Transformers之外的注意力机制
原文: https://magazine.sebastianraschka.com/p/beyond-standard-llms 有删减
从DeepSeek R1到MiniMax-M2,当今规模最大、能力最强的开放权重大语言模型仍然采用自回归解码器风格的Transformer架构,这些架构都基于原始多头注意力机制的不同变体。
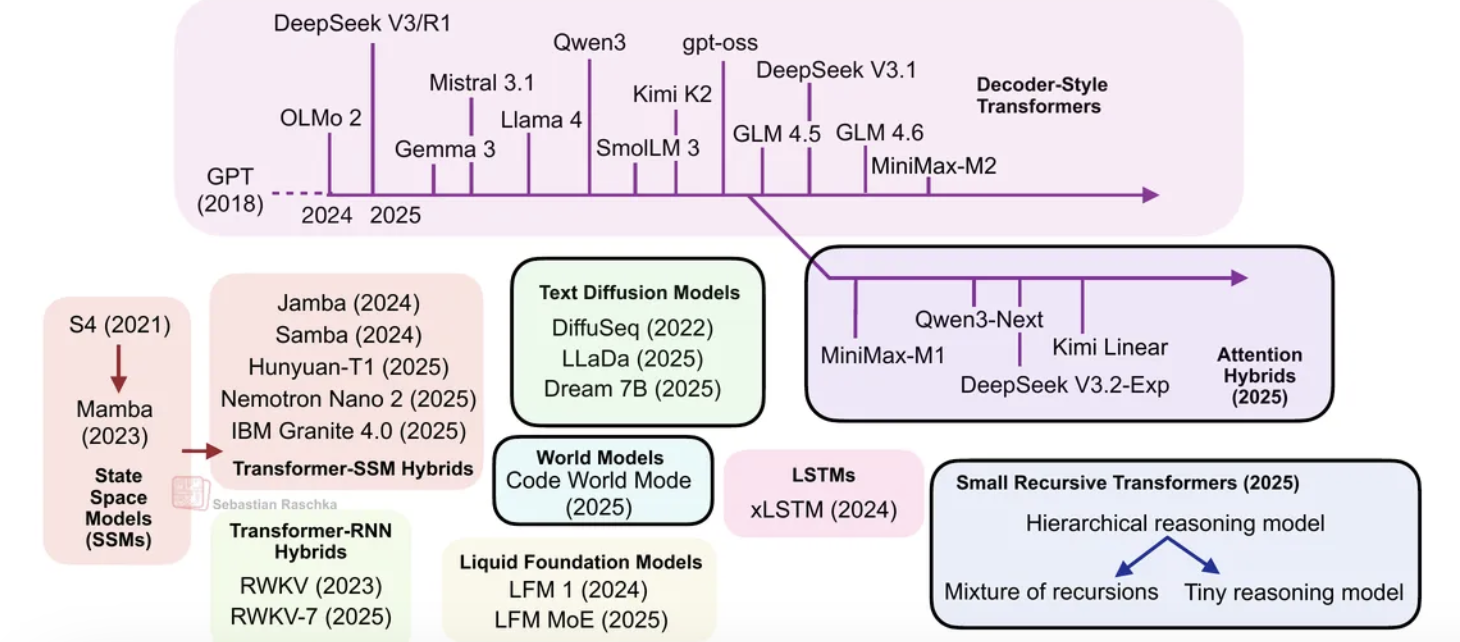
(线性)注意力混合架构
近年来,线性注意力机制重新兴起,以提升大语言模型的效率。
传统注意力与二次成本
原始注意力机制随序列长度呈二次方扩展:
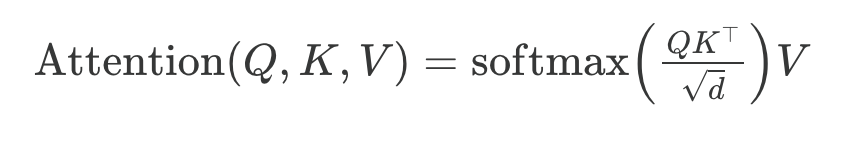
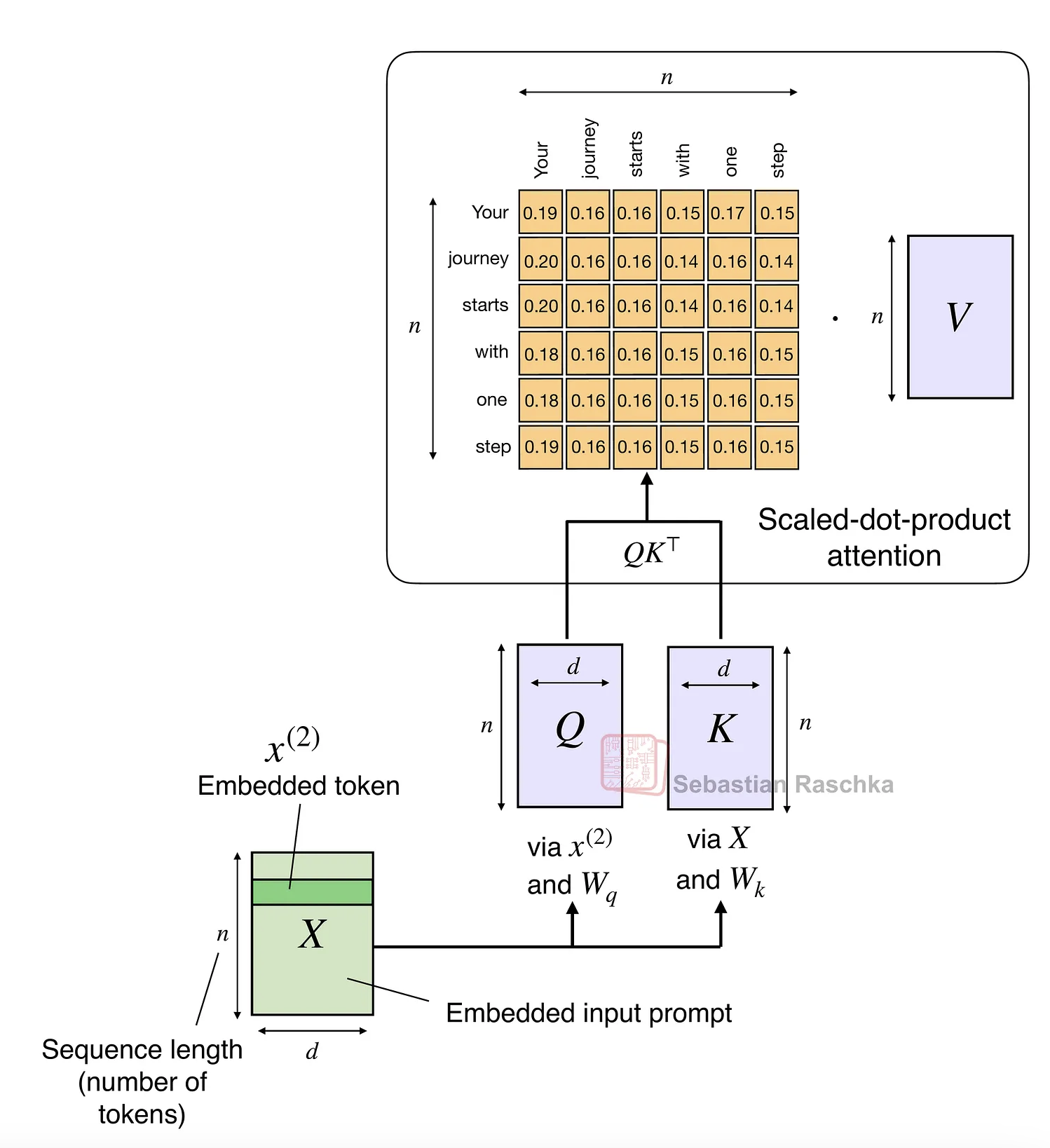
这是因为查询(Q)、键(K)和值(V)是 n×d 矩阵,其中 d 是嵌入维度(超参数),n 是序列长度(即令牌数量)。
线性注意力
线性注意力变体已存在多年,我记得在2020年代看到了大量相关论文。例如,我最早回忆起的是2020年的《Transformers are RNNs: Fast Autoregressive Transformers with Linear Attention》论文,其中研究者通过以下方式近似注意力机制:
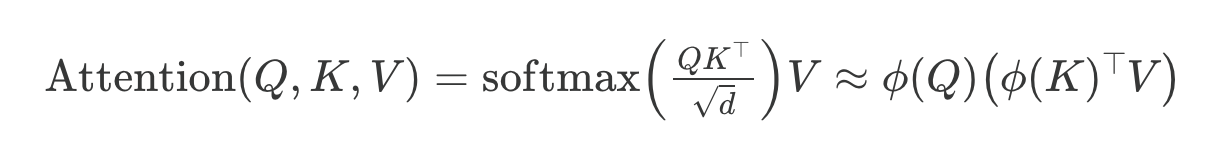
此处 ϕ(⋅) 是一个核特征函数,设置为 ϕ(x) = elu(x) + 1。
这种近似之所以高效,是因为它避免了显式计算 n×n 注意力矩阵 QKᵀ。但归根结底,它们将时间和空间复杂度从 O(n²) 降低至 O(n),使得注意力机制对长序列的处理效率大幅提升。然而,这些方法从未真正流行起来,因为它们会降低模型精度,而且我从未在开放权重的顶尖大语言模型中见到这些变体的实际应用。
线性注意力复兴
今年下半年,线性注意力变体重新兴起,部分模型开发者之间还出现了一些反复讨论,如下图所示。
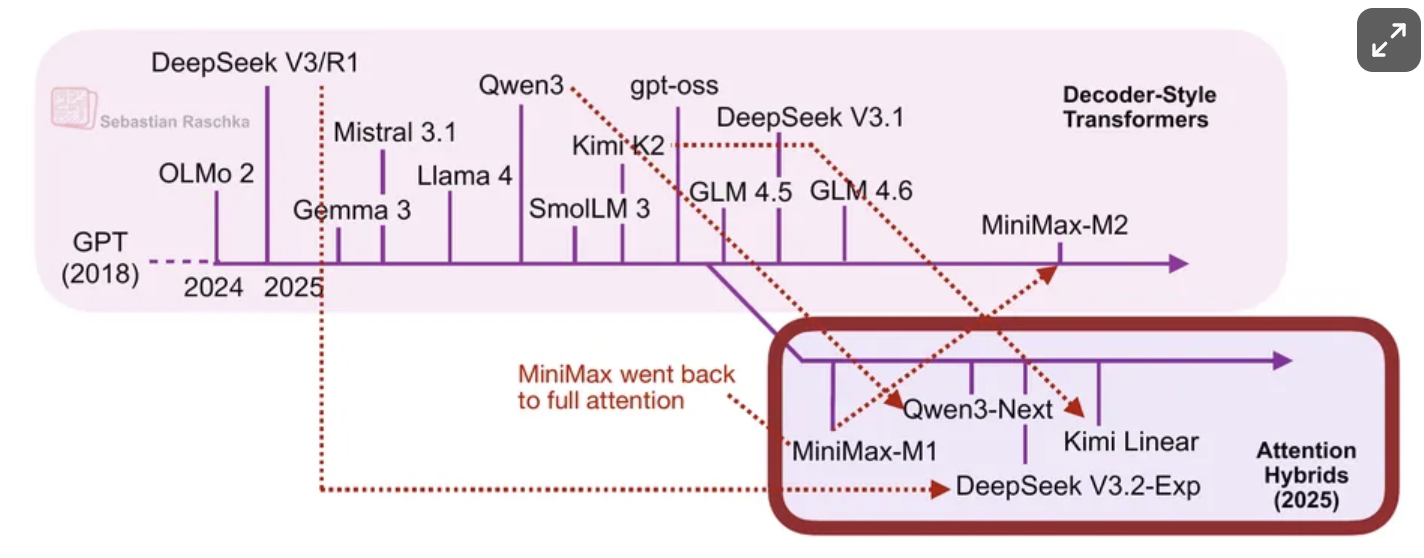
首个值得关注的模型是采用闪电注意力(lightning attention)的MiniMax-M1。
随后在8月,Qwen3团队推出了Qwen3-Next(我在前文已详细讨论)。9月,DeepSeek团队发布了DeepSeek V3.2(虽然其稀疏注意力机制并非严格线性,但计算成本至少是次二次的,因此我认为将其与MiniMax-M1、Qwen3-Next和Kimi Linear归为同一类别是合理的)。