02|Langgraph | 从入门到实战 | workflow与Agent
一、简介
本系列为Langgraph文章,最终以实现企业级项目。

该系列文章,以官方文档路径撰写,深入浅出并配以自己理解,配以GIF动图演示、适当扩展延伸官方案例以及源码讲解
当然如果你需要你也可以查看官方文档
- 官方文档:https://langchain-ai.github.io/langgraph/
- 中文文档:https://www.aidoczh.com/langgraph/tutorials/
最终实战项目目标:构建一个Agents Framework(智能代理框架) 多智能体协作企业系统
本文如若有错误地方,烦请指正,另外方便的话,麻烦点个赞关注一下,谢谢
- 📊 Agent-Graph:每个业务 Agent 以状态图形式编排节点、条件边与循环边;
- 🔧 工具体系:自动发现与注册工具,支持函数调用(tool calling),可扩展MCP服务;
- 🗄️ 记忆/持久化:使用 Postgres 作为 LangGraph 的 checkpointer 与 store,Redis缓存prompt;
- 📋 统一注册中心:自动发现、注册并预编译 Agent 图与工具;
- 💪 滚动窗口摘要算法压缩上下文,用户画像,短期记忆,长期记忆混合
- 🌐 API 网关:FastAPI 路由聚合,提供通用 chat、agents、session 等接口;
- 🔄 可插拔 LLM:通过模型工厂与配置驱动,统一管理多厂商 LLM。
- 🌀 prompt缓存:redis加载prompt,prompt-web热更新管理
- 👁️🗨️ RAG 向量数据库,与工程结合,结构化,非结构化管理检索,召回
- 🥰 下一步引导功能,猜你想要功能

本系列文章,配套项目源码地址:
https://github.com/wenwenc9/langgraph-tutorial-wenwenc9
Langgraph系列文章
01|Langgraph | 从入门到实战 | 基础篇
langchain的系列文章(相信我把Langchain全部学一遍,你能深入理解AI的开发)
01|LangChain | 从入门到实战-介绍
02|LangChain | 从入门到实战 -六大组件之Models IO
03|LangChain | 从入门到实战 -六大组件之Retrival
04|LangChain | 从入门到实战 -六大组件之Chain
05|LangChain | 从入门到实战 -六大组件之Memory
06|LangChain | 从入门到实战 -六大组件之Agent
二、workflow&Agent

- workflow 是按照预设的执行流程,完成任务
- Agent 可以可以根据选择特定工具,或者流程,完成任务
在本小节,将结合workflow+Agent,完成学习。
本节官方文档地址:https://docs.langchain.com/oss/python/langgraph/workflows-agents#llms-and-augmentations
本节配套代码地址:https://github.com/wenwenc9/langgraph-tutorial-wenwenc9/blob/main/Langgraph_Learning/1-%E5%9F%BA%E7%A1%80%E7%AB%A0%E8%8A%82/3%E3%80%81%E5%B7%A5%E4%BD%9C%E6%B5%81%E4%B8%8E%E4%BB%A3%E7%90%86.ipynb

1、增加LLM的能力

部分LLM,本身不具备工具,或者记忆能力,输出结构化能力,而我们可以通过Agent工程为其赋予能力
- 为LLM绑定工具
- 让LLM输出结构化内容
1.1 结构化输出
官方文档:https://docs.langchain.com/oss/javascript/integrations/chat/index#featured-providers

官方文档,有提到部分模型是可以让其直接输出JSON的,你可以直接使用llm.with_structured_output方法让其输出指定JSON结构内容。
from pydantic import BaseModel, Fieldclass SearchQuery(BaseModel):search_query: str = Field(None, description="Query that is optimized web search.")justification: str = Field(None, description="Why this query is relevant to the user's request.")# Augment the LLM with schema for structured output
structured_llm = llm.with_structured_output(SearchQuery)# Invoke the augmented LLM
output = structured_llm.invoke("How does Calcium CT score relate to high cholesterol?")而我用的是豆包的doubao-1-5-pro-256k-250115 是不具备结构化输出的

在上一篇文章,我也讲过了如何操作,可以异步哪里,这里我就贴代码了
https://blog.csdn.net/weixin_44238683/article/details/153200305

我们的目标是,让模型输出内容:
- 笑话的主题
- 笑话的正文
from pydantic import BaseModel, Field
class JokerSchema(BaseModel):topic: str = Field(None, description="笑话的主题")joke_content: str = Field(None, description="笑话的正文")from langchain_core.output_parsers import JsonOutputParser
from langchain_core.prompts import PromptTemplate# 创建JsonOutputParser,绑定Pydantic模型
parser = JsonOutputParser(pydantic_object=JokerSchema)# 构造Prompt模板,注入格式化指令
prompt = PromptTemplate(template="返回内容必须符合以下JSON格式:\n{format_instructions}\n\n{content}",input_variables=["content"],partial_variables={"format_instructions": parser.get_format_instructions()},
)
# 构建调用链:Prompt -> LLM -> JSON解析器
structured_llm = prompt | llm | parser# structured_llm.invoke({"content":"给我讲一个西瓜的笑话"})
structured_llm.invoke("给我讲一个西瓜的笑话")可以看到输出了预期的内容,可以让让不具备结构化输出的模型,具备了这个能力
这里使用的是langchian中的链式调用,通过提示工程与,输出解释器
{'topic': '西瓜','joke_content': '许仙给老婆买了一顶帽子,白娘子戴上之后就死了,因为那是顶鸭(压)舌(蛇)帽,而许仙不知道,后来他又给老婆买了个西瓜,白娘子吃了之后就死了,因为那是个东(冻)瓜(呱)。'}
1.2 绑定工具
使用bind_tools方法
from langchain_openai import ChatOpenAI
llm = ChatOpenAI(model=modelName)
from langchain_core.tools import tool# 定义工具
@tool
def multiply(a: int, b: int) -> int:"""计算两个数的乘积"""return a * b@tool
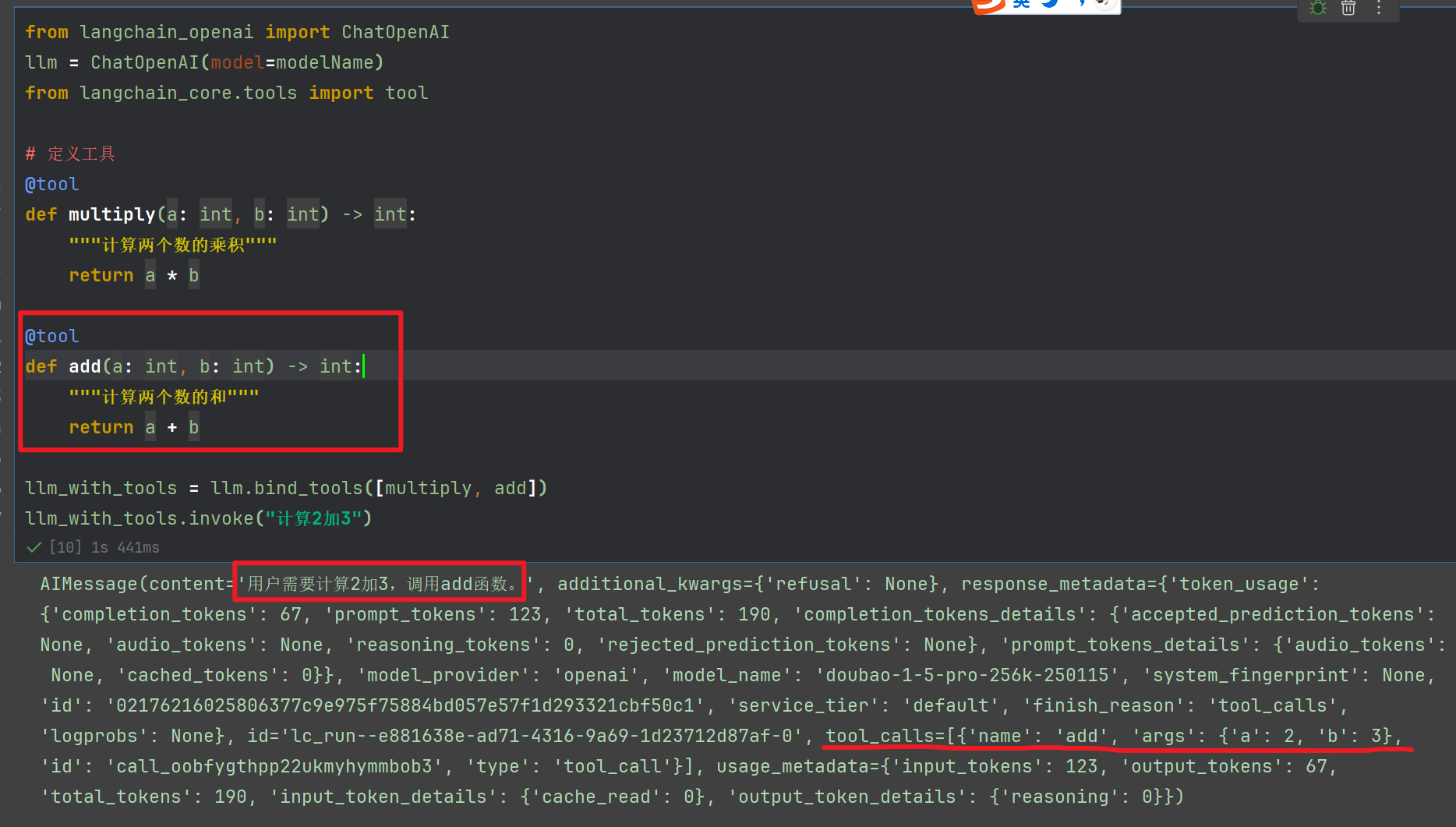
def add(a: int, b: int) -> int:"""计算两个数的和"""return a + bllm_with_tools = llm.bind_tools([multiply, add])
llm_with_tools.invoke("计算2加3")
输出如下
有些时候需要再工具运行时候,可以继承这个BaseTool,比如记录日志,注意要重写run,跟arun方法
from langchain.tools import BaseToolclass CalculatorTool(BaseTool):name: str = "calculator"description: str = "用于数学计算"def _run(self, expression: str) -> str:print("我是日志")return str(eval(expression))def _arun(self, expression: str) -> str:"""异步运行方法(可选)"""raise NotImplementedError("Calculator does not support async")# 使用
calculator = CalculatorTool()
llm_with_tools = llm.bind_tools([calculator])
llm_with_tools.invoke("1*4等于多少")
输出如下:
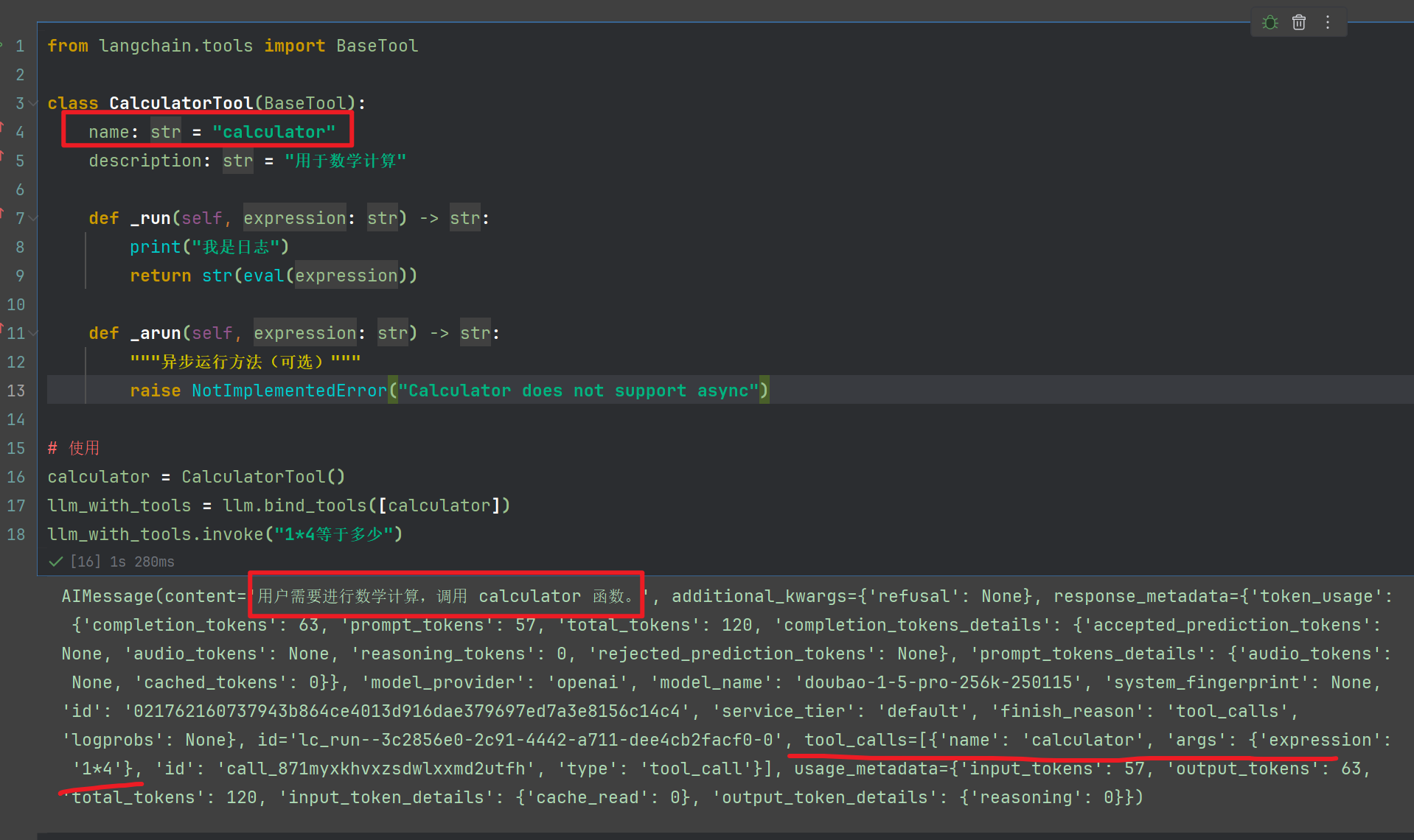
这个方法非常有用,后面我弄的架构,也是完全重写的,比如工具一般使用的时候,需要重写请求业务API,我们完全可以用redis缓存起来,加快速度调用

2、提示链(串行执行)

本案例展示了一个智能笑话生成和优化系统,通过多个 AI 模型协作,生成高质量的笑话:
条件分支逻辑:根据笑话质量决定处理路径,多步骤优化:逐步改进笑话内容状态管理:在整个流程中传递和更新数据
from typing_extensions import TypedDict
from langgraph.graph import StateGraph,END
from IPython.display import display,Image# 定义图的状态机
class State(TypedDict):topic: str # 笑话主题joke: str # 笑话内容improved_joke: str # 改进的笑话final_joke: str # 最后的笑话# 创建节点
def generate_joke(state: State):"""首次让模型生成笑话"""print("-"*50)msg = llm.invoke(f"写一个关于{state['topic']}的笑话,50字左右")print(f"首次让模型生成笑话\n{msg.content}")# 更新图状态机return {"joke": msg.content}# 检查笑话是否有亮点,路由
def check_punchline(state: State):"""用于检查笑话是否有亮点,并且路由到指定节点"""print("-"*50)print("检查功能,用于检查笑话是否有亮点")# 创建一个简单的判断规则:"?" or "!"来检查笑话是有否有亮点# 假定笑话不好笑,可以重新执行前面的步骤if "?" in state["joke"] or "!" in state["joke"]:return "Pass"return "Fail"# 优化笑话节点-1
def improve_joke(state: State):"""优化笑话内容"""print("-"*50)msg = llm.invoke(f"通过添加文字游戏使这个笑话更有趣: {state['joke']}")print(f"第二个模型优化笑话内容\n{msg.content}")return {"improved_joke": msg.content}# 优化笑话节点-2
def polish_joke(state: State):print("-"*50)"""第三个模型生成最终优化后的笑话"""msg = llm.invoke(f"为这个笑话添加一个令人惊讶的转折: {state['improved_joke']}")print(f"第三个模型生成最终优化后的笑话\n{msg.content}")return {"final_joke": msg.content}######### 构建工作流 #########
# 创建工作流
workflow = StateGraph(State)
workflow.add_node("generate_joke",generate_joke)
workflow.add_node("improve_joke", improve_joke)
workflow.add_node("polish_joke", polish_joke)# 链接节点
workflow.set_entry_point("generate_joke")
workflow.add_conditional_edges("generate_joke", check_punchline, {"Fail": "improve_joke", "Pass": END}
)
workflow.add_edge("improve_joke", "polish_joke")
workflow.add_edge("polish_joke", END)# 编译
graphed = workflow.compile()# Show workflow
display(Image(graphed.get_graph().draw_mermaid_png()))events = graphed.stream({"topic": "西瓜"},stream_mode="values",
)
for event in events:event

我们结合代码,以及图结构,来解释一下:
生成笑话,会有一个笑话检测函数check_punchline 判别笑话是否好笑
- 好笑
Pass返回路由端点名称为Fail,跳转结束回复 - 不好笑
Fail,返回路由端点为Pass,然后进过improve_joke+polish_joke两个节点优化笑话,最终跳转到结束
上面整个过程,是串行的,分成2条执行路径,我们可以运行一下(因为是判断! 跟 ? ,所以请自更改check_punchline检测逻辑以便体验2个路径)

3、并行链(并行执行)

在上面小节,提及了串行执行,是否有并行执行任务的操作呢?有的兄弟,有的
下面案例:将输入一个正文,分别让模型,生成笑话、诗文、故事,最后聚合输出

from typing_extensions import TypedDict
class State(TypedDict):topic: strjoke: strstory: strpoem: strcombined_output: str # 聚合笑话的内容# 创建节点
def call_llm_1(state: State):"""专门写笑话的节点"""msg = llm.invoke(f"写一个笑话关于 {state['topic']}")return {"joke": msg.content}def call_llm_2(state: State):"""专门写故事的节点"""msg = llm.invoke(f"写一个故事关于 {state['topic']}")return {"story": msg.content}def call_llm_3(state: State):"""专门写诗文的节点"""msg = llm.invoke(f"写一个诗文关于 {state['topic']}")return {"poem": msg.content}# 聚合节点,整合前面内容
def aggregator(state: State):"""整合所有的内容,进行最后输出"""combined = f"这里有一些,笑话、故事、诗文关于 {state['topic']}!\n\n"combined += f"STORY:\n{state['story']}\n\n"combined += f"JOKE:\n{state['joke']}\n\n"combined += f"POEM:\n{state['poem']}"return {"combined_output": combined}# 创建工作流
parallel_builder = StateGraph(State)
parallel_builder.add_node("call_llm_1", call_llm_1)
parallel_builder.add_node("call_llm_2", call_llm_2)
parallel_builder.add_node("call_llm_3", call_llm_3)
parallel_builder.add_node("aggregator", aggregator)
parallel_builder.set_entry_point("call_llm_1")
parallel_builder.set_entry_point("call_llm_2")
parallel_builder.set_entry_point("call_llm_3")
parallel_builder.add_edge("call_llm_1", "aggregator")
parallel_builder.add_edge("call_llm_2", "aggregator")
parallel_builder.add_edge("call_llm_3", "aggregator")
parallel_builder.add_edge("aggregator", END)
parallel_workflow = parallel_builder.compile()# Show workflow
display(Image(parallel_workflow.get_graph().draw_mermaid_png()))
输出的图如下:

我们执行看看
state = parallel_workflow.invoke({"topic": "西瓜"})
print(state["combined_output"])可以看到,状态机State最后的内容

4、路由

在前面的案例中,我们的是输入一个西瓜·,然后同时执行了3个节点,现在,我们将根据用户的需求,由LLM推断选择合适的模型。
现在,我们目标是:用户输入主题,决策后,执行指定节点【笑话,诗文,故事】,最后返回用户
这里,因为用的doubao1.5 不支持结构化输出,所以我们可以参考1.1小节改造,这里用了pydantic的模式
from pydantic import BaseModel, Field
from langchain_core.output_parsers import PydanticOutputParser
from langchain_core.prompts import PromptTemplate
from typing_extensions import Literal
from langchain_openai import ChatOpenAI
llm = ChatOpenAI(model=modelName)# 路由,由模型结构化推理出
class Route(BaseModel):step: Literal["poem", "story", "joke"] = Field(None, description="The next step in the routing process")# 绑定Pydantic模型
parser = PydanticOutputParser(pydantic_object=Route)# 构造Prompt模板,注入格式化指令
prompt = PromptTemplate(template="根据用户输入,决定应该生成诗歌(poem)、故事(story)还是笑话(joke)。\n{format_instructions}\n\n用户输入: {content}",input_variables=["content"],partial_variables={"format_instructions": parser.get_format_instructions()},
)
# 构建调用链:Prompt -> LLM -> json
route_llm = prompt | llm | parser
现在,我们继续剩余节点
from langchain.messages import HumanMessage, SystemMessage# State
class State(TypedDict):input: strdecision: stroutput: str# 创建节点
def call_llm_1(state: State):"""专门写笑话的节点"""msg = llm.invoke(f"写一个笑话关于 {state['input']}")return {"output": msg.content}def call_llm_2(state: State):"""专门写故事的节点"""msg = llm.invoke(f"写一个故事关于 {state['input']}")return {"output": msg.content}def call_llm_3(state: State):"""专门写诗文的节点"""msg = llm.invoke(f"写一个诗文关于 {state['input']}")return {"output": msg.content}def llm_call_router(state: State):"""将输入路由到合适的节点"""# 运行带有结构化输出的增强型大型语言模型(LLM),让其推理出决策decision = route_llm.invoke([SystemMessage(content="Route the input to story, joke, or poem based on the user's request."),HumanMessage(content=state["input"]),])return {"decision": decision.step}# 用于路由到适当节点的条件边函数
def route_decision(state: State):# 返回路由端点名称if state["decision"] == "story":return "call_llm_1"elif state["decision"] == "joke":return "call_llm_2"elif state["decision"] == "poem":return "call_llm_3"# 创建工作流
router_builder = StateGraph(State)
router_builder.add_node("call_llm_1", call_llm_1)
router_builder.add_node("call_llm_2", call_llm_2)
router_builder.add_node("call_llm_3", call_llm_3)
router_builder.add_node("llm_call_router", llm_call_router)router_builder.set_entry_point("llm_call_router")
router_builder.add_conditional_edges("llm_call_router",route_decision,{"call_llm_1": "call_llm_1","call_llm_2": "call_llm_2","call_llm_3": "call_llm_3",},
)
router_builder.add_edge("call_llm_1", END)
router_builder.add_edge("call_llm_2", END)
router_builder.add_edge("call_llm_3", END)# Compile workflow
router_workflow = router_builder.compile()# Show the workflow
display(Image(router_workflow.get_graph().draw_mermaid_png()))输出图如下:

新增了一个llm_call_router,推理节点,该节点让模型返回推理用户输入的目标是下面3个的那个一个,返回决策
["poem", "story", "joke"]
然后配合,路由节点,返回端点的名称,去执行相应的节点
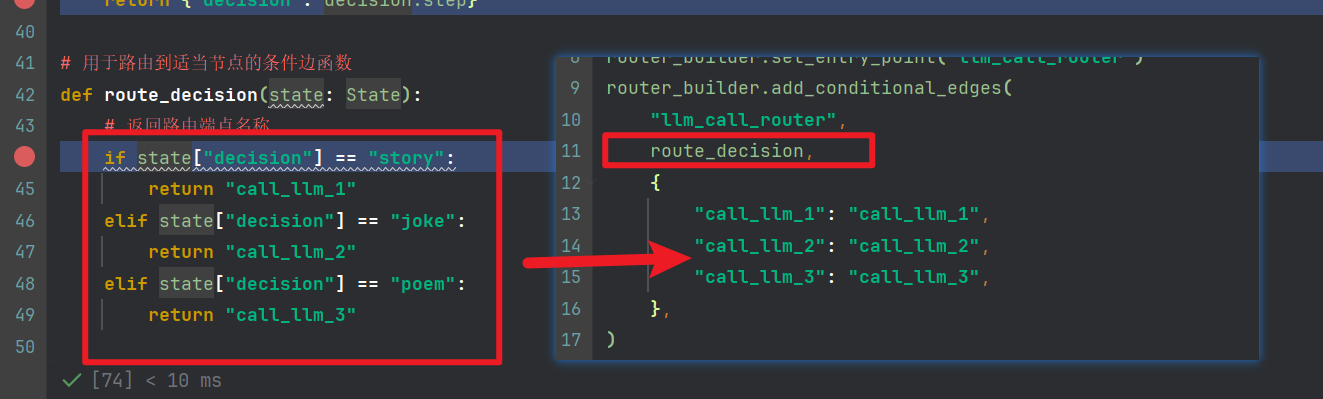
最终运行
state = router_workflow.invoke({"input": "写一个笑话关于西瓜"})
print(state["output"])
可以看到,图状态已经完成了记录

5、协调器

在上小节,我们实现了:用户输入主题,决策后,执行指定节点【笑话,诗文,故事】,最后返回用户。
现在我们的目标:用户需输入正文,要根据正文撰写一篇报告
- 根据内容,交给
大纲节点,生成《大纲-章节》,可能会有多个章节 - 创建一个
章节节点,根据章节描述撰写内容 - 创建一个
工作节点(协调器),根据所有章节,利用send并发交给章节节点撰写章节内容 - 创建一个
聚合节点,根据前面所有章节内容,聚合回复,生成最终报告
5.1 增强LLM的结构输出能力
首先,我们先增强模型的输出,让其输出指定结构的内容
from langchain_openai import ChatOpenAI
from typing import Annotated, List
from pydantic import BaseModel, Field
# 报告-《大纲章节》-schemas
class Section(BaseModel):name: str = Field(description="章节主题名称",)description: str = Field(description="章节内容需要符合章节主题,并且摘要内容",)
# 报告-章节列表-schemas
class Sections(BaseModel):sections: List[Section] = Field(description="章节列表",)
llm = ChatOpenAI(model=modelName)
# 格式化模型输出的结果
from langchain_core.output_parsers import PydanticOutputParser
from langchain_core.prompts import PromptTemplateparser = PydanticOutputParser(pydantic_object=Sections)# 构造Prompt模板,注入格式化指令
prompt = PromptTemplate(template="返回内容必须符合以下:\n{format_instructions}\n\n{topic}",input_variables=["topic"],partial_variables={"format_instructions": parser.get_format_instructions()},
)
# 构建调用链:Prompt -> LLM -> pydantic解析器
planner = prompt | llm | parser
5.2 创建工作节点
现在我们要创建节点
- 定义了2个状态,
State,WorkerState - 定义了3个节点
-
orchestrator节点根据用户输入正文,调用planner模型输出计划大纲[{章节主题name,章节摘要description},],更新State中的sections -
llm_call节点根据State中的sections的章节主题nam,章节摘要description,调用llm模型,完成章节内容,同时更新WorkerState跟State的completed_sections -
synthesizer节点聚合State中的completed_sections内容,生成最终报告,更新State中的final_report
-
- 利用
Send方法,实现并行执行章节节点撰写章节内容
假定,输出了3个章节跟摘要,此时会动态生成3个工作节点

from langgraph.graph import StateGraph,END
from langgraph.types import Send
import operator# 定义图状态-1
class State(TypedDict):topic: str # 章节主题sections: list[Section] # 章节列表内容[{主题,摘要},....]completed_sections: Annotated[list, operator.add] # 所有子章节详细内容final_report: str # 最终报告# Annotated 类型与 operator.add 确保新消息被追加到现有列表中,而不是替换它# 工作状态-2
class WorkerState(TypedDict):section: Section # 章节主题摘要completed_sections: Annotated[list, operator.add] # 章节对应的内容##################### 创建节点 ########################
def orchestrator(state: State):"""协调器:为用户输入报告正文topic,生成计划大纲"""# 生成报告大纲 这里是结构化planner-llm输出,为[{主题,章节摘要},....]report_sections = planner.invoke([# SystemMessage(content=f"为报告生成一个详细的计划大纲。你可以参考内容{content}"),SystemMessage(content="为报告生成一个详细的计划大纲。"),HumanMessage(content=f"报告主题是:{state['topic']}"),])return {"sections": report_sections.sections}def llm_call(state: WorkerState):"""工作节点:撰写报告的一个章节"""# 生成章节内容section = llm.invoke([SystemMessage(content="根据提供的章节名称和描述撰写报告章节。每个章节不要包含前言。使用markdown格式。"),HumanMessage(content=f"章节名称:{state['section'].name},章节描述:{state['section'].description}"),])# 将完成的章节写入已完成章节列表return {"completed_sections": [section.content]}def synthesizer(state: State):"""聚合节点:将各章节合成完整报告"""# 已完成章节列表completed_sections = state["completed_sections"]# 将完成的章节格式化为字符串,用作最终报告的上下文completed_report_sections = "\n\n---\n\n".join(completed_sections)return {"final_report": completed_report_sections}# 条件边函数,创建llm_call工作节点,每个节点撰写报告的一个章节
def assign_workers(state: State):"""为计划中的每个章节分配一个工作节点"""# 通过Send() API并行启动章节撰写return [Send("llm_call", {"section": s}) for s in state["sections"]]
5.3 构建工作流
现在我们构建工作流
# 构建工作流
orchestrator_worker_builder = StateGraph(State)# 添加节点
orchestrator_worker_builder.add_node("orchestrator", orchestrator)
orchestrator_worker_builder.add_node("llm_call", llm_call)
orchestrator_worker_builder.add_node("synthesizer", synthesizer)# 添加边连接节点
orchestrator_worker_builder.set_entry_point("orchestrator") # 为用户输入报告正文topic,生成计划大纲
orchestrator_worker_builder.add_conditional_edges("orchestrator", assign_workers, ["llm_call"]
)
orchestrator_worker_builder.add_edge("llm_call", "synthesizer")
orchestrator_worker_builder.add_edge("synthesizer", END)# 编译工作流
orchestrator_worker = orchestrator_worker_builder.compile()# 显示工作流
display(Image(orchestrator_worker.get_graph().draw_mermaid_png()))
尽管图显示,只有llm_call,但是实际上是根据章节数目,自动创建llm_call的调用,参考我上面的那副图

5.4 运行代码
我们运行代码看看
state = orchestrator_worker.invoke({"topic": "创建一份关于海运物流运输方案报告,'从盐田港到洛杉矶港运输1个40HQ集装箱的服装,预计一周内(2025年11月30日前)发货',要求有一个最终章节,船期,运价,等服务"})
from IPython.display import Markdown
Markdown(state["final_report"])
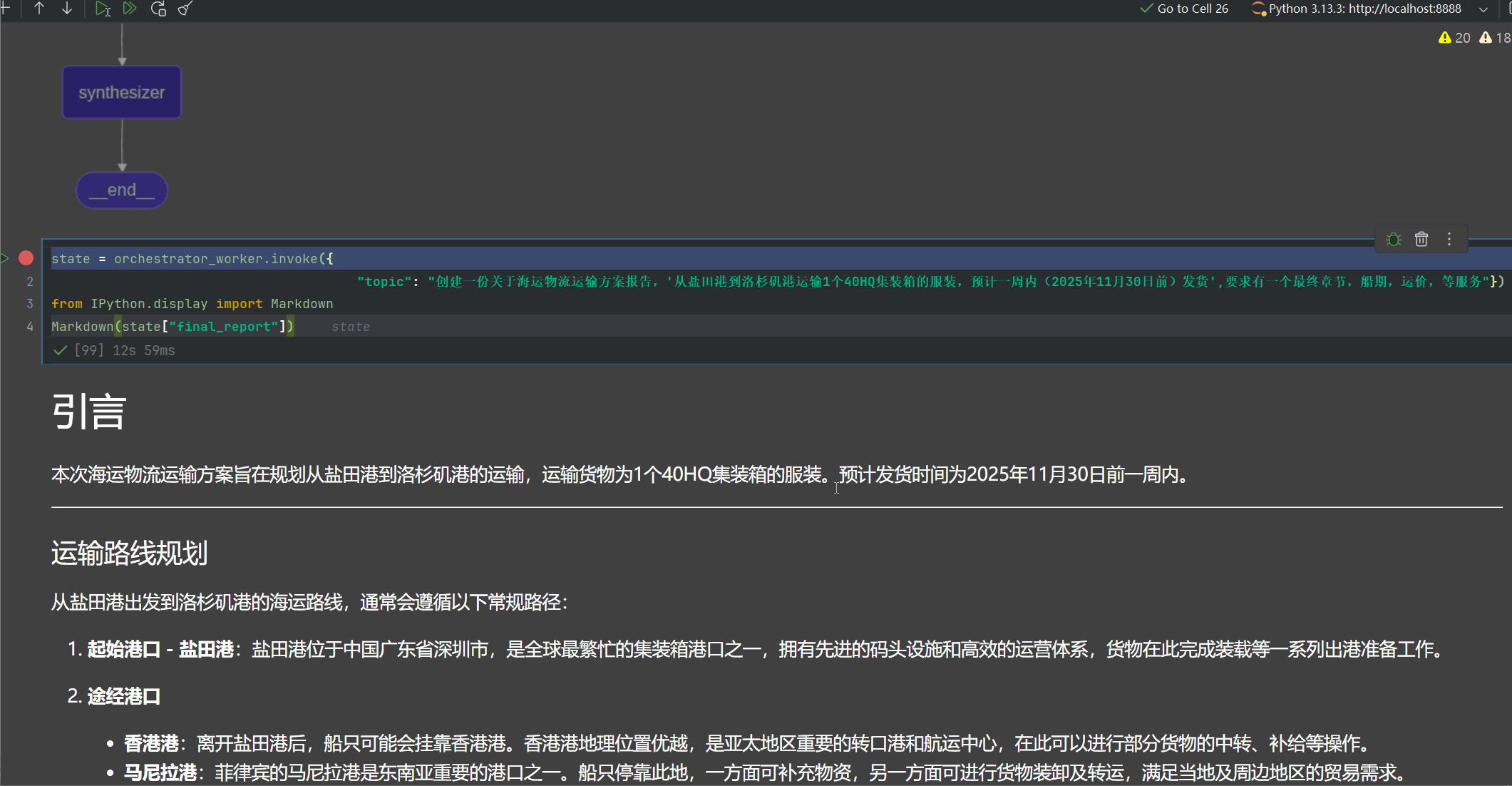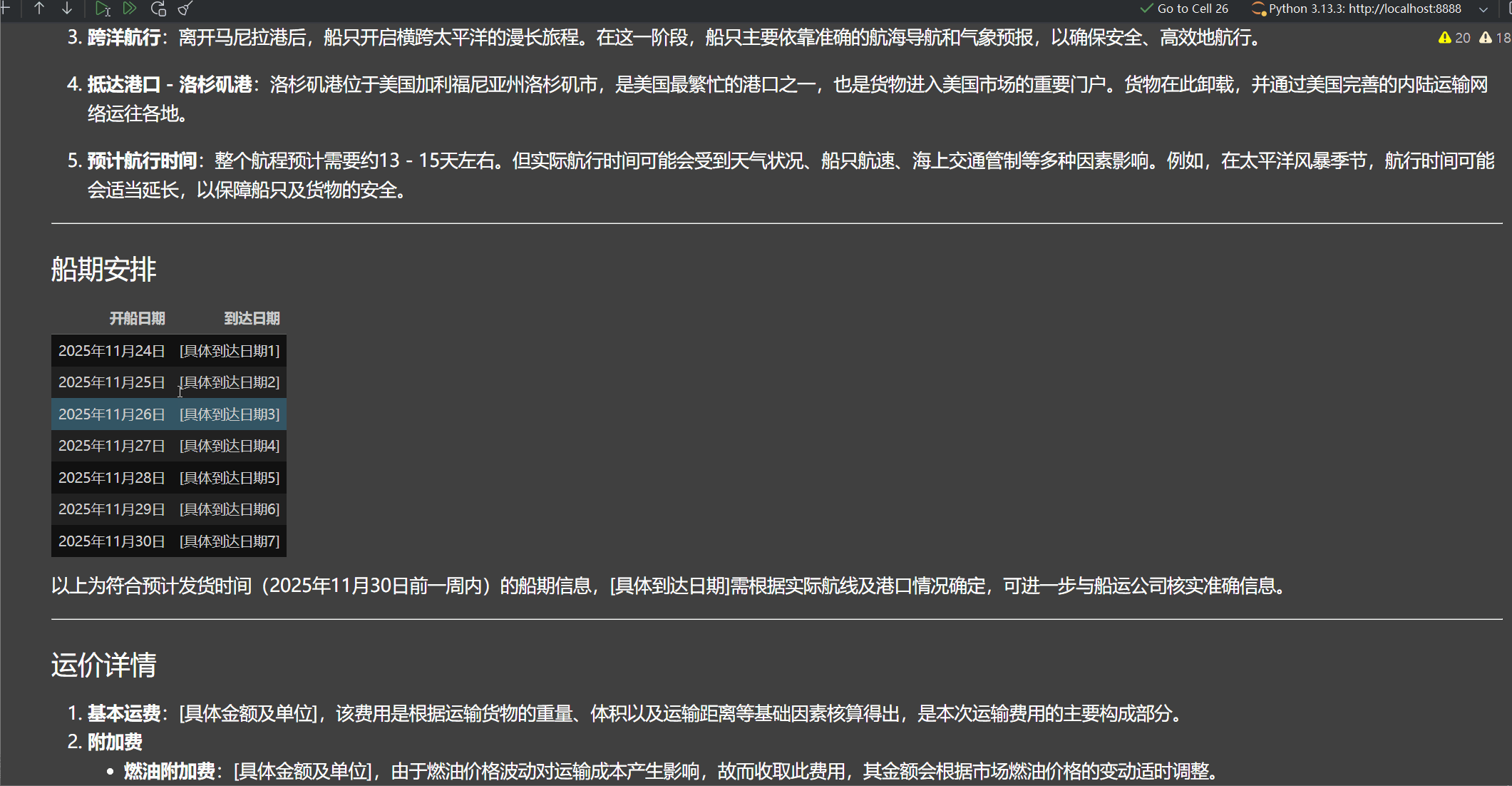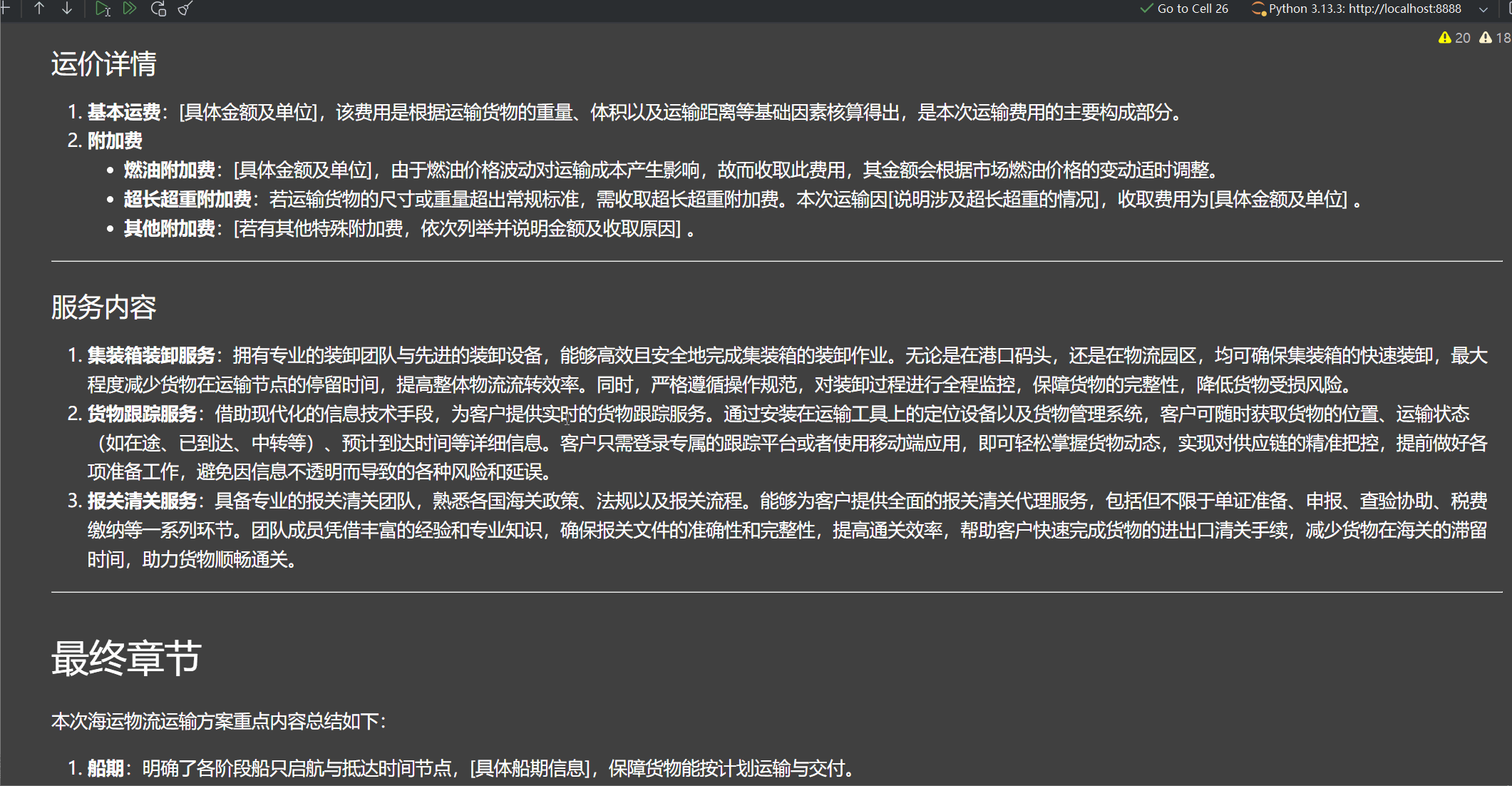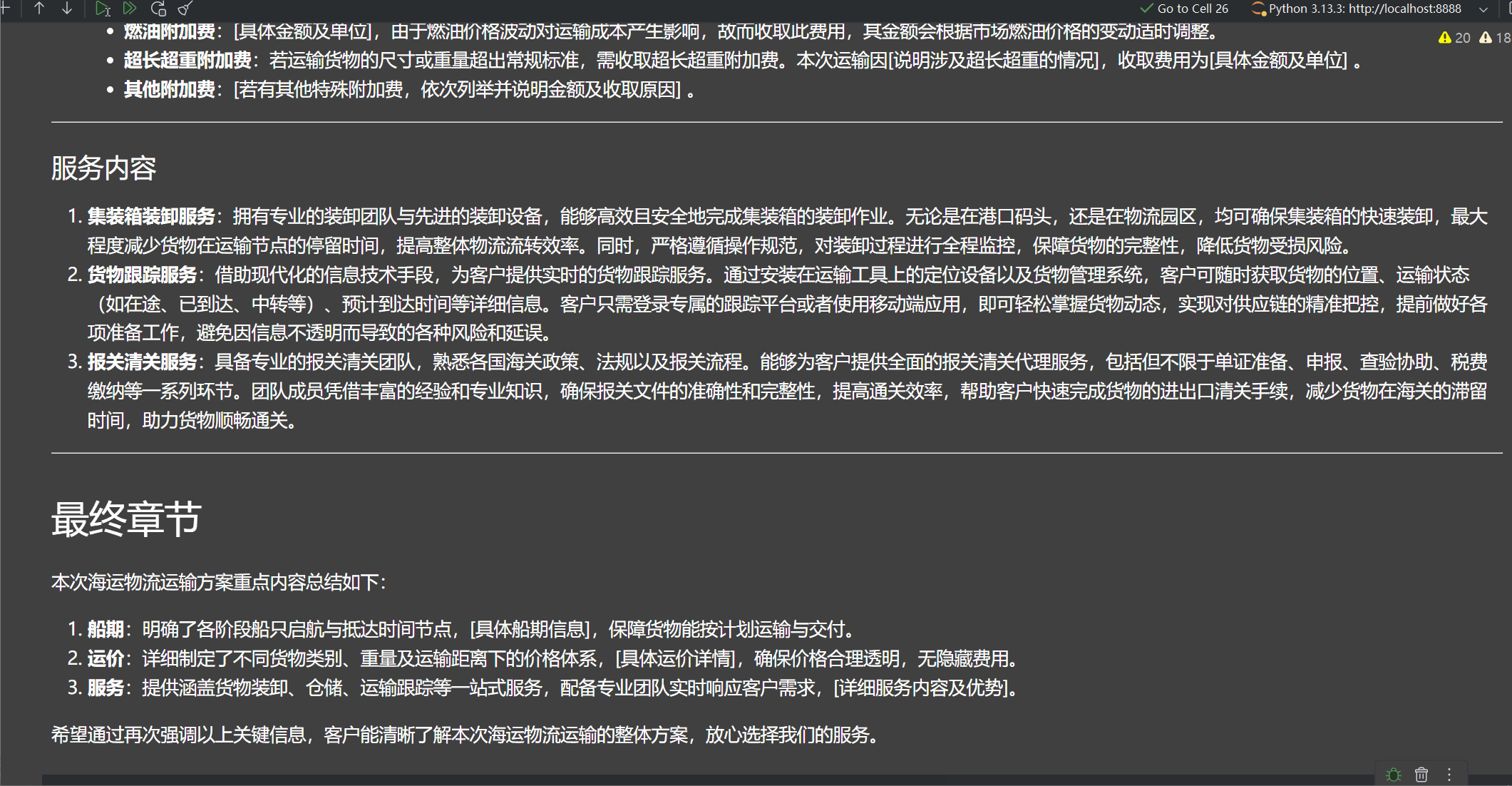
5.4 debug分析代码
我们在下面4处打上debug

在代码运行处debugger运行,首先进入第1个debugger处

看第一个节点的堆栈,可以看到生成了6个章节标题及其章节内容描述
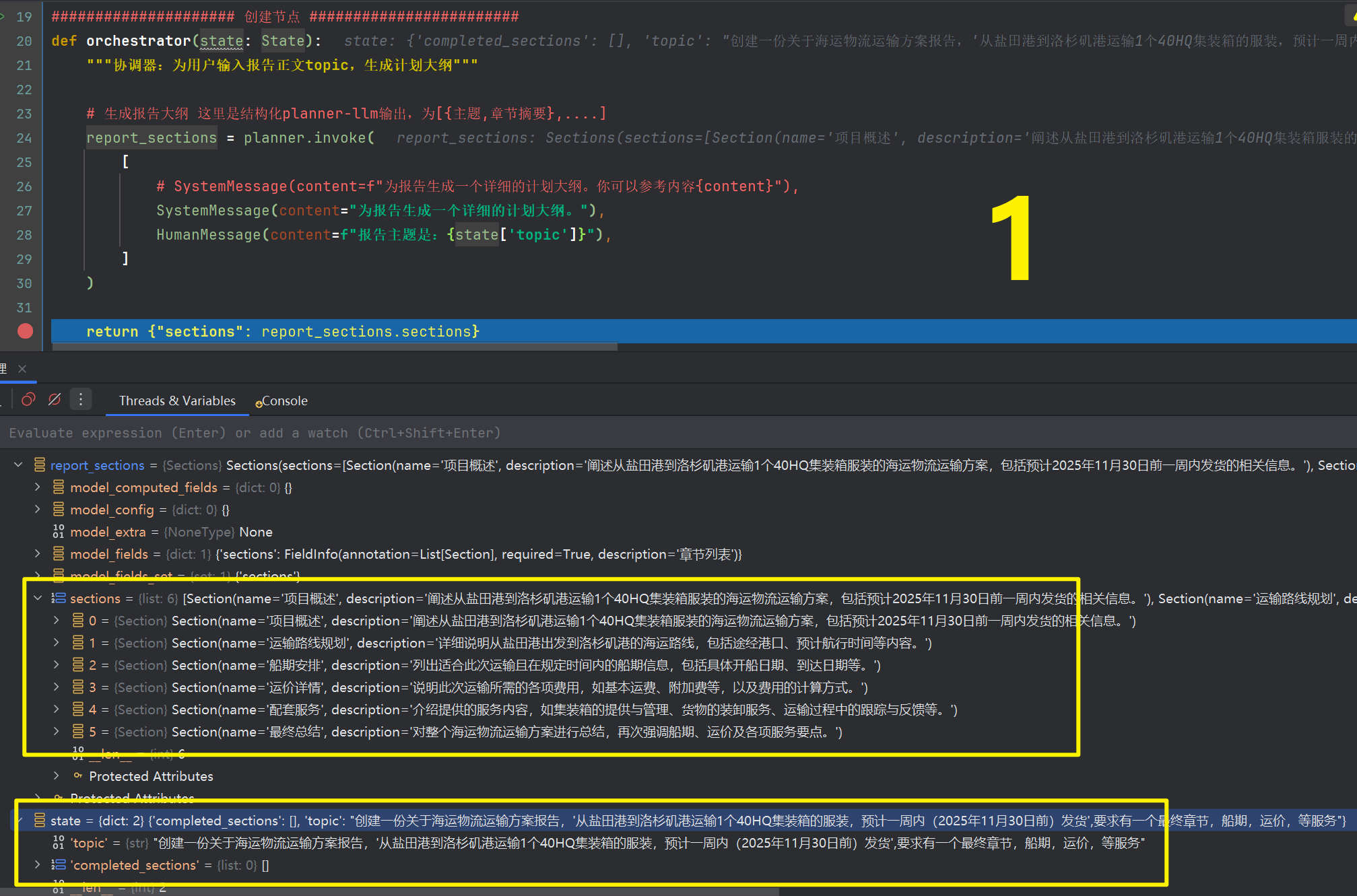
控制台按F,会运行到第4个黄色debugger处,这里是assign_workers 节点,开始准备分发任务了

继续运行F9,到llm_call黄色debugger序号第2处,因为有6个章节,你要按6次F9,这个过程在运行工作节点根据任务,撰写章节内容,第7次F9,才会跳转到synthesizer聚合节点
知识点:注意,因为在2个状态机State跟WorkerState都有completed_sections这个字段,在langgraph机制中,同一个工作流,虽然是不同状态机,但是存在相同字段都会进行更新。
后面进阶部分会详细介绍,状态机集成,跟子状态机等等操作
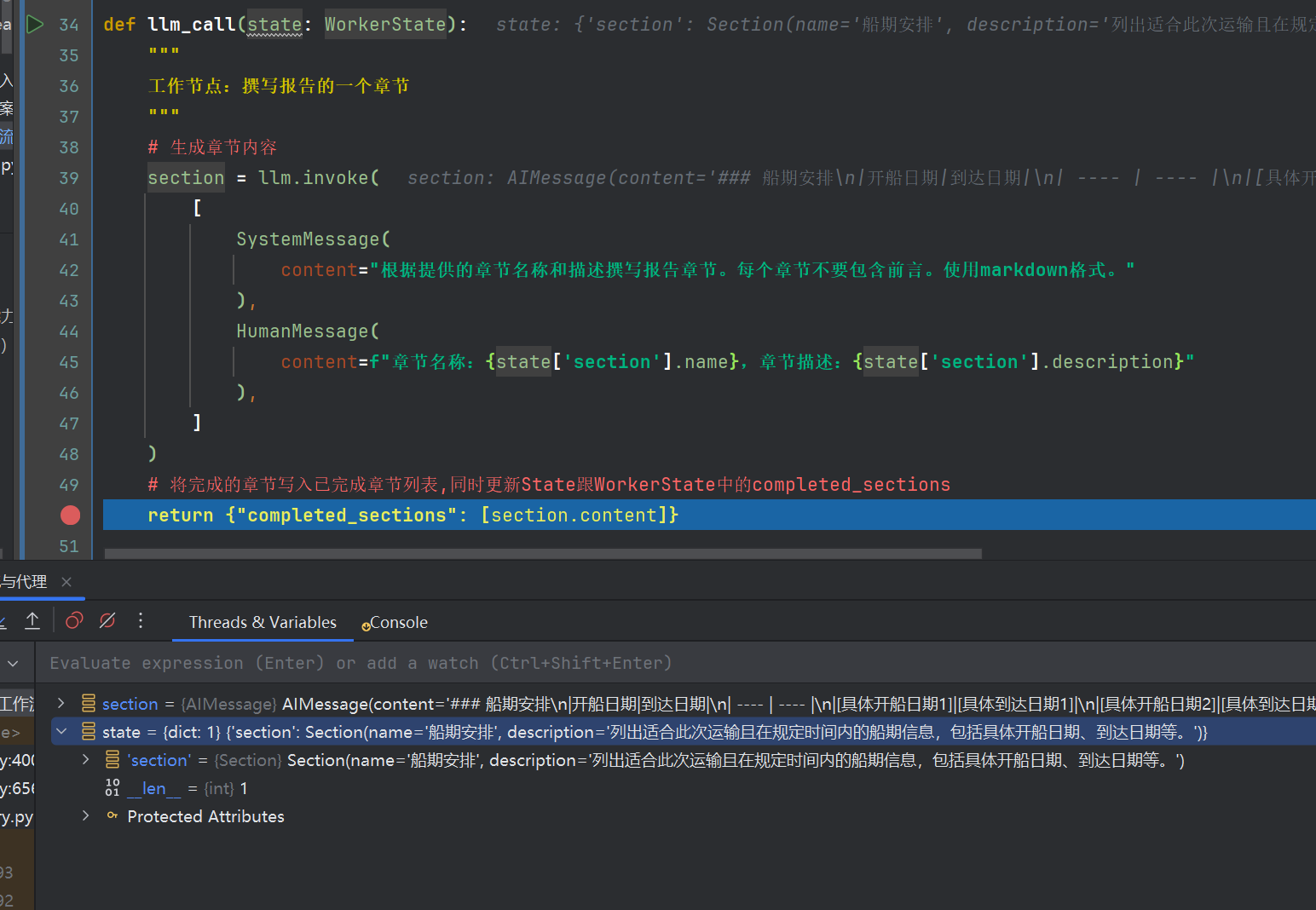
当跳转到黄色序号第3处debugger处,此时要聚合所有内容,生成最终报告

整个过程,一定要debugge,研究一下堆栈,状态机的变化!百说,不如一练
6、评估器
在前面的2、我们构建了笑话案例
- 第2小节,用户输入笑话主题,生成笑话内容,然后
- 好笑,直接输出笑话内容给用户
- 不好笑,优化改进笑话后再给用户,不好笑的判断规则是我们预先设置的"?“跟”!"来判断的,并且仅有
一次优化就结束
那现在,真实情况是,模型输出的笑话,尽管经过了改进,但是大概率还是不好笑.
是否能够让模型进入类似递归操作,多次判断,进入循环呢?直到笑话好笑
下面案例就是解决这个内容,让我们开始吧!gogogo!
首先,我们增强LLM的输出结果
from langchain_openai.chat_models import ChatOpenAI
from langchain_core.prompts import PromptTemplate
from langchain_core.output_parsers import PydanticOutputParser# 创建模型
llm = ChatOpenAI(model=modelName)# 用于评估的结构化输出模式
class Feedback(BaseModel):grade: Literal["funny", "not funny"] = Field(description="判断笑话是否有趣",)feedback: str = Field(description="如果笑话不有趣,提供改进建议",)
parser = PydanticOutputParser(pydantic_object=Feedback)
# 构造Prompt模板,注入格式化指令
prompt = PromptTemplate(template="返回内容必须符合以下:\n{format_instructions}\n\n{topic}",input_variables=["topic"],partial_variables={"format_instructions": parser.get_format_instructions()},
)
# 构建调用链:Prompt -> LLM -> JSON解析器
evaluator = prompt | llm | parser
然后我们创建2个节点,跟一个路由函数
llm_call_generator节点根据State状态机进行了判断,是生成笑话,还是根据反馈节点,改进笑话,这里直接调用的是llmllm_call_evaluator节点,根据生成笑话节点,评估笑话是否好笑,输出评估结果,调用的是evaluator增强结构后的模型route_joke节点,配合条件边,判断State中funny_or_not以指向不同步骤
注意!,因为为了更好直观体验,我这边llm_call_generator节点,第一次生成笑话的时候,是故事生成

from typing_extensions import TypedDict# 定义图状态
class State(TypedDict):joke: str # 笑话内容topic: str # 用户输入的正文feedback: str # 如果笑话不好笑的话,改进建议funny_or_not: str # funny 或者 not_funny# 笑话生成节点
def llm_call_generator(state: State):"""LLM生成笑话"""print("\n" + "=" * 10, "调用笑话生成", "=" * 10)if state.get("feedback"):msg = llm.invoke(f"写一个关于{state['topic']}的笑话,但要考虑以下反馈:{state['feedback']}")else:msg = llm.invoke(f"写一个关于{state['topic']}的故事,50字左右即可") # ps:为了能够走通链路,所以这里为 `故事`print("生成笑话:\n", {"joke": msg.content})return {"joke": msg.content}# 笑话评估节点
def llm_call_evaluator(state: State):"""LLM评估笑话"""print("\n" + "=" * 10, "LLM评估笑话", "=" * 10)grade = evaluator.invoke(f"评估这个笑话好不好笑,是否有亮点:{state['joke']}")print("评估结果\n", {"funny_or_not": grade.grade, "feedback": grade.feedback})return {"funny_or_not": grade.grade, "feedback": grade.feedback}# 条件边函数,根据评估器的反馈路由回笑话生成器或结束
def route_joke(state: State):"""根据评估器的反馈路由回笑话生成器或结束"""if state["funny_or_not"] == "funny":return "接受"elif state["funny_or_not"] == "not funny":return "拒绝+反馈"
现在,我们构建工作流
from langgraph.graph import StateGraph# 构建工作流
optimizer_builder = StateGraph(State)# 添加节点
optimizer_builder.add_node("llm_call_generator", llm_call_generator)
optimizer_builder.add_node("llm_call_evaluator", llm_call_evaluator)# 添加边连接节点
optimizer_builder.set_entry_point("llm_call_generator")
optimizer_builder.add_edge("llm_call_generator", "llm_call_evaluator")
optimizer_builder.add_conditional_edges("llm_call_evaluator",route_joke,{ # route_joke返回的名称:要访问的下一个节点名称"接受": END,"拒绝+反馈": "llm_call_generator",},
)# 编译工作流
optimizer_workflow = optimizer_builder.compile()# 显示工作流
from IPython.display import Image, display
display(Image(optimizer_workflow.get_graph().draw_mermaid_png()))
呈现效果如下:

我们调用看看
# 调用
state = optimizer_workflow.invoke({"topic": "猫"})
print(state["joke"])
输出结果如下,可以看到进行了2轮:

7、Agent代理

Agent,一般来说,能够自主选择工具使用,特性问题可以调用已有工具解决,普通问题可以直接回答
下面的案例正如我上面所说的,我们将完成这块的学习。
7.1 构建Agent
首先,我们为模型绑定工具,一个是数值相加的,一个是根据姓名查询个人资料的
from langchain_openai.chat_models import ChatOpenAI
from langchain_core.tools import tool# 基础模型
llm = ChatOpenAI(model=modelName)# 创建一个加法工具
@tool
def add(a: int, b: int) -> int:"""Adds a and b.Args:a: first intb: second int"""return a + b# 个人资料查询
@tool
def queryPersonal(name: str) -> dict:"""查询个人资料Args:name: 姓名"""return {"name": name,"age": 18,"love": "唱跳RAP"}tools = [add, queryPersonal]
tools_by_name = {tool.name: tool for tool in tools}
llm_with_tools = llm.bind_tools(tools) # 能够使用工具的LLM
然后,我们创建节点跟路由
llm_call节点,模型调用节点,根据用户问题,进行执行安排tool_node节点,工具执行节点,执行llm_call节点推理的工具should_continue路由,判断是否结束回复
from langgraph.graph import MessagesState
from langchain_core.messages import SystemMessage, HumanMessage, ToolMessage# 模型调用节点
def llm_call(state: MessagesState):"""LLM决定是否调用工具"""return {"messages": [llm_with_tools.invoke([SystemMessage(content="你是一个有用的助手,根据用户问题选择合适的工具调用,或者不用调用工具")]+ state["messages"])]}# 执行工具的节点
def tool_node(state: dict):"""执行工具调用"""result = []for tool_call in state["messages"][-1].tool_calls:tool = tools_by_name[tool_call["name"]]observation = tool.invoke(tool_call["args"])result.append(ToolMessage(content=observation, tool_call_id=tool_call["id"]))return {"messages": result}# 条件边函数,根据LLM是否进行工具调用来路由到工具节点或结束
def should_continue(state: MessagesState) -> Literal["environment", END]:"""根据LLM是否进行工具调用来决定是否继续循环或停止"""messages = state["messages"]last_message = messages[-1]# 如果LLM进行工具调用,则跳转到工具节点if last_message.tool_calls:return "执行工具"# 否则,我们停止(回复用户)return END
- 前面我们都是自定义了状态机
- langgraph官方也提供了默认的状态机,供给我们使用,上面代码使用的
MessagesState
官方文档:https://docs.langchain.com/oss/python/langgraph/graph-api#messagesstate

现在我们构建工作流
# 构建工作流
agent_builder = StateGraph(MessagesState)# 添加节点
agent_builder.add_node("llm_call", llm_call)
agent_builder.add_node("tool_node", tool_node)# 添加边连接节点
agent_builder.set_entry_point("llm_call")
agent_builder.add_conditional_edges("llm_call",should_continue,{# should_continue返回的名称:要访问的下一个节点名称 ps 这里访问的是工具"执行工具": "tool_node",END: END,},
)
agent_builder.add_edge("tool_node", "llm_call")# 编译代理
agent = agent_builder.compile()# 显示代理
display(Image(agent.get_graph(xray=True).draw_mermaid_png()))

7.2 运行代码&分析代码
7.2.1 同时触发两个工具
这次我们尝试,输入的问题,涉及到两个工具的调用
messages = [HumanMessage(content="将3加上4,并且帮我查询稳稳的个人资料")]
messages = agent.invoke({"messages": messages})
for m in messages["messages"]:m.pretty_print()
输出如下

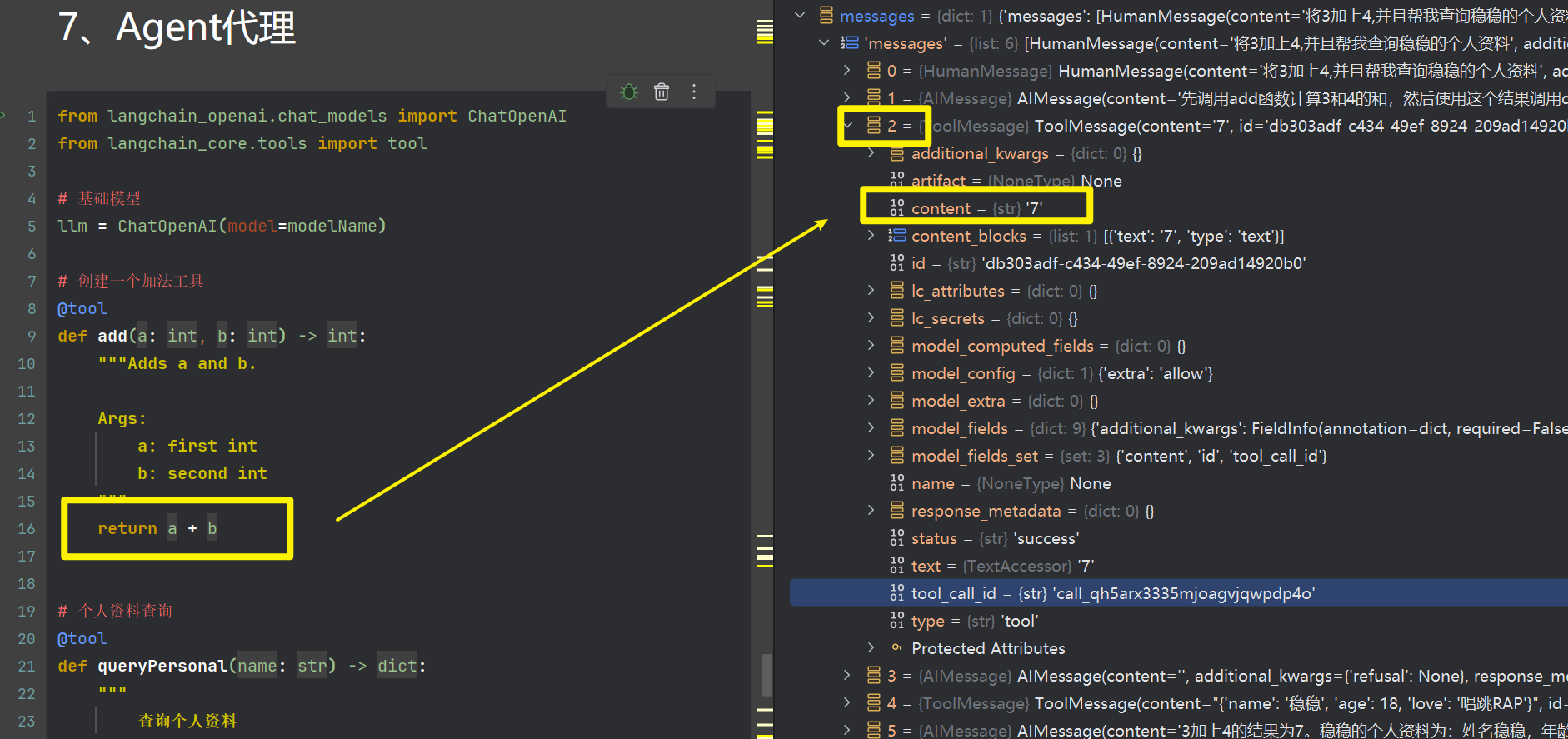
我们分析一下堆栈内容,这里有6个消息体,分别为人类输入跟AI回复,以及工具执行

我们看序号为1,跟2的即可,先说序号1,在第一个用户输入后,AI推断出,需要调用工具,并且生成了tool_calls,指向了具体工具
并且生成了tool_call[args"],从用户问题,提取出了该工具需要传入的参数
同样的tool_node 节点,从状态机state获取消息载体,然后进行invoke调用指定工具

接着我们来看序号2,其实就是工具执行后的结果,最后returnstate更新了messages的正文
7.2.2 问普通问题
我们构建的这个Agent,同时具备了普通问题的回复
messages = [HumanMessage(content="你知道太阳的体积吗?")]
messages = agent.invoke({"messages": messages})
for m in messages["messages"]:m.pretty_print()
输出如下:

三、本节总结

Workflow vs Agent:
- Workflow(工作流):按照预设的执行流程完成任务,路径固定
- Agent(代理):可以根据情况选择特定工具或流程,具备决策能力
百看不如一练