Agent 设计与上下文工程- 02 Workflow 设计模式(上)
⛓️
Workflow 设计模式(上)
学习目标:掌握 Prompt Chaining、Routing、Parallelization 三种基础 Workflow 模式,理解它们的适用场景和实现方法
前置知识:理解 Workflow 与 Agent 的区别(见上一节)
预计时间:40-50 分钟
上一节我们聊了 Workflow 和 Agent 的区别,知道了 Workflow 是通过预定义代码路径来编排 LLM 和工具的。但具体怎么编排?有哪些常见的模式?
Anthropic 总结了五种基础 Workflow 模式,这节课我们先讲前三种:Prompt Chaining、Routing、Parallelization。这三种模式相对简单,但非常实用,几乎能覆盖 80% 的场景。
Prompt Chaining:任务分解的艺术
Prompt Chaining 可能是最直观的 Workflow 模式了。它的核心思想是:把复杂任务分解为一系列顺序步骤,每步处理前一步的输出。
我第一次接触这个概念的时候,觉得这不就是写代码吗?把任务拆成函数,一个接一个调用。但后来发现,关键在于如何拆分任务,以及如何在步骤之间传递上下文。
为什么需要 Prompt Chaining
你可能会问,为什么不能让 LLM 一次性完成所有事情?主要有几个原因:
复杂任务超出了单次调用的推理深度。就像人解决复杂问题需要分步思考一样,LLM 也需要分步处理。而且每个步骤专注于一个子任务,LLM 的表现会更好。
中间步骤可以加入程序化检查。比如你可以验证第一步的输出是否符合格式要求,不符合就重试,而不是等到最后才发现问题。
透明度和可控性更高。你能看到每一步的输出,出了问题好定位。而且可以在步骤之间插入外部逻辑,比如调用 API、查询数据库。
💡
AWS 的文档里有个很好的总结:Prompt Chaining 用延迟换准确度。每多一步,延迟就增加一点,但每步的任务变简单了,整体准确度反而提高了。
实战案例:文档生成流程
我们来看一个实际的例子。假设你要生成一份产品分析报告,如果让 LLM 一次性生成,可能会遗漏要点或者结构混乱。但如果用 Prompt Chaining,就可以这样设计:
def generate_report(product_name):# 步骤1:生成大纲outline = llm.generate(prompt=f"为 {product_name} 生成详细的分析报告大纲,包括市场定位、竞品分析、技术特点、用户反馈四个部分")# 步骤2:检查大纲是否完整if not validate_outline(outline):outline = llm.generate(prompt=f"之前的大纲不完整,请重新生成:{outline}")# 步骤3:逐部分生成内容sections = []for section in outline.sections:content = llm.generate(prompt=f"基于以下大纲,详细撰写 {section.title} 部分:\n{section.description}\n\n要求:数据支撑、逻辑清晰、字数 500-800 字")sections.append(content)# 步骤4:生成摘要summary = llm.generate(prompt=f"基于以下内容生成执行摘要(200 字以内):\n{' '.join(sections)}")# 步骤5:格式化输出return format_report(summary, outline, sections)看到了吗?每一步都有明确的目标,而且步骤之间有检查和验证。这样做的好处是,如果某一步出了问题,你能快速定位,而不是整个报告重新生成。
为什么不在一个 prompt 里完成?
你可能会想,能不能在一个很长的 prompt 里告诉 LLM"先生成大纲,然后检查大纲,然后生成各部分内容"?理论上可以,但实际效果往往不好。因为 LLM 容易跳过某些步骤,或者步骤之间的逻辑不够严谨。而且你没法在中间插入程序化检查,比如调用外部 API 获取数据。
设计 Prompt Chain 的原则
我自己在实践中总结了几个原则,分享给你:
每步任务要单一明确。不要让一步做太多事情,比如"生成内容并格式化"就不如拆成两步。
步骤之间的依赖要清晰。后一步依赖前一步的哪些信息,要明确定义。不要让 LLM 猜测你要传什么数据。
加入验证和重试机制。关键步骤的输出要验证,不符合预期就重试。但要设置最大重试次数,避免无限循环。
考虑失败的传播。如果某一步失败了,是停止整个流程,还是跳过这一步继续?这个要根据业务需求来定。
⚠️
Prompt Chaining 的链条不要太长。我的经验是,超过 5 步就要考虑是不是可以简化或者用其他模式。链条太长,延迟会很高,而且调试起来很痛苦。
适用产品场景
从产品角度看,Prompt Chaining 最适合那些需要保证质量、可以接受一定延迟的场景。
内容生成类产品最适合用 Prompt Chaining。比如你做一个营销文案生成工具,用户更在意的是文案质量,而不是 1 秒还是 3 秒出结果。这个时候,用 Prompt Chaining 把生成过程拆成"理解需求 → 生成大纲 → 撰写正文 → 优化润色"几个步骤,每步都做好,最终质量会比一次性生成高很多。
数据处理流程也很适合。比如你做一个财务报表分析工具,需要"提取数据 → 清洗异常值 → 计算指标 → 生成图表 → 撰写分析"。这种场景下,每步都有明确的输入输出,用 Prompt Chaining 能保证每个环节都可控,出了问题也好定位。
但要注意,实时交互的场景不适合。如果用户期望秒级响应,比如聊天机器人,用 5 步的 Prompt Chain 就会让用户等得不耐烦。这个时候要么简化链条,要么考虑其他模式。
💼
产品设计建议:如果用户能看到进度("正在生成大纲..."、"正在撰写内容..."),他们对延迟的容忍度会高很多。所以用 Prompt Chaining 的时候,最好配合进度提示,让用户知道系统在做什么。
Routing:智能分流的关键
Routing 模式解决的是另一个问题:不同类型的输入需要不同的处理流程。
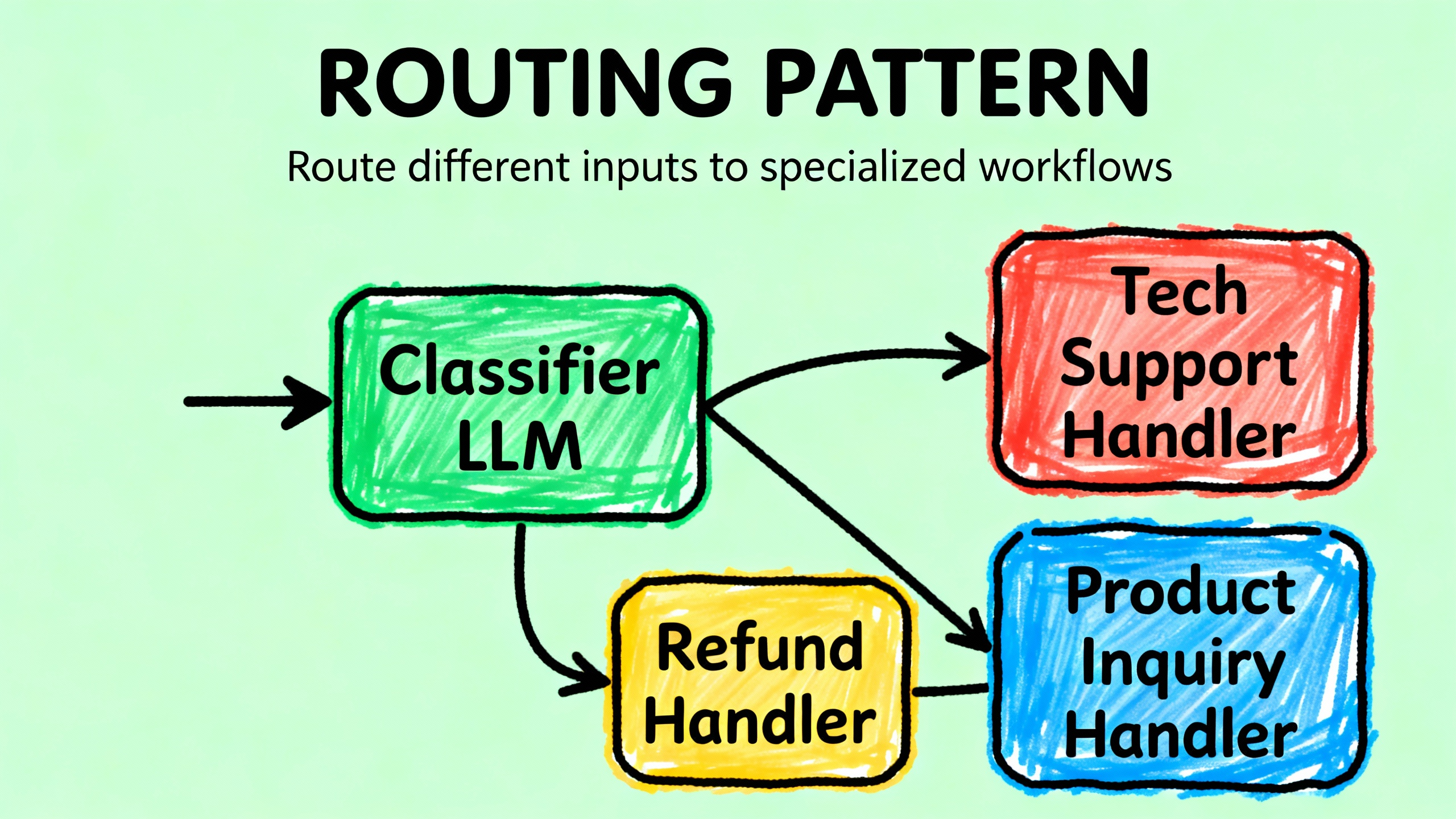
我最早遇到这个需求是在做客服系统的时候。用户的问题五花八门,有的是退款,有的是技术支持,有的是常规咨询。如果用一个 prompt 处理所有类型,效果很差,因为每种类型的处理逻辑完全不同。
这个时候 Routing 就派上用场了。它的核心是:先分类,再路由到专门的处理流程。
Routing 的两种实现方式
Routing 可以用 LLM 来做分类,也可以用传统的分类模型。我倾向于用 LLM,因为更灵活,而且可以处理模糊的边界情况。
def customer_service_router(user_query):# 步骤1:分类category = llm.classify(prompt=f"""分类以下客户问题,返回类别编号:
1. 退款相关
2. 技术支持
3. 产品咨询
4. 其他问题:{user_query}只返回数字,不要解释。""")# 步骤2:路由到专门流程if category == "1":return handle_refund(user_query)elif category == "2":return handle_technical_support(user_query)elif category == "3":return handle_product_inquiry(user_query)else:return handle_general(user_query)这里的关键是,每个处理函数可以有自己的 prompt、自己的工具、自己的逻辑。比如退款流程可能需要查询订单数据库,技术支持可能需要搜索知识库,产品咨询可能需要调用推荐算法。
Routing 的高级用法:多级路由
有的时候,一级分类不够细。比如技术支持还可以分为"软件问题"和"硬件问题",软件问题又可以分为"安装问题"和"使用问题"。这个时候可以用多级路由。
def advanced_router(user_query):# 一级分类main_category = llm.classify(user_query, categories=["退款", "技术支持", "咨询"])if main_category == "技术支持":# 二级分类sub_category = llm.classify(user_query, categories=["软件", "硬件"])if sub_category == "软件":# 三级分类detail = llm.classify(user_query, categories=["安装", "使用", "其他"])return handle_software_issue(user_query, detail)else:return handle_hardware_issue(user_query)else:return handle_other(user_query, main_category)但要注意,层级不要太深,每多一级就多一次 LLM 调用,延迟会增加。我的经验是,两级够用,三级就要慎重了。
🎯
Routing 还有一个很实用的场景:模型选择。你可以把简单问题路由到小模型(便宜快速),复杂问题路由到大模型(贵但效果好)。这样可以在成本和效果之间取得平衡。
Routing 的设计要点
分类要互斥而且完备。每个输入只能属于一个类别,而且所有可能的输入都要有对应的类别。如果做不到,就加一个"其他"类别兜底。
分类的 prompt 要清晰。给 LLM 明确的分类标准,最好有示例。不要让 LLM 自己猜测你的分类逻辑。
考虑边界情况。有些输入可能横跨多个类别,这个时候要么让 LLM 返回多个类别,要么设计一个优先级规则。
真实案例:Notion AI 的 Routing
Notion AI 的"帮我写"功能就是个很好的 Routing 例子。用户可以选择"博客文章"、"待办事项"、"会议纪要"等不同类型,每种类型背后是不同的 prompt 和处理逻辑。这样做的好处是,每种类型都能得到最优化的输出,而不是用一个通用 prompt 勉强应付所有场景。
适用产品场景
Routing 最大的价值在于让产品既简单又专业。用户看到的是一个统一的入口,但背后针对不同场景做了专门优化。
客服系统是 Routing 的经典场景。用户的问题千奇百怪,如果用一个通用 prompt 处理,效果肯定不好。但如果先分类(退款、技术支持、产品咨询),然后路由到专门的处理流程,每个流程都可以针对性优化。退款流程重点是效率和准确性,技术支持重点是问题诊断,产品咨询重点是推荐合适的方案。
成本优化也是一个很实际的应用。我见过一个团队,用 Routing 把简单问题(FAQ、基础查询)路由到小模型,复杂问题(深度分析、创意生成)路由到大模型。这样做之后,成本降低了 60%,但用户体验没有明显下降,因为简单问题本来就不需要大模型。
多语言产品也适合 Routing。根据用户的语言自动路由到对应语言的 prompt 和知识库,而不是让一个通用模型勉强处理所有语言。这样每个语言都能得到原生级别的体验。
💼
产品设计建议:Routing 的分类逻辑要对用户透明。如果系统把用户的问题分类错了,要让用户能轻松纠正,比如"我的问题不是退款,是技术支持"。这样既能提升体验,又能收集数据优化分类模型。
Parallelization:并行提速的魔法
Parallelization 是我最喜欢的模式之一,因为效果立竿见影。它的核心思想是:把独立的任务并行执行,而不是串行等待。
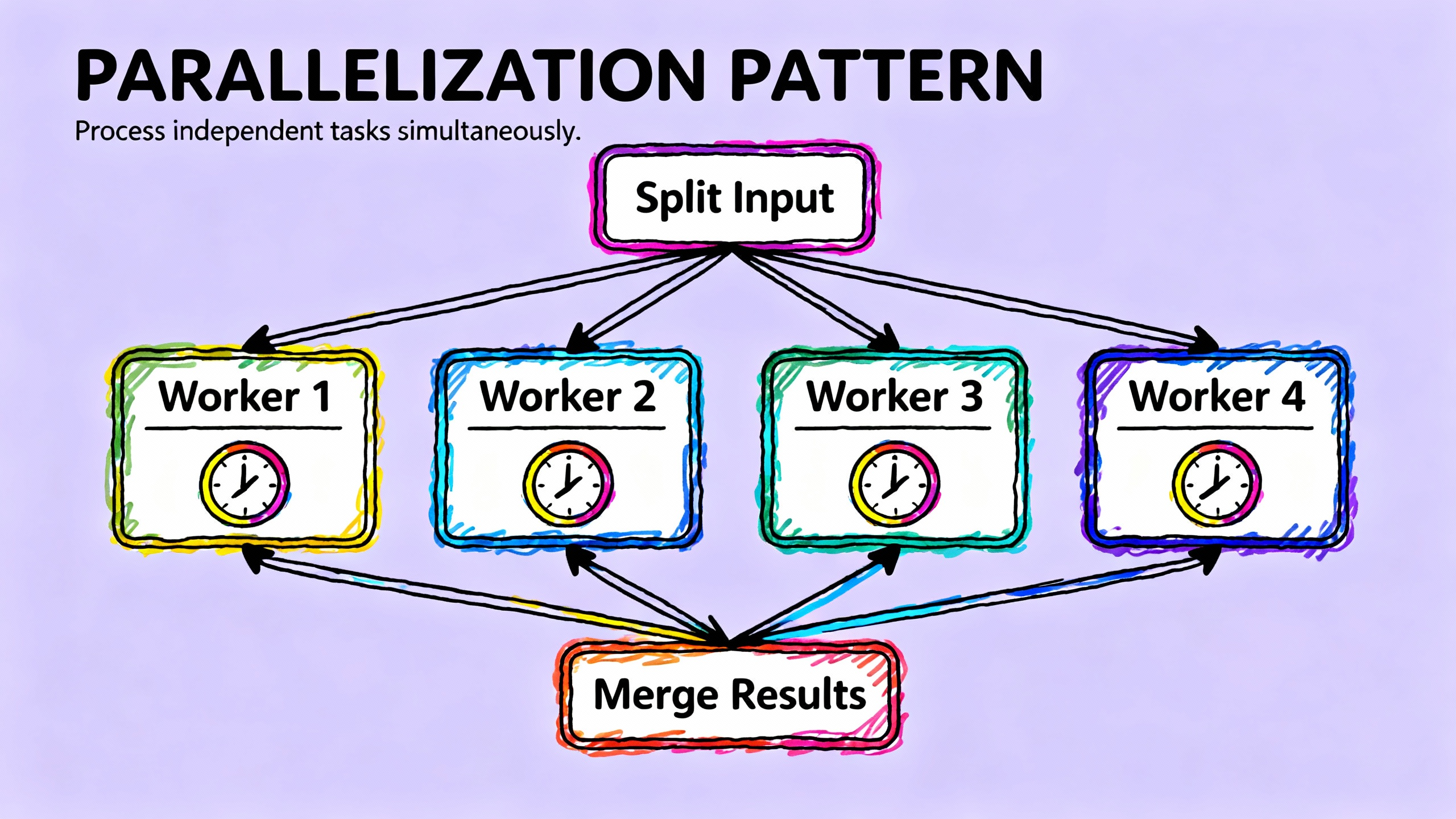
我第一次用这个模式的时候,把一个需要读取 5 个文件的任务从 50 秒优化到了 10 秒,提速 5 倍。原因很简单:这 5 个文件的读取是独立的,完全可以同时进行。
Parallelization 的两种形式
Anthropic 把 Parallelization 分为两种:Sectioning 和 Voting。
Sectioning 是把任务拆分为独立的子任务,并行执行。比如你要分析一篇长文档,可以把文档分成几段,每段分别分析,最后汇总结果。
async def analyze_document(document):# 把文档分成 4 段sections = split_into_sections(document, num_sections=4)# 并行分析每一段tasks = [llm.analyze_async(section, prompt="提取关键信息")for section in sections]results = await asyncio.gather(*tasks)# 汇总结果summary = llm.generate(prompt=f"基于以下分析结果生成总结:\n{results}")return summaryVoting 是对同一个任务运行多次,然后选择最好的结果或者投票决定。这个在需要高可靠性的场景很有用。
async def code_review_with_voting(code):# 用 3 个不同的 prompt 审查代码prompts = ["检查代码的安全漏洞","检查代码的性能问题","检查代码的可维护性"]# 并行执行tasks = [llm.review_async(code, prompt=p) for p in prompts]reviews = await asyncio.gather(*tasks)# 汇总所有发现的问题all_issues = []for review in reviews:all_issues.extend(review.issues)# 去重和优先级排序return deduplicate_and_prioritize(all_issues)什么时候用 Parallelization
判断标准很简单:任务之间有没有依赖。如果任务 A 的输出不影响任务 B,那就可以并行。
典型的适用场景包括:多文件读取、批量 API 调用、多个独立的数据处理任务、多个搜索查询。
但要注意几个陷阱。如果任务之间有依赖,强行并行会出错。比如任务 B 需要任务 A 的结果,那就必须等 A 完成。
并发数量要控制。不要一次性启动 1000 个任务,会把系统搞垮。用信号量(semaphore)限制并发数,比如同时最多 10 个任务。
共享状态要小心。如果多个任务写同一个文件或者修改同一个变量,需要加锁。不然会出现竞态条件(race condition)。
⚠️
Parallelization 最容易出问题的地方是错误处理。如果某个并行任务失败了,怎么办?是整个流程失败,还是只记录错误继续?这个要提前设计好。
适用产品场景
Parallelization 的价值非常直接:让用户少等待。在用户对速度敏感的场景,这个模式能带来立竿见影的体验提升。
批量处理场景是最明显的应用。比如你做一个简历筛选工具,HR 上传 100 份简历,需要提取关键信息、匹配岗位要求。如果串行处理,100 份简历可能要 10 分钟;如果并行处理,可能只要 2 分钟。这个差别对用户来说是巨大的,决定了他们愿不愿意用你的产品。
多维度分析也很适合。比如你做一个市场分析工具,需要从"用户评论"、"竞品对比"、"价格趋势"、"社交媒体"四个维度分析一个产品。这四个维度的分析是独立的,完全可以并行执行,最后汇总结果。用户看到的是一份完整的报告,但生成速度快了 4 倍。
A/B 测试场景也可以用 Parallelization。比如你要测试 3 种不同的文案风格,可以并行生成 3 个版本,然后让用户选择最喜欢的。这比串行生成 3 次要快得多,用户的等待体验会好很多。
但要注意,并行不是免费的。它会增加系统复杂度,增加成本(同时调用多个 API)。所以要在速度和成本之间权衡。如果用户对速度不敏感,或者成本压力很大,串行处理可能是更好的选择。
💼
产品设计建议:用 Parallelization 的时候,最好有个"快速预览"功能。比如 100 份简历并行处理,可以先展示已经处理完的 20 份,让用户有事可做,而不是干等着全部完成。这种渐进式的体验会比"全部完成才展示"好很多。
Parallelization 的性能优化
我在实践中发现,Parallelization 的性能提升不是线性的。比如 10 个任务并行,不一定比串行快 10 倍,可能只快 5-7 倍。原因是有开销:任务调度、结果汇总、网络延迟等。
优化的关键是减少任务之间的通信。尽量让每个任务独立完成,不要频繁交换数据。而且要合理分配任务大小,避免某个任务特别慢拖累整体进度。
性能对比:串行 vs 并行
假设你要读取 5 个文件,每个文件需要 10 秒。串行执行总共 50 秒。如果并行执行,理论上只需要 10 秒(最慢的那个任务的时间)。但实际上可能需要 12-15 秒,因为有任务调度和结果汇总的开销。即便如此,提速也是非常明显的。
• • •
🎯
核心要点:Prompt Chaining 把复杂任务分解为顺序步骤,适合需要逐步推理的场景。Routing 根据输入类型分流到不同处理流程,适合多样化的输入。Parallelization 并行执行独立任务,适合无依赖的批量操作。这三种模式可以组合使用,比如先 Routing 分类,然后 Prompt Chaining 处理,中间某些步骤用 Parallelization 加速。
下一节预告
下一节我们会继续学习另外两种更高级的 Workflow 模式:Orchestrator-Workers 和 Evaluator-Optimizer。这两种模式适合更复杂的场景,比如需要动态分解任务,或者需要迭代优化输出。