上信考:【数据科学技术及应用】考试大纲题型示例、例题解析、模拟卷答案
目录
例题解析
单选题,共10题,20分(二级)
多选题,共5题,10分(二级8分,三级2分)
考试大纲题型示例
1.单选题
2.多选题
3.简答题
4.分析操作题
5.综合应用题
模拟卷答案
一、单选题
二、多选题
三、操作题:
(一) 简答题
(二)分析操作题
(三)综合应用题
主包今年参加了“2025年上海市高等学校信息技术水平考试”,在复习的时候发现模拟卷是没有答案的,所以抽空做这一篇文章
例题解析
单选题,共10题,20分(二级)
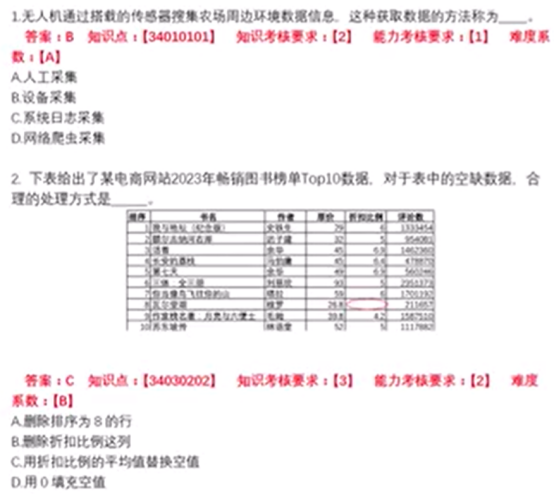
【例】某平台分析大学生常用的手机品牌适合展示各品牌的使用比例。
A.直方图
- 饼图
- C.折线图
- D.箱须图
【参考答案】B
【例】数据智能主要依赖于技术从大量数据中提取有价值的信息。
A. 机器学习
B.传统数据库查询
C.手工数据分析
D.简单的统计计算
【参考答案】C
多选题,共5题,10分(二级8分,三级2分)
【例】(二级)数据科学的知识结构主要由组成。
- 生活常识
B.数学
C.计算机科学
D.领域专业知识
【参考答案】BCD
【例】(三级)多模态大模型能够基于文本描述生成包含相关内容的图像,主要采用了等技术。
- 大规模预训练模型
- 文本图像语义表示对齐
- 跨模态学习
- 图像库自动筛选
- 【参考答案】ABC
考试大纲题型示例
1.单选题
2.多选题
3.简答题
4.分析操作题
(可选择任意分析工具或编写 Python 程序实现分析过程)
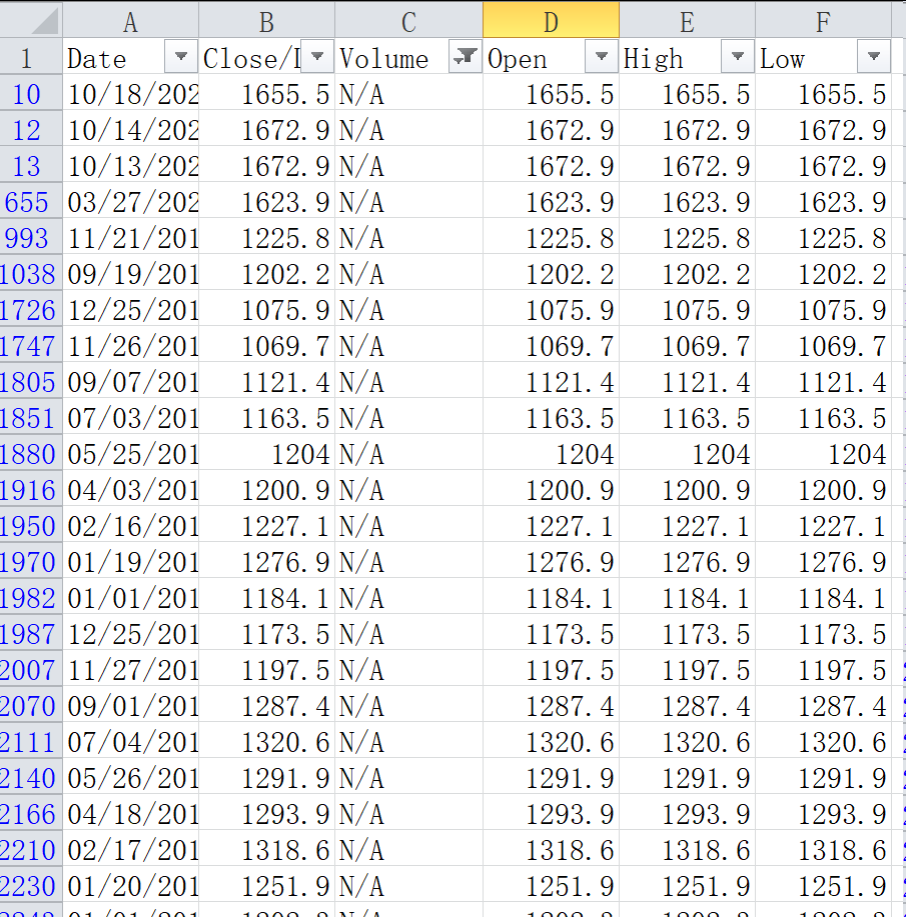
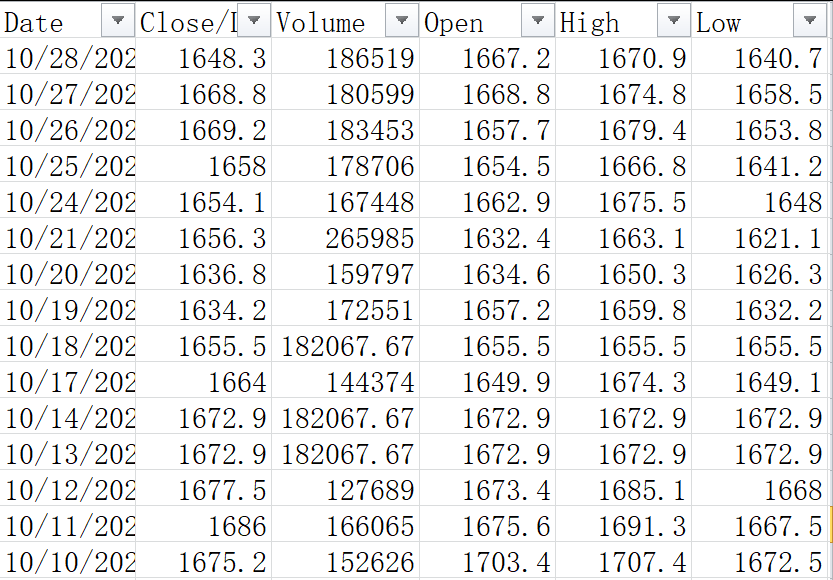
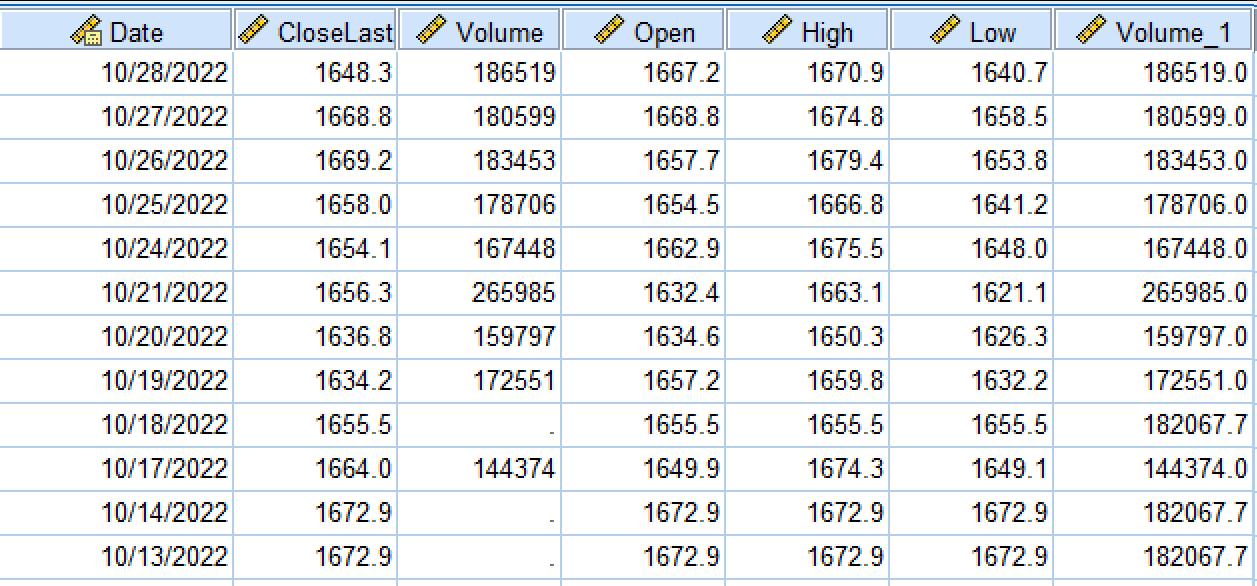
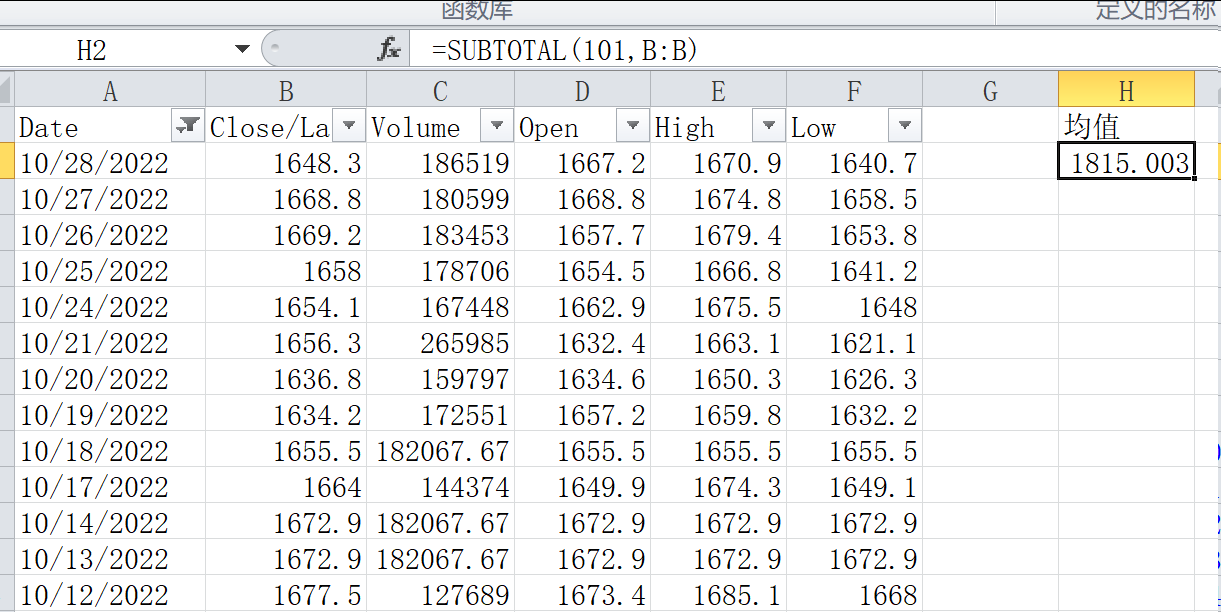
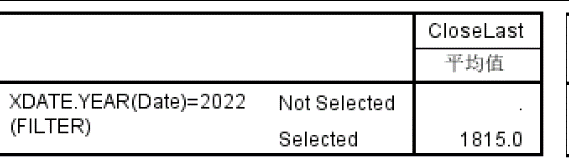
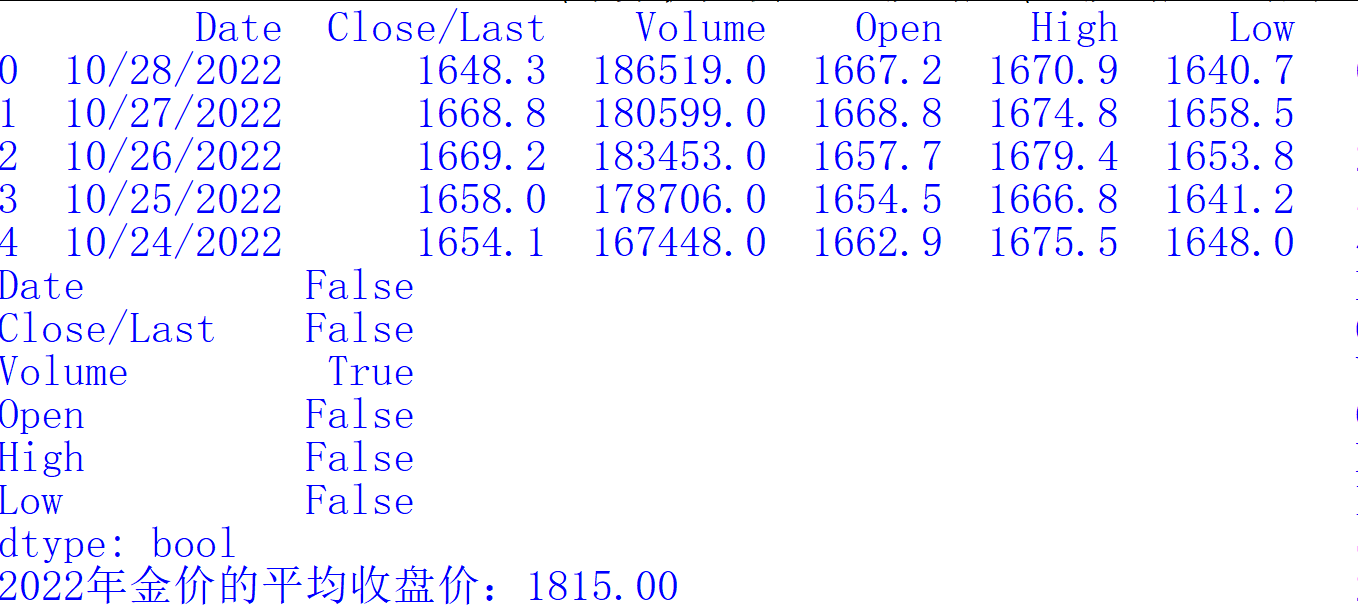
5.综合应用题
模拟卷答案
一、单选题
B. 设备采集
C. 用折扣比例的平均值替换空值
D. 众数
B. 大模型使用互联网上过去数十年的文本、图像数据训练模型
B. 饼图
A. 人工智能
B. 回归
A. 图像识别
C. 时序分析技术
A. 文本分类
二、多选题
B. 数学
C. 计算机科学
D. 领域专业知识
C. 计算订阅量均值和标准差
D. 绘制订阅量的直方图
A. 家庭视频监控报警
C. 分析 X 光片进行疾病诊断
A. 线性回归
C. 朴素贝叶斯
D. 随机森林
A. 大规模预测结果(Transformer)
B. 文本图像语义表示对齐
C. 跨模态学习
三、操作题:
(一) 简答题
1. 分位数在高中赋分制中的应用
答:高中赋分制将学生成绩按排名比例划分为10个等第,这实质上是使用分位数(特别是十分位数)对成绩进行分段。具体方法如下:
将所有考生的原始分数从高到低排序
将排序后的数据分为10个等分,每个等分包含10%的考生
第1等第对应前10%的考生(90%分位数以上)
第2等第对应前10%-20%的考生(80%-90%分位数)
依此类推,第10等第对应后10%的考生(10%分位数以下)
这样可以将不同难度的考试原始分转换为相对公平的等第成绩。
2. K-means在超市选址中的应用
答:企业可以利用K-means聚类方法进行分店选址决策:
确定分店数目:通过肘部法则或轮廓系数确定最优的K值(分店数量)
数据准备:将居民住宅区的经纬度作为二维特征数据
聚类分析:对经纬度数据进行K-means聚类,每个簇的中心点即为潜在分店选址
选址优化:选择簇内居民点密集、交通便利的簇中心作为最终分店位置
决策依据:确保每个分店的服务半径覆盖足够多的居民区,同时避免分店之间服务范围重叠
(二)分析操作题
1

1. np.random.uniform
2. axis=1
3. totals[totals<30]
4. film_booking.argmax()
2.
[1] RestHomes["性质"] == "民营"
[2] groupby("区")
[3] sort_values
[4] plot.pie
3.
[1] read_csv
[2] isnull()
[3] fillna(data['Volume'].mean(), inplace=True)
[4] jj.mean()
4.
[1] merge
[2] ds.columns
[3] concat
[4] ds["城市"] == "上海"
(三)综合应用题
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import OneHotEncoder
from sklearn.ensemble import RandomForestClassifier
from sklearn.svm import SVC
from sklearn.metrics import classification_report, accuracy_score
# 1) 读取数据
data = pd.read_csv('happiness.csv')
# 2) 幸福感转换为数值型
happiness_mapping = {'非常不幸福':1, '比较不幸福':2, '说不上幸福不幸福':3,
'无法回答':3, '比较幸福':4, '非常幸福':5}
data['幸福值'] = data['幸福感'].map(happiness_mapping)
# 3) 独热编码处理养老责任特征
encoder = OneHotEncoder(sparse_output=False)
养老责任_encoded = encoder.fit_transform(data[['养老应该由谁负责']])
养老责任_df = pd.DataFrame(养老责任_encoded, columns=encoder.get_feature_names_out(['养老应该由谁负责']))
data = pd.concat([data, 养老责任_df], axis=1)
# 4) 统计幸福感分布并绘制饼图
happiness_counts = data['幸福感'].value_counts()
plt.figure(figsize=(8, 8))
plt.pie(happiness_counts.values, labels=happiness_counts.index, autopct='%1.1f%%')
plt.title('幸福感分布情况')
plt.show()
# 5) 计算相关系数,筛选最相关特征
numeric_data = data.select_dtypes(include=[np.number])
correlations = numeric_data.corr()['幸福值'].abs().sort_values(ascending=False)
top_feature = correlations.index[1] # 排除幸福值自身
# 6) 构建特征数据集
feature_columns = [col for col in data.columns if col not in ['幸福感', '幸福值', '养老应该由谁负责']]
feature_columns = [col for col in feature_columns if col in numeric_data.columns]
X = data[feature_columns]
y = data['幸福值']
# 7) 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
# 8) 建立两种分类模型
# 随机森林
rf_model = RandomForestClassifier(n_estimators=100, random_state=42)
rf_model.fit(X_train, y_train)
# 支持向量机
svm_model = SVC(kernel='rbf', random_state=42)
svm_model.fit(X_train, y_train)
# 9) 测试模型性能
rf_pred = rf_model.predict(X_test)
svm_pred = svm_model.predict(X_test)
print("随机森林分类报告:")
print(classification_report(y_test, rf_pred))
print("支持向量机分类报告:")
print(classification_report(y_test, svm_pred))
# 10) 模型效果比较
rf_accuracy = accuracy_score(y_test, rf_pred)
svm_accuracy = accuracy_score(y_test, svm_pred)
print(f"随机森林准确率: {rf_accuracy:.4f}")
print(f"支持向量机准确率: {svm_accuracy:.4f}")
if rf_accuracy > svm_accuracy:
print("随机森林模型在此数据集上表现更好")
else:
print("支持向量机模型在此数据集上表现更好")
声明:著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
创作声明:部分内容由AI辅助生成
内容来源网络,进行整合/再创作