神经符号模型与增量学习——下一代可控人工智能的正统新范式
目录
- 神经符号模型——DAHSF
- 论文的Future Work:用RPA程度的增量学习方法训练DAHSF——智能模型的本地训练与本地部署——渐得如意智能自动化办公平台
Introduction of DAHSF
- Paper Link
- Hugging Face
- Podcast
Abstract
Text Normalization and Semantic Parsing have numerous applications in natural language processing, such as natural language programming, paraphrasing, data augmentation, constructing expert systems, text matching, and more. Despite the prominent achievements of deep learning in Large Language Models (LLMs), the interpretability of neural network architectures is still poor, which affects their credibility and hence limits the deployments of risk-sensitive scenarios. In certain scenario-specific domains with scarce data, rapidly obtaining a large number of supervised learning labels is challenging, and the workload of manually labeling data would be enormous. Catastrophic forgetting in neural networks further leads to low data utilization rates. In situations where swift responses are vital, the density of the model makes local deployment difficult and the response time long, which is not conducive to local applications of these fields. Inspired by the multiplication rule, a principle of combinatorial mathematics, and human thinking patterns, a multilayer framework along with its algorithm, the Digestion Algorithm in Hierarchical Symbolic Forests (DAHSF), is proposed to address these above issues, combining text normalization and semantic parsing workflows. The Chinese Scripting Language “Fire Bunny Intelligent Development Platform V2.0” is an important test and application of the technology discussed in this paper. DAHSF can run locally in scenario-specific domains on little datasets, with model size and memory usage optimized by at least two orders of magnitude, thus improving the execution speed, and possessing a promising optimization outlook.
Significant Declaration
Due to very limited resources (esp. equipments), the data (not including DAHSF) in this table was generated by ChatGLM-4.
Podcast Transcript
John: Welcome to our seminar on Alternative Models in Natural Language Processing. Today’s lecture is on the paper ‘DIGESTION ALGORITHM IN HIERARCHICAL SYMBOLIC FORESTS’ by Kevin You. We’ve seen a lot of work on optimizing LLMs, like in ‘From Large to Super-Tiny’, but this paper takes a step back from the deep learning paradigm entirely. It proposes a symbolic, rule-based approach, which is interesting given the field’s current trajectory. The author appears to be an independent researcher, which provides a unique context for the work.
John: Yes, Noah?
Noah: Excuse me, Professor. You mentioned this is from an independent researcher. How does that context, especially the link to a personal blog and a copyrighted software platform, shape our interpretation of this as an academic contribution versus an engineering report?
John: That’s an excellent point. It suggests the work is heavily application-driven. The primary motivation appears to be solving a practical problem—creating a lightweight, locally deployable NLP engine for a specific software product. While it’s presented as research, we should evaluate it through the lens of a highly specialized, engineered solution that directly challenges the assumption that LLMs are the only path forward.
John: The main concept here is the Digestion Algorithm in Hierarchical Symbolic Forests, or DAHSF. The author positions it as a direct response to the key weaknesses of LLMs: their lack of interpretability, poor performance in data-scarce domains, and immense computational requirements. Instead of a neural network, the DAHSF uses a multi-layered symbolic framework. Each layer is a ‘forest’ where every node and edge has an explicit, human-understandable meaning. This design choice is fundamental to its interpretability.
Noah: So, is this essentially a modern, structured version of an expert system?
John: In a way, yes. It’s a rule-based system that relies on predefined lexicons. The ‘Digestion Algorithm’ is the process of mapping input text to standardized forms. It uses equivalence classes to handle synonyms, mapping varied inputs to a single representative element. For example, ‘start,’ ‘launch,’ and ‘open’ might all be mapped to a single command. The system then parses the remaining text to identify keywords and data words, like a program name or a URL. This layered approach allows it to handle increasing levels of abstraction, much like human cognition.
Noah: How does a deterministic system like this handle the inherent ambiguity of natural language, something probabilistic models like LLMs are designed for?
John: It handles ambiguity by being domain-specific. The lexicons and rules are tailored for a particular scenario, which sharply reduces the scope of possible meanings. The paper’s example is the ‘Fire Bunny Intelligent Development Platform’. In that context, the system isn’t trying to understand all of human language, just commands relevant to controlling a computer. The second layer of its architecture is dedicated to contextual analysis to resolve ambiguities that persist after the initial normalization, like omissions common in Chinese.
John: Let’s look at the application. The paper uses the ‘Fire Bunny’ platform to demonstrate the DAHSF in a two-layer pipeline. The first layer acts as a ‘perceiver’. It takes raw text like ‘打开www.baidu.com’—which means ‘Open www.baidu.com’—and performs initial normalization. It identifies ‘打开’ as a keyword and maps it to its core synonym, ‘开’. It then identifies ‘www.baidu.com’ as a data word and labels it as a URL. The output is a structured tuple.
Noah: So the first layer tokenizes and standardizes?
John: Correct. Then, the second layer performs contextual analysis on these structured tuples. It matches the normalized command structure with the identified data words to form a complete, executable instruction. This is how it achieves natural language programming. The performance results are the most notable part of the paper. The author reports that the model is just 1.58 megabytes on disk and uses under 10 megabytes of memory for parsing, which is orders of magnitude smaller and more efficient than even compact LLMs. Execution speed is described as ‘nearly imperceptible’.
Noah: A quick question on the evaluation. The paper says the test set was generated by simulating user inputs with ChatGLM-4. Isn’t there a risk of creating a biased benchmark? An LLM might generate inputs that are syntactically simple or repetitive, which could favor a rule-based system and not reflect the complexity of real human input.
John: That’s a valid critique of the methodology. Using an LLM to generate test data for a system designed to be an alternative to LLMs can introduce biases. A more robust evaluation would involve a dataset of genuine, unscripted user commands. However, for a proof-of-concept from an independent developer, this approach provides a baseline for comparison, and the performance metrics on speed and resource usage are significant regardless of the test data’s origin. They clearly demonstrate the feasibility of local deployment on consumer hardware.
John: The broader implications are quite interesting. This work directly addresses the need for interpretable AI in risk-sensitive fields. In scenarios like industrial control or medical systems, a transparent, deterministic decision process is often preferable to a black-box model, even if the latter is more flexible. The paper also champions natural language programming as a way to lower barriers, especially for non-English speakers, by breaking the ‘monopoly of English computer languages’. This connects to a larger conversation in the field about making technology more accessible.
Noah: The emphasis on interpretability and reasoning reminds me of the goals in neurosymbolic research, like the work on ‘Proof of Thought’. Does the DAHSF have any capacity for learning or adaptation, or is it entirely static until the rules are manually updated?
John: As presented, the core system is static and relies on manually curated lexicons. This avoids issues like catastrophic forgetting seen in LLMs, which is a key point in the paper. However, the ‘Future Works’ section outlines a vision for a self-learning symbolic system. The plan is to use generative AI to create test cases and automatically update the knowledge base and lexicons from failures. This points toward a hybrid approach, using LLMs as a tool to bootstrap and refine a symbolic reasoning engine, which is a compelling research direction.
John: So, to wrap up, the DAHSF is not positioned as a replacement for general-purpose LLMs. Instead, it serves as a strong proof-of-concept for an alternative approach tailored to specific, resource-constrained scenarios where speed, low overhead, and interpretability are paramount. It demonstrates that for certain NLP tasks like command parsing, a well-engineered symbolic system can significantly outperform deep learning models. The key takeaway is that the optimal architecture is highly dependent on the problem context, and older AI paradigms still have much to offer.
John: Thanks for listening. If you have any further questions, ask us or drop a comment.
Gradual Magic Intelligent Office Automation Platform
It’s our second step/project of the Office Agents and Their Incremental Learning Framework series.
渐得如意智能自动化办公平台使用文档
基本语法
- 建议服从基本的汉语语法,用标点符号结尾,形成一个句子;
- 初始时,用户可以使用自然语言的标点符号“!”“;”“,”“。”等作为命令分隔符(回车也可以,但是专门用于脚本文件内容)。所有可用的分隔符保存在数据库中(本平台的“数据库”文件夹),可以修改“数据库\分隔符.txt”来更改自己的分隔符偏好;
一个句子中的词语要么被解析为数据词,要么被解析为关键词
使用本平台
两种基本交互方式
- 调试窗口:直接双击“渐得如意”,进入界面之后就可以直接编写,调试,编辑,浏览,运行本平台命令;支持一行多个句子的命令,但不支持多行输入
- 当输入命令然后按回车时,执行用户输入的命令
- 当输入内容不是本平台命令然后按回车时,本平台会根据用户反馈的“是否输错命令”决定是否要向用户学习
- 开发脚本文件:“机关文件”与“秘籍文件”是本平台的脚本文件,可用记事本编辑开发;二者均可被本平台直接打开。如若代码中存在非命令语句,平台会整体报错提示。
查看帮助
初始的程序有“帮助”命令。输入这个命令后,渐得如意首先会自我介绍。

单击“确定”后,渐得如意会向用户询问是否需要展示本平台的全部最简命令。如果用户点击“确定”,渐得如意会命令系统启动帮助文档。
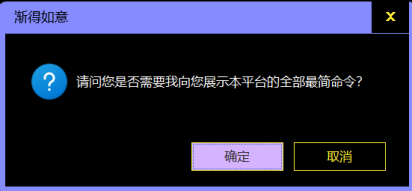
由于本平台的命令是自定义的,帮助文档是现场生成的,因此用户可以明确地利用这点追踪本平台当下的能力边界。如果用户定义了一些新命令,重新生成帮助文档后,帮助文档的内容也会相应变化。为了不过度占用用户电脑磁盘空间,帮助文档生成后,默认会被本平台删除。
如下图,在帮助文档中,标题指明了命令的类型(以下称为“命令类型”)。位于括号“(”和“)”之间的是数据词,而剩下的非标题内容都是关键词。这个帮助文档只展示了全部现有的自定义命令的代表形式,其它与它们同义的命令语句则不被展示。不同的命令之间用“,”隔开。

帮助中的命令可以直接使用。比如在本平台中打出“卸载”两个字,然后回车。

之后,本平台就会执行对应的Python命令。例如这个案例中,启动的是系统设置中的程序列表。可以通过本平台看到,这个命令的命令类型是“打开并跳转”。

用户可以单行输入多个命令,命令之间请用命令分割符隔开,本平台会依次执行。如果用户编写本平台支持的脚本文件,命令分隔符则多支持一个回车,但需要用户严格使用自己定义的表述方式。
让电脑“渐得如意”
这个功能是本平台用于让模型“学习”的工作流程。比如,我要定义一个新命令,我输入了下面的这段内容:
到19:00时,打开记事本
首先,渐得如意会向用户确认是否打错了命令,所有问题用户需要如实准确地回答。


添加新命令,意味着这个命令以前渐得如意没有见过,那么这个表达方式本平台也没有见过,因此用户需回答“是”。
如果出现了渐得如意以前没有见过的新词语,或者是以前的“词语”连起来会出现新的含义。在前者的情况,渐得如意会询问用户:

然而在后者的情况,则会问:
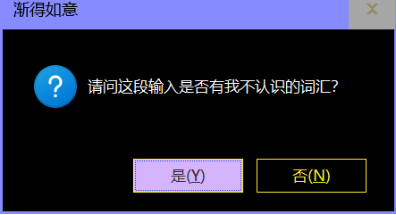
如果在前者的情况否定,例如这个例子中,用户实际上希望“19:00”表示时间,“时”则表示“时候”的意思。渐得如意自动提取功能并不符合用户的预期,因此用户要选择“否”,然后手动按照提示输入内容。在后者的情况中,则是选择“是”。


每次用户输入完毕,渐得如意都会给用户确认的机会。在这个例子中,“时”是词库中的新词语,就像我们遇到了一个以前从来没有见过的生僻字或陌生词汇一样。因此,选择“否”后确认“时”的词性是“名词”。
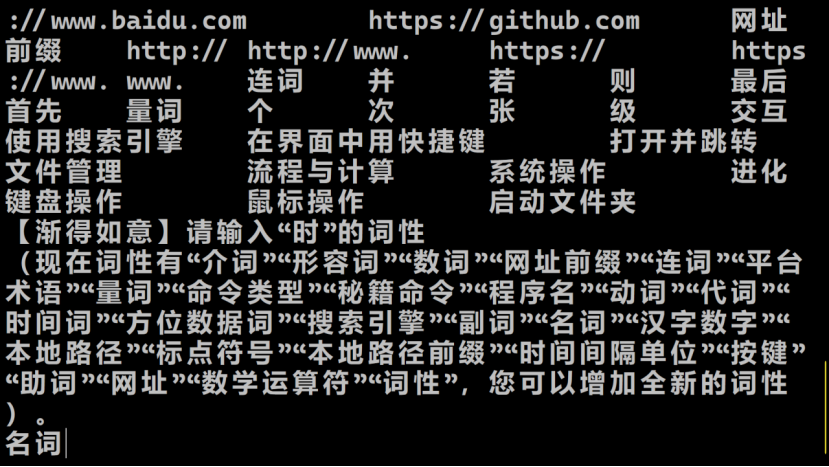
渐得如意学习完词语后,就要学相关的句子。显然在这个例子中,我们的命令是全新的。在下图中,选择“否”。我们需要定义一种新的命令,其命令类型为“流程与计算”。


这个记事本会自动弹出。编辑好代码之后,下次就可以正常运行了。Python代码中,“第三层数据”是一个Python列表,依次记录了这个命令中的全部数据词。比如,利用这个命令,就可以设置19:05的闹钟了。这个音频就会准时地在这个时间打开。
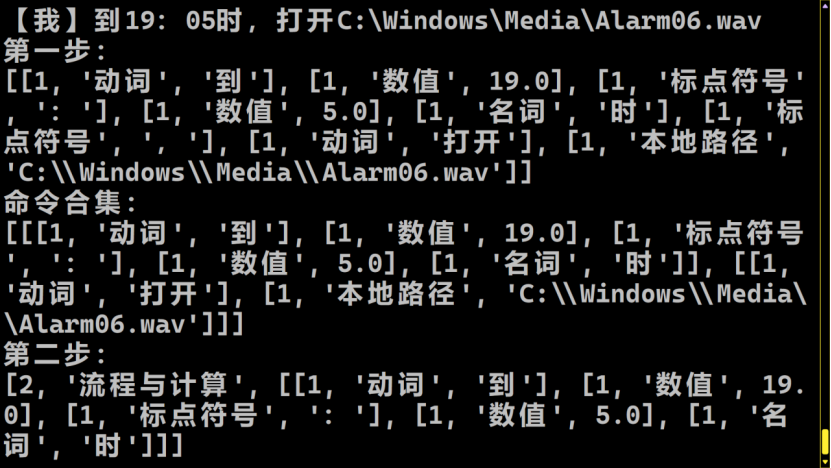
可以用新执行的帮助命令发现,在“流程与计算”这种命令类型中,增添了这个命令。
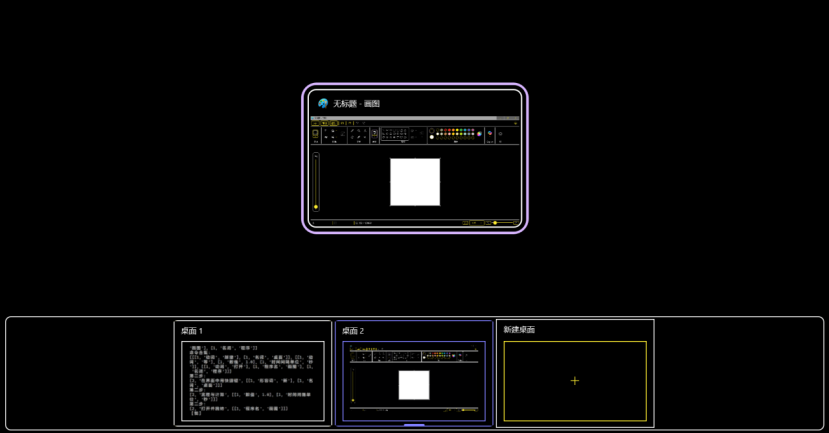
如果用户打错了命令,渐得如意会试图猜测用户的正确命令。如果本平台猜对了,那就执行更正后的命令。后续正常的命令继续执行。下图展示了一个正确的猜测,用户确认后,渐得如意则会完整执行修正后的命令,即“新建桌面,等候1秒,打开画图软件”。可以看到,执行前只有一个桌面1,执行后在桌面2中有一个画图软件。

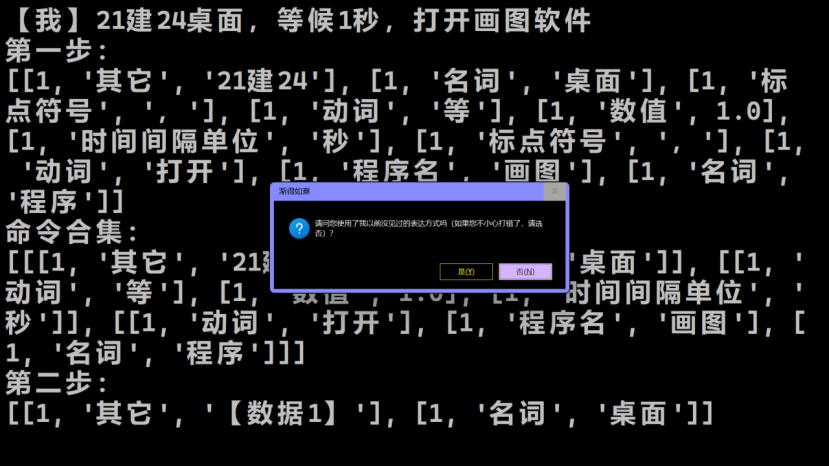
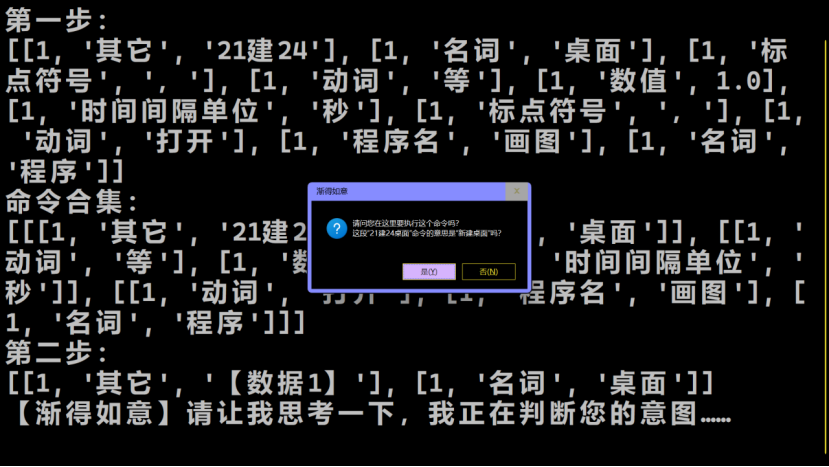
我们讨论最后一种情况——一个Python指令对应多种表达方式的可能。本平台的同义对应支持2个层次——词语层次和句子层次。我们以句子层次的同义对应为例,从刚才的“到19:05时”出发,现在我们更改它的时间点,比如改为“20:00”,并更改这个命令的表达方式,把它改成“等待至20:00”。

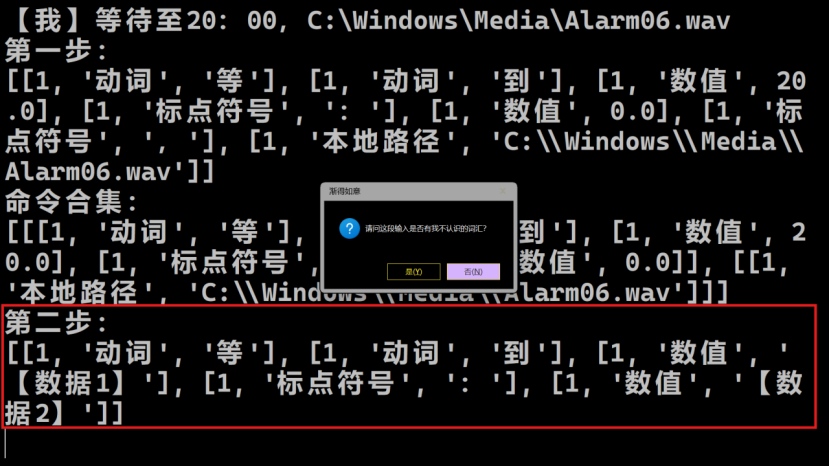
可以从这里看出,所有的词汇本平台都有,因此这里选“否”。然后在下图的这一步中选择“是”(如果用户忘记了之前定义了什么命令或者词语,都可以在终端的显示区查找到)。

这里,请用户重新表述这个命令,使之成为渐得如意熟悉的版本。在这里用户需要输入“到20:00时”并确认。现在,这段命令及其之后的命令就可以正常依次执行了。

平台功能与特色
功能上,本平台可学习用户的词汇、(最好符合中文语法的)句法,并且允许用户使用个性化但相对自由多样的表述方式下达用户自己定义的Python指令。本平台既可以通过“渐得如意”直接命令交互,又可以用“渐得如意”打开中文命令脚本。
特点上,本平台,作为这类架构的典型应用场景,延续了这类架构的特点。本平台因其所采用的架构,能在CPU上学习、本地运行、离线解析命令(除非自定义的指令内容需要联网)。一旦学习完毕,执行知识库内的指令迅速且较为稳定,可靠度高。模型架构之外,本平台使用中文作为脚本语言,无需手动编译就可以执行脚本。
模型架构以外的术语
- 脚本文件:用纯文本保存的程序文件,常用于自动化的批处理,在Windows操作系统中,打开它可以直接运行;
命令:在本平台中被用户定义、使用、编写、编辑且能被本平台执行的代码,本平台脚本语言的具体内容之一(例如,“你好!”在初始化的程序中是一句命令); - 渐得如意:主程序,也就是本平台的IDLE(集成开发环境),是一个调试窗口,能够向用户学习新命令、用户可以编写调试编辑浏览运行本平台命令的界面;
- 机关文件:本质上是后缀名为“.机关”的文本文件,可以被本平台打开;
- 秘籍文件:类似于机关文件。
- 数据词:在一个句子中模式或内容灵活多样且内容难以直接被上下文完全预测,但是可以被归类的句子片段。例如,在句子
进入https://github.com/Magic-Abracadabra/All-Agents-Are-Evolving-Translators。
中,“https://github.com/Magic-Abracadabra/All-Agents-Are-Evolving-Translators”就是一个典型的数据词。
- 关键词:句子中除去数据词以外的部分,它们稳定而且具备上下文关联性强的特点,构成了句子的框架。例如上述案例中,“进入”是一个关键词,句子的框架可以看成“进入(网址)”。当关键词组成一定的框架后,在框架的空缺处填充恰当类型的数据词,便可以形成正确而完整的句子。