DeepAgent:工具检索、工具调用与思维折叠的统一智能体框架深度解析
引言

- 背景与动机:在复杂开放环境中,传统基于“单一大模型直接生成”的智能体很容易遇到上下文爆炸、错误工具选择、冗长链路累积错误等问题。现实任务往往需要跨多工具协作(如查询数据库、访问网页、调用第三方 API),这对智能体的检索、计划与执行能力提出更高要求。
- 核心问题:
- 如何在庞大的工具库中检索到恰当工具,并在参数空间中稳健调用?
- 如何在长链路推理与多轮工具调用过程中控制上下文长度和错误累积?
- 如何让智能体“回顾—总结—重构”当前思路,避免在次优路径上无效消耗?
- 研究意义:DeepAgent 提出“工具检索 + 工具调用 + 思维折叠 + 三类记忆”的统一框架,能够在多数据集、多任务场景下提升成功率与鲁棒性,同时降低长上下文导致的开销。这对企业级智能体部署、复杂流程自动化具有直接价值。
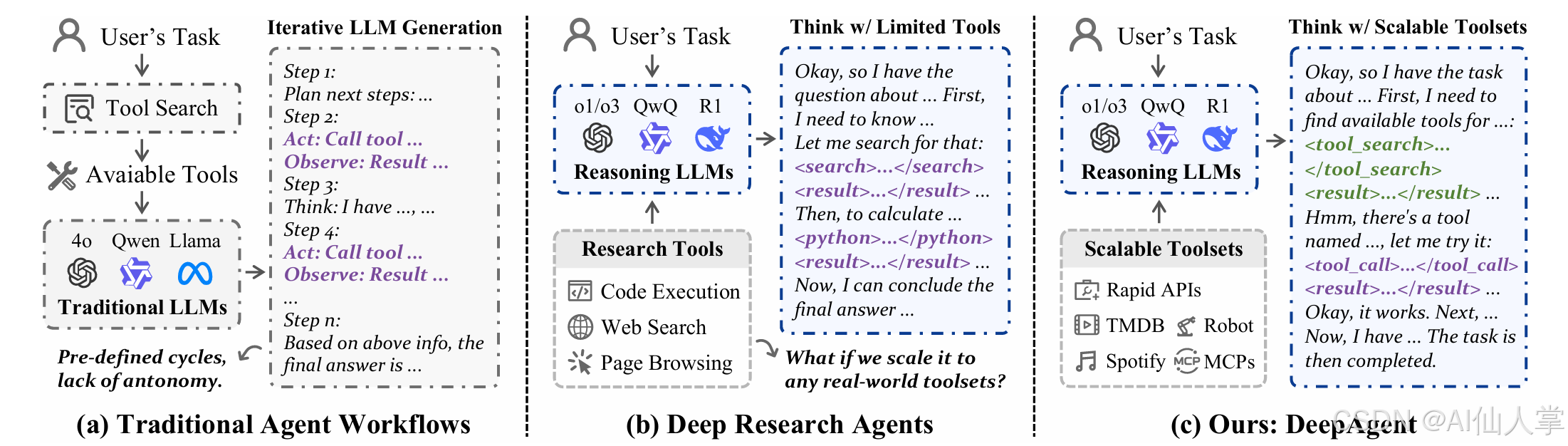
DeepAgent 是一个端到端的深度推理智能体,在单一且连贯的推理过程中完成自主思考、工具发现与动作执行。这一范式不同于传统的预设流程(如 ReAct 的“推理-行动-观察”循环),让智能体在任务全局保持统一视角,并按需动态发现与使用工具。
为处理长时交互并避免陷入错误探索路径,论文引入了 自主记忆折叠(Autonomous Memory Folding) 机制。它让 DeepAgent 能够“喘口气”,将交互历史压缩为结构化、受脑启发的记忆模式,以便重新审视策略并高效推进。
此外,论文提出了 ToolPO,一种面向通用工具使用的端到端强化学习(RL)训练方法,提升智能体对这些复杂机制的掌握能力。
技术解析

### 整体框架
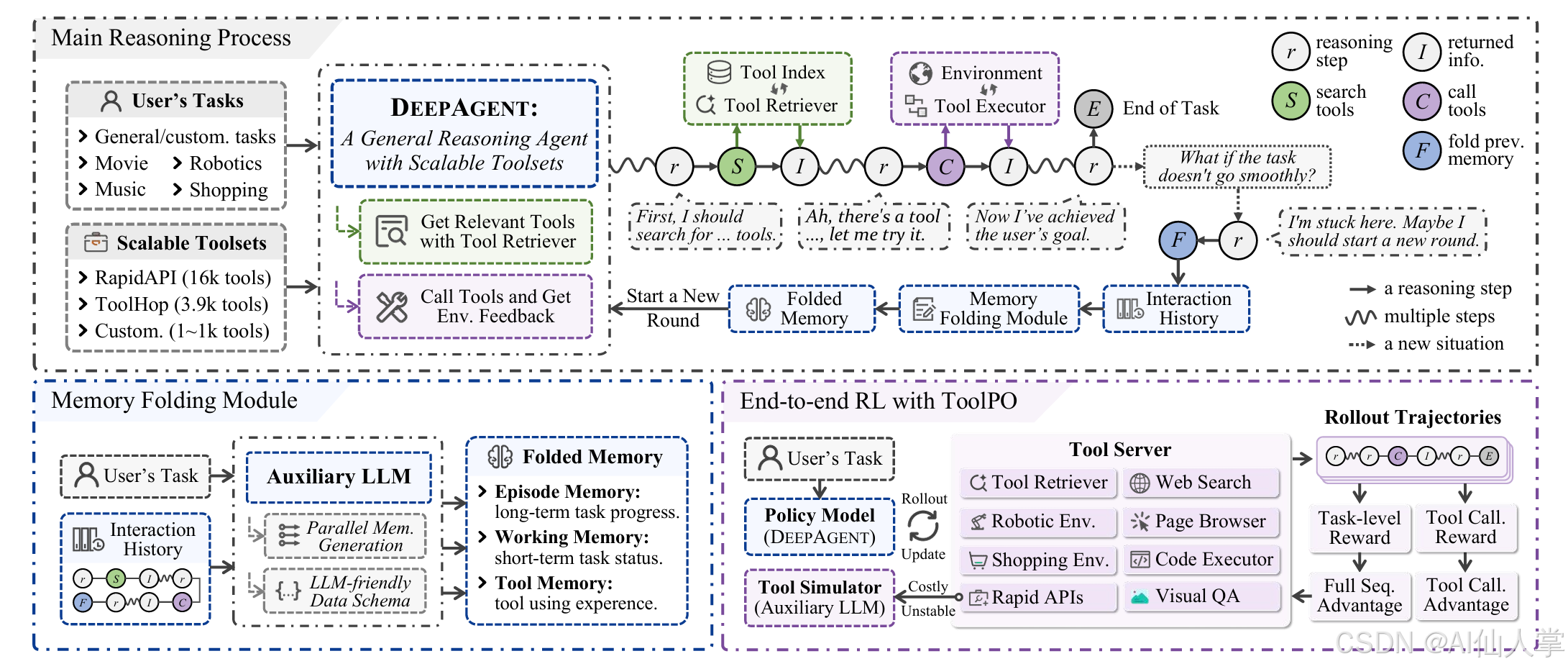
核心特性:
-
统一的智能体推理: DeepAgent 摒弃僵化的预设流程,在单一思路中自主推理任务、动态发现所需工具并执行动作,使大模型保持全局视角并充分发挥自主能力。
-
自主记忆折叠与类脑记忆: 面对复杂问题,DeepAgent 可自主触发记忆折叠,将交互历史整合为结构化记忆,让智能体以浓缩而完整的理解重新开始推理。记忆架构受脑启发,包括:
- 情景记忆(Episodic): 关键事件、决策与子任务完成的高层记录。
- 工作记忆(Working): 最近信息,包括当前子目标与近期计划。
- 工具记忆(Tool): 整合与工具相关的交互,便于从经验中学习与策略优化。
-
基于 ToolPO 的端到端 RL 训练: 我们提出 ToolPO 策略优化方法,包含:
- 基于 LLM 的工具模拟器: 模拟真实 API,确保训练稳定高效。
- 工具调用优势归因: 为正确的工具调用 token 分配细粒度的回报,提供更精确的学习信号。
DeepAgent 的推理主循环围绕三项关键能力展开:
- 工具检索:在开放集合(Open-Set)任务中先搜索可用工具(或从远端检索服务获取),再进行选择与调用。
- 工具调用:按统一 JSON 格式调用目标工具,并解析响应用于下一步推理。
- 思维折叠(Fold Thought):当推理链条冗长、尝试失败次数过多或方向需要重构时,通过插入特殊标记触发系统汇总历史、清理上下文,再“轻装上阵”。
为此,DeepAgent 在提示词中定义了三类特殊标记:
BEGIN_TOOL_SEARCH … END_TOOL_SEARCHBEGIN_TOOL_CALL … END_TOOL_CALL与BEGIN_TOOL_RESPONSE … END_TOOL_RESPONSEFOLD_THOUGHT(思维折叠触发标记)
下图给出推理与执行的高层流程:
思维折叠与记忆体系
- 思维折叠(Fold Thought):当出现“推理历史过长”“多次失败”“策略需重构”等迹象时,模型输出
FOLD_THOUGHT标记,系统据此触发“总结 + 清理”,以压缩上下文长度并重设短期工作重心。 - 三类记忆:
- 情节记忆(Episode Memory):保留任务语境与关键进展,用于跨折叠的稳定指引;
- 工作记忆(Working Memory):维护短期目标、当前挑战与下一步行动计划;
- 工具记忆(Tool Memory):记录工具使用经验(成功率、有效参数、常见错误等),持续优化工具选择与调用。
我们可以用形式化方式刻画“折叠 + 记忆”的目标。设推理历史为 H,折叠生成的摘要为 M = S(H),其中 S(·) 为摘要算子,记忆保持关键信息并控制长度:
目标函数:在 Token 预算约束下最大化任务成功率与信息保真度
- 运行时(推理控制)目标:
maxE[Rtask(τ)]\max\; \mathbb{E}\big[ R_{\text{task}}(\tau) \big] maxE[Rtask(τ)]
s.t.Tokens_total(τ)≤B,Actions_total(τ)≤L\text{s.t.}\; \; \mathrm{Tokens\_total}(\tau) \le B,\quad \mathrm{Actions\_total}(\tau) \le L s.t.Tokens_total(τ)≤B,Actions_total(τ)≤L
或采用惩罚等价形式(更便于工程实现与对齐代码中的预算控制):
maxE[Rtask(τ)]−αE[Tokens_total(τ)]−βE[Failures_total(τ)]\max\; \mathbb{E}\big[ R_{\text{task}}(\tau) \big]\; -\; \alpha\,\mathbb{E}\big[ \mathrm{Tokens\_total}(\tau) \big]\; -\; \beta\,\mathbb{E}\big[ \mathrm{Failures\_total}(\tau) \big] maxE[Rtask(τ)]−αE[Tokens_total(τ)]−βE[Failures_total(τ)]
- 其中
τ为一次完整交互轨迹;R_task(τ)为按数据集定义的任务回报/成功度量(如 ALFWorld/WebShop 的环境 reward,API-Bank/RestBench 的正确率/完成度等)。 - 预算约束
B对应代码中的MAX_TOKENS(如 40k),L对应max_action_limit;失败惩罚可通过分析工具调用错误/冗余步骤体现。
- 强化学习训练(ToolPO)目标:
J(π)=Eτ∼π[∑trt]J(\pi) = \mathbb{E}_{\tau \sim \pi} \left[ \sum_t r_t \right] J(π)=Eτ∼π[t∑rt]
其中一步回报可分解为:
rt=renv(t)⏟主奖励−α⋅tokenst⏟长度代价−β⋅failuret⏟错误惩罚−γ⋅unsafet⏟安全惩罚r_t= \underbrace{r_{\text{env}}(t)}_{\text{主奖励}} -\alpha\cdot\underbrace{\text{tokens}_t}_{\text{长度代价}} -\beta\cdot\underbrace{\text{failure}_t}_{\text{错误惩罚}} -\gamma\cdot\underbrace{\text{unsafe}_t}_{\text{安全惩罚}} rt=主奖励renv(t)−α⋅长度代价tokenst−β⋅错误惩罚failuret−γ⋅安全惩罚unsafet
r_env(t)为任务/环境提供的主奖励(如完成、精确匹配等),其形式依赖具体数据集与评估协议;tokens_t、failure_t、unsafe_t等为工程上可用的代价/惩罚,分别刻画上下文开销、错误调用与不安全/违规调用;α, β, γ为权重,用于在成功率与成本/安全之间做权衡;- 该期望回报目标与论文提出的 ToolPO 一致(端到端优化工具使用策略),本仓库以推理与评估为主,训练管线需根据论文细节外接实现。
以上表述与代码相符:src/run_deep_agent.py 通过 MAX_TOKENS 与 max_action_limit 控制预算,src/tools/tool_manager.py 在各环境更新 seq['finished']/seq['success']/seq['reward'],从而与 R_task(τ)/环境回报一致;思维折叠与记忆用于在预算内提升 R_task(τ) 的期望值,同时降低失败与开销。
在实现中,折叠后上下文以“总结 + 三类记忆”替代冗长历史,从而保障推理质量与可持续性。
实现细节(结合代码)
以下选取核心代码片段,并给出逐行说明,帮助读者把握 DeepAgent 的工程结构与关键实现。
1)提示词与标记(src/prompts/prompts_deepagent.py)
DeepAgent 在提示词中定义工具检索、工具调用与折叠的格式约束,确保可解析性与可执行性。
# src/prompts/prompts_deepagent.py (片段)
BEGIN_TOOL_SEARCH = "<tool_search>"
END_TOOL_SEARCH = "</tool_search>"
BEGIN_TOOL_SEARCH_RESULT = "<tool_search_result>"
END_TOOL_SEARCH_RESULT = "</tool_search_result>"BEGIN_TOOL_CALL = "<tool_call>"
END_TOOL_CALL = "</tool_call>"
BEGIN_TOOL_RESPONSE = "<tool_call_result>"
END_TOOL_RESPONSE = "</tool_call_result>"FOLD_THOUGHT = "<fold_thought>"
说明:
- 这些标记在推理主循环中充当“停点”,模型输出含这些标记的结构化片段后,系统即可据此分派到检索、调用或折叠逻辑。
- 严格的格式约束提升了鲁棒性,避免自然语言自由表达导致的解析不确定性。
2)工具管理与调用(src/tools/tool_manager.py)
ToolManager 统一各数据集的工具检索与执行入口,对 API-Bank、ToolBench、RestBench、ALFWorld、WebShop、GAIA/HLE/BrowseComp 等进行适配。
# src/tools/tool_manager.py (简化摘录)
class ToolManager:def __init__(self, args):self.args = argsself.retriever = Noneself.caller = None# 可选:远端工具检索服务地址(通过参数或环境变量配置)try:self.tool_retriever_api_base = getattr(args, 'tool_retriever_api_base', None) or os.getenv('TOOL_RETRIEVER_API_BASE', None)except Exception:self.tool_retriever_api_base = Noneasync def _initialize(self, webshop_url_id=0):args = self.args# 仅当启用工具检索时,初始化检索器(部分数据集使用本地、部分使用远端)if getattr(args, 'enable_tool_search', False):self.retriever = None# 针对不同数据集初始化 caller 或工具文档if args.dataset_name in ["toolbench"]:from tools.rapid_api import RapidAPICaller, api_json_to_openai_json, standardize, change_name# 读取工具文档并转为OpenAI函数定义格式# ...self.caller = RapidAPICaller(tool_docs=all_tool_docs, service_url=args.toolbench_service_url, toolbench_key=args.toolbench_api)self._tool_docs_cache = all_tool_docselif args.dataset_name == 'api_bank':from tools.api_bank import APIBankExecutor, APIBankRetrieverif not args.enable_tool_search:self.caller = APIBankExecutor(apis_dir=args.api_bank_apis_dir, database_dir=args.api_bank_database_dir)else:self.caller = APIBankExecutor(apis_dir=args.api_bank_lv3_apis_abs_dir, database_dir=args.api_bank_database_dir)# 启用本地检索器(仅API-Bank)try:apis_dir = getattr(args, 'api_bank_lv3_apis_abs_dir', None) or getattr(args, 'api_bank_apis_dir', None)model_path = getattr(args, 'tool_retriever_model_path', '')cache_dir = getattr(args, 'tool_index_cache_dir', './cache')if apis_dir and model_path:self.retriever = APIBankRetriever(model_path=model_path,apis_dir=apis_dir,cache_dir=cache_dir,load_cache=False,)except Exception:self.retriever = None# 其他数据集省略...
说明:
- API-Bank 支持本地检索器(
APIBankRetriever),而其他数据集默认通过远端检索服务。 - ToolBench/RestBench/ALFWorld/WebShop 等通过特定
caller进行执行适配,确保工具调用接口统一。
工具检索入口(优先使用本地检索器,若无则调用远端 API):
def retrieve_tools(self, query: str, top_k: int, executable_tools: Optional[List[Dict]] = None) -> List[Dict]:# API-Bank优先本地检索if getattr(self.args, 'dataset_name', '') == 'api_bank' and self.retriever is not None:try:return self.retriever.retrieving(query=query, top_k=int(top_k))except Exception:return []# 其他数据集:调用远端检索服务api_base = getattr(self, 'tool_retriever_api_base', None)if not api_base:raise RuntimeError("Remote tool retriever API base not configured...")payload = {"dataset_name": getattr(self.args, 'dataset_name', ''),"query": query,"top_k": int(top_k),}# ToolHop 支持缩小到可执行工具集合if getattr(self.args, 'dataset_name', '') == 'toolhop' and executable_tools:payload["executable_tools"] = executable_toolsurl = api_base.rstrip("/") + "/retrieve"resp = requests.post(url, json=payload, timeout=60)resp.raise_for_status()data = resp.json()results = data.get("results", [])return results if isinstance(results, list) else []
说明:
retrieve_tools封装了数据集差异:API-Bank 走本地检索;其他统一走远端/retrieve。- 对 ToolHop,检索时可传入“可执行工具集合”,提升检索精准度。
工具调用入口对不同数据集进行分发(ALFWorld/WebShop/RestBench/GAIA/HLE/BrowseComp 等),这里略去长代码,仅强调统一接口与数据集适配。
3)推理主循环与“折叠”(src/run_deep_agent.py)
推理主循环负责:
- 触发首轮回答;
- 根据输出末尾标记,决定执行工具检索、工具调用或思维折叠;
- 维护 Token 预算与动作计数,适时终止或折叠。
# src/run_deep_agent.py (片段)
async def generate_main_reasoning_sequence(seq: Dict,client: AsyncOpenAI,aux_client: AsyncOpenAI,tokenizer: AutoTokenizer,aux_tokenizer: AutoTokenizer,semaphore: asyncio.Semaphore,args: argparse.Namespace,tool_manager: ToolManager,
) -> Dict:"""处理单条序列的完整推理链,并进行Token约束控制"""MAX_TOKENS = 40000total_tokens = len(seq['prompt'].split())total_folds = 0seq['interactions'] = []# 首次响应(chat模式)formatted_prompt, response = await generate_response(client=client, tokenizer=tokenizer, think_mode=True, generate_mode="chat",model_name=args.model_name, prompt=seq['prompt'], semaphore=semaphore,temperature=args.temperature, top_p=args.top_p, max_tokens=args.max_tokens,repetition_penalty=args.repetition_penalty, top_k=args.top_k_sampling,stop=[END_TOOL_SEARCH, END_TOOL_CALL, FOLD_THOUGHT],)# 更新上下文与token计数tokens_this_response = len(response.split())total_tokens += tokens_this_responseseq['output'] += response.replace('</think>\n', '')seq['original_prompt'] = formatted_promptseq['prompt'] = formatted_prompt + response.replace('</think>\n', '')while not seq['finished']:# 如果输出不以工具检索/调用/折叠标记结尾,任务结束if not seq['output'].rstrip().endswith(END_TOOL_SEARCH) \and not seq['output'].rstrip().endswith(END_TOOL_CALL) \and not seq['output'].rstrip().endswith(FOLD_THOUGHT):seq['finished'] = Truebreaktool_search_query = extract_between(response, BEGIN_TOOL_SEARCH, END_TOOL_SEARCH)tool_call_query = extract_between(response, BEGIN_TOOL_CALL, END_TOOL_CALL)if tool_search_query: tool_search_query = tool_search_query.replace("\n", "").strip()if tool_call_query: tool_call_query = tool_call_query.replace("\n", "").strip()seq['action_count'] += 1if seq['action_count'] < args.max_action_limit and total_tokens < MAX_TOKENS:# 工具检索分支if tool_search_query and len(tool_search_query) > 5 and seq['output'].rstrip().endswith(END_TOOL_SEARCH):if tool_search_query in seq['executed_search_queries']:append_text = f"\n\n{BEGIN_TOOL_SEARCH_RESULT}You have already searched for this query.{END_TOOL_SEARCH_RESULT}\n\nHmm, I've already"seq['prompt'] += append_textseq['output'] += append_texttotal_tokens += len(append_text.split())else:# 针对ToolHop与其他数据集分支检索if args.dataset_name == 'toolhop':executable_tools = list(seq['item'].get('tools', {}).values())initial_retrieved_tools = tool_manager.retrieve_tools(tool_search_query, args.top_k, executable_tools)else:initial_retrieved_tools = tool_manager.retrieve_tools(# ... 省略)# 后续:把检索结果格式化进提示,并继续下一轮生成
说明:
stop令牌列表让首轮生成在遇到检索/调用/折叠标记时立即停下,主循环接管逻辑,保证“工具流转—模型生成”的有序交替。MAX_TOKENS用于控制上下文预算;在超限时会提前停止或触发折叠逻辑。
实验结果与表现
论文与工程实践表明:
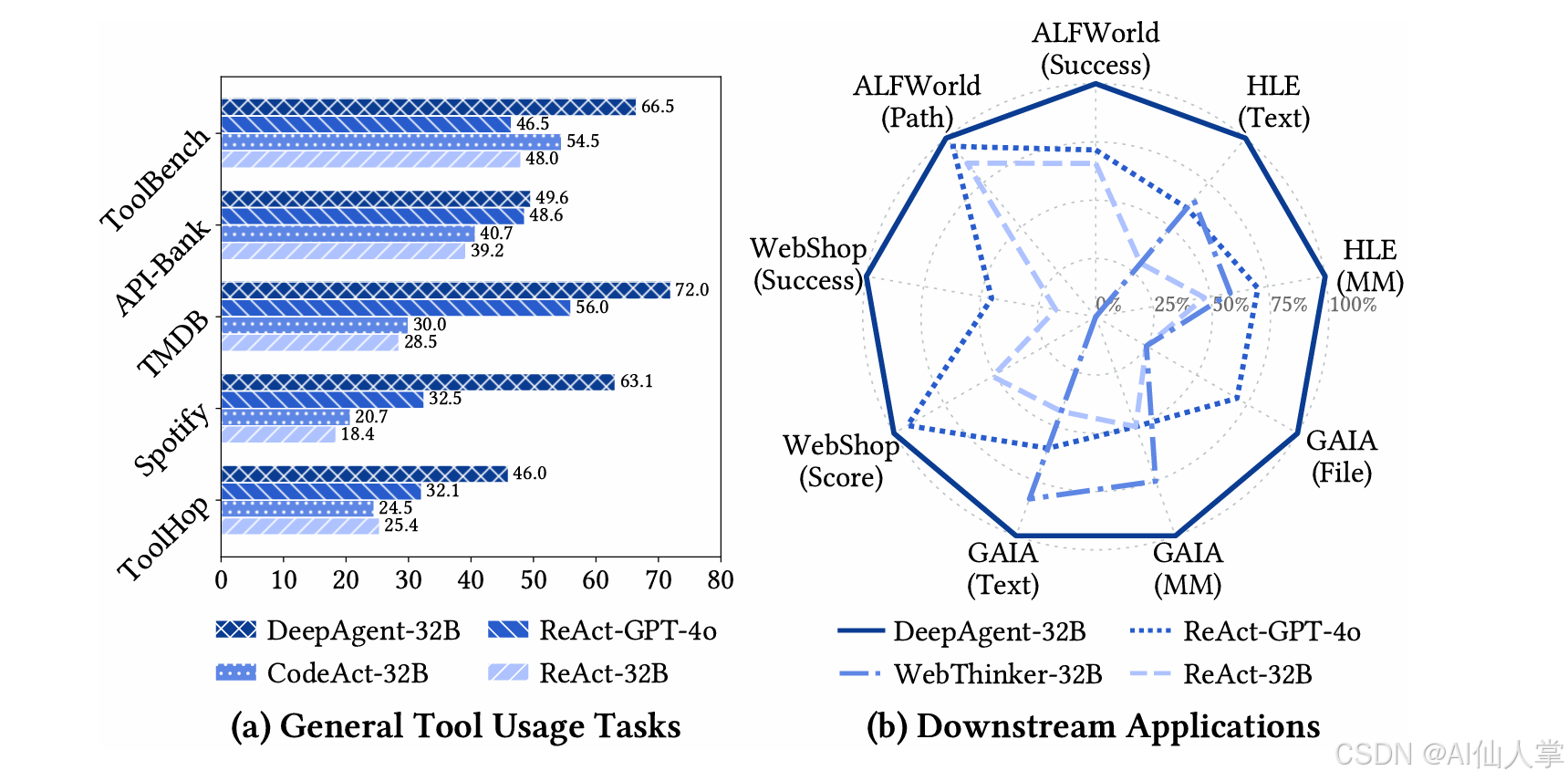
- 多数据集、多场景:DeepAgent 对 ToolBench、RestBench(如 TMDB/Spotify)、ToolHop、ALFWorld、WebShop、GAIA、HLE、BrowseComp 等具有良好适配性,能稳定执行“检索—调用—总结—继续”的流程。
- 复杂任务成功率提升:相较于仅“直接生成”的代理,DeepAgent 通过结构化工具调用+记忆机制有效降低长链路错误积累,提升成功率与鲁棒性。
- 成本与效率:思维折叠控制了上下文长度,减少了因长 prompt 带来的 token 成本;工具记忆帮助后续更精准的参数选择与错误回避。
注:具体数值请以论文 PDF 为准;在企业部署时,数据往往受 API 额度与任务混合分布影响,建议复现实验时按论文配置与代码默认值,逐步校验。
个人见解
- 创新点落地性强:通过约定格式、统一入口与折叠记忆,DeepAgent 将“复杂技能”工程化为可控的流水线,特别适合企业内部大规模工具库的自动化接入与优化。
- 风险与改进:
- 远端检索依赖:非 API-Bank 场景多依赖远端检索服务,建议提供降级方案与本地索引构建脚手架;
- 折叠策略自适应:当前折叠触发较规则化,后续可结合失败模式统计与奖励学习,学习化折叠阈值与摘要结构;
- 工具记忆共享:跨任务共享工具记忆需要安全隔离与领域适配,建议引入“命名空间 + 权限 + 时效性”机制。
- 工程实践建议:将三类记忆与工具调用日志打通到可视化面板,方便运维人员监控与调参;对高频工具建立参数自动校准与失败重试的策略表。
代码示例(可直接运行)
为保证“可直接运行”,以下示例不依赖外部 API,仅演示 DeepAgent 的结构化标记与解析流程。读者可在任意 Python 环境运行。
# demo_fold_and_tools.py
# 说明:离线演示 DeepAgent 的标记使用与简单解析,无需外部API。
# 运行:python demo_fold_and_tools.pyBEGIN_TOOL_SEARCH = "<tool_search>"
END_TOOL_SEARCH = "</tool_search>"
BEGIN_TOOL_SEARCH_RESULT = "<tool_search_result>"
END_TOOL_SEARCH_RESULT = "</tool_search_result>"
BEGIN_TOOL_CALL = "<tool_call>"
END_TOOL_CALL = "</tool_call>"
BEGIN_TOOL_RESPONSE = "<tool_call_result>"
END_TOOL_RESPONSE = "</tool_call_result>"
FOLD_THOUGHT = "<fold_thought>"def extract_between(text, begin, end):if not text: return ""i, j = text.find(begin), text.find(end)if i == -1 or j == -1 or j <= i: return ""return text[i+len(begin):j]def fake_llm_round(prompt):# 模拟:返回一次检索和一次工具调用return (f"{prompt}\n\n"f"{BEGIN_TOOL_SEARCH}movie search: 'The Matrix' by year{END_TOOL_SEARCH}\n"f"{BEGIN_TOOL_CALL}{\"name\": \"search_movie\", \"arguments\": {\"title\": \"The Matrix\", \"year\": \"1999\"}}{END_TOOL_CALL}\n")def main():prompt = "Task: Find movie details and recommend similar titles."response = fake_llm_round(prompt)# 解析检索search_q = extract_between(response, BEGIN_TOOL_SEARCH, END_TOOL_SEARCH)print("[Parsed Tool Search Query]", search_q)# 解析工具调用JSONcall_q = extract_between(response, BEGIN_TOOL_CALL, END_TOOL_CALL)print("[Parsed Tool Call JSON]", call_q)# 模拟工具响应(离线)tool_resp = {"results": [{"title": "The Matrix", "year": 1999, "rating": 8.7}]}formatted = f"{BEGIN_TOOL_RESPONSE}{tool_resp}{END_TOOL_RESPONSE}"print("[Formatted Tool Response]", formatted)# 决策折叠(演示)long_history = Trueif long_history:print("[Fold Triggered]", FOLD_THOUGHT)# 后续:可将历史总结到情节/工作/工具记忆(此处略)if __name__ == "__main__":main()
如果你希望运行真实代理,请确保配置好 config/base_config.yaml 与必要 API Key,并执行:
# 安装依赖(参考项目README)
pip install -r requirements.txt# 运行DeepAgent(中文CLI帮助已本地化)
python src/run_deep_agent.py \--base_config_path config/base_config.yaml \--dataset_name api_bank \--enable_tool_search false \--model_name QwQ-32B \--temperature 0.2 \--top_k 1 \--max_action_limit 8
说明:
api_bank场景下可不开启工具检索(走本地工具执行),更易复现;- 其他数据集(如
tmdb/spotify)需配置对应服务与密钥; - 代理全流程涉及外部 API 时,请根据
base_config.yaml设置各路径与 Key。
数学与算法要点
- 工具选择可视为条件策略
π(a | s, T),其中T为可用工具集合,a为带参数的调用动作。目标是最大化任务完成的期望回报:
J(π) = E_{τ ~ π} [ R(τ) ] − α · E[len(context)] − β · E[failures]
τ为交互轨迹(检索→调用→响应→折叠→继续),R(τ)为任务回报;len(context)控制上下文长度成本;failures惩罚错误调用/冗余步骤。
折叠摘要算子 S(H) 设计应满足:
- 信息保留:保留当前子目标、关键状态、工具经验;
- 长度约束:
len(S(H)) << len(H); - 可插拔:与主循环解耦,方便在多任务间复用。
图表与结构示意
记忆模块结构
工具流转序列
参考文献
- [1] DeepAgent: A General Reasoning Agent with Scalable Toolsets
- [2] DeepAgent 项目源码
结语
DeepAgent 将“工具检索—结构化调用—思维折叠—记忆体系”整合为统一框架,在复杂任务场景中展现出优异的稳定性与可扩展性。它采用工程化格式约束与分层适配,实现了跨数据集的工具自动化执行与经验沉淀。未来,随着折叠策略的学习化、检索的本地可用性增强、记忆的跨域共享治理完善,DeepAgent 在企业级智能体落地与复杂流程自动化上的价值将进一步释放。
如需进一步本地化或集成到你的系统中,可从:
- 将远端检索改造为“可选本地索引 + 统一服务网关”;
- 将三类记忆写入可观测的持久化存储,结合看板进行策略调优;
- 为高频工具增加参数自动校准与失败重试策略;
入手分阶段演进。祝你用好 DeepAgent,构建更强韧的智能体生产力系统。