流匹配动作生成
基于流匹配(Flow Matching)的动作生成
1. 核心思想
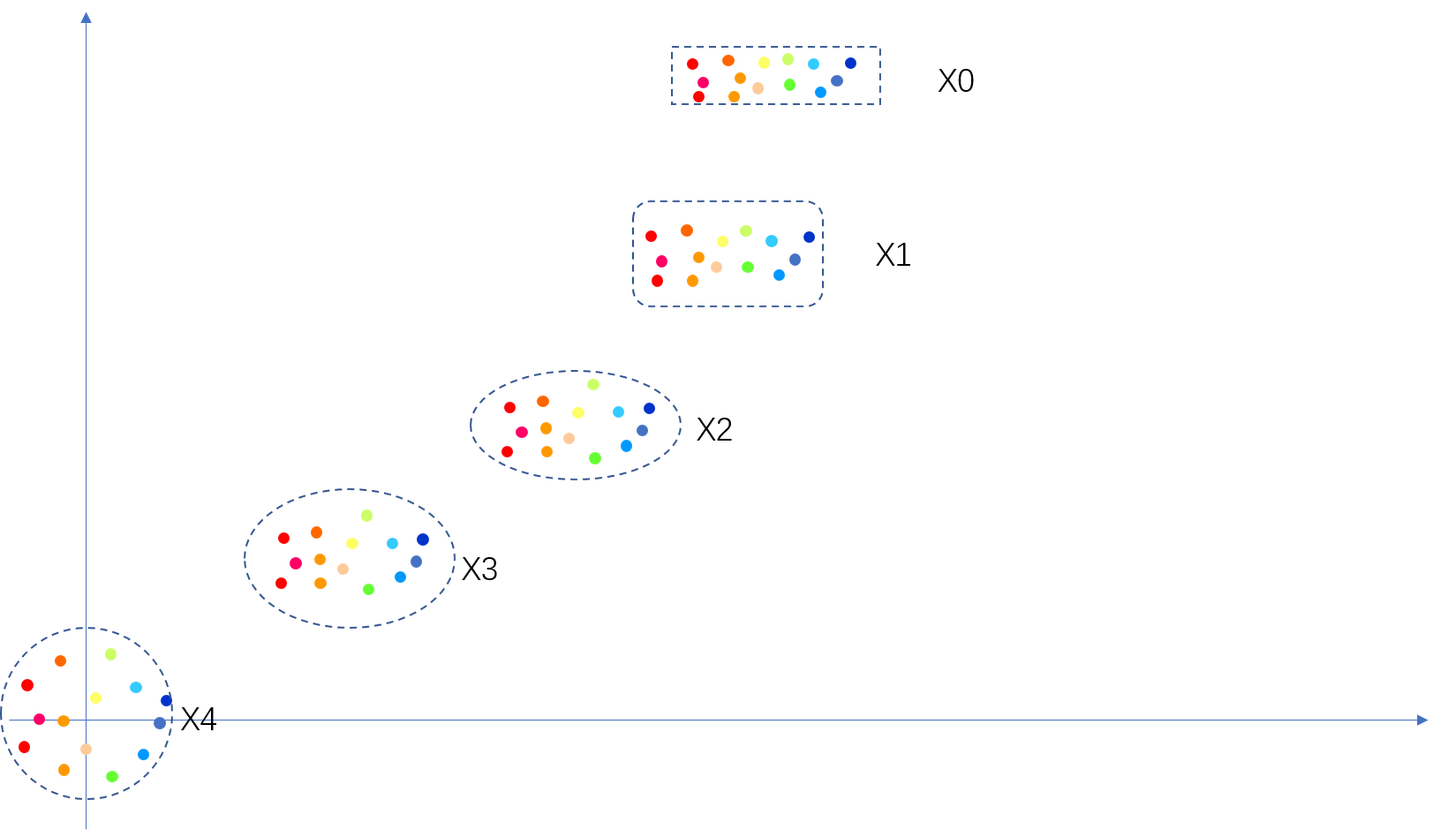
传统的方法(如行为克隆)直接学习一个确定性策略 A=π(o)A = \pi(o)A=π(o) 或一个条件分布 P(A∣o)P(A|o)P(A∣o)。而流匹配方法采用了一种生成式模型的思路,通过一个速度场来刻画从噪声分布到目标动作分布的连续变换过程, 如图中从x4->x0,最上边是动作空间X0,坐标原点是高斯噪声空间X4。
2. 数学框架:定义路径
首先,需要定义一条连接噪声空间和真实动作空间的路径。
-
起点(t=0t=0t=0):一个容易采样的简单分布,通常是标准高斯分布。
- 动作状态:A0∼p0=N(0,I)A^0 \sim p_0 = \mathcal{N}(0, I)A0∼p0=N(0,I)
-
终点(t=1t=1t=1):我们想要得到的真实、复杂的动作分布。
- 动作状态:A1∼pdataA^1 \sim p_{\text{data}}A1∼pdata(即来自专家数据的真实动作块 AAA)
-
路径(0<t<10 < t < 10<t<1):在起点和终点之间,我们定义一条连续的路径。对于任意时间 ttt,都有一个对应的动作状态 AtA^tAt。最简单的是直线路径:
- At=(1−t)⋅A0+t⋅A1A^t = (1 - t) \cdot A^0 + t \cdot A^1At=(1−t)⋅A0+t⋅A1
- 当 t=0t=0t=0 时,A0A^0A0 就是起点噪声
- 当 t=1t=1t=1 时,A1A^1A1 就是终点真实动作
3. 关键概念:速度场(Velocity Field)
速度场 v(At,o,t)v(A^t, o, t)v(At,o,t) 是流匹配方法的核心。
-
直观理解:想象 AtA^tAt 是时刻 ttt 的一个粒子。这个粒子要从噪声 A0A^0A0 运动到目标动作 A1A^1A1。速度场 vvv 就定义了这个粒子在每一个时间点 ttt、每一个位置 AtA^tAt 上,应该朝着哪个方向、以多快的速度运动。
-
数学定义:速度场是路径 AtA^tAt 对时间 ttt 的导数,即瞬时变化率。
- v(At,o,t)=dAtdtv(A^t, o, t) = \frac{dA^t}{dt}v(At,o,t)=dtdAt
对于我们上面定义的直线路径 At=(1−t)A0+tA1A^t = (1-t)A^0 + tA^1At=(1−t)A0+tA1,我们可以计算其速度场:
v(At,o,t)=d[(1−t)A0+tA1]dt=A1−A0v(A^t, o, t) = \frac{d[(1-t)A^0 + tA^1]}{dt} = A^1 - A^0v(At,o,t)=dtd[(1−t)A0+tA1]=A1−A0
这个结果非常重要:它意味着,对于一条已知的、连接 A0A^0A0 和 A1A^1A1 的路径,其真实的速度场就是终点和起点之间的向量差 (A1−A0)(A^1 - A^0)(A1−A0)。
4. 训练目标:学习速度场
在推理时,我们不知道真实的 A1A^1A1(那就是我们要生成的目标)。所以,我们需要一个神经网络 vθv_\thetavθ 来学习逼近这个真实的速度场。
- 训练数据:我们拥有专家数据对 (o,A)(o, A)(o,A),其中 AAA 就是真实的 A1A^1A1
- 训练过程:
- 随机采样一个专家数据对 (o,A)(o, A)(o,A)
- 从高斯分布中采样一个噪声起点 A0∼N(0,I)A^0 \sim \mathcal{N}(0, I)A0∼N(0,I)
- 随机采样一个时间点 t∼Uniform(0,1)t \sim \text{Uniform}(0, 1)t∼Uniform(0,1)
- 根据路径公式(如直线路径)计算 ttt 时刻的中间状态:At=(1−t)A0+t⋅AA^t = (1-t)A^0 + t \cdot AAt=(1−t)A0+t⋅A
- 计算真实的速度场:vtrue=A−A0v_{\text{true}} = A - A^0vtrue=A−A0(根据上面的推导)
- 让神经网络 vθv_\thetavθ,以 (At,o,t)(A^t, o, t)(At,o,t) 为输入,预测速度场 vpred=vθ(At,o,t)v_{\text{pred}} = v_\theta(A^t, o, t)vpred=vθ(At,o,t)
- 最小化预测值与真实值之间的差距(如 L2 损失):
L(θ)=E[∥vθ(At,o,t)−(A−A0)∥2]\mathcal{L}(\theta) = \mathbb{E}[ \| v_\theta(A^t, o, t) - (A - A^0) \|^2 ]L(θ)=E[∥vθ(At,o,t)−(A−A0)∥2]
通过这个简单的损失函数,神经网络学会了在给定观测 ooo 下,如何将任意一个中间状态 AtA^tAt 推向下一个"更接近"真实专家动作 AAA 的状态。
5. 推理(生成)过程:从噪声迭代到动作
训练好网络后,我们就可以进行推理,从噪声"流式"地生成动作:
-
初始化:从高斯分布采样一个随机噪声 A0∼N(0,I)A^0 \sim \mathcal{N}(0, I)A0∼N(0,I)
-
迭代求解(例如使用欧拉法):
-
将时间区间 [0,1][0, 1][0,1] 离散成 NNN 个小步(如 t=0,0.1,0.2,…,1.0t=0, 0.1, 0.2, \ldots, 1.0t=0,0.1,0.2,…,1.0)
-
For k=0k = 0k=0 to N−1N-1N−1:
- 当前时间 tk=k/Nt_k = k / Ntk=k/N,当前状态是 AtkA^{t_k}Atk
- 将 (Atk,o,tk)(A^{t_k}, o, t_k)(Atk,o,tk) 输入神经网络 vθv_\thetavθ,得到预测的速度 vpredv_{\text{pred}}vpred
- 更新状态(向前走一小步):
Atk+1=Atk+1N⋅vpredA^{t_{k+1}} = A^{t_k} + \frac{1}{N} \cdot v_{\text{pred}}Atk+1=Atk+N1⋅vpred
-
End For
-
-
输出:最终的状态 At=1A^{t=1}At=1 就是我们生成的动作 AAA
这个迭代过程,就是沿着学习到的速度场指引的方向,将初始的噪声粒子一步步"流动"到最终符合观测 ooo 的、合理的动作区域。
ref
https://zhuanlan.zhihu.com/p/704226398