ICML 2025|基于大语言模型的多比特文本水印方法
1 引言
由字节跳动研究院、密歇根州立大学以及加州大学圣克鲁兹分校的研究者联合完成的论文《Robust Multi-bit Text Watermark with LLM-based Paraphrasers》发表于ICML 2025。该研究提出了一种利用大语言模型实现的多比特文本水印方法,通过对文本进行语义一致的改写来嵌入隐藏信息,并能精准地检测出水印。研究者训练了两种风格略有差异的语言模型改写器,让它们在保持原文意思不变的同时生成具有可识别特征的文本,从而实现高效的信息嵌入与提取。该方法兼顾了水印的隐蔽性、稳健性和通用性,为AI生成内容的溯源与版权保护提供了新的技术方案。
2 研究背景
在文本水印领域,研究者长期致力于在保持文本可读性和语义一致性的前提下,将隐蔽信息嵌入自然语言中,用于内容溯源、版权保护及AI生成内容检测等任务。现有研究大体可以分为两类:基于词汇替换的传统方法与基于模型生成的水印方法。然而,这些方法在信息容量、鲁棒性和不可察觉性方面仍存在局限。该论文正是在这一背景下提出,旨在解决现有方法无法同时兼顾隐蔽性、鲁棒性与多比特信息嵌入的问题。
| 类别 | 代表研究 | 核心方法 | 优点 | 局限性 |
|---|---|---|---|---|
| 基于词汇替换的水印 | ReversibleNLW | 通过同义词替换或词频特征编码实现水印嵌入 | 方法简单、可控性强 | 易被改写破坏、语义可察觉、信息容量有限 |
| 基于深度模型的文本水印 | Waterfall | 使用LSTM/Transformer改写器生成含水印文本 | 可嵌入多比特信息、检测精度高 | 隐蔽性较弱、对改写攻击敏感 |
| 面向LLM输出的水印 | KGW | 在LLM生成阶段调整采样分布或token概率 | 无需修改输入文本、适配LLM生成检测 | 仅适用于生成文本、通用性不足 |
| 强化学习与联合训练方法 | RL-Watermark | 采用PPO强化学习框架对LLM进行水印嵌入优化 | 可联合训练水印检测器与生成模型 | 尚未实现高容量多比特水印、鲁棒性有限 |
该论文提出的基于LLM改写的多比特文本水印方法,在改写机制、训练框架与鲁棒性上均实现突破。研究通过两种语义一致但风格差异微小的LLM改写器交替生成文本,实现了隐蔽的多比特水印嵌入,并结合PPO强化学习实现改写器与检测器的协同优化,使文本既自然流畅又可高精度解码。相比以往方法仅能嵌入少量信息、易被改写破坏、可察觉性高等问题,该方法在隐蔽性、鲁棒性和通用性上均表现优越,为AI生成内容的溯源与版权保护提供了更高效的解决方案。
3 论文方法
3.1 输入定义与目标设定
给定原始文本序列xo=[w1,w2,…,wT]x_o = [w_1, w_2, \dots, w_T]xo=[w1,w2,…,wT]其由连续的词语或标记构成,用以表示一段具有完整语义结构的自然语言内容;同时设待嵌入的多比特水印信息为 M=[m1,m2,…,mL],M∈{0,1}LM = [m_1, m_2, \dots, m_L], \quad M \in \{0,1\}^LM=[m1,m2,…,mL],M∈{0,1}L 其中,LLL表示水印比特序列的长度,每个比特 mim_imi 对应一个待编码的二值信息单元。系统的核心目标是:在保持文本原始语义一致性与自然流畅性的约束下,将离散的比特序列 MMM 通过语言模型的生成与改写机制隐式地嵌入到自然语言表达中,从而生成具有水印特征的文本表示:xw=E(xo,M)x_w = E(x_o, M)xw=E(xo,M) 其中,E(⋅)E(\cdot)E(⋅)表示语义编码器或基于大型语言模型的改写函数。该过程通过在潜空间中对语言表达的句法结构、词汇选择或风格特征进行微小扰动,实现比特级的信息嵌入,同时最大限度地保持文本的语义等价性和人类可读性。
3.2 解码阶段
解码器D(⋅)D(\cdot)D(⋅)被设计为一个句级文本分类器,其主要任务是从已生成的带水印文本xwx_wxw中识别并恢复出所嵌入的水印比特序列。该模块承担了整个系统的“信息提取”职责,通过学习句段的隐含语义特征与潜在统计规律,判断每个句段所对应的比特值。对于每个句段sis_isi,解码器通过参数化的分类函数g(⋅;θD)g(\cdot; \theta_D)g(⋅;θD)提取特征表示,并利用Sigmoid函数σ(⋅)\sigma(\cdot)σ(⋅)输出属于比特1的概率,从而建立句段与比特之间的概率映射关系:pθD(mi=1∣si)=σ(g(si;θD))p_{\theta_D}(m_i = 1 | s_i) = \sigma(g(s_i; \theta_D))pθD(mi=1∣si)=σ(g(si;θD))在此基础上,整个解码过程可形式化为:M′=D(xw)=[m^1,m^2,…,m^L′]M^\prime= D(x_w) = [\hat{m}_1, \hat{m}_2, \dots, \hat{m}_{L'}]M′=D(xw)=[m^1,m^2,…,m^L′]其中,m^i\hat{m}_im^i表示模型预测的第iii位比特值,L′L^\primeL′ 为可成功预测出的比特长度。为了保证解码结果的有效性与语义一致性,系统在设计上要求解码出的比特序列满足前缀一致性约束(Prefix Consistency Constraint):M′=M[:len(M′)]M^\prime = M[:\text{len}(M^\prime)]M′=M[:len(M′)]该约束意味着:在可解码范围内,模型应确保已恢复出的比特序列与原始水印序列MMM的前缀部分严格一致,从而保证信息在传递与重构过程中无损还原。这一机制有效增强了解码阶段的鲁棒性,使模型能够在面对轻微改写、同义替换或语法扰动时,仍保持较高的水印识别准确率与鲁棒性。
3.3 编码阶段
解码器D(⋅)D(\cdot)D(⋅)被设计为一个句级文本分类器,其主要功能是从生成的带水印文本xwx_wxw中识别并恢复出嵌入的比特序列。 该模块的核心思想是通过建模句子层面的语义差异,学习文本在隐空间中因水印嵌入而产生的微小分布变化,从而实现比特信息的解码与恢复。具体而言,对于每个句段sis_isi,解码器通过一个参数化的判别函数g(si;θD)g(s_i; \theta_D)g(si;θD)提取其语义特征,并使用Sigmoid 函数σ(⋅)\sigma(\cdot)σ(⋅)输出该句段对应比特值为 的概率:pθD(mi=1∣si)=σ(g(si;θD))p_{\theta_D}(m_i = 1 | s_i) = \sigma(g(s_i; \theta_D))pθD(mi=1∣si)=σ(g(si;θD))基于此,模型对整段文本的预测可形式化为:M′=D(xw)=[m^1,m^2,…,m^L′]M' = D(x_w) = [\hat{m}_1, \hat{m}_2, \dots, \hat{m}_{L'}]M′=D(xw)=[m^1,m^2,…,m^L′]其中,m^i\hat{m}_im^i表示预测的第iii个比特,L′L'L′为成功识别的比特序列长度。为确保解码结果的正确性与鲁棒性,系统引入了前缀一致性约束:M′=M[:len(M′)]M' = M[:\text{len}(M')]M′=M[:len(M′)]即要求解码出的序列M′M'M′必须与原始水印序列MMM的前缀严格对应,确保在可识别范围内信息无损传递。 这一约束不仅保证了解码阶段的稳定性,也使系统在面对同义改写、句式变化或语言噪声干扰时,仍能保持高水平的水印恢复精度。通过这种机制,解码器在句子级别建立了比特信息与语义结构之间的稳健映射关系,从而实现“语义等价生成—比特可逆恢复”的闭环过程。
3.4 协同优化阶段
为实现鲁棒的水印嵌入与可逆的信息恢复,系统采用基于强化学习的联合优化框架,对编码器与解码器进行协同训练。核心思想是通过奖励函数将语义保持与水印可识别性两者同时纳入优化目标,使生成文本既自然流畅,又能稳定携带并恢复水印信号。定义联合奖励函数如下:r(xw,M)=λw⋅Acc(M′,M)+λs⋅Sim(xw,xo)r(x_w, M) = \lambda_w \cdot \text{Acc}(M', M) + \lambda_s \cdot \text{Sim}(x_w, x_o)r(xw,M)=λw⋅Acc(M′,M)+λs⋅Sim(xw,xo)
其中,Acc(M′,M)\text{Acc}(M', M)Acc(M′,M)表示水印比特的解码准确率,反映水印信息传递的可识别性,Sim(xw,xo)\text{Sim}(x_w, x_o)Sim(xw,xo)表示生成文本与原文本的语义相似度(通常采用嵌入余弦相似度或句向量匹配度),λw,λs\lambda_w, \lambda_sλw,λs为权重系数,用于平衡可解码性与语义保真性的重要程度。在此框架下,采用近端策略优化算法(PPO) 对编码器参数θE\theta_EθE与解码器参数θD\theta_DθD同时更新。优化目标定义为:maxθE,θDE[r(xw,M)]−βKL(πθE∥πref)\max_{\theta_E, \theta_D} \ \mathbb{E}\left[r(x_w, M)\right] - \beta \, \text{KL}\big(\pi_{\theta_E} \| \pi_{\text{ref}}\big)θE,θDmax E[r(xw,M)]−βKL(πθE∥πref)其中πθE\pi_{\theta_E}πθE表示当前编码策略,πref\pi_{\text{ref}}πref表示参考语言模型策略,β\betaβ为KL正则化系数,用于控制生成分布的偏离程度,防止模型过度调整导致语义漂移。通过该优化过程,系统在生成阶段学习如何以最小语义扰动实现比特信息的稳健嵌入,同时在解码阶段强化分类器对隐式水印信号的识别能力。最终,实现从语义一致文本生成到可逆比特恢复的闭环映射:(xo,M)→Exw→DM′(x_o, M) \xrightarrow{E} x_w \xrightarrow{D} M'(xo,M)ExwDM′这一过程有效地统一了“语言自然性”和“信息可恢复性”两大目标,使模型在面对改写、噪声或同义替换等复杂场景时,依然保持稳定的水印识别性能。
4 实验结果
4.1 整体性能对比
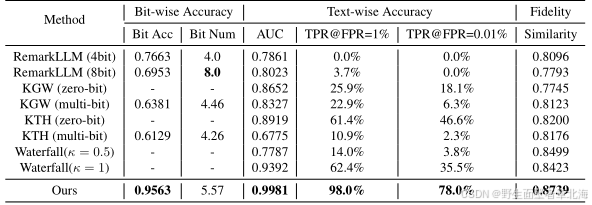
该实验的主要目的是全面验证本文提出的多比特文本水印方法在整体检测性能方面的有效性与优越性。实验在C4 RealNewsLike数据集上进行,选用了TinyLlama-1.1B作为基础架构,同时将其分别微调为两种大模型改写器与一个基于语言模型的文本分类器,构成完整的水印嵌入与检测体系。对比实验涵盖了多种主流水印方法,包括基于固定比特水印的RemarkLLM、基于采样策略扰动的KGW与KTH,以及采用概率重采样机制的Waterfall模型。结果如下表所示,该论文方法在位级精度和文本级检测AUC方面均显著超越其他模型,同时在文本语义保持性方面也达到最高水平,表明该方法能够在确保水印准确识别的同时保持自然语言的流畅性和语义一致性。这一实验充分验证了所提出的联合优化框架在检测性能与语义质量之间实现了理想平衡,为后续鲁棒性与泛化性分析奠定了基础。
4.2 鲁棒性测试
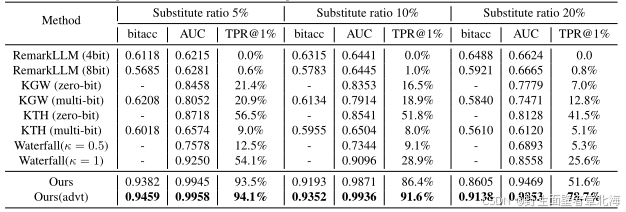
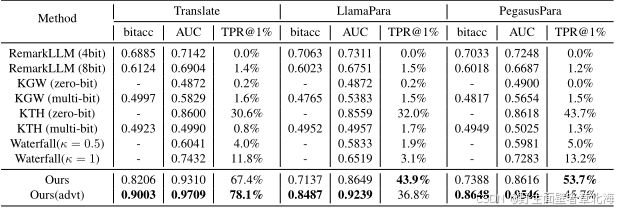
该实验旨在系统评估所提出的多比特文本水印方法在不同文本扰动条件下的鲁棒性与可恢复性。研究者分别设计了两类典型攻击场景:其一为词级替换攻击,即随机替换文本中5%、10%及20%的词汇,以模拟用户修改或自然语言生成过程中可能产生的噪声干扰;其二为句级改写攻击,包括翻译、Llama-2-7B改写以及 Pegasus改写三种形式,主要考察在深度语义改写下的水印保留能力。实验在相同的C4数据集与模型结构下进行,结果如下表所示。即使在20%词替换的极端条件下,模型的检测AUC仍高达0.94以上,而在轻度扰动下甚至可保持0.99的检测准确率;在句级改写攻击中,AUC仍稳定维持在0.93至0.97区间,对抗训练版本在所有类型的改写中均进一步提升了检测效果。这些结果表明,本文方法不仅能够在词汇替换和语义重组等自然语言变化下保持稳定的水印信号,还具备良好的自适应恢复能力,充分验证了其在真实语言环境中的鲁棒性与可靠性。
4.3 跨领域泛化能力
为验证所提方法的通用性与跨领域适应能力,研究者在C4 RealNewsLike之外选取了六个外部数据集进行跨域评估,涵盖HH-RLHF、PKU-SafeRLHF、Reward、UltraFeedback、FineWeb及Pile-Uncopyrighted等多种文本类型,覆盖问答、知识性与网络语料等多样语体。模型直接使用在C4上训练的参数进行零样本推理,不作微调,以评估其迁移能力。结果如表4所示,模型在HH、PKU、Reward与UltraFeedback等任务中检测AUC均超过0.99,语义相似度约为0.87;在结构化语料FineWeb与Pile中亦保持约0.97的AUC。整体而言,该实验表明该方法在不同领域与文本风格下均能稳定识别水印,展现出优异的跨域泛化性能与实际应用潜力。
