IPIDEA海外代理助力-Youtube视频AI领域选题数据获取实践
1、背景
随着生成式AI的出现和不断迭代
以OpenAI为首的Sora、谷歌的Gemini、国内快手的可灵、字节的即梦等生成式视频AI对于自媒体领域的视频产生了巨大的冲击
AI视频的数量以爆发式的规模在各大媒体平台增长
AI视频领域带来的市场是巨大的,创新的,甚至可能是颠覆的,短时间内就成为了自媒体人的共识
最重要的就是AI视频创作突破了现实世界的物理框架限制,那些天马行空的想象能够被AI以视频的方式实现了
海底世界里鱼儿们开起了演唱会、人物在天空飞翔、古代的侠客刀光剑影
与名人穿越时空对话、小猫打咏春、飞船穿梭在璀璨的星河之间等等
这些画面,以前只能在梦里想想,现在用 AI 都能轻松实现,简直不要太酷!
这让人们体验到前所未有兴奋和刺激,但是却也带给所有自媒体人新的难题
AI视频的选题
好的选题才能在众多的视频中脱颖而出,让观众看见和留下,欣赏你的创意
要是天天都在想选题,那留给制作视频的时间肯定就少了,这事儿可就得不偿失了,对吧?
那怎么办呢?
其实呢,自古以来那些厉害的作品和大神们,都是在一步步学习和模仿中成长起来的
所以学习和借鉴现有的视频题材,也是咱们创作路上很重要的一环
而获取对标AI博主的视频题材数据有一门讲究的事了
本文就将提供一种对YouTube视频平台AI博主视频题材数据获取和数据分析方案
方案关键词
- Nodejs运行代码方案
- IPIDEA HTTP代理
- Excel分析
2、流程介绍
为了方便对该方案有整体上的理解,以下列出主要的执行流程
- 先选定对标的AI博主账号
- 设定获取数据分析指标
- 注册IPIDEA代理平台账户,获取HTTP代理权限 (之后会讲为什么HTTP使用代理)
- 使用Nodejs代码配置代理
- 执行代码进行数据访问和网页数据采集
- 导出Excel数据进行分析
3、选定分析博主与数据指标
3.1选定AI视频博主
这里以我自己从一开始就关注的Youtube-AI视频博主为例,从他一开始只有几千粉丝我就关注了
我们可以看到截至现在他的账户数据
- VividCore_AI
- 2024年11月2日注册
- 56.7万位订阅者
- 486个视频
- 319,474,863次观看 (3亿次+的观看量)
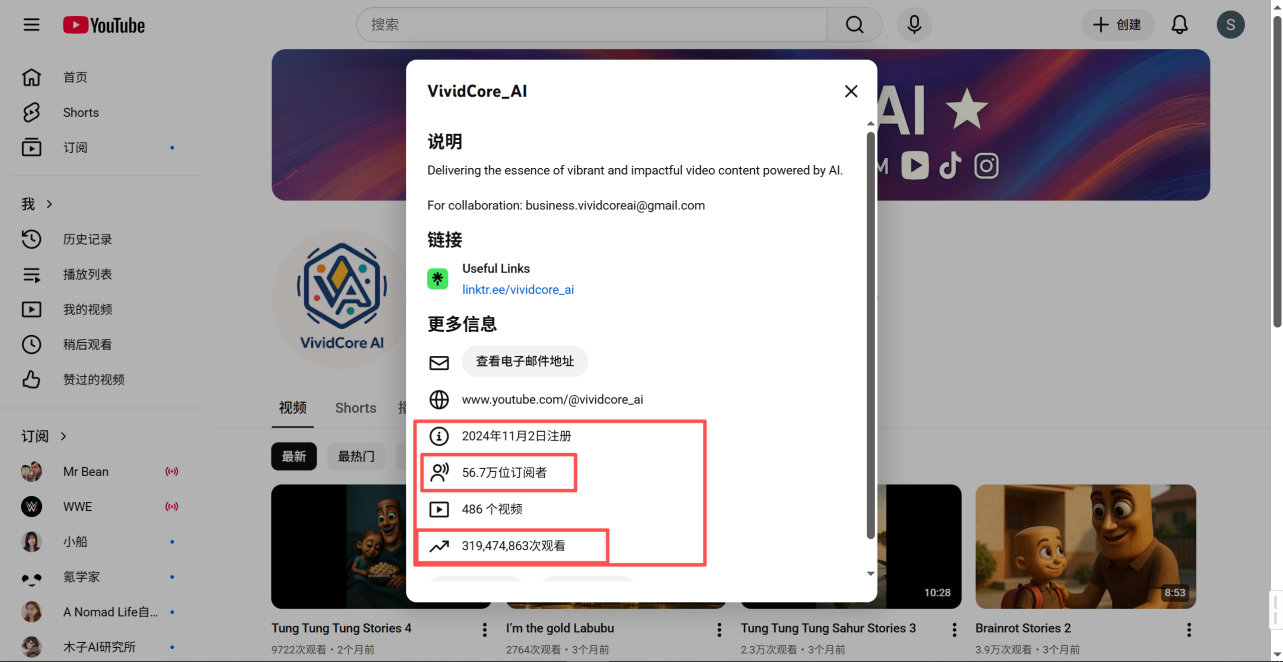
可以看到这个 VividCore_AI 这账号简直太牛了!
2024 年 11 月 2 日才注册,10个月的时间就已经有 56.7 万位订阅者,一共发了 486 个视频
观看量就达到了惊人的 319,474,863 次,妥妥的 3 亿次 +,这数据实在夸张!
简直就是AI 视频领域的爆款制造机
我们甚至可以通过计算网站,计算一下这个账户的广告收益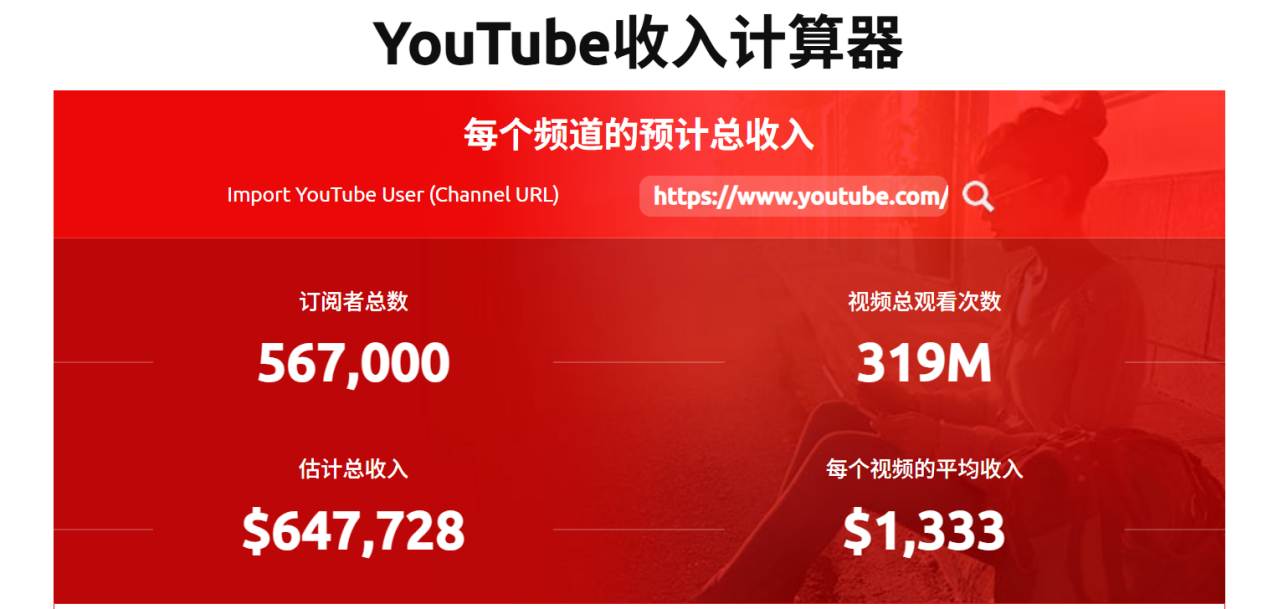
这些观看量转化成了实实在在的收益,总共估计达到了$647,728美元(约450万人民币)
换算一下,每个视频平均能带来$1,333美元(约9000人民币)的收入
当然这是理想数据,真实情况一定是不如这般夸张的
即便是只有十分之一的真实,450万人民币*十分之一依旧达到了45万人民币
10个月视频收益45万,依旧非常的惊人
3.2设定获取数据分析指标
好了,现在有了对标的博主
就需要设置数据分析指标参数了
首先肯定是视频标题
其次是播放量
这两样是最重要的分析指标
同时我们就能对视频标签、发布日期,点赞数、收藏量等常见的关键指标进行获取
由于我们只是针对选题对视频数据的影响
所以我们就先以最主要的指标进行提取,如下
- 视频标题
- 播放量
- 视频标签
之后的脚本中就会对上诉的指标进行获取
4、配置代理策略
4.1注册HTTP代理平台账户
这一步我推荐大家注册IPIDEA账户,获取HTTP代理权限
这一步是为什么呢?为什么要获取HTTP代理权限
主要是Youtube作为海外的最大的视频平台
每日有巨量的访问流量、如果允许非常规的流量访问
会对服务器造成不必要的运行资源的浪费
所以Youtube有严格的流量来源筛查,阻止那些异常流量访问
当然其他的网站也是如此
数据访问时一旦被识别为异常流量时,网站断开你的流量访问,这就无法正常的获取数据了
这样的话就造成了数据获取的不稳定性高
这是一个日常数据获取中的高频的阻塞项
那有什么解决方案嘛?有
在我以往寻找的解决方案中,IPIDEA 作为提供合规 HTTP 代理服务的平台,能模拟正常用户网络访问特征、适用于合法公开数据采集场景,使用效果也不错。
那数据获取的不稳定性高这个难题就迎刃而解了
首页打开IPIDEA官网
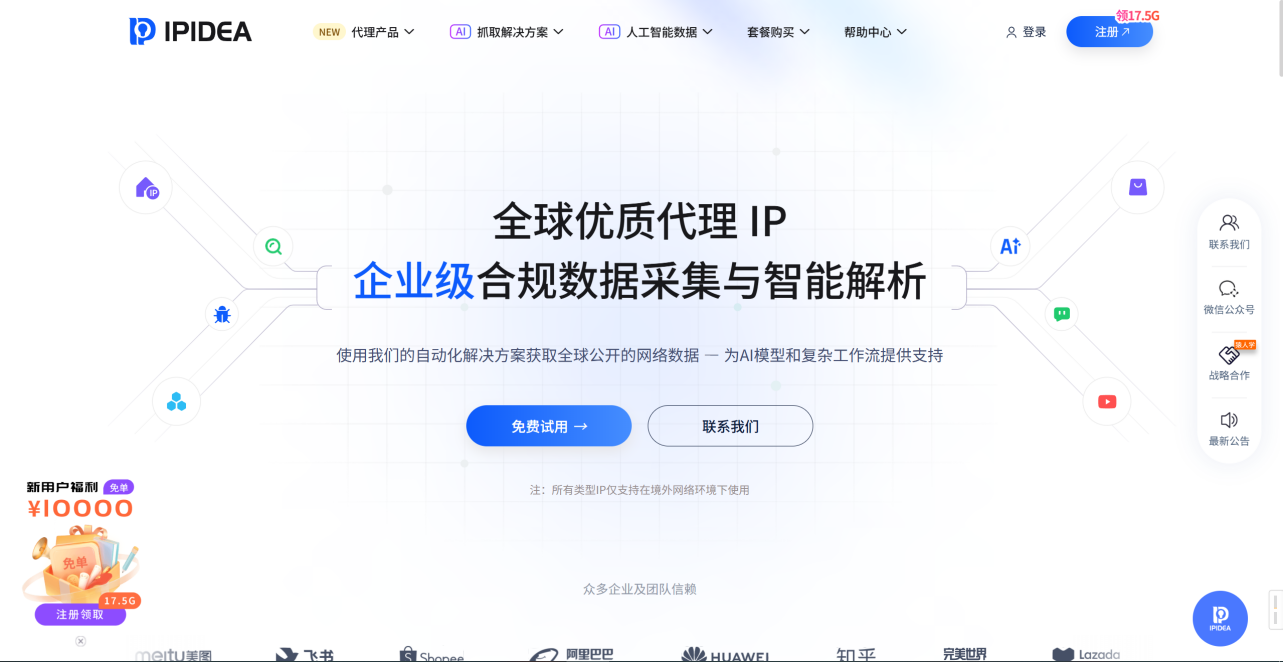
可以看到他们对自己服务的介绍
全球优质代理 IP
企业级合规数据采集与智能解析
可以看到现在还有福利活动,新用户注册即送17.5G的流量
主要分为
- 动态住宅代理
- 静态住宅代理
- 动态长效ISP
- 数据中心代理
- 移动代理
* 所有类型IP仅支持在境外网络环境下使用
4.2配置动态住宅代理
进行注册后我们可以查看自己的信息面板
这次我们的方案主要使用的服务是动态住宅代理
其主要的应用场景就是网页数据采集
和符合我们需要的业务需求场景
并且完成以下的操作
- 配置白名单
主要是使用HTTP代理服务时,平台也要确保你的账户中有效设备地址,防止流量被不明来源偷偷使用了
网上直接搜索本机IP地址,找一个IP地址检查网站查询后,配置到此处即可
- 添加子账户
方便后续对每个不同业务的子账户使用服务的精细化管理
并且后续的API使用也需要用到子账户认证
4.3测试代理
打开账密认证
在中间的配置服务表单区域
配置自己使用的套餐、国家/地区、认证账户等信息
然后复制右侧的测试命令
在自己的电脑上或者服务器上
打开CMD/终端去执行
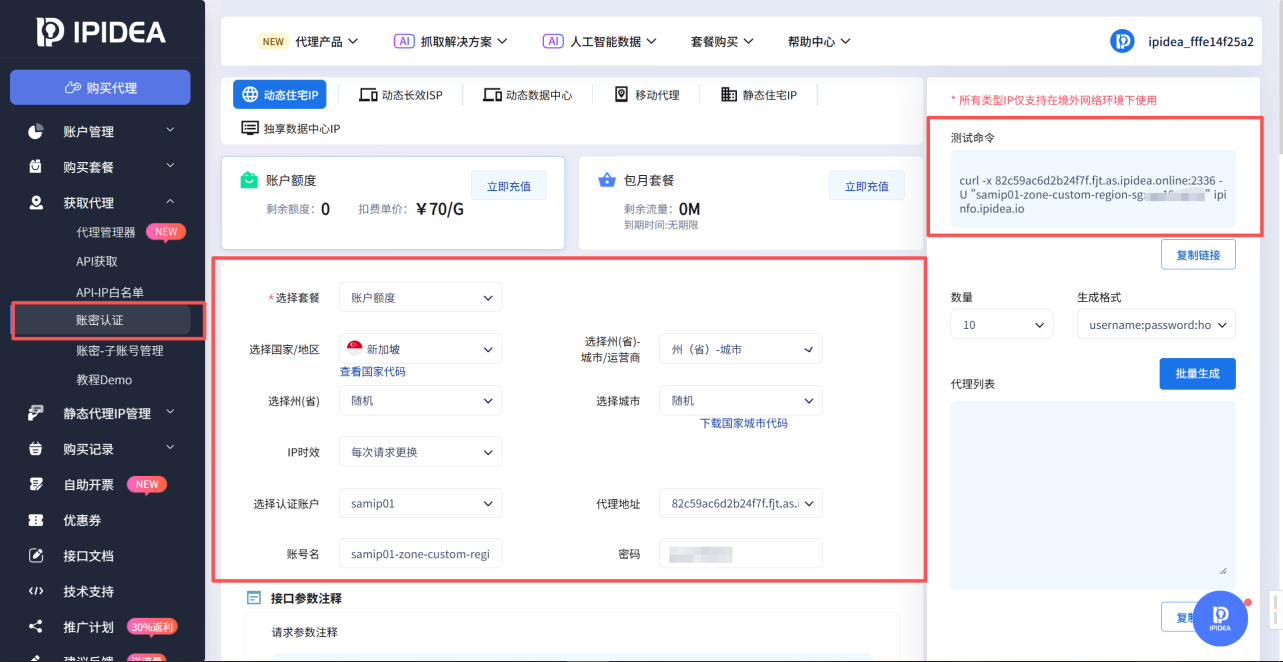
执行测试命令之后当我们看到以下返回时,说明动态住宅-HTTP代理配置服务成功了
{"ip":"101.127.XXX.XX","country_code":"SG","province":"","city":"Jurong West","zip_code":"600318","asn":"AS55430","asn_name":"Starhub Ltd","asn_type":"isp","timezone":"Asia/Singapore","longitude":"103.72278","latitude":"1.35028"}可以看到这个IP就是新加坡的,代理配置正确
接下来我们就可以将其配置到代码中使用它来进行网页数据采集了
5、实践代理方案
因为我们使用的Node环境,请先安装Node环境
这里大家自行网上搜索流程即可,很简单
5.1分析页面信息
首先我们需要分析Youtube的网页内容信息
以便编写脚本时,根据网页内容的数据返回模式针对性的进行数据提取
这是博主的视频页面
https://www.youtube.com/@vividcore_ai/shorts
由于博主发的视频多数是Shorts,我们就分析上诉链接的网页数据返回
点开后右键查看网页源代码
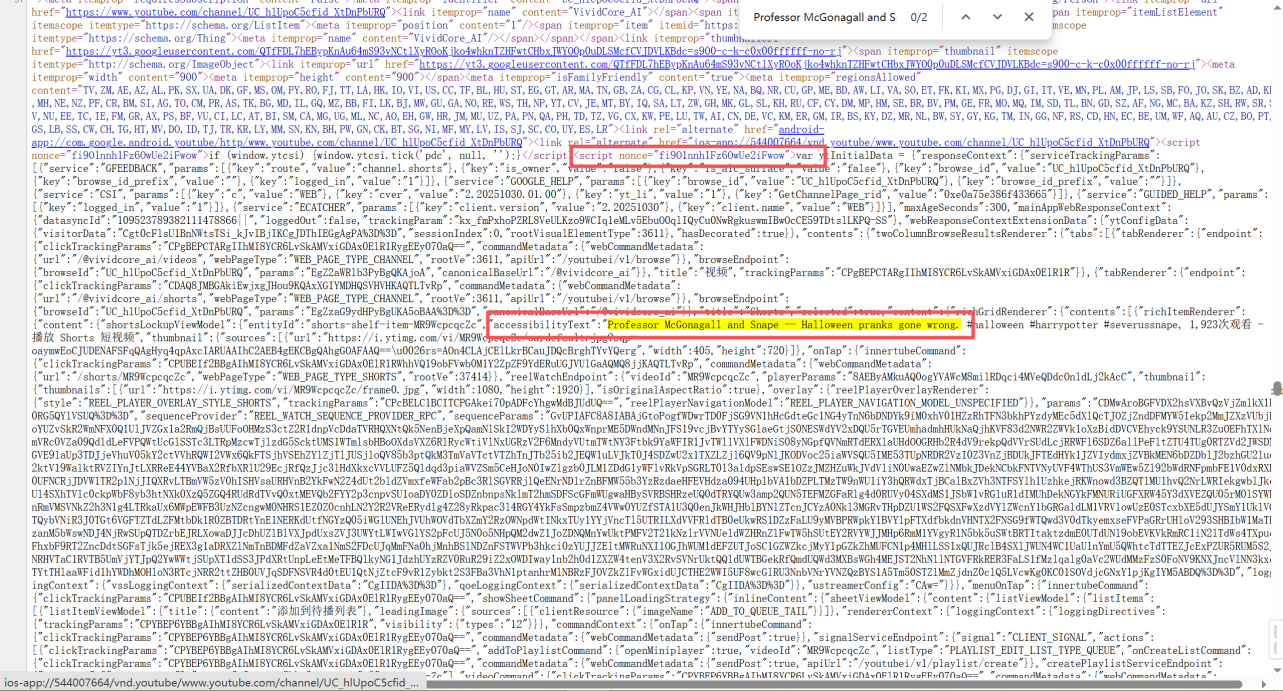
可以看到这里是当前我检索了博主的最新一个视频的标题
Professor McGonagall and Snape — Halloween pranks gone wrong.
而这个标题居然在 Script 脚本元素之中,而不是DOM节点内容元素
在搜索其他的视频标题,也是依旧在script元素之中
说明Youtube的视频内容数据返回模式是服务端渲染好了给到浏览器执行的
所以数据返回在不常见的 script 之中的,而不是常见的网络请求之中
5.2编写脚本与配置代理
这里直接给出主要源码
- 代理配置
需要注意的这里IPIDEA也是通过接口参数来实现
代理池标识、地区混播、配置ip时效时间、指定国家ISP运营商等功能
我上面就是配置了地区"新加坡"
所以这里的zone-custom-region-sg 就代表了新加坡的住宅IP代理
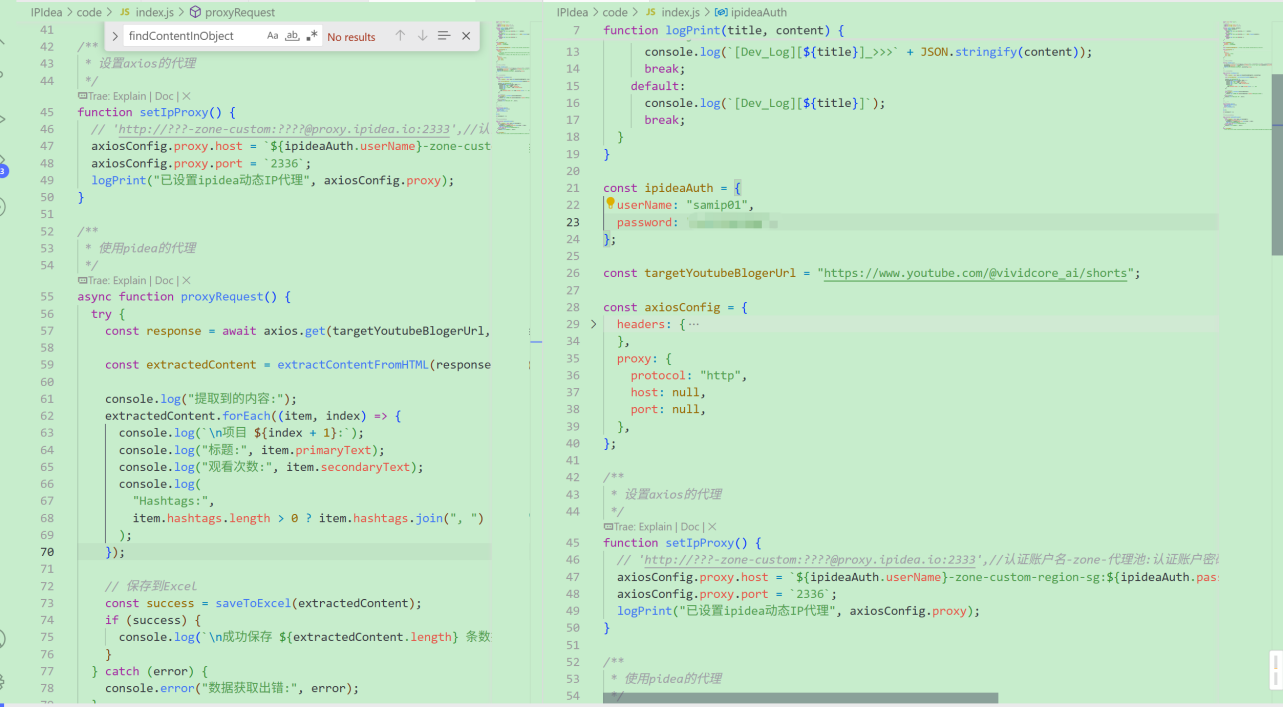
const ipideaAuth = {userName: "XXXX",password: "XXXX",
};const targetYoutubeBlogerUrl = "https://www.youtube.com/@vividcore_ai/shorts";const axiosConfig = {headers: {Accept:"text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8","User-Agent":"Mozilla/5.0 (iPhone; CPU iPhone OS 10_3_3 like Mac OS X) AppleWebKit/603.3.8 (KHTML, like Gecko) Mobile/14G60 MicroMessenger/6.5.19 NetType/4G",},proxy: {protocol: "http",host: null,port: null,},
};/*** 设置axios的代理*/
function setIpProxy() {// 'http://???-zone-custom:????@proxy.ipidea.io:2333',//认证账户名-zone-代理池:认证账户密码@代理地址axiosConfig.proxy.host = `${ipideaAuth.userName}-zone-custom-region-sg:${ipideaAuth.password}:82c59ac6d2b24f7f.fjt.as.ipidea.online:`;axiosConfig.proxy.port = `2336`;logPrint("已设置ipidea动态IP代理", axiosConfig.proxy);
}- 提取视频信息数据
这里我们主要是拿到返回数据之后进行提取操作
主要提取的数据就包含上诉提及的视频标题、播放量、视频标签
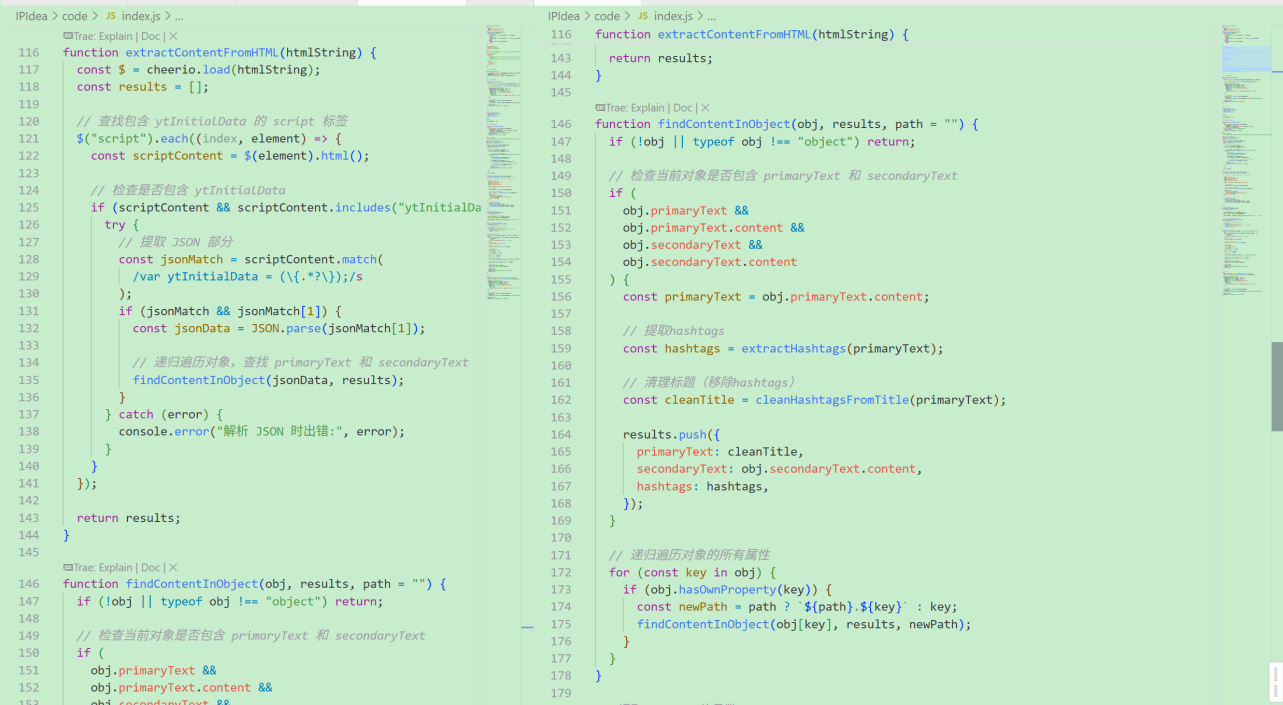
function extractContentFromHTML(htmlString) {const $ = cheerio.load(htmlString);const results = [];// 查找包含 ytInitialData 的 script 标签$("script").each((index, element) => {const scriptContent = $(element).html();// 检查是否包含 ytInitialDataif (scriptContent && scriptContent.includes("ytInitialData")) {try {// 提取 JSON 部分const jsonMatch = scriptContent.match(/var ytInitialData = (\{.*?\});/s);if (jsonMatch && jsonMatch[1]) {const jsonData = JSON.parse(jsonMatch[1]);// 递归遍历对象,查找 primaryText 和 secondaryTextfindContentInObject(jsonData, results);}} catch (error) {console.error("解析 JSON 时出错:", error);}}});return results;
}function findContentInObject(obj, results, path = "") {if (!obj || typeof obj !== "object") return;// 检查当前对象是否包含 primaryText 和 secondaryTextif (obj.primaryText &&obj.primaryText.content &&obj.secondaryText &&obj.secondaryText.content) {const primaryText = obj.primaryText.content;// 提取hashtagsconst hashtags = extractHashtags(primaryText);// 清理标题(移除hashtags)const cleanTitle = cleanHashtagsFromTitle(primaryText);results.push({primaryText: cleanTitle,secondaryText: obj.secondaryText.content,hashtags: hashtags,});}// 递归遍历对象的所有属性for (const key in obj) {if (obj.hasOwnProperty(key)) {const newPath = path ? `${path}.${key}` : key;findContentInObject(obj[key], results, newPath);}}
}存入Excel文件
function saveToExcel(data, filename = "YouTubeAI博主视频数据.xlsx") {try {data = JSON.parse(JSON.stringify(data)).map((item, index) => ({index: index + 1,...item,hashtags: item.hashtags.join(", ") || "无",}));// 创建工作簿const wb = XLSX.utils.book_new();// 将数据转换为工作表const ws = XLSX.utils.json_to_sheet(data);// 设置列宽const colWidth = [{ wch: 8 }, // 序号{ wch: 60 }, // 标题{ wch: 15 }, // 观看次数{ wch: 40 }, // Hashtags];ws["!cols"] = colWidth;// 将工作表添加到工作簿XLSX.utils.book_append_sheet(wb, ws, "YouTubeAI博主视频数据");// // dev-log >>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>console.log(`[Dev_Log][${"data"}_]_>>>`, data);// 写入文件XLSX.writeFile(wb, filename);console.log(`数据已保存到 ${filename}`);return true;} catch (error) {console.error("保存Excel文件时出错:", error);return false;}
}5.3执行脚本进行数据采集
我们通过命令行执行Node源码后
我们就能得到一个 YouTubeAI博主视频数据.excel的文件了,打开excel查看结果
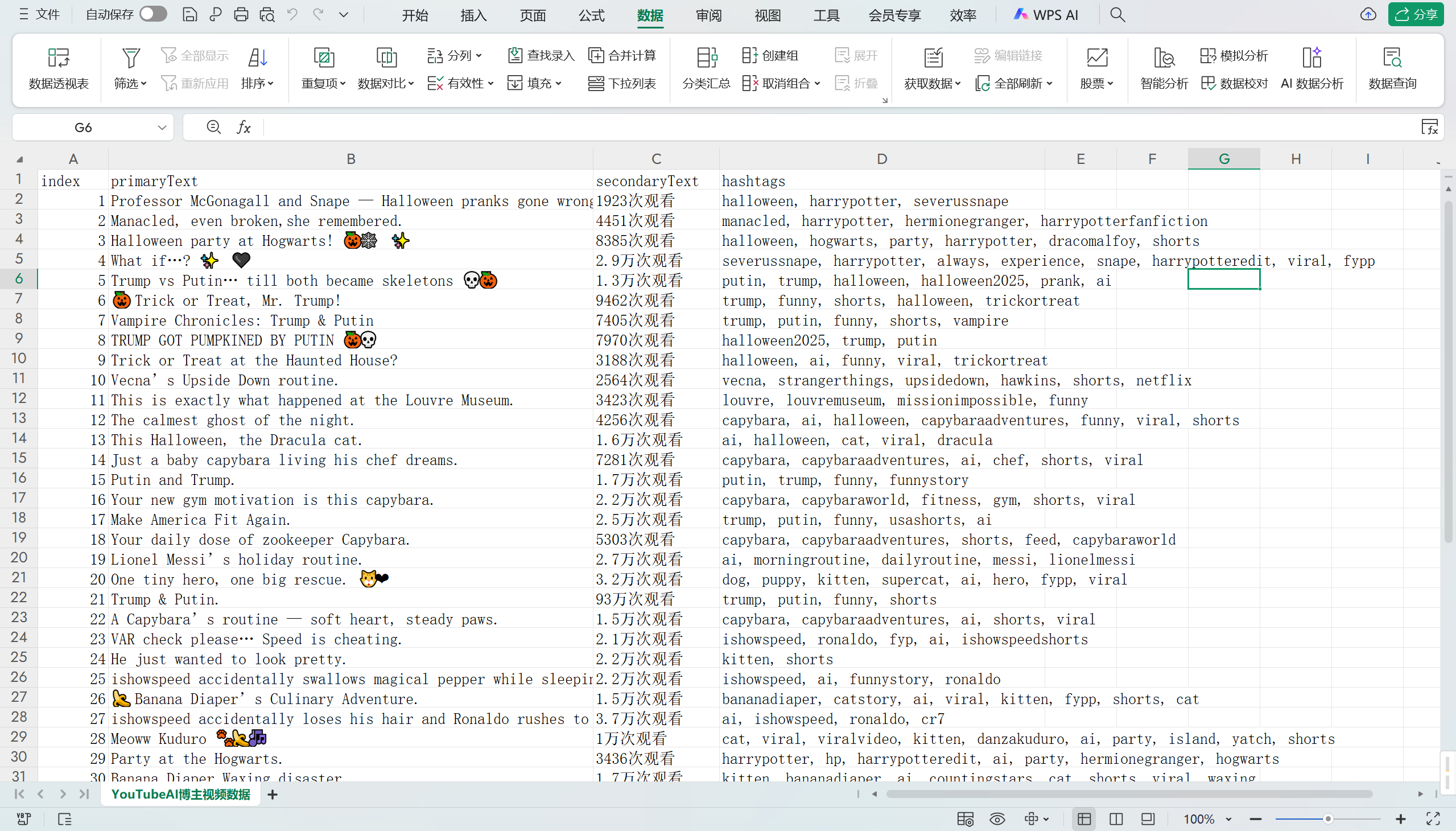
5.4分析结果
之后我们就能对该视频数据文件进行数据分析了
这里我们可以简单的对图中的数据分析一下
可以看到所有的视频播放基本都千次播放量的级别
证明这个博主的AI视频是具备竞争力的,其视频题材选取值得我们去分析
最高的93万次播放,涉及的是人物的AI视频
Trump & Putin. 93万次观看 trump, putin, funny, shorts
看来大家对与 川普和京子的关注度很高嘛
嘿嘿,这样看特定领域的出名人物的虚拟视频具备一定的题材优势
6.结语
在YouTube视频平台AI博主视频题材数据获取的过程中,我尝试使用了这个IPIDEA的HTTP代理服务,整个体验下来,感觉还不错。
一开始,我还在担心配置和使用会不会很复杂,毕竟之前用过的一些工具总是各种问题。但这次出乎意料,相关教程和文档很详细,跟着一步步来,基本没遇到什么障碍,大部分疑问都能轻松解决。
测试的时候,还碰到了账户认证的配置问题,不过客服的响应速度很快,给了我清晰的指引,不到1小时就搞定了,这效率确实挺高的,比之前用的那些服务好多了。
在性能方面,数据返回一直很稳定,没有出现过异常,而且速度也挺快的。从成功采集数据开始,后续整个处理流程,包括数据返回和提取,基本都在8 - 10秒左右,这速度对于数据采集来说已经很理想了。
安全合规也是我一直比较在意的。以往做网络数据获取,合规问题总是让人头疼。但这次用的IPIDEA在这方面做得很不错,从他们的官网介绍可以看到它们严格遵守法律法规,有完善的安全管控措施,不用担心会因为合规问题惹上麻烦。
另外,它支持多种类型的IP代理,像动态住宅、静态住宅、移动代理等,基本能满足各种数据收集的场景需求。
总之,这次的数据获取过程很顺利,IPIDEA的HTTP代理服务确实帮了大忙。如果你们也有类似的项目,需要处理数据采集这类问题,可以试试看,说不定能帮到你们。