DINO系列粗读
DINO(2021)
dino https://github.com/facebookresearch/dino
paper https://arxiv.org/pdf/2104.14294
self-DIstillation with NO labels"(无标签的自蒸馏)
这是该系列的开创性工作,它成功地将自监督学习应用于 Vision Transformer (ViT) 架构 。
-
核心思想: 将自监督学习视为一种知识蒸馏 。
-
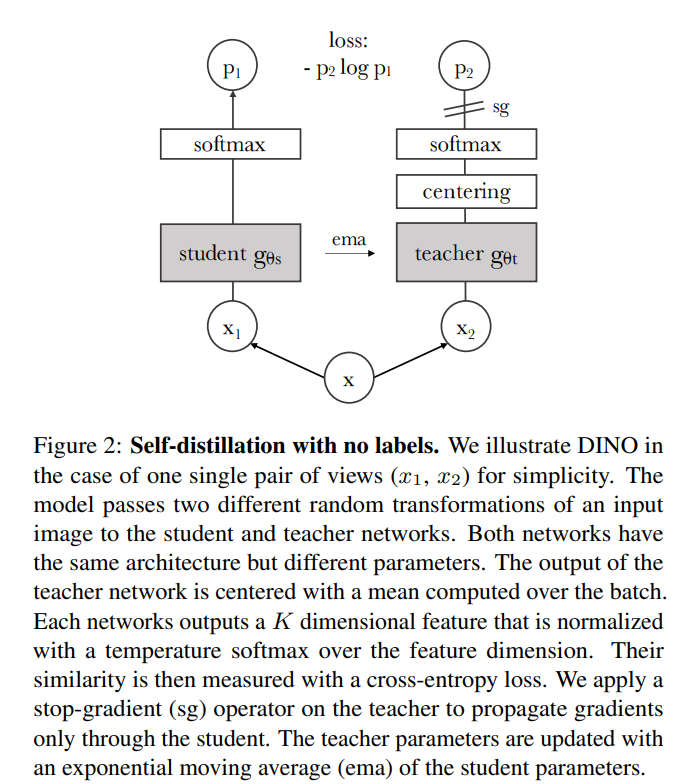
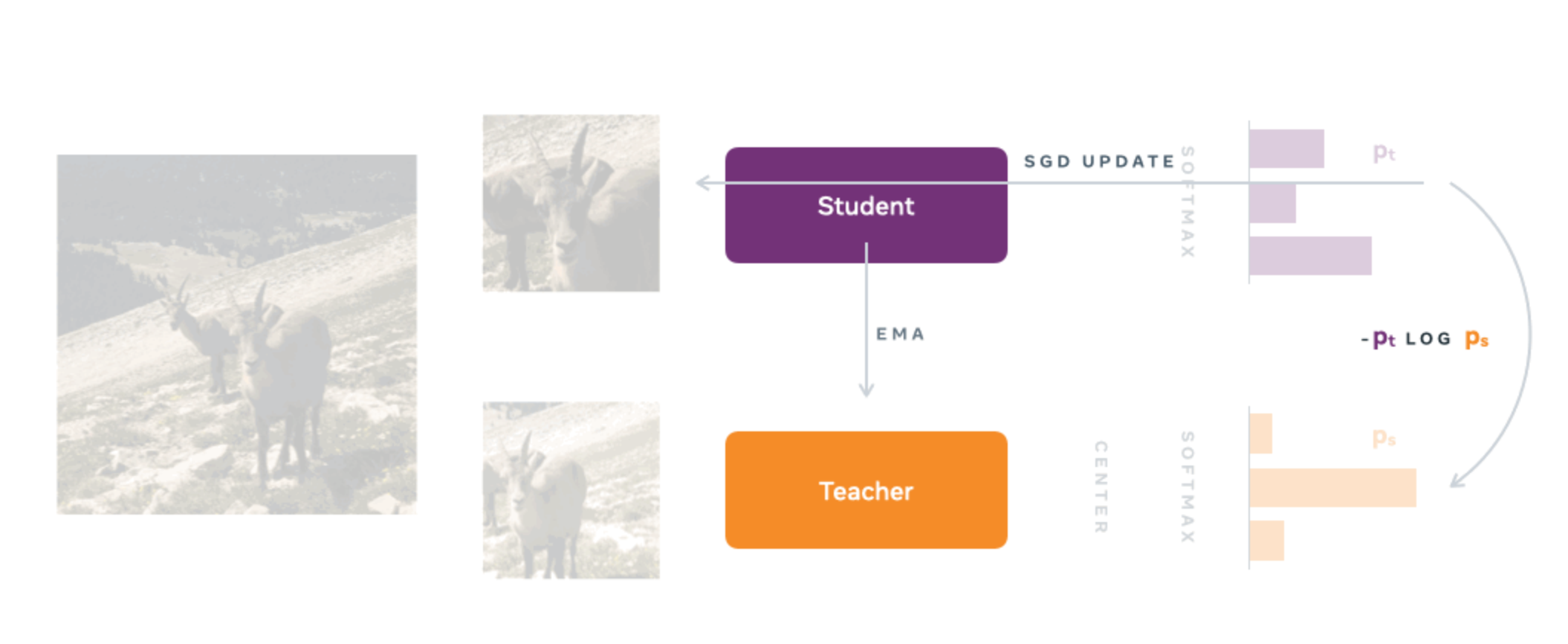
工作机制:
目标是训练一个学生网络(Student)来匹配一个教师网络(Teacher)的输出
它使用一个 学生(Student)网络 和一个 教师(Teacher)网络,二者具有相同的架构 。
学生网络通过梯度下降进行训练和更新 。教师网络的参数是学生网络参数的指数移动平均(EMA)(也称为动量编码器)。
学生网络被训练来匹配教师网络输出的概率分布 ,使用标准的交叉熵损失(Cross-Entropy Loss) 。
-
如何防止模型崩塌 (Collapse):(是指模型对所有输入都输出相同的结果。)
传统的自监督方法依赖对比损失或聚类。DINO 另辟蹊径,仅通过对教师网络的输出进行中心化(Centering)(使用一个在批次上计算的移动平均值)和锐化(Sharpening)(使用较低的温度T)组合,就足以避免模型输出退化(即所有输出都相同)。
在一次迭代中,学生网络会接收到多个来自同一图像的裁切视图(包括两个“全局”视图和多个“局部”小视图)而教师网络只接收两个全局视图 。这会迫使学生网络学习“从局部视图到全局视图”的一致性 。
论文发现,ViT的自注意力图(Self-Attention Map)自动学会了场景的语义分割信息 。即使没有经过任何分割任务的训练,其注意力图也能清晰地勾勒出图像中物体的轮廓 ,这是在监督学习ViT或卷积网络中不曾明确出现的。
此外,它的特征也是非常出色的k-NN分类器 。
验证了“动量教师机 + 交叉熵损失 + 中心化/锐化”这一简洁框架在 ViT 上的有效性,并发现了其自注意力图自发学习物体分割的惊人特性。
DINO-v2(2023): 规模化与通用性
github: https://github.com/facebookresearch/dinov2
提供了从 ViT-S (Small, 21M 参数) 到 ViT-g (Giant, 1.1B 参数) 四种不同尺寸的 Vision Transformer 模型。
-
DINOv2 的一个重要更新是引入了“寄存器 (Registers)”机制。这是基于论文《Vision Transformers Need Registers》的一项改进,通过在 ViT 模型中添加一些额外的可学习的 token,可以显著提升模型特征的质量和在下游任务中的表现。
-
DINOv2 的目标是利用 DINO 的思想,通过大规模预训练,创造出可以无需微调(Finetuning)、“即插即用”的通用视觉特征(General-Purpose Visual Features) 。
核心思想: 通过在足够多且经过精心策展的数据上训练,自监督方法可以产生通用的冻结特征 。
关键贡献:
-
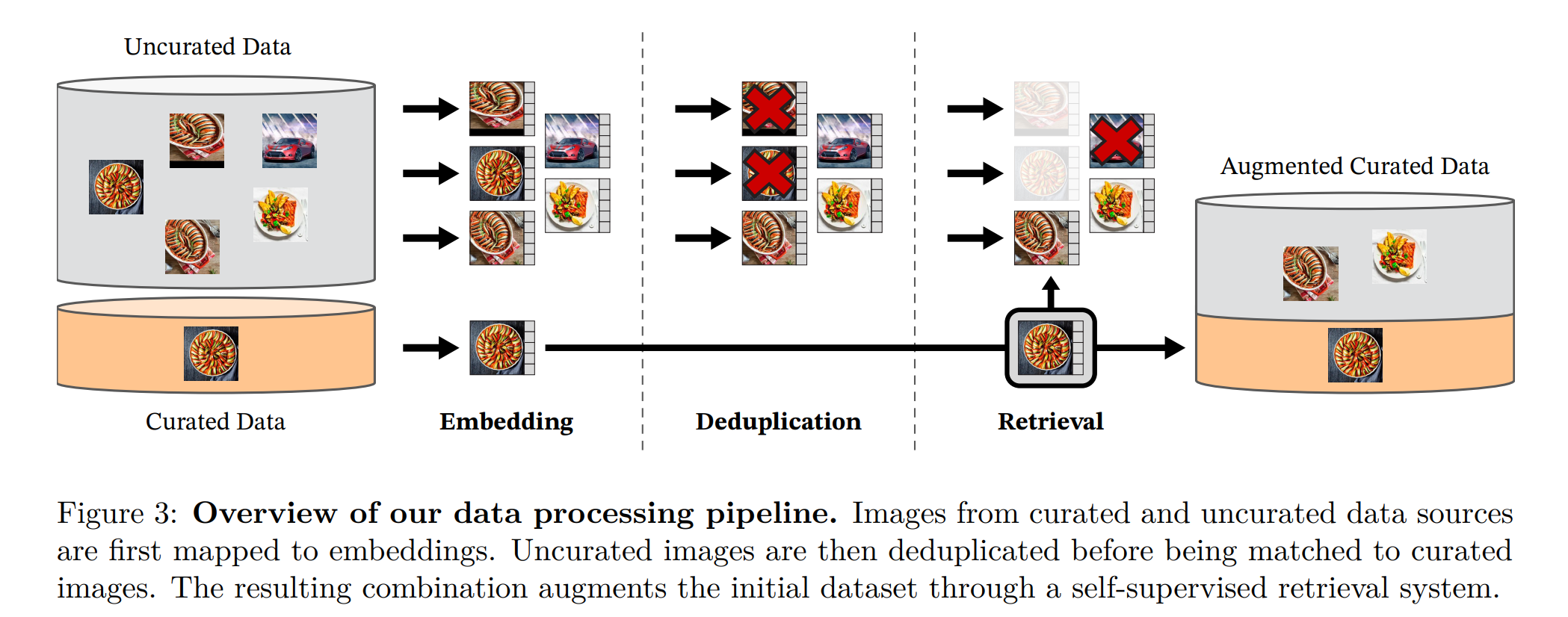
大规模 Data Curation: 团队认识到,简单地在未策展的原始网络数据上训练会导致特征质量下降 。因此,他们构建了一个自动流程,从庞大的未策展数据中筛选、去重和平衡,构建了一个专用的、多样化的大型策展数据集 LVD-142M(1.42亿张图像)。
-
模型规模化 (Model Scale): 在这个大型数据集上,团队训练了一个 1B(11亿)参数的 ViT-g 模型 。
-
稳定的规模化训练: 为了在如此大的规模上稳定训练,DINOv2 融合了 DINO 和 iBOT(另一种SSL方法)的损失 ,并加入了 KoLeo 正则化项以稳定训练 ,同时使用了 FlashAttention 和 FSDP 等技术加速训练 。
-
知识蒸馏: 最终,DINOv2 将这个强大的 1B 参数模型蒸馏回一系列更小的、可供实际使用的模型(如 ViT-S, B, L)。这种蒸馏方式甚至比从头开始训练小模型的效果还要好 。
-
主要成果:
DINOv2 成功地创造出了强大的**“冻结”特征**。
这意味着您可以直接使用 DINOv2 作为骨干网络,冻结其参数,只训练一个简单的线性分类器或轻量级头部,就能在图像分类、分割、深度估计等多种下游任务上超越当时最好的通用特征(如 OpenCLIP)。
DINOv2小结: 核心在于“规模化”。通过“大规模策展数据 + 大模型 + 稳定训练技术 + 蒸馏”,DINOv2 实现了“冻结特征”的SOTA性能,成为真正意义上的通用视觉基础模型。
DINO-v3 (2025): 攻克稠密特征
项目地址 https://ai.meta.com/dinov3/
权重下载 https://huggingface.co/collections/facebook/dinov3-68924841bd6b561778e31009
github https://github.com/facebookresearch/dinov3
技术报告 https://ai.meta.com/research/publications/dinov3/
DINOv3 是对 DINOv2 的再一次大规模扩展,其核心目标是解决在超大规模训练中发现的稠密特征(Dense Features)质量下降问题
-
核心思想: 再次扩大模型(7B)和数据(16.89亿)规模,并引入新技术以保持高质量的稠密特征图(用于分割、深度估计等)。
-
随着训练时间的延长和模型规模的增大(例如超过 ViT-L 规模),模型的全局任务(如图像分类)性能会持续提升,但稠密任务(如分割)的性能在达到一个峰值后反而会开始下降。从特征图上看,表现为特征图变得“嘈杂”,失去了清晰的局部性和物体边界 。
-
关键贡献:Gram 锚定 (Gram Anchoring): 为了解决稠密特征衰退问题,DINOv3 引入了一项全新的技术——Gram 锚定。工作机制: 这是一种在预训练后期(1M次迭代后)加入的“精炼”步骤。它引入了一个额外的损失项 LGram\mathcal{L}_{Gram}LGram ,该损失项迫使学生网络的Gram 矩阵(特征图的成对补丁(patch)相似度矩阵 ),去匹配一个“Gram 教师机”的 Gram 矩阵。这个“Gram 教师机”是模型早期训练阶段(如 200k 次迭代时)的教师机快照,因为它保留了高质量的稠密特征 。
-
效果: 这个方法成功“修复”了已经退化的稠密特征 ,使得 DINOv3 能够在超大规模训练下同时保持全局和稠密任务的SOTA性能 。
-
再次规模化与蒸馏: DINOv3 将骨干网络扩展到了 ViT-7B(67亿参数),并在更大的 LVD-1689M(16.89亿图像)数据集上训练 。
-
同时,它还开发了一种高效的“单教师-多学生”蒸馏流程 ,将 7B 模型的知识压缩到一系列不同大小的模型中(包括ViT和ConvNeXt架构)。
-
主要成果:DINOv3 提供了极高质量的稠密特征 3939,在分割、深度、3D对应等任务上显著超越了包括 DINOv2 和其他(弱)监督模型在内的所有先前方法 。凭借其强大的冻结特征,DINOv3 仅通过训练轻量级头部,就在 COCO 目标检测和 ADE20k 语义分割等基准上达到了 SOTA(或接近SOTA)的性能 。
-
DINOv3小结: 核心在于“解决规模化下的稠密特征衰退”。通过引入“Gram锚定”技术,DINOv3 才能在 7B 级别模型和十亿级数据的规模下继续扩展,最终在稠密任务上取得了决定性优势。
模型分类:
-
按架构分:
-
ViT (Vision Transformer) 模型:从 21M 参数的
ViT-S到 6,716M (6.7B) 参数的巨型ViT-7B,提供了多种尺寸选择。 -
ConvNeXt 模型:提供从
Tiny(29M) 到Large(198M) 的四个版本,这类模型通常在速度和效率上更有优势。
-
按预训练数据集分:
-
LVD-1689M (网页数据集):大多数模型都在这个包含约 17 亿张网页图片的数据集上训练,通用性很强。- 网页图像 (LVD-1689M): 使用 ImageNet 经典的均值
(0.485, 0.456, 0.406)和标准差(0.229, 0.224, 0.225)。 -
SAT-493M (卫星数据集):专门提供了两个在卫星图像上训练的模型 (
ViT-L和ViT-7B),适用于地理空间分析等遥感领域。- 卫星图像 (SAT-493M): 使用专门的均值(0.430, 0.411, 0.296)和标准差(0.213, 0.156, 0.143)。
DINOv3 还提供了一些在特定任务上训练好的“任务头”,可以直接用于图像分类、深度估计、物体检测和语义分割等。