[人工智能-大模型-138]:如何把文本语言转化成词向量,然后作为模型的输入?给出中间每个步骤的输入和输出的实例值。
下面我将 以一个具体的中文/英文混合示例,一步一步展示如何将文本转化为词向量并作为模型输入,并在每一步给出:
- ✅ 步骤说明
- ✅ 输入(Input)
- ✅ 输出(Output)及实例值
- ✅ 代码片段(Python + PyTorch)
🎯 目标任务:情感分类(正面 / 负面)
我们有以下三句话用于训练:
1. I love this movie!
2. This film is terrible.
3. Amazing acting and great story.
我们将通过 7个清晰步骤 把这些文本变成可以喂给神经网络的词向量。
🔢 全流程详解(含每步输入输出示例)
✅ 步骤 1:原始文本清洗与标准化
🔹 功能
去除标点、转小写、去噪
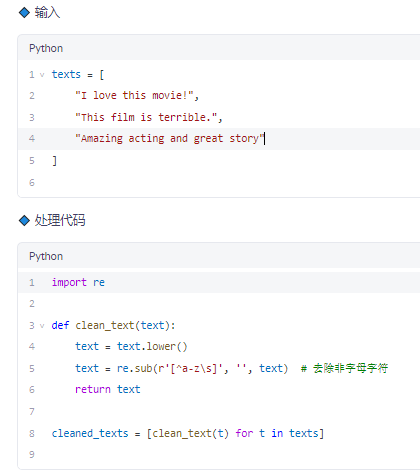
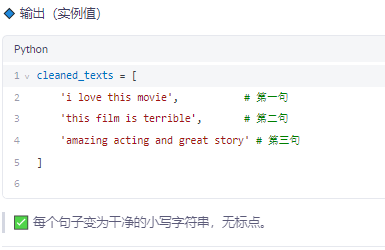
✅ 步骤 2:分词(Tokenization)
🔹 功能
把每个句子拆成单词列表
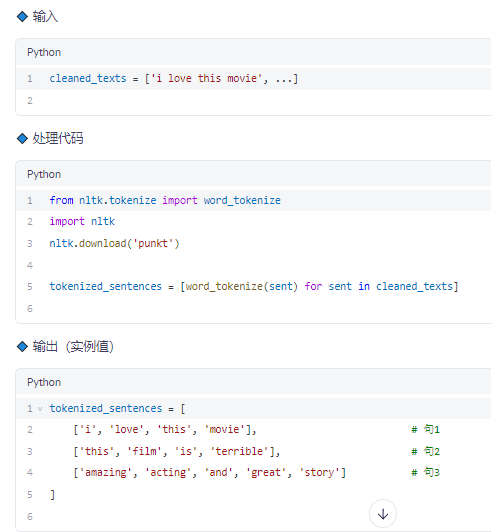
✅ 每个句子是一个词列表。
✅ 步骤 3:构建词汇表(Vocabulary)
🔹 功能
为每个唯一词分配一个整数 ID
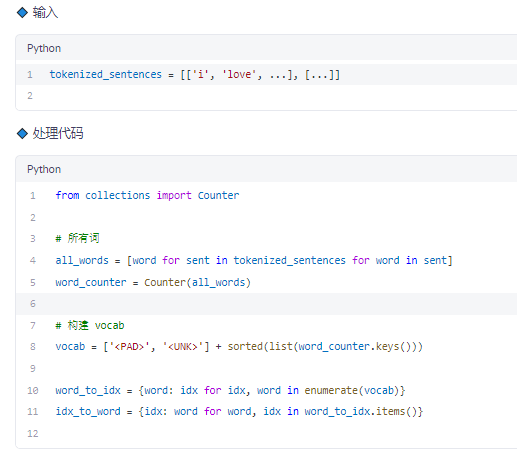
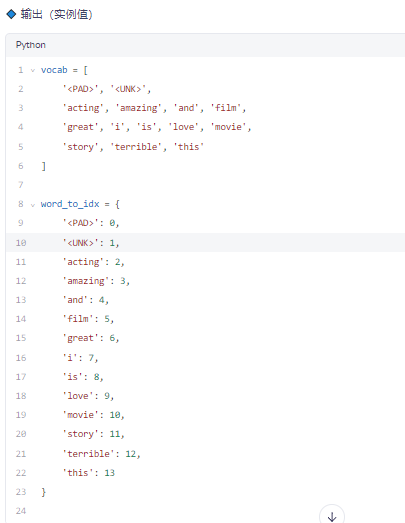
✅ 总共 14 个词(含特殊标记),每个词对应唯一索引。
✅ 步骤 4:将句子转为索引序列(Index Sequence)
🔹 功能
用数字替换词语,并统一长度(padding)
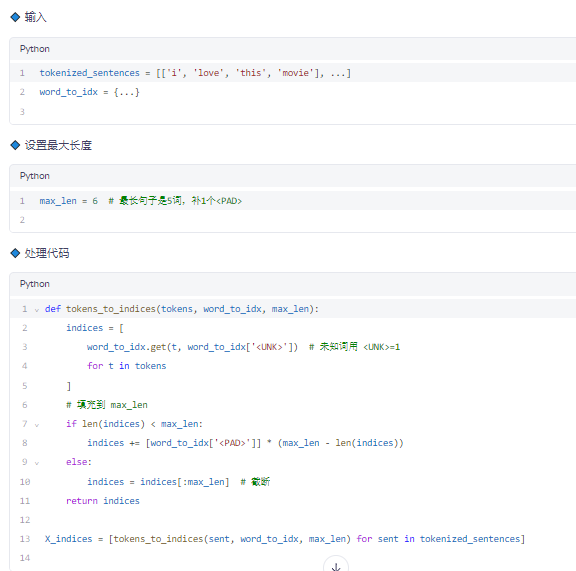
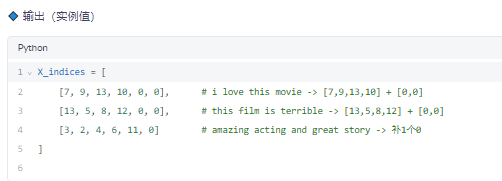
✅ 形状:(3 句, 6 词) → 可转为张量
✅ 步骤 5:加载或初始化词向量矩阵(Embedding Matrix)
🔹 方法一:使用预训练 GloVe 向量(部分模拟)
假设我们从 glove.6B.50d.txt 中提取了部分词向量(50维):
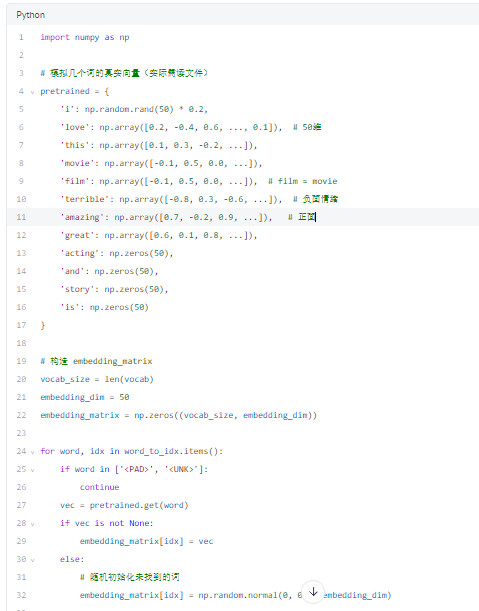
🔹 输出(实例值)
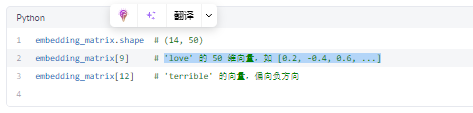
✅ 每个词 ID 对应一个 50 维实数向量。
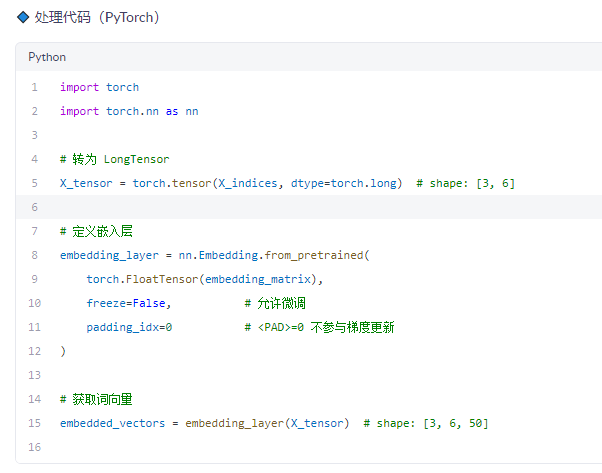
✅ 步骤 6:创建 Embedding 层并生成词向量张量
🔹 输入
X_indices: 索引序列(3, 6)embedding_matrix:(14, 50)
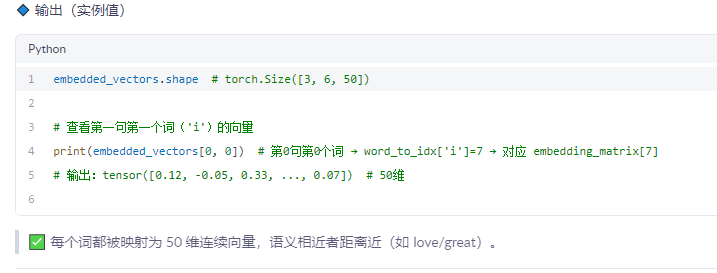
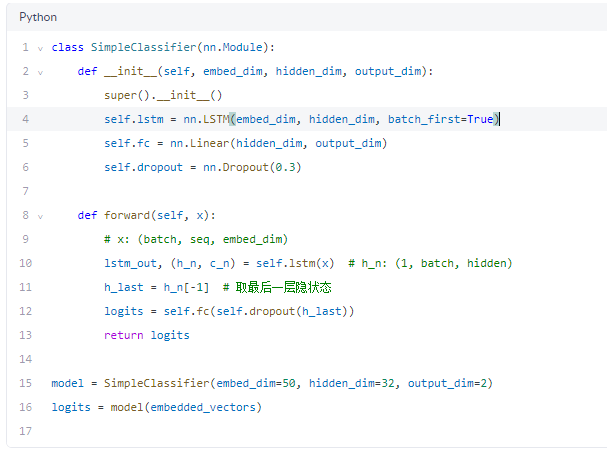
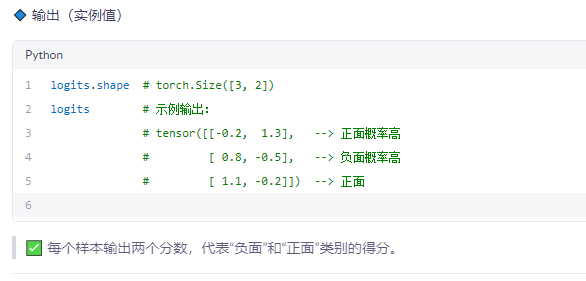
✅ 步骤 7:送入模型(以简单 LSTM 为例)
🔹 输入
embedded_vectors:[3, 6, 50]
🔹 模型定义
🧩 总结表格:各步骤输入输出一览
| 步骤 | 名称 | 输入 | 输出(示例) | 形状 |
|---|---|---|---|---|
| 1 | 清洗文本 | 原始字符串列表 | ['i love this movie', ...] | 3×str |
| 2 | 分词 | 清洗后文本 | [['i','love',...], [...]] | 3×list |
| 3 | 构建词表 | 所有 token | {'i':7, 'love':9, ...} | V=14 |
| 4 | 编码为索引 | token 列表 | [[7,9,13,10,0,0], ...] | (3,6) |
| 5 | 构建嵌入矩阵 | 词表 + 预训练向量 | embedding_matrix[14,50] | (14,50) |
| 6 | 生成词向量 | 索引张量 | embedded_vectors[3,6,50] | (3,6,50) |
| 7 | 输入模型 | 词向量序列 | logits[3,2] | (3,2) |
🚀 小贴士
- 使用
torch.utils.data.Dataset和DataLoader可实现批量处理。 - 实际项目推荐使用 Hugging Face Transformers(BERT等),自动完成上述流程。
- 中文可用
jieba分词 +sgns.wiki.word预训练向量。