10.2 一种融合深度空间特征增强与注意力去噪的新型 3D 室内定位方法研究总结
文献来源:

论文解析
该文献发表于《Scientific Reports》,提出一种融合深度空间特征增强与注意力去噪的新型 3D 室内定位方法。针对室内定位数据稀缺、噪声干扰大、全局特征捕捉弱等问题,该方法采用 SVAE-WGAN 生成高质量合成数据以缓解数据稀缺,通过 ADE 模块结合注意力机制与去噪自编码器提升特征提取鲁棒性,最终结合 DNN 实现定位。在 UJIIndoorLoc、Tampere 等数据集实验显示,仅用 10% UJIIndoorLoc 数据就实现 100% 建筑定位准确率、94.7% 楼层准确率,且定位误差显著降低,验证了方法有效性。
图1 模型的整体框架
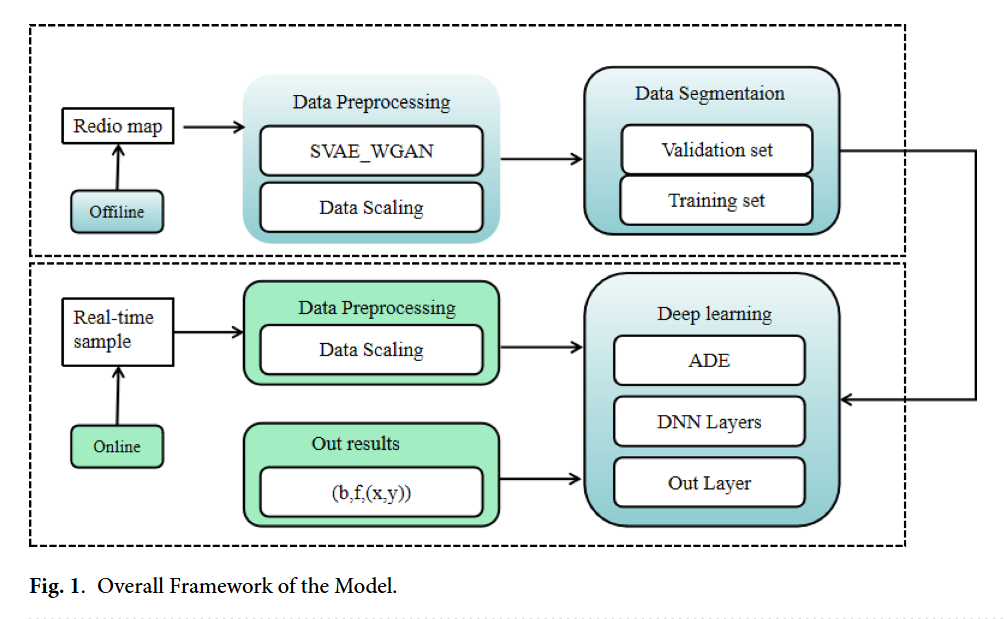
图 1 不仅是流程的可视化,更直接映射了论文对 3D 室内定位核心问题的解决思路,与文档中提及的 “数据稀缺、噪声干扰、全局特征捕捉能力弱” 三大痛点形成对应:
- 针对 “数据稀缺”:通过 “SVAE-WGAN 模块” 的合成数据生成功能,在离线阶段扩充训练数据,解决文档中 “现有方法在训练数据稀缺时定位精度低” 的问题;
- 针对 “噪声干扰”:通过 “ADE 模块” 的去噪与注意力特征聚焦,在离线训练与在线推理中均过滤无效噪声,解决 “室内环境复杂导致信号波动、定位鲁棒性差” 的问题;
- 针对 “全局特征捕捉弱”:通过 “ADE 的注意力机制 + DNN 的深层特征融合”,实现对室内空间全局特征的有效学习,避免传统方法 “局部特征依赖强、定位泛化性差” 的局限。
图2 核心模块
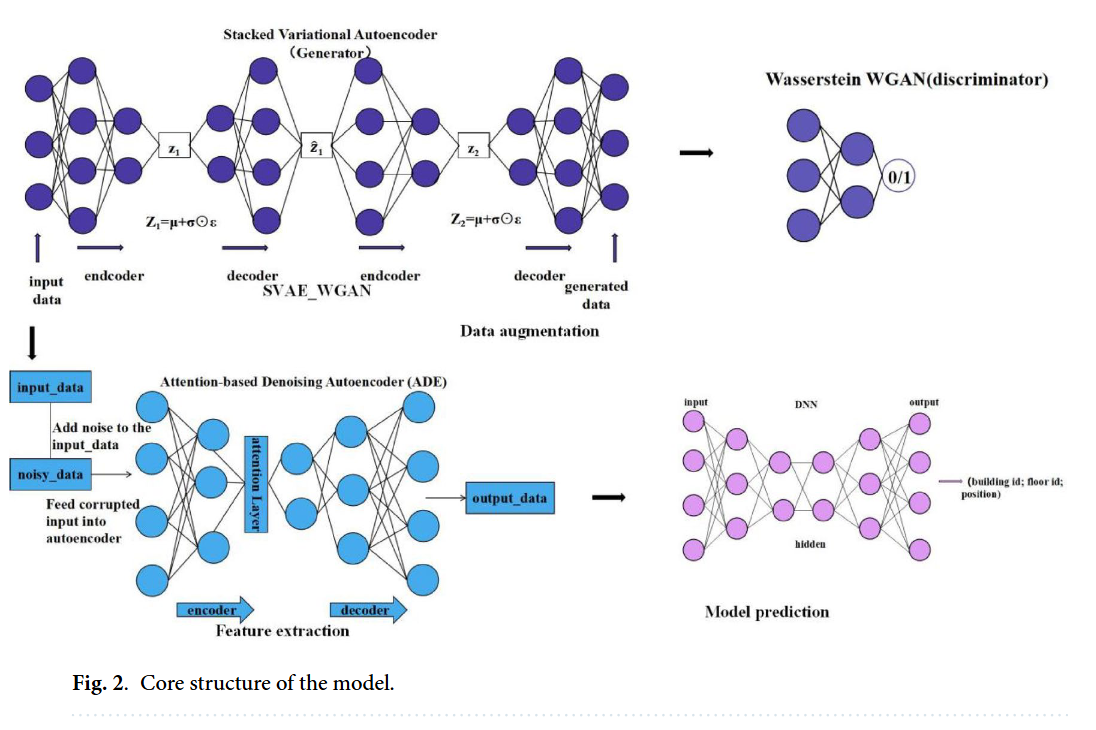
图2为模型的核心结构,其核心作用是聚焦呈现论文提出的3D室内定位框架中两大关键核心模块——SVAE-WGAN(堆叠变分自编码器-Wasserstein生成对抗网络)与ADE(注意力去噪自编码器)的内部结构、数据交互逻辑及功能协同关系,是对图1(整体框架)中核心技术细节的深化拆解,具体可从模块构成、数据流向及功能目标三方面展开解释:
从模块构成来看,图2清晰划分出SVAE-WGAN数据生成模块与ADE特征提取模块两大核心部分。SVAE-WGAN模块内,明确展示了“输入数据→SVAE编码器→SVAE解码器→WGAN判别器→生成数据”的流程,其中SVAE通过两层堆叠结构提取数据深层潜在特征,WGAN则基于Wasserstein距离优化生成样本质量,二者协同生成高保真合成数据;
ADE模块内,呈现了“输入数据→添加噪声→注意力编码器→解码器→去噪输出”的链路,注意力机制嵌入编码器以聚焦关键特征,解码器则从含噪输入中重构有效数据表示,实现去噪与特征增强。
从数据流向来看,图2以箭头明确标注了模块间及模块内部的数据传递路径:原始输入数据一方面流入SVAE-WGAN模块,经处理后生成合成数据;另一方面,原始数据与生成数据共同作为ADE模块的输入,先被注入噪声形成含噪数据,再经注意力编码器提取关键特征,最后由解码器输出去噪后的高质量特征,为后续DNN定位预测提供输入。
从功能目标来看,图2通过结构可视化直观体现两大模块的核心价值:SVAE-WGAN模块解决论文提及的“数据稀缺”问题,生成多样化、高真实度的合成数据以扩充数据集;ADE模块则针对“噪声干扰”与“特征辨识度低”问题,通过去噪与注意力特征加权,提升数据特征的鲁棒性与关键信息占比,二者共同构成定位框架的技术核心,为高精度3D室内定位奠定基础。
图3 SVAE-WGAN 模型框架
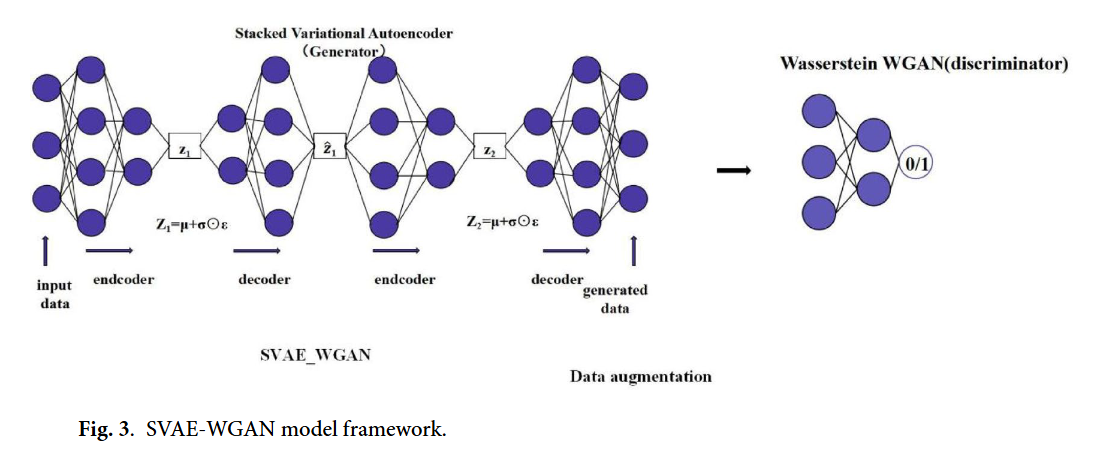
图 3核心作用是聚焦拆解论文核心数据生成模块 ——SVAE-WGAN 的内部架构、组件交互逻辑及数据处理流程,是对图 1(整体框架)和图 2(核心结构)中 “数据生成” 环节的技术细节深化,清晰呈现该模块如何通过 SVAE 与 WGAN 的协同生成高质量室内定位数据,具体可从模块构成、数据流向及功能适配三方面展开:
从模块构成看,图 3 明确划分出 SVAE(堆叠变分自编码器,标注为 “Generator” 生成器端)与 WGAN(沃瑟斯坦生成对抗网络,标注为 “Wasserstein WGAN (discriminator)” 判别器端)两大子模块,且 SVAE 采用论文设计的两层堆叠结构(含两级 “encoder- decoder” 单元),WGAN 则包含独立的编码器与解码器,二者通过潜在变量传递形成统一生成框架,精准匹配论文中 “SVAE 捕捉潜在特征 + WGAN 优化样本质量” 的设计逻辑。
从数据流向看,图 3 以箭头清晰标注全链路数据传递路径:首先,原始室内定位数据(如 Wi-Fi RSSI 数据)输入 SVAE 的第一级编码器(encoder1),经处理生成第一阶段潜在变量z1,再通过第一级解码器(decoder1)初步重构数据;随后,z1输入 SVAE 的第二级编码器(encoder2)生成深层潜在变量z2,经第二级解码器(decoder2)完成二次重构,同时z2作为关键特征传递至 WGAN 的生成器端;WGAN 接收z2与噪声输入(符合论文中 WGAN 的噪声分布假设),通过自身编码器与解码器处理后,输出最终的 “generated data(生成数据)”,且 WGAN 判别器会对生成数据与真实数据的分布差异进行评估,反馈优化 SVAE 与 WGAN 的参数。
从功能适配看,图 3 直观体现 SVAE-WGAN 对论文核心问题的解决:通过 SVAE 的两层堆叠结构,缓解单一层 VAE 特征表示不足的问题,确保生成数据符合真实数据的潜在分布;通过 WGAN 的判别器反馈,解决传统 GAN 训练不稳定、生成样本质量低的问题,最终实现 “高质量、多样化合成数据生成”,为后续 ADE 特征提取与 DNN 定位提供充足数据支撑,直接应对论文提及的 “室内定位数据稀缺、采集成本高” 痛点。
图4 SVAE模型结构
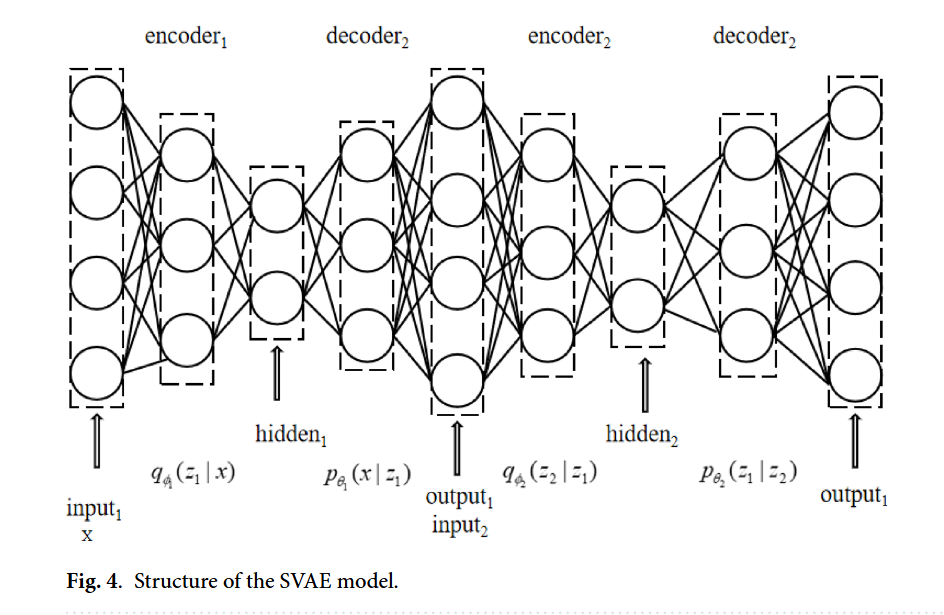
图4为SVAE模型结构,其核心作用是聚焦拆解论文中SVAE(堆叠变分自编码器)的内部层级架构、组件连接关系及数据处理逻辑,是对图3(SVAE-WGAN模型框架)中“SVAE生成器端”的进一步技术细化,清晰呈现SVAE如何通过两层堆叠设计捕捉室内定位数据的深层潜在特征,具体可从模块构成、数据流向及功能目标三方面展开:
从模块构成看,图4严格遵循论文中“两层堆叠VAE”的设计,明确划分出两级独立的“编码器-解码器”单元(encoder1-decoder1、encoder2-decoder2),且标注了各组件的输入输出维度关联。其中,每级编码器(encoder1、encoder2)均负责将输入数据映射至潜在空间并输出均值(μ)与方差(σ²)参数,每级解码器(decoder1、decoder2)则负责从潜在变量中重构数据;同时,图中清晰标注了潜在变量的传递路径(z₁从encoder1输出,作为encoder2的输入),精准匹配论文中“层级化特征提取”的设计逻辑。
从数据流向看,图4以箭头明确标注全链路数据传递:原始室内定位数据(输入维度与论文中UJIIndoorLoc数据集的520维RSSI特征匹配)首先输入第一级编码器(encoder1),经处理后生成第一阶段潜在变量z₁(服从论文假设的高斯分布\(q_{\phi_1}(z_1|x) \sim \mathcal{N}(z_1;\mu_1(x),\sigma_1^2(x))\));z₁一方面输入第一级解码器(decoder1),重构生成与原始数据维度一致的中间结果\(\hat{x}_1\),另一方面作为第二级编码器(encoder2)的输入,生成更深层的潜在变量z₂(同样服从高斯分布\(q_{\phi_2}(z_2|z_1) \sim \mathcal{N}(z_2;\mu_2(z_1),\sigma_2^2(z_1))\));z₂输入第二级解码器(decoder2),重构生成与z₁维度一致的\(\hat{z}_1\),并反馈至decoder1辅助优化原始数据的重构效果,形成“双层重构”闭环。
从功能目标看,图4直观体现SVAE对论文核心需求的适配:通过两层堆叠结构,解决单一层VAE在高维室内定位数据中“特征表示不足”的问题,确保能逐步挖掘数据的深层空间关联;通过“encoder-decoder”的重构机制与高斯分布约束,使潜在变量既符合真实数据分布,又具备良好的泛化性,为后续WGAN生成高质量合成数据提供“规范的潜在特征基础”,直接服务于论文中“缓解数据稀缺”的核心目标。
算法1

算法1(Algorithm 1)核心作用是将论文提出的SVAE-WGAN数据生成模块的工作流程、数学逻辑与参数更新规则转化为可执行的步骤化流程,明确该模块如何通过SVAE(堆叠变分自编码器)与WGAN(沃瑟斯坦生成对抗网络)的协同训练,生成高质量、符合真实分布的室内定位合成数据,以缓解数据稀缺问题,具体可从“输入输出定义”“核心步骤拆解”“与论文理论的关联”三方面展开:
一、算法1的输入与输出:
明确数据与参数范围 算法1开篇清晰界定了执行所需的输入条件与最终输出结果,严格匹配论文中SVAE-WGAN的设计需求:
- **输入(Inputs)**:包含三部分关键信息,一是原始室内定位数据\(X \in \mathbb{R}^{N \times d}\)(\(N\)为样本数量,\(d\)为特征维度,如UJIIndoorLoc数据集的520维RSSI特征),作为数据生成的基础;二是WGAN生成器所需的噪声分布\(p_z\)(论文假设为标准正态分布,确保生成数据的多样性);三是超参数(balancing parameter \(\lambda\)、learning rate、batch size),其中\(\lambda\)用于平衡SVAE损失与WGAN损失,避免单一损失主导训练,学习率与批大小则保障训练稳定性与效率。
- **输出(Outputs)**:最终生成“逼近输入数据分布的合成数据分布”,即通过算法训练后,SVAE-WGAN模块能输出与原始定位数据特征、分布高度一致的合成样本,为后续ADE特征提取与DNN定位提供数据支撑。
二、算法1的核心步骤:
分阶段实现协同训练 算法1将SVAE-WGAN的训练流程拆解为“参数初始化”与“多步骤迭代训练”两部分,每一步骤均对应论文中的数学模型与技术逻辑,具体如下:
1. **参数初始化(Initialize parameters)**:首先初始化SVAE与WGAN的核心参数——SVAE包含两层编码器(encoder1、encoder2)与两层解码器(decoder1、decoder2)的参数,WGAN包含生成器(generator)与判别器(discriminator)的参数,确保模型从合理初始状态启动训练,避免后续收敛困难。
2. **迭代训练(For each training step)**:采用循环迭代方式逐步优化参数,每一轮迭代包含四个关键步骤,形成“特征提取-重构优化-对抗训练-联合损失更新”的闭环:
- **步骤1:第一层VAE训练(First Layer VAE)**:将输入数据\(x\)输入SVAE的第一层编码器,通过公式\(q_{\phi}(z_1 | x) \sim \mathcal{N}(z_1 ; \mu_1(x), \sigma_1^2(x))\)将数据映射为第一阶段潜在变量\(z_1\)(服从高斯分布);随后通过第一层解码器对\(z_1\)进行重构,生成与原始输入维度一致的\(\hat{x}_1\),完成“输入-潜在变量-重构”的初步链路,对应论文中SVAE第一层“捕捉初始潜在特征”的功能。
- **步骤2:第二层VAE训练(Second Layer VAE)**:将第一层输出的潜在变量\(z_1\)作为第二层编码器的输入,生成更深层的潜在变量\(z_2\);再通过第二层解码器对\(z_2\)重构,生成\(\hat{z}_1\)(与\(z_1\)维度一致);同时计算SVAE的总损失\(L_{SVAE}\),该损失由“重构损失”(衡量\(x\)与\(\hat{x}_1\)、\(z_1\)与\(\hat{z}_1\)的差异)与“KL散度损失”(约束潜在变量分布接近先验分布)构成,对应论文公式\(L_{SVAE} = L_{recon} + D_{KL}\),实现对SVAE特征提取能力的优化。
- **步骤3:WGAN训练(WGAN)**:基于SVAE输出的潜在变量与原始数据,分别计算WGAN判别器损失\(L_D\)与生成器损失\(L_G\)——判别器通过区分真实数据与生成数据优化自身“分辨能力”,生成器则通过生成让判别器难以区分的样本优化“生成能力”,且损失计算基于论文中WGAN的Wasserstein距离(替代传统GAN的JS散度),确保训练稳定。
- **步骤4:SVAE-WGAN联合损失更新(SVAE-WGAN Loss)**:将SVAE损失与WGAN判别器损失通过超参数\(\lambda\)加权融合,得到总损失\(L_{SVAE-WGAN} = L_{SVAE} + \lambda L_D\);随后基于该总损失反向传播,更新SVAE的编码器/解码器参数与WGAN的生成器/判别器参数,实现两大模块的协同优化,避免单一模块训练偏差。
三、算法1与论文理论的关联:
技术落地的桥梁 算法1并非独立流程,而是论文中SVAE-WGAN模块理论(如两层VAE结构、Wasserstein距离损失、联合优化逻辑)的“技术落地载体”:它将论文中的数学公式(如潜在变量的高斯分布假设、损失函数计算)转化为可执行的步骤,明确了“何时训练VAE”“何时训练WGAN”“如何平衡两者损失”,确保后续实验中SVAE-WGAN能稳定生成高质量合成数据,直接支撑论文中“缓解数据稀缺、提升定位精度”的核心目标,是连接理论设计与实验验证的关键环节。
图5 ADE模型结构
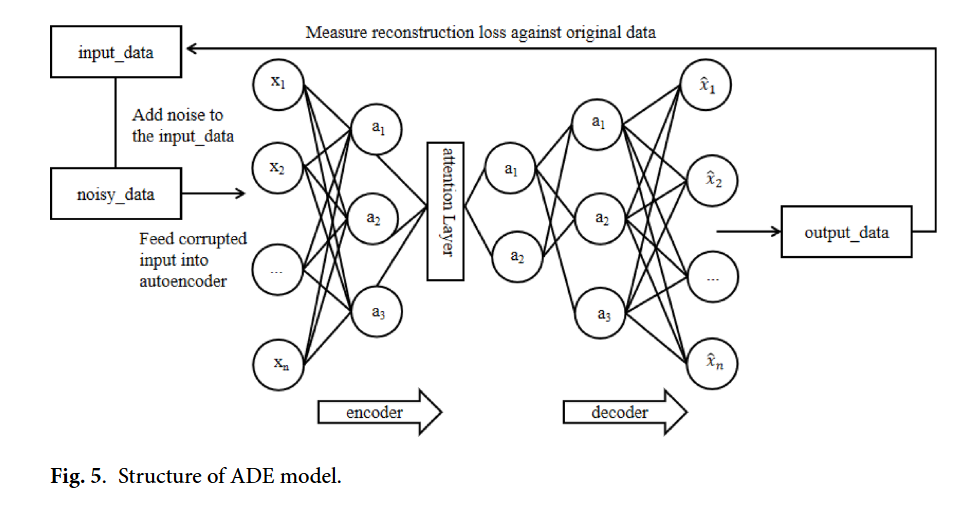
图5(Fig. 5)的标题为“Structure of ADE model”(ADE模型结构)**,其核心作用是直观拆解论文中核心特征提取模块——注意力去噪自编码器(ADE)的内部架构、数据处理链路及关键组件功能,是对图1(整体框架)和图2(核心结构)中“特征提取”环节的技术细节深化,清晰呈现ADE如何实现“去噪”与“关键特征聚焦”的双重目标,为后续DNN定位提供高质量特征输入,具体可从模块构成、数据流向及功能适配三方面展开:
从模块构成看,图5严格遵循论文中ADE“去噪自编码器(DAE)+注意力机制”的融合设计,明确划分出“噪声注入单元”“注意力编码器”“解码器”三大核心组件,且各组件的功能边界与连接关系清晰:噪声注入单元负责对输入数据添加扰动,模拟真实室内定位数据的噪声干扰;注意力编码器嵌入单头注意力机制(论文证实单头设计可降低计算复杂度、避免过拟合),既执行特征提取又为关键特征分配高权重;解码器则从含噪特征中重构去噪后的有效数据表示,三者共同构成“加噪-去噪-特征增强”的完整链路。
从数据流向看,图5以箭头标注全流程数据传递路径,精准匹配论文中ADE的工作逻辑:首先,原始室内定位数据(含真实数据与SVAE-WGAN生成的合成数据)输入模型,经“Add noise to the input data”环节注入噪声(噪声分布符合论文假设),形成“noisy data(含噪数据)”;随后,含噪数据输入“encoder(注意力编码器)”,编码器在提取深层特征的同时,通过注意力机制动态聚焦对定位关键的特征(如高辨识度的AP信号特征),过滤无关噪声;最后,编码器输出的潜在特征输入“decoder(解码器)”,重构生成“denoised output(去噪输出)”,既完成噪声过滤,又输出鲁棒的高维特征,为下游DNN定位任务提供输入,同时图中还标注“Measure reconstruction loss against original data”,体现通过对比重构输出与原始数据计算损失、优化模型参数的过程。
从功能适配看,图5直观体现ADE对论文核心问题的解决:针对“室内定位数据噪声干扰大”的痛点,通过“加噪-去噪”机制提升模型抗噪能力,确保在多径效应、信号衰减等复杂环境下仍能提取有效特征;针对“传统方法难以捕捉关键空间特征”的局限,通过注意力机制强化关键特征权重,避免无关信号干扰定位精度,最终实现“高质量特征提取”,直接支撑论文中“提升3D室内定位鲁棒性与准确性”的核心目标。
算法2 ADE(注意力机制去噪编码器)

算法2(Algorithm 2)的标题为“ADE”**,其核心作用是将论文提出的注意力去噪自编码器(ADE)的工作流程、参数设置与优化逻辑转化为步骤化的可执行流程,明确该模块如何通过“噪声注入-注意力特征提取-去噪重构”的闭环,从含噪室内定位数据中提取鲁棒、高辨识度的深层特征,为后续DNN定位预测提供高质量输入,具体可从“输入输出定义”“核心步骤拆解”“与论文理论的关联”三方面展开:
## 一、算法2的输入与输出:
匹配特征提取需求 算法2开篇明确界定了执行所需的输入条件与最终输出结果,严格贴合论文中ADE的设计目标:
- **输入(Inputs)**:包含三部分关键信息,一是室内定位数据\(X \in \mathbb{R}^{N \times d}\)(\(N\)为样本数,\(d\)为特征维度,如UJIIndoorLoc数据集的520维RSSI特征,且数据含真实样本与SVAE-WGAN生成的合成样本);二是超参数(平衡参数\(\lambda\)、学习率、批大小),其中\(\lambda\)用于平衡重构损失与正则化损失,保障特征提取精度与模型泛化性;三是噪声分布\(p_{noise}\)(论文未明确具体分布,通常为高斯噪声,模拟室内环境的信号波动干扰)。
- **输出(Outputs)**:最终输出“去噪后的输出数据\(\hat{X}\)”与“学习到的潜在特征\(z\)”,前者实现对含噪输入的噪声过滤,后者则是经注意力机制强化的关键空间特征,二者共同服务于下游定位任务,直接应对论文中“数据噪声干扰大、关键特征捕捉难”的痛点。
## 二、算法2的核心步骤:
分阶段实现特征优化 算法2将ADE的训练与特征提取流程拆解为“参数初始化”与“迭代训练”两部分,每一步骤均对应论文中ADE的技术逻辑与数学模型,形成“加噪-编码-解码-优化”的完整链路:
1. **参数初始化(Initialize Parameters)**:
首先初始化ADE的核心组件参数,包括含注意力机制的编码器(attention encoder)、解码器(decoder),以及注意力正则化相关参数。这一步确保模型从合理初始状态启动,避免后续训练中出现收敛困难或特征提取偏差,符合论文中“ADE需平衡去噪能力与特征聚焦能力”的设计要求。
2. **迭代训练(Training Steps)**:采用循环迭代方式逐步优化模型参数,每一轮迭代包含五个关键步骤,层层递进实现“抗噪”与“特征增强”:
- **步骤1:添加噪声(Add Noise)**:按照噪声分布\(p_{noise}\),对输入数据\(X\)注入噪声,生成含噪数据\(X_{noisy} = X + Noise\)。这一步模拟真实室内环境中信号受多径效应、衰减等干扰的场景,让模型在训练中学习从噪声中挖掘有效信息,对应论文中“DAE通过加噪-去噪提升抗噪性”的核心思想。
- **步骤2:注意力编码(Encode with Attention)**:将含噪数据\(X_{noisy}\)输入注意力编码器,通过公式\(z = Attention\_Encoder(X_{noisy})\)生成潜在特征\(z\)。编码器在提取特征过程中,嵌入论文设计的**单头注意力机制**(降低计算复杂度、避免过拟合),为对定位关键的特征(如高稳定性的AP信号特征)分配更高权重,过滤无关噪声与冗余信息,实现“关键特征聚焦”。
- **步骤3:解码重构(Decode)**:将潜在特征\(z\)输入解码器,通过\(\hat{X} = Decoder(z)\)生成去噪后的重构数据\(\hat{X}\)。解码器的核心目标是从经注意力强化的潜在特征中,恢复出与原始无噪数据分布一致的输出,完成“去噪”过程,对应论文中“ADE需同时实现去噪与特征保留”的需求。
- **步骤4:计算损失(Compute Loss)**:损失函数为重构损失与正则化损失的加权组合,公式为\(Loss_{ADE} = MSE(X, \hat{X}) + \lambda \cdot D_{KL}(q(z|X)||p(z))\)。其中,MSE(均方误差)衡量原始数据\(X\)与重构数据\(\hat{X}\)的差异,保障去噪精度;KL散度(\(D_{KL}\))约束潜在特征\(z\)的分布接近先验分布(如标准正态分布),避免模型过拟合,超参数\(\lambda\)平衡二者权重,完全匹配论文中ADE损失函数的定义。
- **步骤5:反向传播(Backpropagation)**:基于计算出的\(Loss_{ADE}\),通过反向传播算法更新编码器、解码器及注意力机制的所有参数,最小化损失值。这一步实现模型的迭代优化,确保ADE在训练中逐步提升“去噪能力”与“关键特征提取能力”,最终输出稳定、鲁棒的特征。
## 三、算法2与论文理论的关联:
技术落地的关键 算法2并非独立流程,而是论文中ADE模块理论设计的“技术落地载体”:它将论文中“ADE=DAE+注意力机制”的融合逻辑、单头注意力的选择依据、损失函数的数学公式,转化为可执行的步骤,明确了“何时加噪”“如何嵌入注意力”“怎样优化损失”,确保后续实验中ADE能稳定处理含噪定位数据,提取出支撑高精度定位的关键特征。同时,算法2的步骤设计也直接呼应了论文中ADE的性能优势——通过加噪步骤提升抗噪性,通过注意力编码强化特征辨识度,最终为DNN定位提供高质量输入,支撑论文中“提升3D室内定位精度与鲁棒性”的核心目标。