Agent 设计与上下文工程- 03 Workflow 设计模式(下)
学习目标:掌握 Orchestrator-Workers 和 Evaluator-Optimizer 两种高级 Workflow 模式,理解动态任务分解和迭代优化的设计方法
前置知识:理解 Prompt Chaining、Routing、Parallelization 三种基础模式
预计时间:35-45 分钟
上一节我们学了三种基础 Workflow 模式,它们的共同特点是:任务分解和执行路径都是预定义的。但有些场景下,你没法提前知道要做哪些子任务,这个时候就需要更灵活的模式。
这节课我们聊两种高级模式:Orchestrator-Workers 和 Evaluator-Optimizer。它们虽然还是 Workflow(流程由代码控制),但引入了一定程度的动态性。
Orchestrator-Workers:动态任务编排
Orchestrator-Workers 模式的核心是:中央 LLM 动态分解任务,委派给工作 LLM,然后合成结果。
我第一次遇到这个模式是在做代码重构工具的时候。用户输入一个需求,比如"把所有 API 调用改成异步",你没法提前知道要修改哪些文件,每个文件怎么改。这个时候就需要一个 Orchestrator 来动态规划。
为什么需要动态分解
在某些场景下,子任务的数量和内容取决于具体输入。比如代码修改任务,可能涉及 3 个文件,也可能涉及 30 个文件,每个文件的修改方式也不同。如果用固定的 Prompt Chain,你没法覆盖所有情况。
Orchestrator-Workers 的思路是:让一个 LLM(Orchestrator)先分析任务,决定要做哪些子任务,然后分配给多个 Worker LLM 并行执行,最后汇总结果。
def orchestrator_workers(user_request):# 步骤1:Orchestrator 分析任务plan = orchestrator_llm.generate(prompt=f"""分析以下需求,制定执行计划:
{user_request}返回 JSON 格式的计划:
{{"subtasks": [{{"id": "task1", "description": "...", "dependencies": []}},{{"id": "task2", "description": "...", "dependencies": ["task1"]}}]
}}""")# 步骤2:根据依赖关系执行子任务results = {}for subtask in plan.subtasks:# 等待依赖任务完成wait_for_dependencies(subtask.dependencies, results)# Worker 执行子任务result = worker_llm.execute(prompt=f"执行以下任务:{subtask.description}\n\n可用上下文:{get_context(subtask, results)}")results[subtask.id] = result# 步骤3:Orchestrator 合成最终结果final_output = orchestrator_llm.generate(prompt=f"基于以下子任务结果,生成最终输出:\n{results}")return final_output看到了吗?Orchestrator 负责规划和协调,Worker 负责执行具体任务。这样做的好处是,系统可以适应不同复杂度的输入,而不需要修改代码。
💡
Orchestrator-Workers 和 Parallelization 的区别在于:Parallelization 的子任务是预定义的,而 Orchestrator-Workers 的子任务是动态生成的。前者适合已知的批量操作,后者适合未知的复杂任务。
Orchestrator 的设计要点
Orchestrator 是整个模式的核心,它的设计直接影响系统效果。我总结了几个关键点:
计划要结构化。让 Orchestrator 返回 JSON 格式的计划,而不是自然语言描述。这样你可以程序化地解析和执行,不会因为格式问题出错。
支持依赖关系。有些子任务之间有依赖,比如任务 B 需要任务 A 的结果。Orchestrator 需要明确指出这些依赖,执行的时候要按顺序来。
限制子任务数量。不要让 Orchestrator 生成太多子任务,否则执行时间会很长。我的经验是,5-10 个子任务比较合适,超过 15 个就要考虑是不是可以进一步抽象。
提供上下文。Worker 执行子任务的时候,需要知道整体目标和前面任务的结果。Orchestrator 要负责准备这些上下文。
真实案例:代码重构工具
假设用户要求"把所有 API 调用改成异步"。Orchestrator 会先扫描代码库,找出所有涉及 API 调用的文件,然后为每个文件生成一个子任务:"修改 file_a.py 中的 API 调用"。Worker 并行执行这些子任务,修改各自的文件。最后 Orchestrator 检查所有修改,生成一个总结报告。
Worker 的设计要点
Worker 相对简单,它只需要专注于执行单个子任务。但也有几个注意事项:
Worker 的 prompt 要通用。因为 Worker 可能被分配各种各样的子任务,prompt 不能写得太具体。通常的做法是,让 Orchestrator 提供详细的任务描述,Worker 只负责执行。
Worker 要能处理失败。如果某个子任务失败了,Worker 应该返回错误信息,而不是让整个流程崩溃。Orchestrator 可以根据错误信息决定是重试还是调整计划。
Worker 之间可以共享工具。比如多个 Worker 都需要读取文件,可以共享一个文件读取工具,避免重复实现。
⚠️
Orchestrator-Workers 的成本和延迟都比较高,因为涉及多次 LLM 调用(Orchestrator 规划 + 多个 Worker 执行 + Orchestrator 合成)。只在任务确实复杂而且无法预测的时候使用这个模式。
适用产品场景
Orchestrator-Workers 适合那些任务复杂度高、子任务不固定的产品场景。
代码助手类产品。比如 GitHub Copilot Workspace、Cursor 这类工具,用户提出一个需求("重构这个模块"),系统需要先分析代码库,找出涉及的文件,然后为每个文件生成修改方案。这个过程中,子任务的数量和内容完全取决于代码库的实际情况,没法提前定义。
复杂查询分析。像 Perplexity Pro 这类深度搜索产品,用户问一个复杂问题("比较中美欧的新能源政策"),系统需要先把问题分解成多个子问题(中国政策、美国政策、欧盟政策、对比分析),然后并行搜索和分析,最后合成答案。问题越复杂,分解出的子任务越多。
项目规划工具。比如 Notion AI 的项目助手,用户输入项目目标,系统自动分解成任务列表、时间线、资源分配。每个项目的复杂度不同,可能分解出 5 个任务,也可能是 50 个,这个动态性正好适合 Orchestrator-Workers。
从产品设计角度,使用这个模式要注意两点。第一,让用户看到规划过程。Orchestrator 生成计划后,先展示给用户确认,而不是直接执行。这样用户知道系统要做什么,也可以及时纠正。第二,提供进度反馈。因为 Worker 是并行执行的,要实时显示每个子任务的状态("正在分析 file_a.py"),让用户感知到系统在工作,而不是卡住了。
Evaluator-Optimizer:迭代优化的循环
Evaluator-Optimizer 模式解决的是另一个问题:如何让 LLM 的输出质量更高。
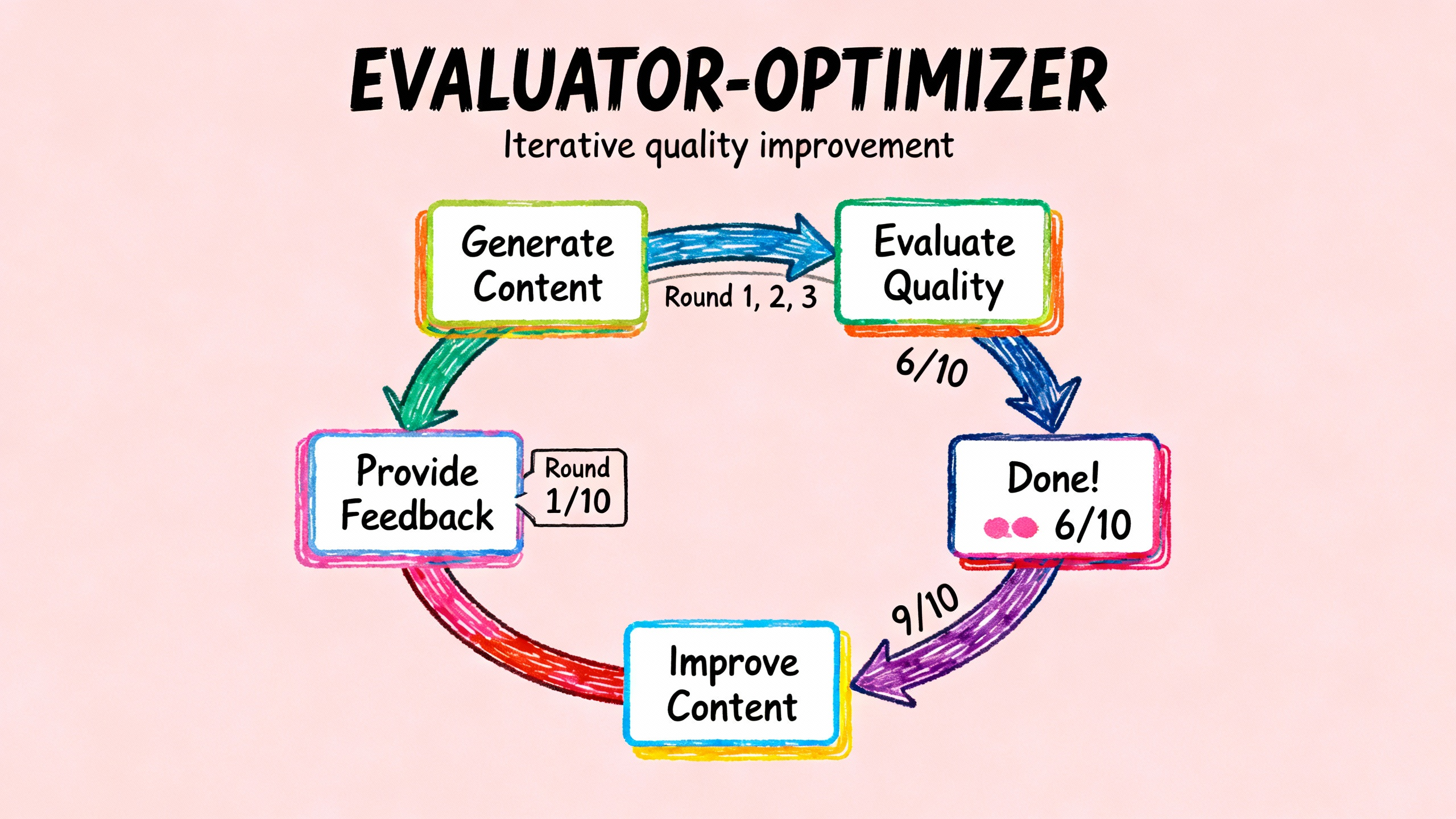
它的核心思想是:一个 LLM 生成内容,另一个 LLM 评估并提供反馈,然后第一个 LLM 根据反馈优化,如此循环直到满意。就像人写文章,写完之后自己审阅,发现问题再修改,反复打磨。
为什么需要迭代优化
LLM 第一次生成的内容往往不够完美。可能遗漏了某些要点,可能表达不够清晰,可能有事实错误。如果有明确的评估标准,而且迭代确实能改进质量,那 Evaluator-Optimizer 就很有用。
def evaluator_optimizer(initial_content, max_iterations=3):content = initial_contentfor i in range(max_iterations):# Evaluator 评估当前内容evaluation = evaluator_llm.evaluate(prompt=f"""评估以下内容的质量:
{content}评估维度:
1. 完整性(是否覆盖所有要点)
2. 准确性(是否有事实错误)
3. 清晰度(是否易于理解)返回评分(1-10)和具体建议。""")# 如果评分足够高,结束循环if evaluation.score >= 8:break# Optimizer 根据反馈优化内容content = optimizer_llm.improve(prompt=f"""改进以下内容:
{content}评估反馈:
{evaluation.feedback}请根据反馈进行针对性改进。""")return content这个循环的关键是,Evaluator 要提供具体的、可操作的反馈,而不是泛泛而谈。比如"第二段缺少数据支撑"比"内容不够充实"更有用。
Evaluator 的设计要点
Evaluator 是整个模式的核心,它的评估质量直接决定优化效果。
评估标准要明确。告诉 Evaluator 从哪些维度评估,每个维度的标准是什么。比如文学翻译可以从"忠实原文"、"语言流畅"、"文化适配"三个维度评估。
反馈要具体。不要只说"不好",要指出具体哪里不好,怎么改进。可以要求 Evaluator 返回结构化的反馈,比如:
{"score": 6,"issues": [{"location": "第二段", "problem": "缺少数据支撑", "suggestion": "补充市场份额数据"},{"location": "第三段", "problem": "逻辑跳跃", "suggestion": "增加过渡句"}]
}设置停止条件。不要无限循环,要么设置最大迭代次数,要么设置评分阈值。我的经验是,3-5 次迭代通常够用,再多也提升不大。
🎯
Evaluator-Optimizer 特别适合有明确质量标准的创作任务,比如文学翻译、技术文档、营销文案。但对于主观性很强的任务(比如创意写作),效果可能不明显。
Optimizer 的设计要点
Optimizer 的任务是根据反馈改进内容。关键是让它专注于反馈指出的问题,而不是重写整个内容。
可以在 prompt 里明确要求:"只修改有问题的部分,保持其他部分不变"。这样可以避免引入新的问题。
而且要提供足够的上下文。Optimizer 需要知道原始内容、评估反馈、以及改进目标,这样才能做出有针对性的修改。
真实案例:文学翻译优化
假设你要把英文小说翻译成中文。第一次翻译可能比较生硬,某些习语翻译不当。Evaluator 指出:"第 5 段的 'kick the bucket' 直译为'踢桶子'不合适,应该用'去世'或'归西'这样的中文表达"。Optimizer 根据这个反馈修改第 5 段,保持其他部分不变。经过 2-3 轮优化,翻译质量明显提升。
Evaluator-Optimizer 的变体
这个模式有几种变体,适合不同场景。
自我评估:用同一个 LLM 既生成又评估。这样可以节省成本,但评估质量可能不如独立的 Evaluator。
多 Evaluator:用多个 Evaluator 从不同角度评估,然后汇总反馈。比如一个关注内容质量,一个关注格式规范,一个关注事实准确性。
人类参与:在某些关键迭代中,让人类来做 Evaluator。这样可以确保质量,但会增加延迟。
⚠️
Evaluator-Optimizer 的成本很高,因为每次迭代都需要两次 LLM 调用(评估 + 优化)。要慎重评估是否值得。如果第一次生成的质量已经足够好,就不要强行迭代。
适用产品场景
Evaluator-Optimizer 适合那些对输出质量要求高、有明确评估标准的产品场景。
内容创作工具。比如 Jasper、Copy.ai 这类营销文案生成工具,用户需要高质量的广告文案或社交媒体内容。第一次生成可能不够吸引人,通过 Evaluator 评估("标题是否抓眼球"、"CTA 是否清晰"),然后优化,可以明显提升转化率。我见过一个案例,某电商公司用这个模式生成商品描述,转化率提升了 18%。
翻译产品。像 DeepL、Google Translate 的高级模式,对于文学作品或专业文档的翻译,第一遍翻译可能有生硬的地方。Evaluator 检查术语一致性、文化适配性,然后 Optimizer 针对性改进。这对于付费翻译服务特别有价值,用户愿意为高质量买单。
代码审查助手。比如 Codium AI 的 PR-Agent,自动审查代码提交。第一遍生成的审查意见可能不够具体,Evaluator 检查是否指出了潜在 bug、性能问题、可读性问题,Optimizer 补充更详细的建议和示例代码。这样开发者才会觉得审查有价值。
产品设计上有几个关键点。第一,让用户看到迭代过程。不要黑盒优化,而是展示每一轮的改进("第 1 版"、"第 2 版 - 优化了标题"),让用户感受到质量在提升。第二,让用户控制迭代次数。有些用户追求完美,愿意等 5 轮优化;有些用户要快速结果,2 轮就够了。给用户一个滑块选择"速度优先"还是"质量优先"。第三,提供对比视图。并排展示优化前后的版本,让用户直观看到改进点,这比单独展示最终版本更有说服力。
两种模式的组合使用
Orchestrator-Workers 和 Evaluator-Optimizer 可以组合使用,形成更强大的 Workflow。
比如在代码生成任务中,可以先用 Orchestrator-Workers 并行生成多个模块的代码,然后用 Evaluator-Optimizer 对每个模块进行质量优化。或者先用 Evaluator-Optimizer 优化需求描述,确保需求清晰准确,然后再用 Orchestrator-Workers 分解和执行。
关键是理解每种模式的优势和局限,根据具体任务选择合适的组合方式。
• • •
🎯
核心要点:Orchestrator-Workers 通过中央 LLM 动态分解任务,适合无法预测子任务的复杂场景。Evaluator-Optimizer 通过迭代反馈循环提升输出质量,适合有明确评估标准的创作任务。这两种模式成本较高,只在简单模式无法满足需求的时候使用。五种 Workflow 模式(Prompt Chaining、Routing、Parallelization、Orchestrator-Workers、Evaluator-Optimizer)可以灵活组合,构建复杂的 AI 系统。
下一节预告
到目前为止,我们学的都是 Workflow,流程由代码控制。下一节我们会深入学习 Agent 模式,看看当 LLM 自己控制流程的时候,系统架构会有什么不同,以及如何设计可靠的 Agent。