vLLM 原理深度分析
vLLM 是 UC Berkeley 团队推出的高性能大语言模型(LLM)推理与服务框架,核心基于创新的 PagedAttention 注意力机制,解决了传统 LLM 服务中的显存碎片化和利用率低等关键痛点,实现了 2-4 倍于主流框架的吞吐量提升。本文结合核心论文《Efficient Memory Management for Large Language Model Serving with PagedAttention》、官方使用指南及实践场景进行全面解析。
https://arxiv.org/pdf/2309.06180
一、背景与框架存在的必要性
LLM 从离线模型到生产级服务,需突破 “性能、工程化、生态兼容” 三重壁垒,这也是 vLLM 等专业框架不可或缺的核心原因 —— 单独实现某个技术点(如 PagedAttention)无法支撑生产级需求,框架的价值在于提供 “全链路工程化解决方案”。
1. 传统方案的痛点:为何不能无框架直接部署?
直接基于 PyTorch/TensorFlow 部署 LLM 会面临一系列难以解决的问题:
-
显存管理混乱:KV Cache 连续存储导致碎片化,相同硬件支持的并发量极低;
-
并发调度低效:静态批处理易引发 “短序列等待长序列”,GPU 算力闲置率高;
-
服务化成本高:需手动封装 API、实现流式输出、兼容外部生态(如 OpenAI SDK),开发周期长达数月;
-
分布式部署复杂:多 GPU / 多节点部署需手动实现模型分片、跨卡通信,稳定性难以保障;
-
性能优化不足:缺乏底层算子融合、显存复用等优化,推理延迟高,无法发挥硬件极限。
2. 框架的核心必要性:解决 “单点优化” 无法覆盖的系统性问题
vLLM 作为专业框架,其必要性体现在 “系统性整合与工程化封装”,具体包括:
-
性能聚合:将 PagedAttention、动态批处理、算子优化等技术整合,形成 “1+1>2” 的性能优势,而非孤立优化;
-
工程化降本:封装显存管理、分布式通信、服务调度等 “脏活累活”,企业无需组建专业底层研发团队,大幅缩短上线周期;
-
生态兼容:无缝对接 Hugging Face 模型库、OpenAI API、K8s 部署生态,降低现有业务迁移成本;
-
稳定性保障:内置异常处理、健康检查、负载均衡等机制,解决单机部署的可靠性问题,满足生产环境 99.9%+ 可用性要求;
-
易用性提升:提供简洁的命令行、Python API 和服务化接口,非底层研发人员也能快速部署高性能 LLM 服务。
简单来说:框架的核心价值是 “让企业聚焦业务创新,而非底层技术重复开发”,是 LLM 工业化落地的 “基础设施”。
二、框架核心作用:连接模型与基础服务的桥梁
vLLM 作为 LLM Server 框架,核心作用是 “将离线训练好的 LLM 转化为高可用、高性能、易调用的网络服务”,具体承担四大核心角色:
1. 性能优化器:突破硬件瓶颈
-
显存高效利用:通过 PagedAttention 消除碎片,显存利用率提升至 90% 以上;
-
计算效率提升:算子融合、增量解码等优化减少无效计算,降低推理延迟;
-
硬件资源最大化:动态批处理让 GPU 算力利用率维持在高位,避免闲置。
2. 服务化封装器:降低调用门槛
-
标准化接口:提供 RESTful/gRPC/OpenAI 兼容 API,用户无需关注底层实现,通过简单调用即可获取推理结果;
-
多样化部署支持:支持单机、多 GPU 张量并行、K8s 集群部署,适配不同规模的服务需求;
-
可观测性保障:集成日志、监控功能,支持 GPU 利用率、请求延迟、错误率等指标监控,便于运维排查。
3. 生态连接器:适配现有技术栈
-
模型兼容:无缝支持 Hugging Face 生态模型、量化模型(GPTQ/AWQ),无需手动转换格式;
-
应用兼容:OpenAI API 兼容设计让现有基于 OpenAI 开发的应用 “零代码迁移”;
-
工具链兼容:支持 Docker 容器化、Prometheus/Grafana 监控、K8s 调度,适配企业现有云原生架构。
4. 灵活扩展器:支撑定制化需求
-
功能扩展:支持自定义采样策略、请求优先级调度、认证授权逻辑,适配企业特殊业务场景;
-
硬件扩展:支持多 GPU 张量并行、未来可扩展至多节点分布式部署;
-
技术扩展:可集成 RAG、Agent 等上层应用,形成 “模型服务 + 业务逻辑” 的完整链路。
三、核心原理:PagedAttention 与全链路优化细节
vLLM 的性能优势根源在于核心创新 PagedAttention 机制,以及围绕该机制的全链路协同优化,而非单一技术点的突破。
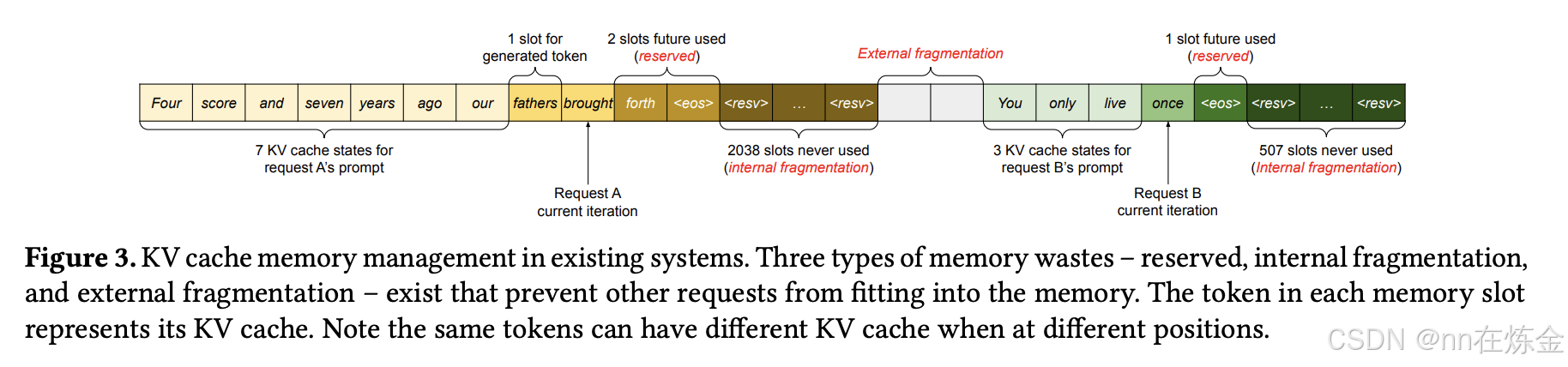
1. PagedAttention:分页注意力机制
灵感源自操作系统虚拟内存分页技术,核心是打破 KV Cache 的连续存储限制,实现非连续显存的精细化管理。
核心设计逻辑
-
分页拆分:将每个序列的 KV Cache 拆分为固定大小的 “KV 块”(默认 16 个 Token / 块),每个块包含固定数量 Token 的键(Key)和值(Value)向量。块大小需平衡 “并行效率” 和 “碎片率”,过小会增加块表管理开销,过大则碎片化问题回归。
-
页表映射:为每个序列维护 “块表”(类比操作系统页表),记录 “逻辑块”(序列视角的连续块)与 “物理块”(GPU 显存中的实际存储块)的映射关系。物理块无需连续,GPU 通过块表快速索引并拼接所需 KV Cache,无需提前预留连续显存。
-
按需分配与回收:仅为已生成的 Token 分配物理块,新 Token 生成时动态从 “空闲块池” 申请资源;请求完成后立即释放物理块,供新请求复用,避免预分配导致的显存浪费。
数学表达与计算流程
传统注意力计算中,输出向量 oio_ioi 依赖所有前置 Token 的键值对:
oi=∑j=1iexp(qi⊤kj/d)∑t=1iexp(qi⊤kt/d)vjo_i = \sum_{j=1}^{i} \frac{exp(q_i^\top k_j/\sqrt{d})}{\sum_{t=1}^{i} exp(q_i^\top k_t/\sqrt{d})} v_joi=∑j=1i∑t=1iexp(qi⊤kt/d)exp(qi⊤kj/d)vj
PagedAttention 将键值对按块分组(KjK_jKj 为第 j 个键块,VjV_jVj 为第 j 个值块),转化为块级并行计算:
oi=∑j=1⌈i/B⌉Vj⋅exp(qi⊤Kj/d)∑t=1⌈i/B⌉exp(qi⊤Kt/d)⊤o_i = \sum_{j=1}^{\lceil i/B \rceil} V_j \cdot \frac{exp(q_i^\top K_j/\sqrt{d})}{\sum_{t=1}^{\lceil i/B \rceil} exp(q_i^\top K_t/\sqrt{d})}^\topoi=∑j=1⌈i/B⌉Vj⋅∑t=1⌈i/B⌉exp(qi⊤Kt/d)exp(qi⊤Kj/d)⊤
其中 B 为块大小。计算时,通过块表索引非连续物理块,直接在块级别执行注意力得分计算,无需拼接完整 KV Cache,兼顾效率与灵活性。
关键优势(对比传统注意力机制)
-
消除显存碎片:所有物理块大小一致,彻底解决外部碎片;内部碎片仅局限于最后一个未填满的块,浪费率低于 1%;
-
支持灵活共享:同一请求的多个序列(如并行采样)或不同请求的共享前缀可复用物理块,束搜索场景内存节省可达 37.6%-55.2%;
-
超长序列支持:非连续存储无需预留大规模连续显存,轻松支持 100k+ Token 超长序列推理,突破传统框架的序列长度限制。
2. 全链路配套优化(支撑 PagedAttention 发挥最大价值)
PagedAttention 需配合一系列配套优化才能实现端到端性能提升,这也是框架 “系统性优势” 的体现:
(1)动态批处理与智能调度
-
迭代级调度:每轮解码后立即移除已完成的请求,从请求队列中补充新请求,新请求仅需等待 1 个迭代即可开始处理,避免传统静态批处理的 “等待整批完成” 问题;
-
分组优化:按序列长度和推理阶段(预填充 / 解码)分组批处理,短序列集中组成小批量快速处理,长序列单独分组避免阻塞短序列,最大化 GPU 利用率;
-
负载控制:通过
max-num-batched-tokens限制单个 batch 的 Token 总数,避免显存溢出,同时保证批处理效率。
(2)高级解码内存共享
-
并行采样共享:多个输出序列共享提示词(Prompt)的 KV Cache,仅生成阶段的差异化部分使用独立块,内存节省 6.1%-30.5%;
-
束搜索共享:不同候选序列共享前缀 KV Cache,动态调整共享模式,避免传统框架的频繁内存拷贝,内存节省 37.6%-66.3%;
-
公共前缀缓存:预计算并缓存系统提示词、常用指令等公共前缀的 KV Cache,用户请求仅需计算任务相关部分,5-shot 前缀场景吞吐量提升 3.58 倍。
(3)显存与计算层优化
-
核函数融合:将块读写、注意力计算、Softmax 等操作融合为单个 CUDA 核函数,减少 kernel 启动开销和数据拷贝,抵消非连续存储的间接开销;
-
量化兼容:原生支持 INT8/FP8/GPTQ/AWQ/bitsandbytes 等量化方案,7B 模型量化后显存占用可降至 4-5GB,适配低显存硬件;
-
抢占与恢复机制:显存不足时,支持 “交换(Swapping)”(低优先级请求 KV 块迁移至 CPU)或 “重计算(Recomputation)”(丢弃块后重新生成),平衡显存使用与延迟。
(4)分布式通信优化
-
张量并行架构:将模型按注意力头维度拆分到多张 GPU,每张 GPU 存储部分权重和对应 KV Cache 分片,通过 NCCL 同步中间计算结果;
-
集中式块表管理:单个 KV Cache 管理器维护全局块表,所有 GPU 共享映射关系,避免分布式环境下的块冲突,提升跨卡协同效率。
四、框架结构:分层解耦设计与核心组件
vLLM 采用 “分层解耦” 架构,从底层到上层分为硬件适配层、核心推理层、服务调度层、接入层,各层职责明确、接口标准化,既便于独立优化,又支持灵活扩展。
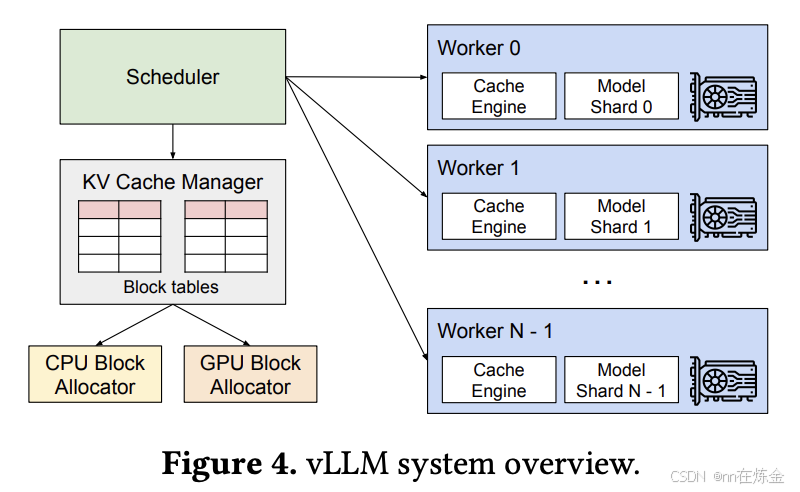
1. 架构分层与组件功能(含层级定位与核心作用)
| 层级 | 核心组件 | 功能描述 | 技术实现 | 层级定位 | 核心作用 |
|---|---|---|---|---|---|
| 硬件适配层(最底层) | CUDA 核函数库 | 实现 PagedAttention、矩阵乘法等核心计算,直接调用 GPU 指令 | 纯 CUDA C++ 编写 | 硬件能力抽象层 | 最大化硬件算力,提供高性能计算基础 |
| 显存管理器 | 管理物理块分配、回收、复用,维护空闲块池和块表映射 | 基于 CUDA 显存 API 封装 | 资源管理层 | 支撑 PagedAttention 的非连续显存管理 | |
| 跨卡通信模块 | 多 GPU 张量并行时的数据传输,同步中间计算结果 | 基于 NCCL 库优化 | 分布式通信层 | 突破单卡显存 / 算力限制,支持大模型部署 | |
| 硬件监控组件 | 采集 GPU 利用率、显存占用、温度等指标,为调度提供依据 | 调用 NVIDIA NVML 库 | 状态感知层 | 保障服务稳定性,避免硬件过载 | |
| 核心推理层(性能核心) | 模型加载器 | 加载 Hugging Face / 本地模型,支持量化模型和模型并行 | 复用 Transformers 解析逻辑,扩展量化解码 | 模型抽象层 | 兼容多样化模型,降低模型接入成本 |
| PagedAttention 引擎 | 执行块级注意力计算,通过块表索引非连续 KV 块 | CUDA 核函数 + 块表映射逻辑 | 推理核心组件 | 实现高效注意力计算,解决显存瓶颈 | |
| 量化引擎 | 支持 GPTQ/AWQ/bitsandbytes 等量化方案,降低显存占用 | 集成量化库,自定义量化解码逻辑 | 推理优化组件 | 适配低显存硬件,扩展部署场景 | |
| 增量解码器 | 复用历史 KV Cache,仅计算新 Token 的键值对 | 与 PagedAttention 联动,维护块表状态 | 效率优化组件 | 减少重复计算,降低推理延迟 | |
| 服务调度层(中间中枢) | 请求队列 | 缓存待处理请求,支持优先级排序和超时控制 | 基于 Python 队列实现,支持优先级调度 | 请求缓冲层 | 削峰填谷,避免突发请求压垮推理层 |
| 动态批处理器 | 智能组合不同请求成批,按 Token 总数和序列长度优化分组 | 自定义调度算法 | 调度核心组件 | 平衡并发量与延迟,最大化 GPU 利用率 | |
| 调度器 | 协调请求队列、批处理器和推理层,管理请求生命周期 | 事件驱动模型 | 服务中枢组件 | 串联全链路流程,决定请求处理顺序与资源分配 | |
| 结果收集器 | 按请求 ID 分组推理结果,支持流式 / 非流式输出 | 维护请求与输出的映射关系 | 结果处理层 | 适配不同输出需求,保障结果准确性 | |
| 接入层(最上层) | API Server | 提供 RESTful/gRPC 接口,兼容 OpenAI API 格式 | 基于 FastAPI 实现 | 接口暴露层 | 降低用户调用门槛,支持生态兼容 |
| 协议解析器 | 校验请求参数合法性,解析 JSON/Protobuf 格式 | 基于 Pydantic/Protobuf 实现 | 请求预处理层 | 保障请求有效性,减少无效计算 | |
| 认证授权组件 | 支持 API Key 认证,适配企业级权限管控 | 自定义认证中间件,支持 OAuth2.0 集成 | 安全层 | 保障服务安全性,防止非法访问 | |
| 日志 / 监控组件 | 记录请求详情和性能指标,支持 Prometheus/Grafana 对接 | 集成 logging 模块和指标暴露接口 | 可观测性层 | 便于运维排查,保障服务稳定运行 |
2. 分布式部署扩展能力
针对 66B、175B 等超大规模模型,vLLM 支持 Megatron-LM 风格的张量并行,核心扩展逻辑:
-
模型分片:将模型权重按注意力头维度拆分到多张 GPU,每张 GPU 仅存储部分层和对应 KV Cache 分片;
-
集中式调度:单个 KV Cache 管理器维护全局块表,所有 GPU 共享映射关系,避免块冲突;
-
跨卡协同:通过 NCCL 库同步注意力计算的中间结果,确保多卡推理一致性;
-
弹性扩展:支持动态增减 GPU 节点,适配不同规模模型的部署需求(175B 模型需 8 张 A100-80GB GPU)。
五、框架扩展性与自定义能力
vLLM 并非 “黑盒框架”,而是提供了多层次的扩展接口和自定义空间,支持企业根据业务需求调整核心逻辑,同时避免底层重构。
1. 核心扩展性维度(含扩展场景与实现方式)
| 扩展维度 | 扩展场景 | 实现方式 | 技术门槛 |
|---|---|---|---|
| 模型扩展 | 支持自定义模型结构、新增量化格式 | 基于 ModelLoader 扩展模型解析逻辑,集成自定义量化解码器 | 中(需了解模型结构与量化原理) |
| 硬件扩展 | 适配非 NVIDIA 硬件(如 Ascend 芯片) | 替换硬件适配层组件:CUDA 核函数→TBE 算子,NCCL→HCCL | 高(需底层算子开发能力) |
| 服务扩展 | 新增 API 接口、自定义认证逻辑 | 基于 FastAPI 扩展路由,集成自定义中间件 | 低(需基础 Web 开发经验) |
| 调度扩展 | 自定义批处理策略、请求优先级规则 | 重写 DynamicBatcher 或 Scheduler 组件的调度逻辑 | 中(需理解调度算法原理) |
| 功能扩展 | 集成 RAG、Agent、日志脱敏 | 在上层服务逻辑中新增功能模块,对接核心推理层 | 低 - 中(根据功能复杂度) |
2. 自定义框架的实现路径(企业级需求)
若通用功能无法满足特殊业务场景(如特殊硬件、极致性能、强耦合内部系统),企业可基于 vLLM 进行二次开发或完全自定义,核心路径如下:
(1)二次开发(推荐,成本较低)
-
核心思路:复用 vLLM 成熟组件(如接入层、调度层),仅修改目标模块(如硬件适配层、量化引擎);
-
典型场景:适配 Ascend 芯片(替换 CUDA 核为 TBE 算子、NCCL 为 HCCL)、新增企业内部认证体系;
-
实现步骤:
-
基于 vLLM 源码创建分支,定位需修改的模块(如硬件适配层的显存管理接口);
-
替换底层依赖(如 CUDA API→Ascend ACL API),保持上层接口不变;
-
验证修改模块功能(如显存分配、算子计算),确保与上层组件兼容;
-
进行性能与稳定性测试(如高并发压测、长时间运行测试),通过调整块大小、调度策略等参数优化性能;
-
封装部署包(如 Docker 镜像),集成企业内部运维工具链(如监控告警系统、日志分析平台),确保符合生产环境规范。
(2)完全自定义框架
仅适用于 “通用框架无法覆盖核心诉求” 的极端场景,例如自研特殊架构芯片、需纳秒级延迟优化、或与内部封闭系统深度耦合等,核心步骤如下:
-
复用成熟生态组件:优先复用 Hugging Face Transformers 的模型加载逻辑、FastAPI 的 Web 服务能力,避免重复开发基础功能;
-
聚焦核心差异化:仅自研底层关键模块(如自定义注意力算子、专属硬件通信协议),明确 “性能指标”(如延迟≤10ms)或 “功能指标”(如支持 1000 卡分布式推理)。
-
严格遵循 “硬件适配层→核心推理层→服务调度层→接入层” 分层设计,定义层间标准化接口(如推理层输出 “Token 生成结果 + KV 块状态”,调度层输入 “请求 ID+Prompt 信息”);
-
采用模块化开发,每个组件独立测试(如单独验证显存管理器的块分配效率、调度器的批处理逻辑)。
-
硬件适配层:针对目标硬件(如自研 ASIC 芯片)开发驱动接口,实现显存分配、算子执行等基础能力,参考 vLLM 的 CUDA 核函数逻辑设计硬件原生算子;
-
核心推理层:基于业务需求优化 KV Cache 管理(如针对金融场景设计 “敏感数据 KV 块加密存储”),实现自定义解码算法(如约束生成合规文本的特殊采样策略);
-
服务调度层:结合企业业务优先级(如 VIP 客户请求优先处理、核心业务低延迟保障)设计调度算法,支持动态资源调整(如业务高峰期自动扩容 GPU 节点)。
-
实现 OpenAI 兼容 API、Hugging Face 模型格式支持,降低用户迁移成本;
-
集成监控(如 GPU 算力利用率、请求成功率)、告警(如显存溢出预警、服务响应超时告警)、日志(如请求链路追踪、错误栈记录)功能,满足生产级可观测性需求;
-
支持 Docker 容器化部署与 K8s 集群调度,适配企业云原生架构。
-
性能测试:通过真实业务流量压测(如模拟 10 万级并发请求)验证吞吐量、延迟指标,对比通用 vLLM 框架定位优化空间;
-
稳定性测试:长时间(如 72 小时)满负载运行,监控内存泄漏、硬件异常等问题;
-
业务测试:针对目标场景(如金融文本生成、医疗报告分析)验证功能合规性与结果准确性,持续迭代优化。
六、使用场景与实操指南
vLLM 凭借高性能、高兼容性与易用性,可覆盖从快速原型验证到大规模生产部署的全场景 LLM 服务需求,不同场景的优化配置与实操方法存在差异,以下为核心场景的深度解析与实操示例。
1. 核心使用场景深度解析
(1)高并发 API 服务(最核心场景)
-
场景特征:多用户同时发起请求(如聊天机器人、AI 写作平台、智能客服),输入长度(如 10-1000 Token)与输出长度(如 50-2000 Token)差异大,需平衡 “高吞吐量” 与 “低延迟”,避免用户等待超时。
-
vLLM 核心优势:
-
动态批处理适配长度差异,短序列快速处理不被长序列阻塞;
-
PagedAttention 提升显存利用率,相同 GPU 支持的并发量是传统框架的 2-4 倍;
-
支持流式输出(SSE/WebSocket),用户无需等待完整结果,体验更流畅。
-
-
实操配置与示例:
# 启动高并发 API 服务(适配 7B 模型,单卡 A10 即可运行)
vllm serve \--model meta-llama/Llama-2-7b-chat-hf \--host 0.0.0.0 \ # 允许外部访问--port 8000 \ # 服务端口--max-num-batched-tokens 4096 \ # 单个 batch 最大 Token 数,平衡效率与显存--max-num-sequences 128 \ # 最大并发序列数,根据 GPU 显存调整(A10-24GB 可设 128)--gpu-memory-utilization 0.9 \ # 显存利用率上限,避免 OOM--enable-streaming \ # 开启流式输出--api-key "prod-xxx-xxx" # 生产环境 API Key 认证,防止非法访问
- 客户端调用示例(Python):
from openai import OpenAI# 连接 vLLM 服务
client = OpenAI(base_url="http://your-server-ip:8000/v1",api_key="prod-xxx-xxx"
)# 流式调用(用户实时接收结果)
stream = client.chat.completions.create(model="meta-llama/Llama-2-7b-chat-hf",messages=[{"role": "user", "content": "写一篇 300 字的春季旅行攻略"}],stream=True,max_tokens=300,temperature=0.7
)# 实时打印流式结果
for chunk in stream:if chunk.choices[0].delta.content:print(chunk.choices[0].delta.content, end="")
(2)超长序列推理(差异化场景)
-
场景特征:输入序列长度超 10k Token(如法律合同分析、学术论文摘要、代码库理解),传统框架因 “连续显存预分配” 导致 OOM 或性能骤降。
-
vLLM 核心优势:
-
PagedAttention 非连续 KV Cache 存储,无需预留大规模连续显存,支持 100k+ Token 推理;
-
块级 KV Cache 管理,超长序列推理时显存利用率仍保持 90% 以上,无明显性能损耗。
-
-
实操配置与示例:
# 启动超长序列推理服务(适配 Mistral-7B,支持 100k Token)
vllm chat \--model mistralai/Mistral-7B-Instruct-v0.2 \--max-sequence-length 100000 \ # 最大序列长度,支持 100k Token--block-size 64 \ # 调整块大小(超长序列建议 64/128,减少块表管理开销)--gpu-memory-utilization 0.95 \ # 充分利用显存,超长序列需更多显存--load-8bit \ # 可选:8bit 量化,进一步降低显存占用(7B 模型量化后约 7GB)
-
关键优化点:
-
块大小调整:超长序列(如 100k Token)建议将
--block-size设为 64 或 128,减少块表条目数量(100k Token/64 Token / 块 = 1562 块,管理开销低); -
量化支持:若显存不足,通过
--load-8bit或--load-4bit启用量化,13B 模型 4bit 量化后显存占用可降至 8GB 左右,仍支持 50k+ Token 推理。
-
(3)复杂解码任务(高级场景)
-
场景特征:需使用并行采样、束搜索等高级解码算法(如机器翻译、多候选内容生成、摘要质量优化),传统框架因 “KV Cache 重复存储” 导致显存占用过高、吞吐量低。
-
vLLM 核心优势:
-
块级 KV Cache 共享,并行采样时共享 Prompt 部分 KV Cache,束搜索时共享前缀 KV Cache,内存节省 37%-66%;
-
解码算法与 PagedAttention 深度协同,复杂解码场景下吞吐量仍比传统框架高 2-3 倍。
-
-
实操配置与示例:
# 束搜索示例(机器翻译场景,追求高准确性)
from vllm import LLM, SamplingParams# 配置束搜索参数
sampling_params = SamplingParams(num_beams=4, # 束宽,越大结果越优但计算量越大(建议 2-4)temperature=0.0, # 束搜索通常用 0 温度,保证确定性max_tokens=512,repetition_penalty=1.2, # 避免重复生成reuse_kv_cache=True # 开启 KV Cache 共享,降低显存占用
)# 初始化 LLM 引擎
llm = LLM(model="facebook/mbart-large-50-many-to-many-mmt", # 多语言翻译模型tensor_parallel_size=2, # 2 卡并行,提升束搜索速度gpu_memory_utilization=0.9
)# 批量翻译请求(英文→中文)
prompts = ["Translate English to Chinese: 'Artificial intelligence is changing the world.'","Translate English to Chinese: 'Large language models have broad application prospects.'"
]# 执行推理
outputs = llm.generate(prompts, sampling_params)# 输出结果
for output in outputs:print(f"输入:{output.prompt}")print(f"翻译结果:{output.outputs[0].text.strip()}\n")
(4)批量推理与数据处理(离线场景)
-
场景特征:批量处理文本生成任务(如数据增强、批量摘要、内容生成),需高吞吐量以缩短处理耗时,通常为离线任务(非实时响应)。
-
vLLM 核心优势:
-
动态批处理最大化 GPU 利用率,批量任务吞吐量比传统框架高 3-5 倍;
-
支持异步推理,可高效处理十万级以上批量请求;
-
支持结果持久化(如写入数据库、文件),便于后续处理。
-
-
实操配置与示例:
# 批量推理异步示例(处理 10 万条商品描述生成任务)
import asyncio
from vllm import AsyncLLM, SamplingParams
import pandas as pd# 读取批量任务数据(10 万条商品名称)
df = pd.read_csv("product_names.csv") # 列名:product_name
prompts = [f"Generate a 100-word product description for: {name}" for name in df["product_name"].tolist()]# 配置采样参数(离线任务可适当提高 batch 大小)
sampling_params = SamplingParams(max_tokens=100,temperature=0.8,top_p=0.95
)async def batch_generate(prompts, batch_size=512):"""异步批量生成,按批次处理避免内存溢出"""llm = AsyncLLM(model="meta-llama/Llama-2-7b-chat-hf",tensor_parallel_size=4, # 4 卡并行,提升批量处理速度max-num-batched-tokens=8192 # 增大 batch Token 数,提升吞吐量)results = []# 分批次处理for i in range(0, len(prompts), batch_size):batch_prompts = prompts[i:i+batch_size]outputs = await llm.generate(batch_prompts, sampling_params)# 提取结果batch_results = [output.outputs[0].text.strip() for output in outputs]results.extend(batch_results)print(f"Processed {i+len(batch_prompts)}/{len(prompts)} tasks")return results# 执行批量推理并保存结果
if __name__ == "__main__":descriptions = asyncio.run(batch_generate(prompts))df["description"] = descriptionsdf.to_csv("product_descriptions.csv", index=False)print("Batch generation completed, results saved to product_descriptions.csv")
(5)多 GPU / 多节点分布式部署(大规模场景)
-
场景特征:部署 70B、175B 等超大规模模型(如 LLaMA-2-70B、GPT-3-175B),单卡显存不足,需多 GPU 张量并行或多节点分布式部署。
-
vLLM 核心优势:
- 原生支持 Megatron-LM 风格的张量并行,无需手动拆分模型权重;
- 集中式 KV Cache 块表管理,多卡协同效率高,避免分布式环境下的块冲突;
- 支持多节点通信(基于 NCCL 或 Gloo),可扩展至数百张 GPU 部署超大规模模型。
-
实操配置与示例:
- 单节点多 GPU 张量并行(70B 模型):
# 8 张 A100-80GB GPU 部署 LLaMA-2-70B 模型
vllm serve \--model meta-llama/Llama-2-70b-chat-hf \--tensor-parallel-size 8 \ # 张量并行 GPU 数量,需与模型分片匹配(70B 模型通常 8 卡并行)--max-num-batched-tokens 2048 \ # 单 batch Token 数,根据显存调整--gpu-memory-utilization 0.9 \--host 0.0.0.0 --port 8000
-
多节点分布式部署(175B 模型):
需先通过
torch.distributed初始化集群,再启动各节点服务,示例如下:
# 节点 1(主节点)启动命令(IP:192.168.1.100)
python -m torch.distributed.run \--nproc_per_node=8 \ # 每节点 GPU 数--nnodes=4 \ # 总节点数--node_rank=0 \ # 节点编号(从 0 开始)--master_addr=192.168.1.100 \ # 主节点 IP--master_port=29500 \ # 主节点通信端口-m vllm.entrypoints.api_server \--model gpt-neox-20b \ # 示例模型,175B 模型需对应配置--tensor-parallel-size 32 \ # 总 GPU 数(4 节点 × 8 卡 = 32 卡)--max-num-batched-tokens 1024 \--gpu-memory-utilization 0.85# 节点 2(从节点)启动命令(IP:192.168.1.101)
python -m torch.distributed.run \--nproc_per_node=8 \--nnodes=4 \--node_rank=1 \--master_addr=192.168.1.100 \--master_port=29500 \-m vllm.entrypoints.api_server \--model gpt-neox-20b \--tensor-parallel-size 32 \--max-num-batched-tokens 1024 \--gpu-memory-utilization 0.85
-
关键注意事项:
-
多节点部署需确保各节点网络互通(建议使用 InfiniBand 网络提升通信速度);
-
模型权重需在各节点可访问(如挂载共享存储或提前同步至各节点);
-
总
tensor-parallel-size需等于 “节点数 × 每节点 GPU 数”,且需与模型支持的分片数匹配(如 175B 模型通常需 32 卡以上并行)。
-
七、vLLM 框架的局限与挑战
尽管 vLLM 优势显著,但仍存在部分局限,需在未来版本中优化:
-
硬件兼容性有限:原生仅支持 NVIDIA GPU(依赖 CUDA),对 Ascend、AMD 等非 NVIDIA 硬件的适配需用户自行改造底层算子,门槛较高;
-
模型类型支持单一:主要聚焦自回归 LLM 模型,对非自回归模型(如 T5 系列 encoder-decoder 模型)、多模态模型(如 GPT-4V)的支持仍不完善;
-
动态资源调度能力不足:当前调度策略主要基于 Token 数与序列长度,未结合业务优先级(如不同服务等级协议 SLA)进行精细化资源分配,难以满足企业级多业务混合部署需求;
-
量化精度与性能平衡:虽支持 INT8/FP8/GPTQ 等量化方案,但部分量化格式(如 4bit 量化)在长序列推理时存在精度损失,且量化后性能优化空间仍需挖掘。
八、附录:vLLM 核心配置参数速查表
为方便用户快速查阅与配置,整理 vLLM 常用核心参数,涵盖部署、性能、模型三大维度:
| 参数类别 | 参数名称 | 作用描述 | 推荐值(参考) | 注意事项 |
|---|---|---|---|---|
| 部署相关 | --model | 指定加载的模型(Hugging Face 模型名或本地路径) | meta-llama/Llama-2-7b-chat-hf | 需确保模型格式与 vLLM 兼容 |
--host/--port | 服务绑定的 IP 与端口 | 0.0.0.0/8000 | 生产环境需配置防火墙,限制外部访问 | |
--api-key | API 访问密钥,用于认证 | 自定义字符串(如 prod-xxx-xxx) | 建议定期更换,保障安全性 | |
--tensor-parallel-size | 张量并行 GPU 数量,用于多卡部署 | 1(单卡)、2/4/8(多卡,需与模型匹配) | 需确保 GPU 数量与模型分片数兼容 | |
| 性能相关 | --max-num-batched-tokens | 单个 batch 最大 Token 数,影响吞吐量与显存占用 | 7B 模型:2048-4096;70B 模型:1024-2048 | 过大易导致 OOM,过小则吞吐量低 |
--max-num-sequences | 最大并发序列数,限制同时处理的请求数 | 7B 模型:64-128;70B 模型:16-32 | 根据 GPU 显存调整,避免并发过高导致 OOM | |
--gpu-memory-utilization | 显存利用率上限,范围 0.0-1.0 | 0.8-0.95 | 预留部分显存防止 OOM,长序列推理建议 0.95 | |
--block-size | KV Cache 块大小(Token 数 / 块) | 16(默认)、32/64(超长序列) | 超长序列建议增大块大小,减少管理开销 | |
| 模型相关 | --load-8bit/--load-4bit | 启用 8bit/4bit 量化,降低显存占用 | 按需启用(显存不足时) | 部分模型量化后可能存在精度损失 |
--quantization | 指定量化格式(如 GPTQ、AWQ) | gptq/awq(需模型支持) | 需确保量化模型权重格式正确 | |
--max-sequence-length | 最大序列长度(输入 + 输出 Token 数) | 2048(默认)、100000+(超长序列) | 超长序列需配合大 block-size 与高显存利用率 |
通过本速查表,用户可根据实际硬件、模型与业务需求快速配置参数,避免反复调试,提升部署效率。