Springcloud_day01
目录
1课程导学
2MybatisPlus介绍
3入门案例
4常见注解
问题:
5常用配置
6核心功能-条件构造器
问题:
7自定义SQL
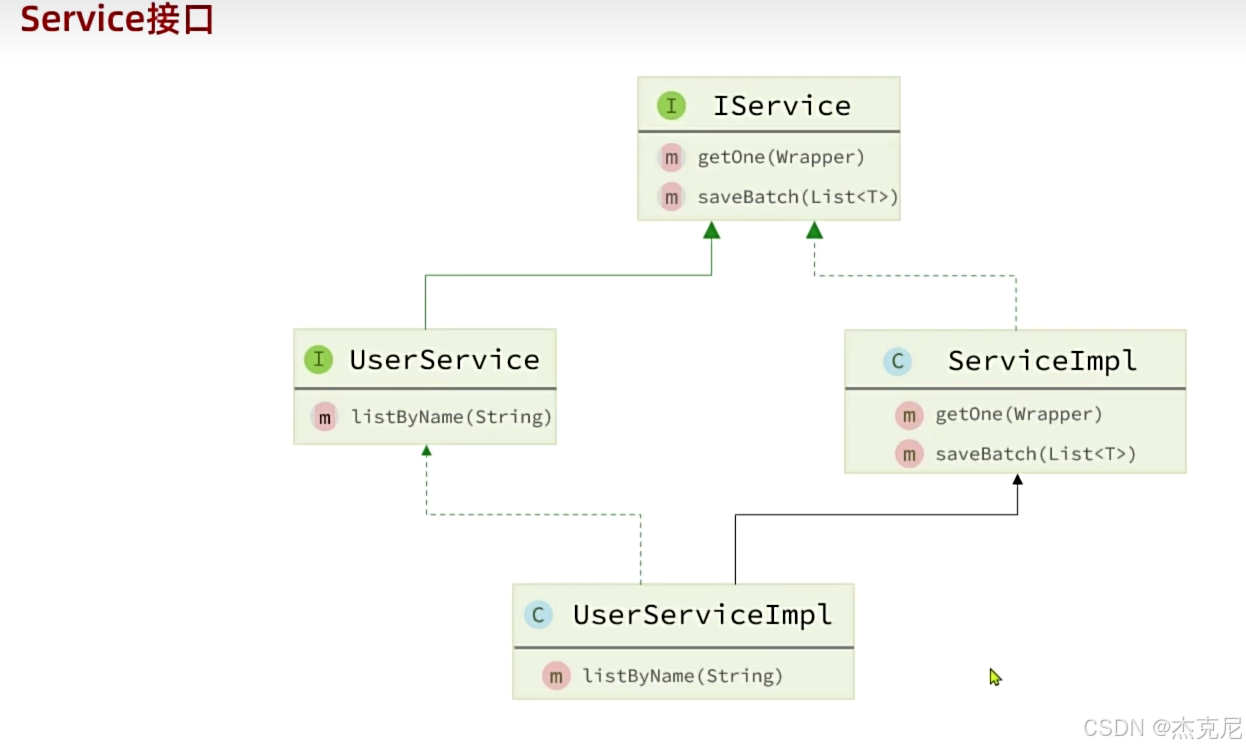
8IService接口的基本用法
9IService开发基础业务接口
问题:
10IService开发复杂业务接口
11IService的Lambda方法
12IService批量新增
13扩展功能-代码生成器
问题:
14DB静态工具
问题;
15DB静态工具练习
16逻辑删除
17枚举处理器
问题:
18JSON处理器
问题:
19分页插件的基本用法
20通用分页插件
问题:
21通用分页实体与MP转换
问题:
22总结
1课程导学
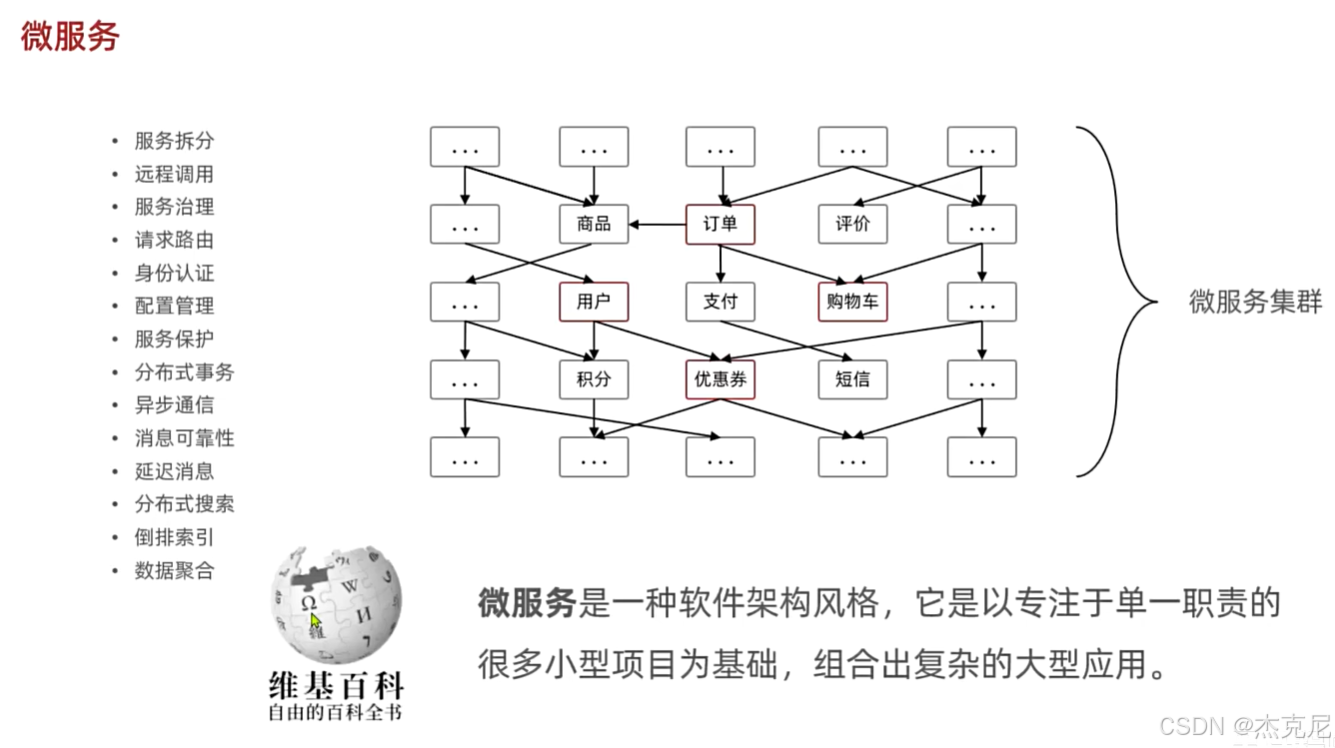
2MybatisPlus介绍
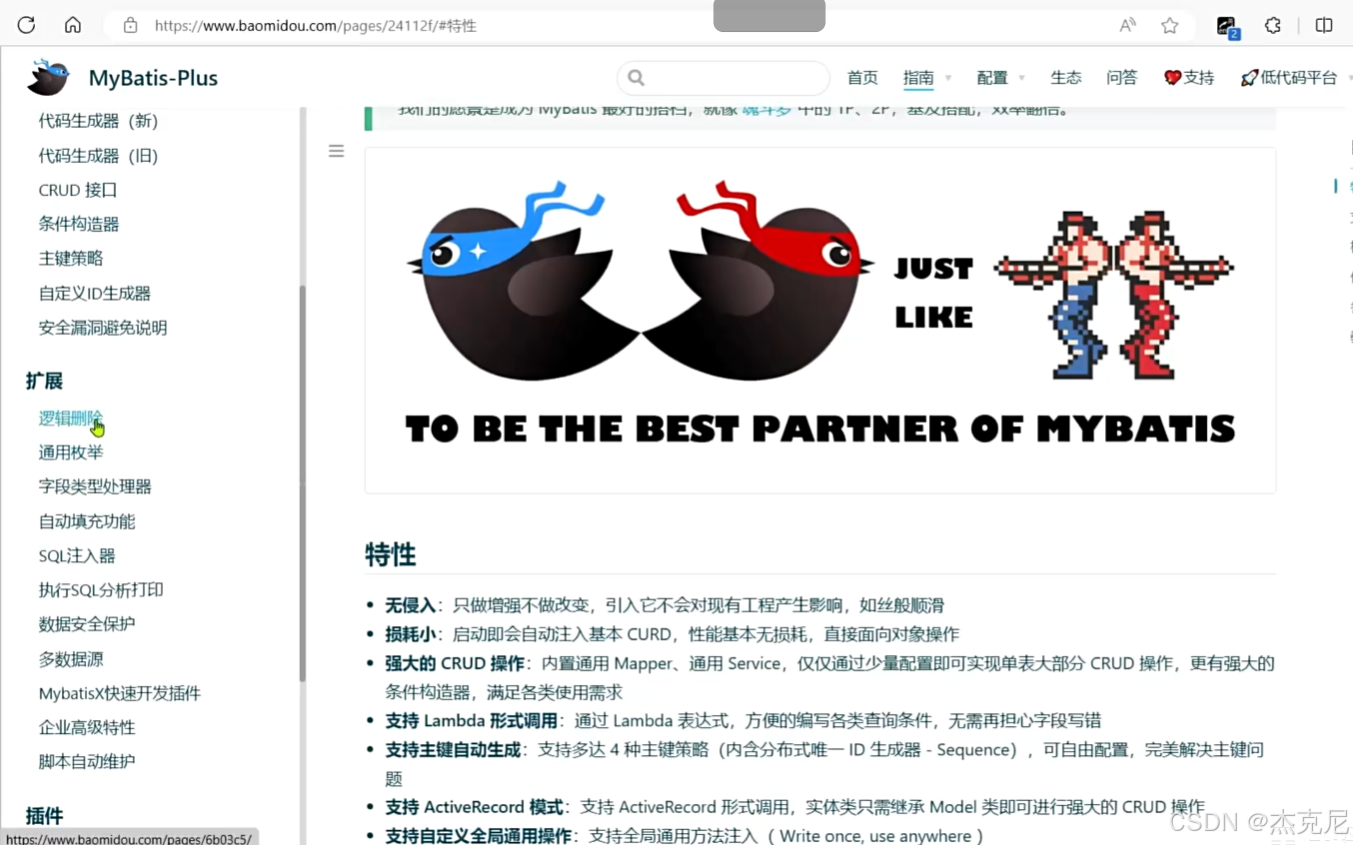

3入门案例


4常见注解


问题:
关键字冲突记得加反引号
5常用配置


6核心功能-条件构造器


第二个也可以使用UpdateWrapper
@Test
void testUpdateByUpdateWrapper() {// 1. 创建 UpdateWrapper 并设置更新条件和更新字段UpdateWrapper<User> updateWrapper = new UpdateWrapper<>();// 设置更新条件:username = "jack"updateWrapper.eq("username", "jack");// 设置要更新的字段:balance = 2000updateWrapper.set("balance", 2000);// 2. 执行更新userMapper.update(null, updateWrapper);
}
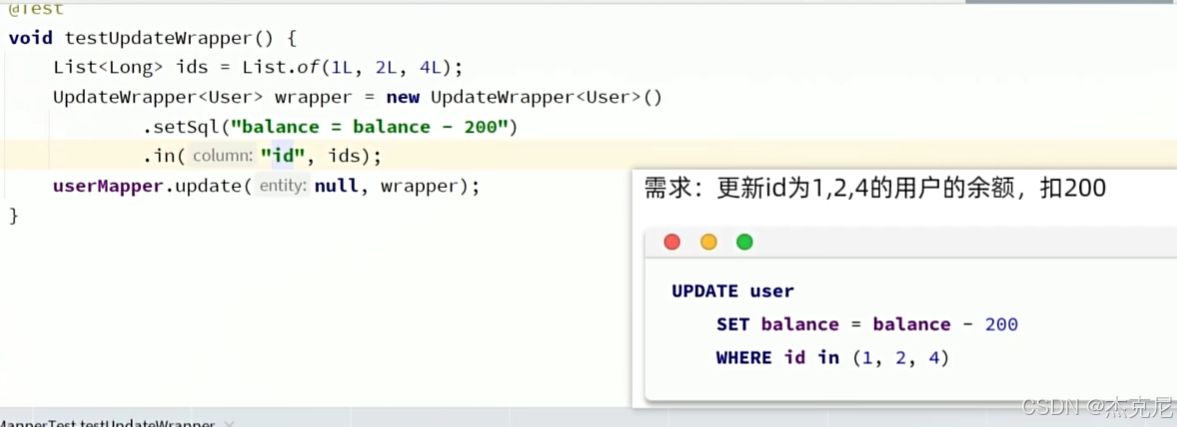

问题:
like寻找username含"0"里面为什么只写"0"而不是写成"*o*"?
在 MyBatis-Plus 的 QueryWrapper 中,like 方法的逻辑是默认进行模糊匹配(即 %o% 形式),所以只需要传入 "o" 即可实现 “名字中带 o” 的查询,无需手动写 *o* 或 %o%。
QueryWrapper 的 like 方法底层会自动为传入的 val 拼接百分号 %,即:
- 当你调用
.like("username", "o")时,MyBatis-Plus 会自动生成 SQL 片段username LIKE '%o%',含义是 “用户名中包含 o”。
如果手动写 *o* 或 %o%,反而会导致匹配逻辑错误(比如变成 LIKE '*o*',此时只有用户名是 *o* 才会匹配,完全不符合需求)。
如果需要更灵活的模糊匹配,还可以使用:
.likeLeft("username", "o"):生成username LIKE 'o%'(以 o 开头);.likeRight("username", "o"):生成username LIKE '%o'(以 o 结尾)。
7自定义SQL


8IService接口的基本用法
9IService开发基础业务接口
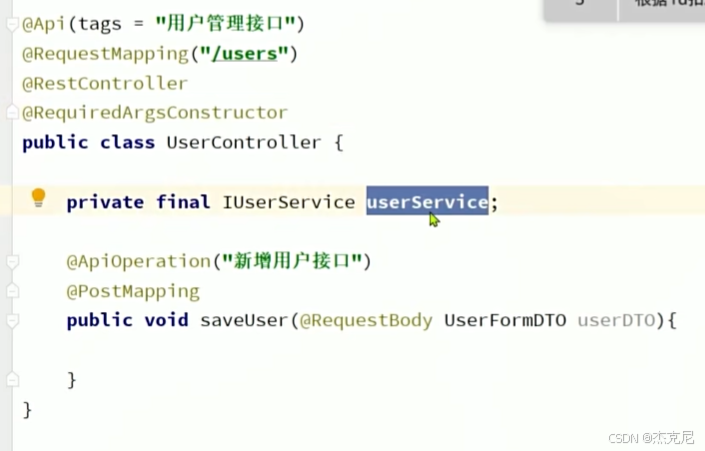
因为要使用到IUserService所以需要注入,一是使用@Autowired注入(但是不推荐),所以就使用构造器传参注入,但是这个写的比较繁琐,可以使用注解@RequiredArgsConstructor 加上final标记哪个变量需要依赖注入;(也可以使用@AllArgsConstructor(不过这个是给所有变量注入依赖))
另外我想问@RequestMapping和@RestController注解有什么用?为什么两个需要同时加?






问题:
要注意注解里面参数的写法已经形参列表里面参数前面的注解;注意区分
10IService开发复杂业务接口

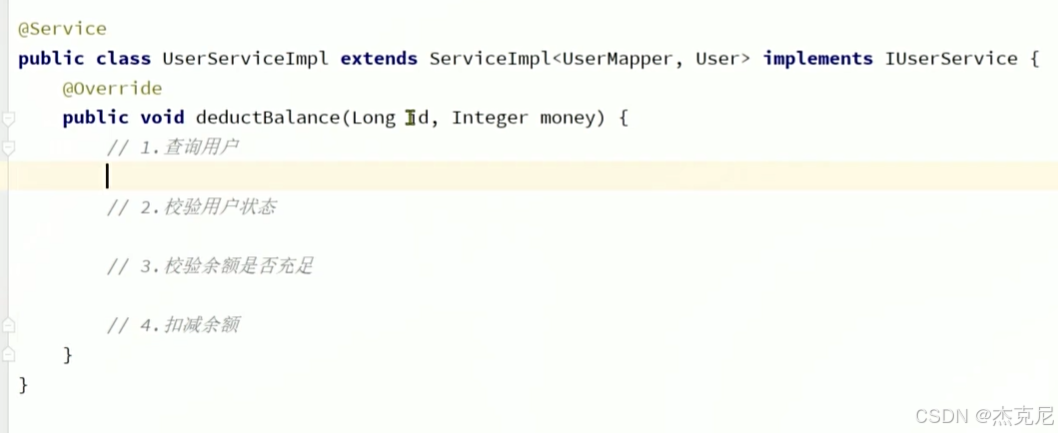
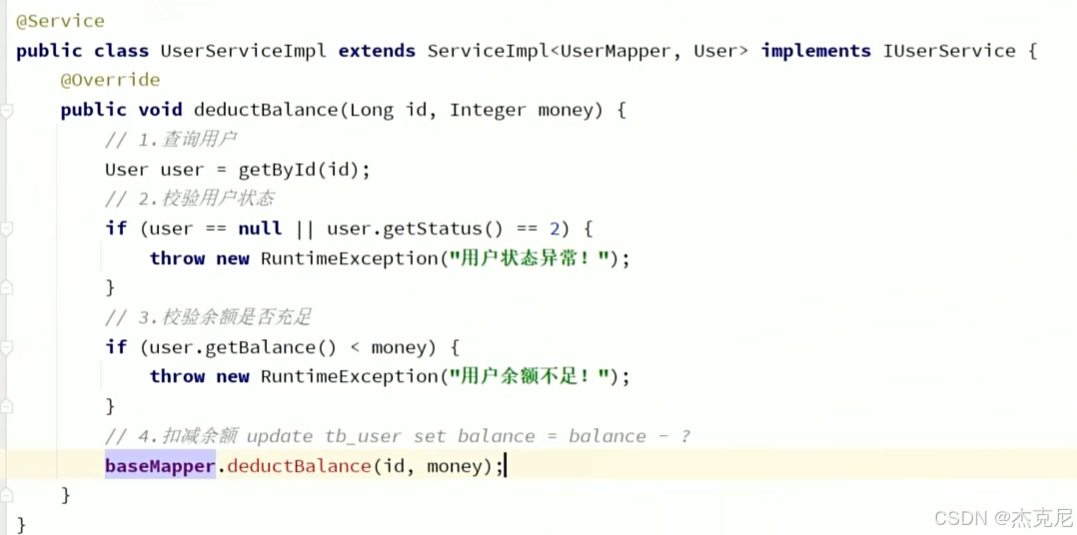
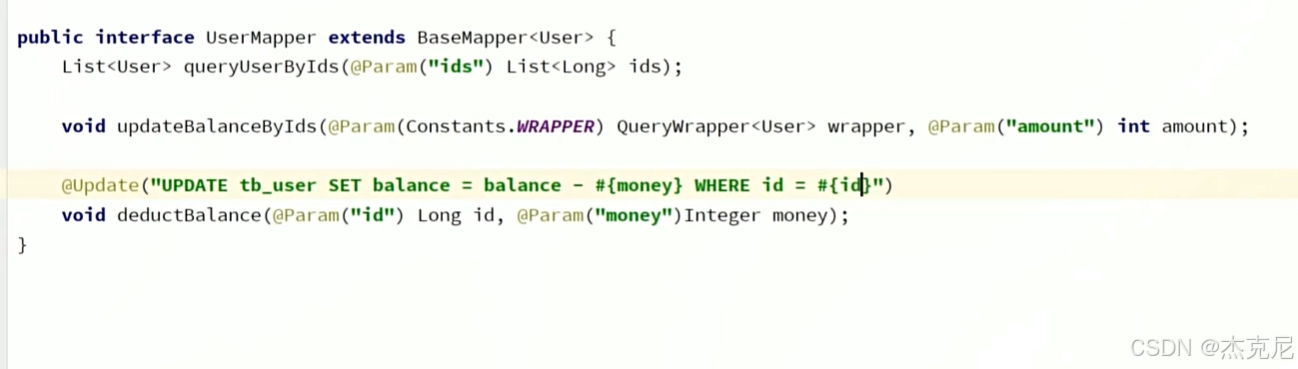
11IService的Lambda方法




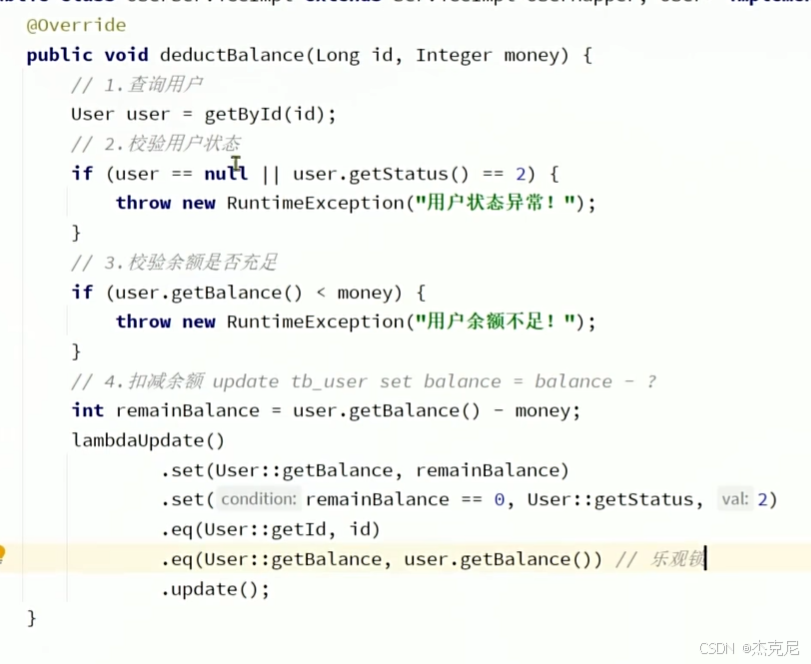
最后记得加.update()否则不会更新
12IService批量新增


问题:
为什么2IService批量插入还是性能不是最好?
因为虽然它是批量传集合,减少网络请求,但是处理的时候还是逐条处理
最后那个的话再数据库层使用的是foreach批量处理
13扩展功能-代码生成器


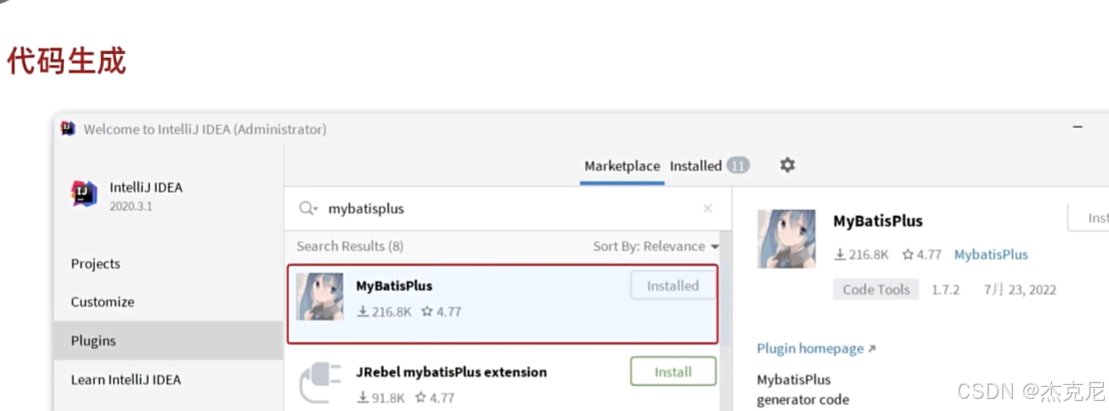
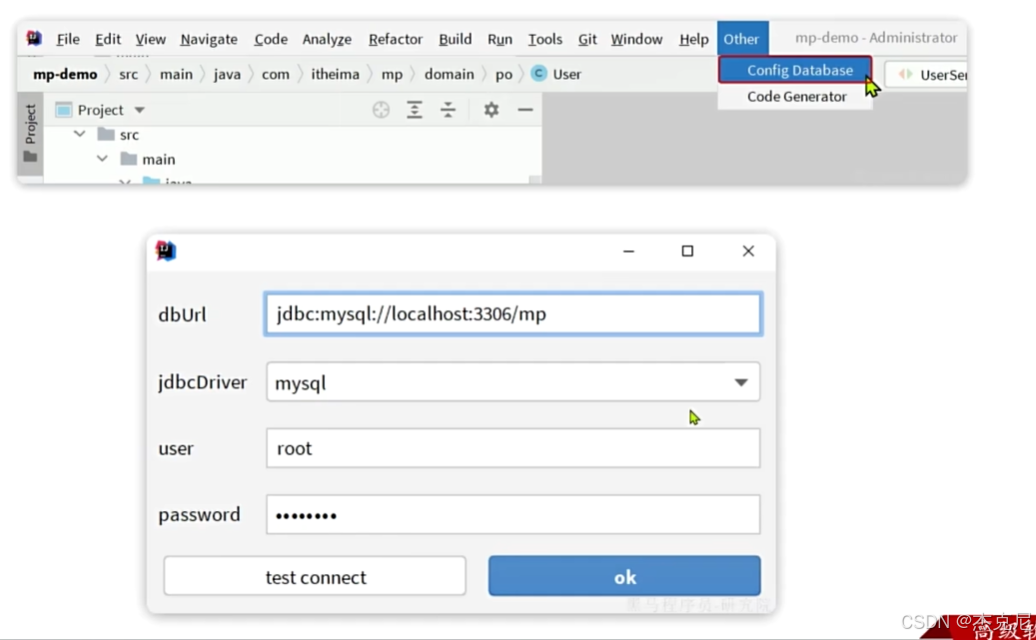
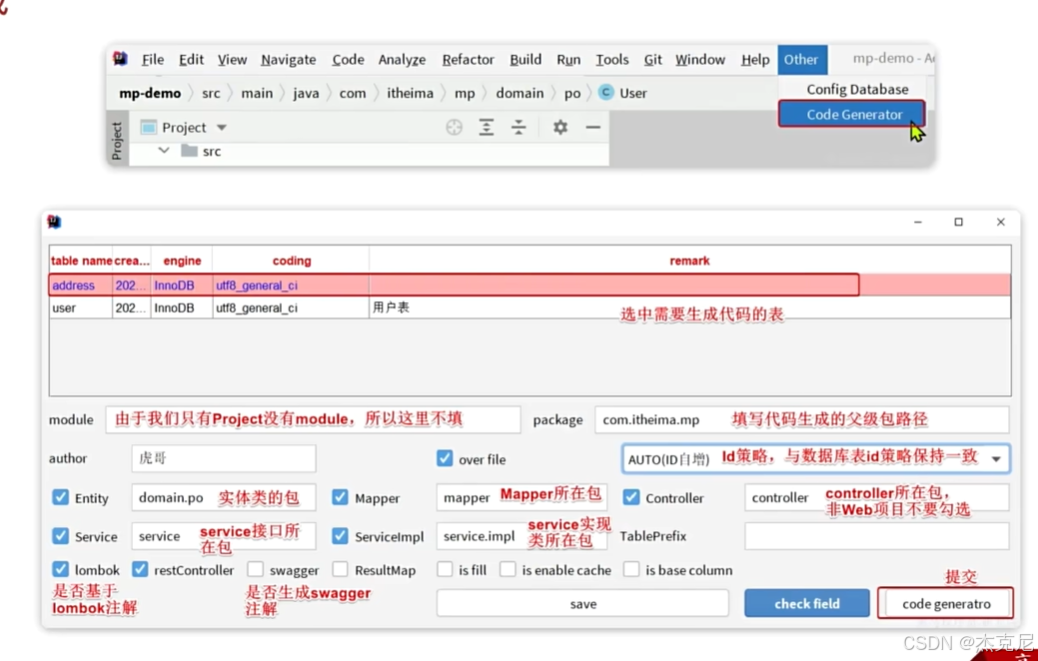
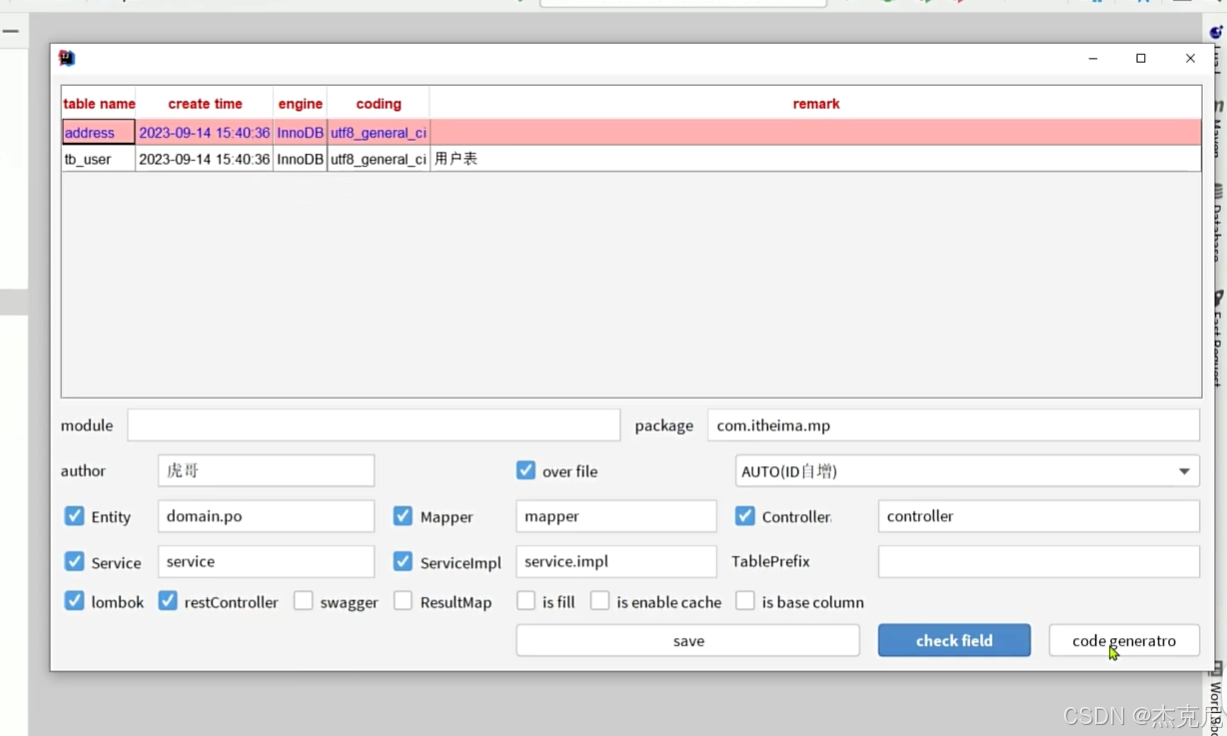
问题:
当数据库表名是tb_user时候,你想要生成的实体类等名字去掉前缀,可以在TablePrefix中写一下前缀就可以默认去掉;
另外,module是用于多模块,package只需要包的前缀即可
14DB静态工具
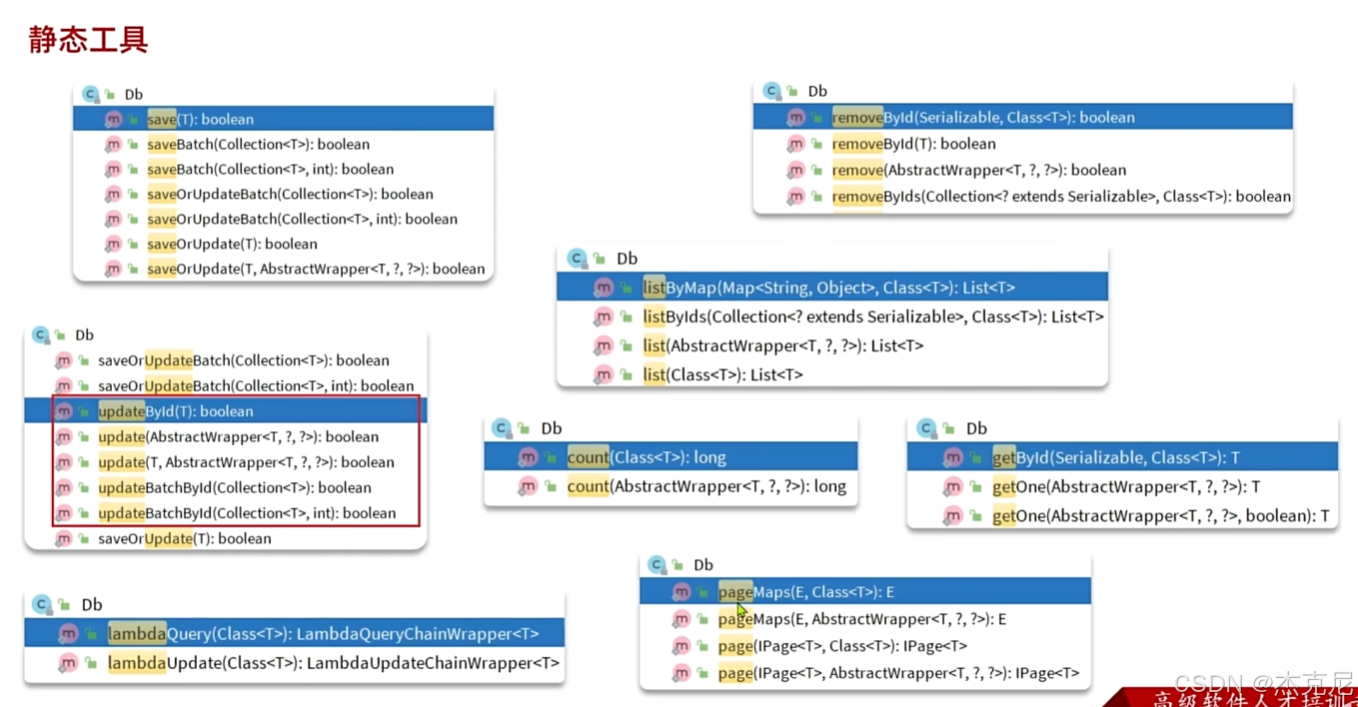
问题;
静态工具和Iservice的差别?
需要你告诉他实体类的类型(传参)
优点:
避免循环依赖,一旦出现Service相互调用,咱就使用静态工具
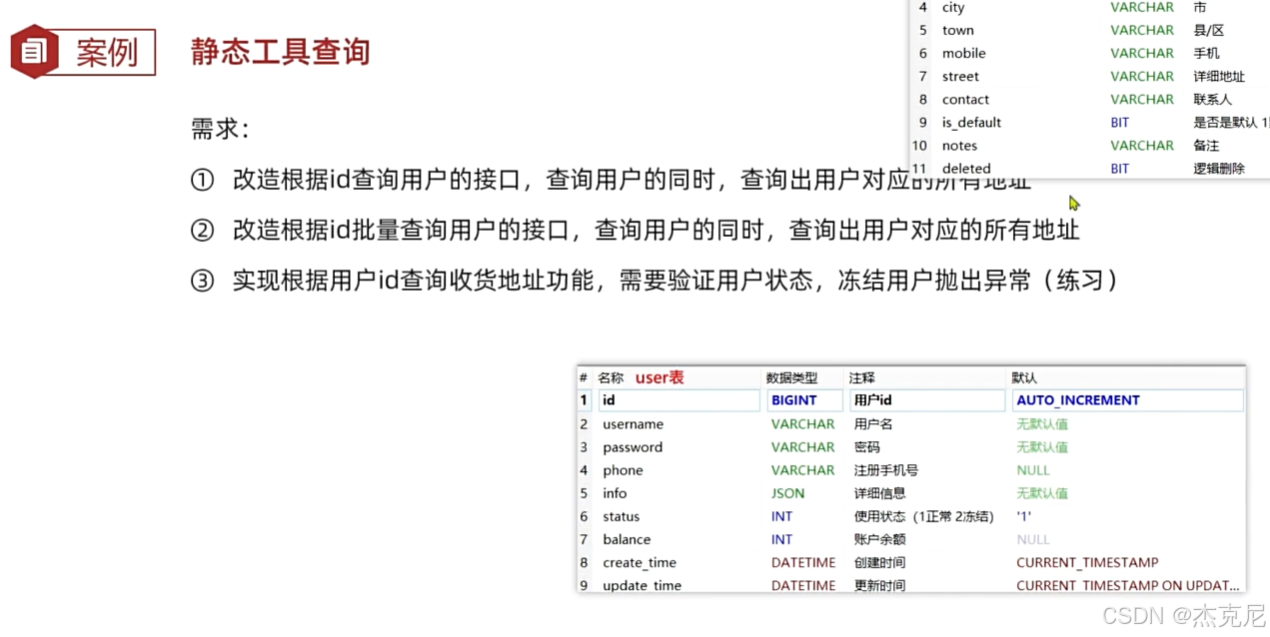
15DB静态工具练习


16逻辑删除
17枚举处理器
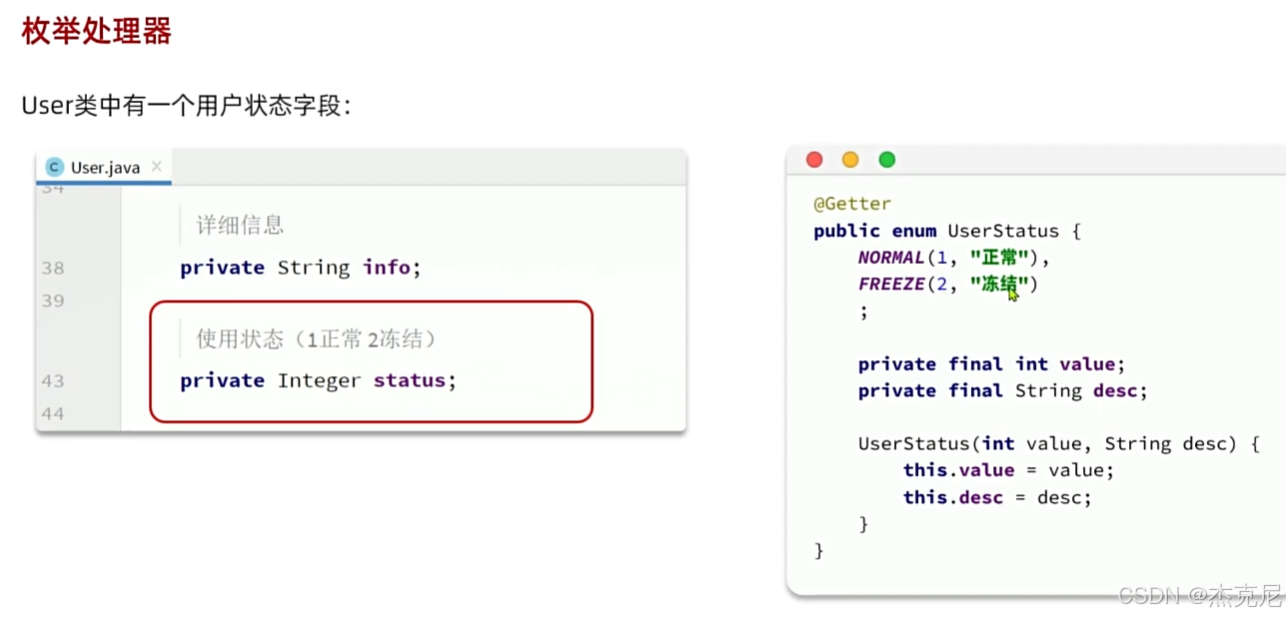

这样的话可以直接用==进行判断是否相等了,代码可读性也好
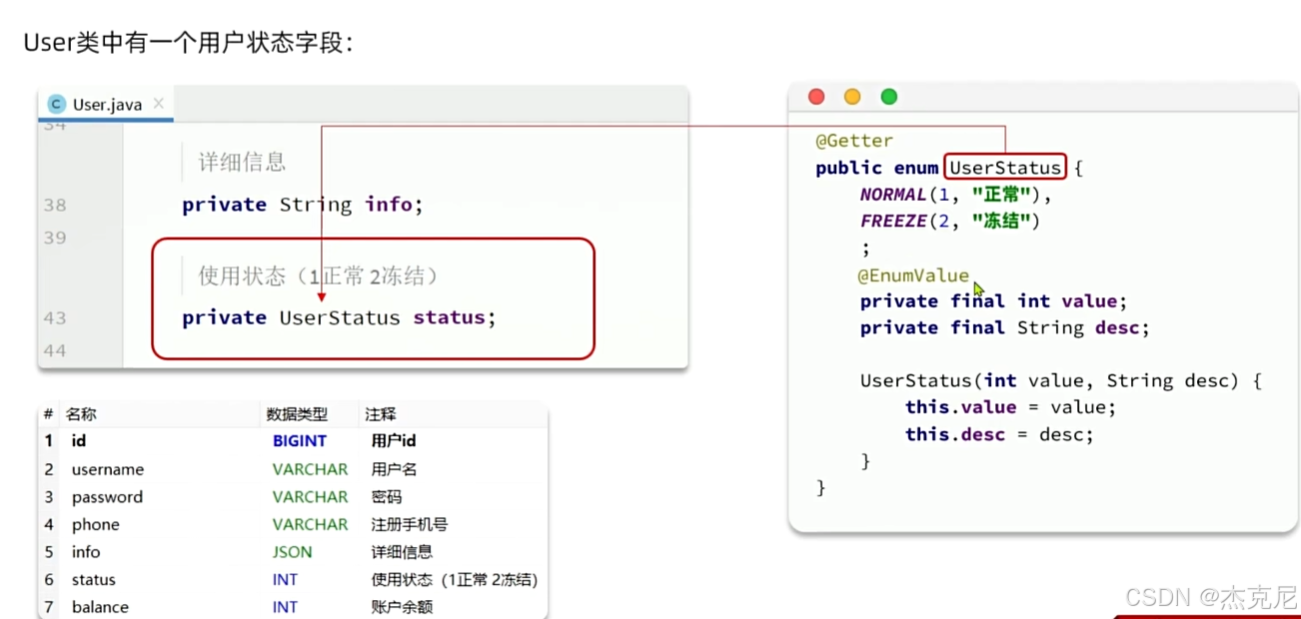
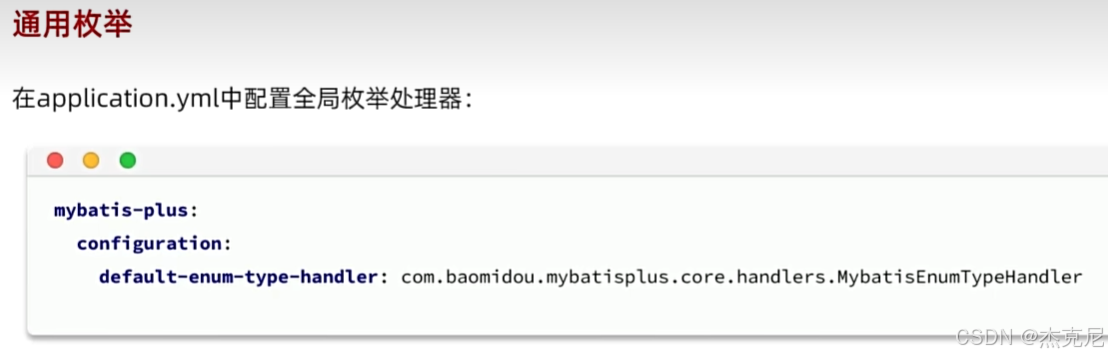
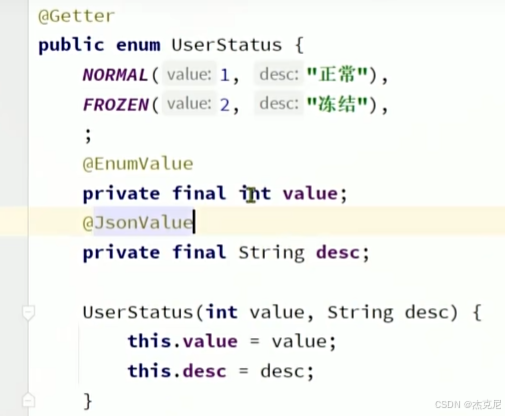
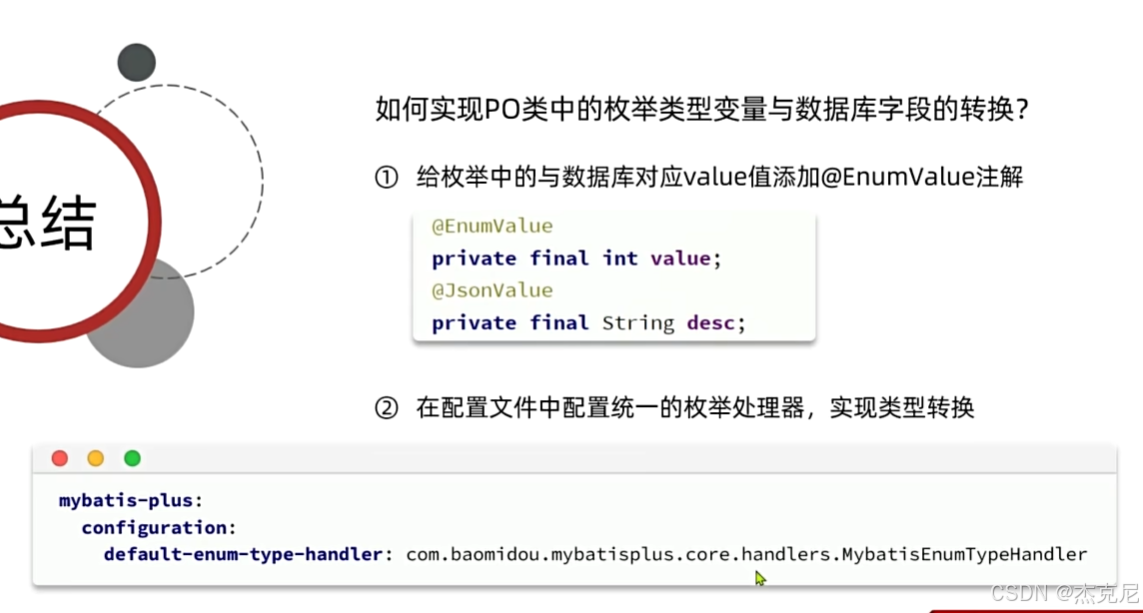
问题:
枚举类中的变量怎么与数据库中的变量进行对应?
可以使用@EnymValue
@JsonValue是干嘛的?
标记的变量当作枚举类返回值
18JSON处理器
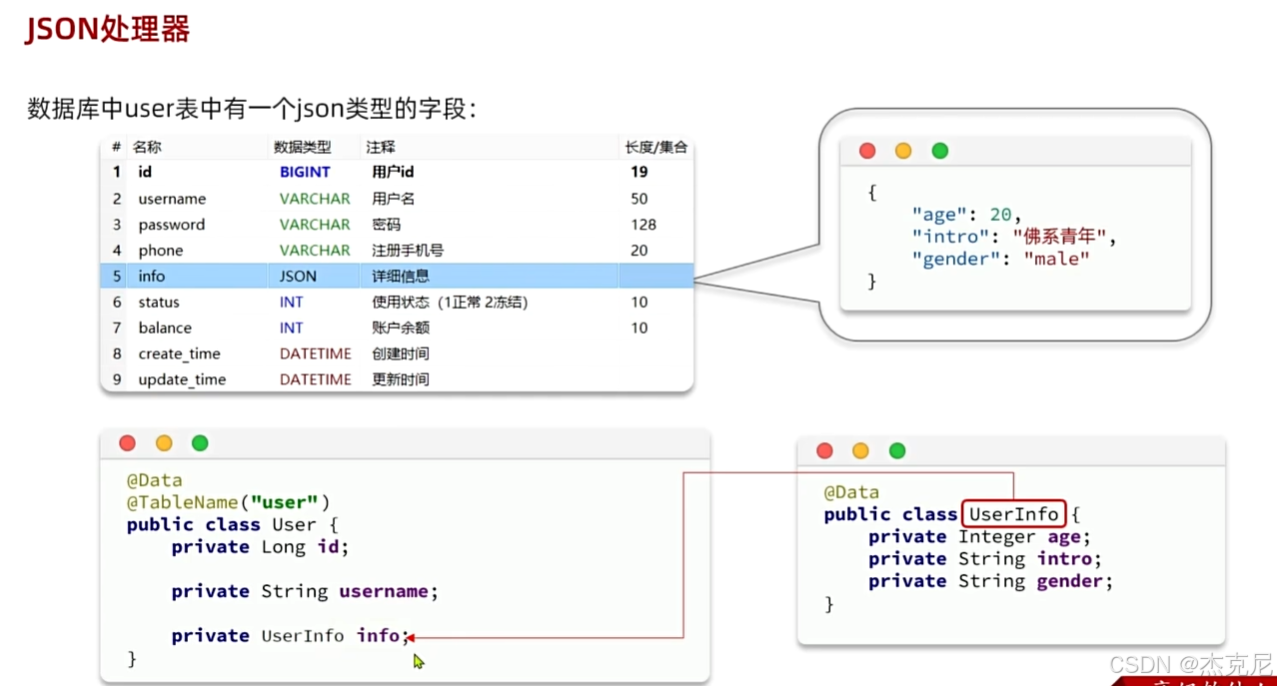
问题:

这个里面那个auto是干什么的?
在 MyBatis-Plus 中,@TableName 注解的 autoResultMap 属性主要用于支持复杂类型的结果映射,特别是当实体类中包含自定义类型(如枚举、日期格式化、JSON 类型等)时,需要开启该属性来让 MyBatis-Plus 自动生成对应的结果映射(ResultMap),从而确保这些复杂类型能够被正确地序列化和反序列化。
例如,如果你在实体类中使用了枚举类型字段,并且配置了自定义的类型处理器(TypeHandler),那么需要将 autoResultMap 设置为 true,MyBatis-Plus 才会自动生成包含该类型处理器的 ResultMap,保证数据库与实体类之间的类型转换正常进行。
简单来说,autoResultMap = true 是为了让 MyBatis-Plus 自动处理实体类中复杂类型的映射关系,避免手动编写 ResultMap 配置,提升开发效率。

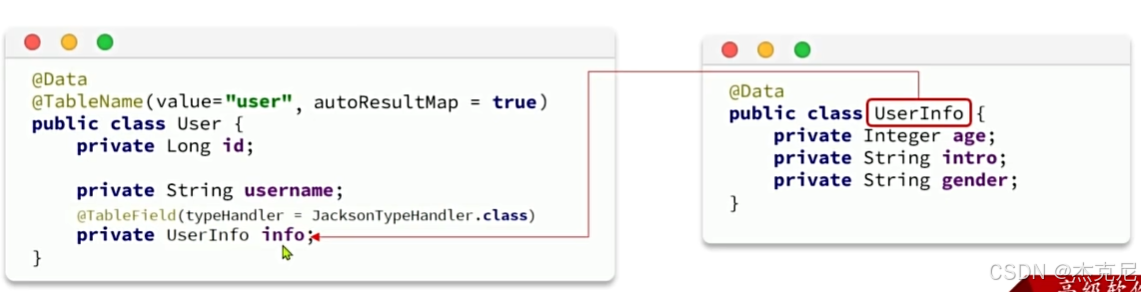
这个注解是干甚的?
这段代码中的 @TableField 注解是 MyBatis-Plus 框架 用于处理实体类字段与数据库字段映射的关键注解,结合 typeHandler = JacksonTypeHandler.class 有特定作用:
它的核心功能是指定该字段的类型处理器,用于在数据库存储和实体类对象之间进行JSON 类型的序列化与反序列化。
具体来说:
- 当将实体类持久化到数据库时,
JacksonTypeHandler会把UserInfo类型的info字段序列化为 JSON 字符串,存储到数据库的对应字段中。 - 当从数据库查询数据并映射为实体类时,它会把数据库中存储的 JSON 字符串反序列化为
UserInfo类型的对象,赋值给info字段。
这样就实现了实体类中复杂对象(UserInfo)与数据库中 JSON 格式字段的自动转换,无需手动处理序列化和反序列化逻辑,提升了开发效率。
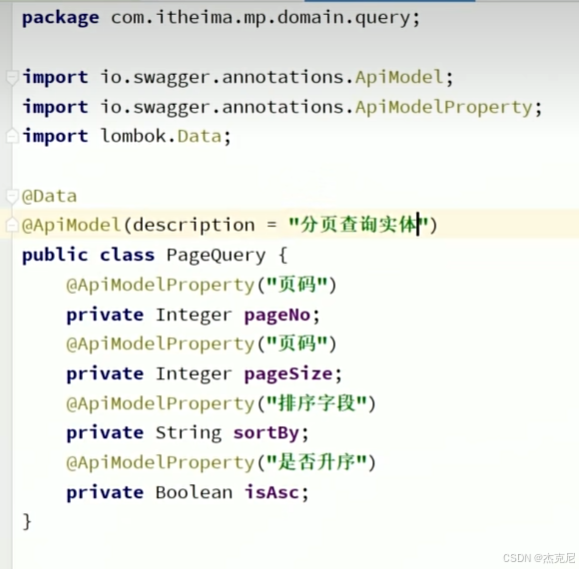
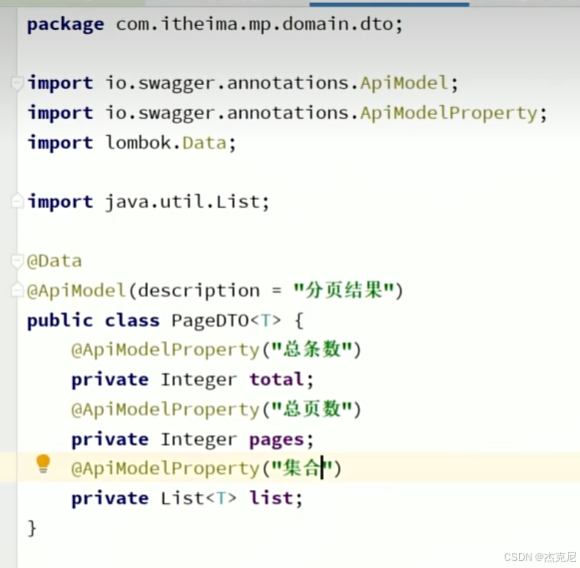
19分页插件的基本用法



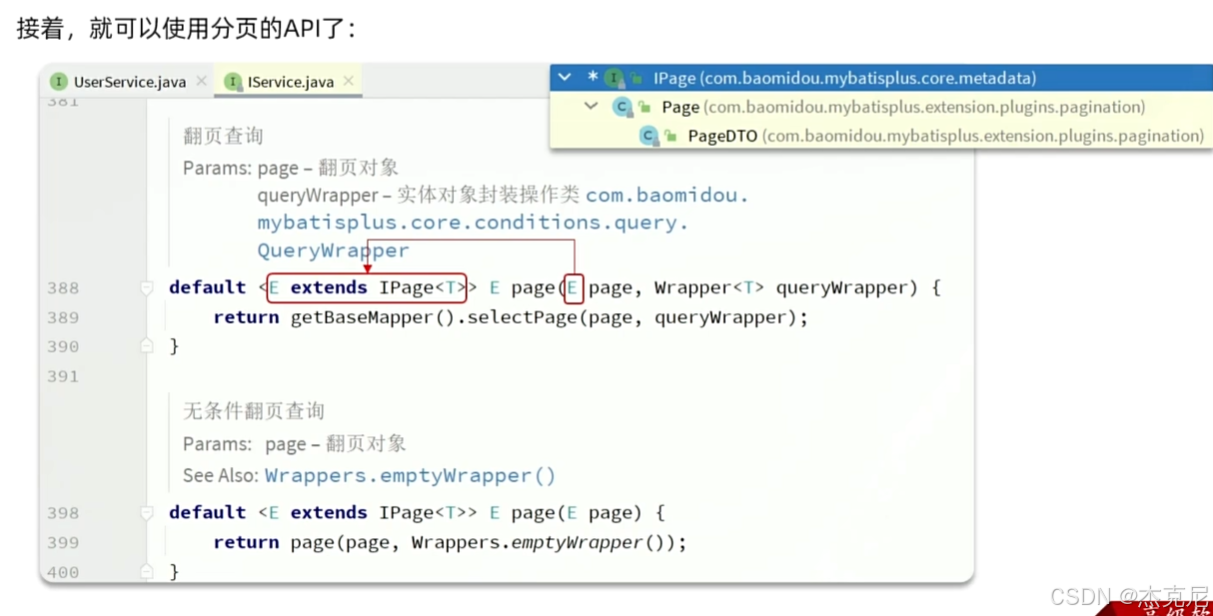
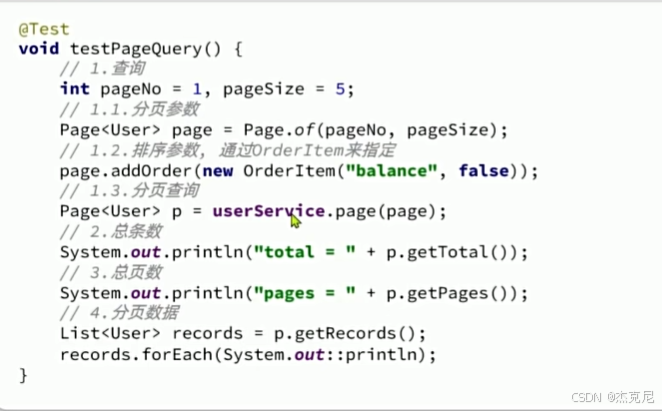
20通用分页插件


总数据条数,总页数,当前页数据



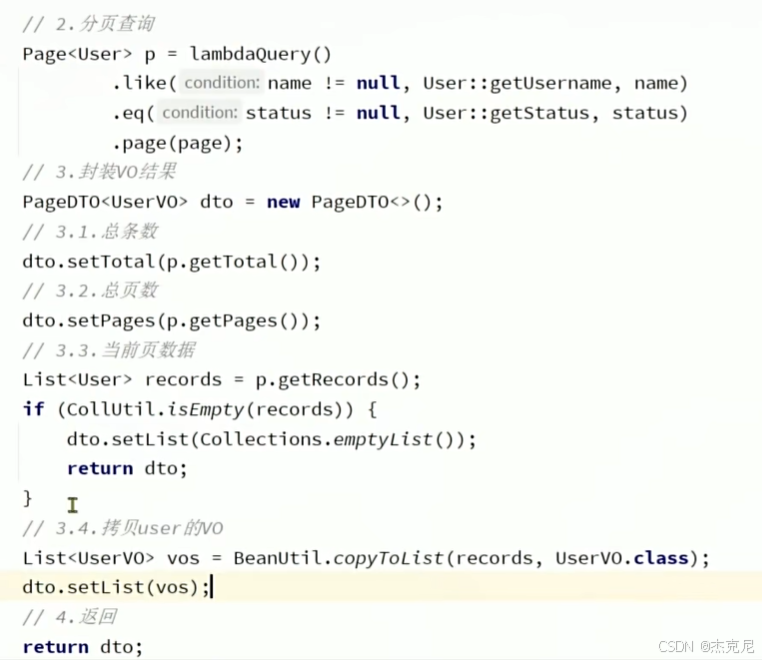
问题:

这个注解是干什么的?

21通用分页实体与MP转换

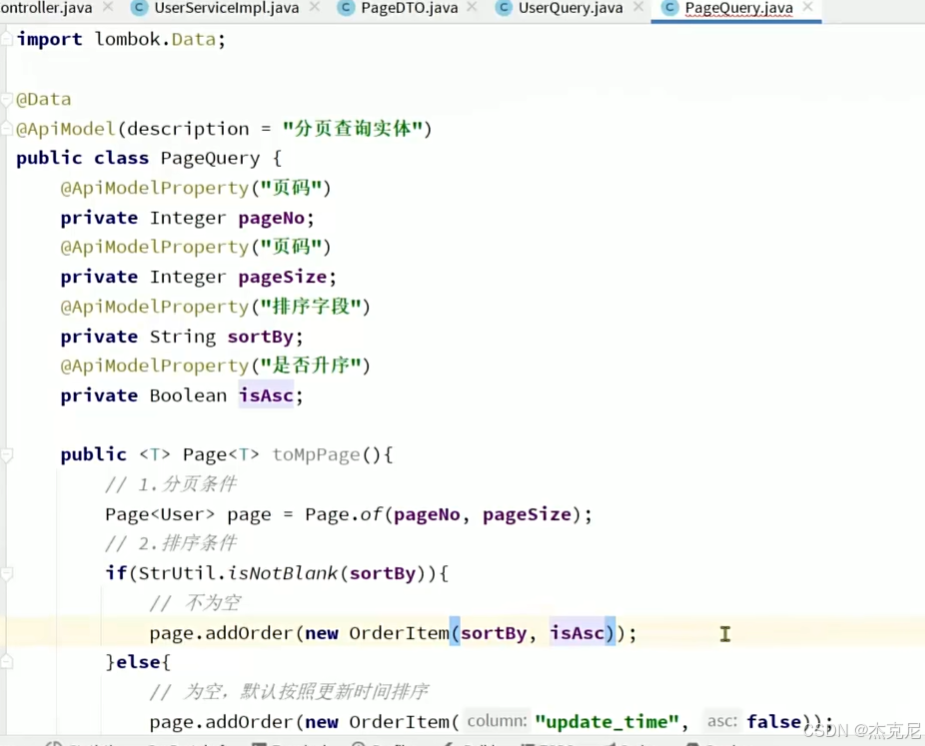
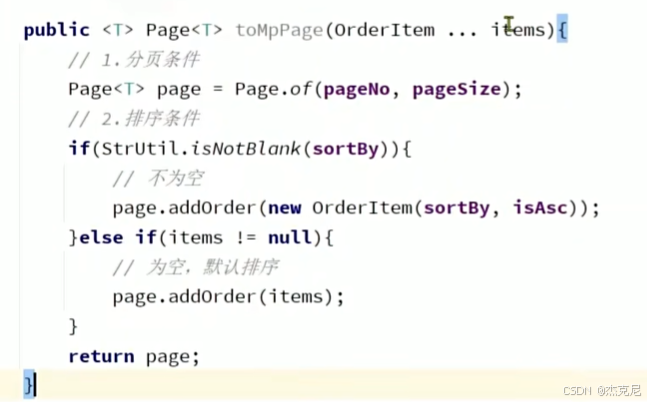
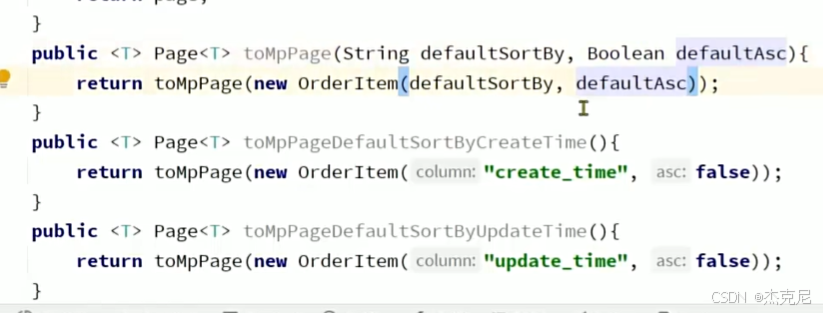
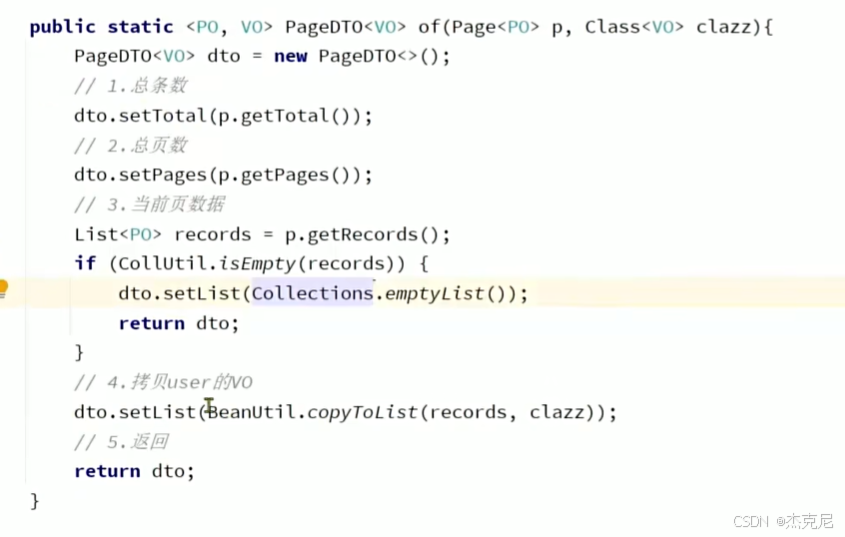
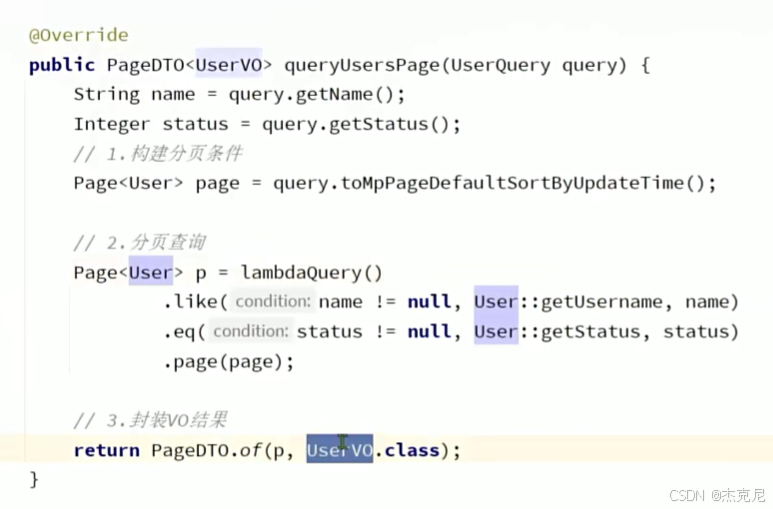
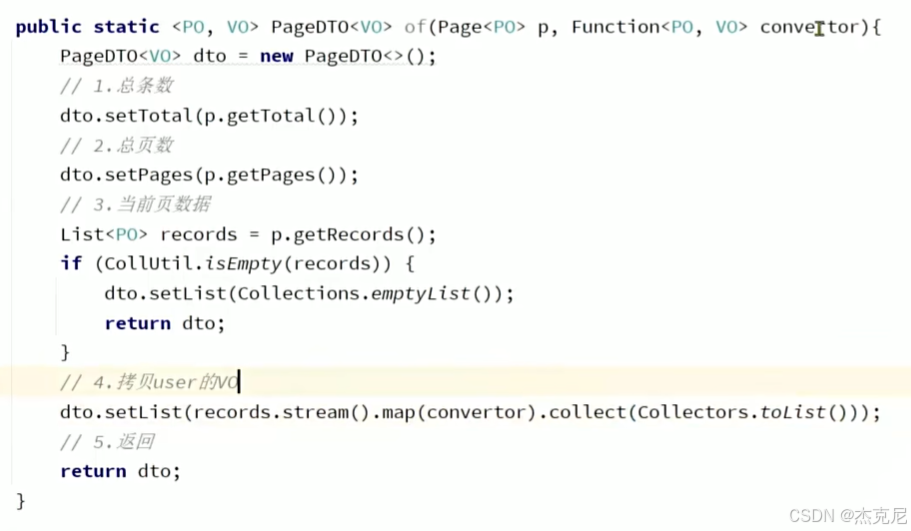
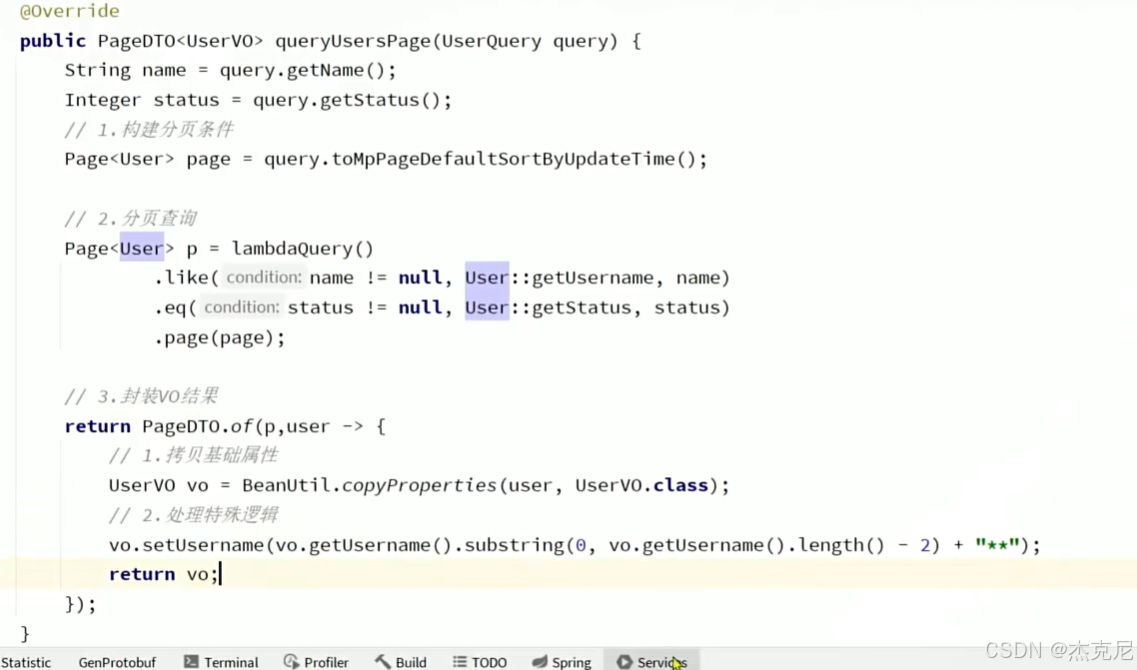
问题:
泛型没有字节码:即VO.class是错误的
解释第一个<po,vo> 和Function?
这段代码是一个通用的分页数据转换工具方法,用于将 MyBatis-Plus 的 Page<PO> 对象(持久层实体分页)转换为自定义的 PageDTO<VO> 对象(前端视图对象分页)。下面详细解释 <PO, VO> 和 Function 的作用:
1. 泛型 <PO, VO>
PO(Persistent Object):表示持久层实体类(如数据库表对应的 User 实体),是从数据库查询后直接得到的对象。
VO(View Object):表示视图对象(如前端需要的 UserVO),是对 PO 进行字段裁剪、格式转换后的数据对象,用于前端展示或接口返回。
泛型 <PO, VO> 让这个方法具备通用性,可以处理任意 “持久层实体 → 视图对象” 的分页转换场景,无需为每个业务写重复代码。
2. Function<PO, VO> convertor
Function 是 Java 8 引入的函数式接口,表示一个 “输入一个参数,返回一个结果” 的函数。在这段代码中:
Function<PO, VO> 定义了一个 “将 PO 类型转换为 VO 类型” 的函数。
convertor 是这个函数的实例,调用方需要传入具体的转换逻辑(比如 UserPO -> UserVO 的字段映射规则)。如下:
dto.setList(records.stream().map(convertor).collect(Collectors.toList()));22总结
深入浅出 MyBatis-Plus:从入门到实战的全方位指南
前言:为何选择 MyBatis-Plus?
在 Java 持久层框架的江湖中,MyBatis 以其灵活的 SQL 控制和贴近原生 JDBC 的特性占据一席之地,但原生 MyBatis 的 XML 映射文件、手动 SQL 拼接等操作也让开发者不胜其烦。MyBatis-Plus(简称 MP)的出现,如同为 MyBatis 装上了 “涡轮增压”,它在 MyBatis 基础上做了无侵入式增强,提供了代码生成器、ActiveRecord 模式、Lambda 查询、分页插件等一系列实用功能,让单表 CRUD 的开发效率提升 80% 以上,同时又保留了 MyBatis 的 SQL 灵活性。
本文将以 “体系化 + 实战化” 的风格,带你从 MyBatis-Plus 的基础概念入手,逐步深入核心功能、高级特性,最终掌握其在复杂业务场景中的应用,让你彻底摆脱 “重复 CRUD” 的机械劳动,把精力聚焦在业务逻辑本身。
一、课程导学:MyBatis-Plus 学习路径规划
学习任何技术都需要清晰的路径,MyBatis-Plus 也不例外。对于零基础的开发者,建议按照 “概念认知→入门案例→核心功能→高级特性→实战整合” 的顺序推进;对于有 MyBatis 基础的开发者,可以快速跳过基础概念,直接切入 MP 的增强特性部分。
1. 前置知识要求
掌握 Java 基础语法(面向对象、集合、注解等)
了解 MySQL 等关系型数据库的基本操作(增删改查、索引、事务)
熟悉 Spring Boot 框架的基本使用(依赖管理、配置、Bean 装配)
对 MyBatis 有初步认知(可选,MP 可零基础入门)
2. 学习目标拆解
初级目标:能独立完成单表的 CRUD 操作,熟练使用 MP 的代码生成器、分页插件
中级目标:掌握 Lambda 查询、条件构造器、自定义 SQL 的整合,能处理多表关联查询
高级目标:理解 MP 的扩展机制(自定义 TypeHandler、插件开发),能基于 MP 封装业务通用组件
二、MyBatis-Plus 介绍:从 “是什么” 到 “为什么”
1. MyBatis-Plus 的定义与定位
MyBatis-Plus 是一个MyBatis 的增强工具,它的设计理念是 “只做增强,不做改变”。这意味着它不会修改 MyBatis 的核心模块,而是通过封装、扩展的方式,为开发者提供更便捷的 API 和更丰富的功能。它的核心价值在于简化开发,让开发者从 “写重复的 CRUD SQL” 中解放出来,同时又不丢失 MyBatis 的灵活性。
2. MyBatis-Plus 的核心特性
无侵入式设计:不修改 MyBatis 原有逻辑,兼容所有 MyBatis 原生特性
强大的 CRUD 操作:内置通用 Mapper、Service,支持单表操作的一站式解决
Lambda 表达式查询:彻底摆脱字符串拼接 SQL 的痛苦,类型安全且语义清晰
自动代码生成:支持 Entity、Mapper、Service、Controller 的一键生成
分页插件:内置分页实现,支持多种数据库方言,使用简单
性能分析插件:可快速定位 SQL 性能问题,支持 SQL 执行时长监控
全局拦截插件:支持自定义 SQL 拦截、改写,实现数据权限控制等业务需求
3. MyBatis-Plus vs 原生 MyBatis vs JPA
特性 MyBatis-Plus 原生 MyBatis JPA(Hibernate)
学习成本 低(MyBatis 基础上扩展) 中(需手动维护 SQL、映射) 高(ORM 概念多)
CRUD 效率 极高(内置通用方法) 低(需手动写 SQL/XML) 中(依赖反射、注解)
SQL 灵活性 高(支持原生 SQL、自定义 SQL) 高(完全手动控制) 低(复杂 SQL 需 NativeQuery)
性能 优(MyBatis 基础上无额外开销) 优 中(ORM 映射有性能损耗)
适用场景 单表 CRUD 多、需兼顾 SQL 灵活性 复杂多表关联、高度定制 SQL 简单单表、快速开发原型
三、入门案例:Hello MyBatis-Plus
理论再多不如动手实践,我们通过一个 “用户管理” 的入门案例,快速体验 MyBatis-Plus 的开发流程。
1. 环境准备
开发工具:IntelliJ IDEA 或 Eclipse
技术栈:Spring Boot 2.7.x + MyBatis-Plus 3.5.x + MySQL 8.0 + Lombok
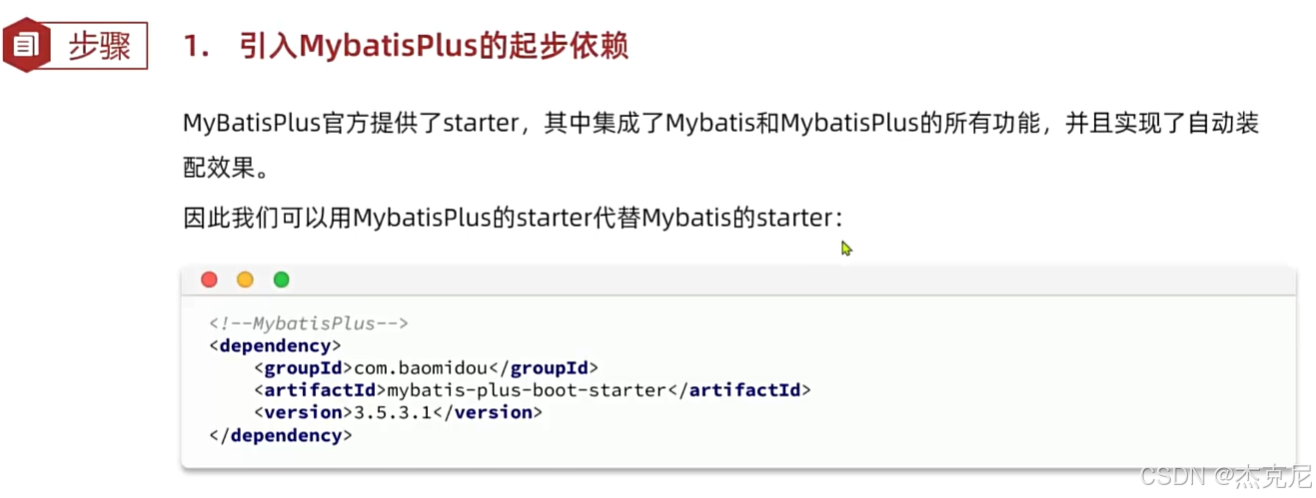
依赖引入(Maven):
xml
<dependencies>
<!-- Spring Boot 核心依赖 -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<!-- MyBatis-Plus 依赖 -->
<dependency>
<groupId>com.baomidou</groupId>
<artifactId>mybatis-plus-boot-starter</artifactId>
<version>3.5.3.2</version>
</dependency>
<!-- MySQL 驱动 -->
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<scope>runtime</scope>
</dependency>
<!-- Lombok 简化实体类 -->
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<optional>true</optional>
</dependency>
<!-- 测试依赖 -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
</dependencies>
2. 数据库表设计
创建user表,包含用户基本信息:
sql
CREATE TABLE `user` (
`id` bigint(20) NOT NULL AUTO_INCREMENT COMMENT '主键ID',
`name` varchar(30) DEFAULT NULL COMMENT '姓名',
`age` int(11) DEFAULT NULL COMMENT '年龄',
`email` varchar(50) DEFAULT NULL COMMENT '邮箱',
`create_time` datetime DEFAULT NULL COMMENT '创建时间',
`update_time` datetime DEFAULT NULL COMMENT '更新时间',
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8mb4;
3. 实体类(Entity)创建
使用 Lombok 和 MP 注解简化实体类编写:
java
运行
import com.baomidou.mybatisplus.annotation.IdType;
import com.baomidou.mybatisplus.annotation.TableId;
import com.baomidou.mybatisplus.annotation.TableName;
import lombok.Data;
import java.time.LocalDateTime;
@Data
@TableName("user") // 映射数据库表名
public class User {
@TableId(type = IdType.AUTO) // 主键策略:自增
private Long id;
private String name;
private Integer age;
private String email;
private LocalDateTime createTime;
private LocalDateTime updateTime;
}
4. Mapper 接口定义
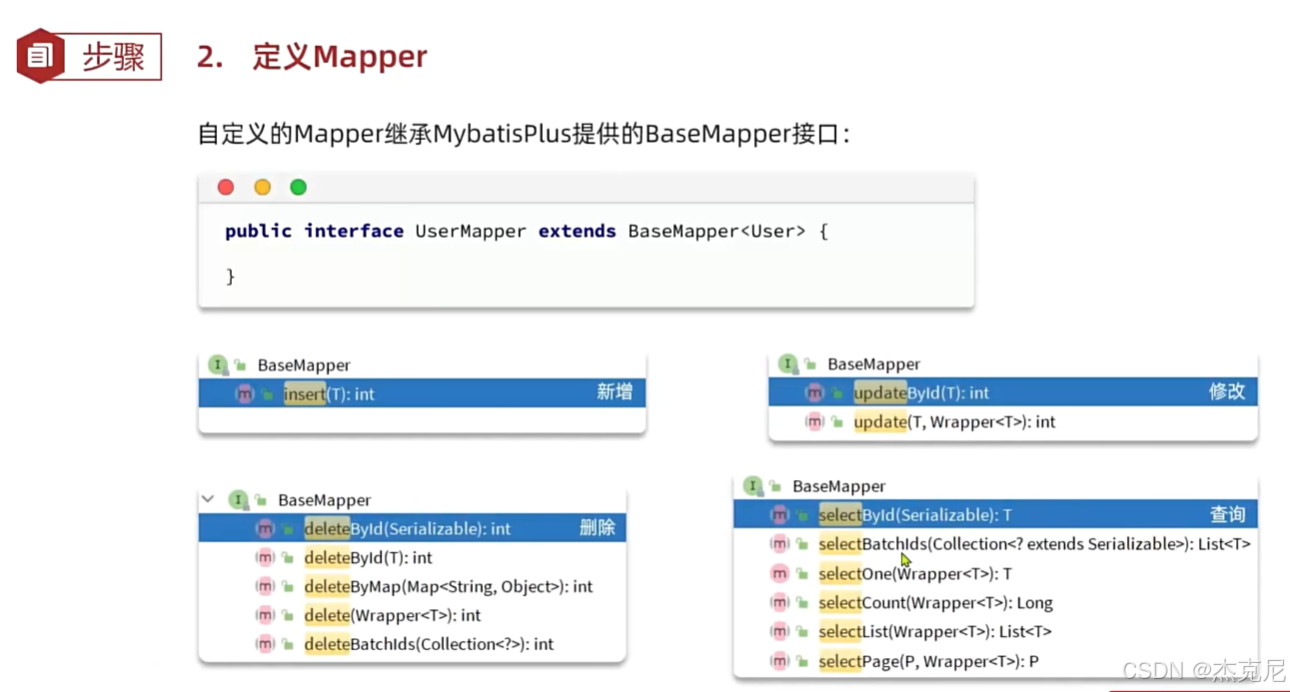
继承 MP 的BaseMapper,即可拥有通用 CRUD 方法:
java
运行
import com.baomidou.mybatisplus.core.mapper.BaseMapper;
import com.example.demo.entity.User;
import org.apache.ibatis.annotations.Mapper;
@Mapper
public interface UserMapper extends BaseMapper<User> {
// 无需编写任何方法,BaseMapper已提供17+通用CRUD方法
}
5. 测试类验证
编写测试类,体验 MP 的 CRUD 便捷性:
java
运行
import com.baomidou.mybatisplus.core.conditions.query.QueryWrapper;
import com.example.demo.entity.User;
import com.example.demo.mapper.UserMapper;
import org.junit.jupiter.api.Test;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import java.util.List;
@SpringBootTest
class MybatisPlusDemoApplicationTests {
@Autowired
private UserMapper userMapper;
// 测试插入
@Test
void testInsert() {
User user = new User();
user.setName("张三");
user.setAge(20);
user.setEmail("zhangsan@example.com");
userMapper.insert(user);
System.out.println("插入成功,ID:" + user.getId());
}
// 测试查询所有
@Test
void testSelectList() {
List<User> userList = userMapper.selectList(null);
userList.forEach(System.out::println);
}
// 测试条件查询
@Test
void testSelectByCondition() {
QueryWrapper<User> queryWrapper = new QueryWrapper<>();
queryWrapper.eq("age", 20) // 年龄等于20
.like("name", "张"); // 姓名包含“张”
List<User> userList = userMapper.selectList(queryWrapper);
userList.forEach(System.out::println);
}
}
运行测试方法后,你会发现无需编写任何 XML 或 SQL 语句,就能完成用户的增删改查操作,这就是 MyBatis-Plus 的魅力所在。
四、常见注解:MyBatis-Plus 的 “语法糖”
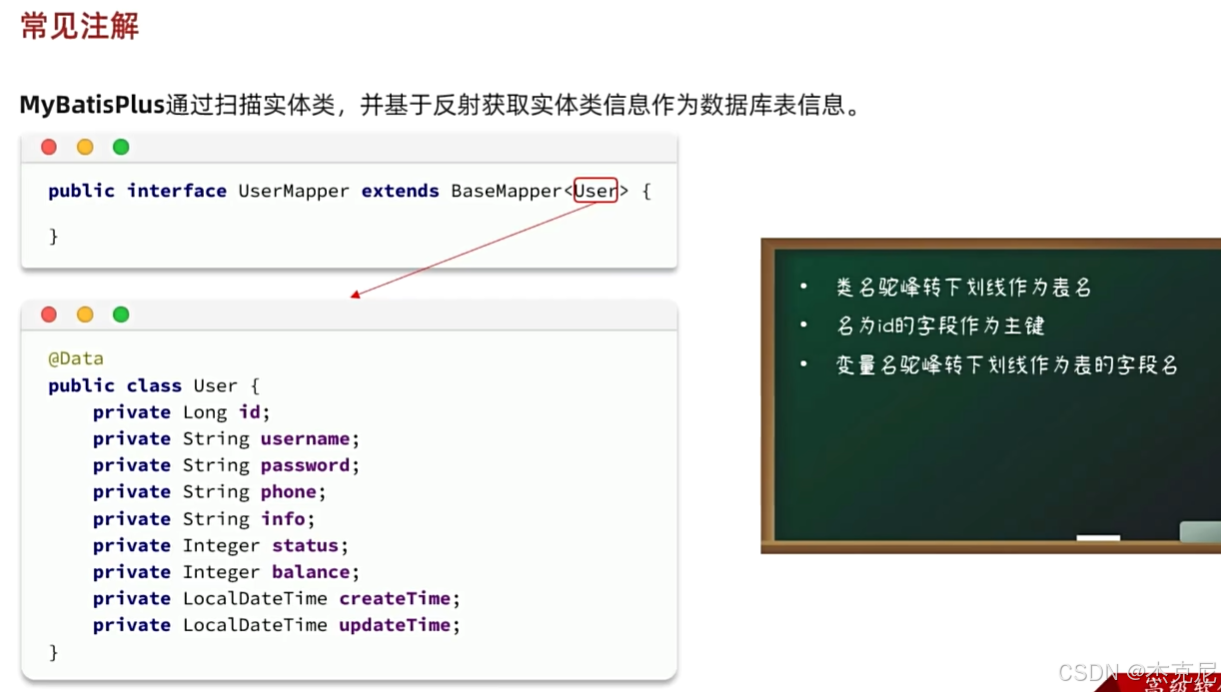
MyBatis-Plus 提供了一系列注解,用于解决实体类与数据库表、字段之间的映射问题,理解这些注解是用好 MP 的基础。
1. @TableName:表名映射
当实体类名与数据库表名不一致时,使用@TableName指定映射关系。
java
运行
@TableName("t_user") // 数据库表名为t_user,实体类名为User
public class User {
// ...
}
进阶用法:@TableName的autoResultMap属性(如@TableName(value = "user", autoResultMap = true)),用于支持复杂类型的结果映射(如 JSON 字段、枚举类型),开启后 MP 会自动生成包含类型处理器的 ResultMap。
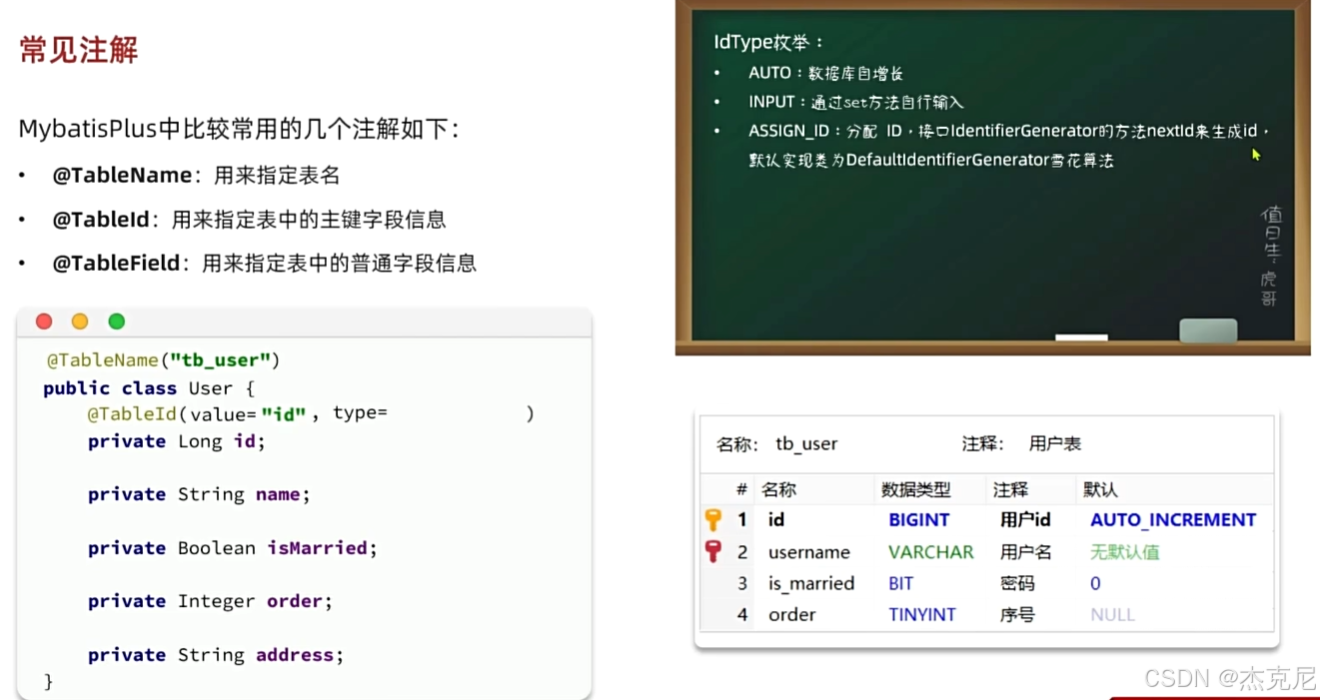
2. @TableId:主键映射
用于指定实体类的主键字段,支持多种主键策略(自增、UUID、雪花算法等)。
java
运行
public class User {
@TableId(type = IdType.AUTO) // 主键自增
private Long id;
@TableId(type = IdType.ASSIGN_ID) // 雪花算法生成ID(分布式场景推荐)
private Long id;
@TableId(type = IdType.ASSIGN_UUID) // 生成UUID字符串
private String id;
}
常用主键策略说明:
IdType.AUTO:数据库自增(需数据库表设置自增)
IdType.ASSIGN_ID:MP 自动生成雪花算法 ID(Long 型,分布式唯一)
IdType.ASSIGN_UUID:生成 UUID 字符串(32 位,无中划线)
3. @TableField:字段映射
解决实体类字段与数据库字段名不一致、字段忽略、类型处理器指定等问题。
(1)字段名映射
java
运行
public class User {
@TableField("user_name") // 数据库字段为user_name,实体类字段为name
private String name;
}
(2)忽略字段
java
运行
public class User {
@TableField(exist = false) // 该字段在数据库表中不存在,查询时忽略
private String extraInfo;
}
(3)类型处理器指定
当字段是 JSON、枚举等特殊类型时,需指定 TypeHandler:
java
运行
public class User {
@TableField(typeHandler = JacksonTypeHandler.class) // 用Jackson处理JSON序列化/反序列化
private UserInfo info; // UserInfo是自定义的复杂对象,存储为JSON字符串
}
JacksonTypeHandler是 MP 提供的 JSON 类型处理器,也可自定义 TypeHandler 来处理特殊类型转换。
4. @Version:乐观锁控制
用于实现乐观锁,解决并发更新冲突问题。
java
运行
public class User {
@Version
private Integer version; // 版本号,每次更新自动+1
}
使用时需配置乐观锁插件:
java
运行
@Configuration
public class MybatisPlusConfig {
@Bean
public MybatisPlusInterceptor mybatisPlusInterceptor() {
MybatisPlusInterceptor interceptor = new MybatisPlusInterceptor();
interceptor.addInnerInterceptor(new OptimisticLockerInnerInterceptor()); // 乐观锁插件
return interceptor;
}
}
5. @EnumValue:枚举映射
将枚举类与数据库字段映射,支持 “枚举值” 或 “枚举名” 存储。
java
运行
public enum GenderEnum {
MALE(0, "男"),
FEMALE(1, "女");
@EnumValue // 标记数据库存储的枚举值
private final Integer code;
private final String desc;
GenderEnum(Integer code, String desc) {
this.code = code;
this.desc = desc;
}
}
// 实体类中使用
public class User {
private GenderEnum gender;
}
搭配IEnum接口或配置枚举扫描,可实现枚举与数据库的自动映射。
五、常用配置:打造个性化 MyBatis-Plus
MyBatis-Plus 的配置灵活且强大,通过配置文件或 Java 配置类,可定制化 SQL 执行、日志、插件等行为。
1. 全局配置(application.yml)
yaml
mybatis-plus:
# 实体类扫描包,用于自动识别实体类
type-aliases-package: com.example.demo.entity
# XML映射文件位置(若使用自定义SQL)
mapper-locations: classpath*:/mapper/**/*.xml
configuration:
# 日志输出(开发环境建议开启,方便调试)
log-impl: org.apache.ibatis.logging.stdout.StdOutImpl
# 下划线转驼峰(默认开启,如数据库字段user_name映射为userName)
map-underscore-to-camel-case: true
# 开启二级缓存(默认关闭,需谨慎使用)
cache-enabled: false
# 全局主键策略(优先级低于实体类@TableId)
global-config:
db-config:
id-type: auto # 全局主键策略:自增
logic-delete-field: deleted # 逻辑删除字段名(实体类需有对应字段)
logic-delete-value: 1 # 逻辑删除值(如1代表已删除)
logic-not-delete-value: 0 # 逻辑未删除值(如0代表未删除)
2. 插件配置(Java Config)
通过配置类注册 MP 的插件,实现分页、乐观锁、性能分析等功能。
(1)分页插件
java
运行
@Configuration
public class MybatisPlusConfig {
@Bean
public MybatisPlusInterceptor mybatisPlusInterceptor() {
MybatisPlusInterceptor interceptor = new MybatisPlusInterceptor();
// 分页插件,支持多种数据库方言
interceptor.addInnerInterceptor(new PaginationInnerInterceptor(DbType.MYSQL));
return interceptor;
}
}
使用示例:
java
运行
@Test
void testPage() {
Page<User> page = new Page<>(1, 2); // 第1页,每页2条
QueryWrapper<User> queryWrapper = new QueryWrapper<>();
queryWrapper.gt("age", 18); // 年龄大于18
Page<User> userPage = userMapper.selectPage(page, queryWrapper);
System.out.println("总记录数:" + userPage.getTotal());
System.out.println("总页数:" + userPage.getPages());
userPage.getRecords().forEach(System.out::println);
}
(2)性能分析插件
用于开发环境监控 SQL 执行时长,超过阈值则报警。
java
运行
@Bean
public PerformanceInterceptor performanceInterceptor() {
PerformanceInterceptor interceptor = new PerformanceInterceptor();
interceptor.setMaxTime(1000); // SQL执行超时时间(毫秒),超过则抛出异常
interceptor.setFormat(true); // SQL格式化输出
return interceptor;
}
(3)自定义插件
若内置插件无法满足需求,可实现InnerInterceptor接口自定义插件,用于 SQL 拦截、改写等场景(如数据权限控制、SQL 审计)。
3. 自定义 SQL 配置
尽管 MP 提供了强大的通用 CRUD,但仍有需要自定义 SQL 的场景,可通过 XML 或注解方式实现。
(1)XML 方式
在resources/mapper目录下创建UserMapper.xml:
xml
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN" "http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="com.example.demo.mapper.UserMapper">
<!-- 自定义查询:根据年龄区间查询用户 -->
<select id="selectUserByAgeRange" resultType="com.example.demo.entity.User">
SELECT * FROM user WHERE age BETWEEN #{minAge} AND #{maxAge}
</select>
</mapper>
在UserMapper接口中添加方法:
java
运行
List<User> selectUserByAgeRange(@Param("minAge") Integer minAge, @Param("maxAge") Integer maxAge);
(2)注解方式
java
运行
@Mapper
public interface UserMapper extends BaseMapper<User> {
@Select("SELECT * FROM user WHERE age BETWEEN #{minAge} AND #{maxAge}")
List<User> selectUserByAgeRange(@Param("minAge") Integer minAge, @Param("maxAge") Integer maxAge);
}
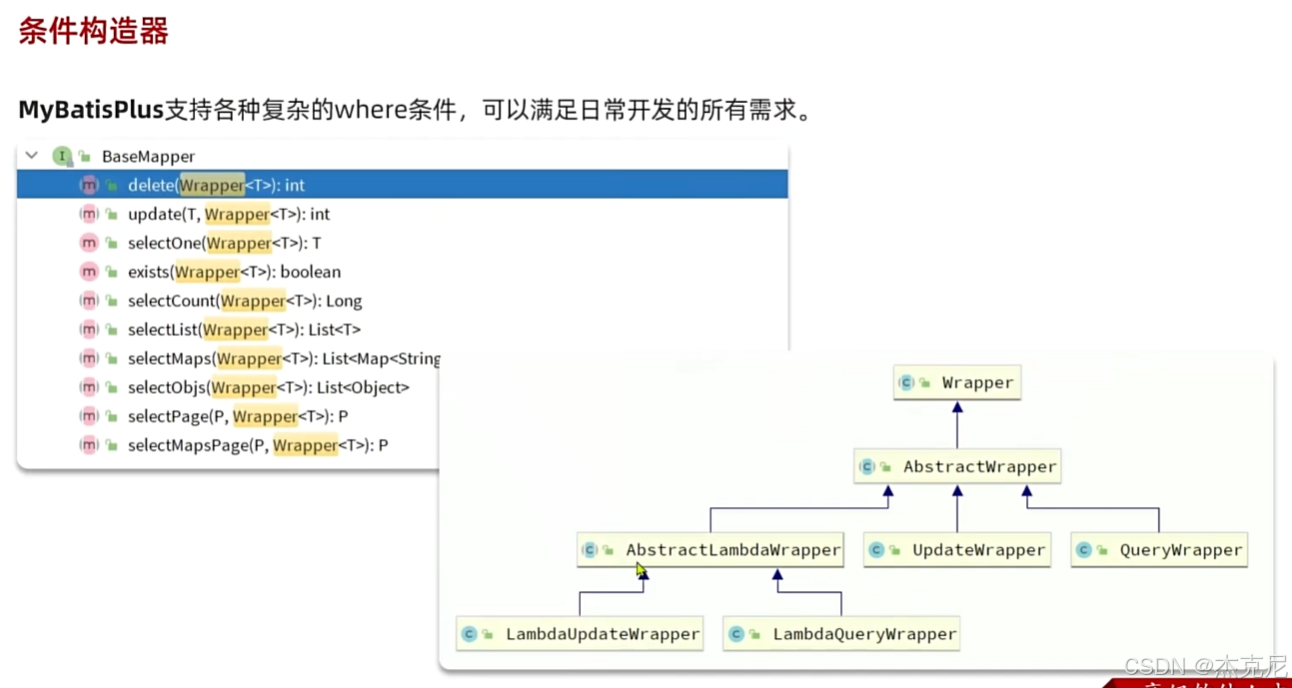
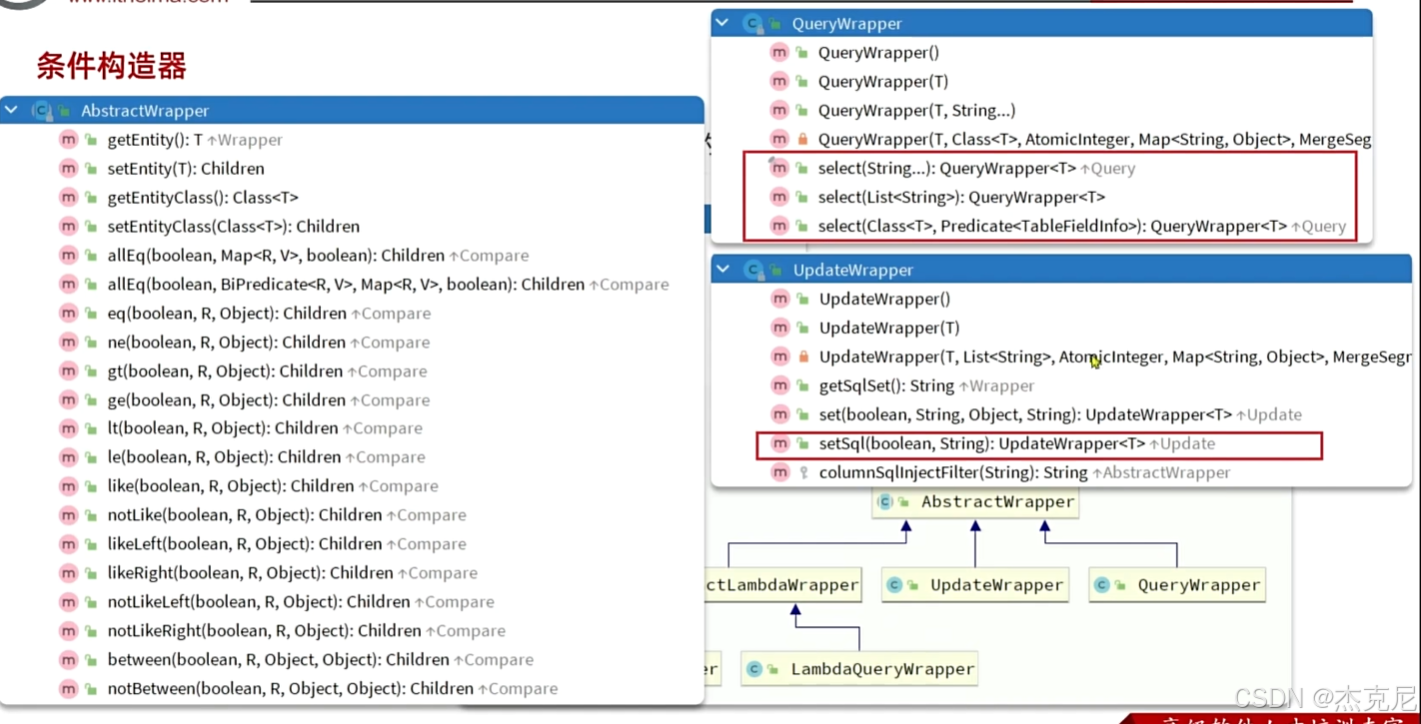
六、核心功能 - 条件构造器:告别 SQL 字符串拼接
MyBatis-Plus 的条件构造器(Wrapper)是其核心竞争力之一,它让复杂条件查询变得简单、类型安全,彻底告别手动拼接 SQL 字符串的时代。
1. 条件构造器体系
MP 的条件构造器主要分为QueryWrapper(通用查询构造器)、UpdateWrapper(通用更新构造器)、LambdaQueryWrapper(Lambda 查询构造器)、LambdaUpdateWrapper(Lambda 更新构造器)四大类。其中,Lambda 形式的构造器是最推荐的使用方式,因为它基于 Lambda 表达式,具备类型安全、自动字段映射的优势。
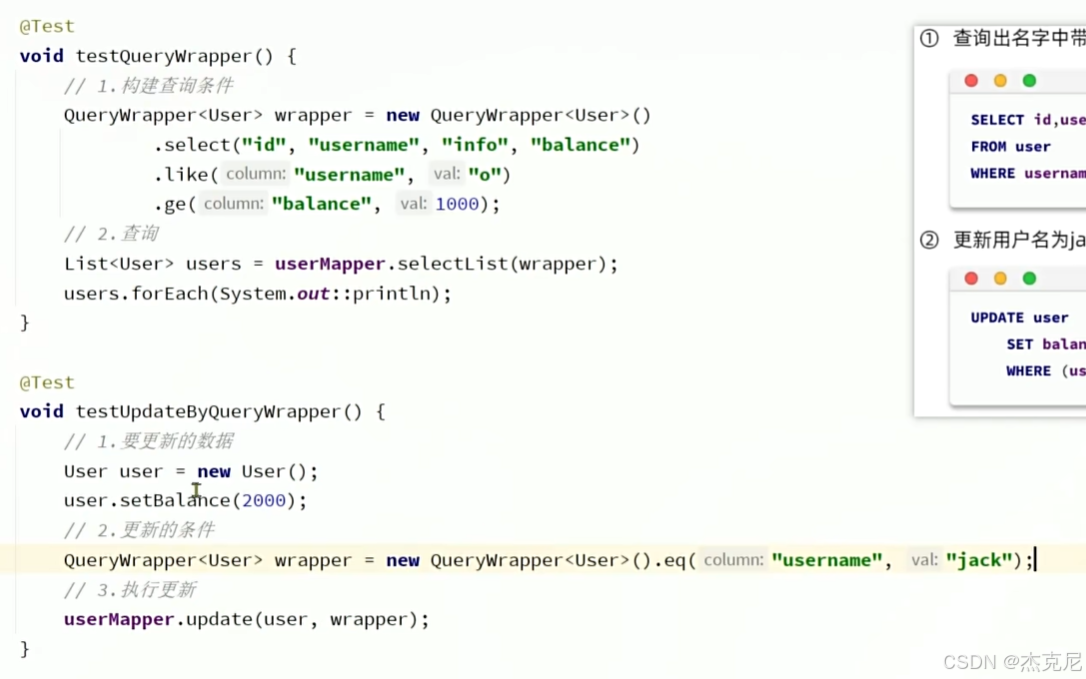
2. QueryWrapper 基础使用
java
运行
// 查询年龄大于20且姓名包含“张”的用户
QueryWrapper<User> queryWrapper = new QueryWrapper<>();
queryWrapper.gt("age", 20)
.like("name", "张");
List<User> userList = userMapper.selectList(queryWrapper);
3. LambdaQueryWrapper 进阶使用(推荐)
java
运行
// Lambda形式,类型安全,无需担心字段名拼写错误
LambdaQueryWrapper<User> lambdaQueryWrapper = new LambdaQueryWrapper<>();
lambdaQueryWrapper.gt(User::getAge, 20) // 年龄>20
.like(User::getName, "张"); // 姓名含“张”
List<User> userList = userMapper.selectList(lambdaQueryWrapper);
4. 常用条件方法详解
方法名 说明 示例
eq 等于 eq("name", "张三")
ne 不等于 ne("age", 20)
gt 大于 gt("age", 18)
ge 大于等于 ge("age", 18)
lt 小于 lt("age", 30)
le 小于等于 le("age", 30)
like 模糊查询(包含) like("name", "张")
likeLeft 左模糊(以... 结尾) likeLeft("name", "三")
likeRight 右模糊(以... 开头) likeRight("name", "张")
in 包含在集合中 in("id", Arrays.asList(1,2,3))
notIn 不包含在集合中 notIn("id", Arrays.asList(4,5))
between 区间范围 between("age", 18, 30)
orderByAsc 升序排序 orderByAsc("age", "id")
orderByDesc 降序排序 orderByDesc("create_time")
last 拼接 SQL 到最后(需注意 SQL 注入) last("LIMIT 1")
5. 复杂条件组合
条件构造器支持嵌套、AND/OR 逻辑组合,满足复杂业务场景。
(1)AND 嵌套
java
运行
LambdaQueryWrapper<User> lambdaQueryWrapper = new LambdaQueryWrapper<>();
lambdaQueryWrapper.gt(User::getAge, 20)
.and(wrapper -> wrapper.like(User::getName, "张")
.or().eq(User::getEmail, "admin@example.com"));
// 等价SQL:age > 20 AND (name LIKE '%张%' OR email = 'admin@example.com')
(2)OR 嵌套
java
运行
LambdaQueryWrapper<User> lambdaQueryWrapper = new LambdaQueryWrapper<>();
lambdaQueryWrapper.or(wrapper -> wrapper.like(User::getName, "张")
.and(w -> w.gt(User::getAge, 20)));
// 等价SQL:(name LIKE '%张%' AND age > 20) OR ...
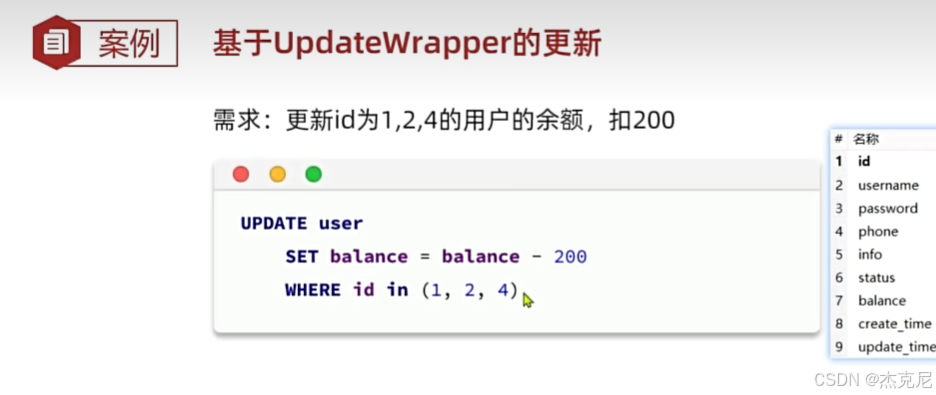
6. UpdateWrapper 使用
用于构造更新条件,支持动态更新字段。
java
运行
UpdateWrapper<User> updateWrapper = new UpdateWrapper<>();
updateWrapper.eq("id", 1) // 更新条件:id=1
.set("age", 22) // 更新字段:age=22
.set("email", "new@example.com"); // 更新字段:email=新值
userMapper.update(null, updateWrapper);
Lambda 形式的LambdaUpdateWrapper使用方式类似,更推荐使用。
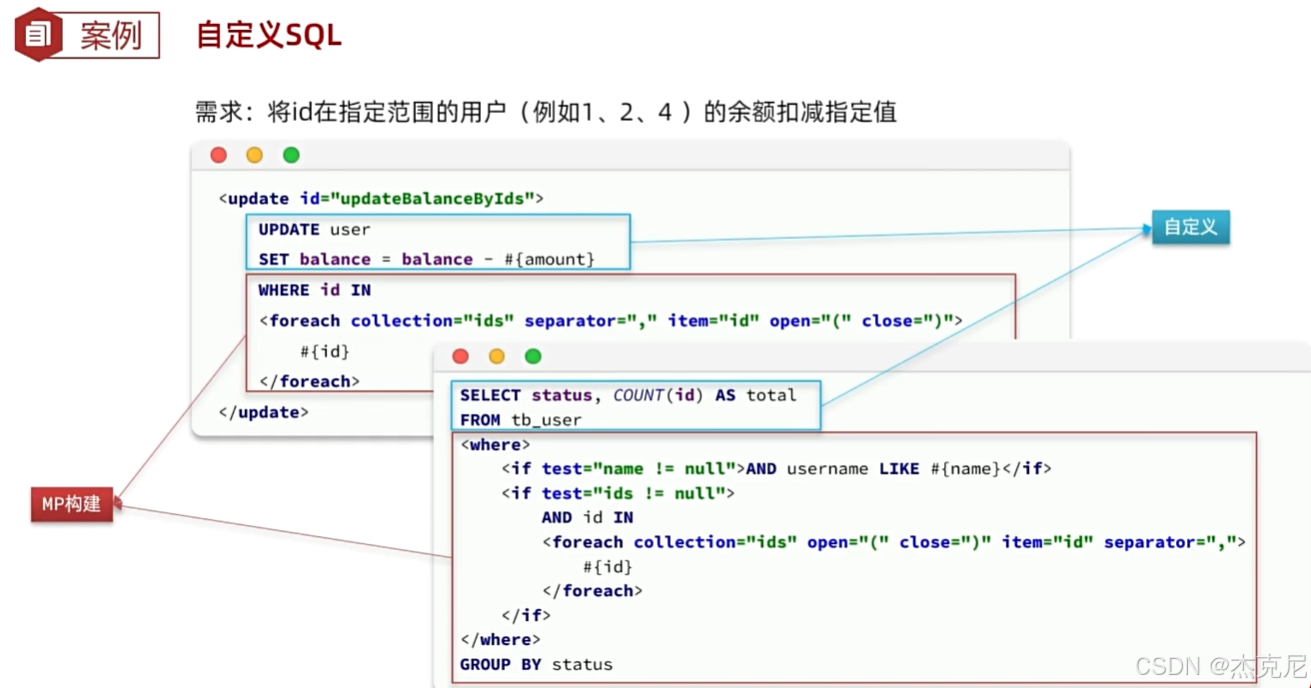
七、自定义 SQL:MP 与原生 MyBatis 的完美融合
尽管 MyBatis-Plus 的通用 CRUD 能满足大部分需求,但在复杂业务场景(如多表关联、复杂聚合查询)下,仍需自定义 SQL。MP 完美兼容原生 MyBatis 的自定义 SQL 方式,让开发者在 “便捷” 与 “灵活” 之间自由切换。
1. 自定义查询 SQL(XML 方式)
假设我们需要查询 “每个年龄段的用户数量”,这是一个分组聚合查询,需自定义 SQL 实现。
(1)创建 XML 映射文件
在resources/mapper目录下创建UserStatMapper.xml:
xml
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN" "http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="com.example.demo.mapper.UserStatMapper">
<select id="selectAgeGroupCount" resultType="java.util.Map">
SELECT age, COUNT(*) as count
FROM user
GROUP BY age
ORDER BY age
</select>
</mapper>
(2)创建 Mapper 接口
java
运行
@Mapper
public interface UserStatMapper {
List<Map<String, Object>> selectAgeGroupCount();
}
(3)测试调用
java
运行
@Autowired
private UserStatMapper userStatMapper;
@Test
void testCustomSql() {
List<Map<String, Object>> result = userStatMapper.selectAgeGroupCount();
result.forEach(System.out::println);
}
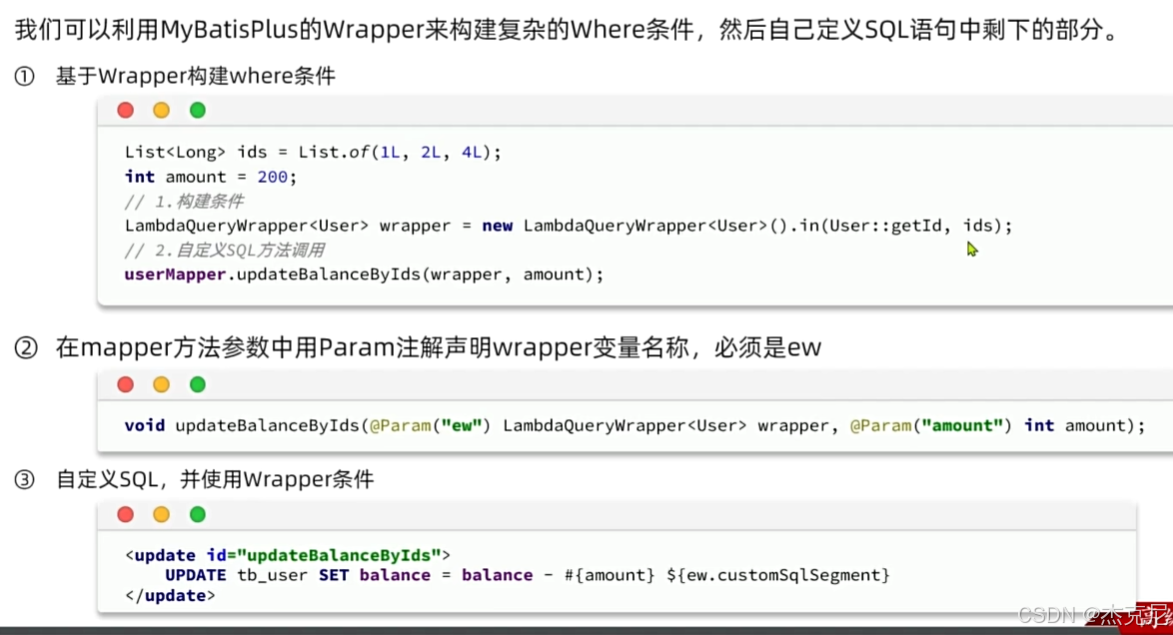
2. 自定义 SQL 与条件构造器结合
MP 允许在自定义 SQL 中使用条件构造器的参数,实现 “通用条件 + 自定义逻辑” 的组合。
(1)XML 中使用条件参数
xml
<select id="selectUserWithCondition" resultType="com.example.demo.entity.User">
SELECT * FROM user
<where>
<if test="ew != null">
${ew.customSqlSegment}
</if>
</where>
</select>
(2)Mapper 接口定义
java
运行
List<User> selectUserWithCondition(@Param("ew") Wrapper<User> wrapper);
(3)调用示例
java
运行
LambdaQueryWrapper<User> lambdaQueryWrapper = new LambdaQueryWrapper<>();
lambdaQueryWrapper.gt(User::getAge, 20);
List<User> userList = userStatMapper.selectUserWithCondition(lambdaQueryWrapper);
这种方式既利用了 MP 条件构造器的便捷性,又保留了自定义 SQL 的灵活性,是复杂查询的利器。
3. 注解方式自定义 SQL
对于简单的自定义 SQL,也可通过@Select、@Insert等注解直接在 Mapper 接口中编写。
java
运行
@Mapper
public interface UserMapper extends BaseMapper<User> {
@Select("SELECT * FROM user WHERE age > #{minAge} AND name LIKE CONCAT('%', #{name}, '%')")
List<User> selectByAgeAndName(@Param("minAge") Integer minAge, @Param("name") String name);
}
八、IService 接口的基本用法:CRUD 的 “一站式” 解决方案
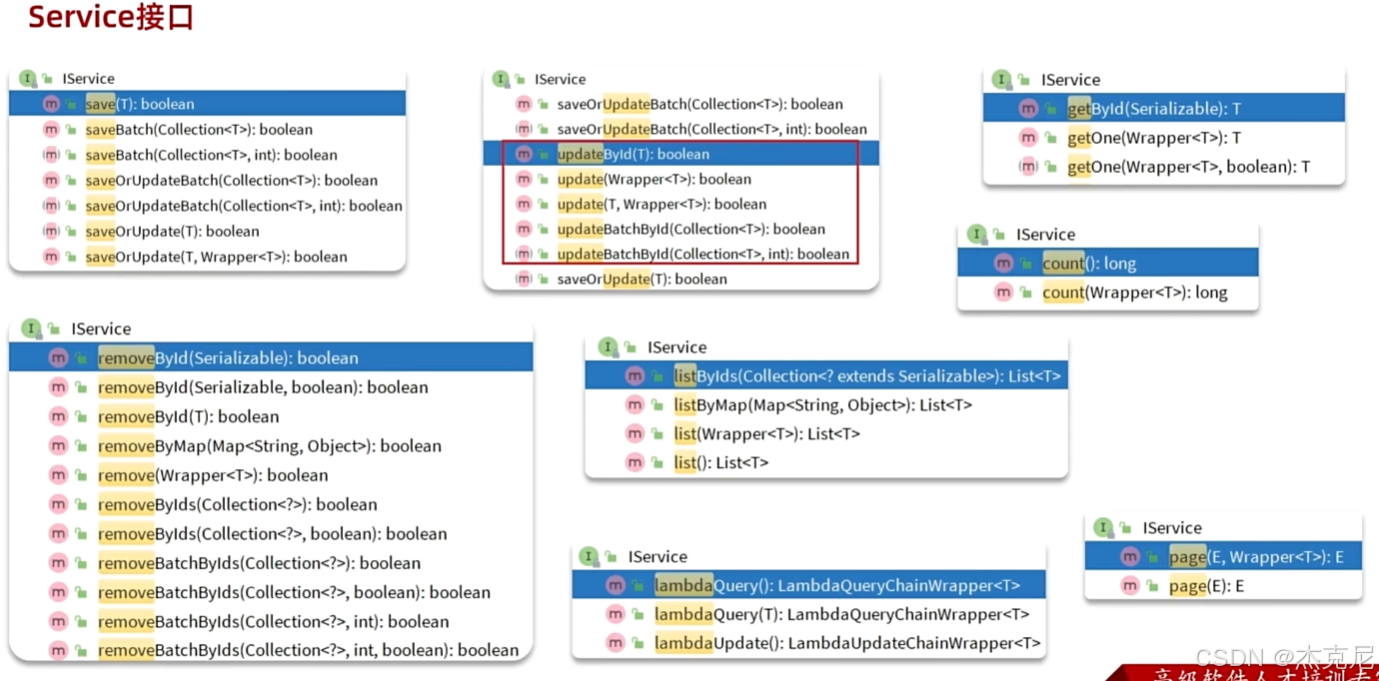
MyBatis-Plus 的IService接口及其实现类ServiceImpl,是对BaseMapper的进一步封装,提供了更丰富的业务层方法,让 Service 层的开发更高效。
1. IService 与 ServiceImpl 介绍
IService:是 MP 定义的服务层接口,包含了批量操作、链式调用、分页查询等高级方法。
ServiceImpl<M, T>:是IService的默认实现类,其中M是 Mapper 类型,T是实体类类型。
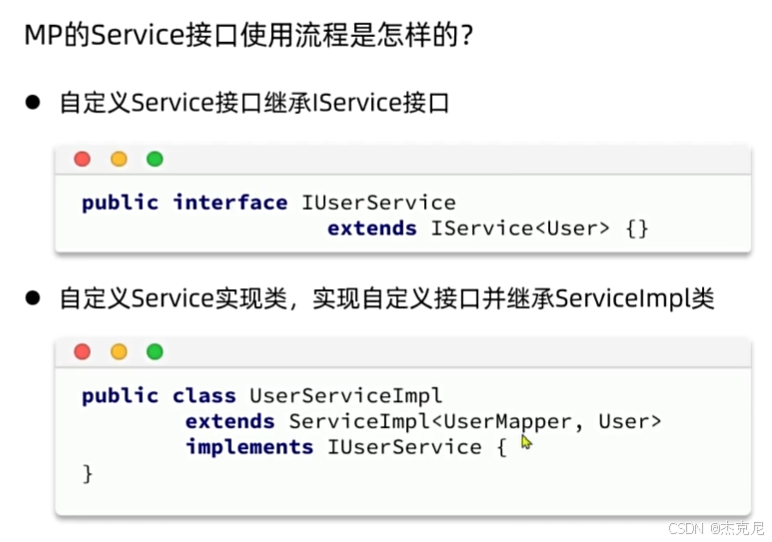
使用时,只需让自定义的 Service 接口继承IService,Service 实现类继承ServiceImpl即可:
java
运行
// Service接口
public interface UserService extends IService<User> {
// 可自定义业务方法
}
// Service实现类
@Service
public class UserServiceImpl extends ServiceImpl<UserMapper, User> implements UserService {
// 可重写或扩展方法
}
2. IService 常用方法
(1)基础 CRUD 方法
java
运行
@Autowired
private UserService userService;
// 插入
User user = new User();
user.setName("李四");
user.setAge(25);
userService.save(user);
// 批量插入
List<User> userList = new ArrayList<>();
// ... 构造userList
userService.saveBatch(userList);
// 根据ID查询
User user = userService.getById(1L);
// 根据条件查询一条记录
User user = userService.getOne(new LambdaQueryWrapper<User>().eq(User::getId, 1L));
// 根据ID更新
User user = new User();
user.setId(1L);
user.setAge(26);
userService.updateById(user);
// 根据ID删除
userService.removeById(1L);
// 批量删除
userService.removeByIds(Arrays.asList(1L, 2L, 3L));
(2)链式查询
java
运行
// 链式查询示例:查询年龄大于20且姓名含“张”的用户列表
List<User> userList = userService.lambdaQuery()
.gt(User::getAge, 20)
.like(User::getName, "张")
.list();
// 链式查询并分页
Page<User> page = new Page<>(1, 5);
Page<User> userPage = userService.lambdaQuery()
.ge(User::getAge, 18)
.page(page);
(3)自定义 Service 方法
在UserService接口中定义自定义方法,在UserServiceImpl中实现:
java
运行
// 接口定义
public interface UserService extends IService<User> {
List<User> findUserByAgeRange(Integer minAge, Integer maxAge);
}
// 实现类
@Service
public class UserServiceImpl extends ServiceImpl<UserMapper, User> implements UserService {
@Override
public List<User> findUserByAgeRange(Integer minAge, Integer maxAge) {
return lambdaQuery()
.between(User::getAge, minAge, maxAge)
.list();
}
}
九、IService 开发基础业务接口:从单表到业务抽象
基于IService,我们可以快速开发符合业务需求的基础接口,将通用逻辑封装复用,提升代码的可维护性和扩展性。
1. 通用查询接口
java
运行
public interface UserService extends IService<User> {
/**
* 根据年龄区间查询用户
* @param minAge 最小年龄
* @param maxAge 最大年龄
* @return 用户列表
*/
List<User> listByAgeRange(Integer minAge, Integer maxAge);
/**
* 分页查询用户(带条件)
* @param pageNum 页码
* @param pageSize 每页条数
* @param keyword 搜索关键词(姓名或邮箱)
* @return 分页结果
*/
Page<User> pageQuery(Integer pageNum, Integer pageSize, String keyword);
}
@Service
public class UserServiceImpl extends ServiceImpl<UserMapper, User> implements UserService {
@Override
public List<User> listByAgeRange(Integer minAge, Integer maxAge) {
return lambdaQuery()
.ge(User::getAge, minAge)
.le(User::getAge, maxAge)
.list();
}
@Override
public Page<User> pageQuery(Integer pageNum, Integer pageSize, String keyword) {
Page<User> page = new Page<>(pageNum, pageSize);
LambdaQueryWrapper<User> queryWrapper = new LambdaQueryWrapper<>();
if (StrUtil.isNotBlank(keyword)) { // StrUtil来自Hutool工具类
queryWrapper.like(User::getName, keyword)
.or()
.like(User::getEmail, keyword);
}
queryWrapper.orderByDesc(User::getCreateTime);
return page(page, queryWrapper);
}
}
2. 通用增删改接口
java
运行
public interface UserService extends IService<User> {
/**
* 新增用户(带参数校验)
* @param user 用户实体
* @return 是否成功
*/
boolean addUser(User user);
/**
* 批量更新用户状态
* @param userIds 用户ID列表
* @param status 目标状态
* @return 影响行数
*/
int batchUpdateStatus(List<Long> userIds, Integer status);
}
@Service
public class UserServiceImpl extends ServiceImpl<UserMapper, User> implements UserService {
@Override
public boolean addUser(User user) {
// 参数校验
if (user == null || StrUtil.isBlank(user.getName()) || user.getAge() == null) {
throw new IllegalArgumentException("用户姓名和年龄不能为空");
}
// 业务逻辑:如检查邮箱是否已存在
User existUser = lambdaQuery()
.eq(User::getEmail, user.getEmail())
.one();
if (existUser != null) {
throw new RuntimeException("邮箱已被注册");
}
// 插入数据
return save(user);
}
@Override
public int batchUpdateStatus(List<Long> userIds, Integer status) {
if (CollUtil.isEmpty(userIds) || status == null) { // CollUtil来自Hutool
return 0;
}
UpdateWrapper<User> updateWrapper = new UpdateWrapper<>();
updateWrapper.in("id", userIds)
.set("status", status);
return update(null, updateWrapper);
}
}
3. 业务接口的分层设计
基于IService的业务接口开发,应遵循 “Controller→Service→Mapper” 的分层原则:
Controller:负责请求参数接收、响应结果封装、异常处理
Service:负责业务逻辑、事务控制、复杂查询组合
Mapper:负责数据库 CRUD 的最底层操作
示例:
java
运行
@RestController
@RequestMapping("/user")
public class UserController {
@Autowired
private UserService userService;
@GetMapping("/list")
public Result<List<User>> listByAgeRange(@RequestParam Integer minAge, @RequestParam Integer maxAge) {
List<User> userList = userService.listByAgeRange(minAge, maxAge);
return Result.success(userList);
}
@PostMapping("/add")
public Result<Boolean> addUser(@RequestBody User user) {
boolean result = userService.addUser(user);
return Result.success(result);
}
}
十、IService 开发复杂业务接口:事务、多表与逻辑整合
在实际项目中,业务逻辑往往涉及多个表操作、事务控制、复杂业务规则,基于IService可以高效实现这些复杂场景。
1. 事务控制
MP 结合 Spring 的事务管理,可轻松实现声明式事务。
java
运行
@Service
public class UserOrderServiceImpl extends ServiceImpl<UserOrderMapper, UserOrder> implements UserOrderService {
@Autowired
private UserService userService;
@Autowired
private OrderService orderService;
/**
* 下单业务:扣减用户余额、创建订单(需事务)
*/
@Transactional(rollbackFor = Exception.class)
@Override
public boolean placeOrder(OrderDTO orderDTO) {
// 1. 扣减用户余额(假设User有balance字段)
User user = userService.getById(orderDTO.getUserId());
if (user.getBalance() < orderDTO.getAmount()) {
throw new InsufficientBalanceException("余额不足");
}
user.setBalance(user.getBalance() - orderDTO.getAmount());
boolean updateUser = userService.updateById(user);
if (!updateUser) {
throw new RuntimeException("用户余额更新失败");
}
// 2. 创建订单
UserOrder order = new UserOrder();
BeanUtil.copyProperties(orderDTO, order); // BeanUtil来自Hutool
boolean saveOrder = save(order);
if (!saveOrder) {
throw new RuntimeException("订单创建失败");
}
return true;
}
}
2. 多表关联业务
尽管 MP 主打单表操作,但通过自定义 SQL 和 Service 组合,可高效处理多表关联业务。
java
运行
@Service
public class OrderServiceImpl extends ServiceImpl<OrderMapper, Order> implements OrderService {
@Autowired
private OrderItemMapper orderItemMapper;
/**
* 查询订单及明细(一对多关联)
*/
@Override
public OrderVO getOrderWithItems(Long orderId) {
// 1. 查询订单主表
Order order = getById(orderId);
if (order == null) {
return null;
}
// 2. 查询订单明细(子表)
List<OrderItem> orderItems = orderItemMapper.selectList(
new LambdaQueryWrapper<OrderItem>().eq(OrderItem::getOrderId, orderId)
);
// 3. 封装VO返回
OrderVO orderVO = new OrderVO();
BeanUtil.copyProperties(order, orderVO);
orderVO.setOrderItems(orderItems);
return orderVO;
}
}
3. 业务规则与逻辑校验
复杂业务往往包含大量规则校验,可在 Service 层集中处理。
java
运行
@Service
public class UserServiceImpl extends ServiceImpl<UserMapper, User> implements UserService {
/**
* 注册用户(含多规则校验)
*/
@Override
@Transactional(rollbackFor = Exception.class)
public boolean register(UserRegisterDTO dto) {
// 规则1:校验手机号格式
if (!Pattern.matches("^1[3-9]\\d{9}$", dto.getPhone())) {
throw new IllegalArgumentException("手机号格式错误");
}
// 规则2:校验邮箱格式
if (!Pattern.matches("^\\w+@\\w+\\.\\w+$", dto.getEmail())) {
throw new IllegalArgumentException("邮箱格式错误");
}
// 规则3:校验用户名是否已存在
User existUser = lambdaQuery()
.eq(User::getUsername, dto.getUsername())
.or()
.eq(User::getPhone, dto.getPhone())
.or()
.eq(User::getEmail, dto.getEmail())
.one();
if (existUser != null) {
throw new RuntimeException("用户名、手机号或邮箱已被注册");
}
// 规则4:密码强度校验(假设要求6-20位,包含大小写字母、数字、特殊字符)
if (!Pattern.matches("^(?=.*[a-z])(?=.*[A-Z])(?=.*\\d)(?=.*[@$!%*?&])[A-Za-z\\d@$!%*?&]{6,20}$", dto.getPassword())) {
throw new IllegalArgumentException("密码强度不足,需包含大小写字母、数字和特殊字符");
}
// 加密密码(假设用BCrypt)
String encryptedPwd = BCrypt.hashpw(dto.getPassword(), BCrypt.gensalt());
// 构造用户实体并保存
User user = new User();
BeanUtil.copyProperties(dto, user);
user.setPassword(encryptedPwd);
user.setStatus(1); // 状态:正常
user.setCreateTime(LocalDateTime.now());
return save(user);
}
}
十一、IService 的 Lambda 方法:让代码更优雅
MP 的 Lambda 方法是其 “语法糖” 的集大成者,它基于 Java 8 的 Lambda 表达式,让代码更简洁、类型更安全、可读性更高。
1. Lambda 查询方法
java
运行
// 查询年龄大于25的用户,按创建时间降序排列
List<User> userList = userService.lambdaQuery()
.gt(User::getAge, 25)
.orderByDesc(User::getCreateTime)
.list();
// 查询ID在1、3、5中的用户,并排除年龄小于20的
List<User> userList = userService.lambdaQuery()
.in(User::getId, 1L, 3L, 5L)
.notLe(User::getAge, 20)
.list();
2. Lambda 更新方法
java
运行
// 将ID为1的用户年龄加1
boolean result = userService.lambdaUpdate()
.eq(User::getId, 1L)
.set(User::getAge, User::getAge + 1)
.update();
// 批量更新状态为1的用户,年龄统一设置为30
boolean result = userService.lambdaUpdate()
.eq(User::getStatus, 1)
.set(User::getAge, 30)
.update();
3. Lambda 删除方法
java
运行
// 删除年龄小于18的用户
boolean result = userService.lambdaUpdate()
.lt(User::getAge, 18)
.remove();
// 删除ID为2、4、6的用户
boolean result = userService.lambdaUpdate()
.in(User::getId, 2L, 4L, 6L)
.remove();
4. Lambda 方法的优势
类型安全:编译期检查字段名,避免运行时因字段名拼写错误导致的 SQL 异常。
代码简洁:无需手动拼接字符串,Lambda 表达式让逻辑更直观。
链式调用:支持方法链式调用,代码可读性高,符合 “流式编程” 的现代开发风格。
十二、IService 批量新增:性能与效率的平衡
批量操作是业务系统中常见的需求,MP 的IService提供了多种批量新增方法,可根据数据量大小选择合适的实现,平衡性能与代码复杂度。
1. 简单批量新增(saveBatch)
java
运行
// 构造用户列表
List<User> userList = new ArrayList<>();
for (int i = 0; i < 100; i++) {
User user = new User();
user.setName("用户" + i);
user.setAge(20 + i % 10);
user.setEmail("user" + i + "@example.com");
userList.add(user);
}
// 批量新增,默认每次批量插入100条
boolean result = userService.saveBatch(userList);
// 自定义批量插入条数(如每次插入50条)
boolean result = userService.saveBatch(userList, 50);
saveBatch方法的底层是通过循环调用insert语句实现,适合中小规模数据(万级以内),优点是实现简单,缺点是当数据量极大时性能一般。
2. 高效批量新增(基于InsertBatchSomeColumn)
对于超大规模数据(十万级以上),可通过自定义 SQL 或 MP 的InsertBatchSomeColumn扩展接口实现更高效的批量插入。
(1)自定义 BaseMapper
java
运行
public interface CustomBaseMapper<T> extends BaseMapper<T> {
/**
* 高效批量插入,忽略null值
* @param entityList 实体列表
* @return 影响行数
*/
int insertBatchSomeColumn(List<T> entityList);
}
// UserMapper继承自定义BaseMapper
public interface UserMapper extends CustomBaseMapper<User> {
}
(2)XML 实现批量插入 SQL
xml
<insert id="insertBatchSomeColumn" parameterType="java.util.List">
INSERT INTO user (name, age, email, create_time)
VALUES
<foreach collection="list" item="item" separator=",">
(#{item.name}, #{item.age}, #{item.email}, #{item.createTime})
</foreach>
</insert>
(3)Service 层调用
java
运行
@Service
public class UserServiceImpl extends ServiceImpl<UserMapper, User> implements UserService {
public boolean saveBatchHighEfficiency(List<User> userList) {
return getBaseMapper().insertBatchSomeColumn(userList) > 0;
}
}
这种方式直接生成一条包含所有数据的 INSERT 语句,避免了多次数据库连接,性能远高于循环插入,适合大数据量场景。
3. 批量新增的性能优化建议
数据量小(千级以内):使用saveBatch即可,代码简洁易维护。
数据量大(万级以上):使用自定义批量 SQL 或InsertBatchSomeColumn,减少数据库交互次数。
开启批量插入优化:在application.yml中配置 JDBC 的批量提交参数:
yaml
spring:
datasource:
url: jdbc:mysql://localhost:3306/test?rewriteBatchedStatements=true
# 其他配置...
rewriteBatchedStatements=true 可让 JDBC 驱动将批量插入转换为更高效的 SQL 语句。
十三、扩展功能 - 代码生成器:解放双手,一键生成 CRUD 代码
MyBatis-Plus 的代码生成器(AutoGenerator)是其 “效率神器” 之一,它可以一键生成 Entity、Mapper、Service、Controller、XML 等全套代码,让开发者彻底告别 “重复 CRUD” 的机械劳动。
1. 代码生成器依赖引入
xml
<dependency>
<groupId>com.baomidou</groupId>
<artifactId>mybatis-plus-generator</artifactId>
<version>3.5.3.2</version>
</dependency>
<!-- 模板引擎(可选,默认Velocity,也可使用Freemarker、Beetl) -->
<dependency>
<groupId>org.apache.velocity</groupId>
<artifactId>velocity-engine-core</artifactId>
<version>2.3</version>
</dependency>
2. 代码生成器配置与使用
创建一个 Java 类,编写生成器配置逻辑:
java
运行
import com.baomidou.mybatisplus.generator.FastAutoGenerator;
import com.baomidou.mybatisplus.generator.config.OutputFile;
import com.baomidou.mybatisplus.generator.engine.VelocityTemplateEngine;
import java.util.Collections;
public class CodeGenerator {
public static void main(String[] args) {
FastAutoGenerator.create("jdbc:mysql://localhost:3306/test?useUnicode=true&characterEncoding=utf-8&useSSL=false", "root", "password")
.globalConfig(builder -> {
builder.author("YourName") // 作者
.outputDir(System.getProperty("user.dir") + "/src/main/java") // 输出目录
.fileOverride() // 覆盖已有文件
.disableOpenDir(); // 生成后不打开目录
})
.packageConfig(builder -> {
builder.parent("com.example.demo") // 父包名
.moduleName("system") // 模块名
.entity("entity")
.mapper("mapper")
.service("service")
.controller("controller")
.pathInfo(Collections.singletonMap(OutputFile.mapperXml, System.getProperty("user.dir") + "/src/main/resources/mapper")); // XML输出路径
})
.strategyConfig(builder -> {
builder.addInclude("user", "order") // 要生成的表名
.entityBuilder()
.enableLombok() // 开启Lombok
.enableTableFieldAnnotation() // 开启字段注解
.enableChainModel(); // 开启链式模型
})
.templateEngine(new VelocityTemplateEngine()) // 使用Velocity模板引擎
.execute();
}
}
运行main方法后,代码生成器会自动在指定目录生成以下文件:
entity/User.java、entity/Order.java
mapper/UserMapper.java、mapper/OrderMapper.java 及对应的 XML 文件
service/UserService.java、service/OrderService.java 及对应的 Impl 实现类
controller/UserController.java、controller/OrderController.java
3. 代码生成器的自定义扩展
代码生成器支持高度自定义,可通过配置调整生成的代码风格、模板、字段策略等。
(1)自定义模板
若对默认生成的代码模板不满意,可在resources目录下创建自定义模板文件(如entity.java.vm),并在生成器中指定模板路径:
java
运行
.strategyConfig(builder -> {
builder.entityBuilder()
.templatePath("/templates/entity.java.vm"); // 自定义实体类模板路径
})
(2)字段策略调整
java
运行
.strategyConfig(builder -> {
builder.entityBuilder()
.ignoreColumns("create_time", "update_time") // 生成实体类时忽略的字段
.addTableFills(
new Column("create_time", FieldFill.INSERT), // 创建时间自动填充
new Column("update_time", FieldFill.INSERT_UPDATE) // 更新时间自动填充
);
})
(3)Service 方法扩展
通过自定义模板或注入自定义配置,可在生成的 Service 中添加通用业务方法。
代码生成器的强大之处在于 “一次配置,永久受益”,尤其在多表、多模块的项目中,能极大提升初始化开发效率。
十四、DB 静态工具:MP 的 “瑞士军刀”
MyBatis-Plus 提供了Db工具类,它是一个 “一站式” 的数据库操作工具,封装了常用的 CRUD、查询、事务等操作,甚至可以在不定义 Entity、Mapper 的情况下直接操作数据库,非常适合临时数据处理、脚本开发、简单业务场景。
1. Db 工具类的基本使用
(1)查询单条记录
java
运行
// 查询id=1的用户,返回Map
Map<String, Object> userMap = Db.getOne("SELECT * FROM user WHERE id = ?", 1L);
// 查询id=1的用户,转换为User实体(需User类存在)
User user = Db.getOne("SELECT * FROM user WHERE id = ?", User.class, 1L);
(2)查询列表
java
运行
// 查询年龄大于20的用户列表,返回Map列表
List<Map<String, Object>> userList = Db.list("SELECT * FROM user WHERE age > ?", 20);
// 查询年龄大于20的用户列表,转换为User列表
List<User> userList = Db.list("SELECT * FROM user WHERE age > ?", User.class, 20);
(3)分页查询
java
运行
// 分页查询:第1页,每页5条,年龄大于20的用户
IPage<Map<String, Object>> page = Db.page(new Page<>(1, 5), "SELECT * FROM user WHERE age > ?", 20);
System.out.println("总记录数:" + page.getTotal());
System.out.println("数据列表:" + page.getRecords());
(4)增删改操作
java
运行
// 插入数据
Map<String, Object> userMap = new HashMap<>();
userMap.put("name", "王五");
userMap.put("age", 28);
userMap.put("email", "wangwu@example.com");
boolean insertResult = Db.insert("user", userMap);
// 更新数据
Map<String, Object> updateMap = new HashMap<>();
updateMap.put("age", 29);
boolean updateResult = Db.update("user", updateMap, "id = ?", 1L);
// 删除数据
boolean deleteResult = Db.delete("user", "id = ?", 1L);
2. Db 工具类的优势与适用场景
优势:无需定义 Mapper、Entity 即可操作数据库,API 简洁,适合快速开发。
适用场景:
项目初始化时的临时数据脚本
简单的后台管理功能(如数据统计、配置修改)
第三方系统数据同步(无需完整 Entity 映射)
原型开发阶段,快速验证业务逻辑
3. Db 工具类的局限
不支持复杂的 Lambda 查询、条件构造器(需手动写 SQL)
缺乏实体关联、级联操作的支持
性能略低于通过 Mapper 的方式(因反射和动态 SQL 解析)
因此,Db工具类更适合 “轻量级、临时性” 的数据库操作,核心业务逻辑仍建议通过IService和BaseMapper实现。
十五、DB 静态工具练习:实战演练
为了更好地掌握Db工具类的使用,我们通过几个实战练习来巩固。
练习 1:统计各年龄段用户数量
需求:查询数据库中各年龄段的用户数量,按年龄分组。
java
运行
public class DbToolDemo {
public static void main(String[] args) {
// 分组查询SQL
String sql = "SELECT age, COUNT(*) as count FROM user GROUP BY age ORDER BY age";
// 使用Db工具类查询,返回Map列表
List<Map<String, Object>> result = Db.list(sql);
// 输出结果
result.forEach(map -> System.out.println("年龄:" + map.get("age") + ",数量:" + map.get("count")));
}
}
练习 2:批量导入用户数据
需求:从 CSV 文件中读取用户数据,批量导入到数据库。
java
运行
public class UserImportDemo {
public static void main(String[] args) throws IOException {
// 读取CSV文件(假设格式:name,age,email)
try (BufferedReader reader = new BufferedReader(new FileReader("users.csv"))) {
String line;
List<Map<String, Object>> userList = new ArrayList<>();
while ((line = reader.readLine()) != null) {
String[] parts = line.split(",");
if (parts.length == 3) {
Map<String, Object> userMap = new HashMap<>();
userMap.put("name", parts[0]);
userMap.put("age", Integer.parseInt(parts[1]));
userMap.put("email", parts[2]);
userList.add(userMap);
}
}
// 批量插入
boolean result = Db.insertBatch("user", userList, 100); // 每次插入100条
System.out.println("导入结果:" + (result ? "成功" : "失败"));
}
}
}
练习 3:用户数据迁移(跨库)
需求:将 A 库的用户数据迁移到 B 库,只迁移年龄大于 20 的用户。
java
运行
public class DataMigrationDemo {
public static void main(String[] args) {
// 从A库查询数据
String querySql = "SELECT id, name, age, email FROM user WHERE age > 20";
List<Map<String, Object>> userList = Db.list(querySql);
// 批量插入到B库(需先配置B库的数据源)
// 假设B库的数据源已配置为另一个连接
boolean result = Db.insertBatch("user", userList, 50);
System.out.println("迁移结果:" + (result ? "成功,共迁移" + userList.size() + "条数据" : "失败"));
}
}
通过这些练习,你可以感受到Db工具类在 “快速数据操作” 场景下的便捷性,它就像一把 “瑞士军刀”,能应对各种临时、简单的数据库操作需求。
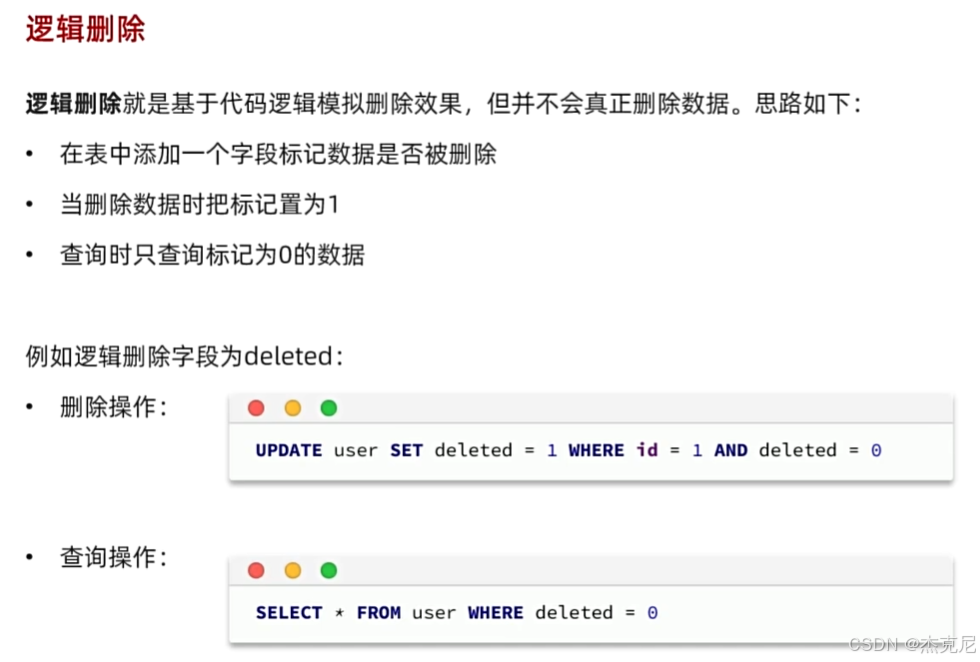
十六、逻辑删除:数据安全的 “后悔药”
在业务系统中,“删除” 操作往往不是真正的物理删除,而是标记为 “已删除”(逻辑删除),这样既保留了数据追溯能力,又避免了误删数据的风险。MyBatis-Plus 对逻辑删除提供了完善的支持。
1. 逻辑删除的配置与实现
(1)数据库表添加逻辑删除字段
sql
ALTER TABLE `user` ADD COLUMN `deleted` tinyint(1) DEFAULT 0 COMMENT '逻辑删除标记(0:未删除,1:已删除)';
(2)实体类添加逻辑删除字段并注解
java
运行
public class User {
// 其他字段...
@TableLogic
private Integer deleted; // 逻辑删除字段,0未删除,1已删除
}
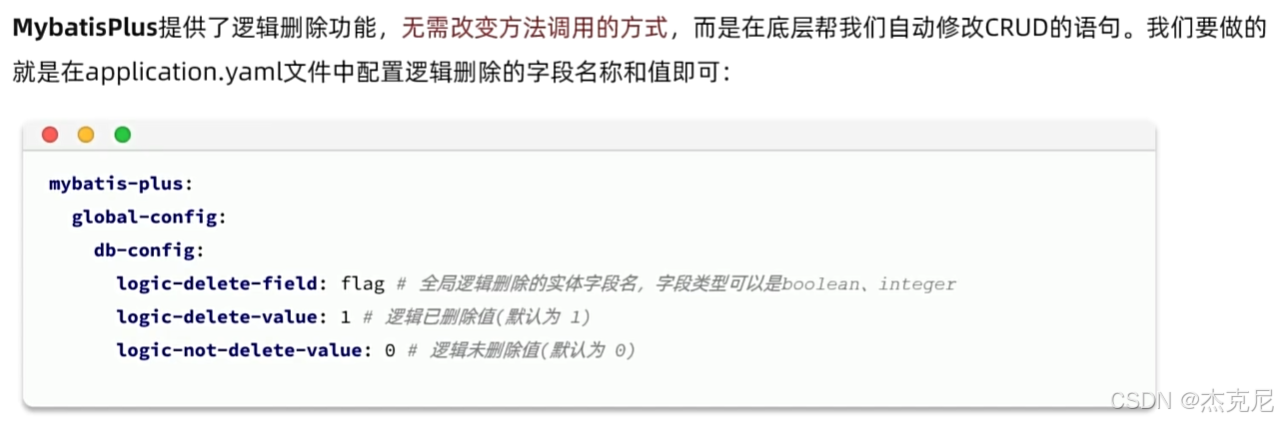
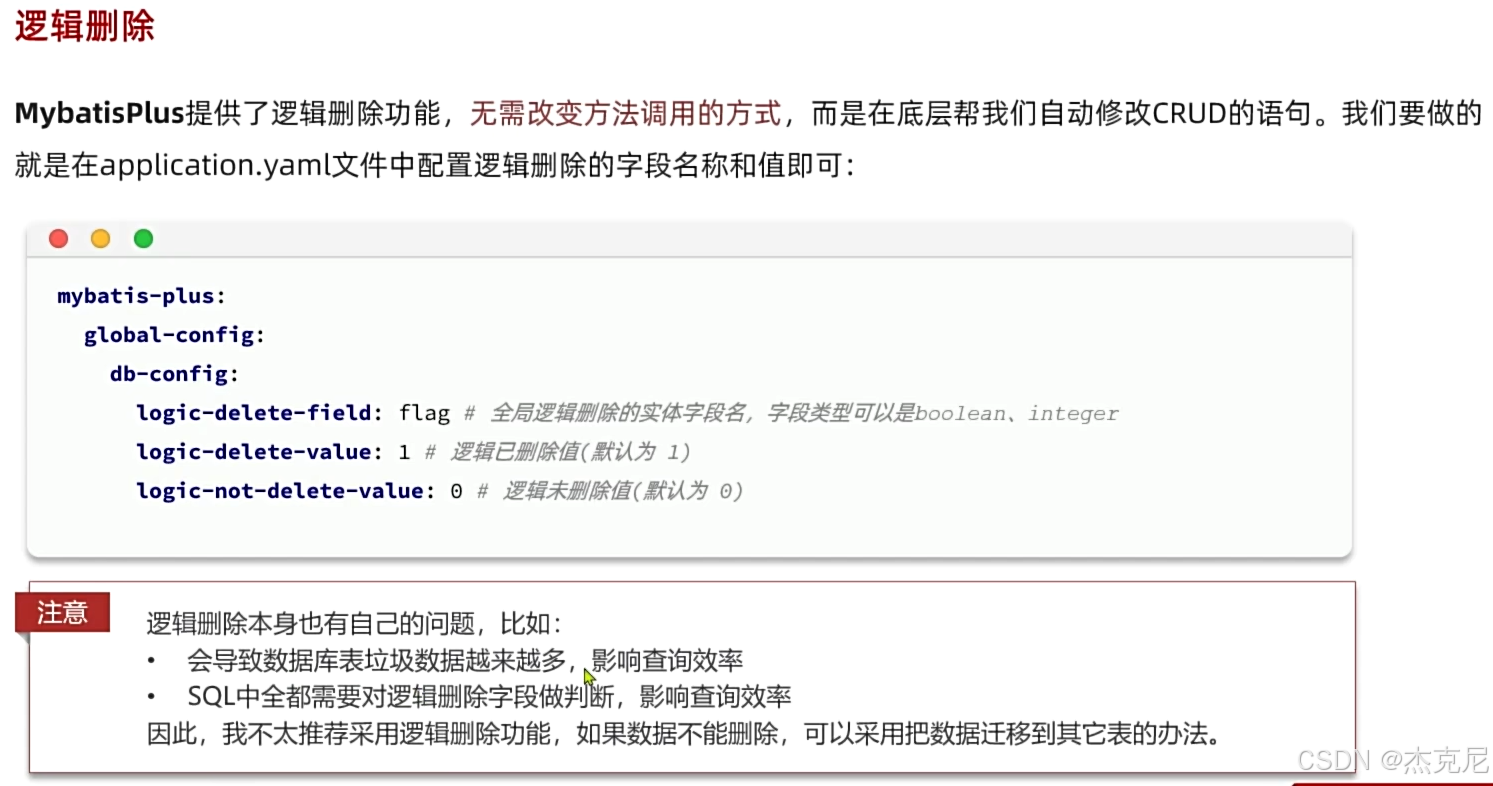
(3)全局配置(可选)
在application.yml中配置逻辑删除的全局规则:
yaml
mybatis-plus:
global-config:
db-config:
logic-delete-field: deleted # 逻辑删除字段名
logic-delete-value: 1 # 逻辑删除值
logic-not-delete-value: 0 # 逻辑未删除值
2. 逻辑删除的效果
配置完成后,MP 会自动处理逻辑删除的 SQL:
删除操作:执行更新语句,将deleted字段设为 1,而非物理删除。
java
运行
userService.removeById(1L);
// 实际执行的SQL:UPDATE user SET deleted=1 WHERE id=1 AND deleted=0
查询操作:自动添加deleted=0的条件,只查询未删除的数据。
java
运行
List<User> userList = userService.list();
// 实际执行的SQL:SELECT * FROM user WHERE deleted=0
3. 逻辑删除的高级用法
(1)自定义逻辑删除值
若业务中逻辑删除的标记值不是 0 和 1,可在@TableLogic注解中指定:
java
运行
public class User {
@TableLogic(value = "2", delval = "1") // 未删除值为2,删除值为1
private Integer delFlag;
}
(2)查询包含已删除数据
在某些场景下(如数据恢复),需要查询包含已删除的数据,可通过条件构造器实现:
java
运行
List<User> userList = userService.lambdaQuery()
.eq(User::getId, 1L)
.ignoreLogicDelete() // 忽略逻辑删除条件
.list();
(3)物理删除(绕过逻辑删除)
若确实需要物理删除,可使用removeById的重载方法:
java
运行
userService.removeById(1L, false); // 第二个参数为false,执行物理删除
逻辑删除是保障数据安全的重要手段,尤其在生产环境中,建议所有删除操作都默认使用逻辑删除,仅在明确需要物理删除时才特殊处理。
十七、枚举处理器:让枚举与数据库无缝对接
在 Java 开发中,枚举类型用于表示固定值的业务状态(如性别、订单状态、用户类型等)非常常见。MyBatis-Plus 提供了对枚举类型的完美支持,可实现枚举与数据库字段的自动映射。
1. 枚举类型的定义与注解
java
运行
import com.baomidou.mybatisplus.annotation.EnumValue;
public enum GenderEnum {
MALE(0, "男"),
FEMALE(1, "女");
@EnumValue // 标记数据库存储的枚举值
private final Integer code;
private final String desc;
GenderEnum(Integer code, String desc) {
this.code = code;
this.desc = desc;
}
// 可选:添加根据code获取枚举的方法
public static GenderEnum getByCode(Integer code) {
for (GenderEnum gender : values()) {
if (gender.code.equals(code)) {
return gender;
}
}
return null;
}
// Getter方法
public Integer getCode() {
return code;
}
public String getDesc() {
return desc;
}
}
2. 实体类中使用枚举
java
运行
public class User {
// 其他字段...
private GenderEnum gender; // 枚举类型字段
}
3. 枚举处理器的配置
MP 默认支持基于@EnumValue注解的枚举映射,无需额外配置即可使用。
(1)插入枚举
java
运行
User user = new User();
user.setGender(GenderEnum.MALE);
userService.save(user);
// 数据库中gender字段存储为0
(2)查询枚举
java
运行
User user = userService.getById(1L);
System.out.println("性别:" + user.getGender().getDesc()); // 输出:性别:男
(3)条件查询枚举
java
运行
List<User> userList = userService.lambdaQuery()
.eq(User::getGender, GenderEnum.FEMALE)
.list();
// 实际执行的SQL:SELECT * FROM user WHERE gender=1
4. 自定义枚举处理器(进阶)
若默认的枚举处理器无法满足需求(如枚举存储的是字符串而非数字),可自定义TypeHandler。
(1)自定义 TypeHandler
java
运行
import org.apache.ibatis.type.JdbcType;
import org.apache.ibatis.type.MappedJdbcTypes;
import org.apache.ibatis.type.MappedTypes;
import org.apache.ibatis.type.TypeHandler;
import java.sql.CallableStatement;
import java.sql.PreparedStatement;
import java.sql.ResultSet;
import java.sql.SQLException;
@MappedTypes(GenderEnum.class)
@MappedJdbcTypes(JdbcType.VARCHAR)
public class GenderEnumTypeHandler implements TypeHandler<GenderEnum> {
@Override
public void setParameter(PreparedStatement ps, int i, GenderEnum parameter, JdbcType jdbcType) throws SQLException {
ps.setString(i, parameter.getDesc()); // 存储枚举的desc(字符串)
}
@Override
public GenderEnum getResult(ResultSet rs, String columnName) throws SQLException {
String desc = rs.getString(columnName);
for (GenderEnum gender : GenderEnum.values()) {
if (gender.getDesc().equals(desc)) {
return gender;
}
}
return null;
}
// 其他getResult方法类似实现...
}
(2)注册 TypeHandler
在application.yml中配置:
yaml
mybatis-plus:
type-handlers-package: com.example.demo.handler # TypeHandler所在包
或在实体类字段上指定:
java
运行
public class User {
@TableField(typeHandler = GenderEnumTypeHandler.class)
private GenderEnum gender;
}
枚举处理器让枚举类型的使用变得简单、类型安全,避免了手动转换枚举与数据库值的繁琐操作,是业务代码 “去冗余” 的重要手段。
十八、JSON 处理器:复杂对象的数据库存储
在现代业务系统中,经常需要将复杂对象(如用户扩展信息、配置项)以 JSON 格式存储在数据库中。MyBatis-Plus 提供了对 JSON 类型的完美支持,可实现 Java 对象与 JSON 字符串的自动序列化 / 反序列化。
1. JSON 字段的数据库设计
以 MySQL 为例,可使用json类型字段存储 JSON 数据:
sql
ALTER TABLE `user` ADD COLUMN `ext_info` json COMMENT '用户扩展信息(JSON格式)';
2. 实体类定义与注解
java
运行
import com.baomidou.mybatisplus.annotation.TableField;
import com.baomidou.mybatisplus.extension.handlers.JacksonTypeHandler;
import lombok.Data;
@Data
public class User {
// 其他字段...
@TableField(typeHandler = JacksonTypeHandler.class)
private UserExtInfo extInfo; // UserExtInfo是自定义的复杂对象
}
// UserExtInfo类
@Data
public class UserExtInfo {
private String hobby; // 爱好
private List<String> skills; // 技能列表
private Map<String, String> settings; // 配置项
}
JacksonTypeHandler是 MP 提供的基于 Jackson 的 JSON 类型处理器,也可根据项目需求选择FastjsonTypeHandler(基于 Fastjson)。
3. JSON 字段的 CRUD 操作
(1)插入 JSON 数据
java
运行
User user = new User();
user.setName("赵六");
user.setAge(30);
UserExtInfo extInfo = new UserExtInfo();
extInfo.setHobby("篮球");
extInfo.setSkills(Arrays.asList("Java", "MySQL", "Spring"));
Map<String, String> settings = new HashMap<>();
settings.put("theme", "dark");
settings.put("language", "zh-CN");
extInfo.setSettings(settings);
user.setExtInfo(extInfo);
userService.save(user);
// 数据库中ext_info字段存储为:{"hobby":"篮球","skills":["Java","MySQL","Spring"],"settings":{"theme":"dark","language":"zh-CN"}}
(2)查询 JSON 数据
java
运行
User user = userService.getById(1L);
UserExtInfo extInfo = user.getExtInfo();
System.out.println("爱好:" + extInfo.getHobby());
System.out.println("技能:" + extInfo.getSkills());
System.out.println("配置:" + extInfo.getSettings());
(3)更新 JSON 数据
java
运行
User user = userService.getById(1L);
UserExtInfo extInfo = user.getExtInfo();
extInfo.getSkills().add("MyBatis-Plus"); // 新增技能
userService.updateById(user);
4. JSON 字段的条件查询
可通过 JSON 函数对 JSON 字段进行条件查询(不同数据库语法略有差异)。
以 MySQL 为例,查询爱好包含 “篮球” 的用户:
java
运行
List<User> userList = userService.lambdaQuery()
.apply("ext_info->'$.hobby' = '篮球'")
.list();
或使用 MP 的条件构造器结合自定义 SQL 片段:
java
运行
List<User> userList = userService.lambdaQuery()
.like("ext_info", "\"hobby\":\"篮球\"")
.list();
JSON 处理器让复杂对象的存储和查询变得简单,避免了将对象拆分为多个表的繁琐设计,特别适合存储 “半结构化” 的业务数据。
十九、分页插件的基本用法:轻松实现分页查询
分页是 Web 系统中几乎必备的功能,MyBatis-Plus 的分页插件支持多种数据库方言,使用简单,只需少量配置即可实现高效分页。
1. 分页插件的配置
java
运行
@Configuration
public class MybatisPlusConfig {
@Bean
public MybatisPlusInterceptor mybatisPlusInterceptor() {
MybatisPlusInterceptor interceptor = new MybatisPlusInterceptor();
// 注册分页插件,指定数据库方言(MySQL)
interceptor.addInnerInterceptor(new PaginationInnerInterceptor(DbType.MYSQL));
return interceptor;
}
}
2. 分页查询的基本使用
(1)Service 层分页
java
运行
@Service
public class UserServiceImpl extends ServiceImpl<UserMapper, User> implements UserService {
public Page<User> pageQuery(Integer pageNum, Integer pageSize, String keyword) {
Page<User> page = new Page<>(pageNum, pageSize);
LambdaQueryWrapper<User> queryWrapper = new LambdaQueryWrapper<>();
if (StrUtil.isNotBlank(keyword)) {
queryWrapper.like(User::getName, keyword)
.or()
.like(User::getEmail, keyword);
}
queryWrapper.orderByDesc(User::getCreateTime);
return page(page, queryWrapper);
}
}
(2)Controller 层调用
java
运行
@RestController
@RequestMapping("/user")
public class UserController {
@Autowired
private UserService userService;
@GetMapping("/page")
public Result<Page<User>> pageQuery(
@RequestParam(defaultValue = "1") Integer pageNum,
@RequestParam(defaultValue = "10") Integer pageSize,
@RequestParam(required = false) String keyword) {
Page<User> page = userService.pageQuery(pageNum, pageSize, keyword);
return Result.success(page);
}
}
(3)测试分页接口
请求 URL:http://localhost:8080/user/page?pageNum=1&pageSize=5&keyword=张返回结果示例:
json
{
"code": 200,
"msg": "成功",
"data": {
"records": [
{ "id": 1, "name": "张三", "age": 20, "email": "zhangsan@example.com", "createTime": "2023-01-01T10:00:00" },
{ "id": 3, "name": "张四", "age": 22, "email": "zhangsan4@example.com", "createTime": "2023-01-03T10:00:00" }
],
"total": 2,
"size": 5,
"current": 1,
"pages": 1
}
}
3. 分页插件的高级用法
(1)自定义分页 SQL
若需对分页 SQL 进行定制,可在 XML 中使用Page参数:
xml
<select id="selectUserPage" resultType="com.example.demo.entity.User">
SELECT * FROM user
<where>
<if test="page.size > 0">
<!-- 分页条件可根据业务自定义 -->
</if>
</where>
ORDER BY create_time DESC
</select>
(2)分页拦截器扩展
通过实现InnerInterceptor接口,可自定义分页逻辑(如数据权限过滤、SQL 改写)。
java
运行
public class CustomPaginationInnerInterceptor extends PaginationInnerInterceptor {
@Override
public void beforeQuery(Executor executor, MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler, BoundSql boundSql) {
// 分页前的拦截逻辑,可修改SQL、参数等
super.beforeQuery(executor, ms, parameter, rowBounds, resultHandler, boundSql);
}
}
// 配置类中注册
@Bean
public MybatisPlusInterceptor mybatisPlusInterceptor() {
MybatisPlusInterceptor interceptor = new MybatisPlusInterceptor();
interceptor.addInnerInterceptor(new CustomPaginationInnerInterceptor(DbType.MYSQL));
return interceptor;
}
分页插件是 MP 最实用的功能之一,它屏蔽了不同数据库分页语法的差异,让开发者可以专注于业务逻辑,无需关心底层分页实现。
二十、通用分页插件:从 “重复造轮子” 到 “一次封装”
在实际项目中,分页功能往往需要与前端交互、自定义分页参数、封装分页结果等,将这些通用逻辑封装为 “通用分页插件”,可大幅提升开发效率。
1. 通用分页参数与结果封装
java
运行
// 通用分页请求参数
@Data
public class PageQuery<T> {
private Integer pageNum = 1; // 页码,默认第1页
private Integer pageSize = 10; // 每页条数,默认10条
private T params; // 查询参数(泛型,可自定义)
}
// 通用分页结果
@Data
public class PageResult<T> {
private Long total; // 总记录数
private List<T> list; // 数据列表
private Integer pageNum; // 当前页码
private Integer pageSize; // 每页条数
private Long pages;