SGV3D:面向基于视觉的路边3D目标检测的场景泛化
论文题目:SGV3D: Toward Scenario Generalization for Vision-Based Roadside 3D Object Detection(面向基于视觉的路边3D目标检测的场景泛化)
期刊:IEEE TRANSACTIONS ON INTELLIGENT TRANSPORTATION SYSTEMS
摘要:路边感知可以将自动驾驶汽车的感知能力扩展到视觉范围之外,并对闭塞区域进行寻址,从而显著提高自动驾驶汽车的安全性。然而,目前最先进的基于视觉的路边检测方法在标记场景上表现出很高的准确性,但在新场景上表现不佳。这种限制是因为路边摄像头在安装后保持静止,只能从单个场景收集数据,导致算法过度拟合这些路边背景和摄像头位置。为了解决这个问题,我们提出了一个创新的基于视觉的路边3D物体检测场景泛化框架,称为SGV3D。具体来说,我们利用背景抑制模块(BSM)通过在2D到鸟瞰投影期间减少背景特征来减少以视觉为中心的管道中的背景过拟合。此外,通过引入半监督数据生成管道(SSDG),该管道使用来自新场景的未标记图像,我们生成具有不同相机姿势的不同前景实例,从而降低了过度拟合到特定相机位置的风险。在两个大规模路边基准测试上进行的实验表明,SGV3D在仅增加最小延迟的情况下,有效地提高了基于视觉的路边3D目标检测器的场景泛化能力。代码可在这里获得(https://github.com/yanglei18/SGV3D)。
深度解读SGV3D——解决路侧3D目标检测场景泛化难题
引言:智能交通的新挑战
随着智能交通系统的快速发展,路侧感知技术成为增强自动驾驶车辆安全性的关键。路侧相机具有更高的安装高度和更广的视野,可以有效解决车载传感器的遮挡和感知范围受限问题。
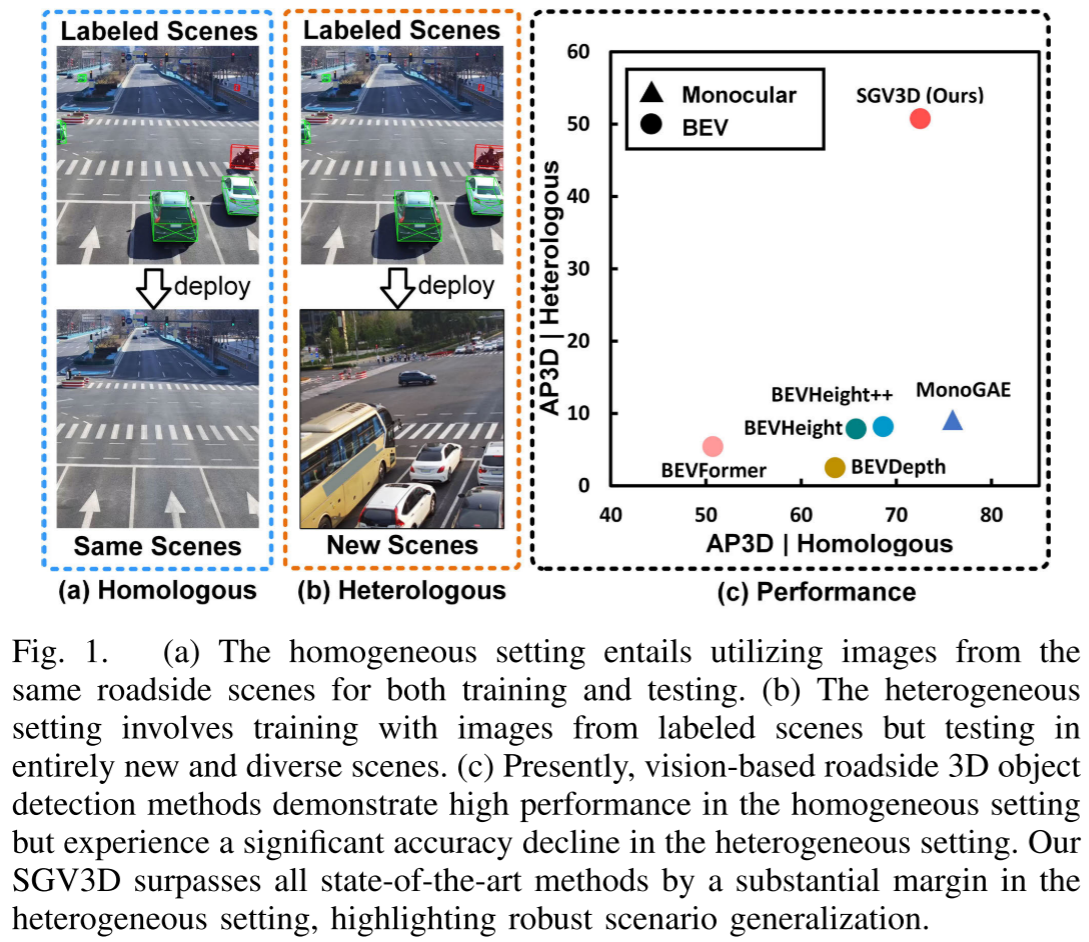
然而,一个关键问题困扰着研究者:为什么在标注场景上表现优异的检测算法,在新场景中性能会急剧下降?
来自清华大学的研究团队在IEEE TRANSACTIONS ON INTELLIGENT TRANSPORTATION SYSTEMS上发表的论文"SGV3D"给出了深入的分析和创新的解决方案。
问题剖析:场景泛化的两大障碍
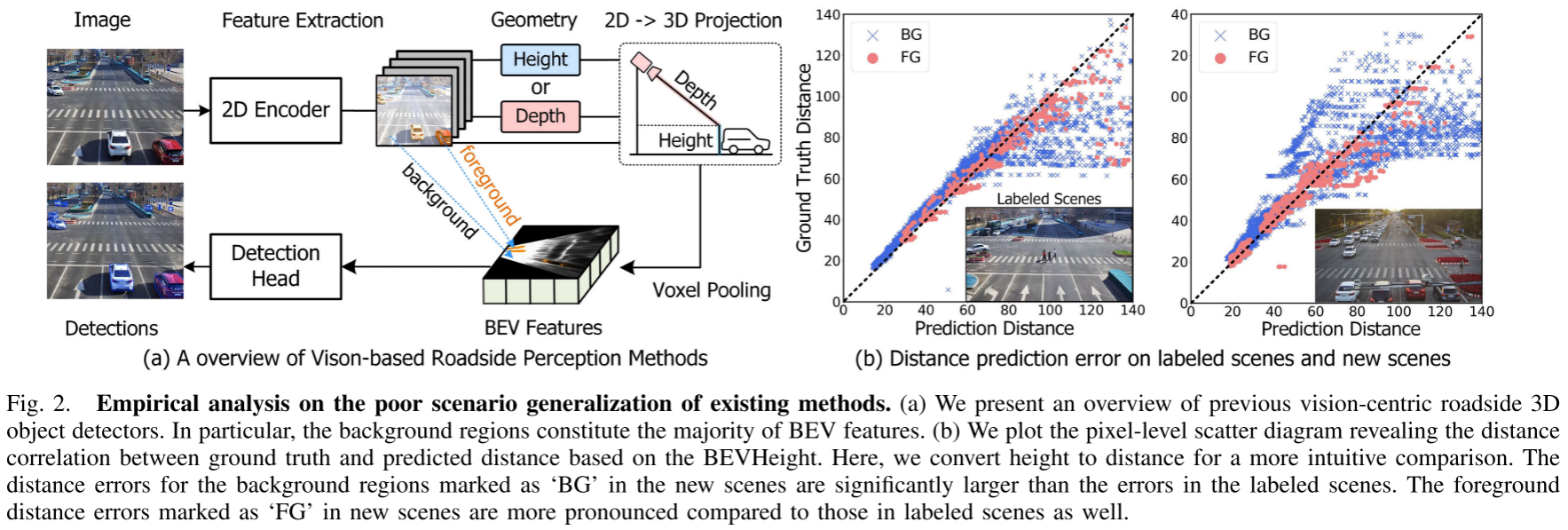
障碍一:背景过拟合
研究团队通过详细的像素级误差分析发现了一个关键问题:
背景区域占据了Bird's Eye View (BEV)特征的大部分。在新场景中,背景的距离预测误差远大于标注场景。这意味着算法严重"记住"了训练场景的特定背景,而不是学习到可泛化的特征。
想象一下:如果一个算法在北京某个路口训练,它可能记住了特定的建筑物、路面纹理等背景信息。当部署到上海的新路口时,这些背景信息完全不同,导致算法性能崩溃。
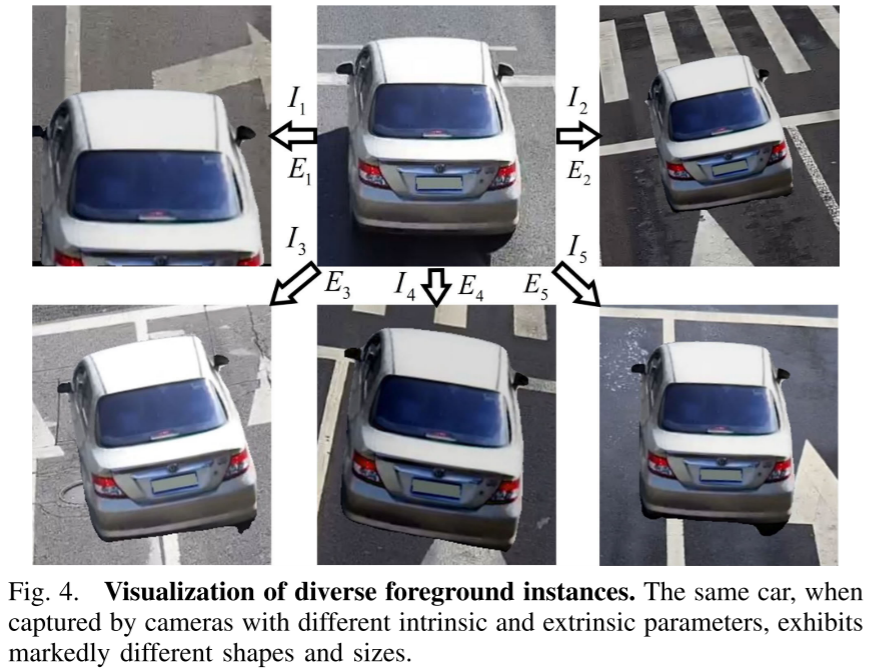
障碍二:相机姿态固定
路侧相机安装后位置固定,只能从单一视角采集数据。这导致算法对特定的相机内参和外参过拟合。
实验数据令人震惊:
- BEVDepth准确率从63.58%暴跌到2.48%
- BEVHeight从65.77%下降到7.86%
这样的性能下降在实际部署中是不可接受的。
创新方案:SGV3D的"双管齐下"策略
核心思想:背景抑制 + 前景丰富
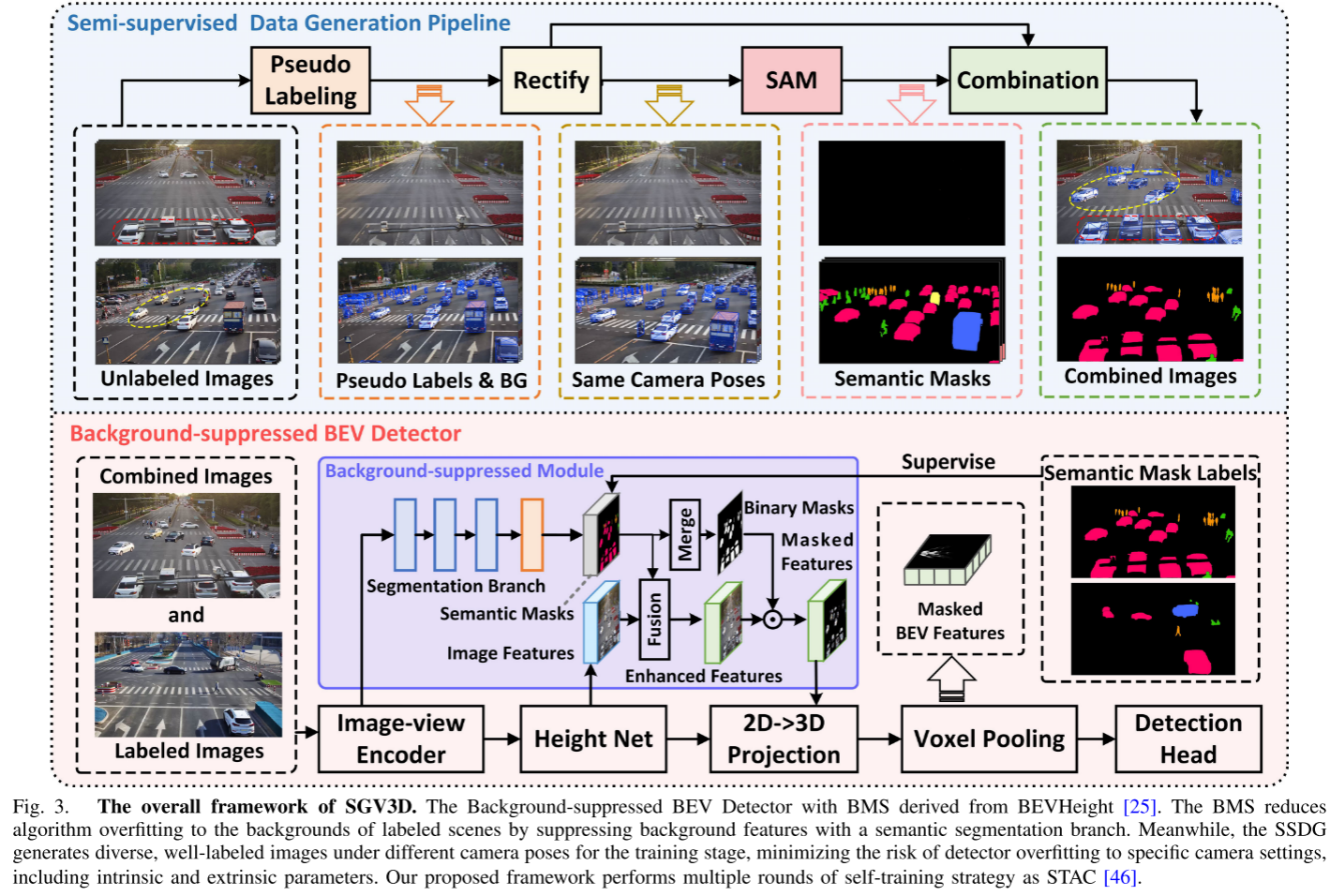
SGV3D提出了一个优雅的解决方案:
- 抑制背景:既然背景容易导致过拟合,那就减少它的影响
- 丰富前景:通过半监督学习生成多样化的前景实例
技术细节一:Background-Suppressed Module (BSM)
BSM的工作流程:
步骤1:语义分割 使用深度学习分割网络识别图像中的前景对象(车辆、行人等)和背景区域。
步骤2:特征融合 将分割信息与原始特征融合,通过通道注意力机制增强有用特征。
步骤3:背景过滤 在将2D特征投影到BEV空间之前,使用二值掩码过滤掉背景特征。
这样,最终的BEV特征主要包含前景对象信息,大大减少了对特定背景的依赖。
技术细节二:Semi-supervised Data Generation Pipeline (SSDG)
SSDG解决了另一个关键问题:如何让模型适应不同的相机姿态?
创新的数据合成流程:
伪标签生成:使用当前模型为未标注的新场景图像生成高置信度的伪标签
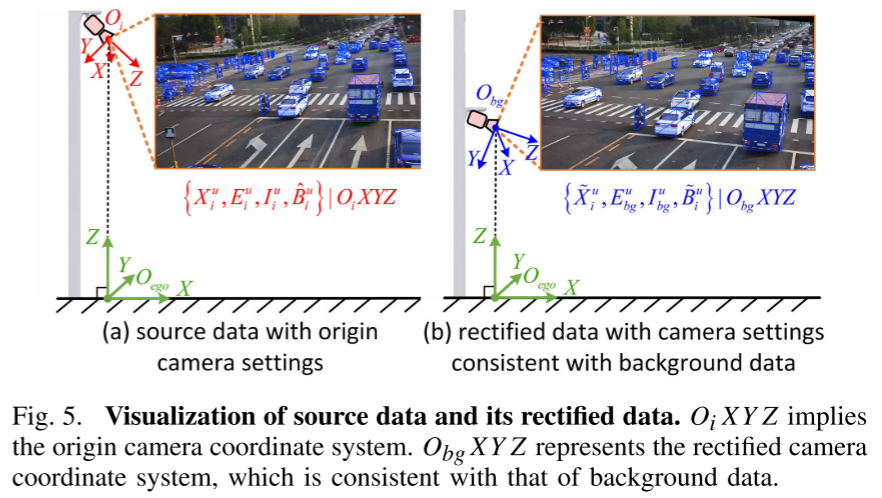
相机参数矫正:
- 统一不同图像的相机姿态
- 调整相机安装高度
- 确保伪标签与图像完美对齐
SAM辅助分割:利用Segment Anything Model生成精确的实例掩码
智能组合:将不同相机视角的前景对象与空白背景巧妙组合,生成多样化的训练样本
这个过程的精妙之处在于:无需人工标注新场景,就能生成大量具有不同相机姿态的高质量训练数据。
实验验证
同质基准:稳定的性能提升
在DAIR-V2X-I数据集的标准测试中,SGV3D相比基线方法全面提升:
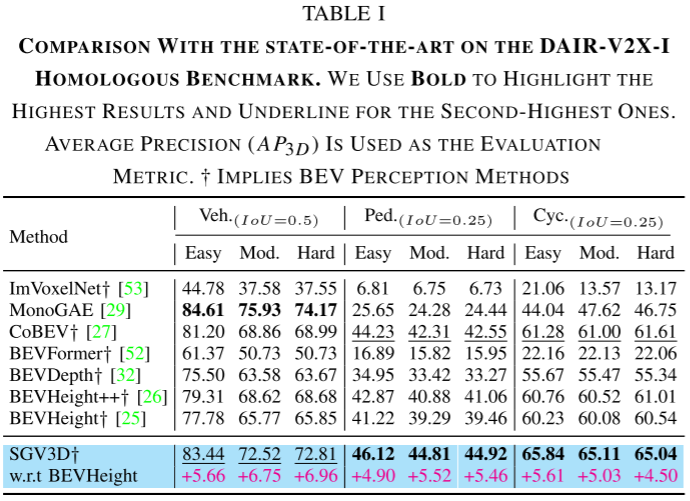
- 车辆检测:+6.75%
- 行人检测:+5.52%
- 骑行者检测:+5.03%
异质基准:场景泛化的巨大突破
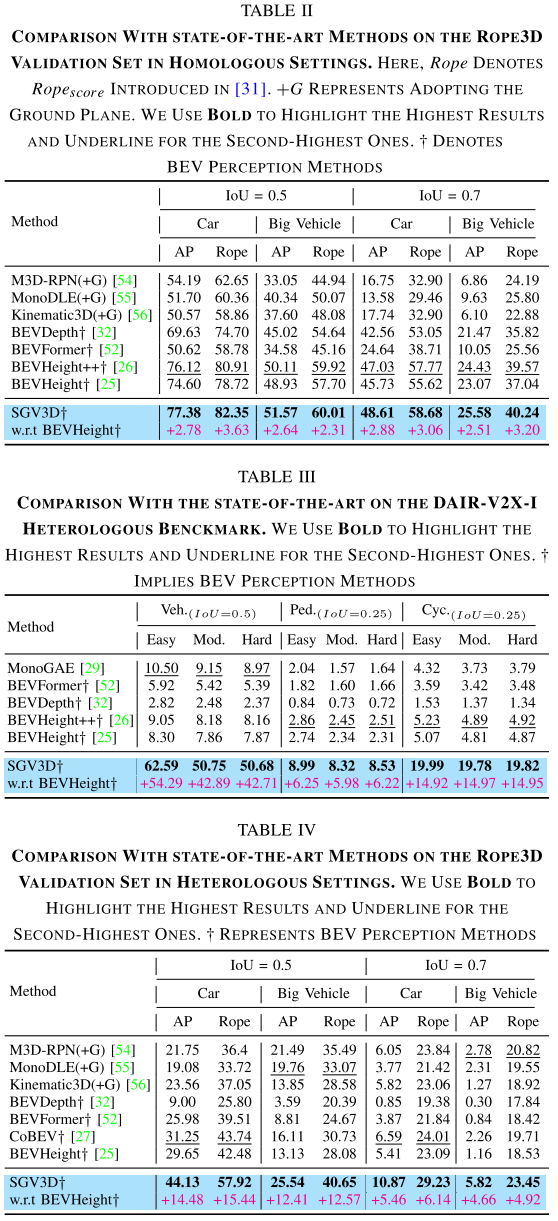
真正令人震撼的是跨场景测试结果:
DAIR-V2X-I异质设置:
- 车辆检测:领先其他方法**+42.57%**
- 行人检测:+5.87%
- 骑行者检测:+14.89%
Rope3D大规模测试:
- 轿车:+14.48% (AP)
- 大型车辆:+12.41% (AP)
这些数字背后的意义是:SGV3D真正实现了从一个场景到完全不同场景的有效迁移。
效率分析:性能与开销的平衡
一个关键问题:这些改进的代价是什么?
答案令人惊喜:
- 准确率提升:+42.89%
- 延迟增加:仅约3%
- 内存增加:仅约3%
这意味着SGV3D可以在实际系统中部署,而不会显著增加计算负担。
消融实验:深入理解各组件
BSM的独立贡献
仅添加BSM模块,在不使用任何未标注数据的情况下:
- 车辆:+8.53%
- 行人:+2.46%
- 骑行者:+3.33%
这验证了背景抑制策略的有效性。
SSDG的增强效果
加入SSDG后,性能进一步飞跃:
- 车辆:达到49.03%
- 行人:6.92%
- 骑行者:17.29%
未标注数据的价值
研究还发现,使用更多未标注数据能持续提升性能:
- 使用25%数据:车辆34.36%
- 使用100%数据:车辆49.03%(提升14.67%)
这为实际应用提供了清晰的指导:收集更多未标注的新场景数据是值得的。
可视化结果:直观的改进
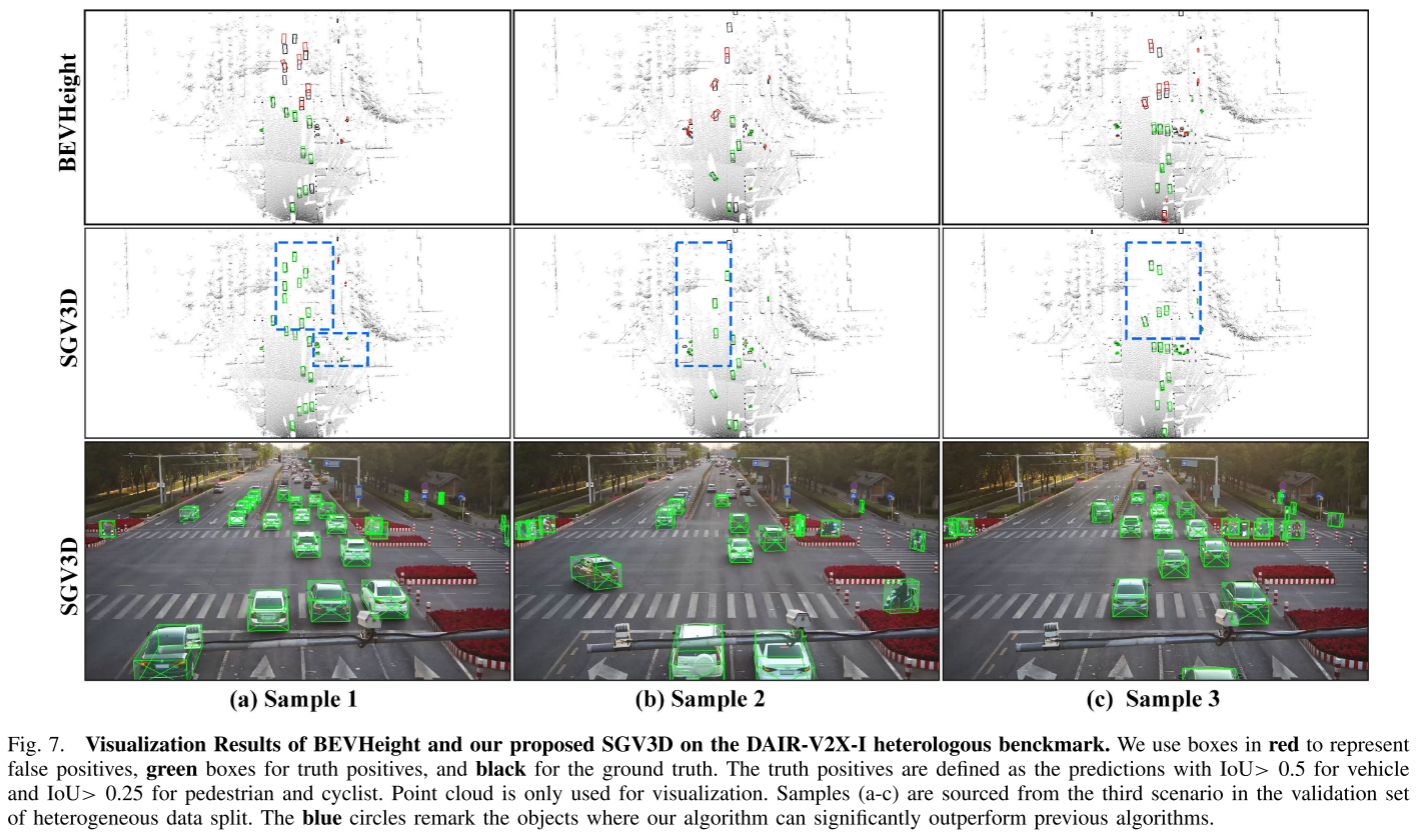

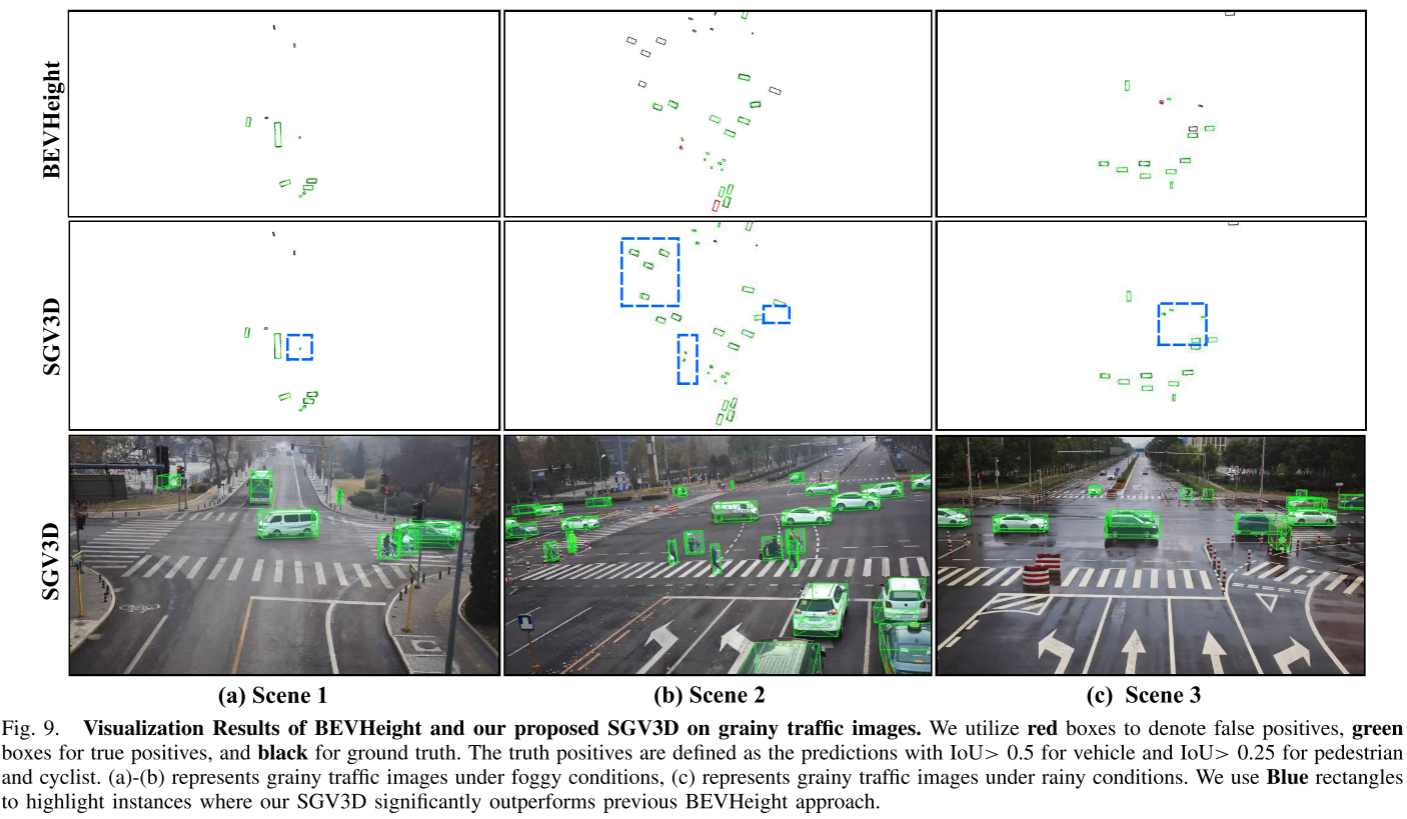
论文提供了丰富的可视化对比:
场景1:城市十字路口
- BEVHeight:多处漏检和定位偏移
- SGV3D:准确检测所有目标,定位精确
场景2:夜间场景
- BEVHeight:远距离车辆检测失败
- SGV3D:成功检测并定位遮挡的远距离车辆
场景3:雾霾天气
- BEVHeight:大量误检和漏检
- SGV3D:鲁棒的检测性能
技术洞察与启示
1. 数据并非越多越好,质量更重要
SGV3D的成功表明,通过智能的数据生成策略,可以用相对少量的未标注数据实现显著的性能提升。
2. 领域知识的重要性
BSM模块的设计体现了对路侧感知问题本质的深刻理解:背景特征在BEV表示中占主导地位,但对检测任务贡献有限。
3. 模块化设计的优势
SGV3D的BSM和SSDG都可以独立发挥作用,这种模块化设计便于在不同场景中灵活应用。
4. 半监督学习的潜力
SSDG展示了半监督学习在解决实际问题中的巨大潜力,特别是在标注成本高昂的场景中。
未来展望
SGV3D为路侧感知的大规模部署铺平了道路,但仍有改进空间:
多模态融合:结合LiDAR等其他传感器,进一步提升鲁棒性
在线适应:开发能够在部署后持续学习的系统
极端天气:增强在雨雪雾等极端天气条件下的性能
计算优化:进一步降低计算开销,支持边缘部署
结论
SGV3D代表了路侧3D目标检测领域的重要进展。通过创新的背景抑制和半监督数据生成策略,它成功解决了场景泛化这一关键挑战。
核心takeaways:
- ✅ 首个专注于场景泛化的路侧3D检测框架
- ✅ 在跨场景测试中领先现有方法40%以上
- ✅ 计算开销增加小于3%
- ✅ 无需标注新场景数据
对于智能交通系统的研究者和从业者,SGV3D提供了宝贵的技术路线和实践指导。它不仅是一个算法创新,更是对如何构建可泛化、可部署的感知系统的深刻思考。