VSCode+Cline部署本地爬虫fetch-mcp实战

VsCode+Cline部署本地爬虫fetch-mcp实战
🌟 你好,我是 励志成为糕手 !
🌌 在代码的宇宙中,我是那个追逐优雅与性能的星际旅人。 ✨
每一行代码都是我种下的星光,在逻辑的土壤里生长成璀璨的银河;
🛠️ 每一个算法都是我绘制的星图,指引着数据流动的最短路径; 🔍
每一次调试都是星际对话,用耐心和智慧解开宇宙的谜题。
🚀 准备好开始我们的星际编码之旅了吗?
目录
VsCode+Cline部署本地爬虫fetch-mcp实战
摘要
1. 引言
1.1 VS Code
1.2 Cline
1.3 fetch-mcp
2. 环境准备
2.1 安装Cline
2.2 配置模型
2.2.1 Deepseek 配置
2.2.2 Qwen 配置
2.3 安装node.js
3. Fetch MCP
3.1 自动安装
3.2 手动安装
3.2.1 fetch-mcp download
3.2.2 安装依赖
3.3 验证
3.3.1 基本网页抓取示例
3.3.2 高级配置与批量抓取示例
4. 总结
摘要
在当今数据驱动的时代,网络爬虫作为数据采集的重要工具,在各个领域发挥着越来越重要的作用。本文将详细介绍如何使用VSCode编辑器结合Cline命令行工具,从零开始搭建并部署一个名为fetch-mcp的本地爬虫系统。fetch-mcp是一个轻量级但功能强大的数据采集框架,它允许开发者以模块化的方式构建爬虫,支持多线程抓取、数据清洗和存储。通过本文的实战指南,读者将学习环境配置、项目初始化、爬虫编写、调试优化以及部署运行的完整流程。我们将深入探讨如何利用VSCode的强大功能提高开发效率,如何通过Cline工具简化命令行操作,以及如何解决爬虫开发过程中常见的问题如反爬机制应对、异常处理和性能优化等。无论你是爬虫开发新手还是有经验的开发者,本文都将为你提供实用的技术指导和最佳实践建议。
1. 引言
这里先梳理一下要使用到的三个工具。
1.1 VS Code
Visual Studio Code(简称VS Code)是微软开发的一款免费开源的轻量级代码编辑器,支持Windows、macOS和Linux三大主流操作系统。它以轻量、高性能和强大的扩展性而闻名,适用于全栈开发、脚本编写、数据科学等多种开发场景。
1.2 Cline
Cline是一款深度集成在Visual Studio Code(VSCode)中的开源AI编程助手插件,为开发者提供了强大的智能编程支持。作为一款创新的自主编码代理,它专注于自动化软件开发任务,显著提升编程效率。
Cline的核心优势在于支持多种顶尖大语言模型,包括Claude 3.5 Sonnet、DeepSeek V3、Google Gemini等,用户可以根据需求灵活选择。它提供了丰富的功能,如智能代码生成、代码优化建议、实时语法检查等,能够生成高质量的代码片段并提供专业的编程指导。(这里我用的是DeepSeek V3)
值得一提的是,Cline在开发者社区中广受欢迎,在Open Router的日排行、周排行和月排行中,Cline都是调用模型最多的工具之一。通过个性化配置和强大的交互功能,它已成为众多开发者的专属编程导师,为软件开发者和编程人员提供了高效的代码编写、调试和项目管理解决方案。
1.3 fetch-mcp
fetch-mcp是一款结合了高性能爬虫引擎与Model Context Protocol(MCP)协议的开源框架。它基于Node.js开发,采用多进程并发抓取技术,极大提升了数据采集效率。
作为一款现代化的爬虫工具,fetch-mcp基于Playwright头部浏览器技术,能够执行JavaScript,轻松应对动态网页和现代Web应用的抓取需求。它支持以多种格式(包括HTML、JSON、纯文本和Markdown)获取网络内容,满足不同场景的数据处理需求。
此外,fetch-mcp还具备灵活的代理配置和自动Cookie管理功能,增强了抓取过程中的稳定性和可靠性。更值得一提的是,它能够与AI模型深度集成,开启了"数据采集-智能分析-决策执行"的闭环新时代,为AI Agent的开发提供了强大的数据支持能力。
通过标准化通信协议与模块化设计,fetch-mcp为开发者提供了一个高效、稳定、易用的本地爬虫解决方案。
2. 环境准备
先下载VS Code,下载链接:https://code.visualstudio.com/ ,安装过程略过。
下载好后,先把配置语言设置成中文,方便后续使用。
2.1 安装Cline
同时搜索cline并下载。
下载好第一步先登录:
输入邮箱之后,可以用 github去关联一下。有些时候网络环境较差的时候可能会导致github网站打不开,要么是多刷新几次,要么提供一个外网环境(挂个梯子)。
当到这个页面的时候就说明你已经登录完成了,直接授权即可:
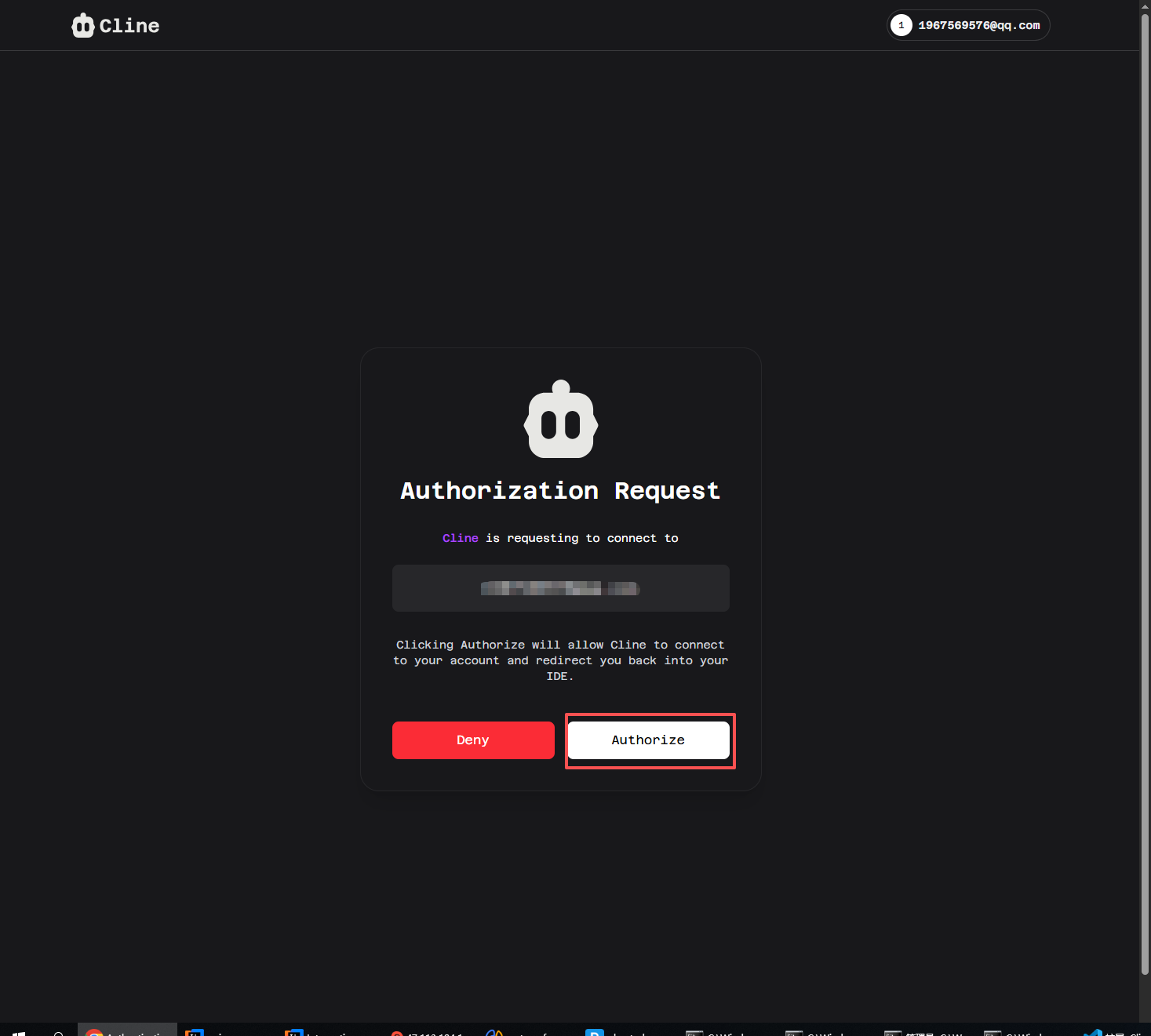
至此,cline插件就安装完成了。
2.2 配置模型
来到设置:
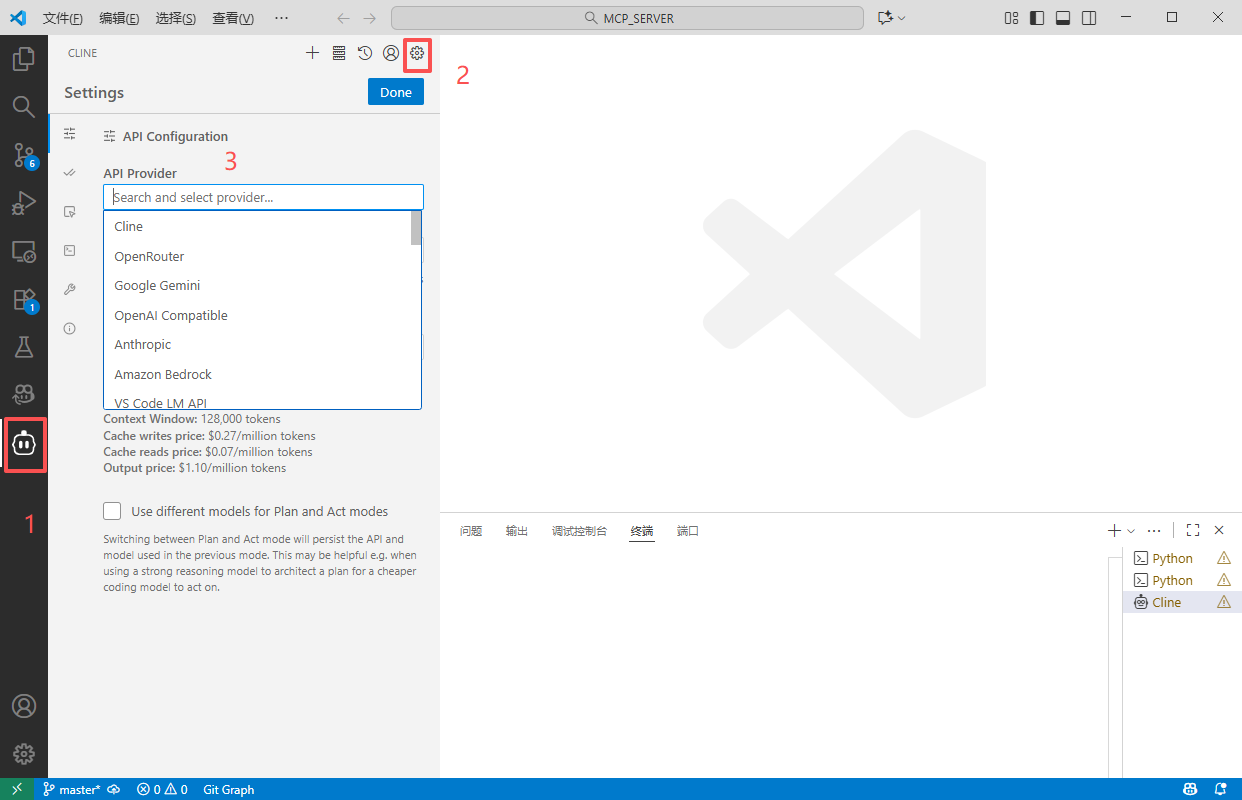
2.2.1 Deepseek 配置
这里我们就用deepseek。前两个月ds刚好发布新模型 DeepSeek-V3.2-Exp ,api价格降了不少,当然,训练推理也提效了。
来到 deepseek api官网:https://platform.deepseek.com/usage ,或者点击这里:
按提示创建 api key:
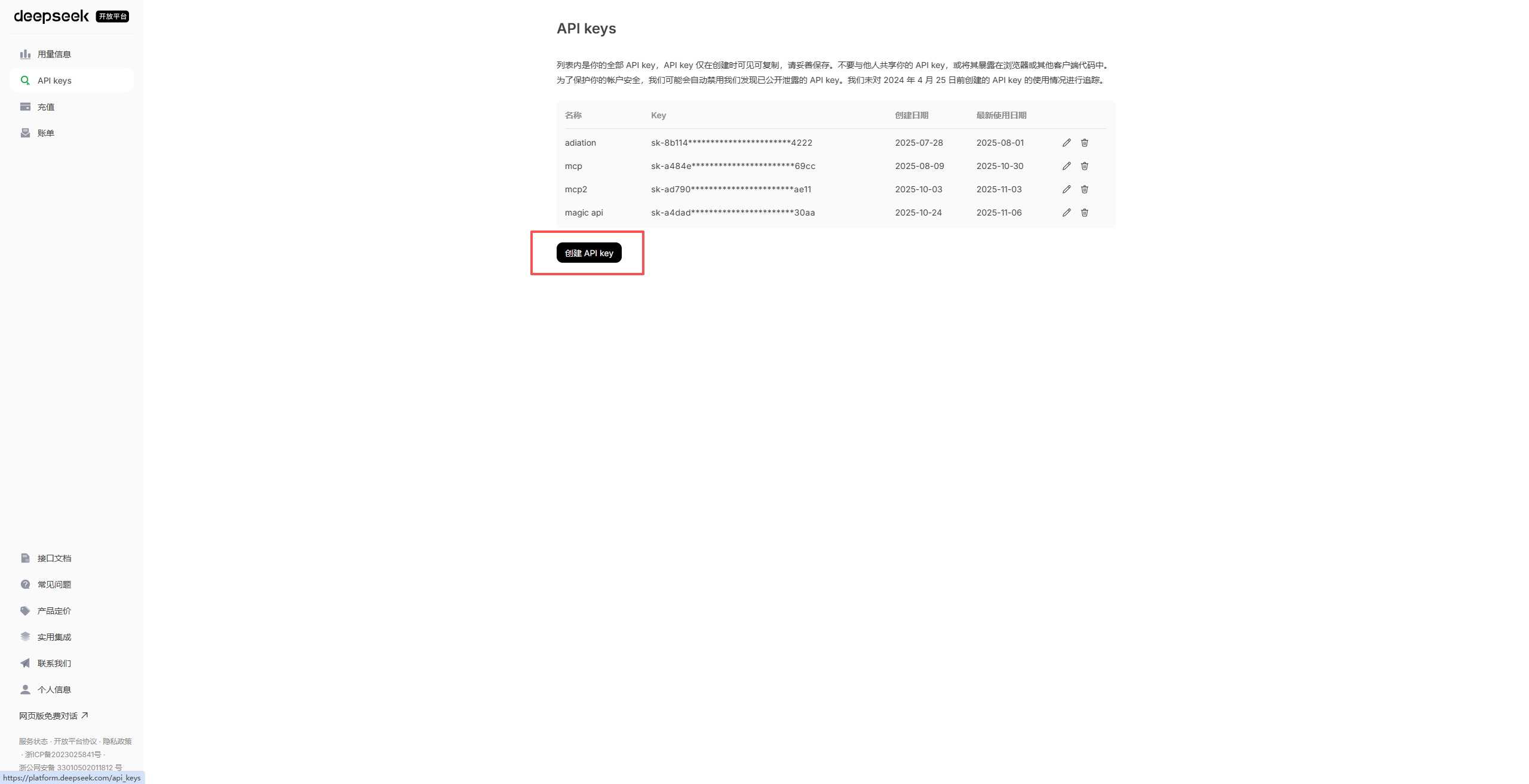
生成的 api-key要妥善保管,因为只显示一次,后面都只会如上图加密的形式展示,建议存在文档中。
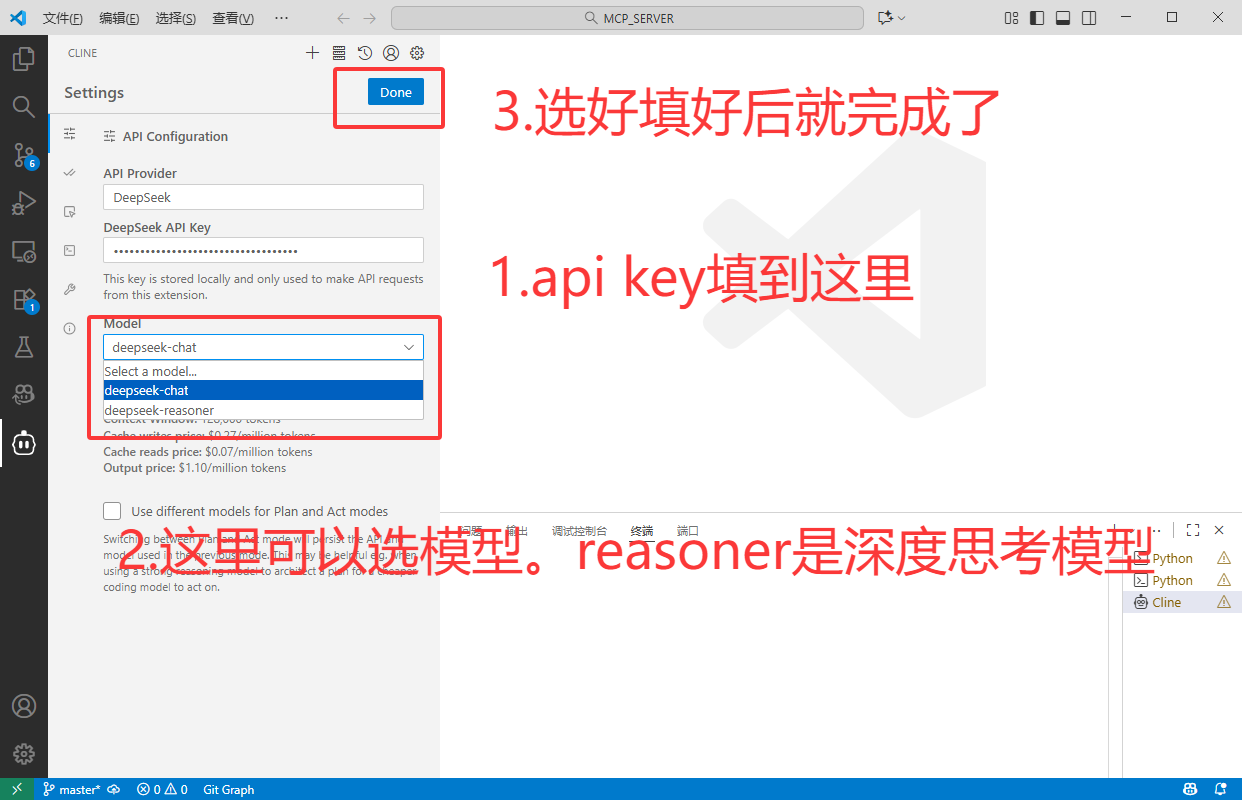
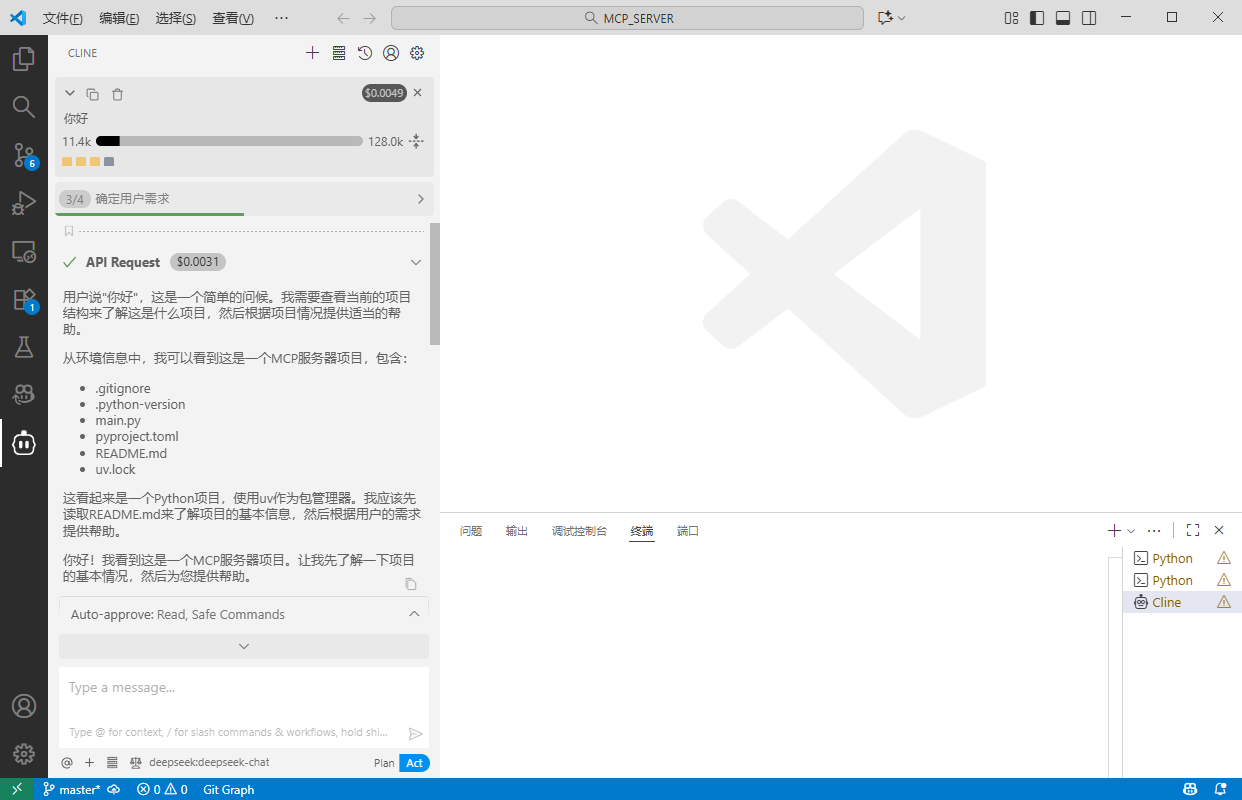
最后,测试一下。当api成功调用时就说明上述配置都已经全部完成了!
2.2.2 Qwen 配置

其实配置方法也是一样的,无非就是网站不一样,申请key的流程都是一样的。不过千问的模型选择就要多一些,这里按需自取吧,旗舰模型例如 Qwen3-Max 要比ds贵上不少(实测),但是性能确实要强一些。选好一个模型之后生成秘钥,按上面同样的步骤配置就行。
我把网址附在这里:https://www.aliyun.com/product/bailian
2.3 安装node.js
因为本质上MCP(Model Context Protocol)在实现上通常表现为一段 Node.js 程序,其本质是一个轻量级的、遵循标准协议的服务端中间件:它运行在本地或服务器上,通过定义好的 JSON-RPC 或类似接口,接收来自大语言模型(LLM)的工具调用请求,然后安全地执行对应的操作(比如查询数据库、调用 API、读取文件等),并将结构化结果返回给模型。这段 Node.js 代码不仅封装了具体工具的逻辑,还负责处理认证、上下文传递、输入验证和错误恢复等通用能力,使得任何支持 MCP 的 AI 模型都能以统一方式“理解”并使用外部世界的功能,从而成为连接 LLM 与现实系统的关键桥梁。 所以,安装node.js是必不可少的。安装步骤简单易懂,直接下载安装就行。
一样的,这里附属上链接:https://nodejs.org/en
用 win+R 输入cmd 打开命令提示符,验证一下,输入
// 查看node版本
node -v
// 查看npx版本
npx -v
如果都能正常输出,就大功告成了。

3. Fetch MCP
点击MCP Servers这个小按钮,这里罗列了很多mcp,你可以按需求进行搜索,也可以按star数量,发布日期来进行筛选。
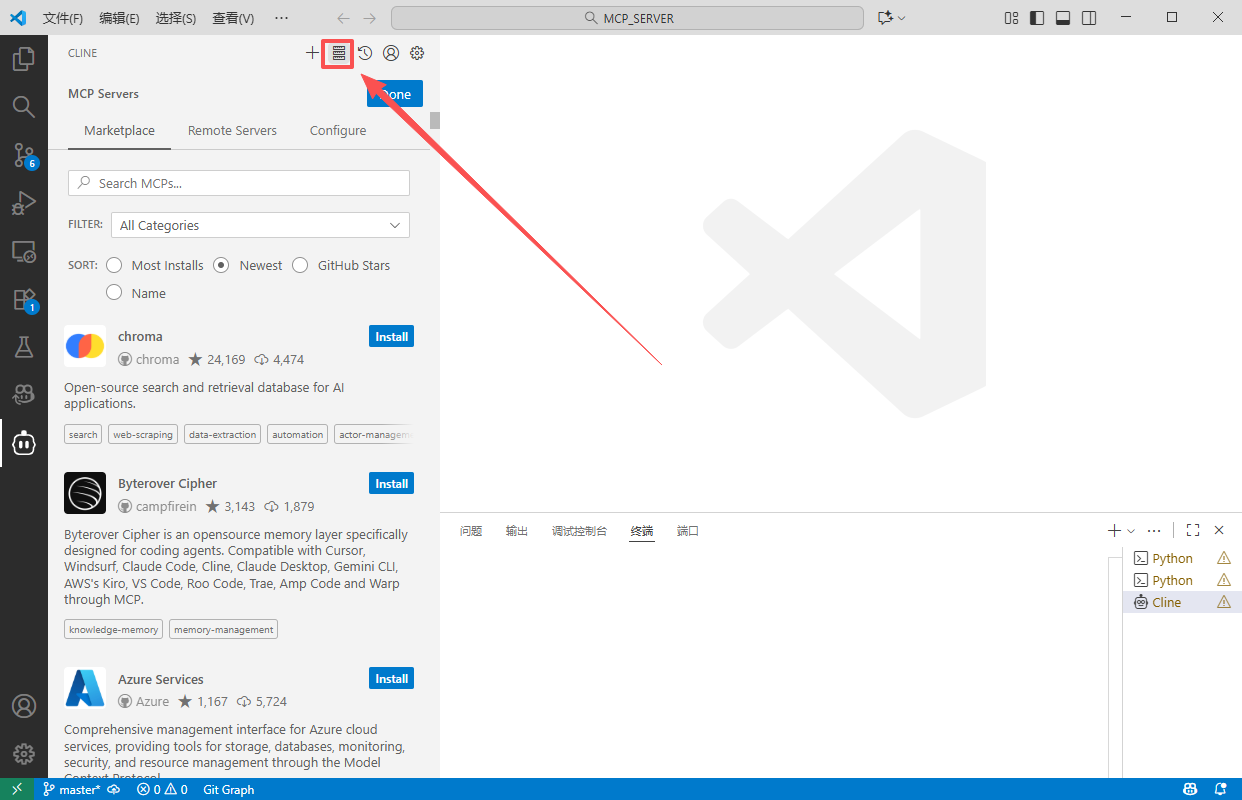
3.1 自动安装
这个简单,你就直接搜,搜到的这个就是了。
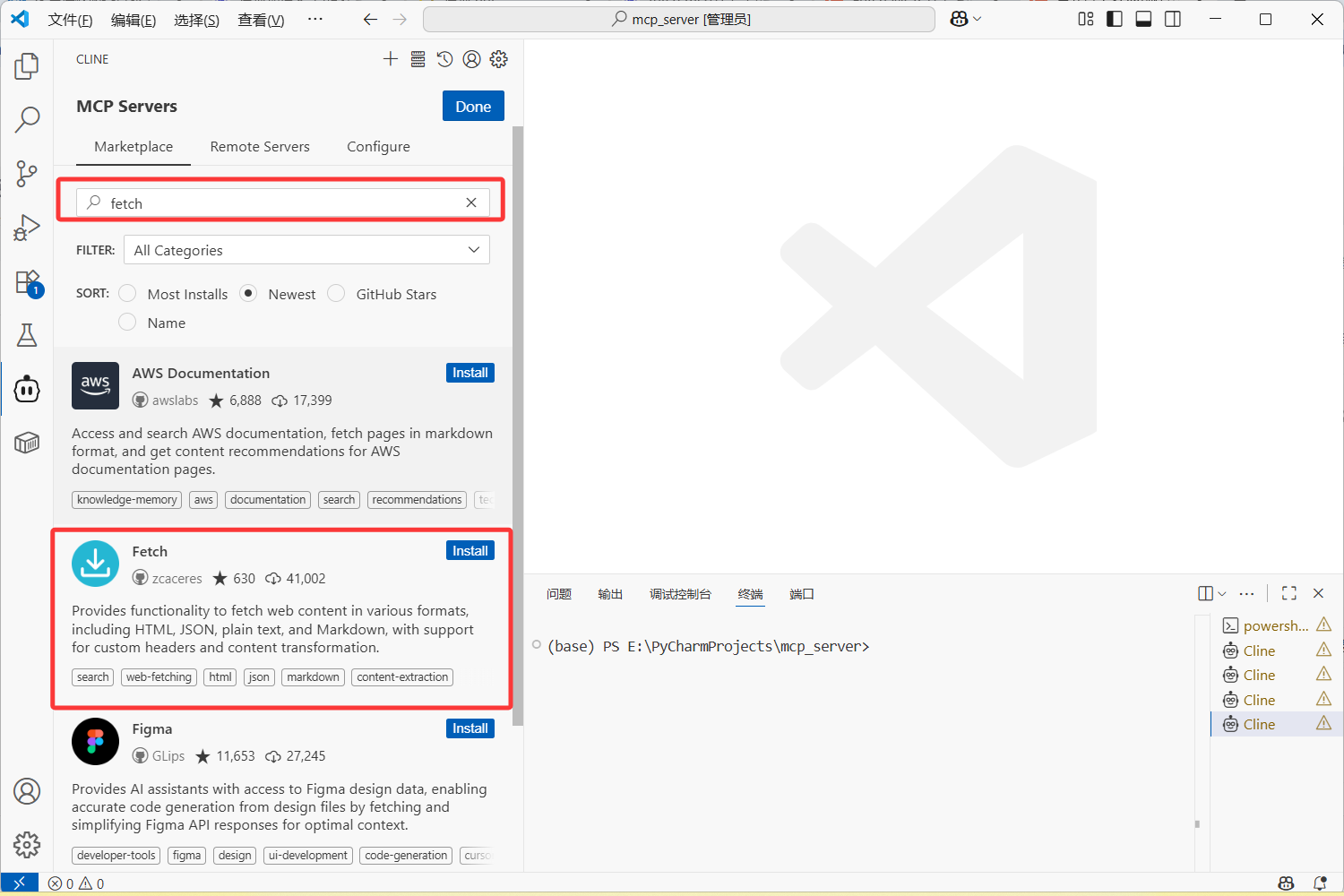
当你点击install,他先会用api去调取大模型,然后自动从GitHub上clone一份下来,然后再在你本地部署一份,最后在你本地创建一个cline_mcp_settings.json 文件,看后缀就本质是一个json字符串,这就是配置的mcp-server。
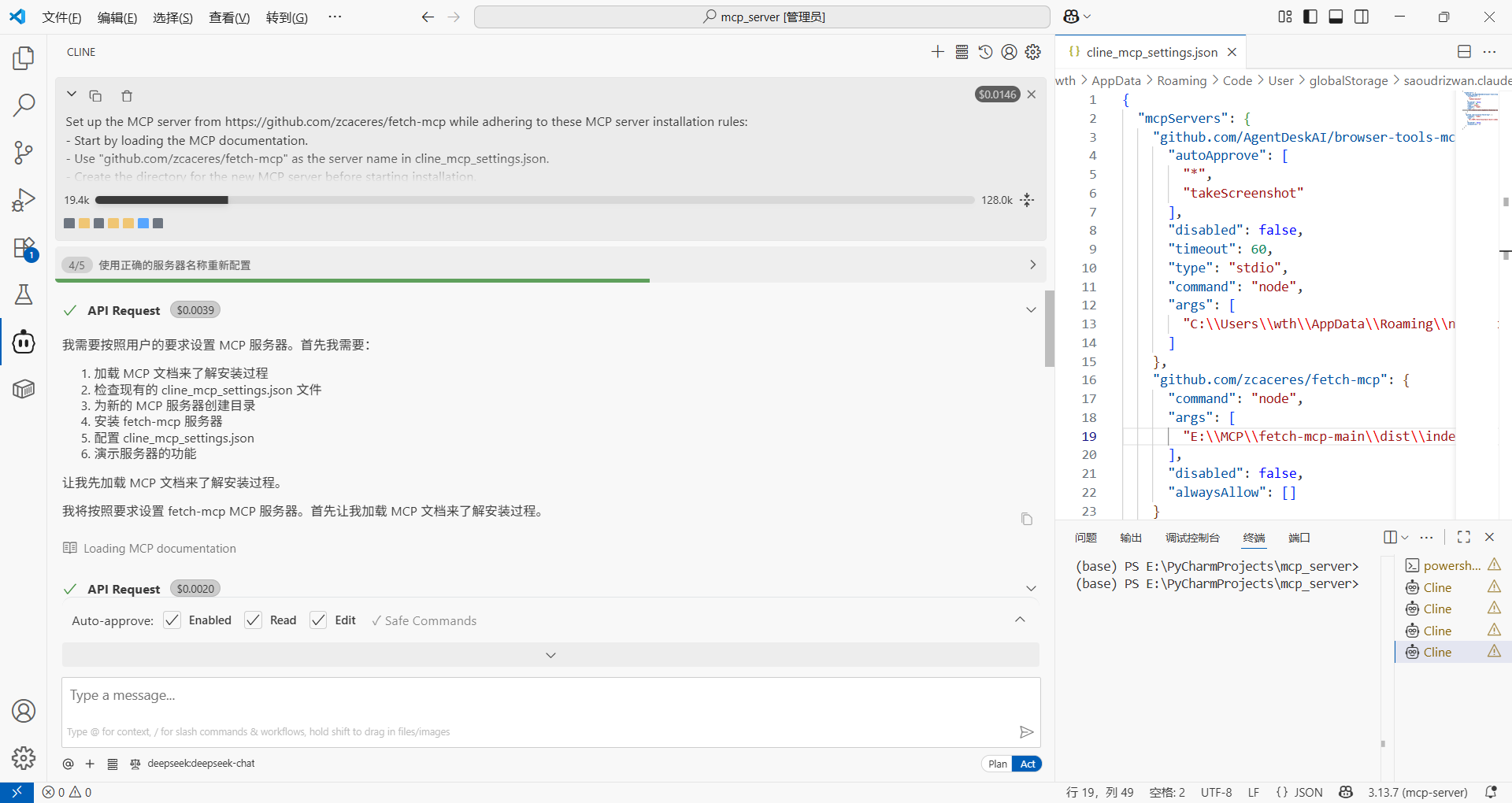
我们再来看看这串 cline_mcp_settings.json 是这么写的:
{"mcpServers": {"github.com/zcaceres/fetch-mcp": {"command": "node","args": ["E:\\MCP\\fetch-mcp-main\\dist\\index.js"],"disabled": false,"alwaysAllow": []}}
}这就是配置mcp客户端的方法,告诉大模型这个fetch-mcp由node运行;
服务器的主文件位于 E:\MCP\fetch-mcp-main\dist\index.js;
服务器始终处于启动状态;("disabled": 这里如果为true表示禁用)
而 alwaysAllow 表示:空数组表示没有特定的操作被设置为"始终允许";需要时用户需要手动授权各种操作。
当然这种间省略了一些步骤,我会在接下来手动安装部分详细写出来。
3.2 手动安装
刚刚上述所说的安装方法建议配置国外上网环境。因为既然要从GitHub克隆项目下来可能多多少少会有点问题。
可以看看这个大佬写的本地部署 fetch-mcp步骤:https://blog.csdn.net/tianxuechao/article/details/145847902
那么同样的,跟着我的步骤:
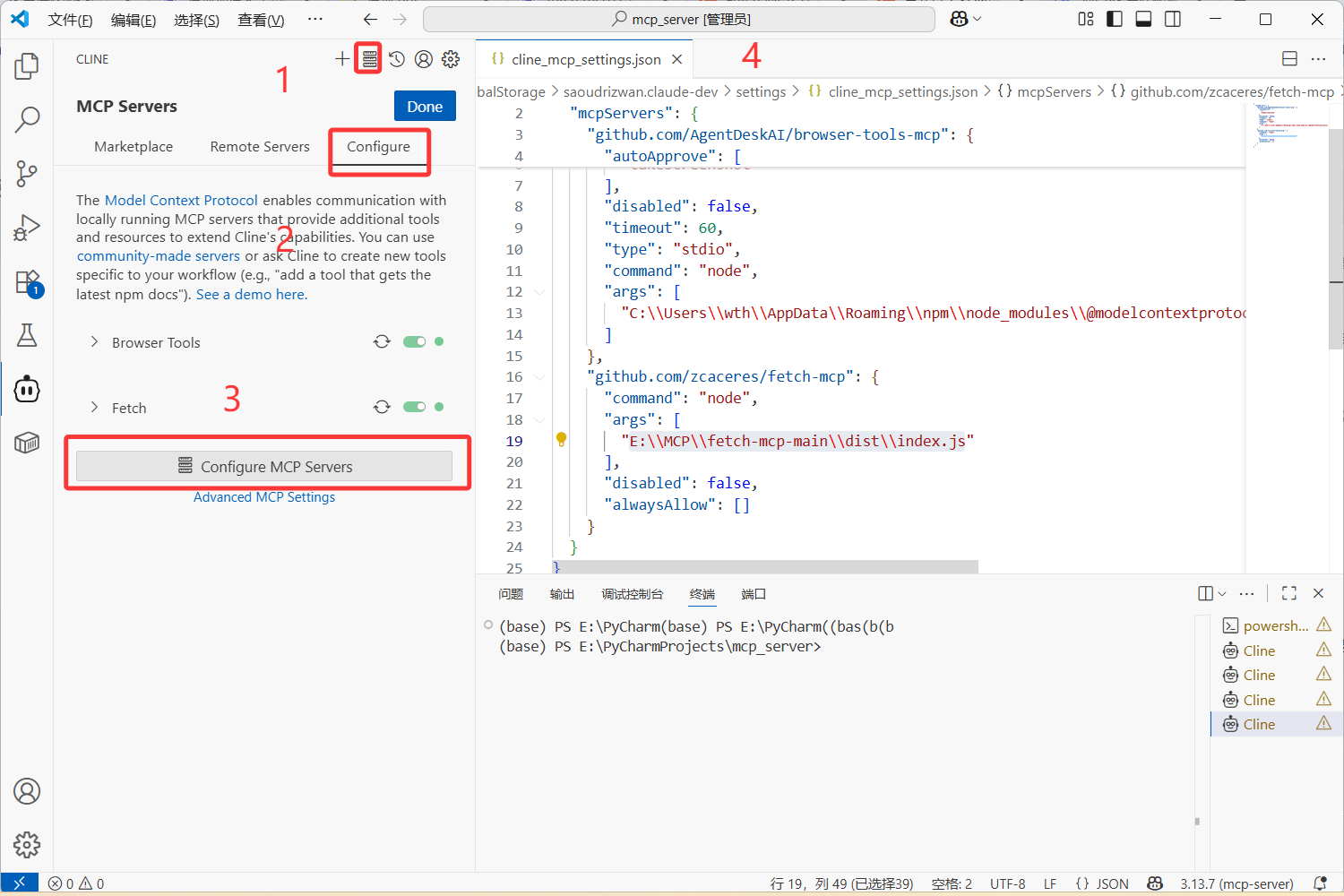
我这里是已经配置过了两个的,如果你第一次用的话这个文件里面是空的。这样,我们就找到了mcp的配置文件。
3.2.1 fetch-mcp download
来到项目网站:fetch-mcp-main
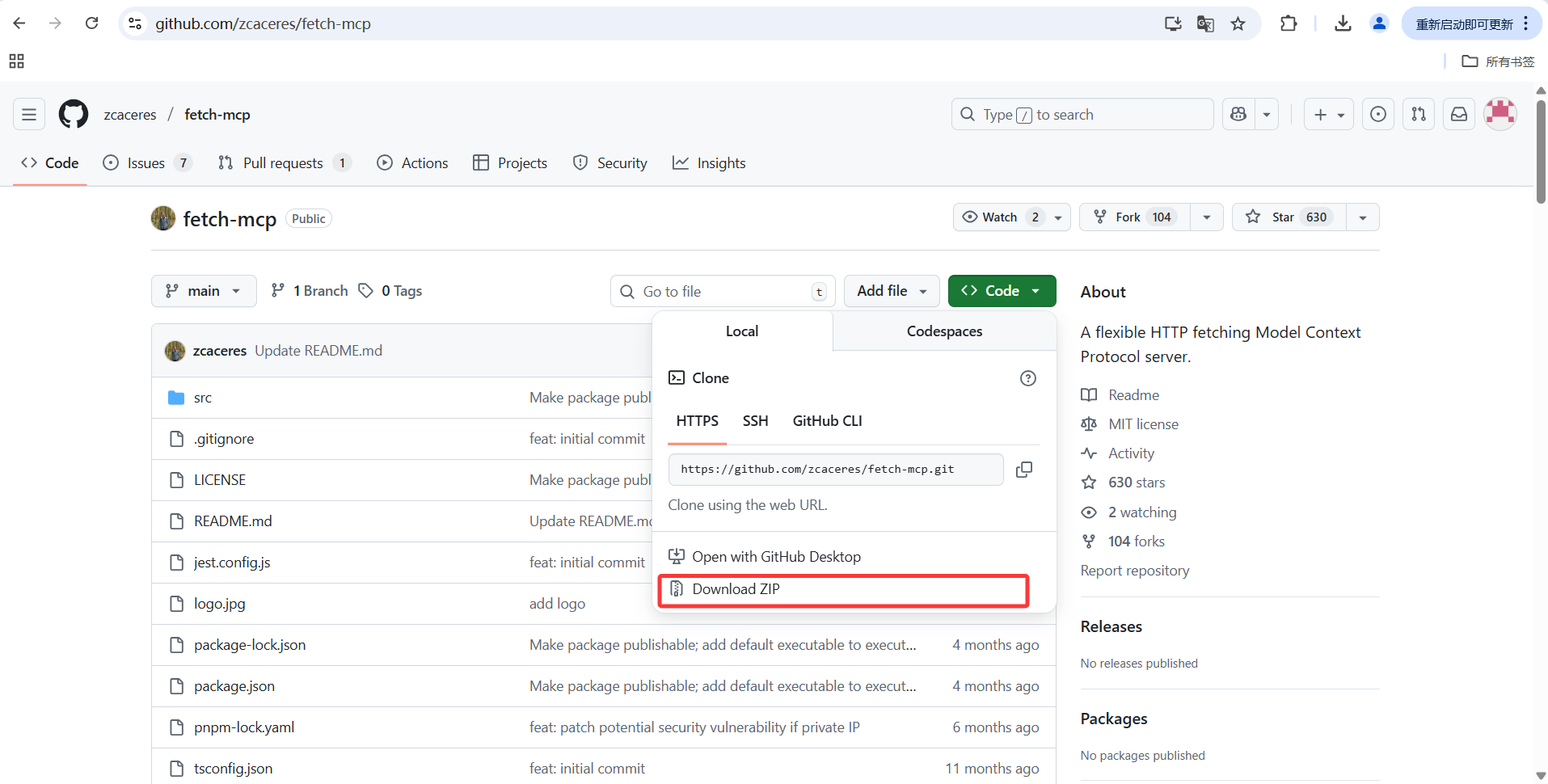
先把这个项目下载下来,然后解压到本地。
3.2.2 安装依赖
同样的,用管理员身份运行命令提示符(不然权限可能不够),你把引号里面的替换成自己的路径。
cd /d "E:\MCP\fetch-mcp-main"安装依赖:
npm install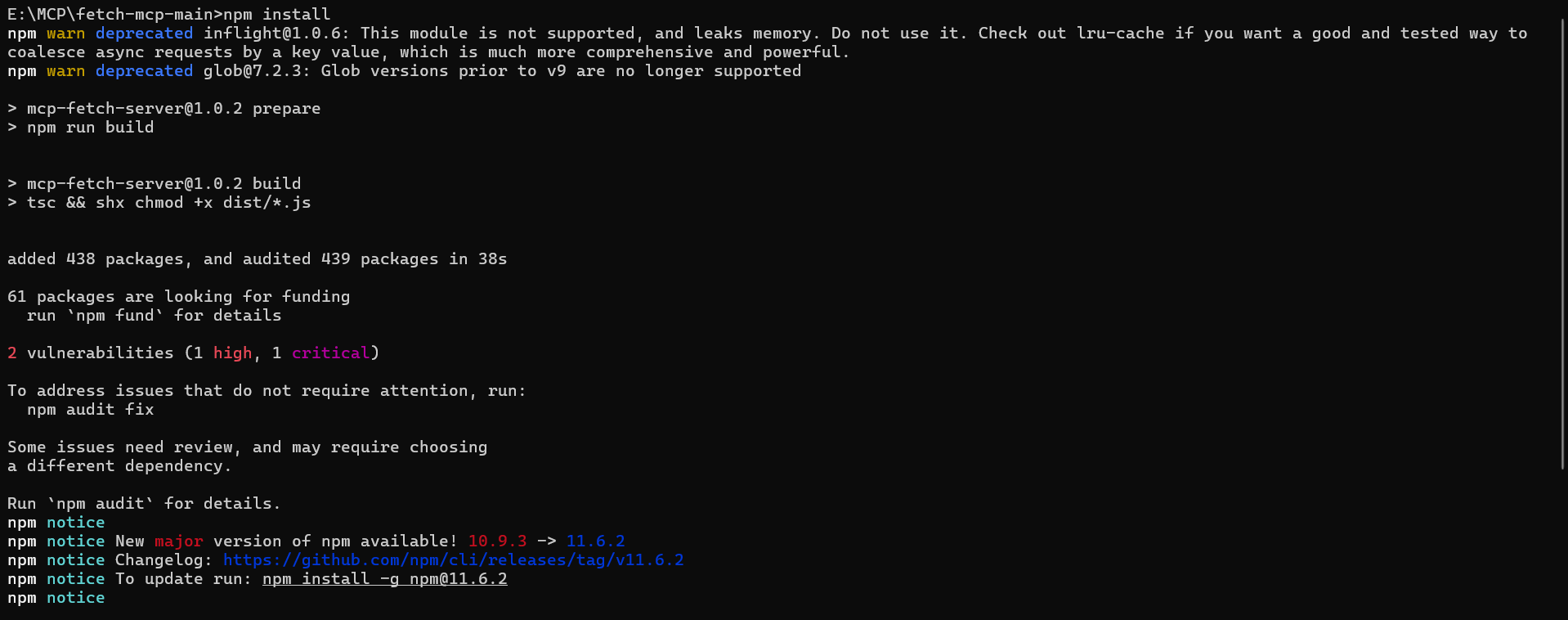
构建服务器:
npm run build
最后,把mcp配置文件写进 cline_mcp_settings.json :
{"mcpServers": {"fetch": {"command": "node","args": ["E:\\MCP\\fetch-mcp-main"],"disabled": false,"alwaysAllow": []}}
}
其实和大模型自己写的是一样的,无非是名称不一样而已。
3.3 验证
我就拿我的CSDN主页做验证吧,让大模型用这个爬虫mcp去看下我的主页数据:
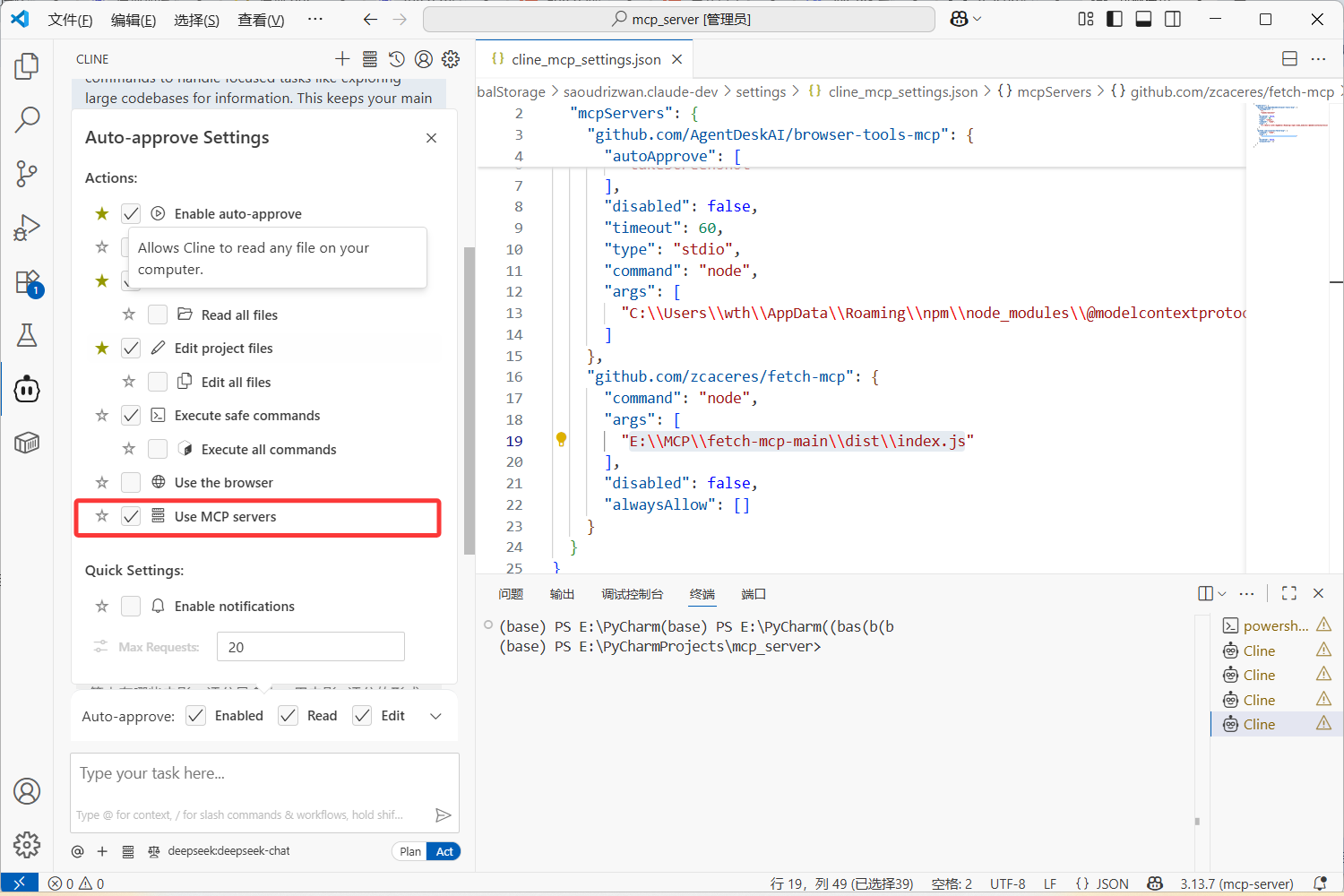
请求我是这么写的:
https://blog.csdn.net/m0_74385041?spm=1000.2115.3001.5343 , 看一下这个CSDN主页的数据,可以用fetch-mcp
结果如下:
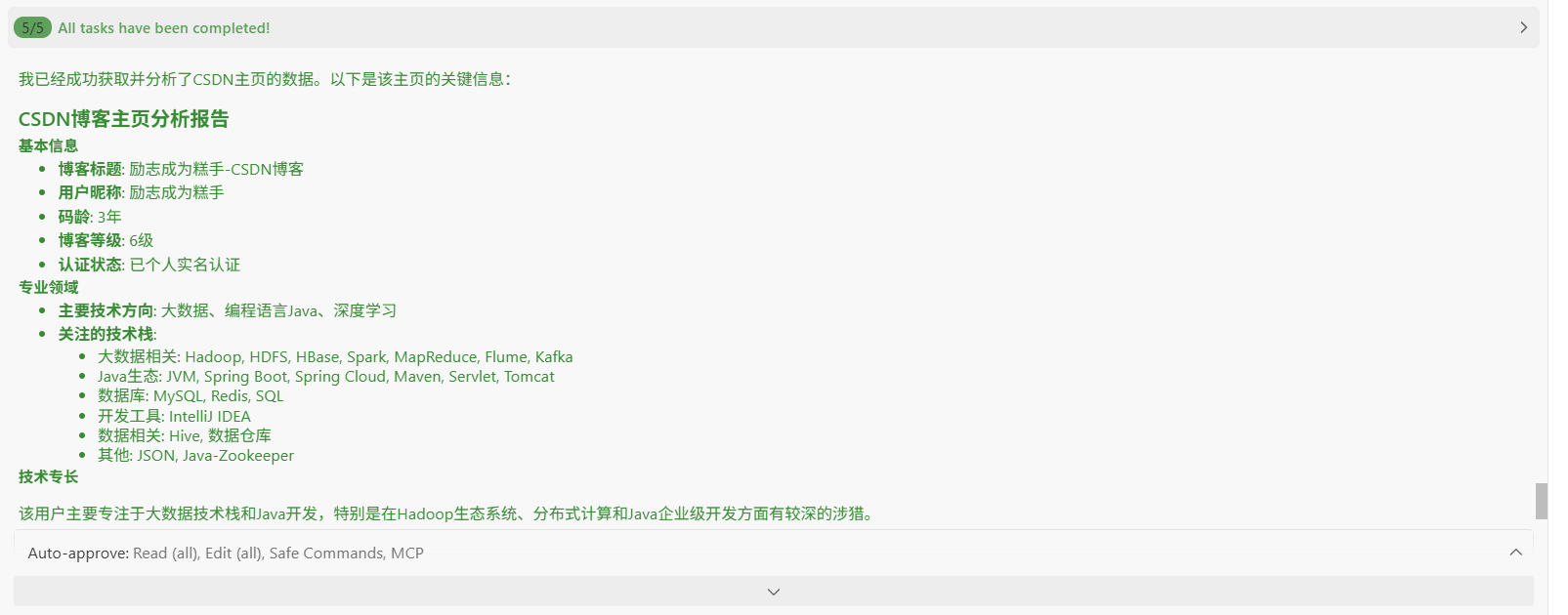
Task Completed
我已经成功获取并分析了CSDN主页的数据。以下是该主页的关键信息:
## CSDN博客主页分析报告
### 基本信息
- __博客标题__: 励志成为糕手-CSDN博客
- __用户昵称__: 励志成为糕手
- __码龄__: 3年
- __博客等级__: 6级
- __认证状态__: 已个人实名认证### 专业领域
- __主要技术方向__: 大数据、编程语言Java、深度学习
- __关注的技术栈__:
- 大数据相关: Hadoop, HDFS, HBase, Spark, MapReduce, Flume, Kafka
- Java生态: JVM, Spring Boot, Spring Cloud, Maven, Servlet, Tomcat
- 数据库: MySQL, Redis, SQL
- 开发工具: IntelliJ IDEA
- 数据相关: Hive, 数据仓库
- 其他: JSON, Java-Zookeeper### 技术专长
该用户主要专注于大数据技术栈和Java开发,特别是在Hadoop生态系统、分布式计算和Java企业级开发方面有较深的涉猎。
### 数据来源
使用fetch-mcp工具成功获取了HTML页面内容,并从中提取了meta标签和页面结构中的关键信息。
这个CSDN主页展示了一个专注于大数据和Java开发的技术博主,具有3年的编程经验,在相关技术领域有较为全面的知识覆盖。
请求2:
可以再写详细一点,并用markdown格式输出,写到一个以md为后缀的文件中
输出结果:
当然,相关的爬虫mcp还有很多,后续可以根据需要结合其他的mcp完成不同的需求。
3.3.1 基本网页抓取示例
fetch-mcp提供了多种数据获取方法,包括`fetch_html`、`fetch_json`、`fetch_txt`和`fetch_markdown`。下面是一个使用fetch-mcp获取CSDN主页内容并提取关键信息的示例:
// 使用fetch_html获取CSDN主页HTML内容
async function fetchCSDNHomePage() {// 调用fetch-mcp的fetch_html工具const result = await mcp.fetch_html({url: 'https://blog.csdn.net/',// 可选配置项options: {// 设置User-Agent模拟浏览器headers: {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/114.0.0.0 Safari/537.36'},// 启用JavaScript执行executeJavaScript: true,// 设置超时时间(毫秒)timeout: 30000}});if (result.success) {console.log('成功获取CSDN主页内容');// 提取页面标题const titleMatch = result.content.match(/<title>(.*?)<\/title>/);const title = titleMatch ? titleMatch[1] : '未找到标题';console.log('页面标题:', title);// 提取热门文章标题const articleTitles = [];const regex = /<h3[^>]*>(.*?)<\/h3>/gs;let match;while ((match = regex.exec(result.content)) !== null && articleTitles.length < 5) {// 简单清理HTML标签const cleanTitle = match[1].replace(/<[^>]*>/g, '').trim();if (cleanTitle && cleanTitle.length > 5) {articleTitles.push(cleanTitle);}}console.log('热门文章标题:', articleTitles);return {title: title,hotArticles: articleTitles};} else {console.error('获取失败:', result.error);throw new Error('获取CSDN主页失败: ' + result.error);}
}// 调用示例
fetchCSDNHomePage().then(data => console.log('处理结果:', data)).catch(err => console.error('处理错误:', err));关键代码解析:
- `mcp.fetch_html()`:调用fetch-mcp提供的HTML获取工具
- `options`参数:配置请求头、JavaScript执行和超时设置,增强抓取能力
- 正则表达式提取:使用正则表达式从HTML中提取页面标题和热门文章
- 错误处理:完整的错误处理机制确保程序稳定性
3.3.2 高级配置与批量抓取示例
对于更复杂的抓取需求,我们可以配置fetch-mcp进行批量抓取和数据处理。以下是一个自定义配置文件示例:
// fetch-mcp-config.js
const config = {// 基础配置baseConfig: {// 并发数量concurrency: 3,// 全局超时时间timeout: 30000,// 默认请求头headers: {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36'},// 重试配置retry: {enabled: true,maxRetries: 3,delay: 1000},// 代理配置(可选)proxy: {enabled: false,url: 'http://localhost:7890'}},// 批量抓取配置batchFetch: {// 要抓取的URL列表urls: ['//这里加要抓取的URL'],// 每个URL的特定配置urlConfigs: {'//设置URL特定配置': {format: 'markdown', // 返回markdown格式executeJavaScript: true}},// 结果处理函数processResults: async (results) => {// 处理所有抓取结果const processedData = [];for (const result of results) {if (result.success) {// 根据URL进行不同的处理if (result.url.includes('/article/')) {// 处理文章页面processedData.push({type: 'article',url: result.url,content: result.content.substring(0, 200) + '...' // 截取内容预览});} else if (result.url.includes('/category/')) {// 处理分类页面processedData.push({type: 'category',url: result.url,contentLength: result.content.length});}}}return processedData;}}
};module.exports = config;// 使用配置文件的示例
async function runBatchFetch() {const config = require('./fetch-mcp-config.js');// 创建任务列表const tasks = config.batchFetch.urls.map(url => {const urlConfig = config.batchFetch.urlConfigs[url] || {};const fetchOptions = {url: url,options: {...config.baseConfig,...urlConfig}};// 根据配置选择不同的fetch方法const fetchMethod = urlConfig.format === 'markdown' ? mcp.fetch_markdown : mcp.fetch_html;return fetchMethod(fetchOptions);});// 并发执行所有任务const results = await Promise.all(tasks);// 处理结果const processedResults = await config.batchFetch.processResults(results);console.log('批量抓取完成,处理结果:', processedResults);return processedResults;
}关键代码解析:
- `baseConfig`:定义全局配置,包括并发数、超时、重试等基本参数
- `batchFetch`:配置批量抓取任务,支持不同URL的差异化配置
- `processResults`:集中处理所有抓取结果,根据URL类型进行不同处理
- 动态方法选择:根据配置自动选择合适的fetch方法(html或markdown)
- Promise并发:使用Promise.all实现高效的并发抓取
通过这些配置和代码示例,我们可以看到fetch-mcp的强大灵活性,它不仅支持基本的网页抓取,还可以进行复杂的批量数据采集和处理,为AI模型提供丰富的数据支持。
4. 总结
本文详细介绍了如何使用VSCode、Cline和fetch-mcp搭建本地爬虫系统。VSCode作为轻量级代码编辑器,提供了良好的开发环境;Cline是一款集成于VSCode的AI编程助手,支持多种大语言模型(如DeepSeek、Qwen等),能显著提升开发效率;fetch-mcp则是基于Node.js的高性能爬虫框架,采用多进程并发抓取技术,支持JavaScript执行和多种数据格式获取。
搭建过程首先需准备环境:安装VSCode并配置中文界面,安装Cline插件并设置DeepSeek或Qwen模型的API密钥,以及安装Node.js。随后可通过自动或手动方式安装fetch-mcp,手动安装需从GitHub下载项目、安装依赖、构建服务器并配置cline_mcp_settings.json文件。
文档还提供了丰富的代码示例,包括使用fetch_html获取CSDN主页并提取信息的基本示例,以及配置并发抓取、重试机制、代理等高级功能的批量抓取示例。这些示例展示了fetch-mcp的灵活性和强大功能,适合不同场景的数据采集需求。通过这三款工具的组合,开发者可快速构建高效、稳定的本地爬虫系统,为数据驱动的应用提供可靠支持。
最后,如果有什么不懂的可以评论区留言我们讨论一下。希望本文能够给到你帮助~