ICLR 2025 | 告别“非黑即白”!X-CLR引入“相似度图谱”,让模型读懂万物关联!
在计算机看图识物的世界里,一种流行的方法叫做“对比学习”。它通过告诉模型“这两张图是相似的(比如同一只猫的不同照片)”和“这两张图是不相似的(一张猫和一张车)”来学习。但这种“非黑即白”的区分方式忽略了一个重要事实:不同事物之间也存在着不同程度的相似性。例如,一张猫的图片和一张狗的图片,虽然不是同一事物,但它们都属于“宠物”,比猫和汽车的相似度要高。现有的方法大多忽略了这种“灰色地带”的相似性,导致学习到的特征不够丰富和准确。
为了解决这个问题,本论文提出了一种名为X-样本对比损失(X-CLR)的新框架。该方法不再简单地将样本分为“相似”或“不相似”,而是引入了一个“相似度图谱”,用0到1之间的连续数值来精确描述任意两个样本之间的相似程度。通过这种更精细的指导,模型学会了更丰富、更具泛化能力的图像特征,在多个图像识别任务上,特别是在数据量较少的情况下,取得了比现有顶尖方法(如CLIP)更好的效果。
论文基本信息
-
论文标题: X-SAMPLE CONTRASTIVE LOSS: IMPROVING CONTRASTIVE LEARNING WITH SAMPLE SIMILARITY GRAPHS(X-样本对比损失:通过样本相似度图谱改进对比学习)
-
论文链接: https://openreview.net/pdf?id=c1Ng0f8ivn
➔➔➔➔点击查看原文,获取更多大模型相关资料![]() https://mp.weixin.qq.com/s/yArPzxnJQGL9T7IXe1-H0A
https://mp.weixin.qq.com/s/yArPzxnJQGL9T7IXe1-H0A
主要贡献与创新
-
重新审视了对比学习,指出其相似度矩阵是稀疏且二元的,忽略了样本间的潜在关联。
-
提出了一种新的X-CLR损失函数,它能够显式地利用样本间的软性相似度 (soft similarities) 。
-
在百万到千万级数据集上验证,证明X-CLR学习的特征在分类、鲁棒性和数据效率上均有提升。
-
证明了X-CLR能有效解耦图像中的物体与背景、属性,并在相关基准测试上取得显著优势。
研究方法与原理
该模型的核心思路是,用一个预先计算好的、能反映样本间连续相似度的“目标相似度矩阵”来指导图像编码器的学习,取代传统对比学习中非黑即白的“正/负”样本标签。
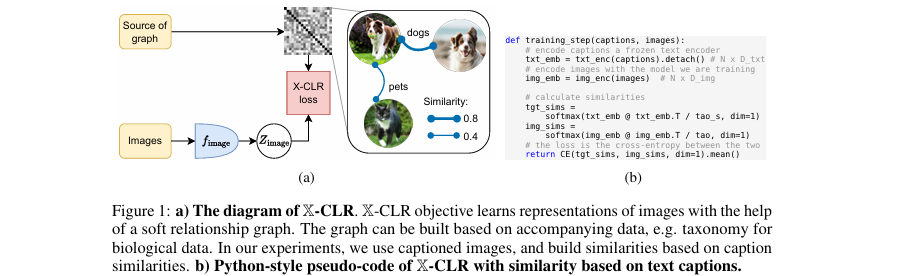
该图直观展示了X-CLR如何利用文本描述构建一个软性的关系图谱来指导图像表示学习,并给出了伪代码
论文首先从相似度图谱的视角统一了多种学习范式。传统的自监督对比学习,如SimCLR,其隐含的相似度图谱是一个二元矩阵。对于一个批次中由同一张原始图片增强得到的两个视图,它们之间的相似度被定义为1,而与其他所有图片的视图相似度都为0。这可以用一个邻接矩阵 来表示,其中如果样本 和 源于同一个原始输入,则 ,否则为0。
本文提出的 X-样本对比学习 (X-Sample Contrastive Learning, X-CLR) 对此进行了改进。它不再使用硬性的0/1标签,而是引入了一个软性相似度图谱 ,其矩阵中的元素 是一个在 区间内的连续值,表示样本 和 之间的语义相似程度。这个图谱可以利用数据附带的任何元信息来构建。在本文的实验中,作者主要利用了图像附带的文本描述(如类别标签或图说)来构建这个图谱。具体来说,他们使用一个预训练且固定的文本编码器 (例如Sentence Transformer)来提取每段文本的嵌入向量,然后通过计算文本嵌入向量之间的余弦相似度来得到样本间的相似度:
其中 和 分别是样本 和 对应的文本描述。
有了这个软性相似度矩阵后,X-CLR将其转化为一个目标概率分布。对于批次中的每个样本 ,其与其他样本 的目标相似度分布 通过对 应用带有温度系数 的Softmax函数来计算:
这里的 是一个超参数,用于调节目标分布的平滑度。较低的 会使分布更尖锐,接近于只关注最相似的样本;而较高的 会使分布更平滑,给予那些“有点像”的样本更多的关注。
同时,正在训练的图像编码器 会为批次中的所有图像(每个原始图像及其增强视图)生成图像嵌入 。模型预测的相似度分布 同样通过计算嵌入向量间的余弦相似度并应用Softmax函数得到,其温度系数为 :
最终,X-CLR的损失函数就是计算模型预测的相似度分布 与我们预先定义的目标相似度分布 之间的**交叉熵 (cross-entropy)**。其目标是让模型学习到的图像相似度分布 尽可能地逼近由文本信息指导的目标分布 :
通过最小化这个损失函数,模型不仅被鼓励去拉近同一图像的两个增强视图(因为 通常是最高的),还被鼓励去根据文本语义的远近,适当地调整不同图像之间的表示距离。
实验设计与结果分析
实验部分旨在验证X-CLR在不同规模和类型的数据集上相对于传统对比学习方法的优势。实验使用了三个数据集:ImageNet-1k(100万张带类别标签的图像)、CC3M(300万张带噪声图说的图像)和CC12M(1200万张带噪声图说的图像)。评估指标主要是在多个下游任务上的线性探测(linear probing)准确率,包括ImageNet分类、ImageNet Real、ImageNet-9(背景鲁棒性测试)、ObjectNet(视图和上下文鲁棒性测试)以及MIT-States(物体与属性识别)。
X-Sample Contrastive with Well-labeled Samples (在标注良好的样本上进行X样本对比学习)
这部分实验在ImageNet-1k上进行,利用类别名称生成的文本描述(例如 "a photo of a [class_name]")来构建相似度图谱。
对比实验:如论文中的 表1所示,X-CLR与多种基线方法进行了比较,包括自监督方法(SimCLR, VICReg, BarlowTwins)、使用类别标签的监督对比学习(SupCon)以及使用软目标的自蒸馏方法(SCE, ReSSL)。结果显示,X-CLR在所有分类基准上都取得了最佳或接近最佳的性能。例如,在ImageNet分类任务上,X-CLR达到了75.6% 的准确率,超过了SupCon(74.3%)和SimCLR(63.4%)。特别是在衡量模型将物体从背景中分离能力的ImageNet-9基准上(论文中称为 Background Decomp.),X-CLR的优势更为明显,在“Mixed”设置下比SupCon高出**3.6%**。
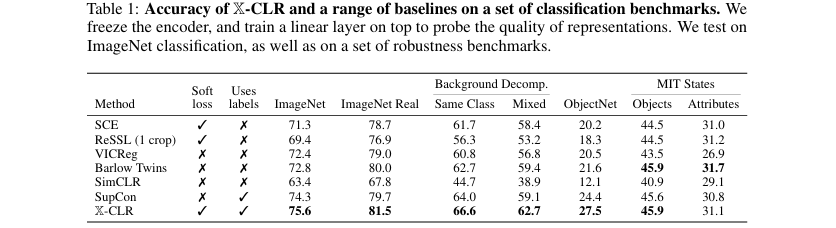
展示X-CLR与多种基线方法在多个分类基准上的性能对比
消融实验:为了探究相似度图谱来源的影响,论文在 表2 中比较了使用不同文本编码器(如Sentence Transformer, CLIP text encoder, LLama2)或WordNet层次结构来构建图谱的效果。结果表明,使用Sentence Transformer构建的图谱效果最好,证明了高质量的文本表示对于构建有效的相似度图谱至关重要。同时,该实验也说明X-CLR并非一个模型蒸馏方法,因为其相似度来源可以是任何元数据,不局限于另一个模型的输出。
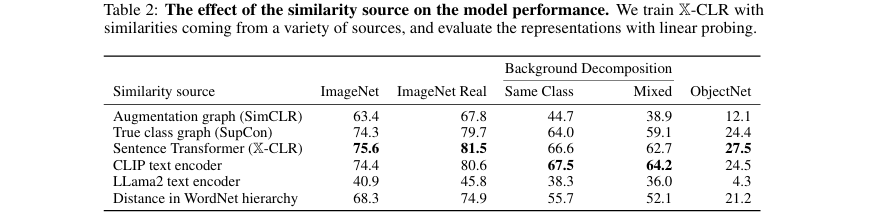
展示不同相似度图谱来源对模型性能的影响
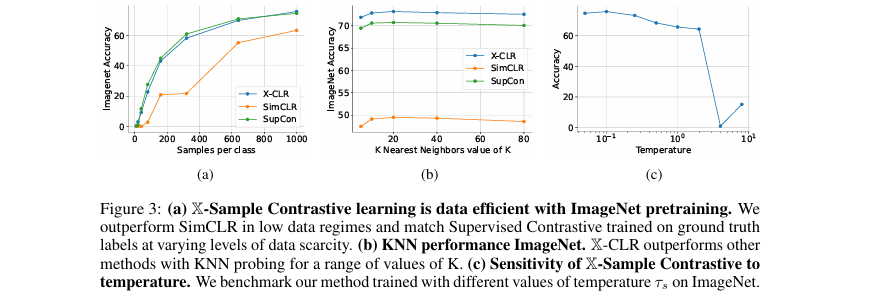
此外,图3(a) 的实验表明,在数据稀疏(每个类别样本很少)的情况下,X-CLR的性能远超SimCLR,并能与使用真实标签的SupCon相媲美,证明了其数据高效性。
X-Sample Contrastive Learning with Noisy Multimodal Samples (在带噪声的多模态样本上进行X样本对比学习)
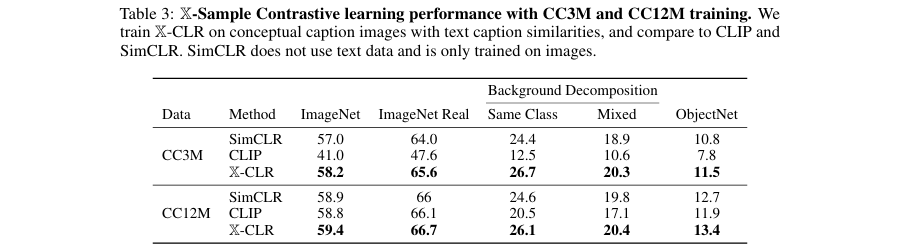
这部分实验在CC3M和CC12M数据集上进行,直接使用数据集中带噪声的图说来构建相似度图谱,并与同样使用这些数据训练的CLIP和SimCLR进行比较。
对比实验:如 表3 所示,无论是在300万样本的CC3M还是1200万样本的CC12M上,X-CLR都展现了优越的性能。在CC12M上训练时,X-CLR在ImageNet分类任务上比CLIP高出0.6%。这个优势在数据量较少的CC3M上更为惊人,X-CLR在ImageNet上的准确率比CLIP高出17.2%,这再次凸显了X-CLR在低数据区域的强大能力。在背景鲁棒性测试(ImageNet-9)上,X-CLR同样大幅领先CLIP,尤其是在CC3M上,提升幅度高达**14.2%**。
展示X-CLR、CLIP和SimCLR在CC3M和CC12M上训练后在各项基准上的表现
X-Sample Contrastive can be used to Finetune Pretrained Backbones (X-Sample Contrastive可用于微调预训练骨干网络)
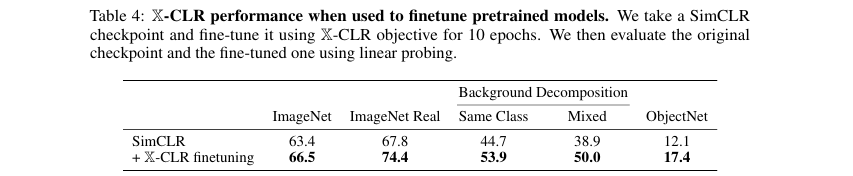
为了验证X-CLR作为微调目标的有效性,作者将一个预训练好的SimCLR模型使用X-CLR损失函数在ImageNet上微调了10个轮次。如 表4 所示,微调后的模型在ImageNet分类准确率上提升了3.1% ,在ObjectNet上提升了5.3% ,在背景鲁棒性测试中提升了9.2%~11.1% ,证明了X-CLR可以作为一种有效的“增强器”,快速提升现有模型的性能。
可视化对比
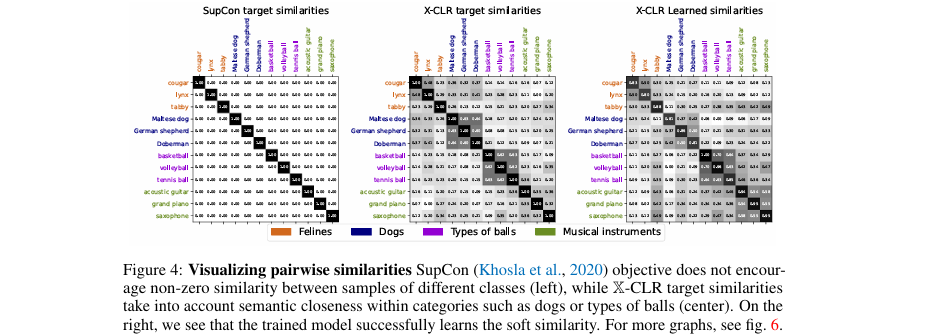
在 图4 中,作者可视化了SupCon和X-CLR的目标相似度矩阵以及X-CLR学习到的图像相似度矩阵。SupCon的目标矩阵是块对角化的,只在同类样本间有相似度。而X-CLR的目标矩阵则体现了更丰富的语义关系,例如不同品种的猫科动物之间、不同种类的狗之间都有较高的相似度。右侧的图表明,模型成功学习到了这种软性的、跨类别的相似性结构,证明了方法的有效性。
该图直观对比了SupCon和X-CLR的目标相似度以及X-CLR学习到的相似度
论文结论与评价
总结
本文从理论上指出传统对比学习只利用了二元的、非黑即白的样本关系,限制了表示学习的质量。为此,论文提出了X-CLR方法,通过引入一个由文本等元数据构建的软性相似度图谱,来指导模型学习更丰富的样本间关系。实验结果非常扎实,证明了在不同规模和质量的数据集上,X-CLR学习到的图像表示在标准分类、鲁棒性以及数据效率方面均优于或持平于当前最先进的对比学习方法,尤其是在数据量较少时优势巨大。
评价
这项研究对实际应用和未来研究有重要的启示。它告诉我们,在训练大模型时,不应丢弃样本间那些“微弱”但有价值的语义联系。在实际应用中,我们可以利用各种可得的元数据(如产品类别、地理位置、时间戳等)来构建相似度图谱,从而在不增加太多计算成本(如 表5 所示,开销极小)的情况下显著提升模型性能。

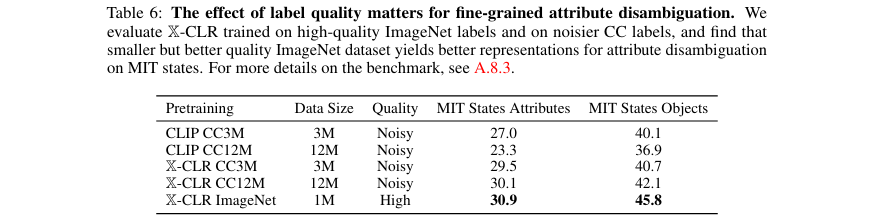
该方法的主要优点是思想简洁、效果显著且易于实现。它巧妙地将知识蒸馏的思想与对比学习相结合,但又超越了蒸馏(因为知识来源不局限于教师模型)。其主要缺点是对高质量元数据的依赖。如实验所示(表6),使用高质量的ImageNet标签比使用12倍数量的噪声网络图说,在细粒度属性识别任务上效果更好。如果元数据本身充满噪声或无法反映真实的语义相似性,X-CLR的效果可能会打折扣。
一个值得深入探讨的方向是,如何自动或以无监督的方式构建更优的相似度图谱,以减少对高质量人工标注元数据的依赖。例如,可以探索利用模型的中间表示进行迭代式地更新和优化相似度图谱,或者结合多种不同来源的元信息来共同构建一个更鲁棒的图谱。
➔➔➔➔点击查看原文,获取更多大模型相关资料![]() https://mp.weixin.qq.com/s/yArPzxnJQGL9T7IXe1-H0A
https://mp.weixin.qq.com/s/yArPzxnJQGL9T7IXe1-H0A