网络通信的奥秘:HTTP详解 (六)
HTTP
HTTP是什么
HTTP(全称为"超⽂本传输协议")是⼀种应⽤⾮常⼴泛的应⽤层协议.
HTTP往往是基于传输层的TCP协议实现的.(HTTP1.0,HTTP1.1,HTTP2.0均为TCP,HTTP3基于UDP实现)
理解HTTP协议的⼯作过程
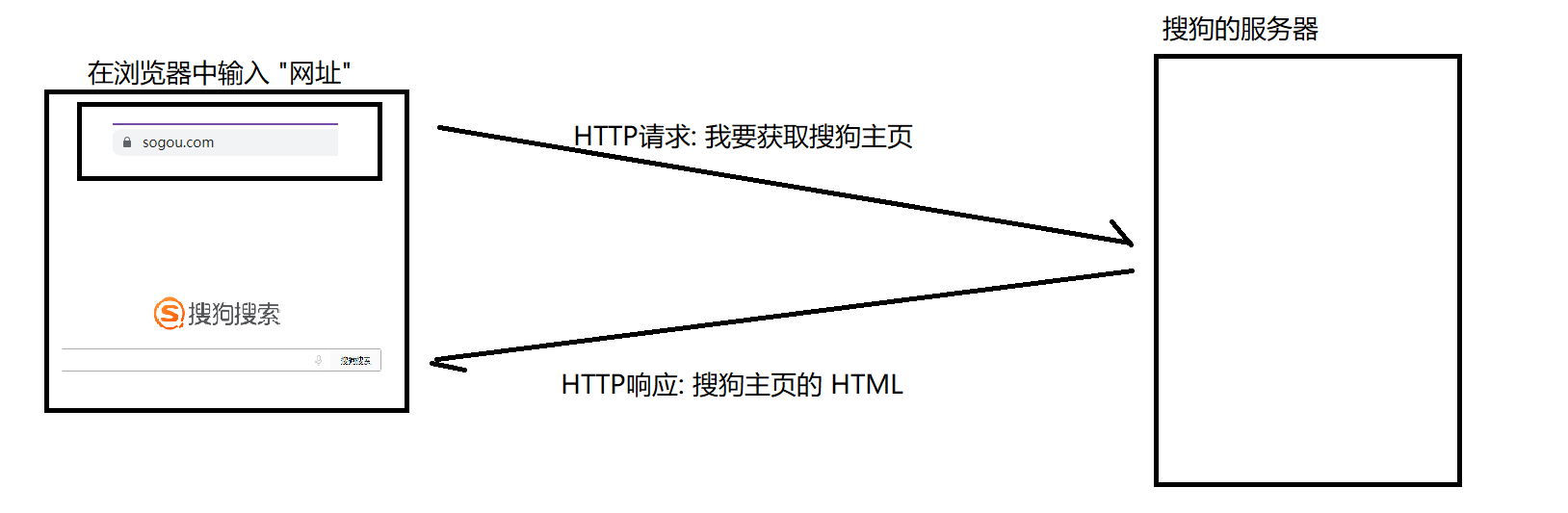
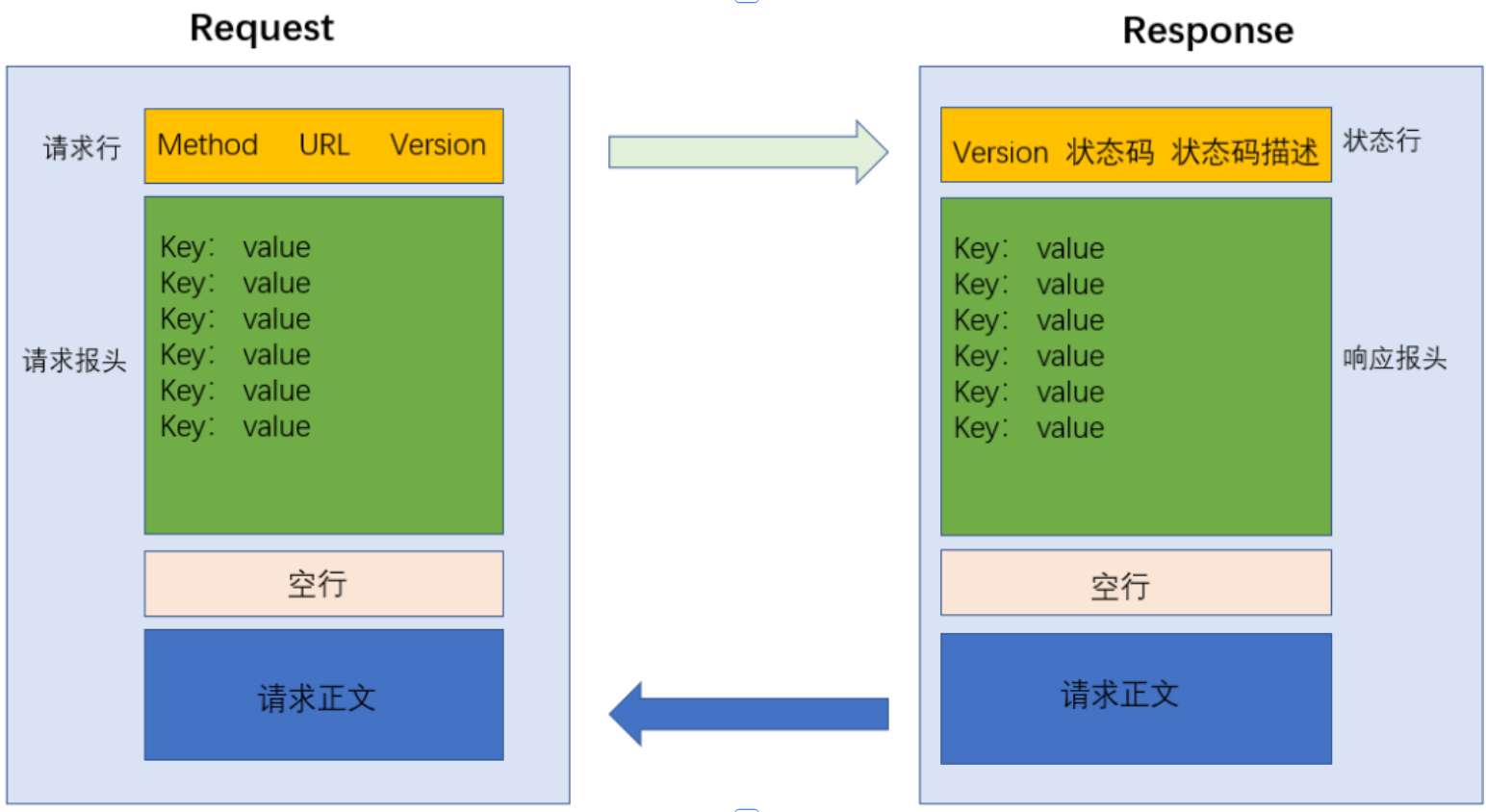
HTTP 是 “请求 - 响应” 模式,整个过程通常分为 6 步,且默认使用80 端口通信。
- 建立连接:客户端通过 TCP 协议与服务器建立连接(三次握手),比如你在浏览器输入网址后,浏览器会先和目标服务器建立 TCP 连接。
- 发送请求:客户端向服务器发送 HTTP 请求,包含 “要获取什么资源”“用什么方式获取” 等信息,比如请求一个网页的 HTML 文件。
- 服务器处理:服务器接收请求后,解析请求内容(如判断请求的资源是否存在),然后准备对应的响应数据。
- 返回响应:服务器将处理结果以 HTTP 响应的形式返回给客户端,包含 “请求是否成功”“返回的资源内容” 等信息,比如返回 200(成功)和网页 HTML。
- 关闭连接:若使用 HTTP/1.1 的 “短连接” 模式,响应完成后会关闭 TCP 连接(四次挥手);若为 “长连接”(Connection: keep-alive),连接会保留一段时间供后续请求复用。
- 客户端渲染:客户端(如浏览器)接收响应后,解析资源(如渲染 HTML、加载 CSS/JS),最终呈现出用户看到的页面。
HTTP协议格式
HTTP是⼀个⽂本格式的协议.可以通过Chrome开发者⼯具或者Fiddler抓包,分析HTTP请求/响应 的细节.
抓包⼯具的使⽤(以Fiddler为例)
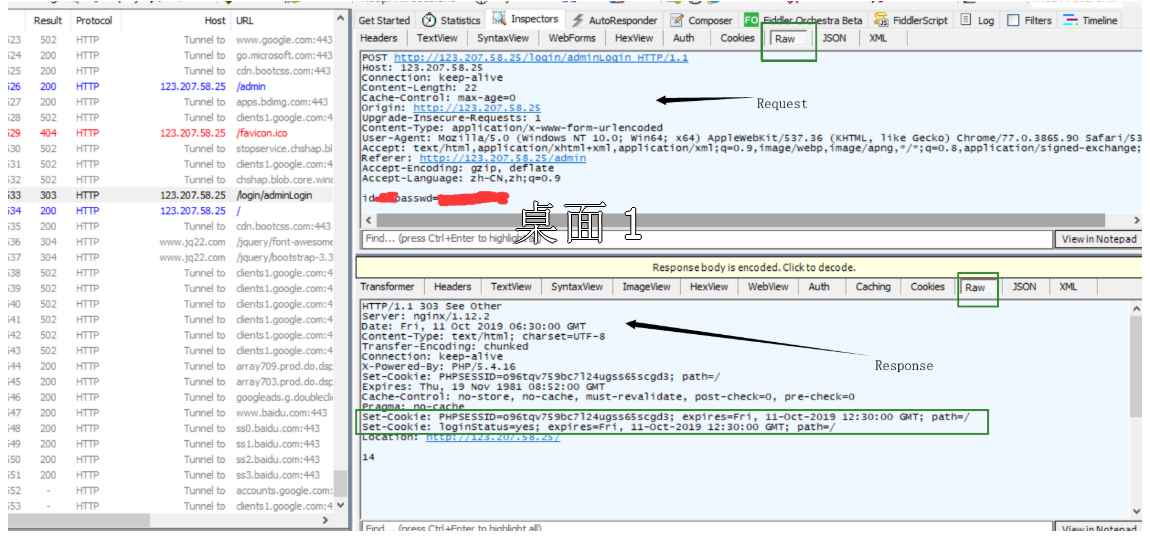
- 左侧窗⼝显⽰了所有的HTTP请求/响应,可以选中某个请求查看详情.
- 右侧上⽅显⽰了HTTP请求的报⽂内容.(切换到Raw标签⻚可以看到详细的数据格式)
- 右侧下⽅显⽰了HTTP响应的报⽂内容.(切换到Raw标签⻚可以看到详细的数据格式)
- 请求和响应的详细数据,可以通过右下⻆的View in Notepad 通过记事本打开.
- 可以使⽤ctrl+a全选左侧的抓包结果,delete键清除所有被选中的结果.
抓包⼯具的原理
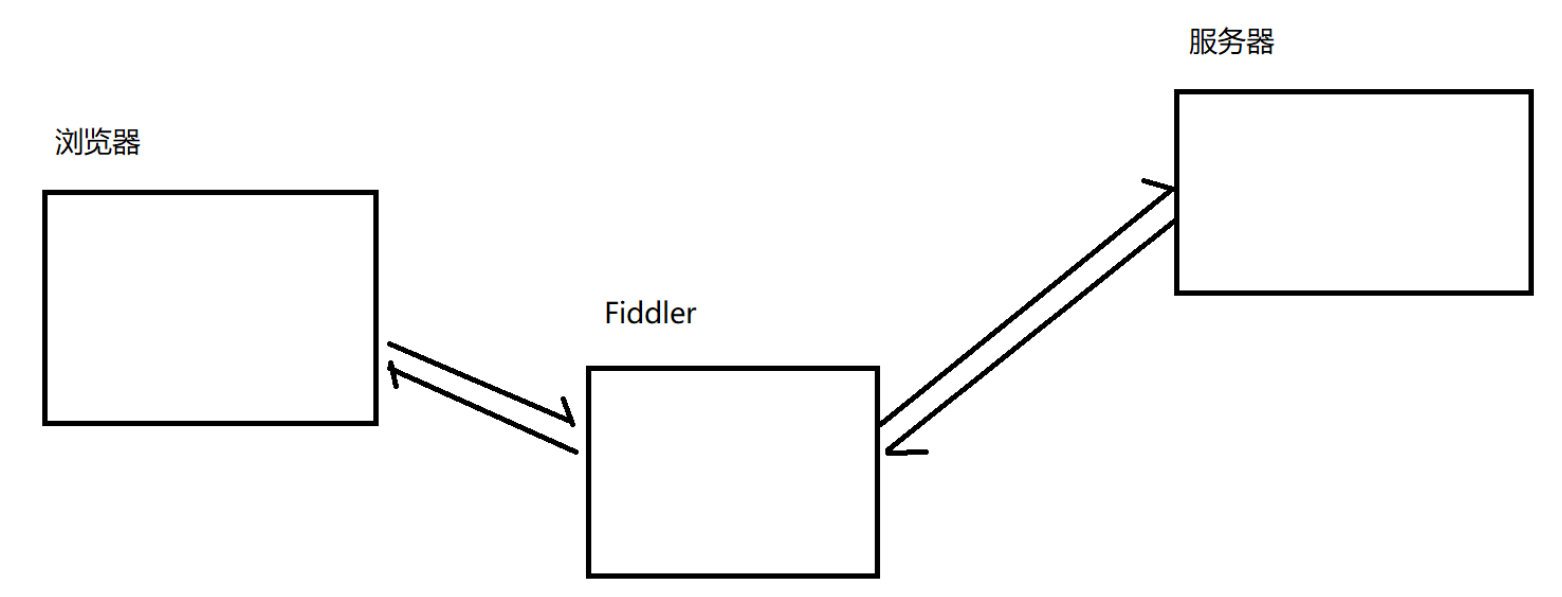
Fiddler相当于⼀个"代理". 浏览器访问sogou.com时,就会把HTTP请求先发给Fiddler,Fiddler再把请求转发给sogou的服务器.当sogou服务器返回数据时,Fiddler拿到返回数据,再把数据交给浏览器.
抓包结果
以下是⼀个HTTP请求/响应的抓包结果.
HTTP请求
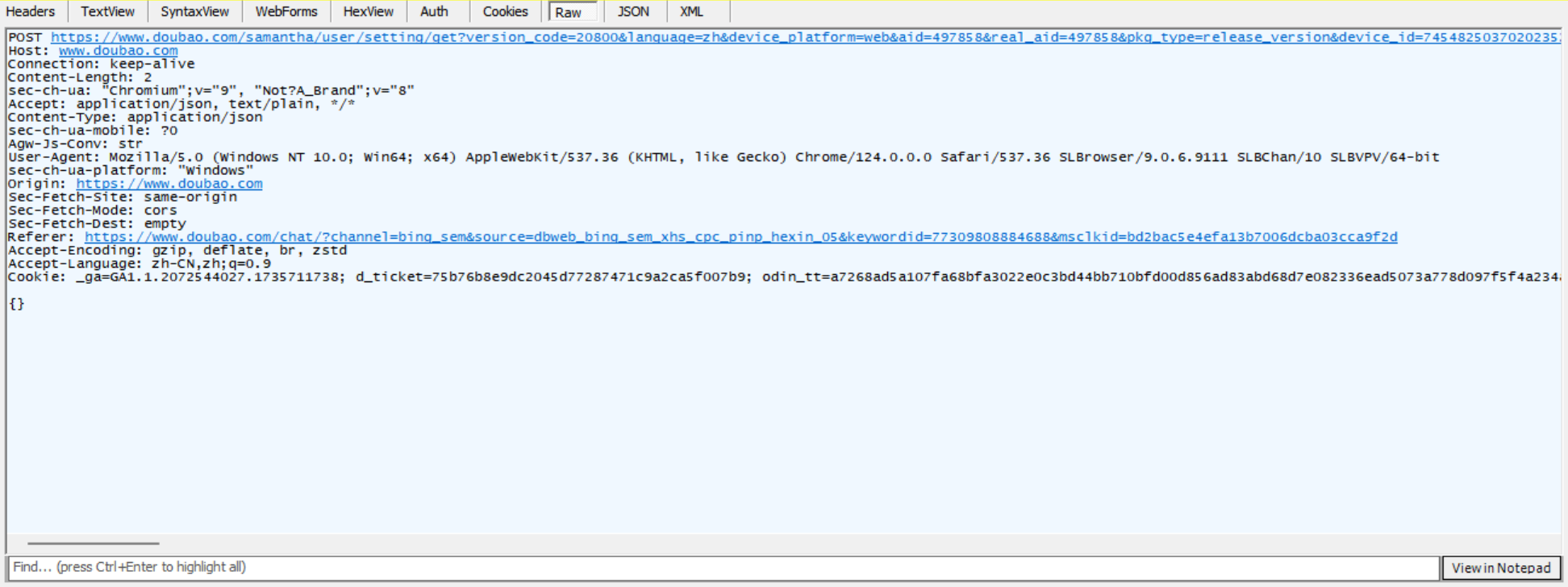
- ⾸⾏:[⽅法]+[url]+[版本]
- Header:请求的属性,冒号分割的键值对;每组属性之间使⽤\n分隔;遇到空⾏表⽰Header部分结束
- Body:空⾏后⾯的内容都是Body.Body允许为空字符串.
- 如果Body存在,则在Header中会有⼀个 Content-Length属性来标识Body的⻓度;
键值对
键值对是一种简单的信息存储和传递格式,核心是用 “键(Key)” 和 “值(Value)” 两个关联的元素来表示一条数据,就像用 “标签” 对应 “内容”,比如 “姓名:张三” 里,“姓名” 是键,“张三” 是值。
它的本质是 “通过唯一的键,快速找到对应的 value”,就像字典里 “单词(键)” 对应 “释义(值)”,或通讯录里 “联系人名字(键)” 对应 “电话号码(值)”。
一、键值对的核心特点
- 一一对应:一个键通常只对应一个值(部分场景支持一个键对应多个值,但基础逻辑是一对一),且键在同一组数据中具有唯一性,不会重复。
- 易读易解析:格式简单,人类和计算机都能快速理解,比如 “age: 25”,一眼就能知道 “年龄是 25”。
- 灵活通用:几乎所有编程语言、协议(如 HTTP)、数据格式(如 JSON)都支持,是跨场景传递简单信息的 “通用语言”。
二、键值对的常见应用场景
HTTP 协议里,就有大量键值对的应用,除此之外还有很多常见场景:
- HTTP 报头:比如请求报头里的
Host: www.baidu.com,“Host” 是键,“www.baidu.com” 是值;Cookie: username=zhangsan里,“username” 是键,“zhangsan” 是值。 - 数据格式(JSON):JSON 是典型的键值对集合,比如
{"name": "小明", "gender": "男"},每个 “键(如 name)” 都对应一个 “值(如小明)”。 - 配置文件:比如软件的配置里,
timeout: 30(超时时间 30 秒)、theme: dark(主题为深色),都是用键值对存储设置。 - 编程语言中的数据结构:比如 Python 的 “字典(dict)”、Java 的 “HashMap”,底层都是基于键值对实现的,用来快速存储和查找数据。
HTTP 请求报文格式
| 组成部分 | 作用说明 |
|---|---|
| 请求起始行 | 包含 “请求方法、请求 URL、HTTP 版本”,比如:GET /index.html HTTP/1.1 |
| 请求报头 | 用键值对(Key: Value)传递附加信息,比如Host: www.baidu.com(指定服务器) |
| 空行 | 报头和正文的分隔符,必须存在(即使没有正文),标志报头结束 |
| 请求正文 | 可选,仅在需要向服务器传数据时存在(如 POST 请求提交表单),比如username=xxx&password=xxx |
HTTP响应
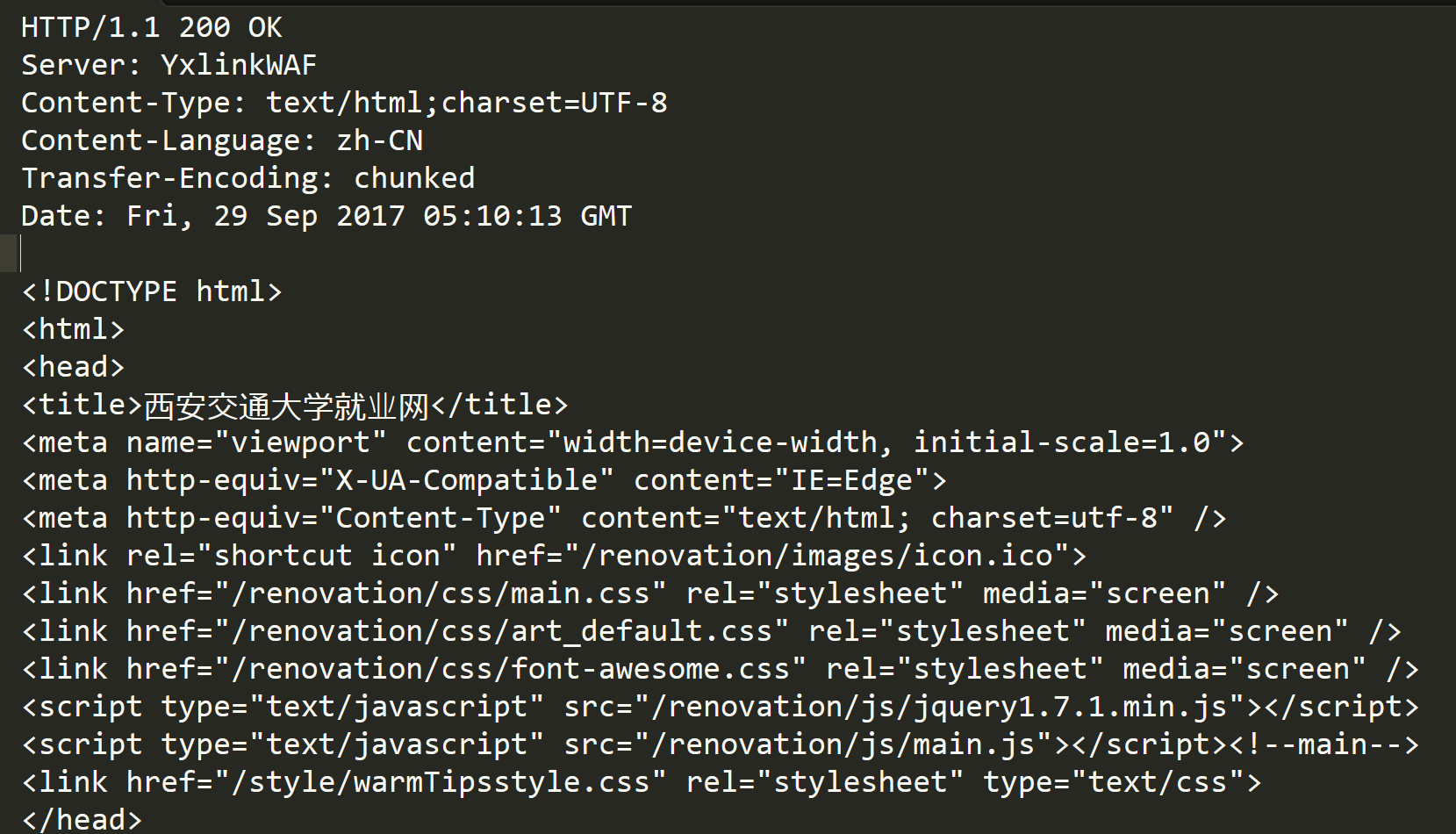
- ⾸⾏:[版本号]+[状态码]+[状态码解释]
- Header:请求的属性,冒号分割的键值对;每组属性之间使⽤\n分隔;遇到空⾏表⽰Header部分结束
- Body:空⾏后⾯的内容都是Body.Body允许为空字符串.如果Body存在,则在Header中会有⼀个
- Content-Length属性来标识Body的⻓度;如果服务器返回了⼀个html⻚⾯,那么html⻚⾯内容就是在body中.
HTTP 响应报文格式
| 组成部分 | 作用说明 |
|---|---|
| 响应起始行 | 包含 “HTTP 版本、状态码、状态描述”,比如:HTTP/1.1 200 OK |
| 响应报头 | 键值对传递附加信息,比如Content-Type: text/html(说明正文是 HTML 类型) |
| 空行 | 报头和正文的分隔符,必须存在 |
| 响应正文 | 服务器返回的实际资源,比如 HTML 代码、图片二进制数据、JSON 数据等 |
协议格式总结
为什么HTTP报⽂中要存在"空⾏"?
因为HTTP协议并没有规定报头部分的键值对有多少个.空⾏就相当于是"报头的结束标记",或者是"报头和正⽂之间的分隔符".
HTTP在传输层依赖TCP协议,TCP是⾯向字节流的.如果没有这个空⾏,就会出现"粘包问题".
HTTP请求(Request)
认识URL
URL基本格式
平时我们俗称的"⽹址"其实就是说的URL(UniformResourceLocator统⼀资源定位符).
互联⽹上的每个⽂件都有⼀个唯⼀的URL,它包含的信息指出⽂件的位置以及浏览器应该怎么处理
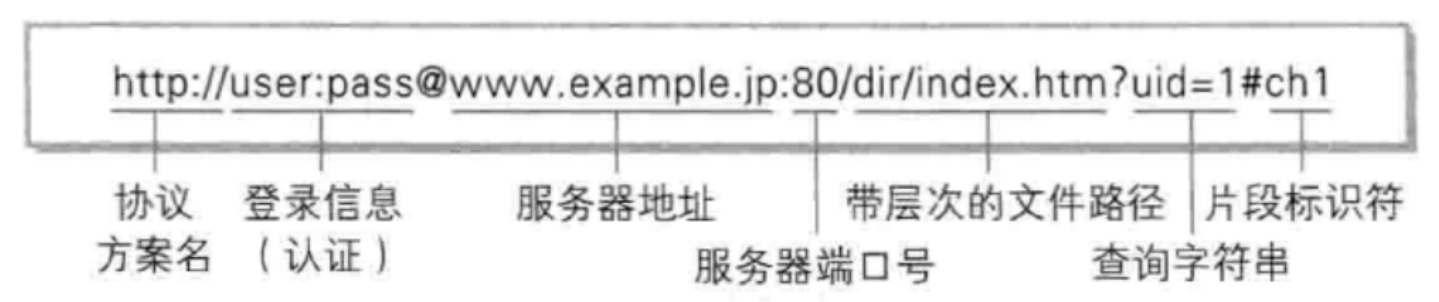
- 协议方案名:即 “http://”,用于指定客户端与服务器之间的通信协议,常见的还有 “https://”(加密传输)、“ftp://”(文件传输)等。
- 登录信息(认证):“user:pass” 部分,用于在访问需要认证的资源时,传递用户名和密码,不过这种方式安全性较低,现在较少直接在 URL 中明文传递认证信息。
- 服务器地址:“www.example.jp”,是服务器的域名,通过域名解析系统可转换为 IP 地址,确定资源所在的服务器。
- 服务器端口号:“:80”,表示客户端与服务器通信的端口,HTTP 协议默认端口是 80,HTTPS 默认是 443,不同端口可对应服务器上不同的服务。
- 带层次的文件路径:“/dir/index.htm”,用于指定服务器上资源的具体位置,类似文件系统的路径,定位到具体的网页文件。
- 查询字符串:“?uid=1”,用于向服务器传递额外的参数信息,多个参数用 “&” 分隔,常用于动态网页获取数据,如查询用户 ID 为 1 的信息。
- 片段标识符:“#ch1”,用于在网页内部定位特定位置,比如跳转到网页中标记为 “ch1” 的锚点处,不会传递到服务器,仅在客户端生效。
URL中的可省略部分
| 组成部分 | 省略条件及说明 |
|---|---|
| 协议方案名 | 若上下文明确协议(如浏览器默认 HTTP),可省略 “http://”,但 “https://” 为安全协议,一般不省略;在部分场景(如站内链接)也可隐式使用协议。 |
| 登录信息(认证) | 几乎总是省略,因明文传递用户名密码存在严重安全风险,现在多通过 Cookie、Token 等方式进行认证。 |
| 服务器端口号 | 当使用协议默认端口时可省略,如 HTTP 默认 80 端口、HTTPS 默认 443 端口,若使用非默认端口(如 8080)则必须明确。 |
| 查询字符串 | 当不需要向服务器传递额外参数时省略,如访问静态网页(仅需获取页面资源,无动态数据交互)。 |
| 片段标识符 | 当不需要在网页内部定位特定位置时省略,如普通网页浏览无需锚点跳转。 |
关于URLencode
像/?:等这样的字符,已经被url当做特殊意义理解了.因此这些字符不能随意出现.
⽐如,某个参数中需要带有这些特殊字符,就必须先对特殊字符进⾏转义.
⼀个中⽂字符由UTF-8或者GBK这样的编码⽅式构成,虽然在URL中没有特殊含义,但是仍然需要进 ⾏转义.否则浏览器可能把UTF-8/GBK编码中的某个字节当做URL中的特殊符号.转义的规则如下:将需要转码的字符转为16进制,然后从右到左,取4位(不⾜4位直接处理),每2位做⼀位,前⾯加上%,编码成%XY格式
例如:
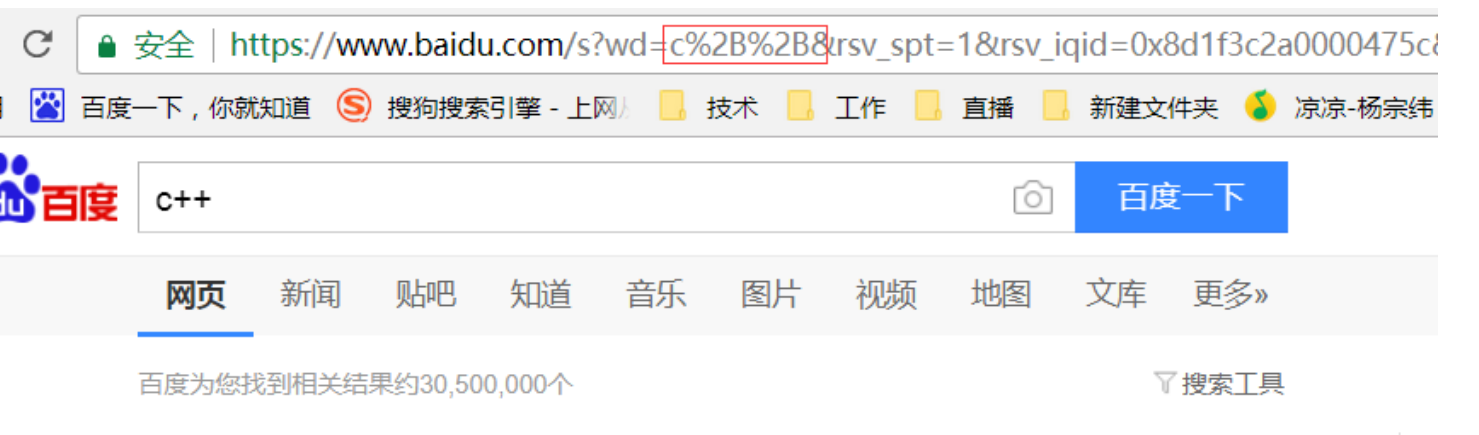
"+"被转义成了"%2B"
认识HTTP 请求方法(GET、POST 及其他)
| 方法 | 核心作用 | 关键特点 |
|---|---|---|
| GET | 从服务器获取资源 | 1. 请求参数拼在 URL 后(如?id=1&name=xxx),肉眼可见;2. 参数长度有限(约 2KB);3. 不适合传敏感数据(如密码)。 |
| POST | 向服务器提交数据(如表单、文件) | 1. 请求参数放在正文里,不暴露在 URL 中;2. 参数长度无限制;3. 适合传敏感数据或大量数据(如上传图片)。 |
| PUT | 向服务器修改 / 替换资源 | 比如用新数据覆盖服务器上的旧资源(如更新用户信息),幂等(多次请求结果一致)。 |
| DELETE | 从服务器删除资源 | 比如删除某个用户账号,幂等。 |
| HEAD | 仅获取响应报头,不获取正文 | 作用与 GET 类似,但只返回报头(如判断资源是否存在),节省带宽。 |
| OPTIONS | 询问服务器 “支持哪些请求方法” | 常用于跨域请求(CORS)中,客户端先判断服务器是否允许自己的请求。 |
幂等性:指多次执行相同请求,服务器最终状态一致(如 GET 多次获取资源,服务器状态不变;POST 多次提交表单可能重复创建数据,非幂等)
使⽤Fiddler观察GET请求
打开Fiddler,访问搜狗主⻚,观察抓包结果. 是通过浏览器地址栏发送的GET请求.
![]()
下⾯的和sogou域名相关的请求,有些是通过html中的link/script/img标签产⽣的,例如

有些是通过ajax的⽅式产⽣的,例如

经典⾯试题:谈谈GET和POST的区别
- 语义不同:GET⼀般⽤于获取数据,POST⼀般⽤于提交数据.
- GET的body⼀般为空,需要传递的数据通过querystring传递,POST的querystring⼀般为空,需要传递的数据通过body传递
- GET请求⼀般是幂等的,POST请求⼀般是不幂等的.(如果多次请求得到的结果⼀样,就视为请求是 幂等的).
- GET可以被缓存,POST不能被缓存.(这⼀点也是承接幂等性)
补充说明:
- 关于语义:GET完全可以⽤于提交数据,POST也完全可以⽤于获取数据.
- 关于幂等性:标准建议GET实现为幂等的.实际开发中GET也不必完全遵守这个规则(主流⽹站都有 "猜你喜欢"功能,会根据⽤⼾的历史⾏为实时更新现有的结果.
- 关于安全性:有些资料上说"POST⽐GET请安全".这样的说法是不科学的.是否安全取决于前端在 传输密码等敏感信息时是否进⾏加密,和GETPOST⽆关.
- 关于传输数据量:有的资料上说"GET传输的数据量⼩,POST传输数据量⼤".这个也是不科学的,标准没有规定GET的URL的⻓度,也没有规定POST的body的⻓度.传输数据量多少,完全取决于不 同浏览器和不同服务器之间的实现区别.
- 关于传输数据类型:有的资料上说"GET只能传输⽂本数据,POST可以传输⼆进制数据".这个也是 不科学的.GET的querystring虽然⽆法直接传输⼆进制数据,但是可以针对⼆进制数据进⾏url encode.
Cookie
1. Cookie 核心作用:解决 HTTP 的 “健忘症”
HTTP 协议本身是 “无状态” 的,这意味着服务器无法记住上一次和用户的交互。Cookie 正是为解决这个问题而生,主要有三个用途:
- 身份识别:用户登录后,服务器会下发一个包含身份信息的 Cookie。后续用户访问时,浏览器自动携带该 Cookie,服务器就能直接识别用户,无需重复登录。
- 个性化配置:记录用户的偏好,比如网页语言、主题颜色、字体大小等,下次访问时直接加载配置。
- 行为跟踪:电商网站用 Cookie 记录用户浏览过的商品,实现 “历史记录” 或 “猜你喜欢” 功能;广告平台也会用它分析用户行为,推送精准广告。
2. Cookie 工作流程:4 步完成数据交互
Cookie 的运作完全由浏览器和服务器自动完成,用户无需手动操作,具体流程如下:
- 用户首次请求:用户通过浏览器访问服务器(如打开某网站首页),此时 HTTP 请求中不包含任何 Cookie。
- 服务器生成 Cookie:服务器处理请求后,在 HTTP 响应头里加入
Set-Cookie字段,把需要存储的信息(如用户 ID、会话 ID)封装成 Cookie,发送给浏览器。 - 浏览器存储 Cookie:浏览器接收到响应后,会将 Cookie 以文本文件的形式保存在本地(不同浏览器存储路径不同)。
- 后续请求自动携带:用户再次访问该服务器时,浏览器会检查本地是否有该服务器的 Cookie。如果有,就会在 HTTP 请求头里加入
Cookie字段,将 Cookie 一并发送给服务器。
3. Cookie 的关键属性:控制其安全性和有效期
为了平衡功能和安全,Cookie 有几个重要属性,服务器会通过 Set-Cookie 字段设置这些属性:
- Expires/Max-Age:控制 Cookie 的有效期。
Expires是具体过期日期(如Expires=Wed, 05 Nov 2025 12:00:00 GMT);Max-Age是存活秒数(如Max-Age=3600表示 1 小时后过期)。没有这两个属性的 Cookie 是 “会话 Cookie”,关闭浏览器后自动删除。 - HttpOnly:禁止 JavaScript 读取该 Cookie,能有效防止 “XSS 跨站脚本攻击”(黑客无法通过脚本窃取 Cookie 里的身份信息)。
- Secure:仅允许 Cookie 在 HTTPS 加密连接中传输,避免在 HTTP 明文传输时被中途窃取。
- SameSite:限制 Cookie 跨网站携带,主要用于防范 “CSRF 跨站请求伪造攻击”。常见值有
Strict(完全禁止跨站携带)、Lax(部分跨站场景允许,如点击链接跳转)。
Cookie 是按域名和路径规则来携带的,不是按 “网页数量” 累积携带。具体来说:
- 当你登录成功后,服务器会下发一个与该域名绑定的 Cookie(比如
www.example.com的 Cookie)。 - 之后你访问该域名下的所有子页面(不管是第几个网页),只要这些页面属于同一个域名(或符合 Cookie 的
Domain和Path属性规则),浏览器都会自动携带这个 Cookie,而不是 “前面两个网页的 Cookie 都带上”。
举个例子:你在 www.example.com/login 登录成功,服务器下发了 www.example.com 域名的 Cookie。之后你访问 www.example.com/home、www.example.com/profile 这些同域名下的子页面时,都会携带这个 Cookie,而不是 “第一个网页的 Cookie + 第二个网页的 Cookie + 第三个网页的 Cookie”。