主流开源视觉语言模型(VLM)的视觉编码器架构解析
本文基于技术架构图,深入解析了当前开源视觉语言模型中三种主流的视觉编码器架构。这些架构虽被广泛采用,但各自存在明显的局限性,制约了模型性能的进一步提升。
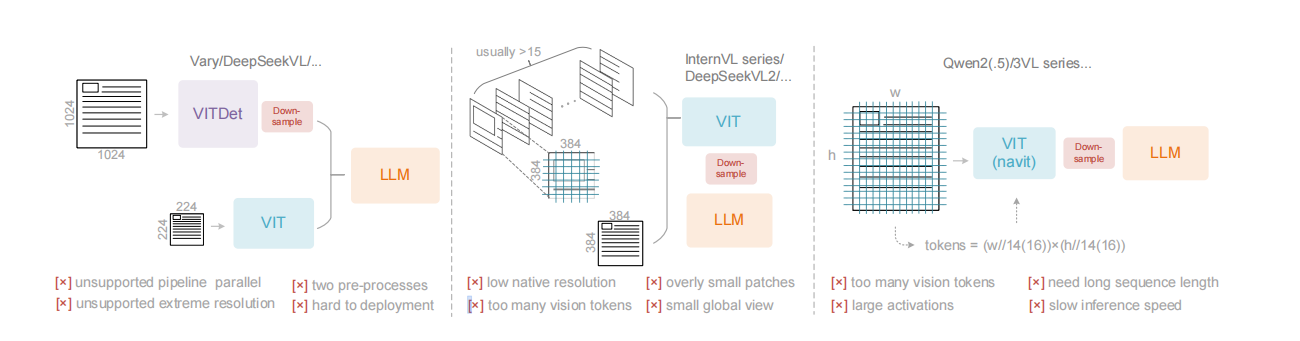
一、总体概览
该示意图清晰地展示了三种常见的VLM视觉编码器设计,它们均遵循“图像输入 → 视觉编码 → 语言模型”的基本流程。图注明确指出,这三种编码器是当前开源VLM中的典型代表,但“都存在各自的缺陷”。
二、三种架构详解
以下从左至右对三种架构进行解析:
1. 架构一:Vary / DeepSeek-VL 系列
- 核心组成:图像输入后,经由视觉编码模块进行处理,最终输出给大语言模型。
- 标注缺点:不支持流水线并行。这意味着该架构在训练时难以通过流水线并行技术来有效扩展,可能会限制训练超大模型或长序列数据的效率。
2. 架构二:InternVL 系列 / DeepSeek-VL2 系列
- 核心组成:同样包含图像输入、视觉编码模块和LLM。
- 标注缺点:原生分辨率低。这表明该架构默认处理的图像分辨率较低,可能导致对图像细节信息的丢失,影响模型在需要高精度视觉理解任务上的表现。
3. 架构三:Qwen2.5-VL / Qwen3-VL 系列
- 核心组成:结构与其他两者类似,视觉编码模块可能采用了如VITDet等架构。
- 标注缺点:动态分辨率缺失。这指的是该架构无法灵活处理任意尺寸的输入图像,通常需要将图像调整到固定尺寸,这可能引入扭曲或裁剪,影响模型对原始图像内容的准确理解。
三、总结
综上所述,当前流行的开源VLM在视觉编码器设计上呈现出几种不同的技术路径,但无一完美。Vary/DeepSeek-VL系列受限于训练扩展性,InternVL/DeepSeek-VL2系列牺牲了图像分辨率,而Qwen2.5/3-VL系列则缺乏处理动态分辨率的灵活性。 这些缺陷指明了VLM技术未来的重要改进方向,例如开发支持高效并行训练、能够原生处理高分辨率及任意尺寸图像的视觉编码器,将是提升模型整体性能的关键。
核心内容中英对照:
- 视觉语言模型:Vision Language Model
- 视觉编码器:Vision Encoder
- 流水线并行:Pipeline Parallelism
- 原生分辨率:Native Resolution
- 动态分辨率:Dynamic Resolution
- 缺陷:Deficiencies