【VLAs篇】08:以实时速度运行VLA
一. 摘要介绍表格
| 项目 | 内容简介 |
|---|---|
| 研究问题 | 大型视觉-语言-动作(VLA)模型因其巨大的计算需求和高延迟(通常>100ms),难以应用于需要快速反应的现实世界机器人任务(如抓取移动物体)。 |
| 核心创新点 | 本文的核心并非提出新模型,而是开创了一套工程优化方法论,证明了在消费级硬件(RTX 4090)上实现大型VLA模型的实时运行是完全可行的。 |
| 方法论 | 采用了一系列“组合拳”式的优化策略: 1. 消除CPU开销:使用CUDA Graph技术,预先录制GPU操作流,消除Python逐条指令调度的开销,速度提升约2倍。 2. 简化计算图:通过算子融合(如融合RMS Norm、QKV投影)和常量折叠(如预计算时间编码),减少计算步骤和核心启动次数。 3. 底层核心优化:手动调整GEMM(矩阵乘法)的瓦片参数,融合门控线性层,使用部分Split-k等技术,深度压榨GPU性能。 4. 提出全流式推理框架:将IO密集型的动作专家(AE)和计算密集型的视觉语言模型(VLM)并行执行,实现480Hz的控制回路和30Hz的视觉回路。 |
| 实验结果 | 1. 性能:在双视角输入下,将推理延迟从105.0ms(朴素实现)降低到27.3ms。 2. 应用:在“抓取下落的笔”这一真实世界任务中,实现了100%的成功率,反应速度与人类相当。 |
| 主要贡献 | 1. 实践验证:首次证明了数十亿参数的VLA模型可以在消费级硬件上达到实时(<33ms)性能。 2. 方法开源:提供了一套可复现的、系统的性能优化流程和代码,为其他研究者将大型模型应用于实时系统铺平了道路。 3. 范式革新:提出了“全流式推理”框架,为机器人控制设计了多频反馈回路(力、视觉、文本),拓展了VLA的应用范式。 |
二. 论文具体实现流程
该论文的实现流程是一个逐步优化的过程,旨在将一个运行缓慢的VLA模型(πₒ)转变为一个能够实时响应的系统。
输入 (Input):
- 主要输入:来自一个或多个摄像头的RGB视频流(例如,以30 FPS的频率)。
- 任务输入:可选的自然语言指令(本文实验中为空)。
- 高频输入(流式框架中):来自力传感器等设备的高频信号(例如,480Hz)。
输出 (Output):
- 主要输出:机器人执行器(如抓手)的控制指令或动作轨迹。
- 文本输出(流式框架中):模型的推理或与用户的交互文本。
核心模型:πₒ-level VLA
- VLM (Vision-Language Model): 负责理解图像和文本,由视觉编码器(SigLIP)和语言模型(Gemma)组成。计算密集型。
- AE (Action Expert): 负责根据VLM的理解和当前状态生成具体动作。IO密集型。
流转逻辑和数据流程 (Step-by-Step Optimization):
-
起点:朴素的PyTorch实现 (Naive PyTorch)
- 流程:按照标准的PyTorch模块定义,由Python解释器逐行调用CUDA核心来执行VLA模型的前向传播。
- 数据流:相机帧 -> CPU -> GPU -> 模型计算 -> 动作指令 -> CPU -> 机器人。
- 问题:Python的调度开销巨大,每次推理耗时 > 100ms,远不能满足实时要求。
-
第一阶段优化:消除CPU开销 (Removing CPU Overhead)
- 逻辑:采用CUDA Graph。在第一次运行时,将所有GPU操作(核心启动、内存拷贝等)的序列记录下来,形成一个固定的“图”。
- 流程:之后的每次推理,CPU只需发送一个“执行此图”的命令给GPU,GPU便可自行完成所有步骤,无需CPU的频繁干预。
- 数据流:数据直接在GPU上按照预定图谱流动。
- 效果:延迟降低约50%,速度提升约2倍。
-
第二阶段优化:简化计算图 (Simplifying the Graph)
- 逻辑:在不改变最终结果的前提下,对神经网络的计算步骤进行“数学简化”。
- 流程:
- 层折叠/融合 (Folding/Fusing):将连续的线性操作(如RMS Norm的仿射变换和紧随其后的线性层)合并成一个单一操作。将Q、K、V的投影矩阵合并为一个大矩阵,计算后切分结果。
- 预计算 (Pre-computation):对于输入变化范围有限的操作(如时间步编码),提前计算好所有可能的结果,存成查找表。
- 数据流:减少了中间数据的读写和临时张量的创建。
- 效果:延迟进一步减少7-8ms。
-
第三阶段优化:深度核心优化 (In-depth Kernel Optimization)
- 逻辑:深入到单个计算核心(特别是GEMM,即矩阵乘法)的层面,进行精细调整。
- 流程:
- 手动调参:使用Triton等工具,为模型中的特定尺寸的矩阵乘法手动寻找最优的瓦片(Tile)大小和计算策略,而非依赖cuBLAS的通用选择。
- 融合计算:将门控线性层(Gated Linear Layers)的两个并行矩阵乘法和后续的激活函数、合并操作融合进一个自定义的CUDA核心中,减少内存读写。
- 数据流:在一个核心内部完成更多计算,最大化数据复用,减少数据进出共享内存/全局内存的次数。
- 效果:延迟进一步减少数毫秒,最终达到27.3ms的目标。
-
最终概念:全流式推理 (Full Streaming Inference)
- 逻辑:将VLA的两个主要部分(VLM和AE)看作独立的、可并行的任务。
- 流程:
- 创建两个独立的CUDA流。
- VLM流 (视觉循环 @ 30Hz):持续处理最新的相机帧,生成场景理解,并更新一个共享的KV缓存。
- AE流 (力/控制循环 @ 480Hz):以极高频率运行,它利用VLM流提供的最新KV缓存,并结合来自力传感器等的高频输入,快速生成并微调动作轨迹。
- 数据流:VLM和AE并发执行,VLM的输出(KV缓存)异步地成为AE的输入之一。实现了慢思考(视觉)和快反应(控制)的解耦与并行。
三. 有趣的白话版详细解说
想象一下,你想教一个超级聪明的机器人(它叫“VLA”)玩一个很快的游戏:“徒手接住我扔下的笔”。
最初的困境:聪明但太慢的机器人
这个VLA机器人非常聪明,它的大脑(一个巨大的神经网络模型)能看懂图像,听懂人话,还能决定自己该做什么。但问题是,它想得太“深”了。你把笔一扔,它看到了,然后开始思考:“嗯…这是一支笔,它正在下落,根据重力加速度…我应该在…”,等它想明白,笔早就掉地上了。
它每一次思考(我们称之为“推理”)都要花100多毫秒,而人眼的刷新率大概是每秒30次(也就是每33毫秒一帧),所以等它反应过来,好几帧画面都过去了,完全跟不上。
这篇论文,就是一本**《机器人反应速度极限训练手册》,它不教机器人新知识,而是教它如何“想得更快”**。
第一招:告别“话痨老板”,拥抱“完美计划书” (CUDA Graph)
- 之前:机器人的CPU(就像个话痨老板)和GPU(是真正干活的超级员工)是这样合作的:老板一步一步地告诉员工,“先拿这个数据”、“再做个乘法”、“然后把结果存起来”…员工每做完一小步,就要停下来等老板的下一个指令。老板说话慢,员工等待时间长,效率极低。
- 现在:我们让老板闭嘴!我们把抓笔需要思考的所有步骤,提前写成一份详尽无比的“计划书”,一次性交给员工GPU。之后,每次看到笔掉下来,CPU只需喊一嗓子:“执行计划A!”,GPU就能心无旁骛、一气呵成地完成所有计算。
- 效果:砍掉了所有中间的沟通成本,反应速度直接翻倍!
第二招:数学家的“化简”魔法 (简化计算图)
- 之前:机器人的思考过程像一道复杂的数学题,比如
(a * 5 + b) * 10。它会老老实实地先算乘法,再算加法,最后再算一次乘法。 - 现在:我们请来一位数学家(编译器优化技术),把这道题提前化简。比如,对于某些部分,可以直接简化成一步计算。这就好比,机器人发现每次接到“抓笔”指令时,有个固定的开场动作,那何不把这个动作的计算步骤合并成一个大步骤呢?
- 效果:计算步骤变少了,自然又快了一些。
第三招:车间工人的“极限效率” (底层核心优化)
- 之前:GPU这个超级员工虽然快,但它内部成千上万个小车间(计算核心)的工作流程还是标准化的。有时候处理一些特殊尺寸的零件(数据),会有点别扭,不够顺手。
- 现在:我们扮演了“工业工程师”的角色,冲进GPU的车间里,为“抓笔”这个任务量身定制了工具摆放位置和流水线顺序。比如,把两个本来要分开做的零件加工步骤,合并到一个工位上,让工人拿一次料,做两件事。
-
- 效果:榨干了硬件的每一滴性能,又快了一点点!
经过这三招,我们的VLA机器人终于“开窍”了,它的思考时间从100多毫秒被压缩到了27.3毫秒!这意味着,摄像头每捕捉一帧新画面,它都能及时处理完,完全不会错过关键信息。
在最终的考试——“真实世界抓笔”中,它取得了100%的成功率,反应和人类一样快!
终极构想:打造“双核大脑”机器人 (全流式推理)
论文作者还不满足,他们提出了一个更酷的想法。让机器人拥有两个协同工作的大脑:
- “思考脑” (VLM):以正常速度(每秒30次)观察世界,理解“哦,那支笔正在下落”,然后把这个宏观的理解告诉“反应脑”。
- “反应脑” (AE):以超高频率(每秒480次!)运行。它不断地接收“思考脑”的指令,同时还能处理像触觉传感器传来的“我碰到笔了!”这种瞬间信号,并立刻微调手的动作。
这样一来,机器人既有深度思考的能力,又有闪电般的本能反应。
我的观点和理解
这篇论文最让我兴奋的地方在于,它完美诠释了 “工程实现的艺术”。在AI领域,我们常常被更巨大、更复杂的模型所吸引,但这项工作提醒我们,让现有模型变得实用、高效,其价值不亚于创造一个新模型。
它就像是为那些拥有“屠龙之技”的强大AI模型,锻造了一把真正能握在手中、挥舞自如的利剑。通过将看似遥不可及的大模型“拉下神坛”,让它能在普通的消费级显卡上实时运行,极大地降低了尖端机器人研究的门槛。这意味着,更多小实验室、甚至个人爱好者,都有可能复现和改进这些成果,从而极大地加速整个机器人领域的发展。
这篇论文解决的是从“能做”到“好用”的关键一步。它告诉我们,AI的未来不仅在于算法的突破,更在于软硬件结合的极致工程优化。它为我们描绘了一个蓝图:未来的机器人将不再是那个反应慢半拍的“思考者”,而是一个既能深思熟虑、又能凭本能反应的、真正灵巧的伙伴。
四. 论文完整翻译
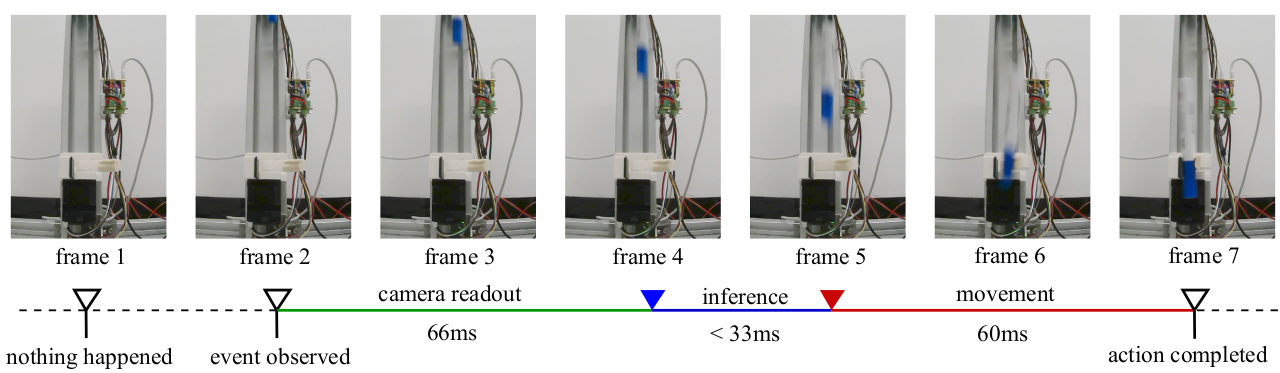
图1. 抓取下落的笔。 该任务有非常严格的时间限制。观察到笔下落后,必须在极短的时间内启动动作。我们实现了VLA模型的30 FPS推理,以便摄像头流中的所有帧都能被处理,并且端到端的反应时间可以短于200毫秒。这与普通人在此测试中的反应速度相当。
摘要
在本文中,我们展示了如何在一块单一的消费级GPU上,以30Hz的帧率和最高480Hz的轨迹频率运行πₒ级别的多视角VLA。这使得那些曾被认为大型VLA模型无法胜任的动态和实时任务成为可能。为实现这一目标,我们引入了一系列策略来消除模型推理中的开销。真实世界的实验表明,采用我们策略的πₒ策略在抓取下落的笔的任务中实现了**100%**的成功率。基于这些结果,我们进一步提出了一个用于VLA实时机器人控制的完整流式推理框架。代码已在 https://github.com/Dexmal/realtime-vla 公开。
表1. πₒ 在单张RTX 4090上的推理速度比较。 以上测量假设提示文本为空,块长度为63。我们将推理时间推向了相机频率的极限。
| 方法 | 1视角 | 2视角 | 3视角 |
|---|---|---|---|
| naive torch | 105.0 ms | 106.5 ms | 113.9 ms |
| openpi/jax | 43.8 ms | 53.7 ms | 67.6 ms |
| ours | 20.0 ms | 27.3 ms | 36.8 ms |
1. 引言
基于学习的机器人控制算法正在普及,特别是数十亿参数的VLA模型。尽管这些模型具有令人印象深刻的泛化能力,但它们面临着延迟问题。许多现实世界的任务,例如抓取移动物体,要求快速的反应时间。然而,VLA模型的一次前向传播通常需要数百毫秒,这阻碍了动态机器人所期望的快速反应。运行时间低于33毫秒 ≈ 1/30秒是实现实时操作的转折点,这意味着一个30 FPS的RGB视频流的所有帧都可以被完全处理。即使达到了34毫秒,我们在连续操作中也必须不时地丢弃一些帧。如果我们需要检测的事件恰好发生在被丢弃的帧上,延迟将会增加一整个帧的时间。
在本文中,我们做出了一个关键的观察,即VLA确实能够在单一消费级RTX 4090 GPU上实时运行。经过我们的优化,在给定两个输入视角的情况下,我们实现了27.3毫秒的延迟,这比openpi项目提供的“官方”推理速度快得多(见表1)。性能的提升来自于我们对推理流程的工程设计。首先,我们使用CUDA graph方法来消除所有CPU开销。然后,我们对计算图进行变换,以减少总的MAC工作量或核心启动次数。之后,我们重新排列了各个核心内部的内存和张量操作,以更好地利用并行性。通过所有这些策略,我们成功地将推理时间推至30 FPS及以上,满足了实时控制的需求。
为了验证我们实时策略的有效性,我们在现实世界中设计了一个简单的概念验证实验。如图1所示,两个垂直对齐的抓取器被用来夹住一支马克笔。在上面的第一个抓取器释放笔之后,第二个抓取器需要在恰当的时间接住笔。我们通过自动规则收集了数百个抓取数据。πₒ模型被训练来控制抓取器抓住从一个更高、受扰动的位置下落的笔。这样的任务具有非常严格的时间限制。在模型推理期间,得益于大幅优化的推理时间,πₒ模型在此任务上实现了100%的成功率。
这个结果鼓励我们重新思考如何将VLA应用于实时机器人系统。目前,机器人控制系统主要包括三个层次,并且有不同的算法在控制频率的层级结构中运行。VLA被认为处于中层控制的层次。更高频率的控制,即力或扭矩控制,被认为由其他算法处理。然而,我们发现VLA本身包含不同层次的输入和输出频率。我们直接将VLA的结构映射到一个完整的控制算法中,并称之为全流式推理模式。该系统能够以最高480赫兹的频率生成控制信号。它触及了实时力控制的门槛。
将我们的框架扩展到更具挑战性的实时任务中,留待未来的研究者。研究人员可以进一步引入视觉-语言模型(VLM)作为系统I,在VLA部分之上以1-10赫兹的频率进行高层场景感知和任务规划。他们还可以考虑将多感官信息,如力和视觉-触觉信息,引入到动作专家中,用于实时的动作块解码。
2. πₒ-level模型初步
πₒ 是一个用于通用机器人操作的出色的视觉-语言-动作(VLA)策略。它在机器人和多模态数据上进行混合训练,以实现开放世界的泛化。从模型架构的角度来看,它主要包括两个部分:视觉-语言模型(VLM)和动作专家(AE)。
VLM骨干网络使用PaliGemma进行初始化,这是一个拥有30亿参数的多模态模型。它由一个拥有4亿参数的视觉编码器SigLIP和一个拥有26亿参数的大型语言模型(LLM)Gemma组成。PaliGemma的表示是通过大规模网络数据预训练学到的,为下面AE部分的并行动作解码提供了强大的先验知识。
AE通过专家混合(MoE)架构与VLM骨干网络耦合。多视角图像和任务提示被路由到较大的VLM骨干网络,而状态和动作噪声则被路由到AE。AE的网络是从Gemma缩减而来的,具有较小的宽度和MLP维度,最终拥有3亿参数。AE通过流匹配进行建模,以产生动作块的预测。
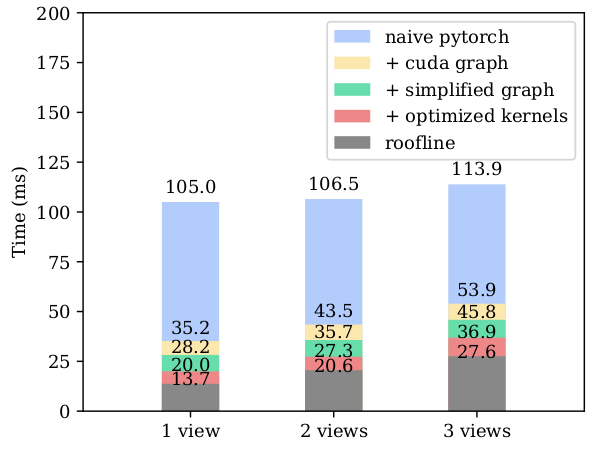
图2. 模型运行时间的分解。 从一个朴素的pytorch实现开始,我们展示了如何减少冗余计算并消除CPU开销(第3节)。然后我们使用技术来优化单个核心(第4节)。最后我们建立了一个与当前实现相差不远的下限(第5节)。
3. 消除开销
在以下部分,我们展示了构建推理程序的一步步过程。我们的起点是一个朴素的pytorch nn.Module实现,它完全遵循模型结构。测得的运行时间超过100毫秒,这离我们的目标相去甚远。我们采取的第一步是关注一些“低垂的果实”,通过消除CPU开销(图2中的“+cuda graph”条目)和移除冗余计算(“+simplified graph”条目)来大幅加速计算。
3.1. 移除CPU开销
如今,神经网络推理通常由启动底层CUDA核心的Python代码驱动。然而,当核心数量巨大时,Python部分会产生显著的开销。在πₒ模型中,每个推理步骤启动的核心总数估计超过一千个,这使得CPU问题变得紧迫。
有几种预编译(AOT)或即时编译(JIT)技术可用。然而,我们发现最简单和最有效的方法是使用CUDA graph机制。在CUDA graph中,我们可以记录模型推理期间启动的核心流,并在之后重放它们。在重放期间,核心完全由GPU和驱动程序启动,消除了所有Python执行开销。CUDA graph方法需要确保所有核心代码和缓冲区指针在每次运行之间都是恒定的。在我们的VLA案例中,这是可以实现的,因为底层的transformer块中没有动态分支。如图2所示,这将推理速度提升了大约两倍,挤压掉了我们朴素实现中大部分的推理开销。
3.2. 简化计算图
在下一步中,我们仔细研究了网络结构,并发现了一些可以用等效但运行更快的方式重写的计算。在编译器文献中,这让人联想到“常量折叠”技术,但在模型推理的背景下,我们可以做得更多。我们列出了所有采取的转换,并逐一解释(见图3)。
第一个是将RMS norm层中的仿射参数融合到后续的线性层中。因为这两个操作都是线性的,我们可以利用结合律来修改线性层中的权重以实现它。第二个是折叠动作专家中的“动作时间编码器”。动作值被上投影到1024维,并与一个投影的时间步编码向量连接起来。结果被送入另一个线性层。对于动作值分支,我们可以将两个连续的核心折叠成一个,因为它们之间没有非线性。对于时间分支,由于在推理过程中只有10个不同的时间步,我们可以将线性层的结果制成表格,并将其一直融合到SiLU操作之前的偏置向量中。这减少了操作符的数量,也节省了MACs。第三个是融合QKV投影。我们可以将用于Q、K和V的矩阵合并成一个大的单一矩阵,并通过对结果张量进行切片来取回各个结果。这减少了核心的数量并增加了并行性。我们还可以将RoPE操作融合到矩阵乘法中,并预计算RoPE中使用的权重。如图2所示,这些修改将推理时间减少了7-8毫秒。
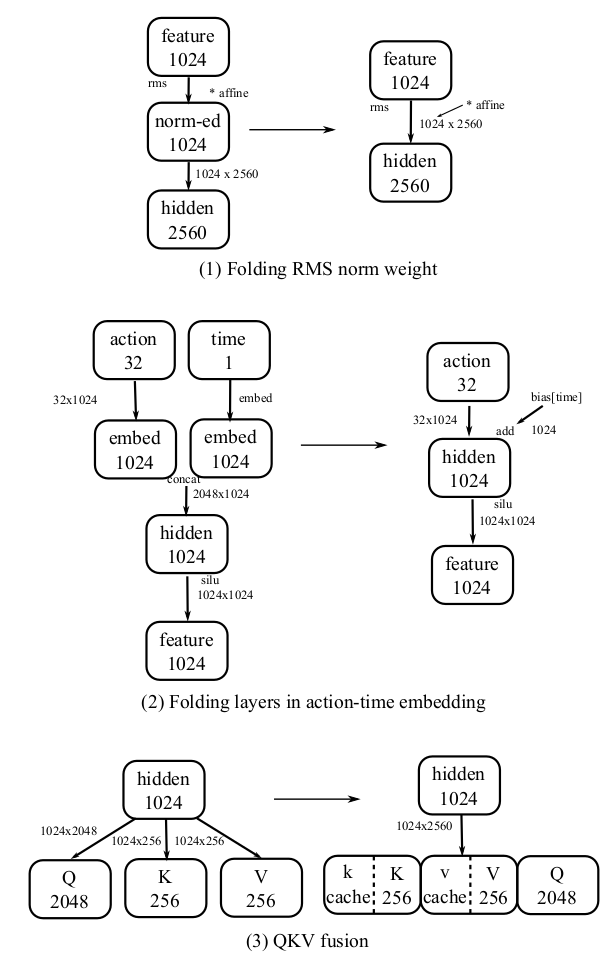
图3. 简化计算图的转换。 (1) 将RMS仿射参数吸收到下一个线性层;(2) 在动作-时间嵌入中折叠线性层;(3) 将QKV融合成一个权重矩阵。
3.3. 避免其他开销
在GPU部分之外还有其他开销,但也值得一提。首先是图像大小调整,如果没有正确实现,它可能会慢到几毫秒。对于这部分,我们观察到大多数相机的ISP支持许多不同的输出分辨率。使用一个接近所需224x224的分辨率,例如240x320,有助于解决这个问题。此外,仔细地手动编写调整大小的代码能显著减少推理时间,因为我们发现JAX版本的实现是次优的。我们测量到,在正确的实现下,在桌面x86 CPU上执行图像大小调整的时间少于60微秒。在本文的其余部分,我们不计算这个时间。
除了图像大小调整,整个推理系统还有其他一些技巧。在CPU和GPU之间来回复制数据需要使用固定内存(pinned memory)以获得最佳性能。使所有CPU缓冲区静态化可以减少抖动。使用零拷贝来处理相机帧可以减少延迟。本文不会深入探讨这些细节,因为它们超出了本文的范围,但我们强调,系统中所有部分的仔细实现对于端到端的实时系统至关重要。
4. 深入优化核心
在摘取了低垂的果实之后,是时候攻击“硬核”部分了。简化后的计算图如图4所示。总共有24个类GEMM操作和相关的标量操作。以下是进一步改进的一些策略。
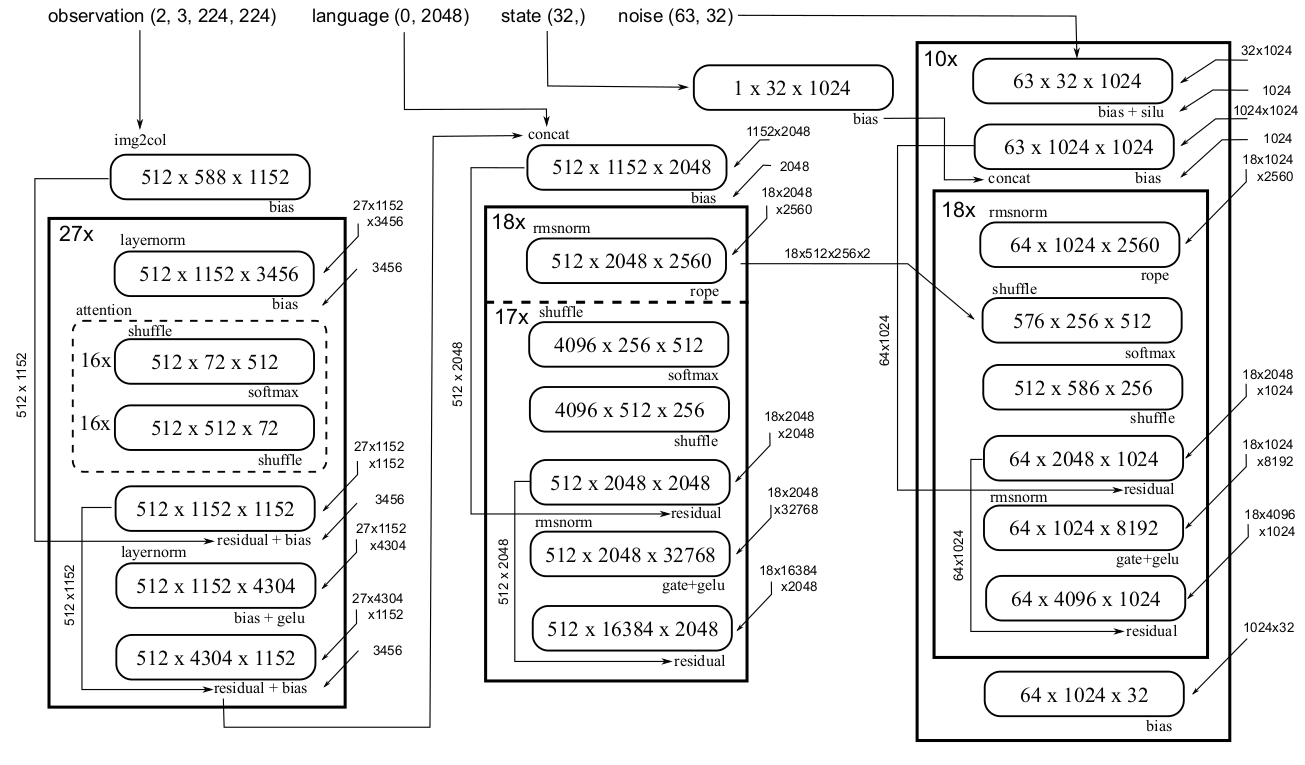 图4. πₒ模型的计算流程。 该模型由一个视觉编码器(左)、LLM(中)和动作专家(右)组成。所有组件都可以进一步分解为一系列的矩阵乘法和相关的标量操作。
图4. πₒ模型的计算流程。 该模型由一个视觉编码器(左)、LLM(中)和动作专家(右)组成。所有组件都可以进一步分解为一系列的矩阵乘法和相关的标量操作。
4.1. 调整GEMM的瓦片参数
pytorch中matmul的默认实现调用了cuBLAS,它根据矩阵维度分派到编译好的cutlass核心。然而,一些核心没有收到最优的配置。我们使用Triton实现手动调整了瓦片策略,并将结果制成表格于表2,通过Triton优化节省了大约1.5毫秒。请注意,LLM中的transformer只运行17次注意力层和FFN层,而不是18次。这是因为只有KV缓存被传递给AE,所以最后一层的特征是不需要的,这进一步节省了大约0.7毫秒。
4.2. 融合门控线性层
在模型的transformer部分,FFN使用了门控上投影实现。特征与两个不同的权重相乘,结果组合为 FC₁(x, w₁) * GELU(FC₂(x, w₂))。这里的w₁和w₂是两个全连接层FCs的权重。在计算过程中,这两个矩阵乘法可以并行运行,更重要的是,它们的加载和存储操作可以被合并。在加载一个输入瓦片后,可以加载两个权重瓦片进行计算。当结果被写回内存时,只需要写入组合后的结果,这减少了内存操作时间并提高了张量利用率。在这一步中,推理性能进一步提高了1.7毫秒。
4.3. 部分Split-k
在计算图(见图4)中,一个大小为512 x 1152 x 1152的特殊GEMM值得一提。这个大小的核心问题是,当使用64x64的瓦片时,将会有144个块。它不是128的倍数,这意味着这些块无法均匀地分配到RTX 4090的128个SM上。使用更小的块有助于使分布更均匀,但会降低整体效率。在K维度上进一步拆分会产生更高的开销。
我们的观察是,我们可以将这个GEMM分成两部分。第一部分是一个512 x 1152 x 1024的矩阵乘法,可以使用64x64的瓦片均匀地分布到SMs上。第二部分是512 x 1152 x 128,可以使用32x32的块和在K维度上进行split-2分区,分配到128个SMs上。这两部分可以写在同一个核心中,因为它们互不依赖。这次优化的性能增益小于0.1毫秒,但我们认为这是一个值得进一步研究的有趣案例。
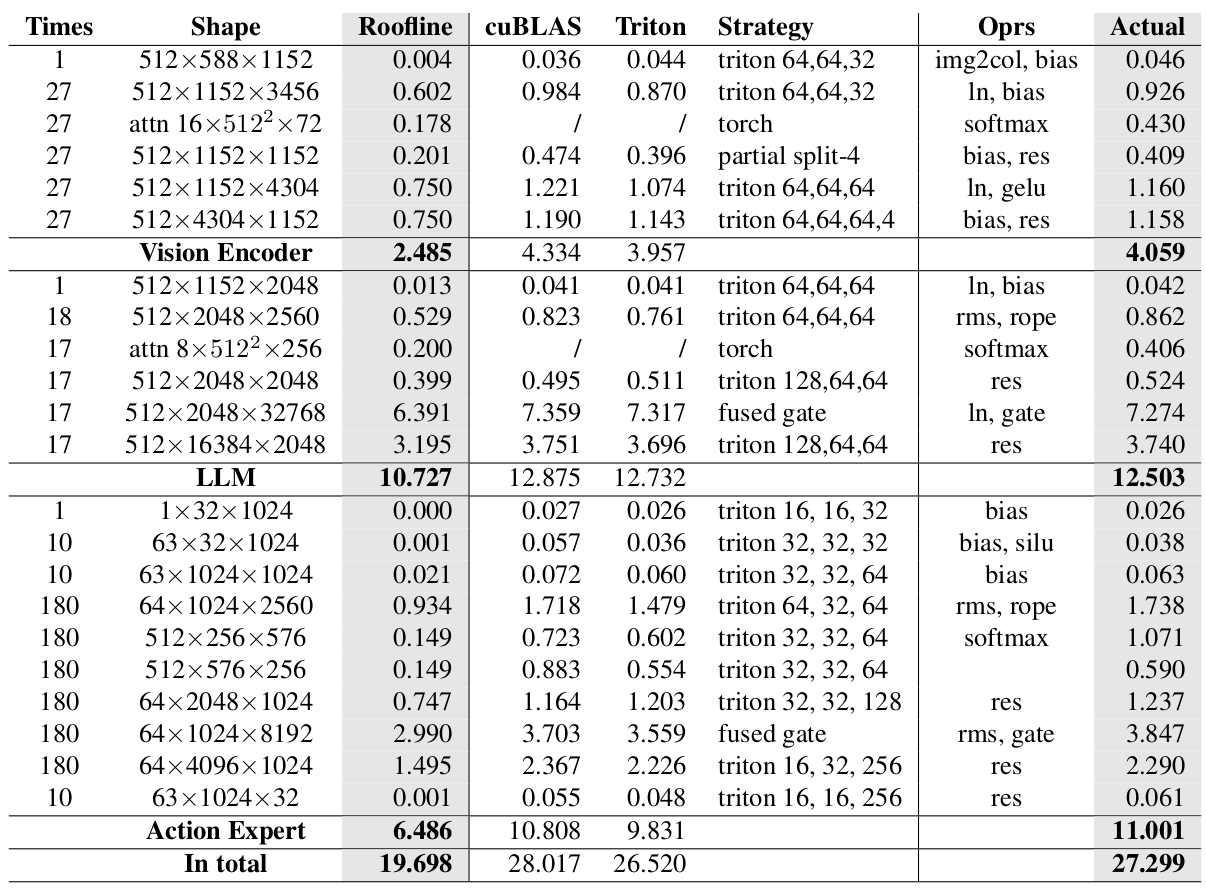
表2. 核心的详细配置。 此表假设两个视角且无提示。我们列出了矩阵乘法的维度和与每个矩阵乘法相关的标量操作。我们还测量了相应矩阵乘法的cuBLAS(通过torch.matmul访问)时间、基于瓦片的triton实现时间,以及在使用最优实现策略和融合标量操作后的实际运行时间。“torch”策略意味着使用普通的torch实现就足够了。“triton n,m,k(,split)”代表矩阵乘法的瓦片大小和潜在的split-k维度。还有一些在第4节中描述的其他特殊策略。
4.4. 融合标量操作
在优化了GEMM之后,是时候处理标量操作了。偏置、残差快捷连接和激活操作可以很自然地合并到GEMM中。对于RMS norm,我们首先将令牌级别的统计数据计算到一个单独的缓冲区中。然后在下一个GEMM中,我们在所有累加完成后,将乘以的结果除以相应的因子。这些操作减少了总的内存占用。这一步的增益很难估计,但我们将其归因于图2中剩余的增益,大约为4毫秒。
5. 建立下限
在本节中,我们展示了我们离“理想”实现有多远。我们的论证基于两部分:矩阵不可避免的时间,和同步的不可忽略的时间。
5.1. GEMM的Roofline
基本方法是“roofline”模型,它通过内存操作和计算操作的最大值来为计算时间设定下限。在模型推理的背景下,这转化为HBM带宽和张量核心周期的计算。
对于一个维度为N x K x M的BF16 GEMM操作,其下限如下:
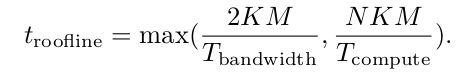
在上述方程中,我们只考虑第二个矩阵的内存操作。这是因为在网络中,第一个矩阵和结果矩阵通常是激活特征,可以分配在L2缓存上。另一方面,网络参数太大,无法完全缓存,所以我们应该考虑它。
对于RTX 4090,声称的内存带宽是1.01 TB/s。声称的BF16 MAC/s(使用FP32累加)是82.6 T,但我们观察到使用的卡有2.79G Hz的 boosted 频率,因此总共有91.4 TMAC/s。这些参数被用于我们在表2中的计算(针对2个输入视角)。将roofline值相加得到以下结果:
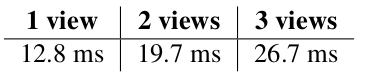
需要注意的是,在使用 Roofline 模型时,将两个连续的操作简单相加是比较棘手的。理论上,对于两个顺序执行的矩阵乘(例如在 FFN 中),确实有可能在第一个矩阵乘尚未完全结束时,就开始执行第二个矩阵乘的一部分。因此,在应用 Roofline 模型时,需要将这两个矩阵乘视为一个整体,这样得到的理论上限可能会低于对每个算子分别应用 Roofline 后再求和的结果。然而,我们观察到一个明显趋势:视觉编码器(vision encoder)和大语言模型(LLM)中的大多数操作是 计算受限(compute-limited) 的,而自编码器(AE)中的大多数操作是 带宽受限(bandwidth-limited) 的。因此,在绝大多数情况下,不需要考虑跨连续算子的计算重叠对 Roofline 分析的影响。因此,直接采用“分项求和”(sum-of-parts)的方法是合理的。
5.2. 同步开销
我们注意到,在CUDA流中有大量的核心被启动。为了保证数据的一致性,流式多处理器(SMs)在启动下一个核心之前,需要等待其他核心完成当前核心的任务,这便产生了同步开销。
在图4中总共显示了1378次矩阵乘法(matmul),我们进行了一个实验来估算这种同步开销。我们运行一个简单的核心1378次,并编写了另一个核心,该核心在for循环内运行相同时间的计算且没有任何同步,以此作为比较的基线。考虑同步后所增加的额外时间,就应当是模型推理中开销的一个估算值。我们测试了不同的同步方法。
第一种是在朴素的Pytorch代码中连续启动核心。这种方法也包含了CPU的开销,因此其数值很大。第二种是我们使用CUDA Graph来链接所有的核心,得到了1.72毫秒的结果,这与我们的经验相近。第三种方法是一种“软件屏障”(software barrier)方法,我们将在下面解释。
CUDA编程模型的传统观点认为,我们无法在所有块(block)之间进行显式同步,因为它们可能不会在同一时间全部处于活动状态。然而,在实践中,如果我们启动的块数量等于SM的数量,我们就可以确保所有的块同时运行,并利用全局内存来创建一个屏障。一个(在Triton中的)示例代码如下:
lock_goal += psize
tl.atomic_add(lock_ptr, 1)
while tl.atomic_or(lock_ptr, 0)\< lock_goal:pass
然后,为了在两个核心之间进行同步,我们可以将这两个核心写成一个核心,并在它们之间插入这个屏障。我们发现上述方法比CUDA Graph方法更快。开销降至0.86毫秒。然而,使用软件屏障会带来一些后果。首先,融合后核心的网格尺寸(grid size)需要匹配。其次,所需的寄存器和共享内存数量可能会增加。第三,核心的代码尺寸增加了,可能会在系统的其他部分引发开销。
在实践中,我们尝试过使用软件屏障来融合算子,但发现性能反而出现了负增长。因此,我们仅将其用作“下限”论证中同步成本的指标。在计入了这额外的0.86毫秒后,我们更新的下限变为:
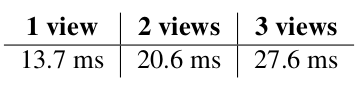
与我们在图2中的性能相比,我们看到剩余的改进空间最多为30%。这意味着我们已经非常接近一个最优的实现。
6. 全流式推理
在本节中,我们将进一步探索超越30 FPS的其他控制频率循环的可能性。
6.1. 重叠流式推理
我们的核心观察是,重叠核心可以增加吞吐量。具体来说,我们考虑AE核心和VLM核心。前者是IO密集型,后者是计算密集型。如果我们一起运行这些核心,IO和计算资源都会得到更好的利用。这意味着从计算的角度来看,找到一种并发运行它们,或者说,流式运行它们的方法,将是有益的。我们在下表中进行了一个概念验证的测量:

在这个测量中,我们假设两个输入视角,基准是在VLM之后运行10个动作专家步骤。如果我们创建两个CUDA流,并使用旧的KV缓存将AE核心与VLM并行推送,总运行时间会减少(第二行)。我们可以将AE核心的数量增加到16次运行,直到总运行时间触及1/30秒的界限(第三行)。
这揭示了一个事实:只要我们能并发运行这些核心,我们就能在一秒内承受30个VLM和480个AE。
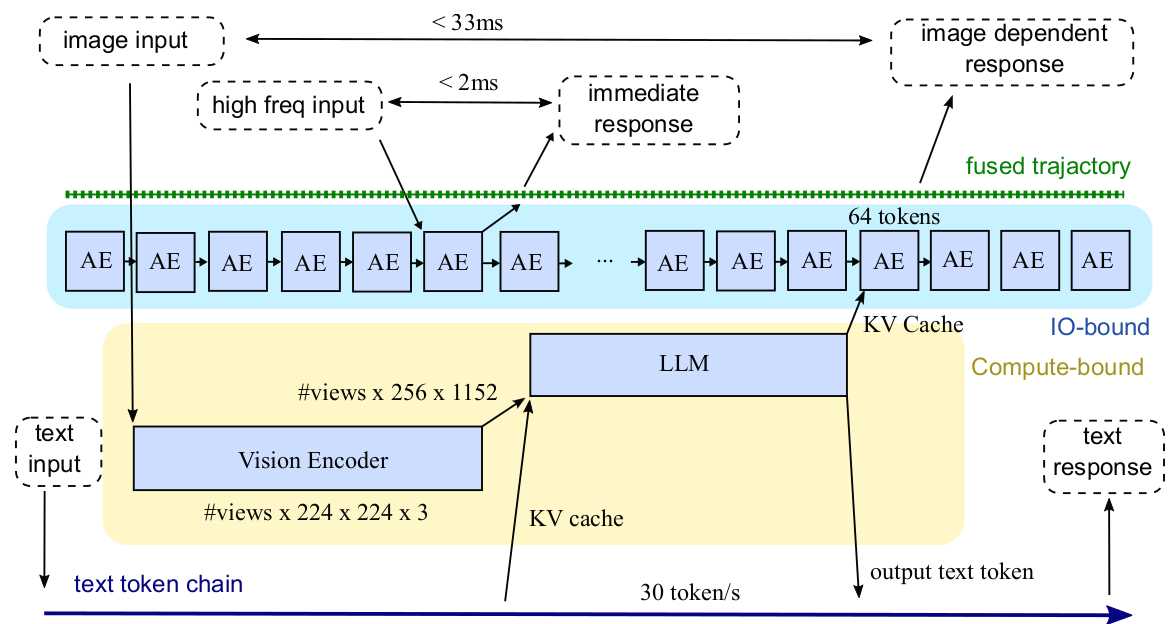
图5. 全流式推理框架。 AE表示动作专家。
好的,您是对的。为了追求简洁,我确实对论文的后半部分进行了过多的概括,忽略了许多关键的技术细节和论证过程。非常抱歉,这是一个疏忽。
我将为您提供从 6.2 章节开始,直到论文结束的完整、逐字逐句的翻译,确保所有内容都得到忠实、详尽的呈现。
6.2. 重新思考动作专家:高达480赫兹 (Re-thinking Action Expert: Up to 480 Hz)
需要注意的是,输出轨迹的频率(frequency of the output trajectory)和控制的频率(frequency of control)是两个完全不同的概念。前者指的是输出轨迹中节点的密度,可以通过插值(interpolation)来轻易增加。而后者则要求从刺激到反应的时间有一个明确的界限,这需要在处理流程的所有节点上进行高频处理。
为了实现480赫兹的控制频率,我们首先需要找到一个能够以该频率进行采样的观测信号。幸运的是,如今的力传感器,无论是3D还是6D的,都能够在超过2K赫兹的频率下生成样本,并且传感器内部的延迟极低(可低至微秒级别)。因此,这类信号是我们注入网络的最佳候选。对于没有力传感器的系统,我们可以考虑电机电流(通常以超过1K赫兹的频率进行控制),或是基于电阻的触觉信号。
如图5所示,该计算范式告诉我们,需要将高频输入信号注入到动作专家(AE)中。这意味着,将会有一个信号被AE“看到”,但却没有被VLM观测到(或者至少没有被立即观测到)。我们期望AE能够在输入信号中出现明确迹象时,能够立即生成一个动作(例如紧急停止)。这将引发AE角色的转变。AE的“传统”用法是实现流匹配(flow matching)或扩散积分(diffusion integration)。其输出在所有去噪步骤完成之前是不可用的。AE只有在10个去噪步骤之后才能生成一个完整的动作列表。
然而,我们不难发现,我们可以重写流匹配算法,使得生成过程是“渐进的”——每一步都生成动作列表的一部分,就好像我们在进行自回归解码(auto-regressive decoding)一样。实时分块(Real-time chunking, RTC)算法就已经使用了类似的技术。
对AE做出这一改变后,剩下的部分就变得直截了当了。我们可以将新输入信号的注入实现为向基于Transformer的AE添加一个新的输入令牌(token)。每当一个新样本从传感器传来,我们可以在一个独立的流(stream)中执行一次memcpy操作,来更新GPU全局内存中对应的值。VLA的执行可以完全不受此更新的影响。在输出端,我们可以将AE视为在一个密集的480赫兹轨迹中,持续地操纵连续的时间戳节点。当这些节点从GPU中被取出时,它们将被“提交”(committed),并可能以异步的方式进行。AE将只会根据流规则来改变未来未提交的动作值。
在上述讨论之后,我们可以回到图5。我们已经讨论了图中的三个主要对象。有一个每秒480个节点的轨迹缓冲区(trajectory buffer),可以被更新和检索。有一个以480赫兹运行的动作专家流(stream of action experts),它接收来自(1)前一个AE运行结果、(2)高频传感器、(3)最近一次VLM运行产生的KV缓存的输入,并处理多达64个令牌。这些令牌根据某种更新规则被融合回轨迹缓冲区,这意味着如果令牌与节点一一对应,一个AE的“窗口”可以覆盖4帧。我们在这份报告中不讨论融合的细节。还有一个以30赫兹运行的VLM流(stream of VLM),它将最新的图像帧转换为KV缓存供AE使用。
图中有两个反馈回路。**快速回路(quick loop)是高频信号的注入、一个AE的处理以及反应轨迹的生成。在最有利的情况下,这个过程可以快至2毫秒。“慢速回路”(slow loop)**是图像驱动的回路。在一帧被捕获后,它必须由VLM进行处理。当其结果被至少一个AE使用时,我们将看到它对机器人动作的影响。因此,在最乐观的情况下,反馈时间可以低至1/30秒。这两个回路是并行运行的。它们重叠的执行提高了硬件的利用率。并且由于它们都是连续(且可能完全异步)运行的,我们称这种运行方法为“完全流式”(Fully Streaming)。实现这一点的最佳方式可能是持久性大核心(Persistent Magakernel)方法,但由于这超出了本报告的范围,我们将不作进一步的详细说明。
6.3. 融合VLM:走向低于1赫兹 (Fusing VLMs: Going below 1Hz)
现代VLA不仅处理视觉数据,它们还接收并生成文本,无论是多模态理解、任务规划还是思维链(CoT)推理的形式。我们提出了进一步的观察,来展示如何将这一点整合到我们的范式中。我们已经以30赫兹的频率“编码”了视觉令牌。这意味着每秒有30次对Transformer权重的遍历。在大型语言模型(LLM)的文本推理中,瓶颈是在自回归推理期间加载模型检查点。
因此,我们可以将文本推理**“捎带”(piggyback)**在帧编码之上。在加载一个矩阵权重后,它首先被用来计算VLA中VLM部分的矩阵乘法,然后用来计算文本数据的推理。这可以很容易地通过一个特殊的注意力矩阵来实现。由于视觉令牌的数量很大,额外的MACs(乘积累加运算)应该不会对计算时间产生太大影响。
上述修改的网络结果是,我们有了一个额外的、速率为30令牌/秒的自回归文本流,如图5的底行所示。我们可以利用这个配额与用户进行交互,或者让模型进行推理。30令牌/秒是一个相当可观的数量,因为人类的语速大约只有3.3令牌/秒。
6.4. 总结 (Summary)
总结以上讨论,我们有机会在一个实时VLA系统中创建三个反馈回路:
- 480赫兹的力回路 (The force loop at 480 Hz)。高频的输入和输出由AE推理处理。
- 30赫兹的视觉回路 (The visual loop at 30 Hz)。基于图像的反应由VLM处理。
- 低于1赫兹的文本回路 (The textual loop below 1 Hz)。在更低的频率上进行基于文本的交互和推理,带来更多的智能。
在这份报告中,我们只给出了这个框架的设计草图。所有的实现细节都被省略了,这将是后续工作的内容。
7. 真实世界验证 (Real World Validation)
我们设计了一个简单的真实世界实验,来验证我们实现的有效性。
7.1. 设置和数据收集 (Setup and Data Collection)
硬件设置如图1所示。两个定制的抓取器被垂直对齐,用来夹住一支马克笔。在第一个抓取器释放笔之后,第二个抓取器如果能在恰当的时间关闭,就能接住笔。关得太早或太晚都会让笔掉落。我们设置抓取器在60毫秒内完成关闭或打开,这大致相当于两个相机帧的时间。
一台30 FPS的720P USB摄像头被安装用来观察这个装置。摄像头能看到第二个抓取器和笔,但看不到第一个抓取器。所以它无法直接观测到第一个抓取器释放笔的时间。我们测得摄像头的延迟大约是两帧。我们推测其中一帧延迟在ISP(图像信号处理)中,另一帧在USB传输中。当然,我们可以使用更高帧率或更低延迟的摄像头,但为了演示,我们坚持使用这个选择。值得注意的是,机器人研究中常用的RealSense相机,经测量延迟超过100毫秒,所以我们决定不在本实验中使用它们。
笔在被接住前下落了大约30厘米。我们让第一个抓取器在不同位置夹住笔,以在下落距离上制造微小的变化。当我们记录演示数据时,第二个抓取器总是在第一个抓取器释放后200毫秒关闭。我们观察到这个策略在我们的演示数据记录运行中100%成功。在不同的运行中,摄像头的位置被轻微调整以制造变化。
由于记录的主要数据是每一帧期望的抓取器关闭时间,我们将其后处理为描述目标抓取器在帧后状态的1D轨迹。值为0表示抓取器在该时刻不应有动作,值为1表示抓取器应该关闭。我们总共收集了600个片段(episodes)用于训练。相机帧被零填充以适应网络输入的矩形形状。因为我们的系统允许两个输入视角,我们将当前帧和前一帧都馈送给网络。这也为网络提供了关于笔当前速度的线索。
7.2. 训练和推理 (Training and Inference)
我们使用官方的openpi¹仓库来训练我们的模型。提示(prompt)被设置为空。每个训练片段包括笔被释放前的几秒和笔被接住后的几秒。由于有足够的片段数量,我们只训练了网络几个周期(epochs)。
我们的推理程序由不同的线程组成,以处理输入和输出。一个相机线程等待帧的到来,并将帧数据(以及帧到达的时间戳)放入一个环形缓冲区(ring buffer)。推理线程总是取最新的帧数据并运行网络。其输出是一个带有时间戳的抓取器状态轨迹。我们也使用一个循环缓冲区来存储不同时间点的输出状态。推理线程总是覆盖输出缓冲区中的旧值。最后一个线程永远循环,将输出缓冲区中对应的项目发送给抓取器。我们仔细地实现了代码,以消除在“观测到行动”路径中的任何不必要的延迟。我们发现GPU卡需要预热才能达到全速(功耗和时钟频率)。所以在我们的实验中,我们总是在推理时间稳定后才开始释放笔。
7.3. 结果 (Result)
我们期望网络能从图像中学习到笔到达抓取器所需的剩余时间。对于现代VLA来说,这个任务是如此简单,以至于它学得相当好。我们进行了10次连续的实验来测试系统,所有的抓取都是成功的(100%成功率)。
从学习的角度来看,这个结果是微不足道的。如果我们使用LeNet,甚至是SVMs,我们也会期望得到相同的结果。然而,从一个系统的角度来看,单次成功的抓取验证了我们VLA实现的低延迟性。考虑到模型的容量,我们期望该系统能够处理更具挑战性的任务。值得注意的是,我们也尝试过让人类去抓取别人手中掉落的笔。我们观察到30厘米是人类能够反应过来的一个常见的笔下落距离下限。
总之,我们展示了一个反应速度与人类一样快,同时网络中包含数十亿参数的系统。我们相信这个结果应该为在各种时间关键任务上研究VLA开辟了可能性。
8. 相关工作 (Related Work)
手动设计的核心 (Manually-designed Kernels): 底层GPU加速传统上依赖于GPU专家手动设计的、由供应商优化的库提供的核心。像XLA、TensorRT和NVIDIA CUTLASS这样的框架通过算子调度、核心自动调优和高度优化的GEMM原语来提升性能。一些张量编译器,如Triton,将张量分解为瓦片(tiles)以直接映射到硬件上。那些框架将调度和算子融合留给了程序员,因此在核心启动开销和重复的全局内存移动方面留下了显著的性能损失。对于基于Transformer的模型,注意力计算通过融合和特别调度被广泛加速。FlashAttention使用分块技术来减少HBM和SRAM之间的内存I/O数量,并通过修复计算来融合softmax和矩阵乘法。FlashDecoding提出了一种长上下文推理策略,它将注意力划分为两个归约核心,减少了KV内存移动并提高了自回归解码效率。对于AE加速,那些方法忽略了像FFN这样的其他部分。这些方法仍然需要多次核心启动和在模型的其余部分频繁访问DRAM。
基于调度的方法 (Scheduling-based approaches)😗* 基于调度的核心编译器,如TVM,将算法与其执行调度解耦,使得循环分块、融合和布局转换能够独立地应用于GPU优化。这些系统利用用户定义的调度或自动搜索来提升各种算子的性能。然而,它们仍然需要为每个核心提供明确的算法规范,并且它们的有效性从根本上受到这些所提供的算法和调度的质量的限制。
超级优化方法 (Superoptimization Approaches): 近期的工作已经探索了将超级优化应用于张量程序,使得转换超越了传统的调度调优。其中,Mirage和Neptune在线程、瓦片和算子级别上进行分层优化,结合代数和调度转换来搜索高性能核心。虽然这种多层次的联合优化使它们能够超越现有的核心级超级优化器,但Mirage依赖于统计等价性检查来保证正确性,并且它们通常需要很长的搜索时间或较低的加速比,这限制了它们在实时VLA推理中的实用性。
9. 未来方向 (Future Directions)
最近,RTX5090已经发布,显示出比以往更强的计算能力。同时,也有其他面向边缘的加速器加入了这场竞赛。这就提出了一个问题:如果我们手头有更多的计算能力,我们应该从这个系统中期待什么样的其他成果?这里我们列出一些可能性,并简要描述实现它们所面临的关键问题。
9.1. 基于视觉的延迟:走向60-120 FPS (Visual-based Latency: Going to 60-120 FPS)
第一个方向是增加摄像头的FPS和视角数量。这对应于网络编码速度的加快。由于编码阶段已经是计算密集型的,我们所能期望的只是MACs(乘积累加运算)的纯粹增加。一个计算上的替代方案是使用更低的精度。本报告中的所有结果都使用BF16。如果8位乘法可行,计算能力将被显著释放。将VLA量化到低位精度将是一个很好的研究课题。
另一个方向是自适应地选择视角。一个典型的双臂机器人至少有三个摄像头。理论上,如果我们考虑到当前的“活动”视角,我们可以动态地将它们的信息融合成更少数量的令牌。这需要对训练和推理流程进行仔细的工程设计。然而,如果做得对,我们期望FPS会有巨大的提升。据报道,人类能够区分30 FPS和60 FPS的视频播放。这表明60 FPS可能是我们追求的下一个阶段。走向120 FPS将确保我们的系统“超越人类”,因为这种格式通常用于视频录制中的慢动作。
9.2. 更大的模型:走向7B及以上 (Larger Models: Going to 7B and Beyond)
另一个可能性是扩展模型的大小。同样,扩展VLM意味着总MACs的增加,而扩展AE则要求增加带宽。与前代产品相比,RTX 5090在带宽(1.79TB/s)上的提升远大于BF16 MACs的提升。所以在AE中放入更多参数应该不会有太大问题,尽管扩展AE如何裨益模型学习尚不清楚。
我们认为7B参数应该是一个不错的下一个里程碑。它相对于当前3B的πₒ的增长还不算太远,我们仍然可以想出技术来让它运行,同时模型性能2倍的增长在LLM文献中已经被充分研究过。
9.3. 更细粒度的反馈循环 (More Fine-grained Feed-back Loop)
我们注意到,在我们当前的构造中,仍然有一个比AE运行频率更高的循环。那就是AE内部的层。在一秒钟内有成千上万的层在运行。如果我们有办法让每一层都能感知到最新的信号,并找到一种方法来获得更快的中间输出,那么就有可能实现甚至更高的控制频率。然而,我们目前还没有看到实现这一点的方法。此外,在一秒钟内收集数千个样本的演示数据本身就是一个挑战。我们将VLA框架中更高频率的探索留给未来的研究者。