什么自查询?为什么在 RAG 中需要自查询?
自查询(Self-Query)是指当用户输入 模糊表述或隐含需求时,RAG 系统通过内部处理让模型自动解析用户查询中的隐含条件(如时间、作者、标签等元数据),生成结构化查询语句的过程。
比如用户说“2025年Rood的用户报告”,自查询会解析出两个条件:
- 语义匹配:用户报告
- 元数据过滤:作者=Rood、时间=2025
为什么在RAG中需要自查询?
因为用户提问往往包含模糊表述或隐含需求,传统向量检索可能忽略元数据导致结果偏差。自查询通过解析+过滤两步走,让检索同时满足语义相关性和元数据条件,解决“检索不准”的核心问题。
扩展知识
自查询的流程示意图
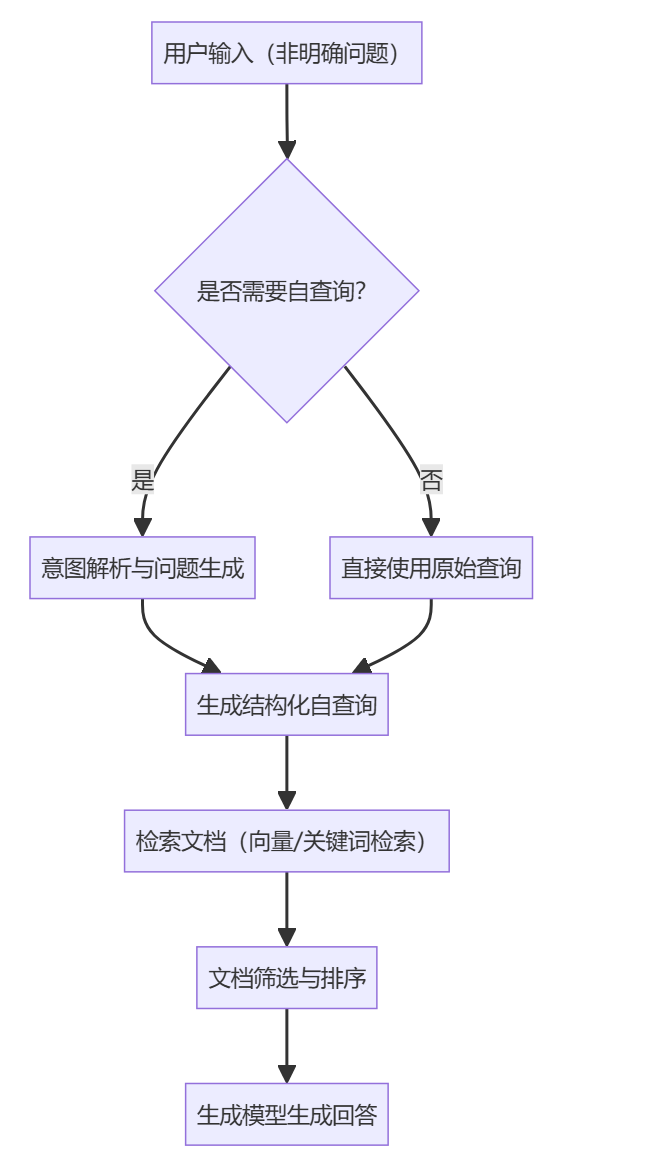
自查询简单模板示例
这是一份结合语义向量搜索与元数据过滤的自查询指令模板,【】内的占位符需替换为实际内容,并根据业务需求调整字段。
# 自查询指令生成器
**原始用户查询**:
【用户输入的自然语言描述,例如:“2025年李四团队撰写的金融风控报告”】**需要解析的元数据字段**:
1. 作者(author):【必填,支持模糊匹配,如“李四”或“*团队”】
2. 时间范围(date):【支持区间,如“>=2024”或“2023-2025”】
3. 标签(tags):【多选,如“金融/风控/合规”】
4. 权限过滤(permission):【可选,如“部门=财务部”】**混合检索条件**:
- 语义匹配关键词:【核心内容关键词,如“风险控制策略”“监管趋势”】
- 元数据过滤逻辑:【组合条件,例如“author=李四 AND date>=2024”】
- 结果排序规则:【例如“按时间倒序”或“按相关性评分排序”】**示例输出**(JSON格式):
```json
{"vector_search": {"query_text": "风险控制策略 监管趋势","embedding_model": "text-embedding-3-large" // 模型名称需指定},"metadata_filter": {"must": [{"field": "author", "operator": "=", "value": "李四"},{"field": "date", "operator": ">=", "value": "2025-01-01"}],"should": [{"field": "tags", "operator": "in", "value": ["金融", "风控"]}]},"options": {"limit": 10,"score_threshold": 0.75 // 相关性分数阈值}
}
自查询与查询扩展的区别
| 维度 | 自查询 | 查询扩展 |
|---|---|---|
| 核心目标 | 精准匹配“内容+元数据”双重条件(如作者、时间、标签) | 解决词不匹配问题,通过添加同义词、相关词提升查全率 |
| 技术手段 | ① 用LLM解析用户查询中的隐含元数据 ② 生成结构化查询(如SQL或过滤条件) | ① 基于同义词/语义词典扩展关键词 ② 利用LLM生成多样化查询变体 |
| 数据依赖 | 依赖知识库的元数据标注质量(如字段类型、格式) | 依赖语料库、用户日志或语义关系库(如WordNet) |
| 典型应用场景 | 带条件的专业搜索(如“2023年后发布的政府报告”) | 问答系统、文档检索(解决用户表述模糊问题) |
| 优点 | ① 精准过滤噪声数据 ② 支持权限控制(如部门权限过滤) | ① 提升语义覆盖范围 ② 减少因用户表述差异导致的漏检 |
| 缺点 | ① 需预定义元数据字段 ② 解析错误可能导致结果偏差 | ① 可能引入无关词导致噪声 ② 扩展策略需平衡查全率与查准率 |
| 典型技术方案 | ① LLM解析意图生成过滤条件 ② 向量数据库混合检索(如Qdrant、Milvus) | ① 基于全局/局部语义分析扩展 ② 伪相关反馈(如Rocchio算法) |
简单来说:
- 自查询:通过“解析+过滤”两步走,例如用户查询“2025年Rood的用户报告”会拆解为语义关键词(用户报告)和元数据(作者=Rood,时间=2025),再组合为结构化查询条件。它更适合精确过滤场景(如法律文档需限定颁布时间、电商商品需价格区间)
- 查询扩展:通过“生成+合并”策略,例如用户查询“大模型幻觉”可能扩展为“LLM生成内容真实性”“GPT输出偏差”等变体,合并多个检索结果提升覆盖。它更适合语义泛化场景(如用户输入“AI生成文本问题”,扩展为“大模型幻觉”“生成内容纠偏”等)
我们在实际使用 RAG 系统中,两者可协同优化。例如先通过自查询过滤出“2025年的金融报告”,再通过查询扩展补充“风险控制”“监管政策”等关键词,提升结果全面性。