Rust内存问题检测
Rust内存问题检测
- 1.Rust背景知识
- 2.SafeDrop
- 2.1.Introduction
- 2.2.Motivating Example
- 2.3.问题描述
- 2.4.Approach
- 2.5.Evluation
- 3.rCanary
- 3.1.Introduction
- 3.2.Design
- 3.3.Encoder
- 3.4.Leak-Free Model
- 3.5.Evaluation
- 参考文献
两篇文章的工作已集成到RAPx中。
1.Rust背景知识
| 机制 / 特性 | 核心含义 | 关键约束 / 行为 | 与内存管理的关系 |
|---|---|---|---|
| Ownership所有权 | 每个变量独占其内存 | 可借用为引用;引用有生命周期限制 | 所有权决定资源释放时机 |
| Borrow借用 | 可变/不可变引用 | 生命周期 ≤ 所引用对象;可变引用不可别名 | 防止悬空引用与数据竞争 |
| Raw Pointer 原始指针 | 传统裸指针 | 可能违反内存安全,仅能在 unsafe 中使用 | unsafe 代码的风险来源 |
Copy trait | 可安全复制的栈上值 | 赋值产生拷贝,旧变量仍可用 | 无需所有权转移与 drop |
Drop trait | 需显式析构的类型 | move 时转移所有权;作用域结束自动 drop | 控制资源释放与析构顺序 |
| RAII + Drop Scope | 资源绑定生命周期 | 离开作用域即自动调用析构函数 | 无需GC即可自动内存回收 |
// Copy 类型示例(栈上值)
fn copy_example() {let x = 5;let y = x; // Copy:复制一份println!("x = {}, y = {}", x, y); // x 仍可用
}// Drop 类型示例(堆上值)
fn drop_example() {let s1 = String::from("hello");let s2 = s1; // Move:所有权转移,s1 无效println!("{}", s2); // ✅ 只能使用 s2// s2 离开作用域时自动drop()释放堆内存
}// Borrow(借用)规则示例
fn borrow_example() {let mut s = String::from("hi");let r1 = &s; // 不可变借用// let r2 = &mut s; // ❌ 不可变借用后不能再可变借用println!("{}", r1);
}// Raw Pointer(原始指针)示例
fn raw_pointer_example() {let s = String::from("raw");let p = &s as *const String; // 原始指针unsafe {println!("{:?}", *p); // 需在 unsafe 中解引用}
}// RAII + Drop Scope 示例
struct D;
impl Drop for D {fn drop(&mut self) {println!("D dropped!");}
}
fn raii_example() {let _d = D; // 离开作用域时自动调用 drop()
}
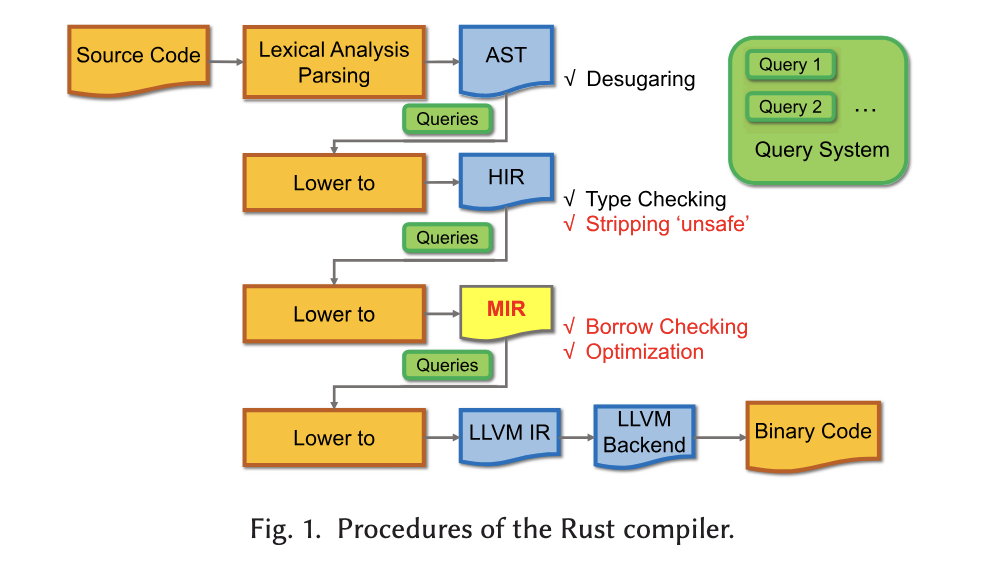
从源码编译到HIR最后到可执行的路径如下图所示
MIR层面核心语法如下图所示

| 语法元素 | 子形式 | 主要语义 | 与资源管理的关系 |
|---|---|---|---|
| BasicBlock | { Statement } Terminator | MIR的基本执行单元,由若干语句和一个终止语句组成。 | 承载资源创建、借用与释放等操作,是分析粒度的基础。 |
| Statement | LValue = RValue、 StorageLive(v)、StorageDead(v) | 为赋值或生命周期标记。 | 描述资源的使用与生存期边界。 |
| Terminator | 控制流语句,如 Goto(BB)、If(v, BB0, BB1)、Drop(v)、SwitchInt(v, BB0, ...)、FnCall(...) | 控制基本块跳转与函数执行流。 | 决定资源释放和异常路径 panic 是否被触发。 |
| StorageLive / StorageDead | StorageLive(x) / StorageDead(x) | 标记变量 _x 的作用域起止。 | 生命周期边界,决定是否触发 drop。 |
| Drop(v) | Drop(x) | 调用 x 的析构函数。 | 自动触发资源释放(RAII 实现点)。 |
| Panic(BB) | Panic(BB_unwind) | 表示异常展开路径。 | 通过 unwind 路径确保异常时也释放资源。 |
| FnCall | LValue = (FnCall, BB0, BB1) | 调用函数并指定正常/异常后继块。 | 可能引入跨函数资源传递或释放。 |
| SwitchInt/If | SwitchInt(v, BB0, BB1, …), If (v, BB0, BB1) | 条件控制流分支。 | 影响资源释放路径的选择。 |
| move | x = move y | 将所有权从 y 移动到 x,y 失效。 | 明确所有权转移(防止 double free)。 |
| &mut / & | x = &mut y / x = &y | 创建(可变 / 不可变)引用。 | 表示借用关系,影响alias分析。 |
| 解引用 | x = *y | 从 y 创建原生指针。 | 绕过borrow 检查,潜在 unsafe 源。 |
2.SafeDrop
2.1.Introduction
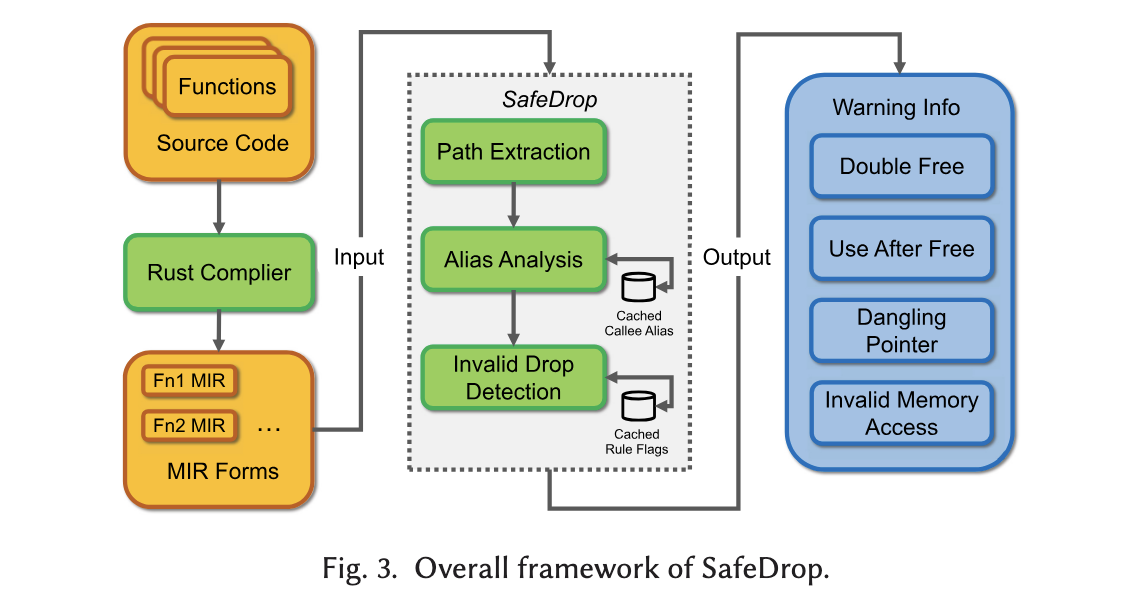
主要针对Rust自动 drop 机制下可能产生的use-after-free与double free等资源管理漏洞进行检测。尽管Rust编译器及其borrow checker提供了完善的内存安全保障,但仍无法覆盖所有与自动 drop 相关的潜在问题。编译器在生成MIR时会去除 unsafe 标记,其内存模型也无法精确分析raw pointer之间的别名关系,从而无法确保内存回收的完全正确性。为弥补这一缺陷,作者提出了 SafeDrop [ 1 ] ^{[1]} [1],一种面向Rust程序的静态数据流分析方法,用于检测自动内存释放过程中的安全隐患。
| Rust 特性 | 核心机制 / 含义 | 导致的挑战或分析需求 | SafeDrop 的应对思路 / 利用方式 |
|---|---|---|---|
| Safe/Unsafe 边界 | Rust 区分 safe code 与 unsafe code,safe code中禁止出现共享可变别名(shared mutable aliasing);若要绕过,必须显式使用 unsafe。 | 分析器需要定位哪些代码可能引入共享可变别名。 | 只需重点分析少量 unsafe API(如 from_raw_parts()),将检测范围缩小,提高效率与准确性。 |
| 所有权(Ownership)模型 | 每个值都有唯一所有者,所有权可在变量间“移动”(move),从而决定资源何时被释放。 | 必须在数据流分析中跟踪所有权转移,否则无法判断资源的真实生命周期。 | SafeDrop在数据流中显式建模所有权的传递,追踪值从创建到 drop 的路径,以检测错误释放。 |
| RAII与自动drop | Rust在作用域结束时自动插入 drop 调用来释放资源(在MIR层表现为统一的 drop 语句)。 | 自动释放可能引发 use-after-free 或 double free(如显式 drop + 自动 drop)。 | SafeDrop 聚焦分析MIR中的 drop 调用,检测可能的悬空引用与重复释放。 |
2.2.Motivating Example
下面示例中 s 和 v 共享同一块内存区域
fn genvec() -> Vec<u8> {let mut s = String::from("a_tmp_string");let ptr = s.as_mut_ptr();let v;unsafe {v = Vec::from_raw_parts(ptr, s.len(), s.len());}// mem::forget(s); 若不加此行,s会在return前被dropreturn v;
}fn main() {let v = genvec(); use(v); // 使用v时访问已释放的内存 => use-after-free// 会再次触发一次drop,造成double free
}
fn genvec() -> Vec<u8> {
bb0:_1 = <String as From<&str>>::from(const "a_tmp_string") -> bb1; // let mut s = String::from("a_tmp_string");
bb1: // let ptr = s.as_mut_ptr();_5 = &mut _1; // 取s的可变引用_4 = <String as DerefMut>::deref_mut(move _5) -> [return: bb2, unwind: bb9]; // 解引用获取底层str
bb2: // s.as_mut_ptr()_3 = &mut (*_4); // 再次取底层可变引用_2 = core::str::<impl str>::as_mut_ptr(move _3) -> [return: bb3, unwind: bb9]; // 调用as_mut_ptr()获取原始指针
bb3: // let ptr = s.as_mut_ptr();以及后续len()调用的第一部分_8 = _2;_10 = &_1; // 获取s的不可变引用_9 = String::len(move _10) -> [return: bb4, unwind: bb9]; // 调用s.len()获取s长度
bb4:_12 = &_1;_11 = String::len(move _12) -> [return: bb5, unwind: bb9]; // 调用s.len()获取s长度
bb5: // unsafe { v = Vec::from_raw_parts(ptr, s.len(), s.len()); }_0 = Vec::<u8>::from_raw_parts(move _8, move _9, move _11)-> [return: bb6, unwind: bb9];// Real-world programs could have more code here, and it may panic the program.
bb6:drop(_1) -> bb7; // ⚠ Invalid Drop of Normal Execution// calling mem::forget(s) can remove this drop statement
bb7:return;
bb8: // 异常展开路径自动插入 — drop(v)drop(_0) -> bb9; // ⚠ Invalid Drop of Exception Handling
bb9: // unwind继续清理sdrop(_1) -> bb10; // unwind path
bb10:resume;
}main:drop(_0); // final invalid drop in main (double free)
执行逻辑:1.String::from 分配堆内存(s 拥有内存的所有权)。2.s.as_mut_ptr() 取得原始指针 ptr。3.Vec::from_raw_parts(ptr, …) 使用原始指针创建了新的 Vec,该 Vec 认为它拥有这块内存的所有权。4.此时 s 仍然会在 genvec 函数结束时被自动 drop,除非在末尾加上 mem::forget(s)。5.use(v) 访问被 drop 的内存造成use-after-free。6.新创建的 v 也会在外部作用域被 drop 一次,导致 double free。7.除此之外在异常处理路径,也存在两次 drop 造成double free。
其中涉及到的别名链 _1 → _5 → _4 → _3 → _2 → _8 → _0。添加 mem::forget 可以修复正常路径上的dangling pointer,但是异常处理路径上的不好修复。
struct Foo {vec: Vec<i32>,
}impl Foo {pub unsafe fn read_from(src: &mut Read) -> Foo {let mut foo = mem::uninitialized::<Foo>(); // 分配但未初始化let s = slice::from_raw_parts_mut(&mut foo as *mut _ as *mut u8,mem::size_of::<Foo>());src.read_exact(s);foo}
}
// MIR for unsafe fn Foo::read_from(src: &mut Read) -> Foo
bb0: {// let mut foo = mem::uninitialized::<Foo>();_0 = const std::mem::uninitialized::<Foo>() -> bb2;
}
bb2: {// &mut foo_6 = &mut _0;// &raw mut (*_6)_5 = &raw mut (*_6);// (*_5) as *mut u8_4 = _5;_3 = move _4 as *mut u8 (Misc);// mem::size_of::<Foo>()_7 = const std::mem::size_of::<Foo>() -> [return: bb3, unwind: bb4];
}
bb3: {// slice::from_raw_parts_mut(&mut foo as *mut u8, mem::size_of::<Foo>())_2 = const std::slice::from_raw_parts_mut::<u8>(move _3, move _7)-> [return: bb5, unwind: bb4];
}
bb5: {// src.read_exact(s)_9 = &mut (*_1);_10 = &mut (*_2);_8 = const <dyn std::io::Read as std::io::Read>::read_exact(move _9, move _10) -> [return: bb6, unwind: bb4];// ⚠ 若此处 panic,则进入 unwind → bb4// Panic before the buffer has been fully initialized
}
bb6: {// 正常路径:函数返回foodrop(_8) -> [return: bb7, unwind: bb4];
}
bb7: {return;
}
// 异常路径:unwind 处理
bb4: {// ⚠ drop(_0) 释放未初始化的 foo// → invalid drop of exception handlingdrop(_0) -> bb1;
}
bb1: {resume; // 继续异常传播
}
执行逻辑:1.mem::uninitialized::<Foo>() 仅分配内存空间,但未构造 Foo 对象(内部字段未初始化)。2.如果 read_exact 在中途 panic,程序会触发 stack unwinding(异常展开)。3.在异常路径中,Rust的RAII会尝试 drop 尚未完全初始化的 foo。4.由于 foo 内部字段未构造完成(例如 vec 未初始化),drop(foo) 将访问未定义内存。
2.3.问题描述
在采用RAII机制的语言中,程序会根据静态策略自动释放资源。然而,由于静态分析能力有限,这种自动释放有时会错误地处理内存,导致安全隐患。主要存在两类问题:(1).释放仍在使用的缓冲区,即在对象仍可能被访问时提前释放,产生dangling pointer并引发 use-after-free 或 double free;(2).释放无效指针,包括对dangling pointer的重复释放,以及对尚未初始化且包含指针字段的内存进行释放,导致递归释放和非法访问。虽然这些问题在C++等RAII语言中也存在,但在以内存安全为核心目标的Rust中尤为严重,因此更需要系统性的检测与防护机制。
作者定义了下面几种pattern,涉及 use-after-free(UAF)、double free(DF)、invalid memory access (IMA)。
Pattern 1: getPtr() -> unsafeConstruct() -> drop() -> use() => UAF
Pattern 2: getPtr() -> unsafeConstruct() -> drop() -> drop() => DF
Pattern 3: getPtr() -> drop() -> unsafeConstruct() -> use() => UAF
Pattern 4: getPtr() -> drop() -> unsafeConstruct() -> Drop() => DF
Pattern 5: getPtr() -> drop() -> use() => UAF
Pattern 6: uninitialized() -> use() => IMA
Pattern 7: uninitialized() -> drop() => IMA
挑战:1.需要准确处理不同MIR指令(如 move、可变借用、不可变借用、解引用等)带来的别名关系。2.Rust对象是否需要在生命周期结束时调用析构函数(drop)取决于其类型是否实现了 Drop trait;复合类型的 Drop 属性还可能由其字段类型自动推导,因此必须推断每种类型的 trait 信息以正确捕获MIR语义。3.分析工具还需具备良好的实用性,即在保持高检测率的同时减少误报。
2.4.Approach
| 名称 | 核心思路 | 关键技术 / 特点 | 输出 |
|---|---|---|---|
| Path Extraction | 使用meet-over-paths (MOP) path-sensitive算法从函数的MIR中枚举执行路径。 | 采用改进的Tarjan 算法合并冗余路径并生成生成树(spanning tree),通过遍历生成树枚举所有有价值路径。 | 获取每个函数的有效执行路径集,为后续分析提供基础。 |
| Alias Analysis | 对每条路径执行flow-sensitive与field-sensitive分析算法,建立变量及其复合字段间的别名关系。 | 分析为inter-procedural但context-insensitive;通过缓存和复用函数参数与返回值间的别名集提高效率。 | 构建每条路径的alias sets,记录潜在共享内存关系。 |
| Invalid Drop Detection | 基于alias sets,识别潜在的危险 drop 模式(如 use-after-free、double free、invalid memory access)。 | 在每条数据流上匹配易受攻击的drop模式,提取可疑的代码片段位置。 | 输出警告信息与对应代码位置,提示潜在的内存释放漏洞。 |
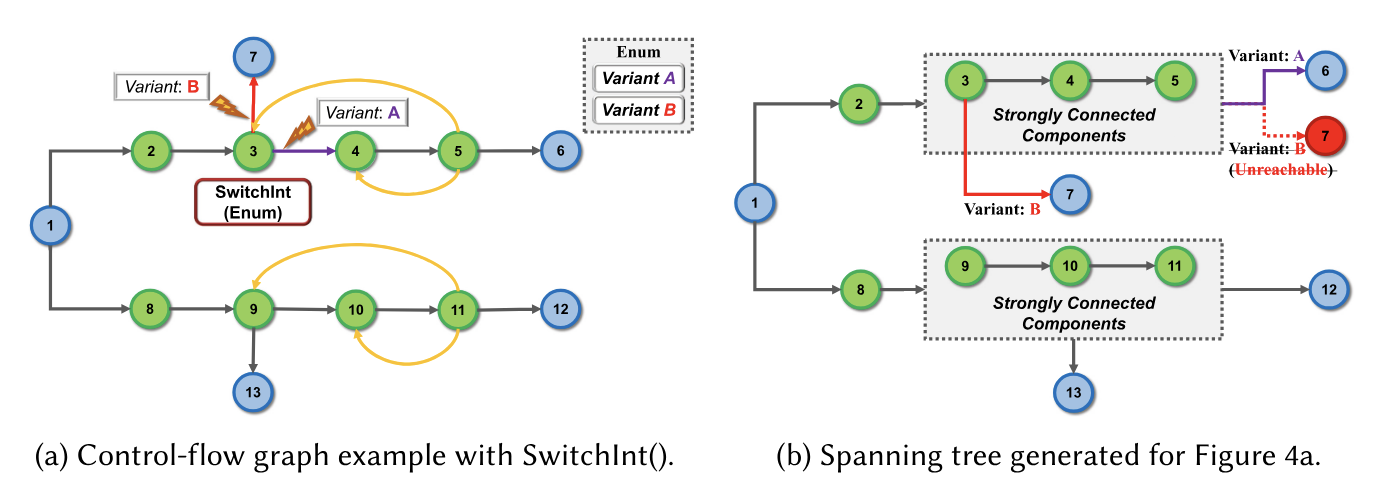
整体算法如下,Path Extraction部分在line 3生成spanning tree st,此后按照 DFSTraverse 的方式遍历spanning tree,不过DFS相比path enumeration而接近IFDS/IDE。每遍历一个spanning tree node 会调用 AnalyzeAlias 和 Detect bug分析这一步的别名和taint情况。

对于下面CFG,其spanning tree如下,SCC中的环路会被消除。
alias analysis对应IFDS/IDE算法的flow function部分,fact为alias sets,下面每一步都会更新alias sets中某些set。
Statement 1: _2 = &_1; // alias set:{_1, _2}
Statement 2: _1 = move _4; // alias sets:{_1, _4}, {_2}
Statement 3: _3 = &_1; // alias sets:{_1, _3, _4}, {_2}
下面为更新规则,其中AddressOf / Ref和Deref 会忽略pointer-level。
| 语句类型 | MIR语句形式 | 示例 | 语义解释 | Alias 集更新操作 |
|---|---|---|---|---|
| Move | LValue := move RValue | a = move b | 所有权从 b 移动到 a,b 失效 | S a = S a − a S_a = S_a - a Sa=Sa−a, S b = S b ∪ a S_b = S_b \cup a Sb=Sb∪a |
| Copy | LValue := RValue | a = b | a复制自 b,但 b 保留所有权 | S a = S a − a S_a = S_a - a Sa=Sa−a, S b = S b ∪ a S_b = S_b ∪ a Sb=Sb∪a |
| AddressOf / Ref | LValue := &RValue | a = &b | a 成为 b 的引用 | S a = S a − a S_a = S_a - a Sa=Sa−a, S b = S b ∪ a S_b = S_b ∪ a Sb=Sb∪a |
| Deref | LValue := *RValue | a = *(b) | a 指向 b 所指对象 | S a = S a − a S_a = S_a - a Sa=Sa−a, S b = S b ∪ a S_b = S_b ∪ a Sb=Sb∪a |
| Function Call (Move) | LValue := Fn(move RValue) | a = Fn(move b) | 函数参数通过 move 传递所有权 | Update ( S a , S b ) \text{Update}(S_a, S_b) Update(Sa,Sb) |
| Function Call (Copy) | LValue := Fn(RValue) | a = Fn(b) | 函数参数通过 copy 传递 | Update ( S a , S b ) \text{Update}(S_a, S_b) Update(Sa,Sb) |
此外不是每个类型的变量的alias set都会被追踪,SafeDrop仅关注实现了 Drop trait的类型的变量,此外实现了下面类型过滤规则。
| 类型 | 语义说明 | Alias集更新 |
|---|---|---|
Type::{Bool, Char, Int, UInt, Float} | 基本类型均实现 Copy trait,无需追踪 | 直接丢弃 |
Type::Array | 取决于元素类型是否需追踪 | 若元素类型全为可过滤类型,则过滤;否则保留 |
Type::Tuple | 取决于每个项的类型 | 所有项均可过滤时才过滤 |
Type::Structure | 取决于每个字段类型 | 所有字段均可过滤时才过滤 |
Type::Enumeration | 取决于每个变体类型 | 所有变体均可过滤时才过滤 |
Type::Union | 取决于每个字段类型 | 所有字段均可过滤时才过滤 |
Bug检测规则如下
| Bug 类型 | 检测条件(根据 alias/taint) | 示例说明 |
|---|---|---|
| Use After Free | 被使用的变量是 tainted(表示之前已被 drop) | x 被 drop 后再次使用 |
| Double Free | 被 drop 的变量仍 tainted | 同一内存块被释放两次 |
| Invalid Memory Access | 被使用或释放的变量被标记为 “uninitialized” tainted | 对未初始化的内存进行访问或释放 |
| Dangling Pointer | 函数返回值是 tainted(即指向已释放内存) | 返回指向栈内局部对象的指针 |
2.5.Evluation
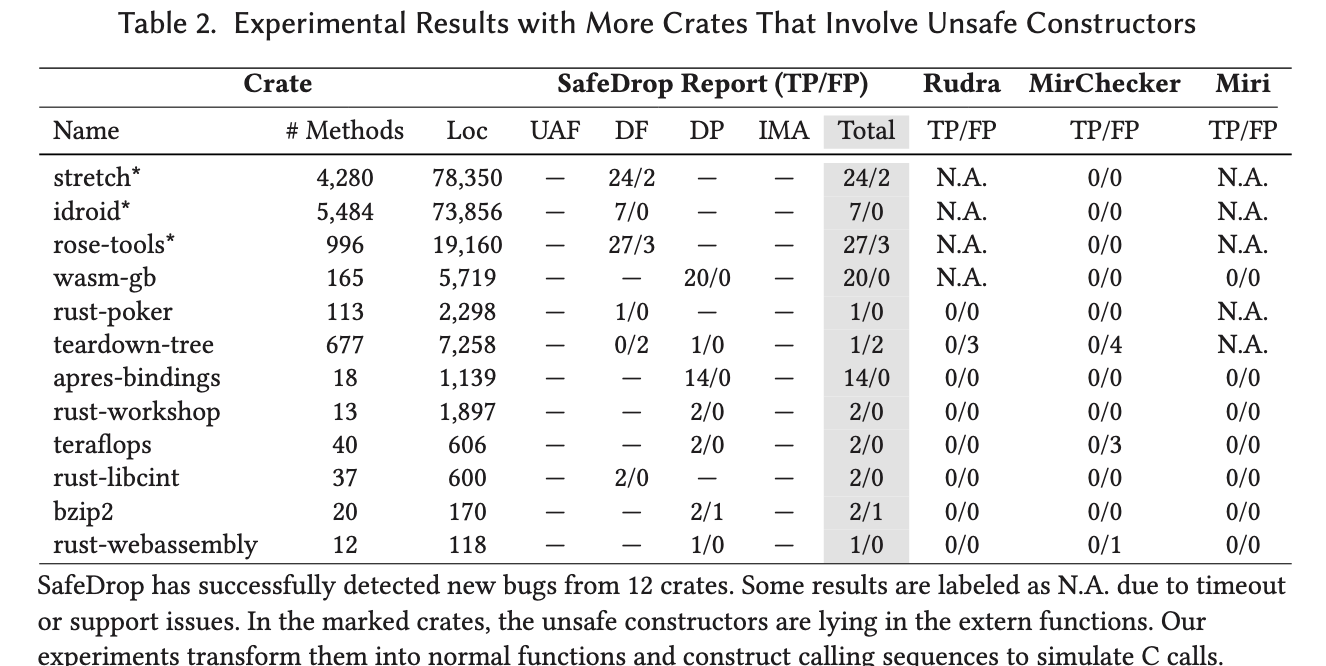
实验用了50个Rust crate,其中在12个上找到了新bug,对比效果如下
3.rCanary
3.1.Introduction
Rust的所有权模型基于RAII原则自动管理资源,但由于 ManuallyDrop 等机制允许用户绕过自动释放,若程序员未手动调用释放操作,就会造成内存泄漏。论文据此定义了 rtoken 并识别出两种典型的泄漏模式。
1.Orphan Object是指被 ManuallyDrop 封装的堆分配对象。当对象被封装进 ManuallyDrop 后,Rust编译器在MIR中不会为它生成 drop() 调用;这意味着编译器不再负责自动释放该对象的资源;如果开发者没有手动释放它(如使用 drop_in_place()),就会造成内存泄漏。buf 原本是堆上对象的所有者,拥有 rtoken;调用 ManuallyDrop::new() 后,buf 的析构被禁用,它成为 orphan object;ptr 持有原始指针,但不具备自动释放能力;若未显式执行 unsafe { drop_in_place(ptr) },则造成泄漏。
2.Proxy Type(代理类型)泄漏: Proxy Type是包含至少一个orphan object字段的复合类型。如果用户自定义类型(如结构体)含有 orphan object 字段,编译器即使自动为整个类型插入 drop(),也不会自动释放其字段中的 orphan object;因此开发者必须在其 Drop 实现中显式调用 drop_in_place() 释放字段。
// example 1
let mut buf = Box::new("buffer");
let ptr = &mut *ManuallyDrop::new(buf) as *mut _;// example 2
struct Proxy<T> { ptr: *mut T }impl<T> Drop for Proxy<T> {fn drop(&mut self) {// 手动释放字段 ptrunsafe { drop_in_place(self.ptr); }}
}fn main() {let mut buf = Box::new("buffer");let ptr = &mut *ManuallyDrop::new(buf) as *mut _;let proxy = Proxy { ptr };
}
3.2.Design
rCanary的设计需要考虑下面3种情况
| 目标 | 说明 |
|---|---|
| 1. 抽象性(Abstraction) | 专注于堆上分配的值(heap values),识别并编码这些值以进行模型检查。支持 Rust 的主要类型特性,如泛型和单态化。选择 MIR 的变量(local)作为分析目标,因为其保留类型信息并通过类型检查。 |
| 2. 可用性(Usability) | 被设计为通用Rust静态分析器。应能逐个分析crate,报告跨边界的潜在泄漏。作为Rust工具链的外部组件,支持Cargo项目,提供用户友好接口,流程全自动、无需注解。 |
| 3. 效率(Efficiency) | 基于布尔可满足性原理:遍历 MIR 函数生成约束,并用 Z3 求解。需在精度与效率间平衡,以应对大规模 Rust 项目。 |
因此rCanary的设计如下图所示
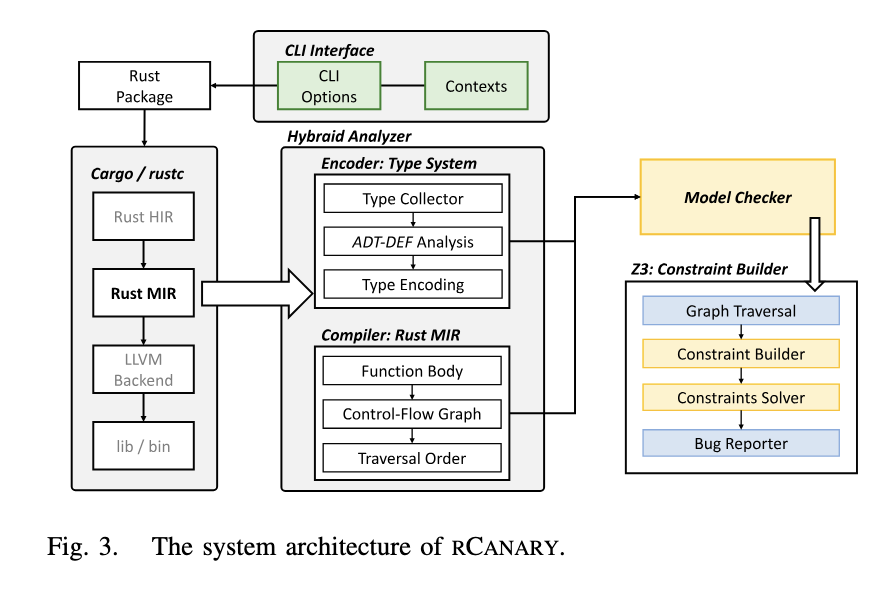
| 组件 | 功能说明 |
|---|---|
| 1. CLI Interface | 前端命令行接口(CLI),作为 Rust 工具链的外部组件实现,可作为 Cargo 的子命令调用。解析参数并初始化配置,在所有 MIR passes 完成后输出编译元数据。分析完成后,错误报告器(bug reporter)会提示潜在的内存泄漏及其位置。 |
| 2. Hybrid Analyzer | 后端的第一部分,基于Rust MIR构建的混合分析器。分析CFG的节点顺序,并使用 Tarjan 算法消除循环。设计了类型编码器(encoder),将任意类型转换为固定长度的位向量(bit vectors),编码复杂度为线性。编码过程先分析类型定义,再利用结果加速单态化类型的编码。 |
| 3. Model Checker | 后端的第二部分,负责基于形式化规则检测内存泄漏。采用flow-sensitive、fleid-sensitive的无泄漏内存模型。利用混合分析器提供的编码器和MIR元数据,将值编码为Z3变量,并依据语句生成Z3断言。最后调用Z3 求解器解约束并输出报告。 |
3.3.Encoder
一个Rust程序包含多种类型,主要分为三类:基本类型(primitives)、对象类型(objects)、指针类型(pointers),每种对象类型都有一组构造函数(constructors) 和唯一的析构函数(destructor)。构造函数可表现为函数(如 Vec::new)或局部变量初始化。析构函数即该类型的唯一 Drop 实现。
| 概念 | 说明 |
|---|---|
| RToken | 表示对象在完全初始化状态下的数据抽象,以 固定长度的位向量(bit vector)形式表示,Rtoken每一个bit表示为( σ ∈ { − 1 , 0 , + 1 } \sigma \in \{-1, 0, +1\} σ∈{−1,0,+1})、 σ = − 1 σ = −1 σ=−1 表示未初始化(uninitialized)、 σ = 1 \sigma = 1 σ=1 表示持有堆对象(holding heap item)、 σ = 0 \sigma = 0 σ=0 表示非堆对象(stack、freed、moved 等情况),顶元素 ⊤ = − 1 \top = −1 ⊤=−1、底元素 ⊥ = 0 \bot = 0 ⊥=0。 |
| Heap-Item Unit | 堆对象单元的形式,一个堆对象单元必须同时包含一个带有泛型参数类型 T 的 PhantomData<T> 字段,以及一个用于存储该类型值 T 的指针字段。该结构体现了堆分配类型的基本特征——具有显式的堆存储指向关系,并由编译器通过类型系统感知其堆分配语义。 |
| Isolated Parameter | 一个独立存在的、有具体类型的泛型参数,例如 T,但不包括被引用或修饰的形式(如 &T)。该定义用于判断泛型参数在单态化(monomorphization)后是否可能成为堆对象类型。 |
-
预处理阶段:系统通过跨函数访问器
CollectTypes收集所有类型(包括本地crate与依赖项),生成类型集合adtdefs。随后使用ExtractAdtDefs提取复合类型定义,并在AnalyzeDependencies中对字段进行扁平化,构建类型依赖图depG。由于Rust不允许复合类型递归,但允许泛型参数递归,分析在泛型层面打破递归,最终得到一个有向无环图(DAG)。 -
类型分析阶段:rCanary判断每种类型及其单态化(monomorphization)形式是否构成堆对象。
-
求解阶段(Result Solving):对每个依赖图连通分量
depCC,使用InverseToposort计算逆拓扑顺序,并递归检测各AdtDef是否包含Heap-Item Unit或Isolated Parameter。分析结果包括两个部分:(1)是否包含堆对象的布尔值;(2)标示各泛型参数是否为孤立参数的布尔向量(如Vec<T, A>→ [ 0 , 1 ] \rightarrow [0, 1] →[0,1])。通过逆拓扑顺序可高效地沿依赖关系传递结果,并缓存分析结果以减少重复计算。

RToken编码过程的目标是确定一个类型在完全初始化后哪些字段对应堆对象,并以位向量(bit vector)的形式进行编码。编码器会遍历类型的每个字段,并调用 EncodeField 函数判断该字段是否为堆对象。由于字段的类型由 AdtDef 和 GenericArgs 组成,编码器首先在缓存中查询该 AdtDef 是否包含heap-item unit;若没有,则会继续递归检查所有isolated parameters,判断其泛型实参是否映射为堆对象类型。以 String 和 Vec<u8, Global> 为例:String 的 RToken为 [ 1 ] [1] [1]。算法分析发现其底层字段是对 Vec 的单态化实例,而 Vec<T, A> 已包含堆对象单元,因此无需进一步处理泛型。Vec<u8, Global> 的 RToken 编码为 [ 1 , 0 ] [1, 0] [1,0]。算法先分析其 RawVec 字段并检测到堆对象单元,再分析第二个字段 usize,得出结果为 0。该算法时间复杂度为 O ( f . d ) O(f.d) O(f.d),其中 f f f 表示字段最大数量, d d d 表示泛型参数最大深度。通过对 AdtDef 的缓存(哈希表)加速,算法避免了在字段中递归搜索或重复处理不同的单态化形式。对于 trait 对象和泛型参数,系统采取保守策略,将它们默认视为堆对象。此外,对于指针类型,其 RToken 构造结果恒为 [ 0 ] [0] [0]。
3.4.Leak-Free Model
Leak-Free 模型的核心目标是追踪堆对象在函数执行过程中的所有权流动。分析中每个堆对象都被抽象为一个RToken,每个bit表示结构体字段是否持有堆资源(heap item)。分析器在每条MIR语句上更新 ( H ; M ; C ) (H; M; C) (H;M;C) 三元组:
| 符号 | 含义 |
|---|---|
| H | 所有堆对象的集合 |
| M | 当前作用域下各变量持有的RToken状态映射 |
| C | 约束集合,记录RToken更新规则与所有权条件 |
当程序点执行 drop、return 或分析结束时,如果仍有RToken存在 + 1 +1 +1 的bit,则说明对应堆对象未被释放,从而报告memory leak。具体分析规则如下(有点乱,以后再整理)

3.5.Evaluation
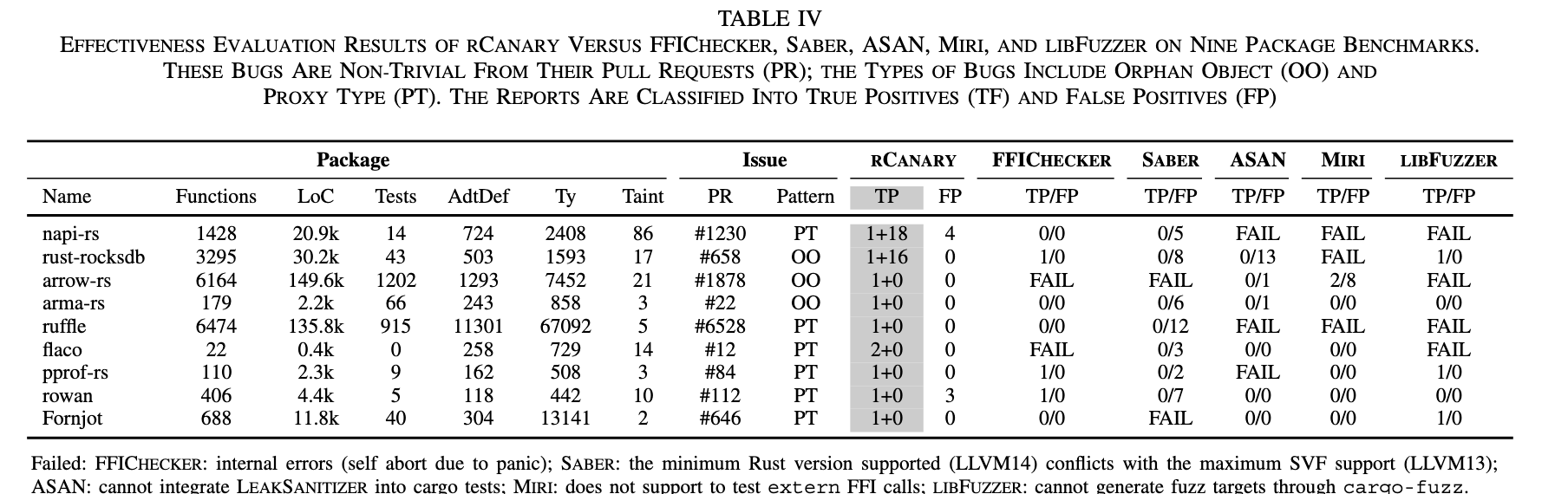
和Saber、FFIChecker等工具进行了对比,效果如下
参考文献
[1].Mohan Cui, Chengjun Chen, Hui Xu, and Yangfan Zhou. 2023. SafeDrop: Detecting Memory Deallocation Bugs of Rust Programs via Static Data-flow Analysis. ACM Trans. Softw. Eng. Methodol. 32, 4, Article 82 (July 2023), 21 pages.
[2].M. Cui, H. Xu, H. Tian and Y. Zhou, “rCanary: Detecting Memory Leaks Across Semi-Automated Memory Management Boundary in Rust,” in IEEE Transactions on Software Engineering, vol. 50, no. 9, pp. 2472-2484, Sept. 2024