如何保证Redis和Mysql数据缓存一致性?
1.读数据流程:
1. 先读缓存
2. 缓存命中 → 直接返回
3. 缓存未命中 → 读数据库 → 写入缓存 → 返回数据2.写数据流程:
1. 更新数据库
2. 删除缓存(而不是更新缓存)3.完整代码示例
3.1.用户服务实现
@Service
@Slf4j
public class UserService {@Autowiredprivate UserMapper userMapper;@Autowiredprivate RedisCache redisCache;// 缓存key前缀private static final String USER_CACHE_KEY = "user:";/*** 根据ID获取用户(读操作 - 旁路缓存)*/public User getUserById(Long userId) {String cacheKey = USER_CACHE_KEY + userId;// 1. 先从缓存读取User user = redisCache.get(cacheKey);if (user != null) {log.info("缓存命中,用户ID: {}", userId);return user;}// 2. 缓存未命中,查询数据库log.info("缓存未命中,查询数据库,用户ID: {}", userId);user = userMapper.selectById(userId);if (user == null) {return null;}// 3. 将数据写入缓存,设置30分钟过期redisCache.set(cacheKey, user, 30 * 60);log.info("数据写入缓存,用户ID: {}", userId);return user;}/*** 更新用户(写操作 - 先更新数据库,再删除缓存)*/@Transactionalpublic boolean updateUser(User user) {try {// 1. 更新数据库int result = userMapper.updateById(user);if (result <= 0) {return false;}// 2. 删除缓存String cacheKey = USER_CACHE_KEY + user.getUserId();redisCache.delete(cacheKey);log.info("更新用户成功,删除缓存,用户ID: {}", user.getUserId());return true;} catch (Exception e) {log.error("更新用户失败,用户ID: {}", user.getUserId(), e);throw new RuntimeException("更新用户失败", e);}}/*** 新增用户*/@Transactionalpublic boolean addUser(User user) {try {// 1. 插入数据库int result = userMapper.insert(user);if (result <= 0) {return false;}// 2. 新增用户不需要立即缓存,等第一次读取时自然缓存// 但如果需要立即使用,可以在这里设置缓存// String cacheKey = USER_CACHE_KEY + user.getUserId();// redisCache.set(cacheKey, user, 30 * 60);log.info("新增用户成功,用户ID: {}", user.getUserId());return true;} catch (Exception e) {log.error("新增用户失败", e);throw new RuntimeException("新增用户失败", e);}}/*** 删除用户*/@Transactionalpublic boolean deleteUser(Long userId) {try {// 1. 删除数据库(逻辑删除)User user = new User();user.setUserId(userId);user.setDelFlag("1"); // 逻辑删除标志int result = userMapper.updateById(user);if (result <= 0) {return false;}// 2. 删除缓存String cacheKey = USER_CACHE_KEY + userId;redisCache.delete(cacheKey);log.info("删除用户成功,删除缓存,用户ID: {}", userId);return true;} catch (Exception e) {log.error("删除用户失败,用户ID: {}", userId, e);throw new RuntimeException("删除用户失败", e);}}
}3.2 控制器层
@RestController
@RequestMapping("/user")
@Slf4j
public class UserController {@Autowiredprivate UserService userService;/*** 获取用户信息*/@GetMapping("/{userId}")public AjaxResult getUser(@PathVariable Long userId) {try {User user = userService.getUserById(userId);if (user == null) {return AjaxResult.error("用户不存在");}return AjaxResult.success(user);} catch (Exception e) {log.error("获取用户信息失败,用户ID: {}", userId, e);return AjaxResult.error("系统异常");}}/*** 更新用户信息*/@PutMappingpublic AjaxResult updateUser(@RequestBody User user) {try {boolean result = userService.updateUser(user);return result ? AjaxResult.success() : AjaxResult.error("更新失败");} catch (Exception e) {log.error("更新用户信息失败,用户ID: {}", user.getUserId(), e);return AjaxResult.error("更新失败");}}/*** 新增用户*/@PostMappingpublic AjaxResult addUser(@RequestBody User user) {try {boolean result = userService.addUser(user);return result ? AjaxResult.success() : AjaxResult.error("新增失败");} catch (Exception e) {log.error("新增用户失败", e);return AjaxResult.error("新增失败");}}/*** 删除用户*/@DeleteMapping("/{userId}")public AjaxResult deleteUser(@PathVariable Long userId) {try {boolean result = userService.deleteUser(userId);return result ? AjaxResult.success() : AjaxResult.error("删除失败");} catch (Exception e) {log.error("删除用户失败,用户ID: {}", userId, e);return AjaxResult.error("删除失败");}}
}4.使用建议
1. 缓存key设计
// 使用统一的命名规范
private static final String USER_CACHE_KEY = "user:";
private static final String PRODUCT_CACHE_KEY = "product:";
private static final String ORDER_CACHE_KEY = "order:";2. 过期时间策略
// 根据业务特点设置不同的过期时间
redisCache.set(key, value, 30 * 60); // 用户数据:30分钟
redisCache.set(key, value, 5 * 60); // 商品数据:5分钟
redisCache.set(key, value, 24 * 60 * 60); // 配置数据:24小时3. 监控和日志
// 添加详细的日志,便于排查问题 log.info("缓存命中,key: {}", key); log.info("缓存未命中,查询数据库,key: {}", key); log.info("删除缓存,key: {}", key);5.CAP理论的基本概念
CAP理论主要用于描述分布式系统中的三大特性:
一致性(Consistency):所有节点在同一时刻看到的数据是一致的。即每次读操作都能返回最新的写入结果,确保数据的正确性。
可用性(Availability):系统能够保证每个请求都会收到响应,无论是成功的响应还是失败的响应。即使某些节点出现故障,系统仍然能够继续提供服务。
分区容忍性(Partition Tolerance):系统能够容忍网络分区,即节点之间的通信中断,并且在出现分区时仍然能够继续运作。
6.为什么选择"更新DB + 删除缓存"而不是"更新DB + 更新缓存"?
方案对比:
方案 优点 缺点 更新DB + 删除缓存 简单、避免并发写问题、减少不必要的缓存更新 有极小的不一致窗口期 更新DB + 更新缓存 数据一致性更好 并发写时可能脏数据、浪费资源更新不常读的数据 并发问题分析:
场景:两个并发写操作
线程A更新用户信息 → 更新DB → 更新缓存
线程B更新用户信息 → 更新DB → 更新缓存
可能出现:
DB中:用户B的数据 缓存中:用户A的数据(因为A的更新晚于B)而使用删除缓存策略,可以避免这种并发写导致的脏数据问题。
针对删除缓存异常的情况,可以使用 2 个方案避免:
1.消息队列方案:将第二个操作(删除缓存)要操作的数据加入到消息队列,由消费者来操作数据。
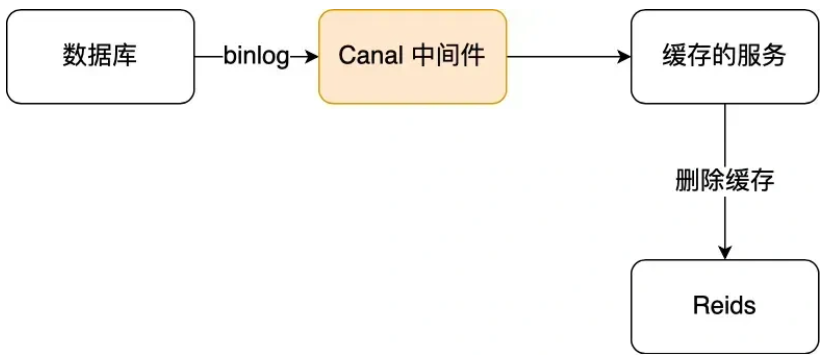
2.订阅 MySQL binlog,再操作缓存:
「先更新数据库,再删缓存」的策略的第一步是更新数据库,那么更新数据库成功,就会产生一条变更日志,记录在 binlog 里。于是我们就可以通过订阅 binlog 日志,拿到具体要操作的数据,然后再执行缓存删除。