Perplexity AI 的 RAG 架构全解析:幕后技术详解
每周跟踪AI热点新闻动向和震撼发展 想要探索生成式人工智能的前沿进展吗?订阅我们的简报,深入解析最新的技术突破、实际应用案例和未来的趋势。与全球数同行一同,从行业内部的深度分析和实用指南中受益。不要错过这个机会,成为AI领域的领跑者。点击订阅,与未来同行! 订阅:https://rengongzhineng.io/

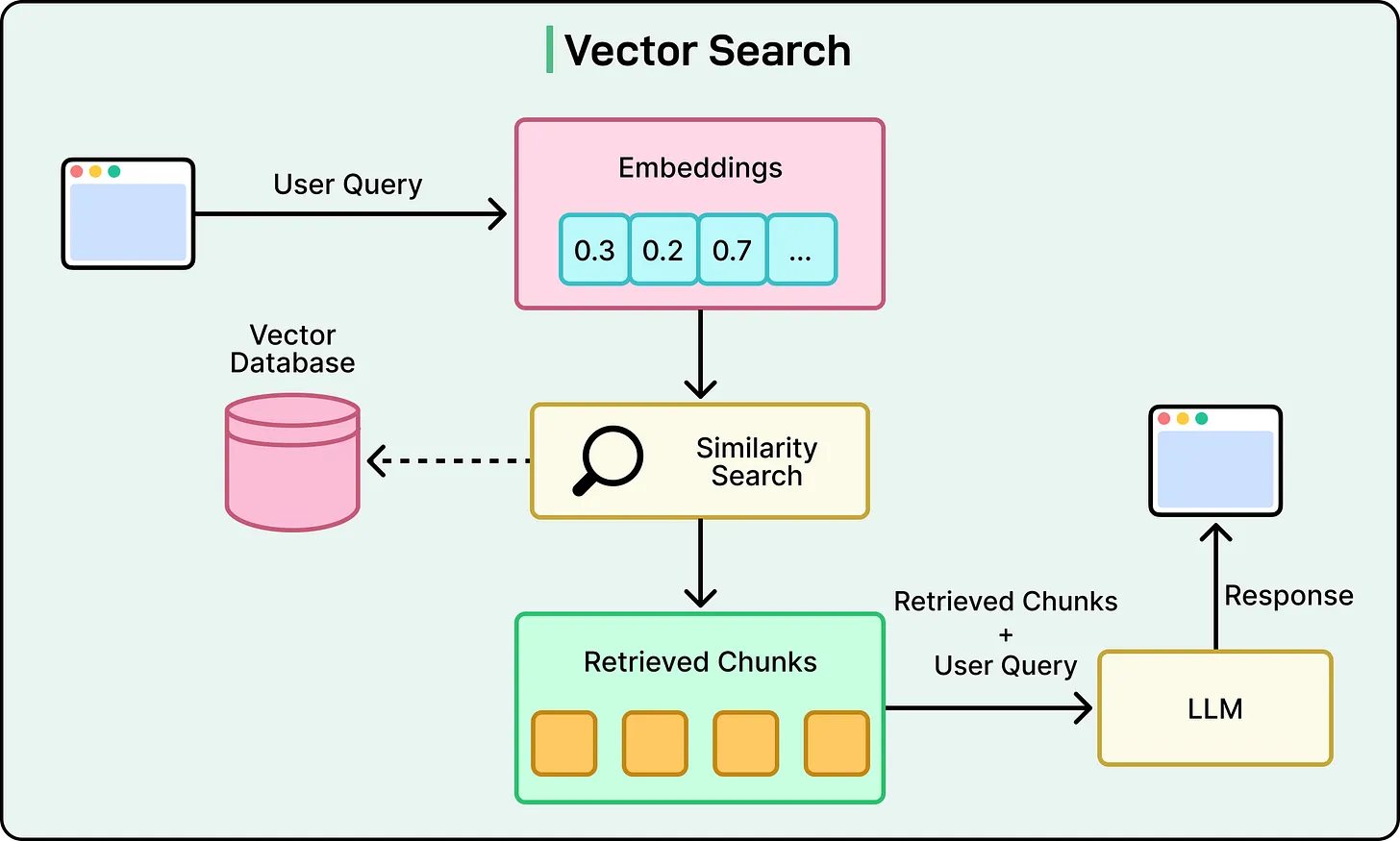
在 Perplexity 的检索增强生成(RAG)系统背后,是一套精心设计的多步骤流程,几乎对每一条用户查询都会执行,以确保答案既相关,又基于最新的事实信息。
这一流水线可以被分解为五个明确的阶段:
1. 查询意图解析
流程起始于用户提交查询。系统并不依赖简单的关键词匹配,而是通过大型语言模型(可能是 Perplexity 自研的 Sonar 系列模型,也可能是 GPT-4 等第三方模型)解析用户的真实意图。这一步关键在于语义层面的深入理解:识别查询背后的上下文、语气、目的等深层含义。
2. 实时网页检索
在理解了用户的意图后,系统会将解析后的查询发送至一个高性能的实时搜索引擎,执行全网检索,寻找可能包含答案的网页和文档。这一步是不可跳过的,确保答案始终建立在最新的信息之上。
3. 片段提取与上下文构建
系统不会将整篇网页传入语言模型,而是通过算法提取最相关的段落或文本片段。这些紧密贴合用户问题的内容被聚合为“上下文”,作为后续生成回答的依据。
4. 答案生成与引文标注
这些构建好的上下文随后被传递至生成型语言模型。模型的任务是基于上述内容,生成一段自然语言的对话式回答。系统架构的核心原则是:“生成内容不得脱离检索信息”。为此,每一段回答都附带引用文献,用户可以直接跳转至原始信息来源,以核实内容。
5. 会话上下文优化
Perplexity 并非一次性问答系统,而是为对话而生。系统保留会话历史,并允许用户提出跟进问题。每当用户追问时,系统结合当前上下文与新的迭代搜索结果,提供更精准的后续回答。
架构总览图:RAG 在 Perplexity 中的整体工作流程
在 Perplexity 架构中,核心技术能力并不在于某个特定的大模型,而是多模型与搜索系统的编排机制,用以实现高速、精准且成本可控的问答系统。这种架构旨在平衡 LLM 的高计算成本与实时搜索产品所需的低延迟需求。
模型无关的编排层
Perplexity 的架构明确支持“模型无关”(model-agnostic)策略。系统使用多种模型组合,包括自研的 Sonar 系列微调模型,以及来自 OpenAI(GPT 系列)、Anthropic(Claude 系列)等外部领先实验室的前沿模型。
智能路由系统使用高效的分类器模型,判断查询意图及其复杂度,再将请求路由至最合适、最具成本效益的模型。例如,简单定义类查询由轻量自研模型处理;多步骤推理或复杂问题则分配给 GPT-5 或 Claude Opus 等高端模型。
这一动态路由机制基于“使用最小但能提供最佳体验的模型”的策略,既优化了性能,又控制了成本。
此架构设计不仅是技术层面的优化,更是关键的商业防御。避免对某一第三方 API 的过度依赖,规避供应商锁定、价格波动、技术路线不透明等风险。最终目标是让模型的差异对用户透明,而由编排层负责实现高质量的组合与调用。
检索引擎:构建答案引擎的地基
Perplexity 的检索能力由 Vespa AI 提供支持,为大规模、实时、高性能的 RAG 提供坚实后盾。Vespa 将向量搜索(语义理解)、词法搜索(关键词精度)、结构化过滤、机器学习排序等关键技术集成于统一引擎中,避免了使用多个系统拼接所带来的复杂性和性能损耗。
这一“构建 vs 购买”的高层次架构决策,使 Perplexity 的小型工程团队能专注于技术栈中具有差异化竞争力的部分:
RAG 编排逻辑
自研 Sonar 模型的微调
内部推理引擎 ROSE 的性能优化
索引与检索基础设施:针对 AI 答案引擎量身打造
1. 网络级索引规模
Perplexity 的索引规模覆盖数千亿网页,追踪超过 2000 亿唯一 URL,使用数万颗 CPU 及超过 400PB 的热存储系统支撑这一索引规模。
2. 实时更新能力
信息过时是问答系统的致命缺陷。Perplexity 每秒处理数万个索引更新请求,Vespa 的索引结构可实现边读取边更新,不影响查询性能。
3. 精细化内容理解
系统不按整篇文档检索,而是分割成“原子级”内容单元(如段落、句子),并以细粒度评分机制评估其与查询的匹配度。
4. AI 驱动的内容解析自优化
面向开放网络的复杂结构,系统配备 AI 内容理解模块。其解析规则集由前沿大模型动态优化,通过评估现有规则的效果,持续生成、验证并部署新规则,实现语义提取的自动演化。
5. 混合搜索与排序能力
结合稠密检索(向量搜索)、稀疏检索(关键词搜索)与机器学习排序,系统通过多阶段排序架构逐步筛选结果,最终输出高精度、高相关度的内容。排序系统通过用户行为信号不断训练优化。
生成引擎:将信息转化为自然语言回答
系统生成回答的过程依赖双重策略:
自研模型 Sonar:基于开源模型微调,具备总结、引用、事实核对等核心能力。所有用户交互都会成为反馈数据,持续提升模型质量。
外部高端模型整合:为付费用户提供 GPT、Claude 等最先进模型能力,支持深度推理、创意生成等任务。
通过 Amazon Bedrock 平台实现外部模型的统一接入,无需单独集成,从而提高系统灵活性和兼容性。
这一“自研 + 外购”的模型策略,成为 Perplexity 商业模式的关键支撑点。
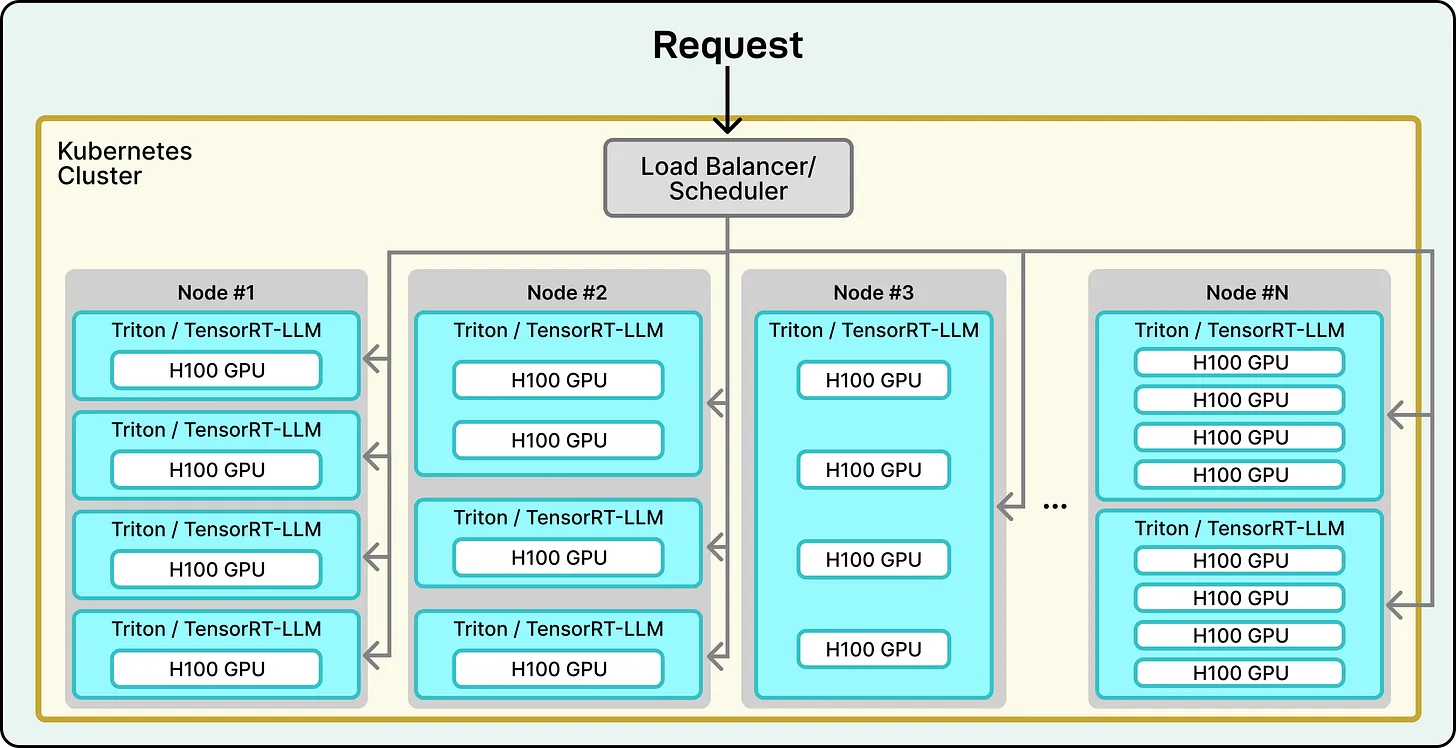
推理引擎:ROSE 引擎支撑的大规模高性能架构
高质量模型只是基础,高效运行它们才是关键。Perplexity 自研的推理引擎 ROSE,是整个服务得以运行的技术核心:
灵活性:支持快速适配各类模型
高性能:推理逻辑关键部分迁移至 Rust,实现高性能与内存安全的平衡
技术栈:使用 PyTorch 进行模型定义,支持多种解码策略(如 speculative decoding、MTP)以优化延迟
基础设施:部署于 AWS 云平台,运行在大规模 NVIDIA H100 GPU 集群之上,使用 Kubernetes 管理资源调度和服务弹性
这一“自建完整栈”的策略,让 Perplexity 能在性能、成本和用户体验三方面取得最佳平衡。
总结:Perplexity 的技术护城河不是某个 LLM,而是架构系统本身
Perplexity 被称为“AI 版 Google”,其强大之处并非依赖某个特定模型,而是源于其精心打造的端到端架构系统:
世界级检索引擎:由 Vespa 支撑,实现实时、规模化、高质量信息检索
灵活编排层:意图解析与智能路由确保每次调用都是“最优模型+最低成本”的组合
高性能推理栈:ROSE 引擎在硬件与软件两端压榨性能极限
在一个模型快速商品化的时代,Perplexity 的技术护城河并非“拥有更强模型”,而是设计出比别人更高效的系统。这才是其长期持续发展的核心竞争力。