线程池浅谈
线程池
为什么要使用线程池
使⽤线程池主要有以下三个原因:
- 资源优化:线程池通过重复利用已创建的线程,减少了频繁创建和销毁线程的开销,从而降低系统资源的消耗。
- 控制并发:线程池可以设定最大线程数量,有效控制系统中同时运行的线程数,避免因并发过高导致的服务器过载问题。
- 管理简化:线程池提供统一的线程管理和任务调度机制,简化了多线程编程的复杂性,使得代码更加清晰易维护。
线程池接口与实现
ThreadPoolExecutor 类
ThreadPoolExecutor提供了一系列构造函数,允许开发者自定义线程池的核心参数
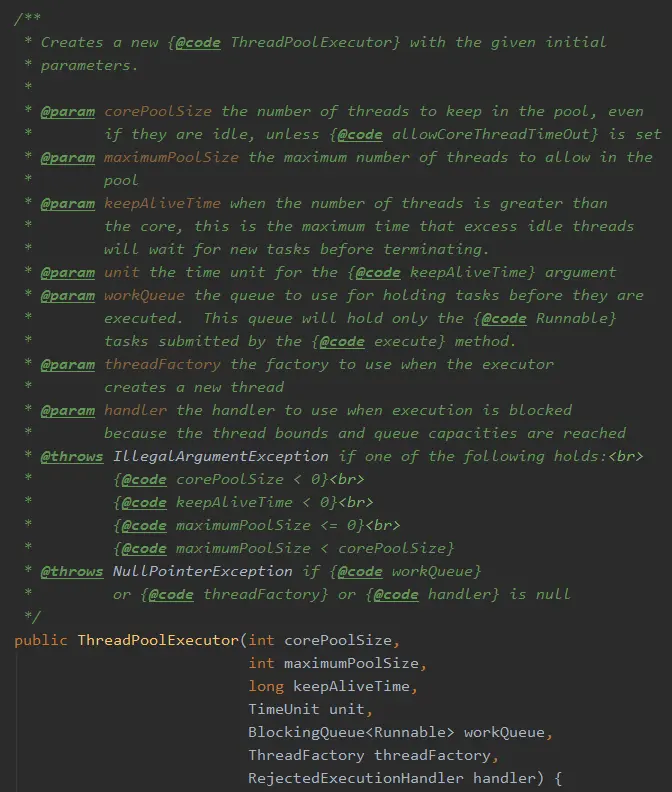
corePoolSize:核心线程数大小:不管它们创建以后是不是空闲的。线程池需要保持 corePoolSize 数量的线程,除非设置了 allowCoreThreadTimeOut。
maximumPoolSize:最大线程数:线程池中最多允许创建 maximumPoolSize 个线程。
keepAliveTime:存活时间:如果经过 keepAliveTime 时间后,超过核心线程数的线程还没有接受到新的任务,那就回收。
unit:keepAliveTime 的时间单位。
workQueue:存放待执行任务的队列:当提交的任务数超过核心线程数大小后,再提交的任务就存放在这里。它仅仅用来存放被 execute 方法提交的 Runnable 任务。
threadFactory:线程工厂:用来创建线程工厂。
handler:拒绝策略:当队列里面放满了任务、最大线程数的线程都在工作时,这时继续提交的任务线程池就触发拒绝策略。
线程池核心参数设置
CPU 密集型场景:
- 核心线程数(Core Pool Size):
- 设置为 CPU 核心数量或者稍微多一些,以保证 CPU 能够充分利用。
- 太多的核心线程数会导致线程切换开销增加,而太少会导致 CPU 无法充分利用。
- 最大线程数(Maximum Pool Size):
- 可以根据 CPU 的核心数量和系统负载来调整,通常不需要太大。
- 如果任务需要的计算量较大,可以适当增加最大线程数,以提高任务并行度。
- 工作队列:
- 由于是 CPU 密集型任务,可以选择一个较小的工作队列,或者使用 SynchronousQueue。
- 较小的工作队列可以减少任务排队的等待时间,提高任务的响应速度。
- 线程存活时间(Keep Alive Time):
- 对于 CPU 密集型任务,一般不需要设置线程存活时间,因为线程会一直被利用来执行任务。
I/O 密集型场景:
- 核心线程数(Core Pool Size):
- 可以设置较大的核心线程数,以充分利用 CPU 资源。
- I/O 操作通常会导致线程阻塞,因此可以增加核心线程数以处理更多的并发 I/O 请求。
- 最大线程数(Maximum Pool Size):
- 与核心线程数相比,可以适当增加最大线程数,以应对突发的大量请求。
- 但是需要注意控制最大线程数的大小,避免过度消耗系统资源。
- 工作队列:
- 对于 I/O 密集型任务,通常需要使用一个较大的工作队列,以缓冲大量的等待执行的任务。
- 选择一个适当大小的有界队列可以控制系统的内存占用,并且可以提供一定程度的任务排队和调度。
- 线程存活时间(Keep Alive Time):
- 可以设置一个较短的线程存活时间,以便及时回收空闲线程,释放系统资源。
threadFactory:线程工厂
线程工厂的主要作用体现在以下几点:
- 命名线程:给线程起一个有意义的名字,这有助于调试和日志记录,因为线程名可以反映线程的用途。
- 设置线程优先级:可以根据需要调整线程的优先级。
- 设置线程组:将线程分配到特定的线程组,这对于资源管理和异常处理是有帮助的。
- 设置守护线程:决定线程是否应该作为守护线程运行,守护线程在所有非守护线程结束后会自动终止。
- 资源管理:在创建线程前后执行特定的操作,比如记录日志或进行其他初始化/清理工作。
- 错误处理:如果线程创建过程中出现错误,自定义的线程工厂可以捕获并处理这些异常。
下面是一个简单的自定义工厂例子:
ThreadFactory threadFactory = new ThreadFactory() {@Overridepublic Thread newThread(Runnable r) {// 创建线程池中的线程Thread thread = new Thread(r);// 设置线程名称thread.setName("Thread-" + r.hashCode());// 设置线程的优先级 (1-10) 最大 10thread.setPriority(Thread.MAX_PRIORITY);// 设置线程的类型 (前台/后台线程)thread.setDaemon(false);// ....return thread;}
}
handler:拒绝策略
ThreadPoolExecutor提供了四个拒绝策略
AbortPolicy
默认的拒绝策略
public static class AbortPolicy implements RejectedExecutionHandler {public AbortPolicy() { }public void rejectedExecution(Runnable r, ThreadPoolExecutor e) {throw new RejectedExecutionException("Task " + r.toString() + " rejected from " + e.toString());}
}
AbortPolicy在任务被拒绝添加后,会直接抛出RejectedExecutionException异常。
ThreadPoolTaskExecutor executor = new ThreadPoolTaskExecutor();
executor.setCorePoolSize(1);
executor.setMaxPoolSize(1);
executor.setQueueCapacity(1);
executor.setRejectedExecutionHandler(new ThreadPoolExecutor.AbortPolicy());
executor.initialize();
for (int i=0;i<=2;i++){int finalI = i;executor.execute(() -> {try {log.info("当前执行任务={}",finalI);Thread.sleep(10000);} catch (InterruptedException e) {e.printStackTrace();}});
}
--------------------输出结果--------------------
[ThreadPoolTaskExecutor-1 - ] INFO n.b.DemoTest - 当前执行任务=1
java.util.concurrent.RejectedExecutionException: xxx
添加第一个任务时,直接执行,任务列表为空。
添加第二个任务时,核心线程正在执行任务,所以会将第二个任务放在任务队列中
添加第三个任务时,因为核心任务还在运行,任务队列已经满了,且已达到最大线程数,再也没有地方能存放和执行这个任务了,就会被线程池拒绝添加。
执行拒绝策略的rejectedExecution方法,直接抛出异常
CallerRunsPolicy
public static class CallerRunsPolicy implements RejectedExecutionHandler {public CallerRunsPolicy() { }public void rejectedExecution(Runnable r, ThreadPoolExecutor e) {if (!e.isShutdown()) {r.run();}}
}
CallerRunsPolicy在任务被拒绝添加后,会用调用execute函数的上层线程去执行被拒绝的任务。
[main - ] INFO n.b.DemoTest - 当前执行任务=3
[ThreadPoolTaskExecutor-1 - ] INFO n.b.DemoTest - 当前执行任务=1
[ThreadPoolTaskExecutor-1 - ] INFO n.b.DemoTest - 当前执行任务=2
添加第三个任务的时候,被线程池拒绝了,因此执行了CallerRunsPolicy的rejectedExecution方法,这个方法直接执行任务的run方法。因此可以看到任务三是在main线程中执行的。
这个策略的缺点就是由于任务在主线程中运行,可能会阻塞主线程。
DiscardPolicy
public static class DiscardPolicy implements RejectedExecutionHandler {public DiscardPolicy() { }public void rejectedExecution(Runnable r, ThreadPoolExecutor e) {}
}
CallerRunsPolicy在任务被拒绝添加后直接抛弃,不会抛异常也不会执行。
[ThreadPoolTaskExecutor-1 - ] INFO n.b.DemoTest - 当前执行任务=1
[ThreadPoolTaskExecutor-1 - ] INFO n.b.DemoTest - 当前执行任务=2
添加第三个任务的时候,被线程池拒绝了,什么反应都没有,直接丢弃。
DiscardOldestPolicy
public static class DiscardOldestPolicy implements RejectedExecutionHandler {public DiscardOldestPolicy() { }public void rejectedExecution(Runnable r, ThreadPoolExecutor e) {if (!e.isShutdown()) {e.getQueue().poll();e.execute(r);}}
}
DiscardOldestPolicy策略的作用是,当任务被拒绝添加时,会抛弃任务队列中最旧的任务,再把这个新任务添加进去。
[ThreadPoolTaskExecutor-1 - ] INFO n.b.DemoTest - 当前执行任务=1
[ThreadPoolTaskExecutor-1 - ] INFO n.b.DemoTest - 当前执行任务=3
在添加第三个任务时,会被线程池拒绝。这时任务队列中有 任务二
这时拒绝策略会让任务队列中最旧的任务弹出,也就是任务二.
然后把被拒绝的任务三添加到任务队列
线程池状态
线程池有多种状态,每种状态反映了线程池当前的行为模式,主要包括以下五种:
- RUNNING
- 描述:线程池处于运行状态,能够接收新任务,并且会处理已经在工作队列中的任务。
- 行为:这是线程池的初始状态,也是其主要的工作状态。
- SHUTDOWN
- 描述:线程池处于关闭状态,不再接收新任务,但是会继续处理已经在工作队列中的任务,直到它们完成。
- 行为:通常通过调用shutdown()方法达到此状态。
- STOP
- 描述:线程池处于停止状态,不再接收新任务,也不再处理已经在工作队列中的任务,并且会尝试中断正在执行的任务。
- 行为:通常通过调用shutdownNow()方法达到此状态。
- TIDYING
- 描述:当线程池中的所有任务都已终止,且工作队列为空,线程池会进入TIDYING状态。
- 行为:在此状态下,线程池会执行一个钩子方法terminated(),这是一个空实现,但可以被重写以执行一些清理工作。
- TERMINATED
- 描述:这是线程池的最终状态,在执行完terminated()方法后,线程池会进入TERMINATED状态,表示线程池已经完全终止。
- 行为:一旦到达TERMINATED状态,线程池就无法再恢复到之前的状态,也不能重新接收和处理任务。
线程池状态之间的转换是单向的,从RUNNING状态开始,可以转换到SHUTDOWN或STOP状态,而从SHUTDOWN或STOP状态,可以进一步转换到TIDYING,最后到达TERMINATED状态。这些状态的转换是由线程池内部的逻辑自动处理的,通常用户不需要直接干预这些状态的改变,而是通过调用shutdown()或shutdownNow()等方法间接触发状态的改变。
线程池处理流程
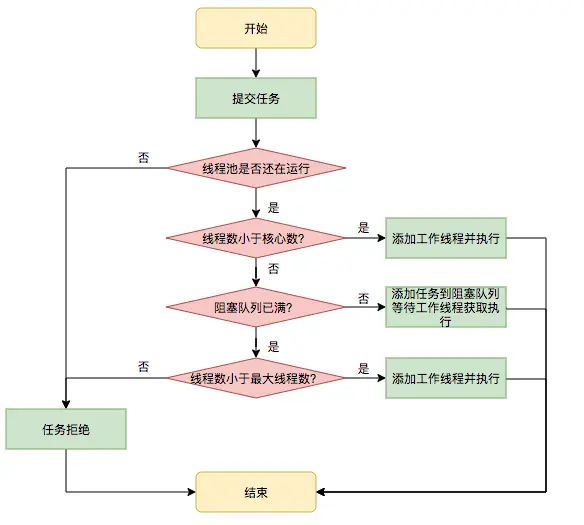
线程池主要的任务处理流程
public void execute(Runnable command) {if (command == null)throw new NullPointerException(); int c = ctl.get();// 1.当前线程数⼩于corePoolSize,则调⽤addWorker创建核⼼线程执⾏任务if (workerCountOf(c) < corePoolSize) {if (addWorker(command, true))return;c = ctl.get();}// 2.如果不⼩于corePoolSize,则将任务添加到workQueue队列。if (isRunning(c) && workQueue.offer(command)) {int recheck = ctl.get();// 2.1 如果isRunning返回false(状态检查),则remove这个任务,然后执⾏拒绝策略。if (! isRunning(recheck) && remove(command))reject(command);// 2.2 线程池处于running状态,但是没有线程,则创建线程else if (workerCountOf(recheck) == 0)addWorker(null, false);}// 3.如果放⼊workQueue失败,则创建⾮核⼼线程执⾏任务,// 如果这时创建⾮核⼼线程失败(当前线程总数不⼩于maximumPoolSize时),就会执⾏拒绝策略。else if (!addWorker(command, false))reject(command);
}
Executors中的四种线程池
- newFixedThreadPool (固定数目线程的线程池)
- newCachedThreadPool(可缓存线程的线程池)
- newSingleThreadExecutor(单线程的线程池)
- newScheduledThreadPool(定时及周期执行的线程池)
newFixedThreadPool
public static ExecutorService newFixedThreadPool(int nThreads, ThreadFactory threadFactory) {return new ThreadPoolExecutor(nThreads, nThreads,0L, TimeUnit.MILLISECONDS,new LinkedBlockingQueue<Runnable>(),threadFactory);
}
线程池特点:
- 核心线程数和最大线程数大小一样
- 没有所谓的非空闲时间,即keepAliveTime为0
- 阻塞队列为无界队列LinkedBlockingQueue
工作机制
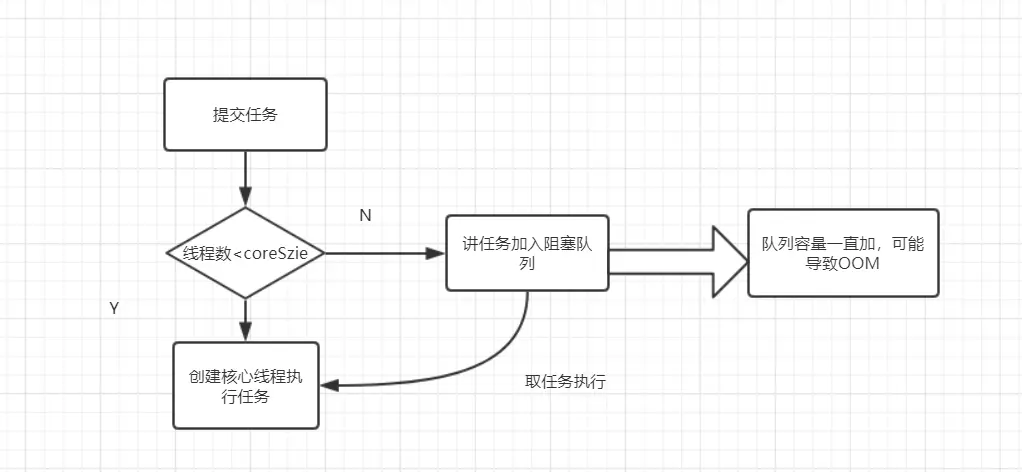
- 提交任务
- 如果线程数少于核心线程,创建核心线程执行任务
- 如果线程数等于核心线程,把任务添加到LinkedBlockingQueue阻塞队列
- 如果线程执行完任务,去阻塞队列取任务,继续执行。
newCachedThreadPool
public static ExecutorService newCachedThreadPool(ThreadFactory threadFactory) {return new ThreadPoolExecutor(0, Integer.MAX_VALUE,60L, TimeUnit.SECONDS,new SynchronousQueue<Runnable>(),threadFactory);
}
线程池特点
- 核心线程数为0
- 最大线程数为Integer.MAX_VALUE
- 阻塞队列是SynchronousQueue
- 非核心线程空闲存活时间为60秒
当提交任务的速度大于处理任务的速度时,每次提交一个任务,就必然会创建一个线程。极端情况下会创建过多的线程,耗尽 CPU 和内存资源。由于空闲 60 秒的线程会被终止,长时间保持空闲的 CachedThreadPool 不会占用任何资源。
工作机制
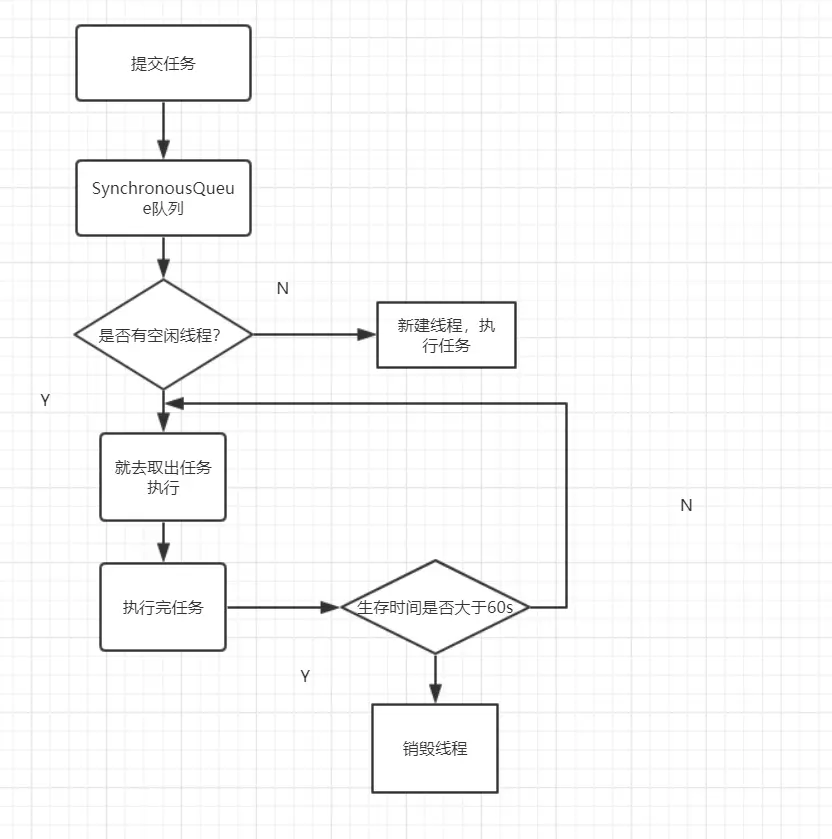
- 提交任务
- 因为没有核心线程,所以任务直接加到SynchronousQueue队列。
- 判断是否有空闲线程,如果有,就去取出任务执行。
- 如果没有空闲线程,就新建一个线程执行。
- 执行完任务的线程,还可以存活60秒,如果在这期间,接到任务,可以继续活下去;否则,被销毁。
newSingleThreadExecutor
public static ExecutorService newSingleThreadExecutor(ThreadFactory threadFactory) {return new FinalizableDelegatedExecutorService
(new ThreadPoolExecutor(1, 1,0L, TimeUnit.MILLISECONDS,new LinkedBlockingQueue<Runnable>(),threadFactory));
}
线程池特点
- 核心线程数为1
- 最大线程数也为1
- 阻塞队列是LinkedBlockingQueue
- keepAliveTime为0
工作机制
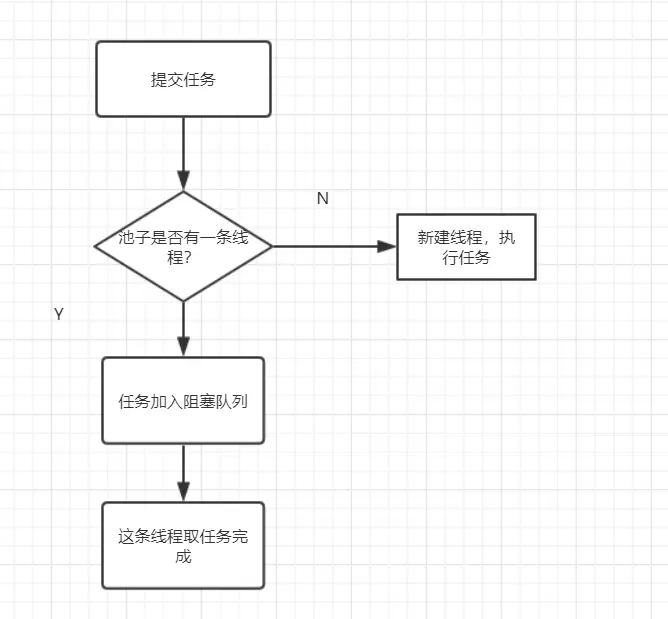
- 提交任务
- 线程池是否有一条线程在,如果没有,新建线程执行任务
- 如果有,讲任务加到阻塞队列
- 当前的唯一线程,从队列取任务,执行完一个,再继续取,一个人(一条线程)夜以继日地干活。
newScheduledThreadPool
public ScheduledThreadPoolExecutor(int corePoolSize) {super(corePoolSize, Integer.MAX_VALUE, 0, NANOSECONDS,new DelayedWorkQueue());
}
线程池特点
- 最大线程数为Integer.MAX_VALUE
- 阻塞队列是DelayedWorkQueue
- keepAliveTime为0
- scheduleAtFixedRate() :按某种速率周期执行
- scheduleWithFixedDelay():在某个延迟后执行
工作机制
- 添加一个任务
- 线程池中的线程从 DelayQueue 中取任务
- 线程从 DelayQueue 中获取 time 大于等于当前时间的task
- 执行完后修改这个 task 的 time 为下次被执行的时间
- 这个 task 放回DelayQueue队列中
线程池的提交方式
execute方式提交
不关心返回值的,直接往线程池里面扔任务就完事
public class JDKThreadPoolExecutorTest {public static void main(String[] args) throws Exception {ThreadPoolExecutor executor = new ThreadPoolExecutor(2, 5, 60, TimeUnit.SECONDS, new LinkedBlockingQueue<>(10));//execute(Runnable command)方法。没有返回值executor.execute(() -> {System.out.println("MJW");});Thread.currentThread().join();}
}
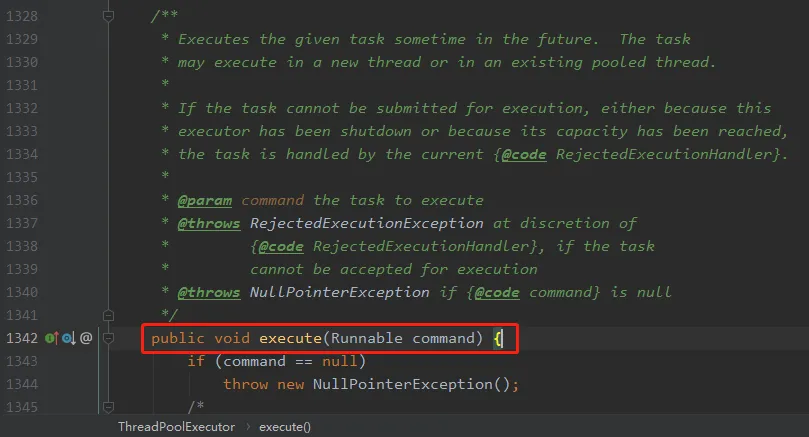
可以看一下 execute 方法,接受一个 Runnable 方法,返回类型是 void:
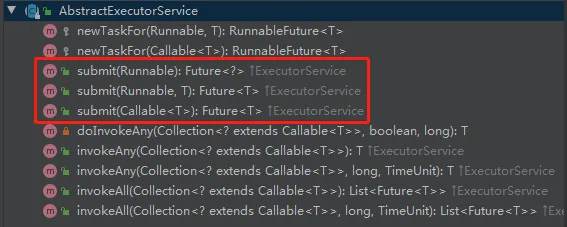
submit方法提交
有三种 submit。这三种按照提交任务的类型来算分为两个类型。
- 提交执行 Runnable 类型的任务。
- 提交执行 Callable 类型的任务。
Callable 类型的任务是怎么执行的
public static void main(String[] args) throws Exception {ThreadPoolExecutor executor = new ThreadPoolExecutor(2, 5, 60, TimeUnit.SECONDS, new LinkedBlockingQueue<>(10));Future<String> future = executor.submit(() -> {System.out.println("MJW");return "这次一定!";});System.out.println("future的内容:" + future.get());Thread.currentThread().join();
}
输出结果如下:
接下来再说说 submit 的任务为 Runable 类型的情况。
这个时候有两个重载的形式:
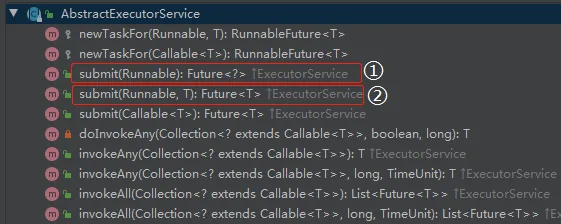
① 和 ② 的方法的区别就是 ② 再扔进去一个泛型 T
首先验证标号为 ① 的方法
public class JDKThreadPoolExecutorTest {public static void main(String[] args) throws Exception {ThreadPoolExecutor executor = new ThreadPoolExecutor(2, 5, 60, TimeUnit.SECONDS, new LinkedBlockingQueue<>(10));Future<?> future = executor.submit(() -> {System.out.println("MJW");});System.out.println("future的内容:" + future.get());Thread.currentThread().join();}
}
可以看到,确实是调用的标号为 ① 的方法:
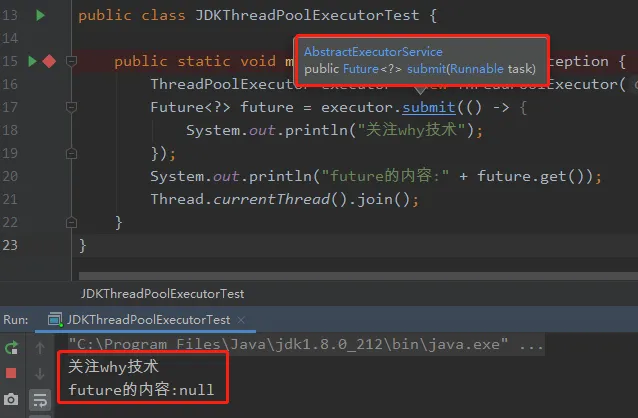
我们也可以看到 future.get() 方法的返回值为 null,那为什么不使用 execute 方式来提交任务呢,还不需要构建一个寂寞的返回值,徒增无用对象。
接下来,我们看看标号为 ② 的方法是怎么用的:
public class JDKThreadPoolExecutorTest {public static void main(String[] args) throws Exception {ThreadPoolExecutor executor = new ThreadPoolExecutor(2, 5, 60, TimeUnit.SECONDS, new LinkedBlockingQueue<>(10));AtomicInteger atomicInteger = new AtomicInteger();Future<AtomicInteger> future = executor.submit(() -> {System.out.println("MJW");//在这里进行计算逻辑atomicInteger.set(5201314);}, atomicInteger);System.out.println("future的内容:" + future.get());Thread.currentThread().join();}
}
可以看到改造之后,确实是调用了标号为 ② 的方法:
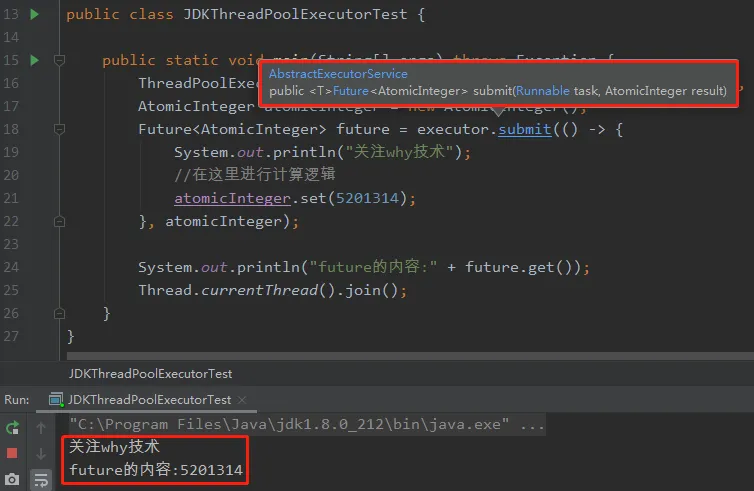
future.get() 方法的输出值也是异步任务中我们经过计算后得出的 5201314。
从上面的代码我们可以看出,当我们想要返回值的时候,都需要调用下面的这个 get() 方法:
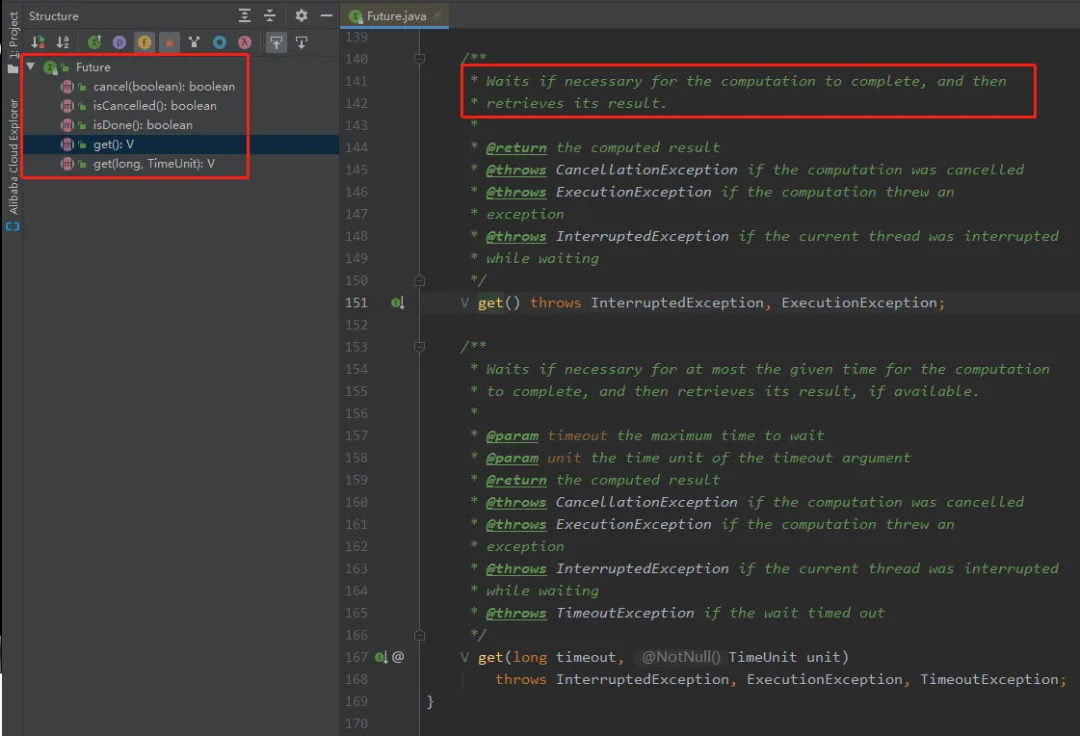
而从这个方法的描述可以看出,这是一个阻塞方法。拿不到值就在那里等着。当然,还有一个带超时时间的 get 方法,等指定时间后就不等了。
所以总结一下这种场景下返回的 Future 的不足之处:
- 只有主动调用 get 方法去获取值,但是有可能值还没准备好,就阻塞等待。
- 任务处理过程中出现异常会把异常隐藏,封装到 Future 里面去,只有调用 get 方法的时候才知道异常了。
文献:https://mp.weixin.qq.com/s/dhJ78uzAgIGchErw-5VL3A
项目中使用的线程池
目前我们项目中是使用的@Async来实现的
@Async是Spring框架4.0版本中新增的功能。用于异步执行方法
首先想要使用@Async注解需要在启动类上添加@EnableAsync注解
先写一段测试代码看看执行情况。
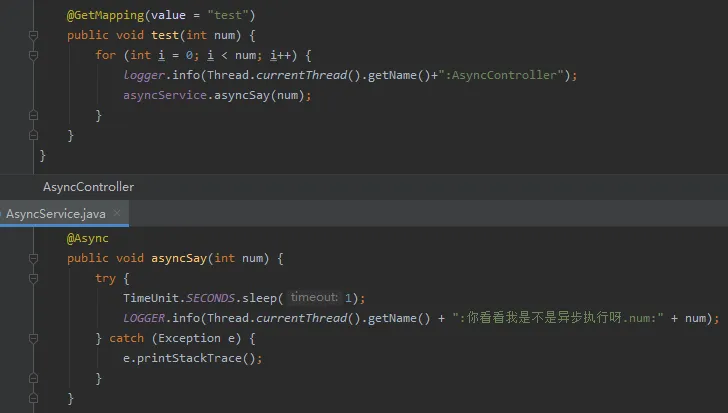
从日志我们可以看出任务是异步执行的,并且我们可以看到 taks 最多就到 8
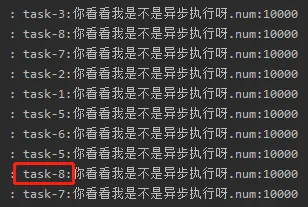
从这里我们可以分析线程池的核心线程数的配置可能是8,任务队列的大小可能很大,我们改变下请求次数
通过 jconsole 观察堆内存使用情况:
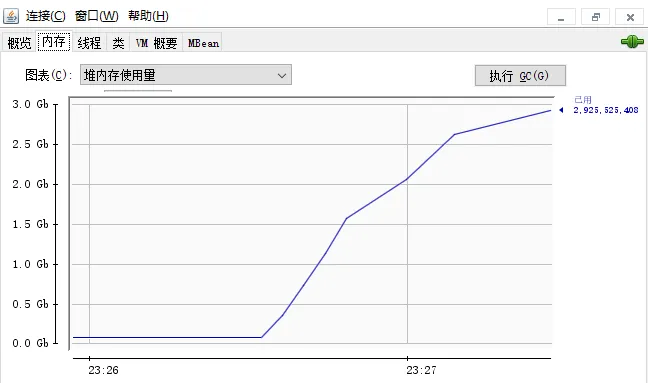
那叫一个飙升啊,点击【执行GC】按钮也没有任何缓解。
也从侧面证明了:任务有可能都进队列里面排队了,导致内存飙升。
虽然,我现在还不知道它的配置是什么,但是经过刚刚的黑盒测试,我有正当的理由怀疑:
默认的线程池有导致内存溢出的风险。
源码
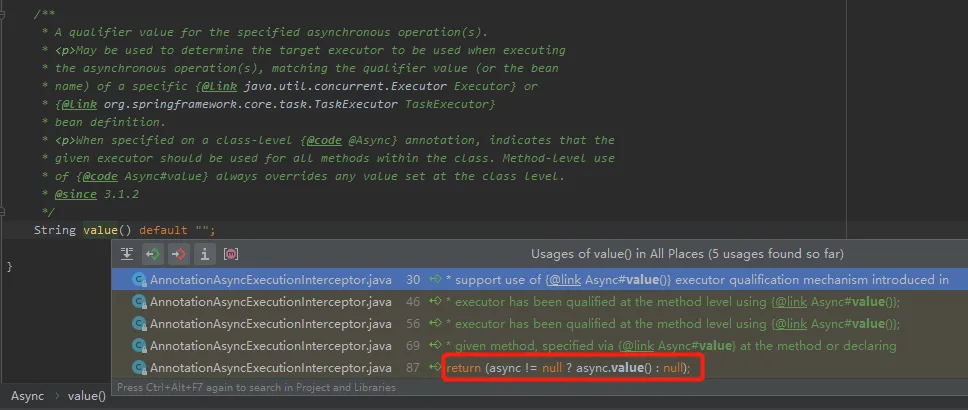
打上断点,发起调用之后,顺着断点往下调试,就会来到这个地方:
org.springframework.aop.interceptor.AsyncExecutionAspectSupport#determineAsyncExecutor
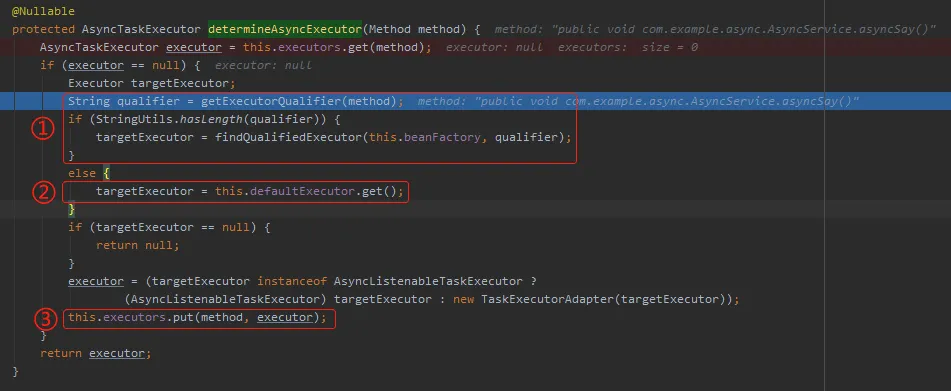
这个代码结构非常的清晰。
编号为 ① 的地方,是获取对应方法上的 @Async 注解的 value 值。这个值其实就是 bean 名称,如果不为空则从 Spring 容器中获取对应的 bean。
如果 value 是没有值的,也就是我们 Demo 的这种情况,会走到编号为 ② 的地方。
这个地方就是我要找的默认的线程池。
最后,不论是默认的线程池还是 Spring 容器中我们自定义的线程池。
都会以方法为维度,在 map 中维护方法和线程池的映射关系。
也就是编号为 ③ 的这一步,代码中的 executors 就是一个 map
我们要找的东西,是编号为 ② 的这个地方的逻辑,最终会调试到这个地方来:
org.springframework.aop.interceptor.AsyncExecutionAspectSupport#getDefaultExecutor
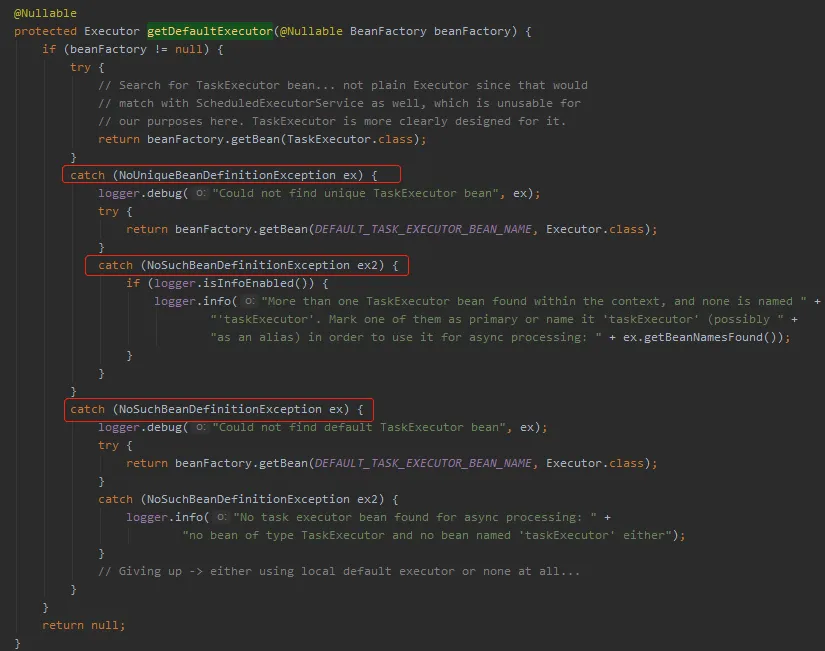
这个代码就有点意思了,就是从 BeanFactory 里面获取一个默认的线程池相关的 Bean 出来。流程很简单
最终获取到的线程池
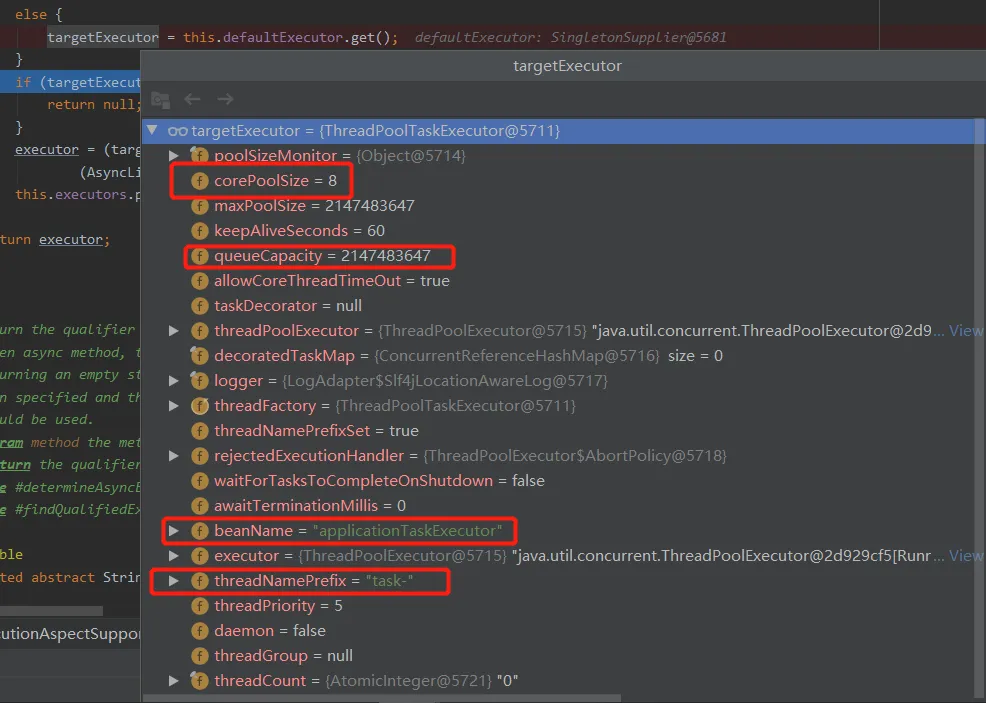
我们可以看到核心线程数配置是 8 ,队列长度应该是 Integer.MAX_VALUE
由此可见使用@Async默认的线程池可能导致OOM
根据beanName找到的bean
org.springframework.boot.autoconfigure.task.TaskExecutionAutoConfiguration
@Async 注解的 value
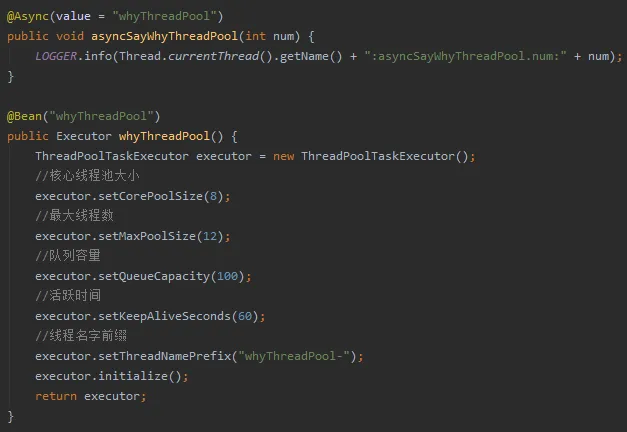
接下来我们看看 @Async 注解的 value 属性是干什么的。
我把 Demo 程序修改为这样:
再次跑起来,跑到这个断点的地方,就和我们默认的情况不一样了,这个时候 qualifier 有值了: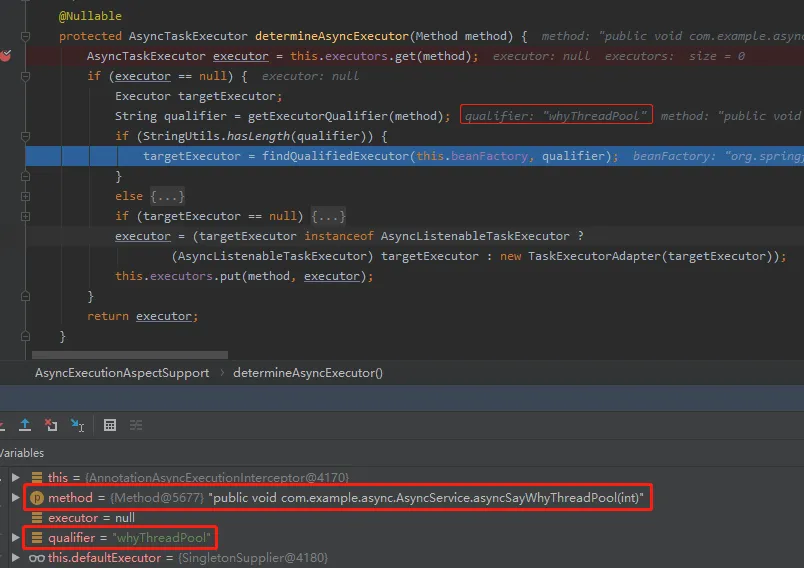
接下来就是去 beanFactory 里面拿名字为 whyThreadPool 的 bean 了。
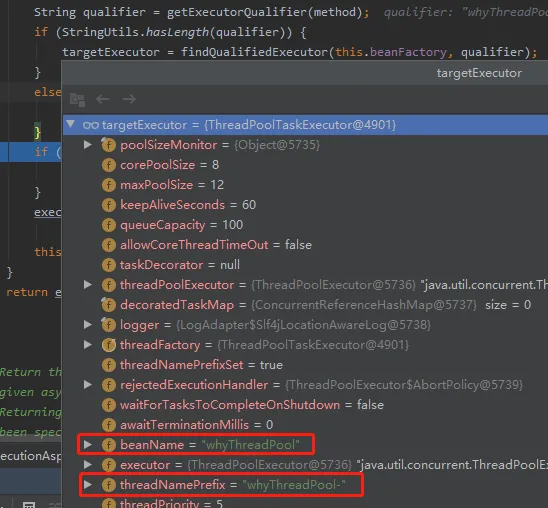
最后,拿出来的线程池就是我自定义的这个线程池:
文献:https://mp.weixin.qq.com/s__biz=Mzg3NjU3NTkwMQ==&mid=2247522594&idx=1&sn=0ad582443ed8723d8060ce00924f4456&scene=21#wechat_redirect