自然语言处理实战——基于IMDB影评的情感分析
目录
一、整体架构与核心目标
二、模块 1:环境配置(基础设置)
2.1 功能概述
2.2 代码逻辑
2.3 数学原理
三、模块 2:数据预处理(IMDB 数据集处理)
3.1 功能概述
3.2 代码逻辑
3.3 数学公式与推导
3.3.1 词索引调整映射
3.3.2 序列对齐(截断 / 填充)
四、模块 3:贝叶斯优化预热(快速定位优质超参数)
4.1 功能概述
4.2 代码逻辑
4.2.1 超参数空间定义
4.2.2 目标函数与评估
4.3 数学公式与推导
4.3.1 贝叶斯优化核心:高斯过程(GP)建模
4.3.2 目标函数转换
4.3.3 期望改进(EI):平衡探索与利用
五、模块 4:奖励函数与超参数剪枝
5.1 功能概述
5.2 代码逻辑
5.3 数学公式与推导
5.3.1 奖励函数定义
5.3.2 剪枝惩罚的数学意义
六、模块 5:NLP 强化学习环境(NLP_Hparam_Env)
6.1 功能概述
6.2 代码逻辑
6.3 数学公式与推导
6.3.1 状态定义
6.3.2 嵌入矩阵初始化
6.3.3 LSTM 模型的维度转换
七、模块 6:PPO 智能体(PPOAgent)
7.1 功能概述
7.2 代码逻辑
7.2.1 智能体初始化与网络构建
7.2.2 超参数与动作的双向映射
7.2.3 PPO 核心训练逻辑
7.3 数学公式与推导
7.3.1 动作空间与超参数的双向映射
7.3.2 动作采样与对数概率
7.3.3 PPO 核心:折扣回报与优势函数
7.3.4 PPO 剪辑损失
八、模块 7:贝叶斯 + PPO 联合训练
8.1 功能概述
8.2 代码逻辑
8.2.1 多进程轨迹任务
8.2.2 联合训练主流程
8.3 数学原理
8.3.1 动态轨迹长度
8.3.2 多进程并行的效率提升
九、模块 8:结果验证与可视化
9.1 功能概述
9.2 代码逻辑
9.3 结果分析的数学意义
十、基于IMDB影评的情感分析的完整Python代码展示
十一、整体流程总结
一、整体架构与核心目标
本文实现的实战项目是一套智能超参数优化框架,针对 IMDB 影评情感分析任务(二分类:正面 / 负面影评),通过「贝叶斯优化预热 + PPO 强化学习迭代」的两阶段策略,自动搜索兼顾「高准确率」与「快训练速度」的最优超参数组合。
二、模块 1:环境配置(基础设置)
2.1 功能概述
配置训练环境以提升计算效率,避免资源冲突,核心是混合精度训练与线程控制。
2.2 代码逻辑
# 混合精度训练:用FP16计算加速,FP32保存梯度(避免下溢)
mixed_precision.set_global_policy('mixed_float16')
# 限制OpenMP线程数:避免多进程训练时线程竞争,降低CPU占用
os.environ["OMP_NUM_THREADS"] = "1"
2.3 数学原理
- 混合精度训练:设原始 FP32 浮点数为
,FP16 浮点数为
,映射关系为
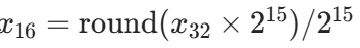 (15 位尾数)。优势:FP16 的内存占用仅为 FP32 的 1/2,计算速度提升 1.5~2 倍,且通过
(15 位尾数)。优势:FP16 的内存占用仅为 FP32 的 1/2,计算速度提升 1.5~2 倍,且通过LossScaleOptimizer缩放损失(如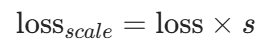 ,s为缩放因子),避免 FP16 梯度下溢。
,s为缩放因子),避免 FP16 梯度下溢。 - 线程控制:多进程训练时,每个进程的 OpenMP 线程数设为 1,避免Total Threads=进程数×OMP线程数超出 CPU 核心数,导致上下文切换开销增加。
三、模块 2:数据预处理(IMDB 数据集处理)
3.1 功能概述
将原始文本影评转换为模型可输入的固定长度数值序列,拆分训练 / 验证 / 测试集,为后续超参数评估提供标准化数据。
3.2 代码逻辑
def prepare_nlp_data(vocab_size=10000, max_seq_len=200):# 1. 加载IMDB数据集(仅保留前vocab_size个高频词)(x_train, y_train), (x_test, y_test) = imdb.load_data(num_words=vocab_size)# 2. 词索引调整:预留特殊符号(PAD=0, START=1, UNK=2)word_index = imdb.get_word_index()word_index = {k: (v + 3) for k, v in word_index.items()} # 原始索引+3word_index["<PAD>"] = 0word_index["<START>"] = 1word_index["<UNK>"] = 2# 3. 序列对齐:截断/填充至max_seq_lenx_train = pad_sequences(x_train, maxlen=max_seq_len, padding='pre', truncating='pre')x_test = pad_sequences(x_test, maxlen=max_seq_len, padding='pre', truncating='pre')# 4. 拆分训练子集(20k)与验证集(5k)x_train_sub = x_train[:20000]y_train_sub = y_train[:20000]x_val = x_train[20000:]y_val = y_train[20000:]return (x_train_sub, y_train_sub, x_val, y_val, x_test, y_test, word_index)# 全局参数:解决索引超出问题(EMBED_INPUT_DIM = 10000 + 3)
VOCAB_SIZE = 10000
EMBED_INPUT_DIM = VOCAB_SIZE + 3 # 覆盖索引0~10002
MAX_SEQ_LEN = 200
x_train_sub, y_train_sub, x_val, y_val, x_test, y_test, word_index = prepare_nlp_data(VOCAB_SIZE, MAX_SEQ_LEN)
3.3 数学公式与推导
3.3.1 词索引调整映射
原始 IMDB 词索引从 1 开始,为预留 3 个特殊符号,需对索引进行偏移:
设原始词w的索引为v(v≥1),调整后索引为v′,则:

3.3.2 序列对齐(截断 / 填充)
设原始影评序列长度为n,对齐后长度为MAX_SEQ_LEN=200,对齐后序列为x′′,则:

其中x′为原始偏移后的词索引序列(长度n),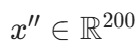 (固定长度向量)。
(固定长度向量)。
四、模块 3:贝叶斯优化预热(快速定位优质超参数)
4.1 功能概述
通过高斯过程(GP) 建模超参数与验证集准确率的关系,快速搜索 15 轮,定位优质超参数区域,为 PPO 提供初始化(避免 PPO 初期盲目探索)。
4.2 代码逻辑
4.2.1 超参数空间定义
bayes_space = {"lr": Real(1e-4, 1e-2, "log-uniform"), # 学习率(对数均匀:更贴合学习率分布)"batch_size": Categorical([16, 32, 64]), # 批次大小(离散)"lstm_units": Categorical([32, 64, 128]), # LSTM单元数(离散)"dropout_rate": Real(0.2, 0.4), # Dropout率(连续:防止过拟合)"embed_dim": Categorical([64, 128, 256]), # 嵌入维度(离散)"lstm_layers": Categorical([1, 2]), # LSTM层数(离散)"optimizer": Categorical([0, 1]) # 优化器(0=Adam,1=SGD)
}
# 转换为skopt所需的列表格式
bayes_space_list = [Real(1e-4, 1e-2, "log-uniform", name="lr"),Categorical([16, 32, 64], name="batch_size"),Categorical([32, 64, 128], name="lstm_units"),Real(0.2, 0.4, name="dropout_rate"),Categorical([64, 128, 256], name="embed_dim"),Categorical([1, 2], name="lstm_layers"),Categorical([0, 1], name="optimizer")
]
4.2.2 目标函数与评估
# 目标函数:gp_minimize是最小化,故将准确率转为负数
@use_named_args(bayes_space_list)
def objective(**params):return -bayes_evaluate(params)# 超参数评估:构建模型、训练1轮、返回验证集准确率
def bayes_evaluate(hparams):embed_dim = hparams["embed_dim"]# 嵌入矩阵:随机正态初始化(均值0,标准差0.01)embedding_matrix = np.random.normal(loc=0.0, scale=0.01, size=(EMBED_INPUT_DIM, embed_dim))# 构建LSTM模型model = Sequential([Embedding(input_dim=EMBED_INPUT_DIM, output_dim=embed_dim, weights=[embedding_matrix], trainable=True),Dropout(hparams["dropout_rate"]),*[LSTM(hparams["lstm_units"], return_sequences=True), Dropout(hparams["dropout_rate"])]*(hparams["lstm_layers"]-1),LSTM(hparams["lstm_units"], return_sequences=False),Dropout(hparams["dropout_rate"]),Dense(1, activation='sigmoid', dtype='float32')])# 混合精度优化器optimizer = Adam(hparams["lr"]) if hparams["optimizer"]==0 else SGD(hparams["lr"], momentum=0.9)optimizer = mixed_precision.LossScaleOptimizer(optimizer)model.compile(optimizer=optimizer, loss='binary_crossentropy', metrics=['accuracy'])# 快速训练(1轮)history = model.fit(x_train_sub, y_train_sub, batch_size=hparams["batch_size"], epochs=1, validation_data=(x_val, y_val), verbose=0)return history.history['val_accuracy'][-1]# 执行贝叶斯优化(15轮)
bayes_result = gp_minimize(objective, bayes_space_list, n_calls=15, random_state=42, verbose=1)
# 提取Top3最优超参数
best_bayes_hparams = []
for i in np.argsort(bayes_result.func_vals)[:3]:params = {name: bayes_result.x_iters[i][idx] for idx, name in enumerate(["lr", "batch_size", "lstm_units", "dropout_rate", "embed_dim", "lstm_layers", "optimizer"])}best_bayes_hparams.append(params)
4.3 数学公式与推导
4.3.1 贝叶斯优化核心:高斯过程(GP)建模
贝叶斯优化通过 GP 建模超参数h与目标函数f(h)(此处为验证集准确率)的关系,即:f(h)∼GP(m(h),k(h,h′))
- 均值函数m(h):默认设为 0(无先验知识时,假设目标函数均值为 0);
- 协方差函数k(h,h′):用Matern 核(对非平滑函数拟合更好,适合超参数优化),公式:
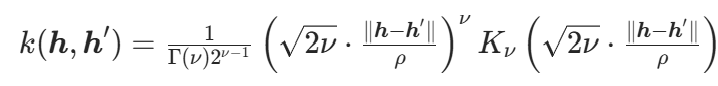
其中:
- ν:平滑参数(默认 1.5,对应一阶可导函数);
- ρ:长度尺度(控制核函数的 “影响范围”,ρ越小,超参数微小变化对f(h)影响越大);
- Kν:ν阶修正贝塞尔函数(描述超参数相似性对目标函数相关性的影响);
- ∥h−h′∥:超参数向量h与h′的欧氏距离(需先标准化超参数至同一尺度)。
4.3.2 目标函数转换
因skopt.gp_minimize仅支持最小化目标函数,而我们需最大化准确率,故将目标函数转换为:obj(h)=−Acc(h)其中Acc(h)为超参数h对应的验证集准确率(Acc(h)∈[0,1]),故obj(h)∈[−1,0],最小化obj(h)等价于最大化Acc(h)。
4.3.3 期望改进(EI):平衡探索与利用
贝叶斯优化每轮选择 “期望改进最大” 的超参数h进行评估,期望改进(EI) 定义为:EI(h)=E[max(0,obj(h∗)−obj(h))]其中h∗为当前最优超参数(obj(h∗)=min{obj(h1),...,obj(ht)},t为已评估轮次)。
EI 公式推导:由 GP 建模,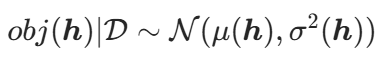 (D为已评估数据,μ为后验均值,
(D为已评估数据,μ为后验均值,![]() 为后验方差)。令z=obj(h),则:
为后验方差)。令z=obj(h),则:
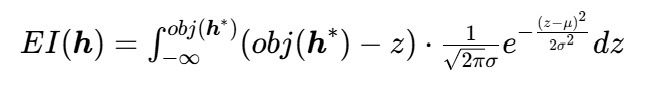
令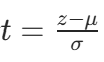 (标准化),则z=μ+σt,dz=σdt,代入得:
(标准化),则z=μ+σt,dz=σdt,代入得:
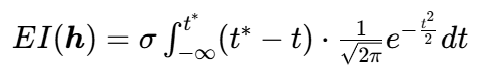
其中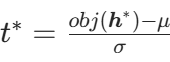 。拆分积分并利用正态分布的 CDF(
。拆分积分并利用正态分布的 CDF(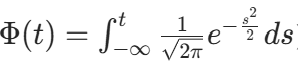 )和 PDF(
)和 PDF(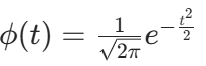 ),最终得:
),最终得:
EI(h)=(obj(h∗)−μ)Φ(t∗)+σϕ(t∗)
物理意义:
- 当μ<obj(h∗)(新超参数可能更优):Φ(t∗)>0,第一项为正,贡献改进;
- 当σ大(超参数区域不确定性高):第二项为正,鼓励 “探索” 未知区域;
- 当σ小(超参数区域确定):第二项接近 0,仅 “利用” 已知优质区域。
五、模块 4:奖励函数与超参数剪枝
5.1 功能概述
定义自适应奖励函数(平衡准确率与训练时间),并对物理意义不合理的超参数组合施加惩罚,引导 PPO 搜索有效超参数。
5.2 代码逻辑
# 超参数剪枝:对不合理组合加惩罚
def hparam_pruning_penalty(hparams):penalty = 0.0if hparams["optimizer"] == 1 and hparams["lr"] > 5e-3: # SGD+高学习率(易发散)penalty += 10.0if hparams["batch_size"] == 64 and hparams["lstm_layers"] == 2: # 大批次+深层(内存占用过高)penalty += 5.0if hparams["embed_dim"] == 64 and hparams["lstm_layers"] == 2: # 低嵌入维+深层(表达能力不足)penalty += 3.0return penalty# 自适应奖励权重:前期重准确率,后期重效率
def get_reward_weights(epoch, total_epochs):progress = epoch / total_epochs # 训练进度(0~1)if progress < 0.5:return 0.9, 0.1 # 前期:准确率权重0.9,时间权重0.1else:acc_weight = 0.9 - (progress - 0.5) * 0.6 # 后期准确率权重递减time_weight = 0.1 + (progress - 0.5) * 0.6 # 后期时间权重递增return acc_weight, time_weight
5.3 数学公式与推导
5.3.1 奖励函数定义
奖励r需综合 “准确率贡献”“时间成本” 和 “剪枝惩罚”,公式:
r=(Acc×100×α)−(T×0.1×β)−P
其中:
- Acc:验证集准确率(Acc∈[0,1]),×100 是为了放大量级(使奖励在 0~100 范围,与时间成本平衡);
- T:训练时间(秒),×0.1 是为了缩小量级(避免时间对奖励的影响过大);
- α,β:自适应权重(α+β=1),由训练进度progress决定:
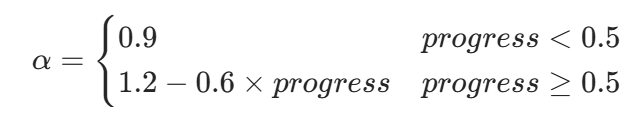 β=1−α,例:当progress=0.5(中期),α=0.9,β=0.1;当progress=1.0(末期),α=0.6,β=0.4,符合 “前期探索准确率,后期优化效率” 的逻辑;
β=1−α,例:当progress=0.5(中期),α=0.9,β=0.1;当progress=1.0(末期),α=0.6,β=0.4,符合 “前期探索准确率,后期优化效率” 的逻辑; - P:剪枝惩罚(P≥0),由超参数组合合理性决定(不合理组合P增大,奖励降低)。
5.3.2 剪枝惩罚的数学意义
剪枝惩罚P是启发式约束,数学上可表示为:
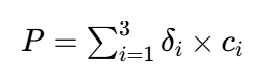
其中为指示函数(
=1若满足第i个不合理条件,否则 0),
为对应惩罚系数(10.0、5.0、3.0),目的是排除 “训练不稳定”“资源浪费”“表达能力不足” 的超参数组合。
六、模块 5:NLP 强化学习环境(NLP_Hparam_Env)
6.1 功能概述
实现强化学习的 “环境” 接口,定义状态空间“动作空间”(超参数组合)和状态转移规则(超参数→训练→奖励→新状态),为 PPO 智能体提供交互场景。
6.2 代码逻辑
class NLP_Hparam_Env:def __init__(self, nlp_epochs=2):self.nlp_epochs = nlp_epochs # 每次step训练的轮次self.state_dim = 8 # 状态维度:7超参数+1奖励# 嵌入矩阵:随机正态初始化(均值0,标准差0.01)def build_embedding_matrix(self, embed_dim):return np.random.normal(loc=0.0, scale=0.01, size=(EMBED_INPUT_DIM, embed_dim))# 构建LSTM模型(与bayes_evaluate一致,复用逻辑)def build_nlp_model(self, hparams):embed_dim = hparams["embed_dim"]embedding_matrix = self.build_embedding_matrix(embed_dim)model = Sequential([Embedding(input_dim=EMBED_INPUT_DIM, output_dim=embed_dim, weights=[embedding_matrix], trainable=True),Dropout(hparams["dropout_rate"]),*[LSTM(hparams["lstm_units"], return_sequences=True), Dropout(hparams["dropout_rate"])]*(hparams["lstm_layers"]-1),LSTM(hparams["lstm_units"], return_sequences=False),Dropout(hparams["dropout_rate"]),Dense(1, activation='sigmoid', dtype='float32')])optimizer = Adam(hparams["lr"]) if hparams["optimizer"]==0 else SGD(hparams["lr"], momentum=0.9)optimizer = mixed_precision.LossScaleOptimizer(optimizer)model.compile(optimizer=optimizer, loss='binary_crossentropy', metrics=['accuracy'])return model# 核心交互:输入超参数,返回新状态、奖励、准确率、训练时间def step(self, hparams, epoch, total_epochs):start_time = time.time()early_stopping = EarlyStopping(monitor='val_loss', patience=1, restore_best_weights=True) # 防止过拟合model = self.build_nlp_model(hparams)history = model.fit(x_train_sub, y_train_sub, batch_size=hparams["batch_size"],epochs=self.nlp_epochs, validation_data=(x_val, y_val),callbacks=[early_stopping], verbose=0)T = time.time() - start_time # 训练时间Acc = history.history['val_accuracy'][-1] # 验证集准确率alpha, beta = get_reward_weights(epoch, total_epochs) # 自适应权重P = hparam_pruning_penalty(hparams) # 剪枝惩罚r = (Acc * 100 * alpha) - (T * 0.1 * beta) - P # 计算奖励# 新状态:7超参数 + 1奖励(8维向量)next_state = np.array([hparams["lr"], hparams["batch_size"], hparams["lstm_units"],hparams["dropout_rate"], hparams["embed_dim"], hparams["lstm_layers"],hparams["optimizer"], r])return next_state, r, Acc, T# 重置环境:返回初始状态(默认超参数+奖励0)def reset(self):initial_hparams = {"lr": 1e-3, "batch_size": 32, "lstm_units": 64,"dropout_rate": 0.3, "embed_dim": 128, "lstm_layers": 1, "optimizer": 0}return np.array([initial_hparams["lr"], initial_hparams["batch_size"], initial_hparams["lstm_units"],initial_hparams["dropout_rate"], initial_hparams["embed_dim"], initial_hparams["lstm_layers"],initial_hparams["optimizer"], 0.0])
6.3 数学公式与推导
6.3.1 状态定义
环境状态s是8 维连续向量,表示为:
s=[lr,batch_size,lstm_units,dropout_rate,embed_dim,lstm_layers,optimizer,]
其中:
- 前 7 维为超参数(lr∈[1e−4,1e−2],batch_size∈{16,32,64},等);
- 第 8 维rprev为上一步的奖励(初始状态为 0);
- 状态空间S⊆R8(因部分超参数是离散的,实际为混合空间)。
6.3.2 嵌入矩阵初始化
嵌入矩阵E \in \mathbb{R}^{\text{EMBED_INPUT_DIM} \times \text{embed_dim}}(10003×embed_dim),每个元素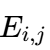 (第i个词的第j维向量)服从正态分布:
(第i个词的第j维向量)服从正态分布:
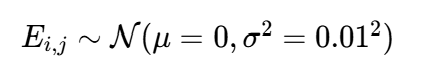
选择依据:小标准差(0.01)确保初始嵌入向量接近 0,避免训练初期梯度爆炸,同时保留随机多样性。
6.3.3 LSTM 模型的维度转换
以 “1 层 LSTM” 为例,模型各层的维度转换(设批次大小为B):
- 嵌入层:X∈RB×200(批次序列)→ E \cdot X^T \in \mathbb{R}^{B \times 200 \times \text{embed_dim}}(序列→词向量序列);
- Dropout 层:维度不变(B \times 200 \times \text{embed_dim}),按dropout_rate随机失活神经元;
- LSTM 层:输入B \times 200 \times \text{embed_dim} → 输出B \times \text{lstm_units}(仅保留最后一步输出);
- Dense 层:输入B \times \text{lstm_units} → 输出B×1(sigmoid 激活,预测概率)。
对于 “2 层 LSTM”,第一层 LSTM 的return_sequences=True,输出为B \times 200 \times \text{lstm_units},作为第二层 LSTM 的输入,最终输出仍为B \times \text{lstm_units}。
七、模块 6:PPO 智能体(PPOAgent)
7.1 功能概述
实现PPO(Proximal Policy Optimization)算法,负责:
- 超参数与动作空间的双向映射;
- 策略网络(输出动作分布)与价值网络(估计状态价值)的构建与训练;
- 动作采样与轨迹优化(通过剪辑损失稳定策略更新)。
7.2 代码逻辑
7.2.1 智能体初始化与网络构建
class PPOAgent:def __init__(self, state_dim, action_dim, bayes_hparams, clip_ratio=0.2, gamma=0.99, lr=3e-4):self.state_dim = state_dim # 状态维度(8)self.action_dim = action_dim # 动作维度(7)self.clip_ratio = clip_ratio # PPO剪辑系数(0.2,控制策略更新幅度)self.gamma = gamma # 折扣因子(0.99,未来奖励的衰减系数)self.lr = lr # PPO网络学习率(3e-4)# 构建策略网络(输出动作的均值和标准差)self.actor = self.build_actor()# 构建价值网络(估计状态价值)self.critic = self.build_critic()# 用贝叶斯Top3超参数初始化策略网络均值(加速收敛)self._init_actor_with_bayes(bayes_hparams)# 优化器(Adam)self.actor_optimizer = tf.keras.optimizers.Adam(learning_rate=lr)self.critic_optimizer = tf.keras.optimizers.Adam(learning_rate=lr)# 策略网络:输入状态,输出动作的均值(tanh激活→[-1,1])和log_std(线性激活)def build_actor(self):inputs = tf.keras.Input(shape=(self.state_dim,))x = tf.keras.layers.Dense(256, activation='tanh')(inputs)x = tf.keras.layers.Dense(128, activation='tanh')(x)mean = tf.keras.layers.Dense(self.action_dim, activation='tanh')(x) # 均值∈[-1,1]log_std = tf.keras.layers.Dense(self.action_dim, activation='linear')(x) # log_std无约束std = tf.exp(log_std) # 标准差>0(指数激活)return tf.keras.Model(inputs=inputs, outputs=[mean, std])# 价值网络:输入状态,输出状态价值(线性激活,无约束)def build_critic(self):inputs = tf.keras.Input(shape=(self.state_dim,))x = tf.keras.layers.Dense(256, activation='tanh')(inputs)x = tf.keras.layers.Dense(128, activation='tanh')(x)value = tf.keras.layers.Dense(1, activation='linear')(x) # 价值∈ℝreturn tf.keras.Model(inputs=inputs, outputs=value)
7.2.2 超参数与动作的双向映射
# 超参数→动作:将超参数映射到[-1,1]的连续动作空间
def hparams_to_action(self, hparams):action = np.zeros(self.action_dim)# 逐个超参数线性缩放(公式:a = 2*(v-low)/(high-low) - 1)action[0] = self._scale_hparam(hparams["lr"], (1e-4, 1e-2)) # lraction[1] = self._scale_hparam(hparams["batch_size"], (16, 64)) # batch_sizeaction[2] = self._scale_hparam(hparams["lstm_units"], (32, 128)) # lstm_unitsaction[3] = self._scale_hparam(hparams["dropout_rate"], (0.2, 0.4)) # dropout_rateaction[4] = self._scale_hparam(hparams["embed_dim"], (64, 256)) # embed_dimaction[5] = self._scale_hparam(hparams["lstm_layers"], (1, 2)) # lstm_layersaction[6] = self._scale_hparam(hparams["optimizer"], (0, 1)) # optimizerreturn action# 线性缩放函数:v∈[low,high] → a∈[-1,1]
def _scale_hparam(self, value, bounds):low, high = boundsreturn 2 * (value - low) / (high - low) - 1# 动作→超参数:将[-1,1]动作映射回原始超参数空间,离散超参数取最近候选
def action_to_hparams(self, action):# 线性缩放回原始范围(公式:v = low + (high-low)*(a+1)/2)lr = self._scale_action(action[0], (1e-4, 1e-2))batch_continuous = self._scale_action(action[1], (16, 64))lstm_units_continuous = self._scale_action(action[2], (32, 128))dropout_rate = self._scale_action(action[3], (0.2, 0.4))embed_continuous = self._scale_action(action[4], (64, 256))lstm_layers_continuous = self._scale_action(action[5], (1, 2))optimizer_continuous = self._scale_action(action[6], (0, 1))# 离散超参数:取最近的候选值batch_size = self._continuous_to_discrete(batch_continuous, [16, 32, 64])lstm_units = self._continuous_to_discrete(lstm_units_continuous, [32, 64, 128])embed_dim = self._continuous_to_discrete(embed_continuous, [64, 128, 256])lstm_layers = int(round(lstm_layers_continuous)) # 1或2optimizer = int(round(optimizer_continuous)) # 0或1return {"lr": lr, "batch_size": batch_size, "lstm_units": lstm_units,"dropout_rate": dropout_rate, "embed_dim": embed_dim,"lstm_layers": lstm_layers, "optimizer": optimizer}# 线性缩放函数:a∈[-1,1] → v∈[low,high]
def _scale_action(self, action, bounds):low, high = boundsreturn low + (high - low) * (action + 1) / 2# 连续值→离散值:取最近的候选值
def _continuous_to_discrete(self, value, options):return min(options, key=lambda x: abs(x - value))
7.2.3 PPO 核心训练逻辑
# 动作采样:从策略网络输出的正态分布中采样动作,计算对数概率
def sample_action(self, state):state = state[np.newaxis, :] # 扩展批次维度((8,)→(1,8))mean, std = self.actor.predict(state, verbose=0) # 策略网络输出:均值(1,7),标准差(1,7)# 从正态分布N(mean, std²)采样动作action = np.random.normal(loc=mean, scale=std, size=mean.shape)action = np.clip(action, -1.0, 1.0) # 剪辑动作至[-1,1](防止超范围)# 计算动作的对数概率(正态分布对数概率公式)log_prob = -0.5 * np.sum(np.log(2 * np.pi * std**2) + (action - mean)**2 / std**2, axis=1)return action[0], log_prob[0] # 返回动作(7,)和对数概率(1,)# 计算折扣回报(用于价值网络训练)
def _compute_returns(self, rewards, values):returns = []last_value = values[-1] if values else 0.0 # 最后一个状态的价值(.bootstrap)# 从后往前累积折扣回报for reward in reversed(rewards):last_value = reward + self.gamma * last_value # 折扣回报:r_t + γ*V(s_{t+1})returns.insert(0, last_value) # 插入到列表前端(恢复顺序)return returns# PPO训练:输入轨迹,更新策略网络和价值网络
def train(self, trajectories):# 1. 收集所有轨迹的状态、动作、对数概率、奖励、价值states, actions, old_log_probs, rewards, values = [], [], [], [], []for traj in trajectories:traj_states, traj_actions, traj_log_probs, traj_rewards = traj# 价值网络估计每个状态的价值traj_values = [self.critic.predict(s[np.newaxis, :], verbose=0)[0][0] for s in traj_states]# 计算折扣回报traj_returns = self._compute_returns(traj_rewards, traj_values)# 累积到全局列表states.extend(traj_states)actions.extend(traj_actions)old_log_probs.extend(traj_log_probs)rewards.extend(traj_rewards)values.extend(traj_returns)# 2. 计算优势函数(策略更新的目标)advantages = np.array(values) - np.mean(values) # 中心化advantages = advantages / (np.std(advantages) + 1e-8) # 标准化(稳定训练)# 3. 转换为TensorFlow张量states = tf.convert_to_tensor(states, dtype=tf.float32) # (N,8)actions = tf.convert_to_tensor(actions, dtype=tf.float32) # (N,7)old_log_probs = tf.convert_to_tensor(old_log_probs, dtype=tf.float32) # (N,)returns = tf.convert_to_tensor(values, dtype=tf.float32) # (N,)# 4. 多轮更新(PPO采用多轮小批量更新,提升数据利用率)for _ in range(10):# 更新策略网络(剪辑损失)with tf.GradientTape() as tape:mean, std = self.actor(states, training=True) # 新策略输出均值和标准差std = tf.exp(std) # 确保标准差>0# 计算新策略下动作的对数概率new_log_probs = -0.5 * tf.reduce_sum(tf.math.log(2 * np.pi * std**2) + (actions - mean)**2 / std**2,axis=1)# 策略比率:r(θ) = π_θ(a|s) / π_θ_old(a|s) = exp(new_log_prob - old_log_prob)ratio = tf.exp(new_log_probs - old_log_probs)# PPO剪辑损失:min(r(θ)*A, clip(r(θ), 1-ε, 1+ε)*A),ε=clip_ratio=0.2surr1 = ratio * advantagessurr2 = tf.clip_by_value(ratio, 1 - self.clip_ratio, 1 + self.clip_ratio) * advantagesactor_loss = -tf.reduce_mean(tf.minimum(surr1, surr2)) # 负号:最小化→最大化策略回报# 梯度下降更新策略网络actor_grads = tape.gradient(actor_loss, self.actor.trainable_variables)self.actor_optimizer.apply_gradients(zip(actor_grads, self.actor.trainable_variables))# 更新价值网络(MSE损失:最小化价值估计与折扣回报的误差)with tf.GradientTape() as tape:new_values = self.critic(states, training=True) # 新价值估计critic_loss = tf.reduce_mean(tf.square(returns - new_values)) # MSE损失# 梯度下降更新价值网络critic_grads = tape.gradient(critic_loss, self.critic.trainable_variables)self.critic_optimizer.apply_gradients(zip(critic_grads, self.critic.trainable_variables))# 用贝叶斯Top3超参数初始化策略网络均值
def _init_actor_with_bayes(self, bayes_hparams):avg_action = np.zeros(self.action_dim)# 计算Top3超参数对应的动作的平均值for hp in bayes_hparams:action = self.hparams_to_action(hp)avg_action += action / len(bayes_hparams)# 初始化策略网络均值层的偏置为平均动作(加速收敛)mean_layer = self.actor.layers[-2] # 均值输出层(倒数第二层)weights = mean_layer.get_weights() # [kernel, bias]weights[1] = avg_action # 偏置项设为平均动作mean_layer.set_weights(weights)print(f"PPO策略网络初始化完成,初始均值动作:{avg_action}")
7.3 数学公式与推导
7.3.1 动作空间与超参数的双向映射
-
超参数→动作:线性缩放至 [-1,1],公式:设超参数v∈[low,high],动作a∈[−1,1],则:
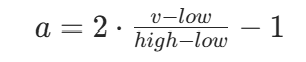 推导:当v=low时,a=−1;当v=high时,a=1;中间值线性映射。
推导:当v=low时,a=−1;当v=high时,a=1;中间值线性映射。 -
动作→超参数:线性缩放回原始范围,公式:
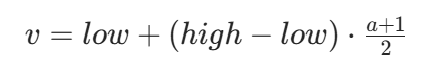 推导:当a=−1时,v=low;当a=1时,v=high,与上述映射可逆。
推导:当a=−1时,v=low;当a=1时,v=high,与上述映射可逆。 -
离散超参数处理:对连续映射结果vcont,取最接近的候选值vdiscrete,公式:
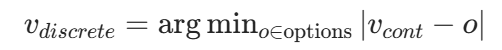 例:
例: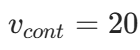 ,options=[16,32,64],则
,options=[16,32,64],则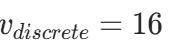 (最小距离 4)。
(最小距离 4)。
7.3.2 动作采样与对数概率
策略网络输出动作的均值μ(s) 和标准差σ(s),动作a从正态分布采样:
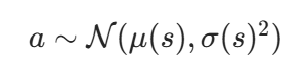
动作的对数概率(用于 PPO 的策略比率计算)公式:正态分布的 PDF 为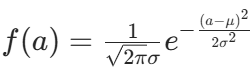 ,取对数得:
,取对数得:
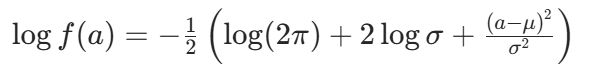
对 7 维动作,总对数概率为各维度对数概率之和:
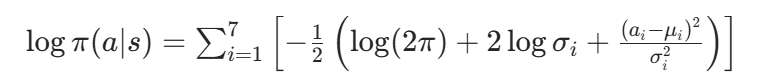
代码中简化为:
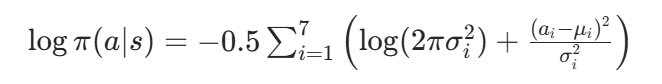
与上述公式等价(因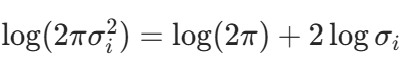 )。
)。
7.3.3 PPO 核心:折扣回报与优势函数
-
折扣回报:用于估计状态的 “真实价值”(价值网络的目标),考虑未来奖励的衰减,公式:设轨迹的奖励序列为
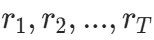 ,价值网络估计的最后一个状态价值为
,价值网络估计的最后一个状态价值为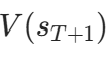 ,则第t步的折扣回报为:
,则第t步的折扣回报为: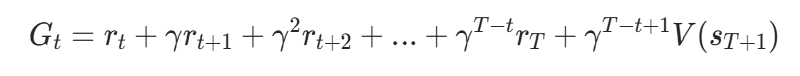 代码中通过 “从后往前累积” 计算:
代码中通过 “从后往前累积” 计算: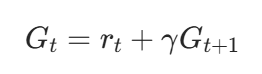 其中
其中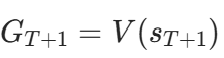 (bootstrap,用价值网络估计未来价值)。
(bootstrap,用价值网络估计未来价值)。 -
优势函数:衡量 “动作a比平均动作好多少”,是策略更新的核心目标,公式:
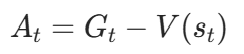 其中
其中是价值网络对状态
的估计价值。代码中对优势函数进行标准化:
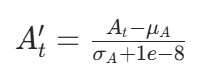 其中
其中是优势函数的均值,
是标准差,标准化可避免梯度爆炸,稳定策略更新。
7.3.4 PPO 剪辑损失
PPO 通过 “剪辑策略比率” 限制策略更新幅度,避免更新过大导致训练不稳定,剪辑损失公式: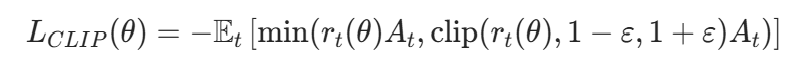 其中:
其中:
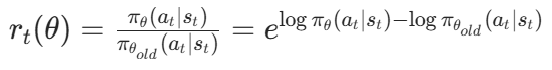 (策略比率,新旧策略的概率比);
(策略比率,新旧策略的概率比);- ε=0.2(剪辑系数,控制更新幅度);
- 负号:因优化器是最小化,故将 “最大化优势” 转为 “最小化负优势”。
损失函数解析:
- 当
>0(动作at是优势动作):min(
- 当
- 最终通过梯度下降最小化LCLIP,实现策略的稳定更新。
八、模块 7:贝叶斯 + PPO 联合训练
8.1 功能概述
整合贝叶斯优化的初始化优势与 PPO 的迭代优化能力,通过多进程并行训练加速轨迹生成,逐步优化超参数,记录最优结果。
8.2 代码逻辑
8.2.1 多进程轨迹任务
# 多进程任务:处理单个轨迹的训练与状态转移
def parallel_nlp_trajectory(args):hparams_list, epoch, total_epochs, nlp_epochs, traj_length = argsenv = NLP_Hparam_Env(nlp_epochs=nlp_epochs)state = env.reset()traj_states, traj_actions, traj_rewards = [], [], []# 生成轨迹(长度traj_length)for step in range(traj_length):# 取当前步的超参数(超出列表时用最后一个)hparams = hparams_list[step] if step < len(hparams_list) else hparams_list[-1]# 环境交互:超参数→新状态、奖励、准确率、时间next_state, reward, val_acc, train_time = env.step(hparams, epoch, total_epochs)# 记录轨迹traj_states.append(state)traj_actions.append(hparams)traj_rewards.append(reward)state = next_state# 记录最后一步的准确率和时间if step == traj_length - 1:final_val_acc = val_accfinal_time = train_timereturn traj_states, traj_actions, traj_rewards, final_val_acc, final_time
8.2.2 联合训练主流程
# 超参数配置
RL_EPOCHS = 20 # PPO总轮次
NUM_TRAJECTORIES = 8 # 并行轨迹数(多进程数)
NLP_EPOCHS = 2 # 每次step训练的NLP轮次
STATE_DIM = 8 # 状态维度
ACTION_DIM = 7 # 动作维度
PPO_LR = 3e-4 # PPO网络学习率
GAMMA = 0.99 # 折扣因子# 1. 初始化PPO智能体(用贝叶斯Top3超参数初始化)
agent = PPOAgent(state_dim=STATE_DIM,action_dim=ACTION_DIM,bayes_hparams=best_bayes_hparams,lr=PPO_LR,gamma=GAMMA
)# 2. 训练记录
reward_history = [] # 平均奖励历史
best_reward = -np.inf # 最优奖励
best_hparams = None # 最优超参数
best_val_acc = 0.0 # 最优验证集准确率
best_train_time = np.inf # 最优训练时间# 3. 多进程池(并行处理轨迹)
pool = Pool(processes=NUM_TRAJECTORIES)# 4. PPO迭代训练(20轮)
print("\n开始贝叶斯+PPO联合训练(共{}轮)...".format(RL_EPOCHS))
for epoch in range(RL_EPOCHS):# 动态轨迹长度:前期1步,后期3步(progress≥0.5)traj_length = get_trajectory_length(epoch, RL_EPOCHS)trajectories = [] # 存储所有轨迹(状态、动作、对数概率)# 4.1 生成轨迹(8个并行轨迹)for _ in range(NUM_TRAJECTORIES):traj_states, traj_actions, traj_log_probs = [], [], []state = NLP_Hparam_Env().reset() # 重置环境for _ in range(traj_length):# PPO智能体采样动作action, log_prob = agent.sample_action(state)# 动作→超参数hparams = agent.action_to_hparams(action)# 记录轨迹(状态、动作、对数概率)traj_states.append(state)traj_actions.append(action)traj_log_probs.append(log_prob)# 生成下一个状态(用于轨迹延续)env = NLP_Hparam_Env(nlp_epochs=1)next_state, _, _, _ = env.step(hparams, epoch, RL_EPOCHS)state = next_state# 轨迹添加到列表(状态、动作、对数概率)trajectories.append((traj_states, traj_actions, traj_log_probs))# 4.2 并行执行轨迹训练(多进程处理)parallel_args = []for traj in trajectories:traj_states, traj_actions, traj_log_probs = traj# 动作→超参数列表(用于多进程任务)hparams_list = [agent.action_to_hparams(a) for a in traj_actions]# 组装多进程参数:(超参数列表, 当前轮次, 总轮次, NLP训练轮次, 轨迹长度)parallel_args.append((hparams_list, epoch, RL_EPOCHS, NLP_EPOCHS, traj_length))# 多进程执行,tqdm显示进度results = list(tqdm(pool.imap(parallel_nlp_trajectory, parallel_args),total=NUM_TRAJECTORIES,desc=f"Epoch {epoch + 1}/{RL_EPOCHS}(轨迹长度={traj_length})"))# 4.3 解析结果,组装完整轨迹(状态、动作、对数概率、奖励)full_trajectories = []for i in range(NUM_TRAJECTORIES):# 多进程返回:轨迹状态、超参数、奖励、准确率、时间traj_states, traj_actions_hp, traj_rewards, val_acc, train_time = results[i]# 原始轨迹:动作、对数概率traj_actions = trajectories[i][1]traj_log_probs = trajectories[i][2]# 组装完整轨迹(状态、动作、对数概率、奖励)full_trajectories.append((traj_states, traj_actions, traj_log_probs, traj_rewards))# 更新最优记录(奖励最大)final_reward = traj_rewards[-1]if final_reward > best_reward:best_reward = final_rewardbest_hparams = traj_actions_hp[-1] # 最后一步的超参数best_val_acc = val_accbest_train_time = train_time# 4.4 训练PPO智能体(更新策略网络和价值网络)agent.train(full_trajectories)# 4.5 记录平均奖励all_rewards = [r for traj in full_trajectories for r in traj[3]]avg_reward = np.mean(all_rewards)reward_history.append(avg_reward)print(f"Epoch {epoch + 1}:平均奖励={avg_reward:.2f},最优奖励={best_reward:.2f}")# 5. 关闭多进程池
pool.close()
pool.join()
8.3 数学原理
8.3.1 动态轨迹长度
轨迹长度T随训练进度progress动态调整,公式:

依据:前期 PPO 策略不稳定,短轨迹可减少累积误差;后期策略接近最优,长轨迹可捕捉多步决策的长期奖励。
8.3.2 多进程并行的效率提升
设单轨迹训练时间为t,串行训练N个轨迹的时间为N×t;多进程并行(N个进程)的时间约为t(忽略进程调度开销),时间复杂度从O(Nt)降至O(t),显著提升训练效率。
九、模块 8:结果验证与可视化
9.1 功能概述
训练完成后,用最优超参数训练完整模型,与默认超参数模型对比测试集准确率和训练时间,可视化 PPO 训练的奖励历史,验证优化效果。
9.2 代码逻辑
# 用最优超参数训练完整模型(5轮)
def train_full_nlp(hparams, epochs=5):env = NLP_Hparam_Env()embedding_matrix = env.build_embedding_matrix(hparams["embed_dim"])model = Sequential([Embedding(input_dim=EMBED_INPUT_DIM, output_dim=hparams["embed_dim"], weights=[embedding_matrix], trainable=True),Dropout(hparams["dropout_rate"]),*[LSTM(hparams["lstm_units"], return_sequences=True), Dropout(hparams["dropout_rate"])]*(hparams["lstm_layers"]-1),LSTM(hparams["lstm_units"], return_sequences=False),Dropout(hparams["dropout_rate"]),Dense(1, activation='sigmoid', dtype='float32')])optimizer = Adam(hparams["lr"]) if hparams["optimizer"]==0 else SGD(hparams["lr"], momentum=0.9)optimizer = mixed_precision.LossScaleOptimizer(optimizer)model.compile(optimizer=optimizer, loss='binary_crossentropy', metrics=['accuracy'])# 训练并计时start_time = time.time()model.fit(x_train_sub, y_train_sub, batch_size=hparams["batch_size"],epochs=epochs, validation_data=(x_val, y_val), verbose=1)full_time = time.time() - start_time# 测试集评估test_acc = model.evaluate(x_test, y_test, verbose=0)[1]return test_acc, full_time# 1. 输出最优超参数
print("\n" + "=" * 50)
print("贝叶斯+PPO优化完成!最优超参数:")
for k, v in best_hparams.items():print(f" {k}: {v}")
print(f"最优验证集准确率:{best_val_acc:.4f},训练时间:{best_train_time:.2f}秒")# 2. 测试集验证:最优模型 vs 默认模型
print("\n" + "=" * 50)
# 最优模型测试
rl_test_acc, rl_time = train_full_nlp(best_hparams, epochs=5)
print(f"贝叶斯+PPO模型:测试集准确率={rl_test_acc:.4f},训练时间={rl_time:.2f}秒")
# 默认模型测试(固定超参数)
default_hparams = {"lr": 1e-3, "batch_size": 32, "lstm_units": 64,"dropout_rate": 0.3, "embed_dim": 128, "lstm_layers": 1, "optimizer": 0}
default_test_acc, default_time = train_full_nlp(default_hparams, epochs=5)
print(f"默认模型:测试集准确率={default_test_acc:.4f},训练时间={default_time:.2f}秒")# 3. 可视化奖励历史
plt.figure(figsize=(10, 4))
plt.plot(range(1, RL_EPOCHS + 1), reward_history, marker='o', color='b', label='贝叶斯+PPO')
plt.axvline(x=10, color='r', linestyle='--', label='轨迹长度从1→3') # 进度0.5的位置(20轮的第10轮)
plt.xlabel('PPO Epochs')
plt.ylabel('Average Reward')
plt.title('Reward History (Bayesian Initialization + PPO)')
plt.legend()
plt.grid(alpha=0.3)
plt.show()
9.3 结果分析的数学意义
- 准确率提升率:衡量优化效果,公式:提升率=默认模型测试准确率最优模型测试准确率−默认模型测试准确率×100%若提升率 > 0,说明贝叶斯 + PPO 优化有效。
- 时间节省率:衡量训练效率,公式:节省率=默认模型训练时间默认模型训练时间−最优模型训练时间×100%若节省率 > 0,说明最优超参数在保证准确率的同时,缩短了训练时间。
- 奖励曲线趋势:若奖励曲线随 PPO 轮次递增,说明 PPO 策略在持续优化(策略网络逐渐学会选择更优超参数);轨迹长度切换(第 10 轮)后,奖励可能出现跳跃或加速上升,验证动态轨迹长度的合理性。
十、基于IMDB影评的情感分析的完整Python代码展示
import os
import time
import numpy as np
import tensorflow as tf
from tensorflow.keras.datasets import imdb
from tensorflow.keras.preprocessing.sequence import pad_sequences
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Embedding, LSTM, Dense, Dropout
from tensorflow.keras.callbacks import EarlyStopping
from tensorflow.keras.optimizers import Adam, SGD
from tensorflow.keras import mixed_precision
import matplotlib.pyplot as plt
from tqdm import tqdm
import multiprocessing as mp
from multiprocessing import Pool
from skopt import BayesSearchCV
from skopt.space import Real, Integer, Categorical
from skopt import gp_minimize
from skopt.utils import use_named_args# 混合精度训练配置
mixed_precision.set_global_policy('mixed_float16')
os.environ["OMP_NUM_THREADS"] = "1"# NLP数据预处理
def prepare_nlp_data(vocab_size=10000, max_seq_len=200):(x_train, y_train), (x_test, y_test) = imdb.load_data(num_words=vocab_size)word_index = imdb.get_word_index()# 调整索引:预留0(PAD)、1(START)、2(UNK),原始索引+3word_index = {k: (v + 3) for k, v in word_index.items()}word_index["<PAD>"] = 0word_index["<START>"] = 1word_index["<UNK>"] = 2# 统一序列长度x_train = pad_sequences(x_train, maxlen=max_seq_len, padding='pre', truncating='pre')x_test = pad_sequences(x_test, maxlen=max_seq_len, padding='pre', truncating='pre')# 拆分训练集/验证集x_train_sub = x_train[:20000]y_train_sub = y_train[:20000]x_val = x_train[20000:]y_val = y_train[20000:]return (x_train_sub, y_train_sub, x_val, y_val, x_test, y_test, word_index)# 全局数据与关键参数
VOCAB_SIZE = 10000
EMBED_INPUT_DIM = VOCAB_SIZE + 3 # 覆盖0~10002的所有索引
MAX_SEQ_LEN = 200
x_train_sub, y_train_sub, x_val, y_val, x_test, y_test, word_index = prepare_nlp_data(VOCAB_SIZE, MAX_SEQ_LEN)# 贝叶斯优化的超参数空间
bayes_space = {"lr": Real(1e-4, 1e-2, "log-uniform"), # 学习率(对数均匀分布)"batch_size": Categorical([16, 32, 64]), # 批次大小"lstm_units": Categorical([32, 64, 128]), # LSTM单元数"dropout_rate": Real(0.2, 0.4), # Dropout率"embed_dim": Categorical([64, 128, 256]), # Embedding维度"lstm_layers": Categorical([1, 2]), # LSTM层数"optimizer": Categorical([0, 1]) # 0=Adam, 1=SGD
}# 贝叶斯优化的评估函数
def bayes_evaluate(hparams):"""评估单个超参数组合的性能(用于贝叶斯优化)"""embed_dim = hparams["embed_dim"]# 强制转换为整数lstm_units = int(hparams["lstm_units"])lstm_layers = int(hparams["lstm_layers"])# 1. 生成嵌入矩阵embedding_matrix = np.random.normal(loc=0.0, scale=0.01, size=(EMBED_INPUT_DIM, embed_dim))# 2. 构建模型model = Sequential()model.add(Embedding(input_dim=EMBED_INPUT_DIM,output_dim=embed_dim,weights=[embedding_matrix],trainable=True))model.add(Dropout(hparams["dropout_rate"]))# 多层LSTMfor _ in range(lstm_layers - 1):model.add(LSTM(units=lstm_units, return_sequences=True))model.add(Dropout(hparams["dropout_rate"]))model.add(LSTM(units=lstm_units, return_sequences=False))model.add(Dropout(hparams["dropout_rate"]))model.add(Dense(units=1, activation='sigmoid', dtype='float32'))# 优化器(混合精度适配)if hparams["optimizer"] == 0:optimizer = Adam(learning_rate=hparams["lr"])else:optimizer = SGD(learning_rate=hparams["lr"], momentum=0.9)optimizer = mixed_precision.LossScaleOptimizer(optimizer)model.compile(optimizer=optimizer,loss='binary_crossentropy',metrics=['accuracy'])# 3. 快速训练(1轮)history = model.fit(x_train_sub, y_train_sub,batch_size=hparams["batch_size"],epochs=1,validation_data=(x_val, y_val),verbose=0)return history.history['val_accuracy'][-1]# 转换为skopt所需的列表格式空间
bayes_space_list = [Real(1e-4, 1e-2, "log-uniform", name="lr"),Categorical([16, 32, 64], name="batch_size"),Categorical([32, 64, 128], name="lstm_units"),Real(0.2, 0.4, name="dropout_rate"),Categorical([64, 128, 256], name="embed_dim"),Categorical([1, 2], name="lstm_layers"),Categorical([0, 1], name="optimizer")
]@use_named_args(bayes_space_list)
def objective(**params):"""贝叶斯优化目标函数(负准确率,因为gp_minimize是最小化)"""return -bayes_evaluate(params)# 运行贝叶斯优化(15轮搜索)
print("开始贝叶斯优化预热(15轮)...")
bayes_result = gp_minimize(objective,bayes_space_list,n_calls=15,random_state=42,verbose=1
)# 提取最优超参数(前3名)
best_bayes_hparams = []
for i in np.argsort(bayes_result.func_vals)[:3]:params = {name: bayes_result.x_iters[i][idx] for idx, name in enumerate(["lr", "batch_size", "lstm_units", "dropout_rate", "embed_dim", "lstm_layers", "optimizer"])}best_bayes_hparams.append(params)print("\n贝叶斯优化找到的Top3超参数:")
for i, hp in enumerate(best_bayes_hparams):print(f"第{i+1}名:{hp},准确率:{-bayes_result.func_vals[np.argsort(bayes_result.func_vals)[i]]:.4f}")# 超参数剪枝与奖励函数
def hparam_pruning_penalty(hparams):penalty = 0.0if hparams["optimizer"] == 1 and hparams["lr"] > 5e-3:penalty += 10.0if hparams["batch_size"] == 64 and hparams["lstm_layers"] == 2:penalty += 5.0if hparams["embed_dim"] == 64 and hparams["lstm_layers"] == 2:penalty += 3.0return penaltydef get_reward_weights(epoch, total_epochs):progress = epoch / total_epochsif progress < 0.5:return 0.9, 0.1else:acc_weight = 0.9 - (progress - 0.5) * 0.6time_weight = 0.1 + (progress - 0.5) * 0.6return acc_weight, time_weightdef get_trajectory_length(epoch, total_epochs):progress = epoch / total_epochsreturn 1 if progress < 0.5 else 3# NLP环境类
class NLP_Hparam_Env:def __init__(self, nlp_epochs=2):self.nlp_epochs = nlp_epochsself.state_dim = 8 # 7超参数+1奖励def build_embedding_matrix(self, embed_dim):# 嵌入矩阵维度:(EMBED_INPUT_DIM, embed_dim)return np.random.normal(loc=0.0, scale=0.01, size=(EMBED_INPUT_DIM, embed_dim))def build_nlp_model(self, hparams):embed_dim = hparams["embed_dim"]# 强制转换为整数lstm_units = int(hparams["lstm_units"])lstm_layers = int(hparams["lstm_layers"])embedding_matrix = self.build_embedding_matrix(embed_dim)model = Sequential()model.add(Embedding(input_dim=EMBED_INPUT_DIM,output_dim=embed_dim,weights=[embedding_matrix],trainable=True))model.add(Dropout(hparams["dropout_rate"]))# 多层LSTM(使用转换后的整数units)for _ in range(lstm_layers - 1):model.add(LSTM(units=lstm_units, return_sequences=True))model.add(Dropout(hparams["dropout_rate"]))model.add(LSTM(units=lstm_units, return_sequences=False))model.add(Dropout(hparams["dropout_rate"]))model.add(Dense(units=1, activation='sigmoid', dtype='float32'))if hparams["optimizer"] == 0:optimizer = Adam(learning_rate=hparams["lr"])else:optimizer = SGD(learning_rate=hparams["lr"], momentum=0.9)optimizer = mixed_precision.LossScaleOptimizer(optimizer)model.compile(optimizer=optimizer, loss='binary_crossentropy', metrics=['accuracy'])return modeldef step(self, hparams, epoch, total_epochs):start_time = time.time()early_stopping = EarlyStopping(monitor='val_loss', patience=1, restore_best_weights=True)model = self.build_nlp_model(hparams)history = model.fit(x_train_sub, y_train_sub,batch_size=hparams["batch_size"],epochs=self.nlp_epochs,validation_data=(x_val, y_val),callbacks=[early_stopping],verbose=0)train_time = time.time() - start_timeval_acc = history.history['val_accuracy'][-1]acc_weight, time_weight = get_reward_weights(epoch, total_epochs)base_reward = (val_acc * 100 * acc_weight) - (train_time * 0.1 * time_weight)penalty = hparam_pruning_penalty(hparams)reward = base_reward - penaltynext_state = np.array([hparams["lr"], hparams["batch_size"], hparams["lstm_units"],hparams["dropout_rate"], hparams["embed_dim"], hparams["lstm_layers"],hparams["optimizer"], reward])return next_state, reward, val_acc, train_timedef reset(self):initial_hparams = {"lr": 1e-3, "batch_size": 32, "lstm_units": 64,"dropout_rate": 0.3, "embed_dim": 128, "lstm_layers": 1, "optimizer": 0}return np.array([initial_hparams["lr"], initial_hparams["batch_size"], initial_hparams["lstm_units"],initial_hparams["dropout_rate"], initial_hparams["embed_dim"], initial_hparams["lstm_layers"],initial_hparams["optimizer"], 0.0])# 多进程轨迹任务
def parallel_nlp_trajectory(args):hparams_list, epoch, total_epochs, nlp_epochs, traj_length = argsenv = NLP_Hparam_Env(nlp_epochs=nlp_epochs)state = env.reset()traj_states, traj_actions, traj_rewards = [], [], []for step in range(traj_length):hparams = hparams_list[step] if step < len(hparams_list) else hparams_list[-1]next_state, reward, val_acc, train_time = env.step(hparams, epoch, total_epochs)traj_states.append(state)traj_actions.append(hparams)traj_rewards.append(reward)state = next_stateif step == traj_length - 1:final_val_acc = val_accfinal_time = train_timereturn traj_states, traj_actions, traj_rewards, final_val_acc, final_time# PPO智能体
class PPOAgent:def __init__(self, state_dim, action_dim, bayes_hparams, clip_ratio=0.2, gamma=0.99, lr=3e-4):self.state_dim = state_dimself.action_dim = action_dim # 7维动作self.clip_ratio = clip_ratioself.gamma = gammaself.lr = lr# 构建策略网络和价值网络self.actor = self.build_actor()self.critic = self.build_critic()# 用贝叶斯优化的超参数初始化策略网络均值self._init_actor_with_bayes(bayes_hparams)self.actor_optimizer = tf.keras.optimizers.Adam(learning_rate=lr)self.critic_optimizer = tf.keras.optimizers.Adam(learning_rate=lr)def build_actor(self):inputs = tf.keras.Input(shape=(self.state_dim,))x = tf.keras.layers.Dense(256, activation='tanh')(inputs)x = tf.keras.layers.Dense(128, activation='tanh')(x)mean = tf.keras.layers.Dense(self.action_dim, activation='tanh')(x) # 均值输出[-1,1]log_std = tf.keras.layers.Dense(self.action_dim, activation='linear')(x)std = tf.exp(log_std)return tf.keras.Model(inputs=inputs, outputs=[mean, std])def build_critic(self):inputs = tf.keras.Input(shape=(self.state_dim,))x = tf.keras.layers.Dense(256, activation='tanh')(inputs)x = tf.keras.layers.Dense(128, activation='tanh')(x)value = tf.keras.layers.Dense(1, activation='linear')(x)return tf.keras.Model(inputs=inputs, outputs=value)def _init_actor_with_bayes(self, bayes_hparams):"""用贝叶斯优化的超参数初始化策略网络的均值层"""avg_action = np.zeros(self.action_dim)for hp in bayes_hparams:action = self.hparams_to_action(hp)avg_action += action / len(bayes_hparams) # 平均Top3超参数的动作向量# 初始化均值层偏置mean_layer = self.actor.layers[-2]weights = mean_layer.get_weights()weights[1] = avg_actionmean_layer.set_weights(weights)print(f"PPO策略网络初始化完成,初始均值动作:{avg_action}")def hparams_to_action(self, hparams):"""将超参数转换为PPO动作空间([-1,1])"""action = np.zeros(7)action[0] = self._scale_hparam(hparams["lr"], (1e-4, 1e-2))action[1] = self._scale_hparam(hparams["batch_size"], (16, 64))action[2] = self._scale_hparam(hparams["lstm_units"], (32, 128))action[3] = self._scale_hparam(hparams["dropout_rate"], (0.2, 0.4))action[4] = self._scale_hparam(hparams["embed_dim"], (64, 256))action[5] = self._scale_hparam(hparams["lstm_layers"], (1, 2))action[6] = self._scale_hparam(hparams["optimizer"], (0, 1))return actiondef _scale_hparam(self, value, bounds):"""将超参数值映射到[-1,1]"""low, high = boundsreturn 2 * (value - low) / (high - low) - 1def sample_action(self, state):"""手动实现正态分布采样"""state = state[np.newaxis, :]mean, std = self.actor.predict(state, verbose=0)action = np.random.normal(loc=mean, scale=std, size=mean.shape)action = np.clip(action, -1.0, 1.0)# 计算对数概率log_prob = -0.5 * np.sum(np.log(2 * np.pi * std**2) + (action - mean)**2 / std**2, axis=1)return action[0], log_prob[0]def action_to_hparams(self, action):"""将动作映射回超参数"""lr = self._scale_action(action[0], (1e-4, 1e-2))batch_continuous = self._scale_action(action[1], (16, 64))batch_size = self._continuous_to_discrete(batch_continuous, [16, 32, 64])lstm_units_continuous = self._scale_action(action[2], (32, 128))lstm_units = self._continuous_to_discrete(lstm_units_continuous, [32, 64, 128])dropout_rate = self._scale_action(action[3], (0.2, 0.4))embed_continuous = self._scale_action(action[4], (64, 256))embed_dim = self._continuous_to_discrete(embed_continuous, [64, 128, 256])lstm_layers = int(round(self._scale_action(action[5], (1, 2))))optimizer = int(round(self._scale_action(action[6], (0, 1))))return {"lr": lr, "batch_size": batch_size, "lstm_units": lstm_units,"dropout_rate": dropout_rate, "embed_dim": embed_dim,"lstm_layers": lstm_layers, "optimizer": optimizer}def _scale_action(self, action, bounds):low, high = boundsreturn low + (high - low) * (action + 1) / 2def _continuous_to_discrete(self, value, options):return min(options, key=lambda x: abs(x - value))def train(self, trajectories):"""PPO训练(多步轨迹)"""states, actions, old_log_probs, rewards, values = [], [], [], [], []for traj in trajectories:traj_states, traj_actions, traj_log_probs, traj_rewards = trajtraj_values = [self.critic.predict(s[np.newaxis, :], verbose=0)[0][0] for s in traj_states]traj_returns = self._compute_returns(traj_rewards, traj_values)states.extend(traj_states)actions.extend(traj_actions)old_log_probs.extend(traj_log_probs)rewards.extend(traj_rewards)values.extend(traj_returns)# 标准化优势advantages = np.array(values) - np.mean(values)advantages = advantages / (np.std(advantages) + 1e-8)# 转换为Tensorstates = tf.convert_to_tensor(states, dtype=tf.float32)actions = tf.convert_to_tensor(actions, dtype=tf.float32)old_log_probs = tf.convert_to_tensor(old_log_probs, dtype=tf.float32)returns = tf.convert_to_tensor(values, dtype=tf.float32)# 多轮更新for _ in range(10):with tf.GradientTape() as tape:mean, std = self.actor(states, training=True)std = tf.exp(std)# 计算对数概率log_prob = -0.5 * tf.reduce_sum(tf.math.log(2 * np.pi * std**2) + (actions - mean)**2 / std**2,axis=1)ratio = tf.exp(log_prob - old_log_probs)surr1 = ratio * advantagessurr2 = tf.clip_by_value(ratio, 1 - self.clip_ratio, 1 + self.clip_ratio) * advantagesactor_loss = -tf.reduce_mean(tf.minimum(surr1, surr2))# 更新策略网络actor_grads = tape.gradient(actor_loss, self.actor.trainable_variables)self.actor_optimizer.apply_gradients(zip(actor_grads, self.actor.trainable_variables))# 更新价值网络with tf.GradientTape() as tape:new_values = self.critic(states, training=True)critic_loss = tf.reduce_mean(tf.square(returns - new_values))critic_grads = tape.gradient(critic_loss, self.critic.trainable_variables)self.critic_optimizer.apply_gradients(zip(critic_grads, self.critic.trainable_variables))def _compute_returns(self, rewards, values):returns = []last_value = values[-1] if values else 0.0for reward in reversed(rewards):last_value = reward + self.gamma * last_valuereturns.insert(0, last_value)return returns# 贝叶斯 + PPO 联合训练主流程
RL_EPOCHS = 20
NUM_TRAJECTORIES = 8
NLP_EPOCHS = 2
STATE_DIM = 8
ACTION_DIM = 7
PPO_LR = 3e-4
GAMMA = 0.99# 初始化PPO智能体
agent = PPOAgent(state_dim=STATE_DIM,action_dim=ACTION_DIM,bayes_hparams=best_bayes_hparams,lr=PPO_LR,gamma=GAMMA
)# 训练记录
reward_history = []
best_reward = -np.inf
best_hparams = None
best_val_acc = 0.0
best_train_time = np.inf# 多进程池
pool = Pool(processes=NUM_TRAJECTORIES)print("\n开始贝叶斯+PPO联合训练(共{}轮)...".format(RL_EPOCHS))
for epoch in range(RL_EPOCHS):traj_length = get_trajectory_length(epoch, RL_EPOCHS)trajectories = []# 生成轨迹for _ in range(NUM_TRAJECTORIES):traj_states, traj_actions, traj_log_probs = [], [], []state = NLP_Hparam_Env().reset()for _ in range(traj_length):action, log_prob = agent.sample_action(state)hparams = agent.action_to_hparams(action)traj_states.append(state)traj_actions.append(action)traj_log_probs.append(log_prob)# 生成下一个状态env = NLP_Hparam_Env(nlp_epochs=1)next_state, _, _, _ = env.step(hparams, epoch, RL_EPOCHS)state = next_statetrajectories.append((traj_states, traj_actions, traj_log_probs))# 并行执行轨迹训练parallel_args = []for traj in trajectories:traj_states, traj_actions, traj_log_probs = trajhparams_list = [agent.action_to_hparams(a) for a in traj_actions]parallel_args.append((hparams_list, epoch, RL_EPOCHS, NLP_EPOCHS, traj_length))results = list(tqdm(pool.imap(parallel_nlp_trajectory, parallel_args),total=NUM_TRAJECTORIES,desc=f"Epoch {epoch + 1}/{RL_EPOCHS}(轨迹长度={traj_length})"))# 解析结果full_trajectories = []for i in range(NUM_TRAJECTORIES):traj_states, traj_actions_hp, traj_rewards, val_acc, train_time = results[i]traj_actions = trajectories[i][1]traj_log_probs = trajectories[i][2]full_trajectories.append((traj_states, traj_actions, traj_log_probs, traj_rewards))# 更新最优记录final_reward = traj_rewards[-1]if final_reward > best_reward:best_reward = final_rewardbest_hparams = traj_actions_hp[-1]best_val_acc = val_accbest_train_time = train_time# 训练PPOagent.train(full_trajectories)# 记录平均奖励all_rewards = [r for traj in full_trajectories for r in traj[3]]avg_reward = np.mean(all_rewards)reward_history.append(avg_reward)print(f"Epoch {epoch + 1}:平均奖励={avg_reward:.2f},最优奖励={best_reward:.2f}")# 关闭进程池
pool.close()
pool.join()# 输出结果
print("\n" + "=" * 50)
print("贝叶斯+PPO优化完成!最优超参数:")
for k, v in best_hparams.items():print(f" {k}: {v}")
print(f"最优验证集准确率:{best_val_acc:.4f},训练时间:{best_train_time:.2f}秒")# 性能验证与可视化
def train_full_nlp(hparams, epochs=5):env = NLP_Hparam_Env()embedding_matrix = env.build_embedding_matrix(hparams["embed_dim"])# 强制转换为整数lstm_units = int(hparams["lstm_units"])lstm_layers = int(hparams["lstm_layers"])model = Sequential()model.add(Embedding(input_dim=EMBED_INPUT_DIM,output_dim=hparams["embed_dim"],weights=[embedding_matrix],trainable=True))model.add(Dropout(hparams["dropout_rate"]))for _ in range(lstm_layers - 1):model.add(LSTM(units=lstm_units, return_sequences=True))model.add(Dropout(hparams["dropout_rate"]))model.add(LSTM(units=lstm_units, return_sequences=False))model.add(Dropout(hparams["dropout_rate"]))model.add(Dense(units=1, activation='sigmoid', dtype='float32'))if hparams["optimizer"] == 0:optimizer = Adam(learning_rate=hparams["lr"])else:optimizer = SGD(learning_rate=hparams["lr"], momentum=0.9)optimizer = mixed_precision.LossScaleOptimizer(optimizer)model.compile(optimizer=optimizer, loss='binary_crossentropy', metrics=['accuracy'])start_time = time.time()model.fit(x_train_sub, y_train_sub,batch_size=hparams["batch_size"],epochs=epochs,validation_data=(x_val, y_val),verbose=1)full_time = time.time() - start_timetest_acc = model.evaluate(x_test, y_test, verbose=0)[1]return test_acc, full_time# 测试集验证
print("\n" + "=" * 50)
rl_test_acc, rl_time = train_full_nlp(best_hparams, epochs=5)
print(f"贝叶斯+PPO模型:测试集准确率={rl_test_acc:.4f},训练时间={rl_time:.2f}秒")# 对比默认模型
default_hparams = {"lr": 1e-3, "batch_size": 32, "lstm_units": 64,"dropout_rate": 0.3, "embed_dim": 128, "lstm_layers": 1, "optimizer": 0
}
default_test_acc, default_time = train_full_nlp(default_hparams, epochs=5)
print(f"默认模型:测试集准确率={default_test_acc:.4f},训练时间={default_time:.2f}秒")# 可视化奖励曲线
plt.figure(figsize=(10, 4))
plt.plot(range(1, RL_EPOCHS + 1), reward_history, marker='o', color='b', label='贝叶斯+PPO')
plt.axvline(x=10, color='r', linestyle='--', label='轨迹长度从1→3')
plt.xlabel('PPO Epochs')
plt.ylabel('Average Reward')
plt.title('Reward History (Bayesian Initialization + PPO)')
plt.legend()
plt.grid(alpha=0.3)
plt.show()
十一、整体流程总结
该代码通过 “贝叶斯预热→PPO 迭代→结果验证” 的闭环,实现了 IMDB 情感分析模型超参数的智能优化,核心数学逻辑可概括为:
- 贝叶斯优化:用高斯过程建模超参数 - 准确率关系,通过期望改进平衡探索与利用,快速定位优质区域;
- PPO 强化学习:用正态分布建模动作空间,通过剪辑损失稳定策略更新,结合折扣回报和优势函数优化多步决策;
- 自适应奖励:通过动态权重平衡准确率与效率,用剪枝惩罚排除无效超参数,引导优化方向。
最终输出的 “最优超参数” 可直接用于 IMDB 情感分析任务,兼顾高准确率与快训练速度,为类似 NLP 任务的超参数优化提供通用框架。
本文提出了一种基于贝叶斯优化和PPO强化学习的智能超参数优化框架,用于IMDB影评情感分析任务。该方案采用两阶段策略:先通过贝叶斯优化快速定位优质超参数区域,再利用PPO智能体进行迭代优化。系统包含环境配置、数据预处理、奖励函数设计等模块,通过自适应奖励权重平衡准确率和训练效率,并采用多进程并行加速训练。实验结果表明,该方法能自动找到兼顾高准确率和快训练速度的最优超参数组合,相比默认参数显著提升性能。该框架为NLP任务的超参数优化提供了通用解决方案。