Redis黑马点评 Feed流

1.Feed流推拉结合机制
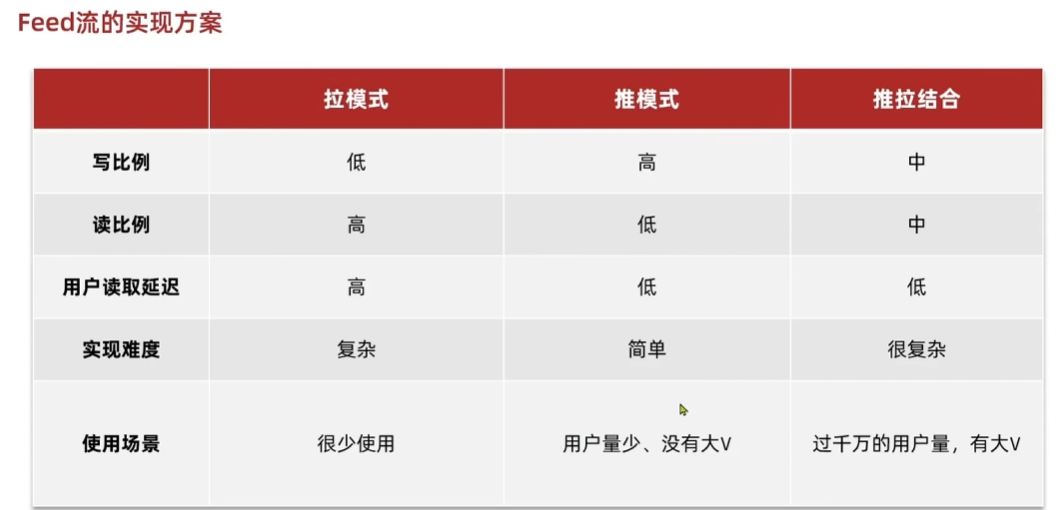
Feed流是一种常见的信息展示方式,用于向用户推送内容更新,如社交媒体动态、新闻更新等。实现Feed流的方案有多种,其中推拉结合模式是一种折中的方案,兼具推和拉两种模式的优点。
推模式(写扩散)
定义:用户发布动态时,系统主动将动态推送到其粉丝的收件箱中。
优点:用户能够实时接收到内容更新,无需手动刷新。
缺点:内存压力大,特别是对于有大量粉丝的用户(大V),需要写入大量数据。
拉模式(读扩散)
定义:用户需要读取动态时,系统从其关注的用户中拉取所有动态,然后进行排序。
优点:节约空间,因为动态只保存在发布者的邮箱中。
缺点:延迟较大,特别是当用户关注了大量的用户时,需要拉取大量内容,对服务器压力较大。
推拉结合模式(读写混合)
定义:结合了推和拉两种模式的优点,是一种折中的方案。
实现方式:
对于普通用户,采用推模式,直接将动态写入其粉丝的收件箱。
对于有大量粉丝的用户(大V),采用拉模式,当粉丝需要读取动态时,再去拉取这些动态。大V的铁粉则继续使用推模式。
优点:
兼具推模式的实时性和拉模式的空间节约。
避免了大V带来的推送压力,同时保证了中小V内容的实时触达。
缺点:实现复杂。
实现逻辑
发布动态:
普通用户发布动态时,直接将动态写入其粉丝的收件箱。
大V发布动态时,对普通粉丝只写入自己的发件箱,不立即推送。铁粉则立即推送。
读取动态:
用户查看Feed流时,先读取自己的收件箱。
如果用户关注了大V,再去拉取大V的发件箱内容。
将收件箱和拉取的内容合并,按时间排序后返回给用户。
性能优化
推送优化:
分级推送:小V内容实时推送,中V内容批量推送。
粉丝分片:对中V采用粉丝分片推送,避免瞬时压力。
拉取优化:
预拉取机制:用户进入Feed流页面时,异步预拉取前几个头部大V的最新内容。
结果缓存:缓存拉模式聚合结果,减少重复计算。
存储优化:
内容分表:按创作者ID哈希分片存储内容表。
历史数据归档:超过一定时间的内容迁移至冷存储。
Controller
@GetMapping("/of/follow")public Result queryBlogOfFollow(@RequestParam("lastId") Long max,@RequestParam(value = "offset",defaultValue = "0")Integer offset){return blogService.queryBlogOfFollow(max,offset);}
@Overridepublic Result saveBlog(Blog blog) {UserDTO user = UserHolder.getUser();blog.setUserId(user.getId());boolean isSuccess = save(blog);if(!isSuccess){return Result.fail("发布笔记失败");}//查询作者所有粉丝//推送笔记Id给所有粉丝List<Follow> follows = followService.query().eq("follow_user_id",user.getId()).list();//返回Idfor(Follow follow : follows){Long userId = follow.getUserId();//4.2推送String key = FEED_KEY + userId;stringRedisTemplate.opsForZSet().add(key,blog.getId().toString(),System.currentTimeMillis());}return Result.ok(blog.getId());}查询
@Overridepublic Result queryBlogOfFollow(Long max, Integer offset) {//1.获取用户Long userId = UserHolder.getUser().getId();//2.查询收件箱String key = FEED_KEY + userId;//3.解析数据:blogId、score时间戳 offsetSet<ZSetOperations.TypedTuple<String>> typedTuples = stringRedisTemplate.opsForZSet().reverseRangeByScoreWithScores(key, 0, max, offset, 3);//4.根据id查询blogif(typedTuples == null || typedTuples.isEmpty()){return Result.ok();}//5.封装返回List<Long> ids = new ArrayList<>(typedTuples.size());long minTime = 0;int os = 1;for(ZSetOperations.TypedTuple<String> tuple:typedTuples){String idStr = tuple.getValue();ids.add(Long.valueOf(idStr));long time = tuple.getScore().longValue();if(time == minTime){os++;}else{minTime = time;os = 1;}}String idStr = StrUtil.join(",",ids);List<Blog> blogs = query().in("id",ids).last("ORDER BY FIELD(id," + idStr + ")").list();for(Blog blog : blogs){//2.查关于blog有关的用户queryBlogUser(blog);//3.查询blog是否点赞isBlogLiked(blog);}ScrollResult r = new ScrollResult();r.setList(blogs);r.setOffset( os);r.setMinTime(minTime);return Result.ok(r);}2.用户签到:
@Overridepublic Result sign(){//1.获取当前用户Long userId = UserHolder.getUser().getId();//2.获取日期LocalDateTime now = LocalDateTime.now();//3.拼接keyString keySuffix = now.format(DateTimeFormatter.ofPattern(":yyyyMM"));String key = USER_SIGN_KEY + userId + keySuffix;//4.获取第几天int dayOfMonth = now.getDayOfMonth();//5.写入Redis set bitstringRedisTemplate.opsForValue().setBit(key,dayOfMonth-1,true);return Result.ok();}
@Overridepublic Result signCount() {//1.获取当前用户Long userId = UserHolder.getUser().getId();//2.获取日期LocalDateTime now = LocalDateTime.now();//3.拼接keyString keySuffix = now.format(DateTimeFormatter.ofPattern(":yyyyMM"));String key = USER_SIGN_KEY + userId + keySuffix;//4.获取第几天int dayOfMonth = now.getDayOfMonth();//5.得到签到记录 十进制数字List<Long> result = stringRedisTemplate.opsForValue().bitField(key, BitFieldSubCommands.create().get(BitFieldSubCommands.BitFieldType.unsigned(dayOfMonth)).valueAt(0));if(result == null || result.isEmpty()){return Result.ok(0);}Long num = result.get(0);if(num == null || num == 0){return Result.ok(0);}//6.循环遍历int count = 0;while (true) {//7.让数字与1做与运算,得到最后一个bit位if ((num & 1) == 0){//为0返回 没签到break;}else {//不为0已签到 计数加一count ++;}//数字右移 继续判断num >>>= 1;}return Result.ok(count);}1. 使用位运算遍历
你的代码中使用了位运算来遍历二进制位,这种方法的优点是性能高且直接操作二进制位。
代码逻辑:
int count = 0;
while (true) {if ((num & 1) == 0) {break;} else {count++;}num >>>= 1;
}优点:
性能高:位运算在 CPU 级别是非常高效的,不需要额外的内存分配。
直接操作二进制位:可以精确地控制每一位的操作,适合这种需要逐位检查的场景。
缺点:
可读性稍差:对于不熟悉位运算的开发者来说,可能需要花一点时间理解代码逻辑。
2. 转字符串遍历
如果你选择将数字转换为字符串,然后逐字符遍历,也可以实现相同的功能,但性能和可读性会有所不同。
示例代码:
int count = 0;
String binaryString = Long.toBinaryString(num);
for (int i = 0; i < binaryString.length(); i++) {if (binaryString.charAt(i) == '1') {count++;} else {break;}
}优点:
可读性好:对于不熟悉位运算的开发者来说,字符串遍历的逻辑更容易理解。
简洁:代码更简洁,逻辑更直观。
缺点:
性能低:字符串操作涉及到更多的内存分配和字符操作,性能不如位运算。
额外内存占用:需要将数字转换为字符串,增加了内存占用。
3.Redis Geo
Redis Geo 是 Redis 提供的一种用于处理地理位置数据的功能模块。它允许用户将地理位置信息存储在 Redis 数据库中,并执行各种与地理位置相关的操作,例如计算两点之间的距离、查找某个位置附近的其他位置等。以下是 Redis Geo 的一些主要功能和使用方法:
1. 数据结构
Redis Geo 使用有序集合(Sorted Set)来存储地理位置信息。每个地理位置由以下三部分组成:
经度(longitude):表示地理位置的经度。
纬度(latitude):表示地理位置的纬度。
成员(member):一个字符串,用于标识该地理位置。
2. 主要命令
Redis Geo 提供了一系列命令来操作地理位置数据,以下是一些常用的命令:
添加地理位置
GEOADD key longitude latitude member [longitude latitude member ...]功能:将一个或多个地理位置添加到指定的键中。
示例
GEOADD locations 116.397428 39.90923 "Beijing" GEOADD locations 121.473701 31.230393 "Shanghai"
计算距离
GEODIST key member1 member2 [unit]功能:计算两个地理位置之间的距离。
单位:单位可以是
m(米)、km(千米)、mi(英里)、ft(英尺)。示例:
GEODIST locations Beijing Shanghai km
查找附近的位置
GEORADIUS key longitude latitude radius [unit] [WITHDIST] [WITHCOORD] [WITHHASH] [COUNT count] [ASC|DESC] [STORE key] [STOREDIST key]功能:查找指定位置周围一定范围内的其他位置。
示例
GEORADIUS locations 116.397428 39.90923 100 km WITHDIST
获取地理位置的坐标
GEOPOS key member [member ...]功能:获取一个或多个地理位置的坐标。
示例
GEOPOS locations Beijing
删除地理位置
ZREM key member [member ...]功能:从有序集合中删除指定的成员。
示例
ZREM locations Beijing
3. 应用场景
Redis Geo 在许多实际场景中非常有用,例如:
位置服务:如地图应用、外卖平台等,可以根据用户的位置查找附近的商家或服务。
社交网络:根据用户的位置推荐附近的朋友或活动。
物流配送:计算配送距离,优化配送路线。
@Overridepublic Result queryShopByType(Integer typeId, Integer current, Double x, Double y) {//1.判断是否根据坐标查询if(x == null || y == null){Page<Shop> page = query().eq("type_id", typeId).page(new Page<>(current, SystemConstants.DEFAULT_PAGE_SIZE));return Result.ok(page.getRecords());}//2.计算分页参数int from = (current - 1) * SystemConstants.DEFAULT_PAGE_SIZE;int end = current * SystemConstants.DEFAULT_PAGE_SIZE;//3.查询redis、按照距离排序分页String key = SHOP_GEO_KEY + typeId;GeoResults<RedisGeoCommands.GeoLocation<String>> results =stringRedisTemplate.opsForGeo().search(key, GeoReference.fromCoordinate(x, y),new Distance(5000),RedisGeoCommands.GeoSearchCommandArgs.newGeoSearchArgs().includeDistance().limit(end));//4.解析idif(results == null ){return Result.ok(Collections.emptyList());}List<GeoResult<RedisGeoCommands.GeoLocation<String>>> list = results.getContent();List<Long> ids = new ArrayList<>(list.size());Map<String,Distance> distanceMap = new HashMap<>(list.size());list.stream().skip(from).forEach(result ->{String shopIdStr = result.getContent().getName();ids.add(Long.valueOf(shopIdStr));Distance distance = result.getDistance();distanceMap.put(shopIdStr,distance);});// 🚨 防止 id 为空if (ids.isEmpty()) {return Result.ok(Collections.emptyList());}//获取店铺idString idStr = StrUtil.join(",", ids);List<Shop> shops = query().in("id",ids).last("ORDER BY FIELD(id," + idStr + ")").list();for(Shop shop : shops){shop.setDistance(distanceMap.get(shop.getId().toString()).getValue());}return Result.ok(shops);}