hidden" v-html="$t('headings.h1')"></h1><section><h2 class="visually-hidden" v-html="$t('headings.h2-1')"></h2><h3 class="visually-hidden" v-html="$t('headings.h3-1')"></h3></section><section><h2 class="visually-hidden" v-html="$t('headings.h2-2')"></h2><h3 class="visually-hidden" v-html="$t('headings.h3-2')"></h3></section><section><h2 class="visually-hidden" v-html="$t('headings.h2-3')"></h2><h3 class="visually-hidden" v-html="$t('headings.h3-3')"></h3></section>
上述代码,通过CSS样式对标签结构进行隐藏,不破坏本身的业务逻辑和UI结构,但是能够做到结构自定义并利于搜索引擎抓取
风险:如果滥用 visually-hidden 来填充大量与用户实际可见内容不符的关键词或不相关的标题,可能会被搜索引擎视为黑帽 SEO 行为(Keyword Stuffing 或 Hidden Text),从而导致惩罚
visually-hidden 更适合用于补充那些视觉上没有但语义上需要的标题,或者在某些复杂布局下,为了保持语义结构而隐藏的标题。
✔HrefLangs
是 HTML 和 HTTP 头部中一个非常重要的属性,它告诉搜索引擎一个页面有多个语言或地域版本。
一句话
简单来说,它帮助搜索引擎了解你的网站有哪些不同语言或针对不同地区的内容版本,从而在用户搜索时,为他们提供最适合其语言和所在地区的页面版本。
作用
- 改善用户体验: 确保用户在搜索时,能看到与其语言和地理位置最相关的页面,提高用户满意度。
- 避免重复内容惩罚: 如果你的网站有多个语言版本或地域版本,内容可能非常相似,没有
hreflang,搜索引擎可能会将这些相似内容视为重复内容,从而影响你的搜索排名。 - 提高国际SEO表现:提高你的网站在不同国际市场上的可见性和排名。
🏛标准结构
<link rel="canonical" href="https://www.metric-converter.com/en/pressure">
<link rel="alternate" hreflang="en" href="https://www.metric-converter.com/en/pressure" />
<link rel="alternate" hreflang="zh-Hans" href="https://www.metric-converter.com/zh/pressure" />
<link rel="alternate" hreflang="zh-Hant" href="https://www.metric-converter.com/zh-tw/pressure" />
<link rel="alternate" hreflang="ja" href="https://www.metric-converter.com/ja/pressure" />
<link rel="alternate" hreflang="ko" href="https://www.metric-converter.com/ko/pressure" />
<link rel="alternate" hreflang="x-default" href="https://www.metric-converter.com/en/pressure" />
上述代码分别表明
- 当前网站拥有 英文、简中、繁中、日、韩语
hreflang="${locale}" - 当前网站有默认回退版本
hreflang="x-default" - 当前网站正在使用语言为英文
rel="canonical" - 不同语言分别对应的地址什么
href="xxxxxxxxxxx"
如何实现?🏃🏃
这里有很多实现策略,本质都是要构造出上述的结构,无非就是如何生成一种 语言+当前页面的结构
伪代码:
<link rel="canonical" href="url">locales.map((locale)=>{```<link rel="alternate" hreflang="${locale}" href="https://www.metric-converter.com/${locale}" />```
})
根据当前的语言表,循环遍历生成
在Nuxt2中,你可以使用**head选项函数**
head() {const links = [];const locales = this.$i18n.locales || [];const canonicalUrl = `https://aimangatranslator.com${this.$route.path}`;locales.forEach((locale) => {// const routeName = `${locale.code}-${this.$route.name}`;// const routePath = this.localePath({ name: routeName });if (locale.code === "en") {links.push({hid: "alternate-x-default",rel: "alternate",hreflang: "x-default",href: "https://aimangatranslator.com/",});} else {links.push({hid: "alternate-" + locale.code,rel: "alternate",hreflang: locale.iso,href: `https://aimangatranslator.com/${locale.code}/`,});}});links.push({ rel: "canonical", href: canonicalUrl });return {link: links,};},
在Nuxt3中,你可以使用useHead函数去处理
在Next中,你可以在layout文件中对外暴露一个generateMetadata函数,这是一个约定,同时必须返回一个对象,对象中有一个alternates属性
export async function generateMetadata({ params: { locale } }: Props): Promise<Metadata> {// 不再使用headers()获取路径,而是使用固定的路径模式// 静态路径无法获取当前路径,因此我们只使用locale参数const baseUrl = 'https://www.metric-converter.com';const path = ''; // 简化处理,只用基本路径// 生成所有语言版本的URLconst languages = locales.reduce((acc, loc) => {if (loc === 'en') {acc[loc] = `${baseUrl}${path}`;} else {acc[loc] = `${baseUrl}/${loc}${path}`;}return acc;}, {} as Record<ValidLocale, string>);// 添加x-default指向英文版本languages['x-default' as ValidLocale] = `${baseUrl}${path}`;// 获取SEO配置,如果没有找到对应语言的配置,使用英文配置const seo = seoConfig[locale] || seoConfig['en'];const currentUrl = locale === 'en' ? `${baseUrl}${path}` : `${baseUrl}/${locale}${path}`;return {alternates: {canonical: currentUrl,languages},};
}
如果实在无法在head中完成怎么办???
也可以通过sitemap文件去完成,具体sitemap是什么可以看我下面的内容,通过xhtml:link去完成。
但是这就需要动态去构造sitemap文件了,同时可能会造成数量过多的问题
<?xml version="1.0" encoding="UTF-8"?>
<urlset xmlns="http://www.sitemaps.org/schemas/sitemap/0.9"xmlns:xhtml="http://www.w3.org/1999/xhtml"><url><loc>https://www.example.com/product</loc><xhtml:linkrel="alternate"hreflang="en"href="https://www.example.com/product"/><xhtml:linkrel="alternate"hreflang="en-GB"href="https://www.example.com/en-gb/product"/><xhtml:linkrel="alternate"hreflang="fr"href="https://www.example.com/fr/product"/><xhtml:linkrel="alternate"hreflang="zh"href="https://www.example.com/zh/product"/><xhtml:linkrel="alternate"hreflang="x-default"href="https://www.example.com/product"/></url><url><loc>https://www.example.com/en-gb/product</loc><xhtml:linkrel="alternate"hreflang="en"href="https://www.example.com/product"/><xhtml:linkrel="alternate"hreflang="en-GB"href="https://www.example.com/en-gb/product"/><xhtml:linkrel="alternate"hreflang="fr"href="https://www.example.com/fr/product"/><xhtml:linkrel="alternate"hreflang="zh"href="https://www.example.com/zh/product"/><xhtml:linkrel="alternate"hreflang="x-default"href="https://www.example.com/product"/></url><!-- ...其他语言版本的 URL 及其 hreflang 链接... -->
</urlset>
仅在无法通过head设置的情况下去使用
注意点
lang_code格式
lang_code 遵循 ISO 639-1 (语言代码) 和 ISO 3166-1 Alpha 2 (国家/地区代码) 的标准。
- 仅语言:
en(英语),fr(法语),zh(中文) - 语言-地区组合:
en-GB(英国英语),en-US(美国英语),fr-CA(加拿大法语),zh-CN(中国大陆中文),zh-TW(台湾中文)
默认语言
如果你的网站默认使用英文(en),回退语言也是指向英文(x-default)
尽量不要变成两个页面,即https://www.example.com/en 和https://www.example.com/是不同的网页
可能会被搜索引擎判定内容重复
可以使用301策略或者仅使用https://www.example.com/作为默认和英文版本
重复定义问题
不要重复在Head中定义Hreflangs,否则也会被认定存在重复内容
文档指向ref=canonical 指向错误问题
这是Google的一个SEO规范,ref=canonical标签中的href不要跟rel="alternate"中的href链接一致,可以在最后面加一个/来区分
✔Metadata
Metadata 主要是指用于描述网页、应用程序资源、组件或数据的结构、内容和行为的信息。它不会直接显示在用户界面上,但对搜索引擎优化(SEO)、可访问性、性能、开发工具和应用程序逻辑至关重要。
一句话
他相当于当前网页的名片
Metadata通常包括以下几个方面的内容
常见内容属性🔥
- **
Title🔥🔥🔥🔥**
网页的标题,显示在浏览器标签或窗口标签栏,对SEO至关重要,**一般在60个字符以内,不低于29个字符**
在网页中的表现通常为:
<title>当前网页的标题</title>
不同的页面最好赋予不同的网页标题
- **
description🔥🔥🔥🔥**
网页内容的简短描述,搜索引擎在搜索结果中可能显示。对SEO非常重要,**一般在160个字符以内,不低于120个字符**
在网页中的表现通常为:
<meta name="description" content="网站描述">
不同的页面最好赋予不同的网页描述
keywords🔥
SEO使用的关键词列表,一般在100个字符以内,不低于50个字符
在网页中的表现通常为:
<meta name="keywords" content="关键词1, 关键词2,关键词3...........">
不同的页面最好赋予不同的关键词
上述内容可以在Overview中查看到
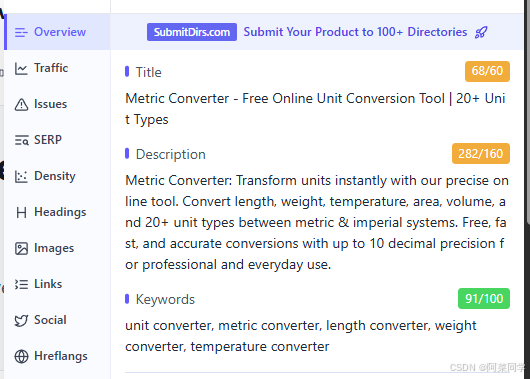
keywords 标签在现代 SEO 中权重已经非常低,Google 官方明确表示不将其作为排名因素
https://developers.google.com/search/blog/2009/09/google-does-not-use-keywords-meta-tag?hl=zh-cn
- **
author🔥**
网页作者
<meta name="author" content="...">:网页作者。
- Viewport 🔥
控制浏览器视口
<meta name="viewport" content="...">:控制浏览器视口,用于响应式设计。例如:width=device-width, initial-scale=1.0。
- Icon 🔥 🔥 🔥
定义网站图标,图标可以有不同的尺寸
其中apple-touch-icon主要是提供给Safari浏览器使用,可以利用一些Safari专属特性
https://developer.apple.com/library/archive/documentation/AppleApplications/Reference/SafariWebContent/ConfiguringWebApplications/ConfiguringWebApplications.html rel=“apple-touch-icon”
<link rel="icon" href="/favicon.ico" type="image/x-icon" sizes="16x16">
<link rel="icon" href="/icon.png" sizes="192x192" type="image/png">
<link rel="apple-touch-icon" href="/apple-touch-icon.png">
开放图谱协议 (Open Graph Protocol - OGP)
由Facebook推出,用于社交媒体分享时,指定网页在社交媒体上的显示方式。
- **
<meta property="og:title" content="...">**:分享标题。 - **
<meta property="og:description" content="...">**:分享描述。 - **
<meta property="og:image" content="...">**:分享图片URL。 - **
<meta property="og:image:width" content="...">**:图片宽度 - **
<meta property="og:image:height" content="...">**:图片高度 - **
<meta property="og:image:alt" content="...">**:分享图片描述。 - **
<meta property="og:url" content="...">**:分享链接的规范URL。 - **
<meta property="og:type" content="...">**:内容类型(如website、article等)。 - **
<meta property="og:site_name" content="...">**:网站标题。
在next中配置openGraph字段
export const metadata: Metadata = {openGraph: {type: 'website',url: baseUrl,title: 'Metric Converter',description: 'A powerful online unit conversion tool',siteName: 'Metric Converter',images: [{url: `${baseUrl}/og-image.png`,width: 1200,height: 630,alt: 'Metric Converter - A powerful online unit conversion tool'}]},}
同样的,可以在工具中的Social一栏中可以查看
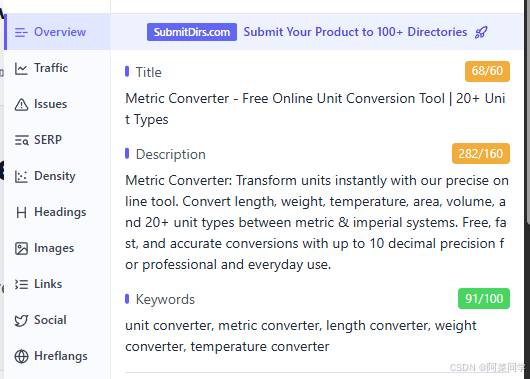
Twitter Cards
类似OGP,专门用于Twitter分享
- **
<meta name="twitter:card" content="summary_large_image">**:卡片类型。 - **
<meta name="twitter:site" content="@yoursite">**:网站Twitter账户。 - **
<meta name="twitter:title" content="...">**:Twitter分享标题。 - **
<meta name="twitter:description" content="...">**:Twitter分享描述。 - **
<meta name="twitter:image" content="...">**:Twitter分享图片URL。
在Next中的twitter字段
export const metadata: Metadata = {twitter: {card: 'summary_large_image',title: 'Metric Converter',description: 'A powerful online unit conversion tool',images: [`${baseUrl}/og-image.png`]}
}
同样的,可以在工具中的Social一栏中可以查看

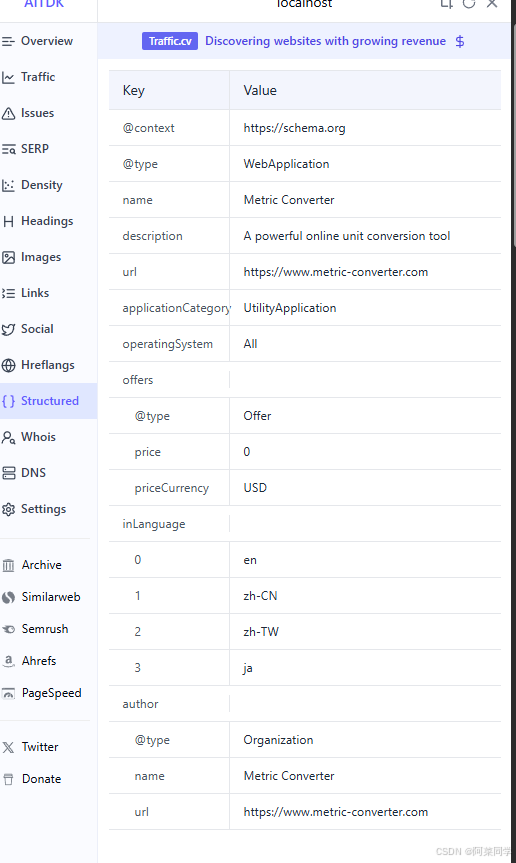
JSON-LD 结构化数据
一种以JSON格式嵌入在HTML中的元数据,用于向搜索引擎提供更丰富的上下文信息,以生成富媒体搜索结果(Rich Snippets)。
- 例如,描述一个产品、一个食谱、一个活动、一篇文章或一个本地商家。
- 通常放在
<script type="application/ld+json">标签中。
<script type="application/ld+json">{"@context":"https://schema.org","@type":"WebApplication","name":"Metric Converter","description":"A powerful online unit conversion tool","url":"https://www.metric-converter.com","applicationCategory":"UtilityApplication","operatingSystem":"All","offers":{"@type":"Offer","price":"0","priceCurrency":"USD"},"inLanguage":["en","zh-CN","zh-TW","ja"],"author":{"@type":"Organization","name":"Metric Converter","url":"https://www.metric-converter.com"}}</script>
在代码中的实现
<head>{/* 添加结构化数据 */}<scripttype="application/ld+json"dangerouslySetInnerHTML={{ __html: JSON.stringify(jsonLd) }}/></head>//定义一个jsonLd
const jsonLd = {'@context': 'https://schema.org','@type': 'WebApplication',name: 'Metric Converter',description: 'A powerful online unit conversion tool',url: baseUrl,applicationCategory: 'UtilityApplication',operatingSystem: 'All',offers: {'@type': 'Offer',price: '0',priceCurrency: 'USD'},inLanguage: ['en', 'zh-CN', 'zh-TW', 'ja'],author: {'@type': 'Organization',name: 'Metric Converter',url: baseUrl}
}
可以在AI TDK 的 Structured字段中看到
PWA | manifest.json 文件
描述渐进式Web应用的元数据,让Web应用可以像原生应用一样被安装到设备主屏幕。
name / **short_name**:应用的完整名称和短名称。- **
icons**:应用图标的各种尺寸。 - **
start_url**:应用启动时的URL。 - **
display**:显示模式(如standalone)。 background_color / **theme_color**:应用背景色和主题色。
主要是用于浏览器中的添加到主屏幕的一些配置以及最终在用户桌面的呈现效果
以Safari浏览器为例:
在Next中,同样是在根路径对外暴露manifest函数
export default function manifest(): MetadataRoute.Manifest {return {name: '单位转换器',short_name: '单位转换',description: '一个功能强大的在线单位转换工具',start_url: '/',display: 'standalone',background_color: '#ffffff',theme_color: '#ffffff',icons: [{src: '/icon.png',sizes: '192x192',type: 'image/png',},{src: '/icon.png',sizes: '192x192',type: 'image/png',purpose: 'maskable'},{src: '/apple-touch-icon.png',sizes: '180x180',type: 'image/png'},{src: '/favicon.ico',sizes: 'any',type: 'image/x-icon'}]}
}
无障碍性
通过ARIA属性(Accessible Rich Internet Applications)为辅助技术(如屏幕阅读器)提供额外信息。
- **
aria-label**:为元素提供可访问的标签。 - **
aria-describedby**:指向描述元素的其他元素。 - **
aria-hidden**:指示元素是否应该对辅助技术隐藏。 - **
role**:定义元素的角色(如button、dialog、navigation)。
<nav aria-label="Unit types"><a data-type="lenght"></a><a data-type="area"></a><a data-type="volume"></a>.....
</nav>
一般用于导航栏中
总结
- 规划和定义:根据项目需求(SEO、社交分享、PWA、可访问性)确定需要哪些元数据字段。
- 选择工具和方法:根据使用的前端框架、是否需要SSR等选择合适的元数据管理库或原生API。
- 实现:
- 在
<head>中静态添加通用元数据。 - 在组件或路由中动态设置页面特有的
title和meta标签。 - 根据需要嵌入 OGP、Twitter Cards 和 JSON-LD 数据。
- 为PWA创建并链接
manifest.json。 - 在HTML元素上添加 ARIA 属性以增强可访问性。
- 在
- 测试和验证:
- 使用浏览器开发者工具检查
<head>中的元数据是否正确。 - 使用Google Search Console的“富媒体搜索结果测试工具”验证JSON-LD。
- 使用Facebook Sharing Debugger或Twitter Card Validator检查社交分享效果。
- 使用Lighthouse等工具进行SEO和可访问性审计。
- 使用AI TDK去进行整体检查
- 使用浏览器开发者工具检查
🗺️Sitemap.xml
谷歌官方指导:https://developers.google.com/search/docs/crawling-indexing/sitemaps/build-sitemap?hl=zh-cn
Sitemap通讯标准:https://www.sitemaps.org/zh_TW/protocol.html
Sitemap (站点地图) 是一个文件,列出了你网站上的所有页面、视频、图片文件,以及它们之间的关系。
它旨在告知搜索引擎你的网站上有哪些内容可以被抓取和索引。
- 帮助搜索引擎发现页面:特别是对于新网站、页面较少链接的网站(“孤岛页面”)、内容经常更新的网站,Sitemap 可以确保搜索引擎能发现所有重要的页面。
- 提供页面元数据:除了页面URL,Sitemap 还可以包含每个URL的额外信息:
- **上次修改时间 (lastmod)**:告诉搜索引擎这个页面什么时候最后更新过。
- **更改频率 (changefreq)**:建议搜索引擎这个页面大概多久会更新一次(如
always、hourly、``daily、weekly`、`monthly`、`yearly`、`never`)。 - **优先级 (priority)**:告知搜索引擎这个页面的相对重要性(0.0到1.0)。
- 支持特殊内容:
- 图片 Sitemap:帮助搜索引擎发现和理解网站上的图片内容。
- 视频 Sitemap:提供视频的标题、描述、播放时长、缩略图等信息。
- 新闻 Sitemap:帮助新闻网站的内容更快地被Google新闻索引。
一句话
网站的目录或者导航图
结构示例
<?xml version="1.0" encoding="UTF-8"?>
<urlset xmlns="http://www.sitemaps.org/schemas/sitemap/0.9"><url><loc>http://www.example.com/</loc><lastmod>2023-10-27</lastmod><changefreq>daily</changefreq><priority>1.0</priority></url><url><loc>http://www.example.com/page1.html</loc><lastmod>2023-10-25</lastmod><changefreq>weekly</changefreq><priority>0.8</priority></url><url><loc>http://www.example.com/category/page2.html</loc><lastmod>2023-10-20</lastmod><changefreq>monthly</changefreq><priority>0.6</priority></url>
</urlset>
<urlset>:Sitemap 文件的根元素,并声明命名空间。<url>:包含一个页面的所有信息。<loc>:页面的完整URL(必需)。<lastmod>:页面上次修改日期。<changefreq>:页面修改频率的提示。<priority>:页面相对于网站其他页面的重要性。
🗺️🗺️多个Sitemap文件
对于大型网站,往往页面内容会比较多,如果全部堆积在一个页面,往往会超过规范的大小限制
一般sitemap中的网址不能超过50000条,大小不能超过50mb,超过就需要进行拆分
<?xml version="1.0" encoding="UTF-8"?>
<sitemapindex xmlns="http://www.sitemaps.org/schemas/sitemap/0.9"><sitemap><loc>http://www.example.com/sitemap_articles.xml</loc><lastmod>2023-10-27T10:00:00+00:00</lastmod></sitemap><sitemap><loc>http://www.example.com/sitemap_products_1.xml</loc><lastmod>2023-10-26T14:30:00+00:00</lastmod></sitemap><sitemap><loc>http://www.example.com/sitemap_products_2.xml</loc><lastmod>2023-10-26T14:30:00+00:00</lastmod></sitemap><sitemap><loc>http://www.example.com/sitemap_images.xml</loc><lastmod>2023-10-27T11:00:00+00:00</lastmod></sitemap><sitemap><loc>http://www.example.com/sitemap_videos.xml</loc><lastmod>2023-10-27T12:00:00+00:00</lastmod></sitemap>
</sitemapindex>
<sitemapindex>:Sitemap 索引文件的根元素。<sitemap>:包含一个子 Sitemap 文件的信息。<loc>:子 Sitemap 文件的完整URL(必需)。<lastmod>:子 Sitemap 文件上次修改的日期和时间(可选,但推荐提供)。
🖼️图片sitemap
官方地址:https://developers.google.com/search/docs/crawling-indexing/sitemaps/image-sitemaps?hl=zh-cn
<?xml version="1.0" encoding="UTF-8"?>
<urlset xmlns="http://www.sitemaps.org/schemas/sitemap/0.9"xmlns:image="http://www.google.com/schemas/sitemap-image/1.1"><url><loc>https://www.example.com/products/product-1001/</loc><image:image><image:loc>https://www.example.com/images/product-1001-main.jpg</image:loc><image:caption>高质量产品图</image:caption><image:title>产品1001主图</image:title></image:image><image:image><image:loc>https://www.example.com/images/product-1001-gallery.jpg</image:loc></image:image></url><url><loc>https://www.example.com/blog/article-a/</loc><image:image><image:loc>https://www.example.com/images/article-a-thumbnail.jpg</image:loc></image:image></url><!-- ... 其他图片 URL ... -->
</urlset>
<image:image>(必填):表示一个图片的信息。一个<url>元素可以包含多个<image:image>元素,即一个页面可以包含多张图片。<image:loc>(必填):图片的完整 URL。这是图片 Sitemap 中最重要的元素。<image:caption>(可选):图片的说明文字。它类似于 HTML 中alt属性或<figcaption>标签的内容,对图片的描述性文字有助于搜索引擎理解图片内容。<image:geo_location>(可选):图片所描绘地点的地理位置。例如,Hawaii, USA。<image:title>(可选):图片的标题。它类似于 HTML 中title属性。<image:license>(可选):指向图片许可信息的 URL。
图片 Sitemap 的作用:
- 提升图片搜索可见性:帮助你的图片出现在 Google 图片搜索结果中。
- 提供更多上下文信息:即使图片没有
alt属性或其alt属性不够详细,Sitemap 也能补充这些信息。 - 发现嵌入式图片:对于通过 CSS 或 JavaScript 加载的图片,或不在标准
<img>标签中的图片,Sitemap 是一个重要的发现机制。
📺️视频Sitemap
官方地址:https://developers.google.com/search/docs/crawling-indexing/sitemaps/video-sitemaps?hl=zh-cn
<?xml version="1.0" encoding="UTF-8"?>
<urlset xmlns="http://www.sitemaps.org/schemas/sitemap/0.9"xmlns:video="http://www.google.com/schemas/sitemap-video/1.1"><url><loc>https://www.example.com/products/product-video-page/</loc><video:video><video:thumbnail_loc>https://www.example.com/videos/thumbnails/product-video.jpg</video:thumbnail_loc><video:title>产品演示视频</video:title><video:description>观看此视频了解产品功能。</video:description><video:content_loc>https://www.example.com/videos/product-video.mp4</video:content_loc><video:player_loc allow_embed="yes" autoplay="ap=1">https://www.example.com/embed/product-video</video:player_loc><video:duration>600</video:duration><video:publication_date>2023-09-01T08:00:00+00:00</video:publication_date><video:tag>电商</video:tag><video:tag>产品演示</video:tag></video:video></url><!-- ... 其他视频 URL ... -->
</urlset>
video:video 元素及其子元素详解:
<video:video>(必填):表示一个视频的信息。一个<url>元素可以包含多个<video:video>元素。<video:thumbnail_loc>(必填):视频缩略图的 URL。<video:title>(必填):视频的标题。<video:description>(必填):视频的描述。<video:content_loc>(必填之一):指向视频媒体文件本身的 URL(例如,.mp4文件的直链)。<video:player_loc>(必填之一):指向视频播放器页面的 URL。allow_embed属性 (可选):指示是否允许在外部网站嵌入视频 (yes或no)。autoplay属性 (可选):播放器加载后是否自动播放。例如autoplay="ap=1"或autoplay="true"。
- 注意:
content_loc和player_loc至少要提供一个。如果同时提供,通常content_loc更受青睐。 <video:duration>(可选):视频时长,以秒为单位,范围 1-28800。<video:publication_date>(可选):视频首次发布的日期和时间 (ISO 8601 格式)。<video:tag>(可选):与视频相关的标签或关键词。一个视频可以有多个<video:tag>。<video:category>(可选):视频所属的类别。<video:family_friendly>(可选):指示视频是否适合所有年龄段观看 (yes或no)。<video:requires_subscription>(可选):观看视频是否需要付费订阅 (yes或no)。<video:uploader>(可选):视频上传者的信息。display_name属性:上传者的名称。info属性:指向上传者更多信息的 URL。
<video:live>(可选):指示视频是否是实时直播 (yes或no)。
视频 Sitemap 的作用:
- 增强视频搜索可见性:让你的视频出现在 Google 视频搜索结果中,并可能以富媒体片段的形式展示。
- 提供丰富上下文:搜索引擎可以获得视频的缩略图、描述、时长、发布日期等关键信息。
- 更容易被发现:特别是对于嵌入在页面中、不直接出现在HTML结构中的视频。
- 帮助理解视频内容:通过标题、描述、标签等,帮助搜索引擎更好地理解视频内容主题。
🤖Robots
网页标签(页面级别指令)
<meta name="robots" content="index, follow">
- **
name="robots"**:这个属性表示这条<meta>标签是为所有搜索引擎爬虫(或称为“机器人”)提供的指令。 - **
content="index, follow"**:这是指令的核心内容,包含两个值,用逗号分隔。
index (或 **noindex)**:- **
index:告诉搜索引擎抓取并索引**这个页面。这意味着这个页面可以出现在搜索引擎的搜索结果中。- 注意:
index是搜索引擎的默认行为。也就是说,如果你的页面没有任何noindex指令,搜索引擎默认就会尝试索引它。所以,content="index"往往是冗余的,但明确写出来可以增强可读性或确保意图。
- 注意:
- **
noindex:告诉搜索引擎不要索引**这个页面。这意味着这个页面不会出现在搜索结果中。这通常用于:- 登录页、注册页
- 个人账户信息页
- 一些临时页面或测试页面
- 重复内容页面(希望搜索引擎只索引原版)
- 低质量或不重要的页面
- **
follow (或 **nofollow)**:- **
follow:告诉搜索引擎抓取并跟随**当前页面上的所有链接。这意味着搜索引擎会沿着这些链接继续爬取其他页面,并将这些链接视为正常的“投票”或“推荐”,从而可能传递 PageRank(现在称为链接价值或链接公平)。- 注意:
follow也是搜索引擎的默认行为。如果你的页面没有任何nofollow指令,搜索引擎默认就会尝试跟随页面上的所有链接。所以,content="follow"同样也是冗余的,但明确写出来可以增强可读性或确保意图。
- 注意:
- **
nofollow:告诉搜索引擎不要抓取并跟随**当前页面上的所有链接。这意味着搜索引擎不会沿着这些链接继续爬取其他页面,也不会将这些链接视为正常的推荐(即不传递链接价值)。这通常用于:- 用户评论中的链接(防止垃圾评论中的恶意链接)
- 论坛帖子中的链接
- 付费链接或广告链接(根据 Google 的规定,这些链接应该用
nofollow或sponsored属性标记) - 不信任的外部链接
- 指向网站内部不重要页面的链接,以控制抓取预算
- **
总之,<meta name="robots" content="index, follow"> 是一个明确告诉搜索引擎“这个页面很重要,请抓取、索引并跟随其中的链接”的指令,尽管在大多数情况下,省略这个标签也会达到相同的默认效果。
Robot.txt(全局)
官方地址:https://developers.google.com/search/docs/crawling-indexing/robots/intro?hl=zh-cn
robots.txt 也是一个简单的文本文件,通常命名为 robots.txt,放置在网站的根目录下。
User-agent: *
Disallow: /admin/
Disallow: /private/
Disallow: /temp/User-agent: Googlebot
Disallow: /dont-crawl-by-google/Sitemap: https://www.example.com/sitemap.xml
Sitemap: https://www.example.com/images-sitemap.xml
- **
User-agent**:指定规则适用的爬虫。*表示适用于所有爬虫。Googlebot仅适用于 Google 搜索引擎爬虫。
- **
Disallow**:指定不允许爬虫访问的URL路径。Disallow: /admin/表示不允许访问/admin/目录及其所有子目录和文件。Disallow: /private/index.html表示不允许访问/private/index.html这个特定文件。
- **
Allow**:在Disallow的规则下,允许访问特定的子路径(不常用,但有时会用到)。 - **
Sitemap**:指定 Sitemap 文件的URL。
重要说明:
- **robots.txt 是一个“建议”而非“强制”**。不遵守规则的恶意爬虫依然可以访问被
Disallow的内容。 Disallow 只是阻止抓取,不一定阻止索引。搜索引擎可能通过外部链接发现被Disallow的页面,并将其索引(尽管内容无法抓取),在搜索结果中可能显示为一个没有描述的链接。要完全阻止索引,需要使用noindex元标签。
Sitemap 和 robots.txt 的关系
Sitemap 和 robots.txt 都是用于指导搜索引擎的文件,但它们的作用是互补的,而不是替代的。
- Sitemap 告诉搜索引擎“我有哪些重要的页面希望你来抓取和索引”。
- 它是一个积极的推荐列表。
- robots.txt 告诉搜索引擎“我有哪些页面你不应该抓取”。
- 它是一个消极的禁止列表。
四、性能优化
网页性能和SEO之间存在非常强的正相关性。它们不是独立的因素,而是相互促进、共同影响网站在搜索引擎中排名的关键要素,因此放在一起阐述。
- 用户体验是核心,而性能是用户体验的基石。
- 搜索引擎关注用户满意度:Google等搜索引擎的目标是为用户提供最佳的搜索结果,而最佳的搜索结果不仅指内容相关,也指用户能流畅、快速地访问和使用。
- 快速加载减少跳出率:如果一个网页加载缓慢,用户很可能会失去耐心并直接关闭页面(跳出)。高的跳出率是搜索引擎判断用户体验不佳的一个负面信号。
- 积极的用户行为信号:相反,快速加载的网页能让用户更快地看到内容、进行交互,从而可能增加停留时间、点击更多链接,这些都是积极的用户行为信号,会提升网页的SEO表现。
- 搜索引擎直接将性能作为排名因素。
- **Core Web Vitals (核心网页指标)**:Google在2021年推出了Core Web Vitals作为正式的排名因素。这些指标直接衡量网页的用户体验,包括加载速度、交互性和视觉稳定性:
- **LCP (Largest Contentful Paint)**:最大内容绘制,衡量加载性能,即页面上最大内容元素(图片或文本块)渲染所需的时间。
- **FID (First Input Delay)**:首次输入延迟,衡量交互性,即用户首次与页面交互(点击按钮、输入文本)到浏览器实际响应之间的时间。
- **CLS (Cumulative Layout Shift)**:累积布局偏移,衡量视觉稳定性,即页面内容在加载过程中是否有意外的布局移动。
- 移动优先索引:Google现在主要使用移动版内容进行索引和排名。移动设备的网络环境可能不稳定,对性能的要求更高。一个在移动设备上表现良好的网站更有可能获得更好的排名。
- 爬虫效率:如果你的网站加载速度快,搜索引擎的爬虫(Crawler)可以更高效地抓取更多的页面,这有助于你的网站内容更快地被索引。如果网站速度慢,爬虫可能会因为“预算”限制而放弃抓取部分页面。
- **Core Web Vitals (核心网页指标)**:Google在2021年推出了Core Web Vitals作为正式的排名因素。这些指标直接衡量网页的用户体验,包括加载速度、交互性和视觉稳定性:
- 技术SEO与性能的交集。
- 渲染方式:现代前端框架(如React, Vue, Angular)的客户端渲染(CSR)可能导致初始HTML内容为空,不利于搜索引擎爬虫抓取。通过服务器端渲染(SSR)或静态网站生成(SSG)可以在服务器端预先生成完整HTML,提高首屏加载速度,同时解决SEO抓取问题。
- 图片优化:优化图片大小、格式(如WebP)、使用懒加载等,不仅提升了加载速度,也减少了带宽消耗,对用户和搜索引擎都友好。
- 代码优化:压缩CSS/JS、移除不必要的代码、延迟加载非关键资源等,都直接影响性能,也间接影响爬虫对页面内容的识别和解析。
✔静态资源优化 (LCP | FP | FCP )
这里的静态资源一般指图片、代码等
这里一般影响 LCP | FP | FCP 这三个参数
我们需要先分析当前网页的资源加载情况
可以使用浏览器自带的资源控制器进行查询
网络 > 停用缓存 > 全部
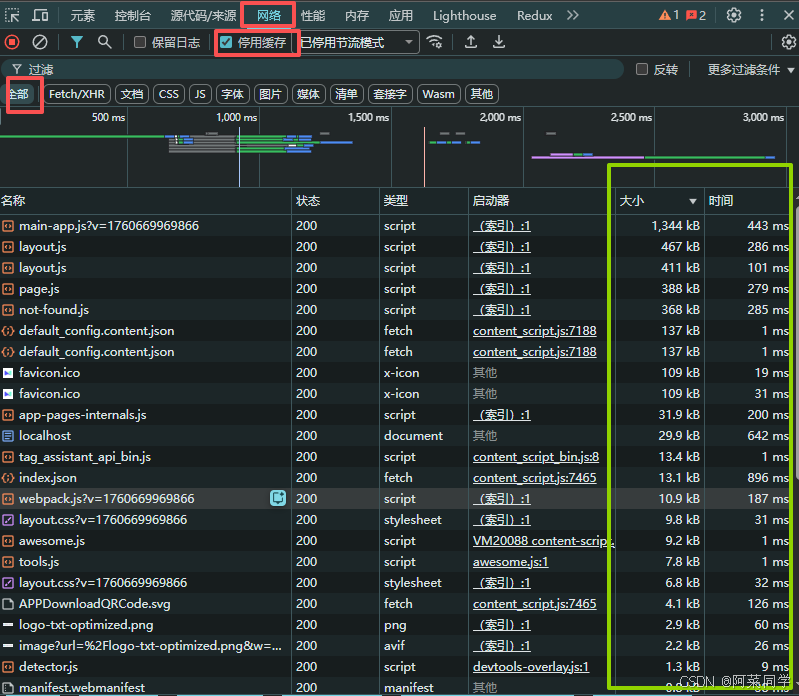
一般来说,大小跟时间都是成正比,用户最长等待时间不能超过3s,如果超过1s就可以观察到非常明显的卡顿白屏
图片资源优化👈️
优化格式
比如说换用webp格式
WebP 的优点(为什么值得使用):
- 文件大小更小:这是 WebP 最大的优势。与相同质量的 JPEG 和 PNG 相比,WebP 通常能将文件大小减少 25-34%,甚至更多,这意味着更快的加载速度和更少的带宽消耗。
- 支持有损和无损压缩:WebP 可以同时提供有损压缩(类似 JPEG,适合照片)和无损压缩(类似 PNG,适合图标、Logo),并且无损压缩也比 PNG 小。
- **支持透明度(Alpha 通道)**:与 PNG 一样,WebP 支持透明背景,同时文件大小比 PNG 小得多。
- 支持动画:WebP 也支持动画(类似 GIF),并且动画 WebP 文件通常比 GIF 文件小得多。
- 浏览器支持日益普及:主流的现代浏览器对 WebP 的支持度已经非常高。
但是请注意!!!,webp格式对浏览器版本是有要求的,如果你的目标用户群体中仍有大量的IE用户
或者旧版Safari(macOS 10.15 Catalina 及更早版本,iOS 13 及更早版本)
<picture> 标签:这是推荐的解决方案。它允许你指定多个图片源,浏览器会选择它支持的第一个格式。

优化大小
一般图片大小不超过150k,如果超过可以通过压缩的方式去处理
在网页端可能感知不深,但是在移动端对于网络情况非常敏感
图片压缩在线工具:https://tinypng.com/
优化体验
人都是视觉动物,看到白屏都会拉低用户体验,超过2s可能就会直接滑走导致用户流失
因此在上述优化后仍然受限于业务情况,例如接口等待超时或者网络超时,可以使用一些手段去优化体验
- 图片懒加载:监听可视区,优先处理可视区的图片,而不是全量加载
- 图片占位:可以主图加载的时候,在之上覆盖一层遮罩层,展示加载中的效果
- 图片预加载:对于网站图标或者主图,这些图片往往不会太大并且是首屏可见,可以使用预加载策略
- 骨架屏效果:整体加载可以使用骨架屏效果进行优化体验
- 图片缓存:对于经常使用的图片可以进行缓存,先检查本地再远程更新
- 缩略图效果:对于网络较差的情况可以给予一张缩略图效果覆盖在最顶层,等待真实图片加载
现代浏览器原生支持的 loading="lazy" 属性,这是最简单高效的懒加载方式
<img> 标签的 loading="lazy" 属性
JS资源优化👈️
优化大小
对于JS来说,一般都是避免单文件过大的情况,如果在本地运行发现JS文件比较大,这并不是真实的大小,因为在正式上线的时候,框架会先进行Tree Shakeing (树摇优化),大幅减少JS文件大小
如果还是文件过大,可以使用文件分片策略或者代码分割
优化加载顺序
- 默认情况下,
script标签会阻塞HTML解析。 defer:脚本会并行下载,但在HTML解析完成后、DOMContentLoaded事件之前执行,保持执行顺序。async:脚本会并行下载,下载完成后立即执行,不保证执行顺序。- 对于不依赖DOM或不关心执行顺序的脚本使用
async,对于依赖DOM或有执行顺序要求的脚本使用defer。
字体优化👈️
- **子集化 (Subsetting)**:只包含页面实际使用的字符,减少字体文件大小。
- Woff2 格式:现代浏览器支持,压缩率最高。
font-display 属性:控制字体加载时的显示行为(如swap、fallback)。
移动端优化👈️
弹窗检测
如果你发现在PC端不存在LCP问题,但是在移动端却出现了LCP问题。你需要先明白什么是LCP
LCP是最大内容绘制,它是按照你的页面布局中占比较大的模块认定为最大内容
如果最大内容绘制速度慢,LCP值会变得非常慢
很大可能是由于某些弹窗,例如语言检测弹窗、Cookie接受弹窗,这些弹窗在PC端往往并不是那么明显,但是在移动端,这些弹窗占据页面很大一部分的内容,导致被浏览器认定为是最大内容
因此解决方式也很简单,就是做延迟加载,避免让浏览器认定这些弹窗也属于当前网页的最大实际内容
✔渲染优化(LCP | CLS | FCP | TTI )
在业务场景中,通常就是因为频繁的监听某个元素或者节点,然后要对某个节点进行DOM操作,改变一些样式或者布局
例如在AI漫画翻译中在之前就有严重的CLS(累计布局偏移问题)和 TTI (可交互时间)
- 翻译数量显示(通过后端接口,拿到数据之后,动态插入到首屏,导致用户直接看到插入DOM的过程)
- 样式改变(所有的字体大小使用Rem格式,依赖于根元素的字体大小,但是设置根字体大小是网页加载之后设置,导致用户看到布局偏移)
布局偏移(CLS),导致本来的按钮位置发生偏移,导致用户无法正常点击按钮,导致可交互时间变长(TTI)。
首次内容绘制时间变长(FCP),导致最大内容绘制时间变长(LCP)
所以性能问题往往是一个链式反应。
优化体验
- 批量操作 DOM:使用 DocumentFragment 或修改 DOM 树外元素,然后一次性插入。
- 使用 CSS **
transform 和 opacity 进行动画**:这些属性不会触发布局或重绘,而是使用 GPU 进行合成。 - 避免在循环中读取计算样式:将计算结果缓存。
- 为图片和视频设置尺寸:在
<img>或<video>标签中明确设置width和height属性,或使用 CSSaspect-ratio,为浏览器预留空间,避免图片加载后撑开页面。 - 为广告、内嵌内容等预留空间:避免动态插入的广告或第三方组件导致页面内容跳动。
- 预加载字体或使用 **
font-display 策略**:避免因字体加载导致文本内容闪烁或大小改变引起的布局偏移。使用font-display: optional或swap可以减少对CLS的影响。
以AI漫画翻译官网举例
- 翻译数量确实需要后端提供数据支撑,但是前端可以先用
占位,比如翻译数量一开始是0,那就先给0,而不是给空,然后判定不为空再显示 - 对于页面整体大小基于根元素大小,那么可以使用
预加载的手段,把判断提前到网站加载前去设置,网站加载前早已可以获取页面实际大小 - 也可以选择
vw或者vh为单位基准,依赖于屏幕实际宽度或者高度,而不通过js动态检测的方式,往往性能更好
五、更多有用的小知识
Google 搜索从信息收集到呈现给用户的整个过程
https://developers.google.com/search/docs/fundamentals/how-search-works?hl=zh-cn
Google 搜索的工作流程分为 4个阶段,并非每个网页都会经历这 4 个阶段:
- 抓取 (Crawling):
- 目的: 发现互联网上的新网页和更新的网页。
- 工具: Googlebot(Google 的网络爬虫)。
- 工作方式: Googlebot 从已知网页的链接开始,不断跟踪这些链接去发现新的网页。它还会使用网站管理员提交的站点地图 (sitemaps) 来发现网页。
- 重要性: 如果 Googlebot 无法抓取你的网页,那么你的网页就无法被 Google 索引和排名。
- 控制抓取: 网站管理员可以使用
robots.txt文件来告诉 Googlebot 哪些页面可以抓取,哪些页面不应该抓取。
- 索引 (Indexing):
- 目的: 理解网页内容,并将其存储在 Google 的巨大数据库中。
- 工作方式: Googlebot 抓取到网页后,Google 会处理这些网页,分析其内容(文本、图片、视频等),理解其主题和含义。
- 关键信息提取: Google 会提取关键信息,如关键词、图片和视频内容、网页的结构和布局等。
- 存储: 这些信息被组织并存储在 Google 的搜索索引中,这是一个巨大的数字图书馆。
- 控制索引: 网站管理员可以使用
noindexmeta 标签来阻止 Google 索引某个页面,即使该页面被抓取了。
- 排名 (Ranking):
- 目的: 当用户输入查询时,从索引中找到最相关、最有用的结果,并按顺序排列。
- 复杂性: Google 使用数百个因素(信号)来评估网页的相关性和质量。
- 核心因素:
- 查询的含义: Google 会尝试理解用户查询的意图(例如,是想找图片、视频、新闻还是购物)。
- 网页的相关性: 网页内容与查询词语的匹配程度。
- 内容的质量: 网页是否提供高质量、有价值、可信赖的信息(E-E-A-T)。
- 可用性: 网页是否易于访问、加载速度快、移动设备友好、安全(HTTPS)。
- 上下文和设置: 用户的地理位置、历史搜索记录、设置等也会影响结果。
- 持续改进: Google 的排名算法不断更新和改进,以提供更好的搜索结果。
- 提供结果 (Serving Results):
- 目的: 以用户友好的方式呈现搜索结果。
- 多样性: 搜索结果页 (SERP) 不仅仅是蓝色链接,还包括各种功能,如图片、视频、新闻、地图、购物结果、精选摘要 (Featured Snippets)、知识面板 (Knowledge Panels) 等。
- 个性化: 结果可能会根据用户的地理位置、语言和之前的搜索历史进行一定程度的个性化。
- 用户体验: 旨在快速、清晰地向用户提供他们正在寻找的信息。
Google搜索流量权重
https://firstpagesage.com/seo-blog/the-google-algorithm-ranking-factors/
Google建议的JavaScript SEO做法
https://developers.google.com/search/docs/crawling-indexing/javascript/javascript-seo-basics?hl=zh-cn
检测当前网站是否被Google纳入索引
https://search.google.com/search-console/welcome?action=inspect&utm\_medium=referral&utm\_campaign=9012289&sjid=797295167314465338-NC