python从入门到精通(二十二):python文件操作之Excel全攻略(基于pandas)
Python处理表格数据
- 1.表格的基础知识
- 1.1 xls与xlsx格式详解
- 1.2 表格内部结构的认识
- 2.表格的基础操作
- 2.1 认识表格的基本库
- 2.1.1 csv内置的标准库
- 2.1.2 xlrd 和 xlwt
- 2.1.3 openpyxl
- 2.1.4 pandas
- 2.2 安装和环境配置
- 2.3 xlrd 和 xlwt
- 2.3.1 库的说明
- 2.3.2 安装xlrd库
- 2.3.3 导入模块
- 2.3.4 深入使用
- 2.4 Pandas
- 2.4.1 简介
- 2.4.2 安装pandas
- 2.4.3 导入pandas
- 2.4.3 pandas Series数据结构
- 2.4.3.1 Series的作用和参数
- 2.4.3.2 创建一个空Series对象
- 2.4.3.3 创建一个简单的Series对象
- 2.4.3.4 根据索引值读取数据
- 2.4.3.5 手动设定索引值
- 2.4.3.7 手动设置索引并取值
- 2.4.3.8 使用key/value创建Series
- 2.4.4 pandas DataFrame数据结构
- 2.4.4.1使用ndarrays和字典创建DF
- 2.4.5 Pandas读取写入CSV
- 2.4.5.1 read_csv读取CSV文件
- 2.4.5.2 to_csv写入csv文件
- 2.4.5.3 数据处理
- 2.4.6 Pandas读取写入Execl
- 2.4.6.1 Pandas数据查看
- 2.4.6.1.1 head()
- 2.4.6.1.2 tail()
- 2.4.6.1.3 info()
- 2.4.6.1.4 set_option 指定查看行数
- 2.4.6.1.5 shape 行列数
- 2.4.6.1.6 dtypes 变量类型
- 2.4.6.1.7 describe 统计
- 2.4.6.2 Pandas数据选择
- 2.4.6.2.1 index 行名称或者行索引
- 2.4.6.2.2 columns 查找列名称
- 2.4.6.2.3 values查找表的值
- 2.4.6.2.4 df["A"] 查找某一列
- 2.4.6.2.5 df[['A','B']] 查找多个列
- 2.4.6.2.6 sample 随机选取几行
- 2.4.6.2.7 df[x:x]指定连续选择多行
- 2.4.6.2.8 loc 根据行列名称定位查找
- 2.4.6.2.9 iloc 根据索引定位查找
- 2.4.6.2.10 布尔值索引
- 2.4.6.3 Pandas数据修改
- 2.4.6.3.1 list修改列名
- 2.4.6.3.2 rename修改列名
- 2.4.6.3.3 set_index修改索引
- 2.4.6.3.4 按列修改值
- 2.4.6.3.5 切片操作
- 2.4.6.3.5 条件设置
- 2.4.6.3.5 按列修改类型
- 2.4.6.4 Pandas数据增加
- 2.4.6.4.1 使用 loc按行增加
- 2.4.6.4.1 使用 loc按列增加
- 2.4.6.3 Pandas数据拼接
- 2.4.6.3 Pandas数据删除
- 2.4.6.3.1 删除空值数据
- 2.4.6.3.2 删除格式错误数据
- 2.4.6.3.3 删除错误数据
- 2.4.6.3.4 删除重复数据
- 2.4.6.4 Pandas数据排序
- 2.4.6.5 Pandas数据过滤
- 2.4.6.6 Pandas数据分组
- 2.4.6.7 Pandas数据合并
- 2.4.6.8 Pandas时间序列处理
- 2.4.6.9 Pandas数据可视化
1.表格的基础知识
如果我们要使用python来处理表格,首先我们需要了解怎么表格的每个部分对应的python应该怎么操作
1.1 xls与xlsx格式详解
- 历史演变:xls是Excel 2003及之前版本的默认格式,采用BIFF8二进制格式存储
- xlsx格式特点:基于XML的开放格式(OOXML标准),采用ZIP压缩技术
兼容性对比:
- Excel 2007+ 支持读写两种格式
- Excel 2013+ 默认保存为xlsx
- 其他办公软件兼容性差异
文件结构差异:
- xls最大限制:65536行×256列
- xlsx最大支持:1048576行×16384列
打开方式:
- xls是excel2003及以前版本所生成的文件格式
- xlsx是excel2007及以后版本所生成的文件格式
(excel 2007之后版本可以打开上述两种格式,但是excel2013只能打开xls格式)
1.2 表格内部结构的认识
- 一个Excel电子表格文档称为一个工作簿
- 一个工作簿保存在一个扩展名为.xlsx的文件中
- 一个工作簿可以包含多个表
- 用户当前查看的表(或关闭Excel前最后查看的表)称为活动表
- 在特定行和列的方格称为单元格、格子

2.表格的基础操作
2.1 认识表格的基本库
2.1.1 csv内置的标准库
- 简介:csv 是 Python 内置的标准库,专门用于处理 CSV(逗号分隔值)文件。CSV
文件是一种简单的文本文件,数据以逗号分隔不同字段,常用于数据交换和存储。 - 优点:无需额外安装,使用简单,适合处理简单的 CSV 文件读写操作。
- 缺点:功能相对单一,只能进行基本的读写操作,缺乏数据处理和分析功能。
- 示例代码 - 读取 CSV 文件
import csv
with open('example.csv', 'r', newline='') as file:
reader = csv.reader(file)
for row in reader:
print(row)
2.1.2 xlrd 和 xlwt
- 简介:xlrd 用于读取 Excel 文件(主要支持 .xls 格式),xlwt 用于写入 Excel 文件(仅支持 .xls
格式)。这两个库在早期 Python 处理 Excel 文件时非常常用,但由于 .xls 格式的局限性,现在逐渐被 openpyxl
取代。 - 优点:简单易用,对于处理旧版本的 Excel 文件有一定的优势。
- 缺点:仅支持 .xls 格式,不支持 Excel 2010 及以上版本的 .xlsx 格式,功能相对有限。
import xlrd
# 打开 Excel 文件
workbook = xlrd.open_workbook('example.xls')
# 获取指定工作表,这里以获取第一个工作表为例
sheet = workbook.sheet_by_index(0)
# 获取工作表的行数和列数
rows, columns = sheet.nrows, sheet.ncols
# 遍历每一行
for row in range(rows):
# 用于存储当前行的数据
row_data = []
# 遍历当前行的每一列
for col in range(columns):
# 获取当前单元格的值
cell_value = sheet.cell_value(row, col)
row_data.append(cell_value)
print(row_data)
import xlwt
# 创建一个新的工作簿
workbook = xlwt.Workbook()
# 创建一个工作表
sheet = workbook.add_sheet('Sheet1')
# 定义要写入的数据
data = [
['Name', 'Age', 'City'],
['Alice', 25, 'New York'],
['Bob', 30, 'Los Angeles']
]
# 遍历数据列表
for row_index, row in enumerate(data):
# 遍历当前行的数据
for col_index, value in enumerate(row):
# 在指定单元格写入数据
sheet.write(row_index, col_index, value)
# 保存工作簿到文件
workbook.save('output.xls')
2.1.3 openpyxl
- 简介:openpyxl 是一个用于读写 Excel 2010 及以上版本文件(.xlsx、.xlsm 等)的库。它可以直接操作 Excel
文件的单元格、工作表、图表等元素。 - 优点:能够精确控制 Excel 文件的各种元素,如单元格样式、合并单元格、设置公式等,适合需要对 Excel 文件进行复杂格式设置的场景。
- 缺点:主要专注于 Excel 文件的操作,对于其他格式的表格数据支持有限,且在数据处理和分析方面不如 pandas 强大。
from openpyxl import load_workbook
workbook = load_workbook('example.xlsx')
sheet = workbook.active
for row in sheet.iter_rows(values_only=True):
print(row)
2.1.4 pandas
- 简介:pandas 是一个强大的数据处理和分析库,提供了 DataFrame 和 Series
两种主要的数据结构,非常适合处理表格数据。它支持多种文件格式的读写,包括 CSV、Excel、SQL 数据库等。 - 优点:功能全面,涵盖了数据读取、清洗、转换、分析、可视化等多个方面,提供了丰富的方法和函数,能够高效地处理大规模数据。
- 缺点:学习曲线相对较陡,对于初学者来说可能需要花费一些时间来掌握其复杂的 API。
import pandas as pd
df = pd.read_csv('example.csv')
average_age = df['Age'].mean()
print(f"Average age: {average_age}")
2.2 安装和环境配置
安装必要库
pip install pandas openpyxl xlrd xlsxwriter sqlite3
2.3 xlrd 和 xlwt
2.3.1 库的说明
什么是xlrd模块
- python操作excel主要用到xlrd和xlwt这两个库,即xlrd是读excel,xlwt是写exce的库。
为什么用xlrd模块
- 在UI自动化或者接口自动化中数据维护是一个核心,所以此模块非常实用。xlrd模块可以用于读取Excel的数据,速度非常快,推荐使用!
2.3.2 安装xlrd库
1.如果安装慢或者安装失败,可以指定安装源安装

2.百度搜索安装源
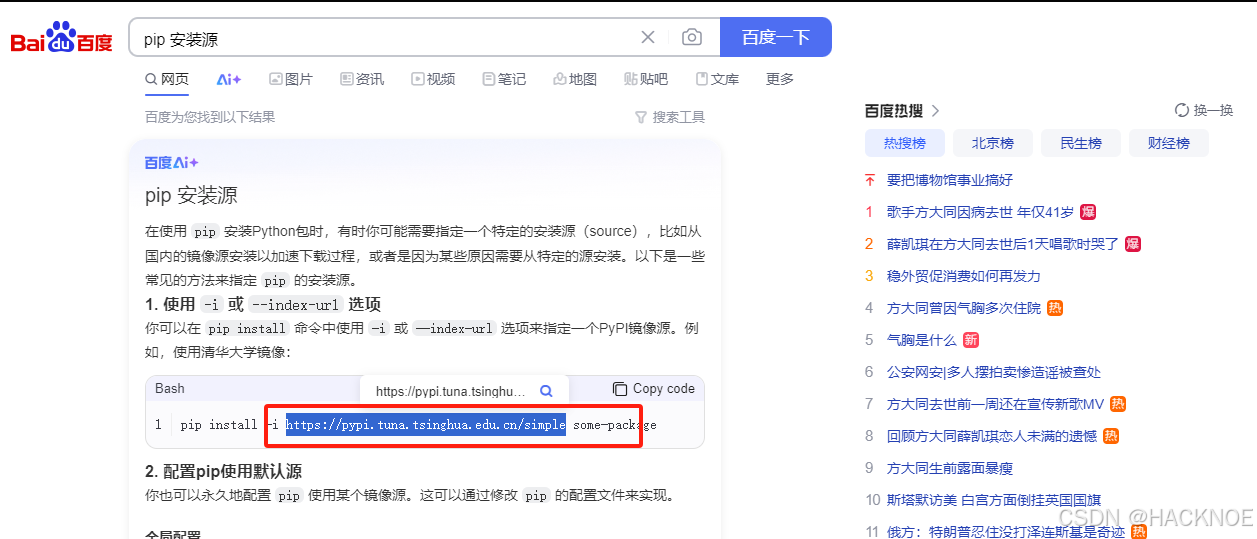
3.命令行下指定安装源安装

2.3.3 导入模块
import xlrd
2.3.4 深入使用
1.打开execl文件读取数据
data = xlrd.open_workbook("1.xls")
2.获取book中的工作表
#方法一
table = data.sheets()[0]
#方法二
table = data.sheet_by_index(0)
#方法三
table = data.sheet_by_name("sheet1")
3.返回book中的所有表
names = data.sheet_names()
4.检查sheet是否导入完毕
data.sheet_loaded(sheet_name or index)
5.获取sheet中的行数
2.4 Pandas
2.4.1 简介
pandas 是基于NumPy 的一种工具,该工具是为了解决数据分析任务而创建的。Pandas 纳入了大量库和一些标准的数据模型,提供了高效地操作大型数据集所需的工具。pandas提供了大量能使我们快速便捷地处理数据的函数和方法。你很快就会发现,它是使Python成为强大而高效的数据分析环境的重要因素之一。
官方网站:https://pandas.pydata.org/
官方文档:https://pandas.pydata.org/pandas-docs/stable/
2.4.2 安装pandas
pip安装pandas
pip install pandas
2.4.3 导入pandas
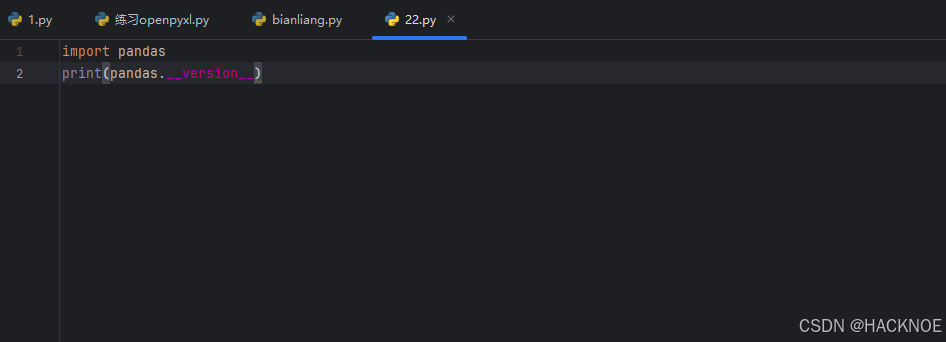
导入pandas并查看相应版本 as 是给pandas起一个简称,方便我们使用
import pandas as pd
pandas._version_
2.4.3 pandas Series数据结构
2.4.3.1 Series的作用和参数
Pandas Series 类似表格中的一个列(column),类似于一维数组,由一组数据值(value)和一组标签组成,其中标签与数据值之间是一一对应的关系。Series 可以保存任何数据类型。Series 由索引(index)和列组成,函数如下:
pandas.Series(data,index,dtype,name,copy)
参数说明如下所示:
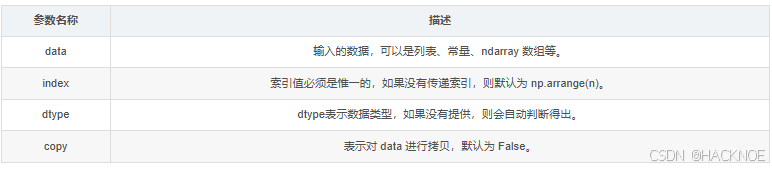
- data:一组数据(ndarray 类型)。
- index:数据索引标签,如果不指定,默认从0开始。
- dtype:数据类型,默认会自己判断。
- name:设置名称。
- copy:拷贝数据,默认为 False。
2.4.3.2 创建一个空Series对象
import pandas as pd
# print(pandas.__version__)
series1 = pd.Series()
print(series1)
2.4.3.3 创建一个简单的Series对象
import pandas as pd
# print(pandas.__version__)
a = [1,2,3]
series2 = pd.Series(a)
print(series2)
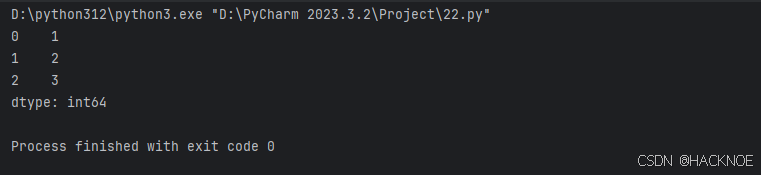
2.4.3.4 根据索引值读取数据
从上图可知,如果没有指定索引,索引值就从0开始,我们可以根据索引值读取数据:
import pandas as pd
# print(pandas.__version__)
a = [1,2,3]
series2 = pd.Series(a)
print(series2[1])

2.4.3.5 手动设定索引值
import pandas as pd
# print(pandas.__version__)
a = [1,2,3]
series2 = pd.Series(a,index=('x','y','z'))
print(series2)
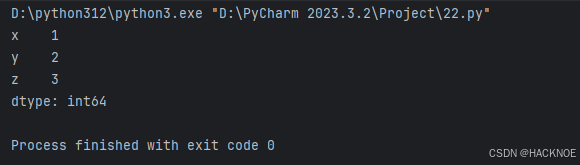
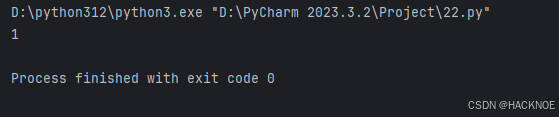
2.4.3.7 手动设置索引并取值
import pandas as pd
# print(pandas.__version__)
a = [1,2,3]
series2 = pd.Series(a,index=('x','y','z'))
print(series2["x"])
2.4.3.8 使用key/value创建Series
字典的 key 变成了索引值
import pandas as pd
# print(pandas.__version__)
a = {1:"xsad",2:"dsadas",3:"sdasds"}
series2 = pd.Series(a)
print(series2)
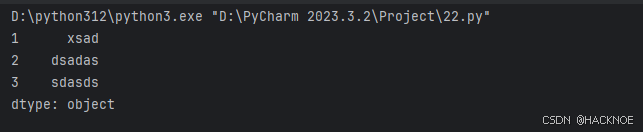
如果我们只需要字典中的一部分数据,只需要指定需要数据的索引即可,如下实例:
import pandas as pd
# print(pandas.__version__)
a = {1:"xsad",2:"dsadas",3:"sdasds"}
series2 = pd.Series(a,index=[1,2])
print(series2)
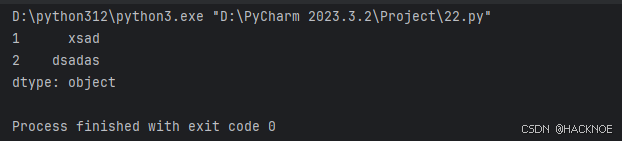
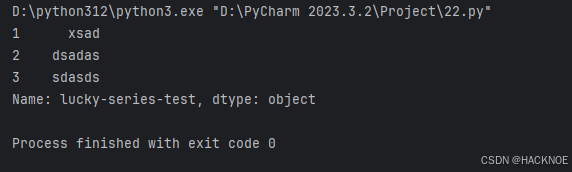
设置series的name
import pandas as pd
# print(pandas.__version__)
a = {1:"xsad",2:"dsadas",3:"sdasds"}
series2 = pd.Series(a,name="lucky-series-test")
print(series2)
2.4.4 pandas DataFrame数据结构
DataFrame 是一个表格型的数据结构,它含有一组有序的列,每列可以是不同的值类型(数值、字符串、布尔型值)。DataFrame 既有行索引也有列索引,它可以被看做由 Series组成的字典(共同用一个索引)。
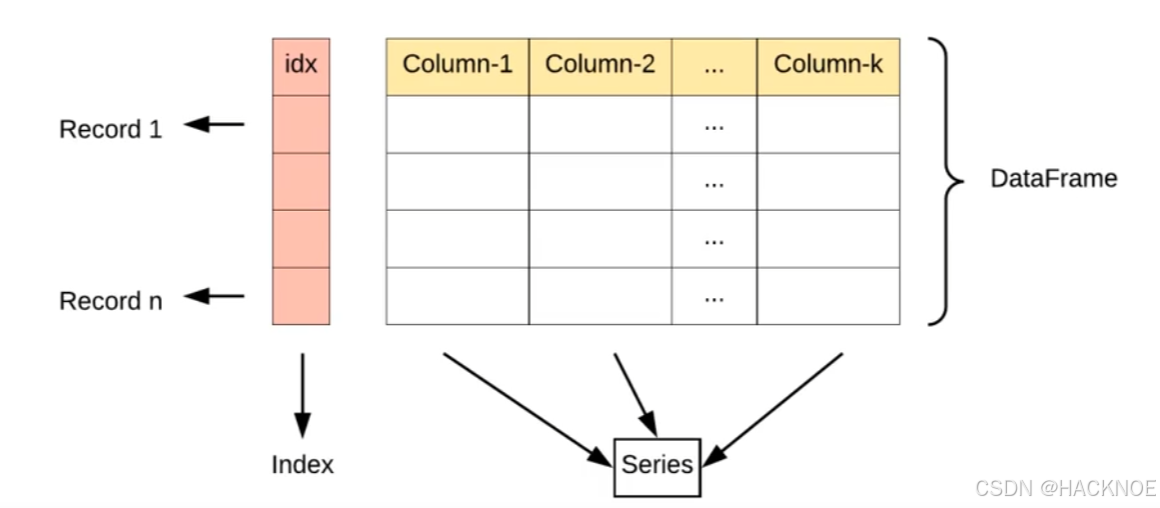
DataFrame 其实是从 Series 的基础上演变而来,就是多个Series组成的字典
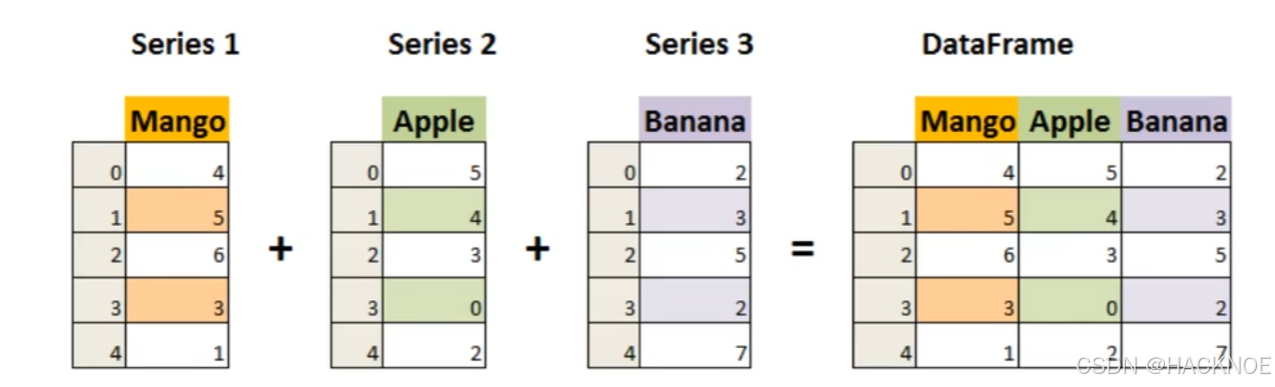
行标签(index),又有列标签(columns)
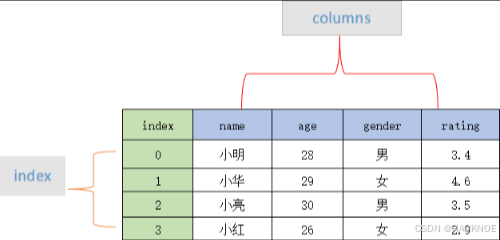
标签和现实表格的对应关系
DataFrame 构造方法如下:
pandas.DataFrame( data,index,columns,dtype,copy)
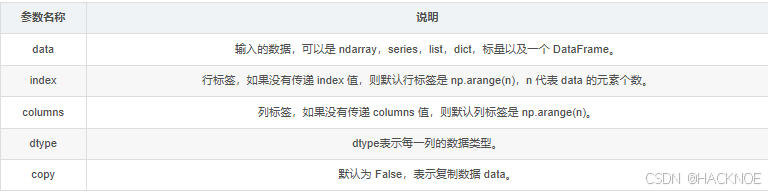
- data:一组数据(ndarray,series, map, lists, dict 等类型)。
- index:索引值,或者可以称为行标签
- columns:列标签,默认为 Rangelndex(0,1,2,…,n)。
- dtype:数据类型。
- copy:拷贝数据,默认为False。
Pandas DataFrame 是一个二维的数组结构,类似二维数组
import pandas as pd
# print(pandas.__version__)
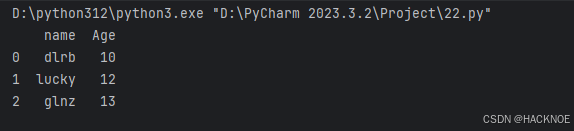
data =[['dlrb',10],['lucky',12],['glnz',13]]
df = pd.DataFrame(data,columns=['name','Age'])
print(df)
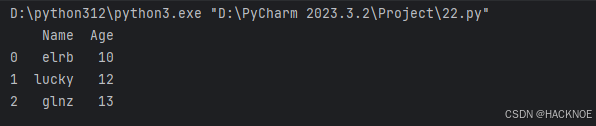
2.4.4.1使用ndarrays和字典创建DF
以下实例使用 ndarrays 创建,ndarray的长度必须相同,如果传递了 index,则索引的长度应等于数组的长度。如果没有传递索引,则默认情况下,索引将是range(n),其中n是数组长度。
ndarray(N 维数组)是一个快速且灵活的数据集容器。
以下实例-使用 ndarrays 创建
import pandas as pd
# print(pandas.__version__)
data ={'Name':['elrb','lucky','glnz'],'Age':[10,12,13]}
df = pd.DataFrame(data)
print(df)
从以上输出结果可以知道, DataFrame 数据类型一个表格,包含rows(行)和columns(列):
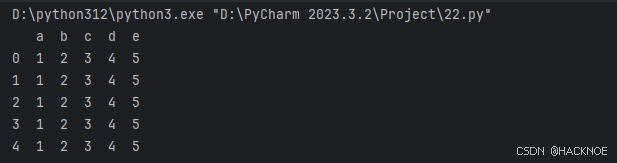
还可以使用字典(key/value),其中字典的 key 为列名
实例-使用字典创建
import pandas as pd
# print(pandas.__version__)
data = [{'a':1,'b':2,'c':3,'d':4,'e':5},{'a':1,'b':2,'c':3,'d':4,'e':5},{'a':1,'b':2,'c':3,'d':4,'e':5},{'a':1,'b':2,'c':3,'d':4,'e':5},{'a':1,'b':2,'c':3,'d':4,'e':5}]
df = pd.DataFrame(data)
print(df)
Pandas 可以使用loc属性返回指定行的数据,如果没有设置索引,第一行索引为 0,第二行索引为 1,以此类推:
import pandas as pd
# print(pandas.__version__)
data ={
"calories":[420,380,390],
"duration":[50,40,45]
}
df = pd.DataFrame(data)
print(df.loc[0])
print(df.loc[1])
注意:返回结果其实就是一个 Pandas Series 数据。
返回多行数据,也可以返回多行数据,使用[[…]]格式,…为各行的索引,以逗号隔开:
import pandas as pd
# print(pandas.__version__)
data ={
"calories":[420,380,390],
"duration":[50,40,45]
}
df = pd.DataFrame(data)
print(df.loc[[0,1]])
返回某行数据
import pandas as pd
# print(pandas.__version__)
data ={
"calories":[420,380,390],
"duration":[50,40,45]
}
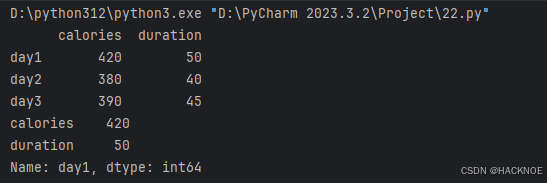
df = pd.DataFrame(data,index=['day1','day2','day3'])
print(df)
print(df.loc['day1'])
2.4.5 Pandas读取写入CSV
CSV(Iomma-Separated Values,逗号分隔值,有时也称为CSV字符分隔值,因为分隔字符也可以不是逗号),其文件以纯文本形式存储表格数据(数字和文本)
CSV 是一种通用的、相对简单的文件格式,被用户、商业和科学广泛应用。
Pandas 可以很方便的处理 CSV 文件 本文以 nba.csv为例
2.4.5.1 read_csv读取CSV文件
import pandas as pd
data = pd.read_csv('2.csv')
print(data.to_string())
to_string()用于返回 DataFrame 类型的数据,如果不使用该函数,则输出结果为数据的前面5行和未尾5行,中间部分以…代替。
2.4.5.2 to_csv写入csv文件
import pandas as pd
data = pd.read_csv('2.csv')
data.to_csv('test.csv')
print(data.to_string())
注意: 在写入csv文件会默认将索引写入如果不需要索引 则需添加参数进行处理
data.to_csv('test.csv',index=False)
2.4.5.3 数据处理
1.head()
head( n)方法用于读取前面的n行,如果不填参数n,默认返回 5 行。
实例-读取前面10行
import pandas as pd
data = pd.read_csv('2.csv')
print(data.head(10))
2.tail()
tail( n)方法用于读取尾部的n行,如果不填参数n,默认返回 5 行,空行各个字段的值返回 NaN,
实例-读取未尾10 行
import pandas as pd
data = pd.read_csv('2.csv')
print(data.tail(10))
3.info()
info()方法返回表格的一些基本信息
import pandas as pd
data = pd.read_csv('2.csv')
print(data.info())
2.4.6 Pandas读取写入Execl
Pandas提供了非常强大的功能操作Excel,是数据分析领域处理Excel文档的重要工具
Pandas方法
- 读取Excel
df= pd.read excel()
- 写入Excel
df.to excel()
常用参数
- index:是否写入索引默认为True
- header :是否写入表头 默认True
- sheet_name:写入哪个sheet页 默认sheet1
- startrow 写入Excel数据开始行 默认0行
- startcol 写入Excel数据开始列 默认0列
import pandas as pd
# 读取Excel 去除表头 使用默认生成表头
df = pd.read_excel('1.xlsx',header=None)
print(df.to_string())
# 写入Excel 去除表头header=None和索引index=False
df.to_excel('1.xlsx',index=False,header=False)
注意
当前在读取Excel以后会默认把第一行作为表头,这样在写入的时候会自带格式,为了防止这个问题出现,所以需要再读取和写入的时候给定参数,下面所有数据操作都以这个表为对象
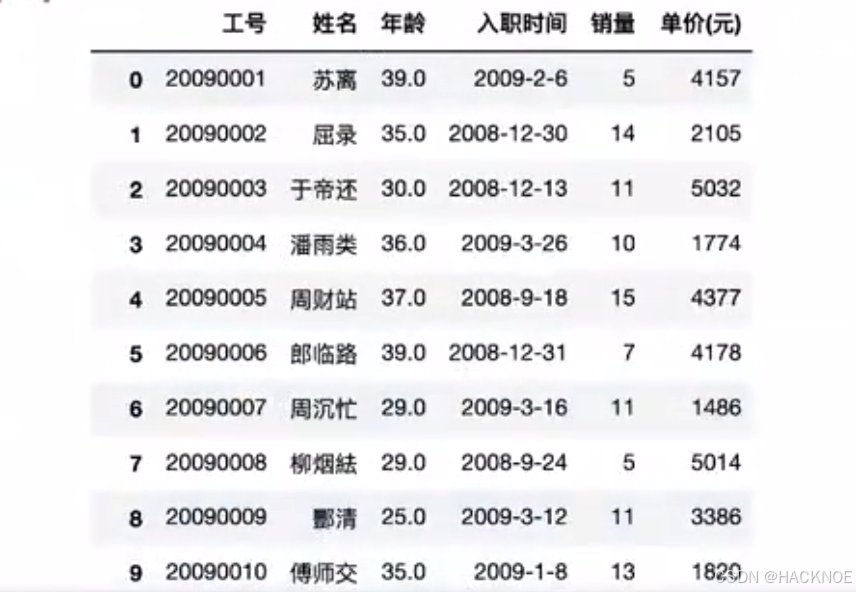
2.4.6.1 Pandas数据查看
上面处理csv的所有方法在这里可以同样去使用,这里就不在过多赘述~
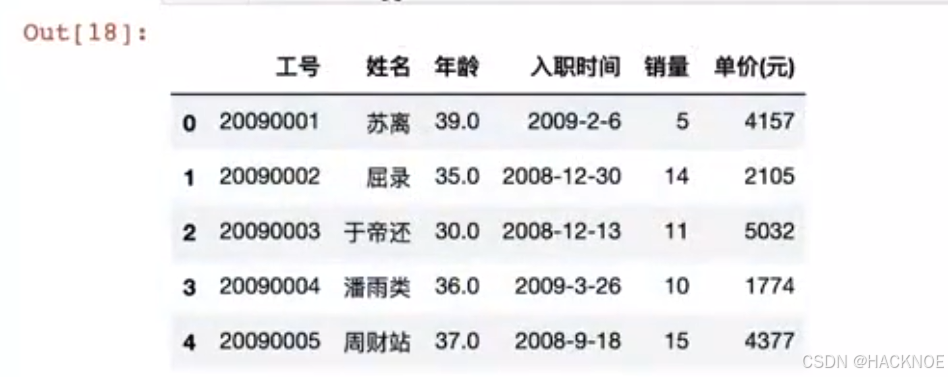
2.4.6.1.1 head()
head( n)方法用于读取前面的n行,如果不填参数n,默认返回 5 行。
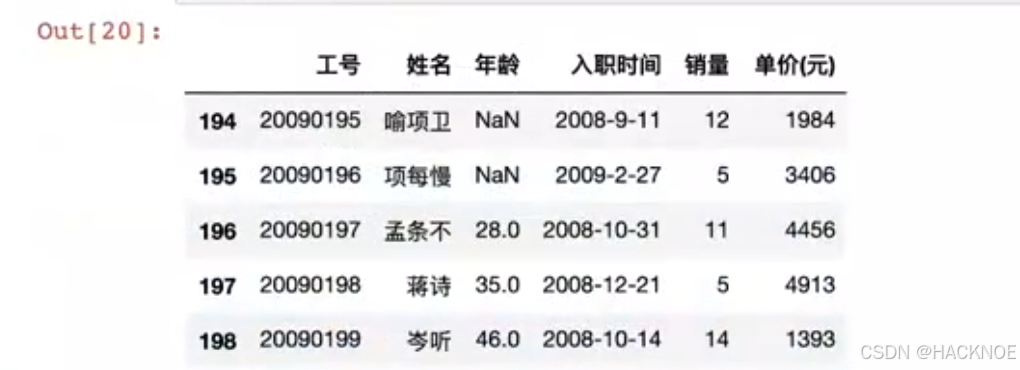
2.4.6.1.2 tail()
tail( n)方法用于读取尾部的n行,如果不填参数n,默认返回 5 行,空行各个字段的值返回 NaN,
实例-读取未尾10 行
2.4.6.1.3 info()
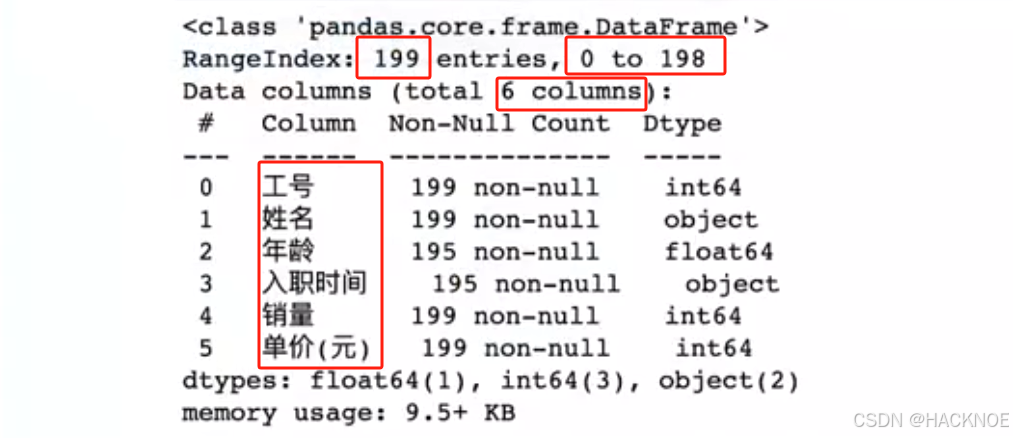
info()方法返回表格的一些基本信息
import pandas as pd
# 读取Excel 去除表头 使用默认生成表头
df = pd.read_excel('1.xlsx',header=None)
# print(data.to_string())
print(df.head())
print(df.head(10))
print(df.tail())
print(df.tail(10))
print(df.info())
# 写入Excel 去除表头和索引
df.to_excel('1.xlsx',index=False,header=False)
2.4.6.1.4 set_option 指定查看行数
df= pd.set option('max rows',200) # 可查看200行
2.4.6.1.5 shape 行列数
df.shape #DataFrame的行列数 199行 6列

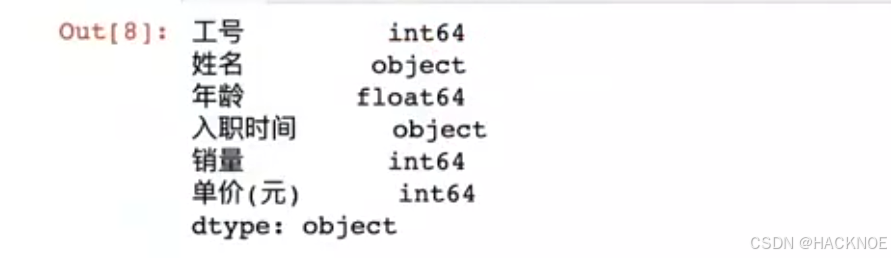
2.4.6.1.6 dtypes 变量类型
df.dtypes
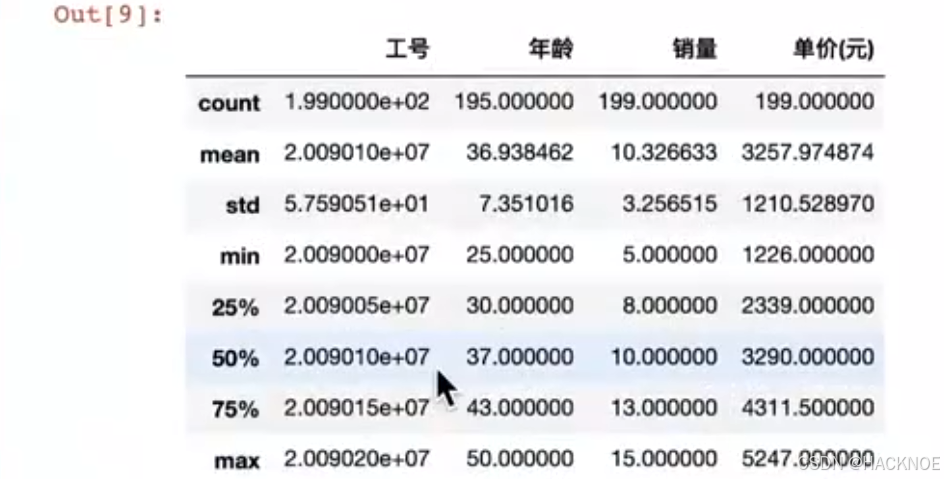
2.4.6.1.7 describe 统计
df.describe()
2.4.6.2 Pandas数据选择
2.4.6.2.1 index 行名称或者行索引
df.index
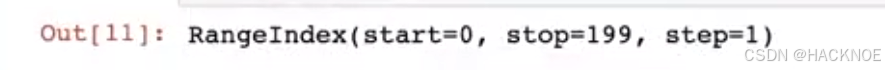
2.4.6.2.2 columns 查找列名称
df.columns

2.4.6.2.3 values查找表的值
df.values

2.4.6.2.4 df[“A”] 查找某一列
df['姓名'] #查找出姓名这一列

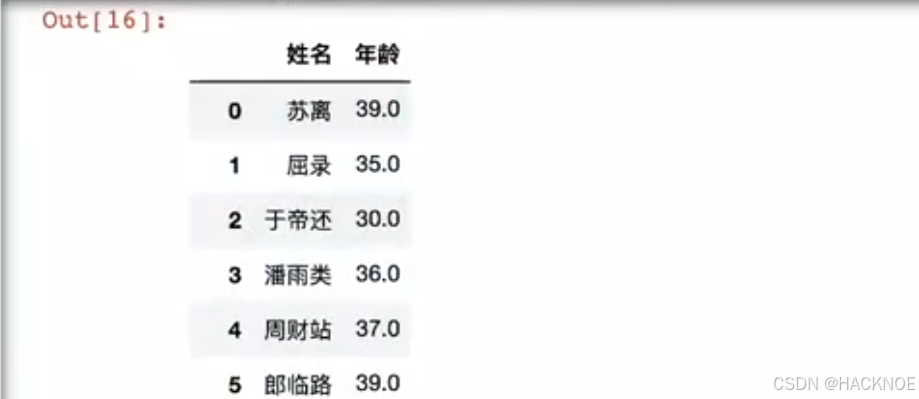
2.4.6.2.5 df[[‘A’,‘B’]] 查找多个列
df[['姓名','年龄']]
2.4.6.2.6 sample 随机选取几行
df.sample(5) #随机选5行
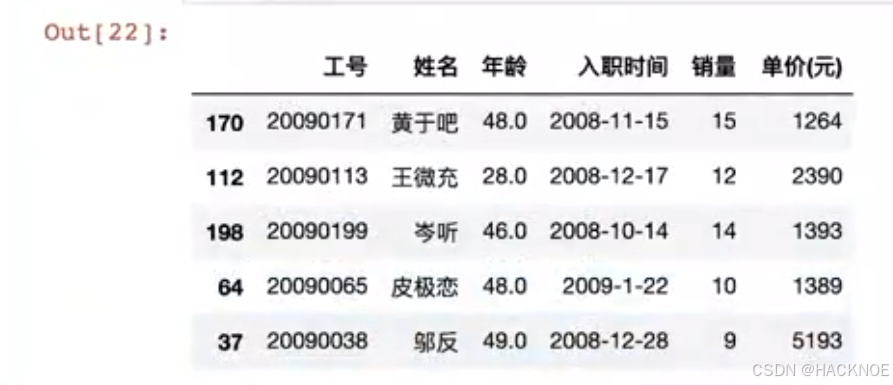
2.4.6.2.7 df[x:x]指定连续选择多行
df[1:5] #
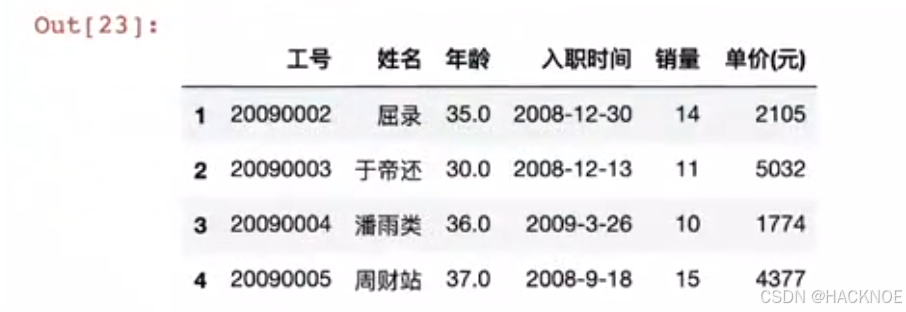
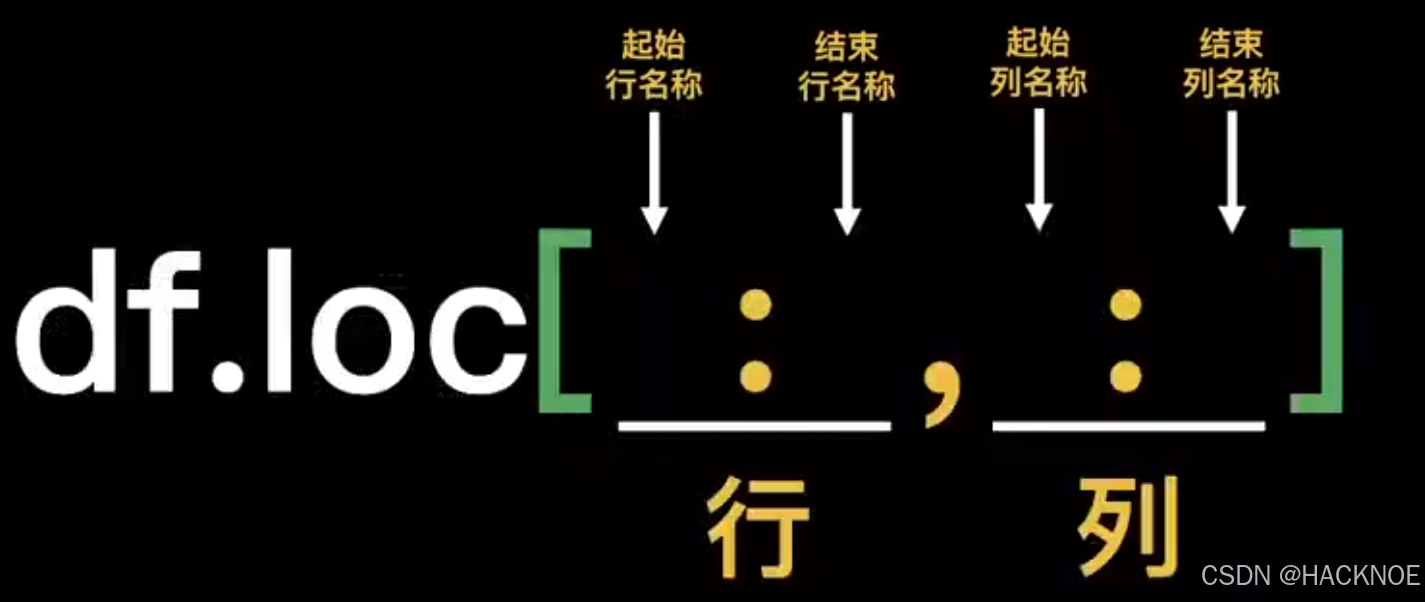
2.4.6.2.8 loc 根据行列名称定位查找
格式:
df.loc[ :,:]
按图取出如下数据:
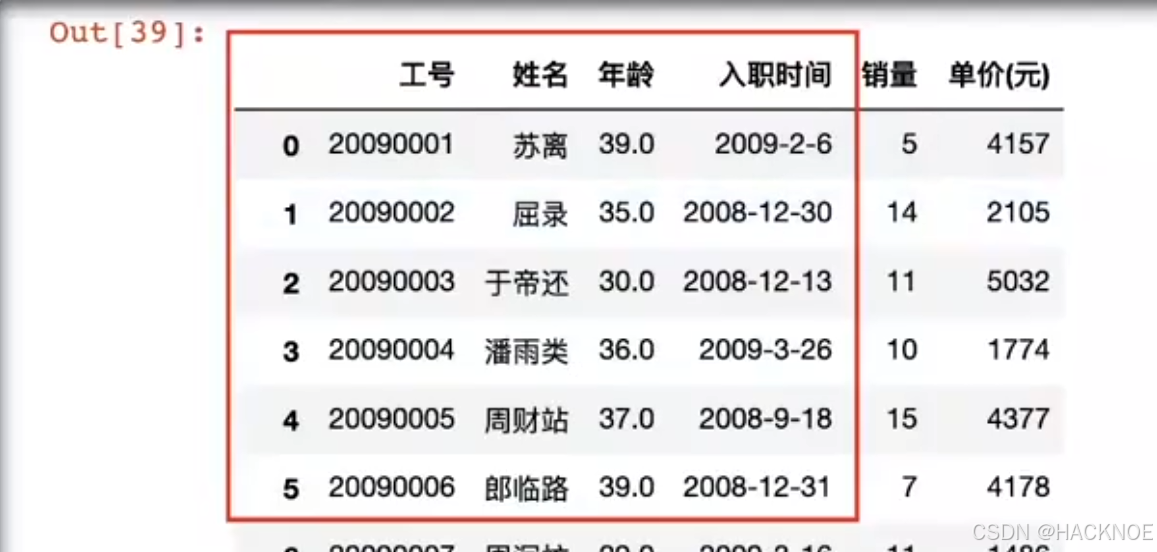
df.loc[0:5,'工号':'入职时间']
1.取一列,指定行
df.loc[0:9,'工号']
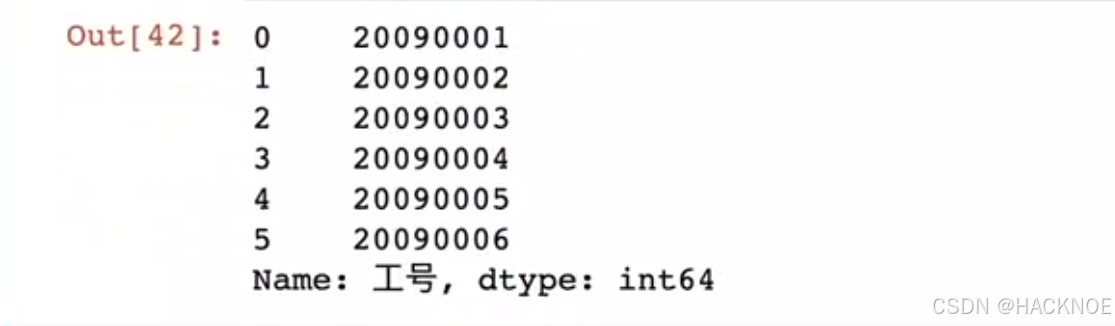
2.取一列,全部行,相当于取 series
df.loc[:,'工号']
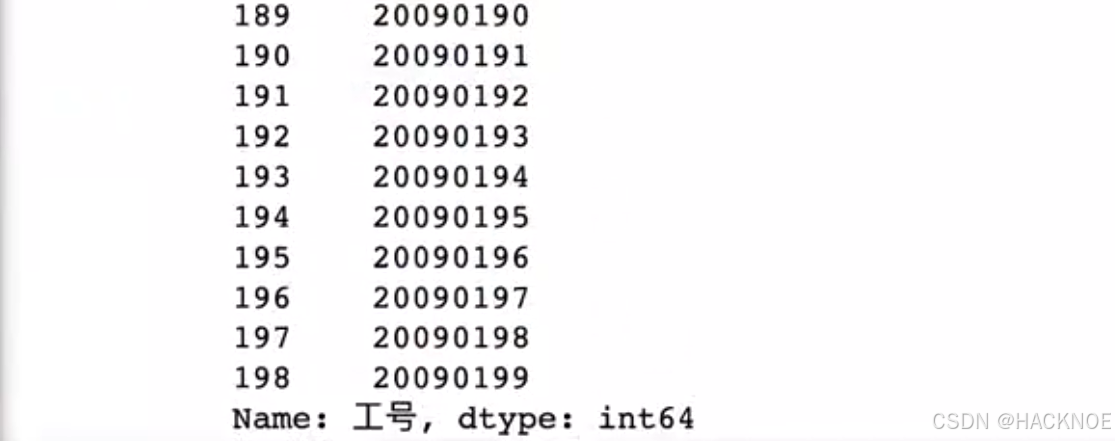
3.取一行,指定连线列
df.loc[9,'工号':'入职时间']

4.取一行,指定不连续列
df.loc[9,['工号','入职时间']]

2.4.6.2.9 iloc 根据索引定位查找
格式:
df.iloc[:,:]
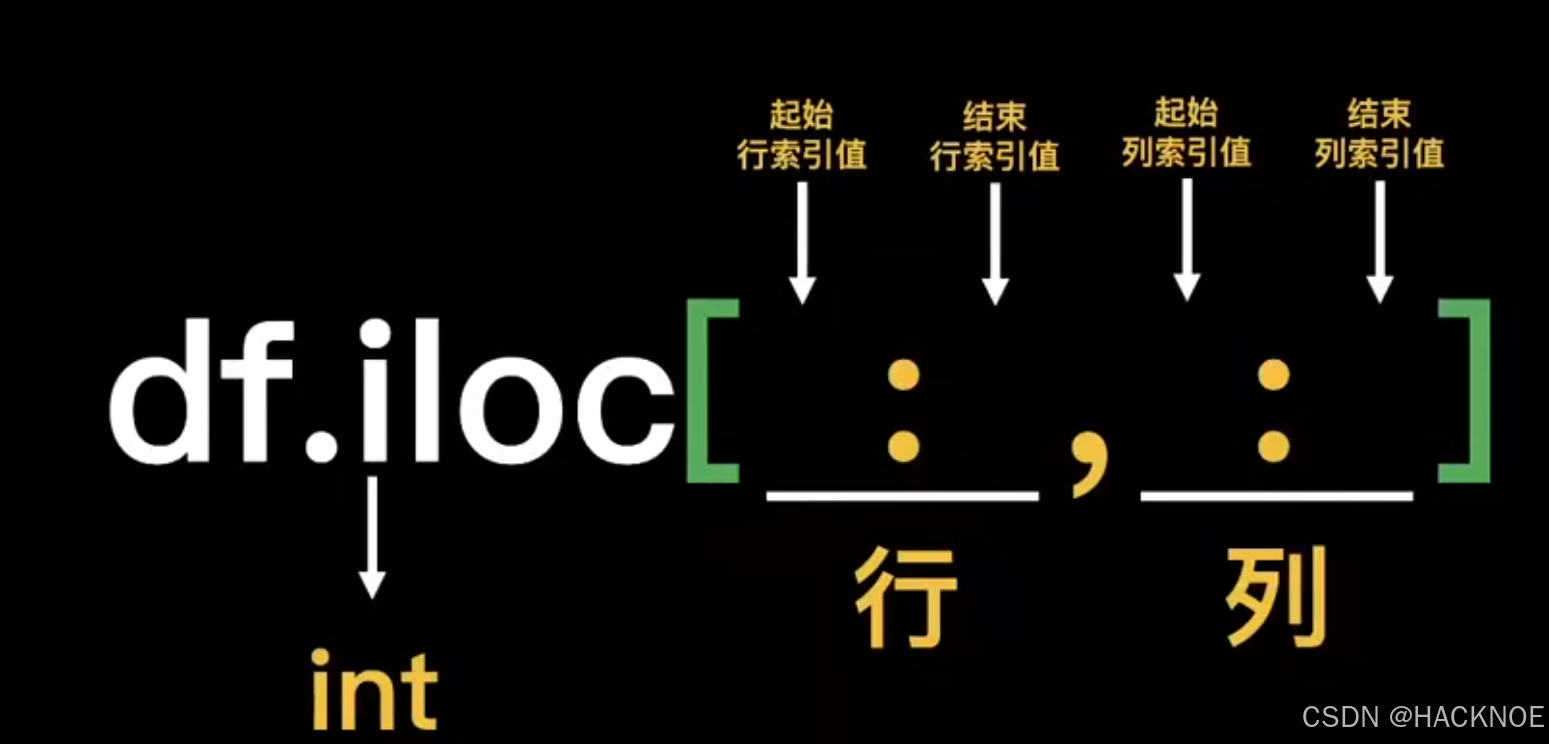
按照图中取出所需数据:
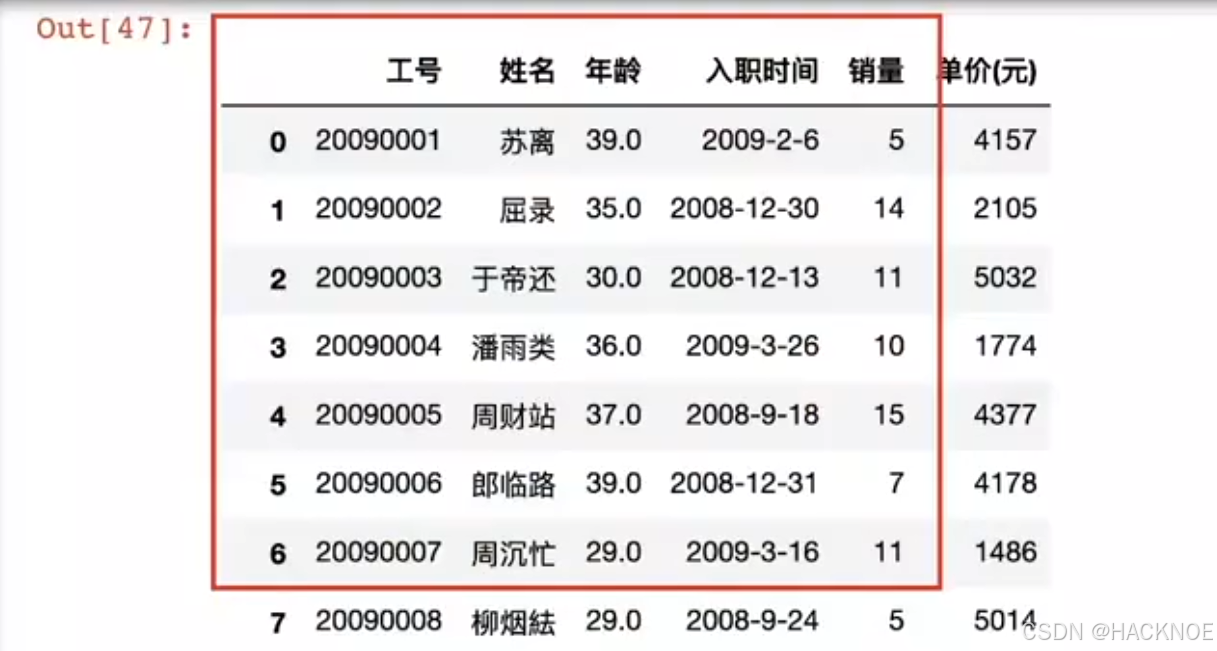
df.iloc[0:7,0:5] #包左不包右,省略顶到头
1.取一列,指定行
df.iloc[0:4,1]

2.取一列,全部行,相当于取 series
df.iloc[:,1]

3.取一行,指定连续列
df.iloc[4,1:6]

4.取一行,指定不连续列
df.iloc[5,[1,6]] #报错 取这样的数据用标签取而不是索引
5.取一行,全部列
df.iloc[46,:]

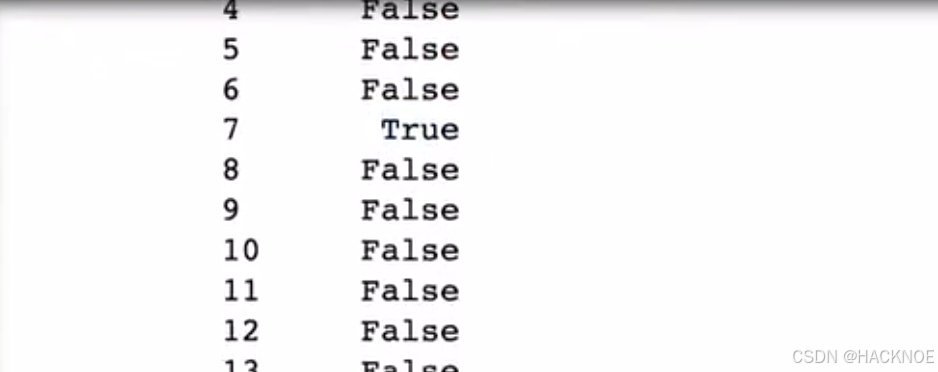
2.4.6.2.10 布尔值索引
最后我们可以采用判断指令(Boolean indexing)进行选择,我们可以约束某项条件然后选择出当前所有数据
df['年龄'] == 30

df[df['年龄'] == 30]
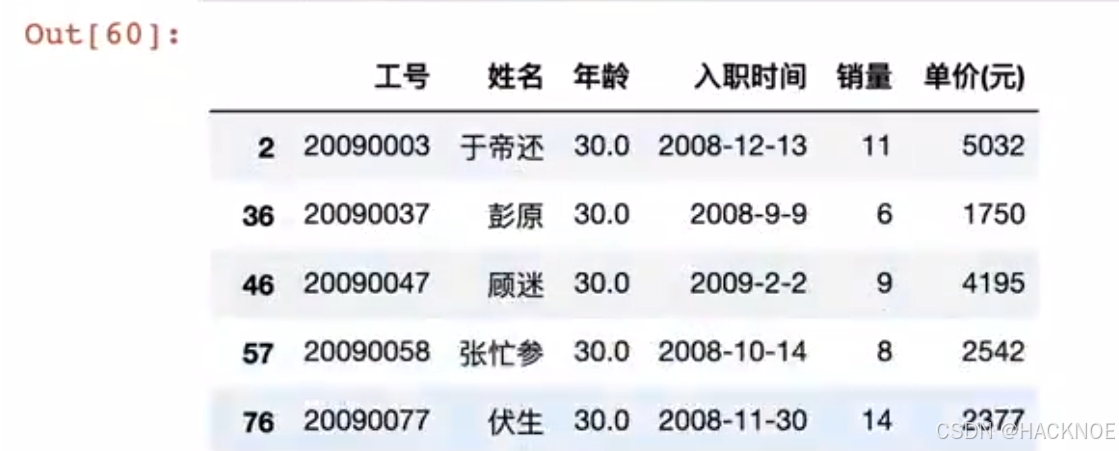
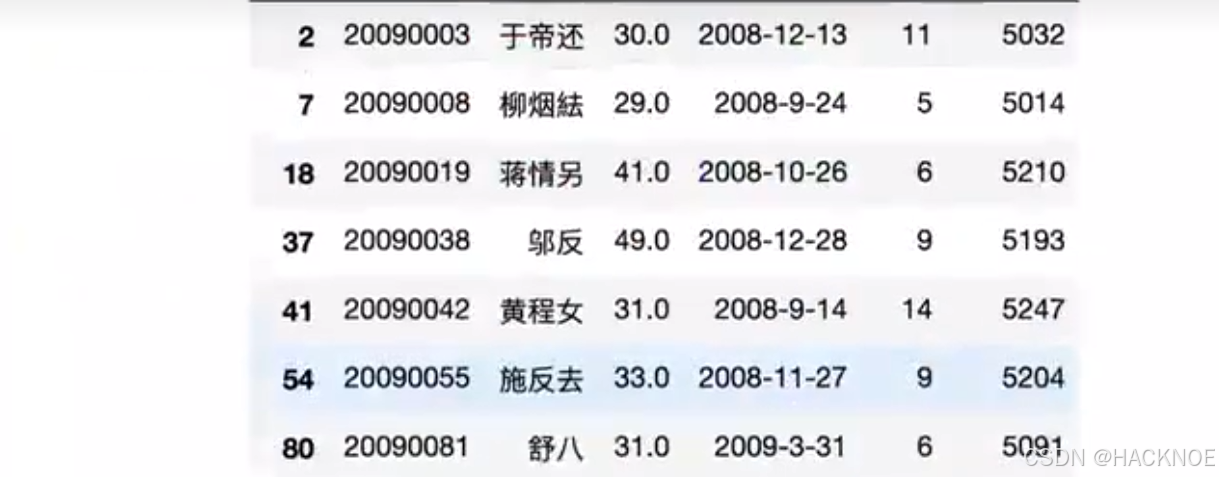
df['单价(元)'] > 5000
df[df['单价(元)'] > 5000]
2.4.6.3 Pandas数据修改
2.4.6.3.1 list修改列名
df.columns = ['num','name','age','time','sale' ,'price']
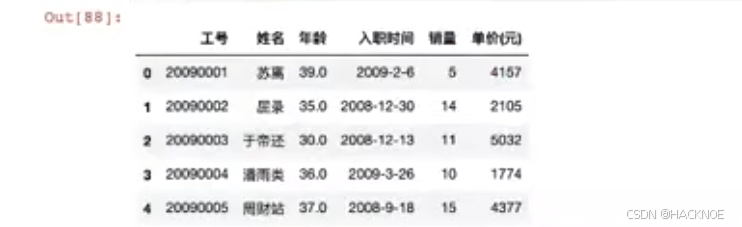
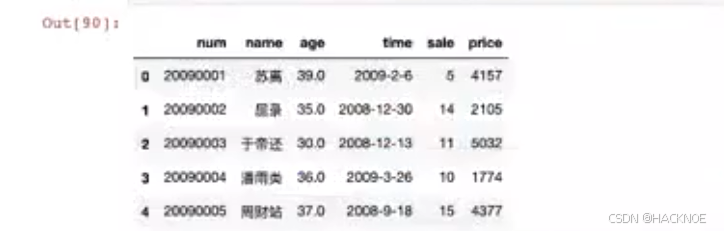
2.4.6.3.2 rename修改列名
df.rename(columns={'num'='工号','name'='姓名','age'='年龄','time'='入职时间','sale'='销量','price'='单价(元)'},inplace=True) #把英文名称改回汉字
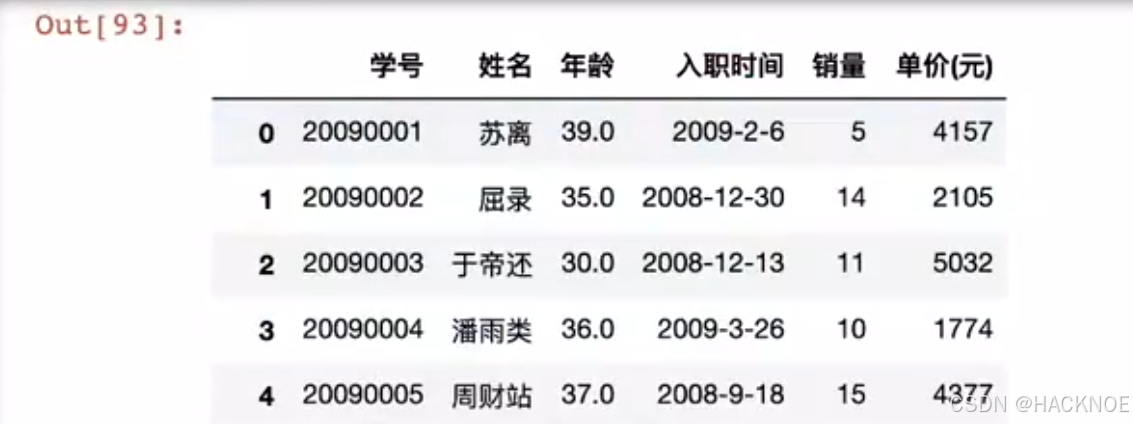
2.4.6.3.3 set_index修改索引
df.set_index('工号') #工号成了索引
df.set_index('工号',inplace=True) #工号成了索引
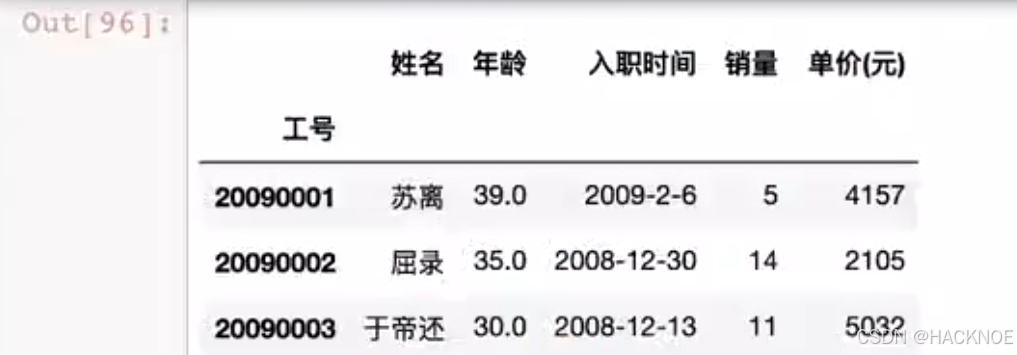
df.reset_index(inplace=True) # 取消刚才的赋值操作
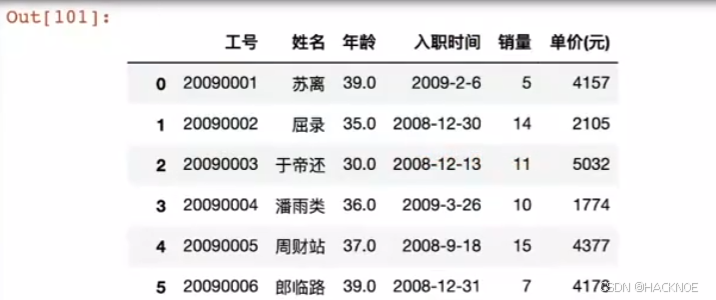
多次reset ,drop就是舍弃丢掉,当你想重新设置index的时候,就可以用到
df.reset_index(inplace=True,drop=True) # 取消刚才的赋值操作
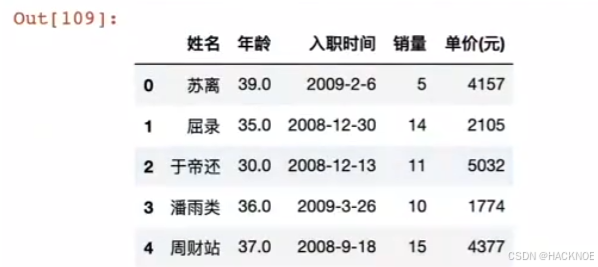
2.4.6.3.4 按列修改值
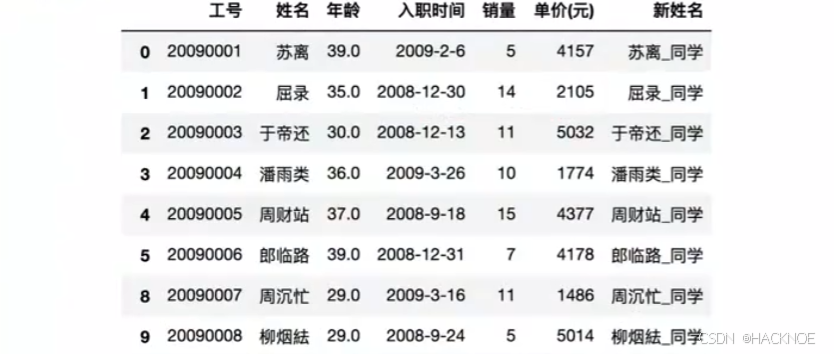
df['姓名'] + ['_同学'] #字符串列可以直接加上字符串,对整列进行操作

在原表修改
df['姓名'] = df['姓名'] + ['_同学']
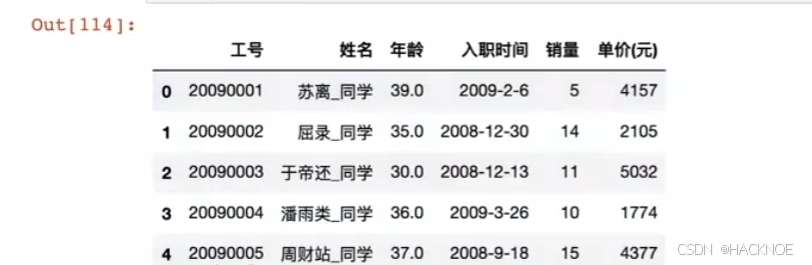
2.4.6.3.5 切片操作
字符串操作:长度
df['姓名'].str.len()

字符串操作:切分 split()
df['姓名'].str.split('_',expand=True)[0]

将姓名_同学切分后重新赋值
df['姓名'] = df['姓名'].str.split('',expand=True)[0]
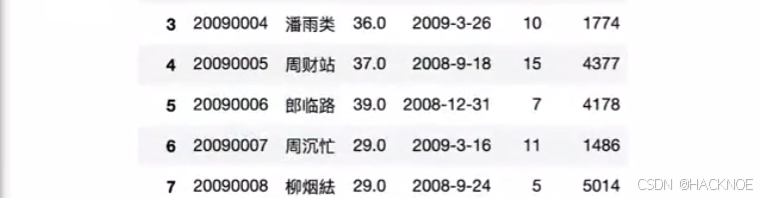
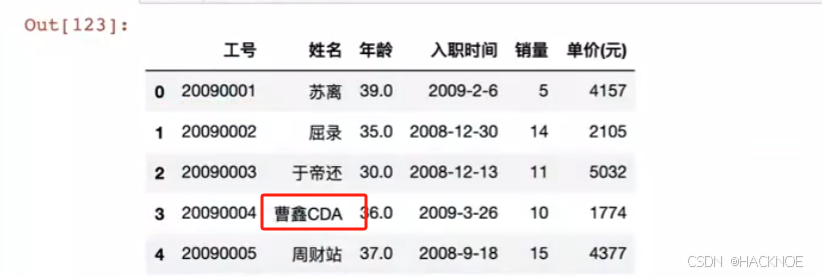
#用 loc 标签来选取修改
df.loc[3,'姓名']='曹鑫CDA'
#用iloc 索引来选取修改
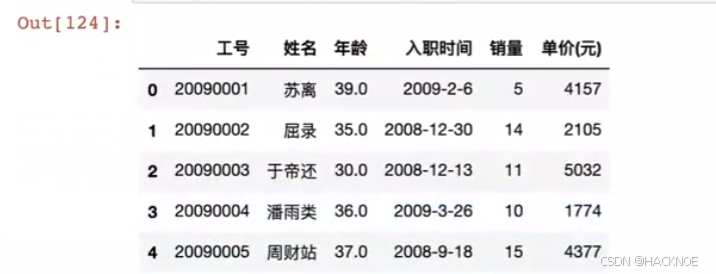
df.iloc[3,1]='潘雨类'
2.4.6.3.5 条件设置
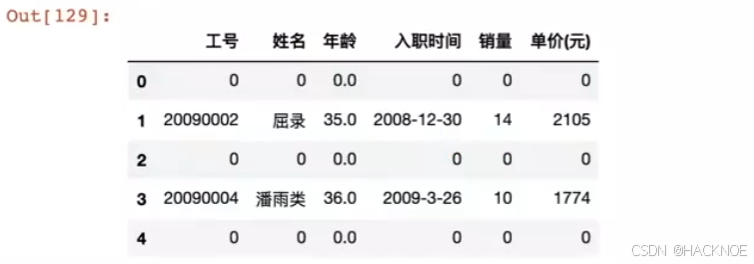
如果现在的判断条件是这样,我们想要更改B中的数,而更改的位置是取决于A的,对于A大于4的位置.更改B在相应位
df['单价(元)'] > 4000

df[df['单价(元)'] > 4000] = 0
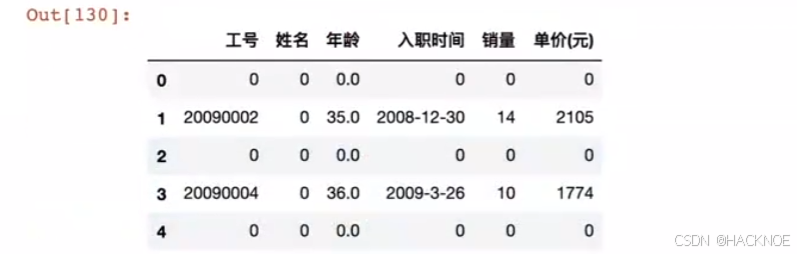
df.loc[df['年龄']>30,'姓名'] = 0 #年龄>30的姓名改为0
2.4.6.3.5 按列修改类型
#一列一列的处理,str,float,int
df['工号'] = df['工号'].astype('str')
df .dtypes
#一列一列的处理,时间
df['入职时间']= pd.to_datetime(df['入职时间'])
df .dtypes
2.4.6.4 Pandas数据增加
2.4.6.4.1 使用 loc按行增加
df.loc[199]=[1,1,1,1,1,1]
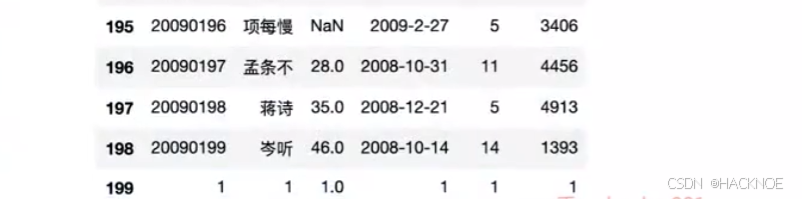
2.4.6.4.1 使用 loc按列增加
在原始上面改还是新建一列呢?
df['新姓名'] = df['姓名'〕+ ' 同学'
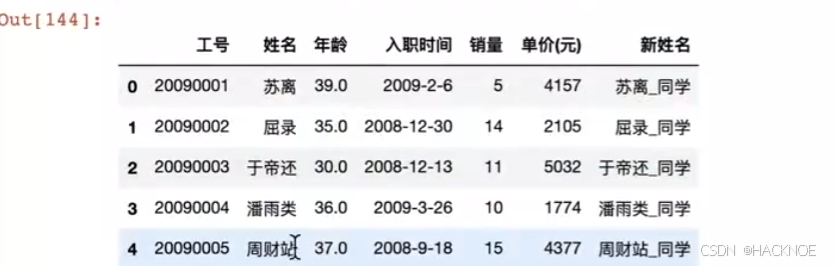
2.4.6.3 Pandas数据拼接
dfl = df.loc[0:5,:]
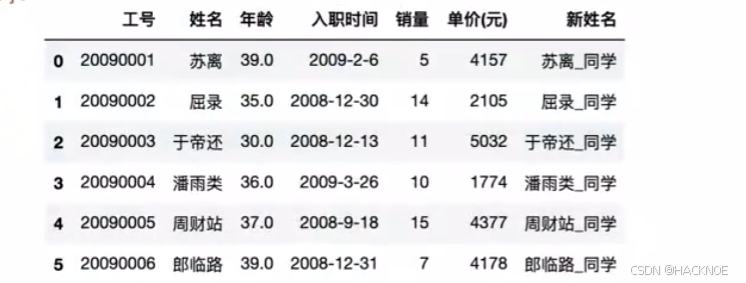
df2 =df.loc[4:10,:]
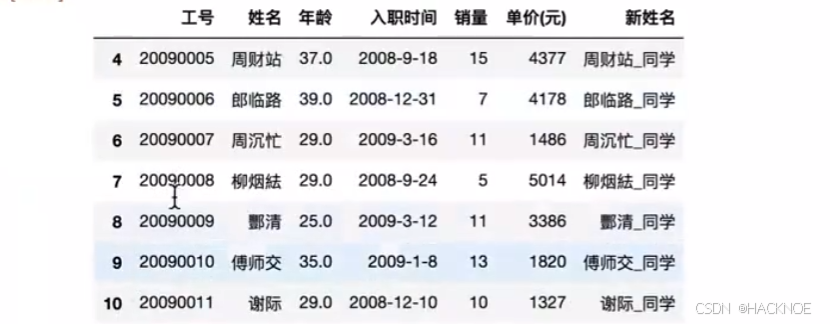
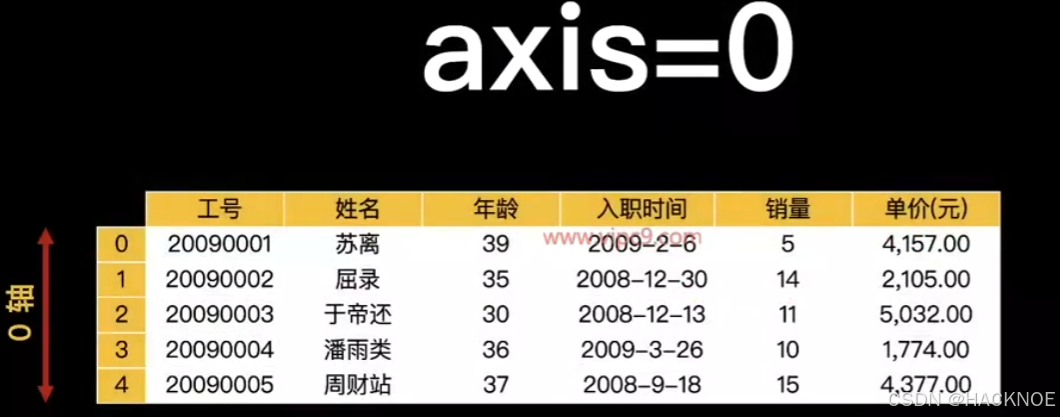
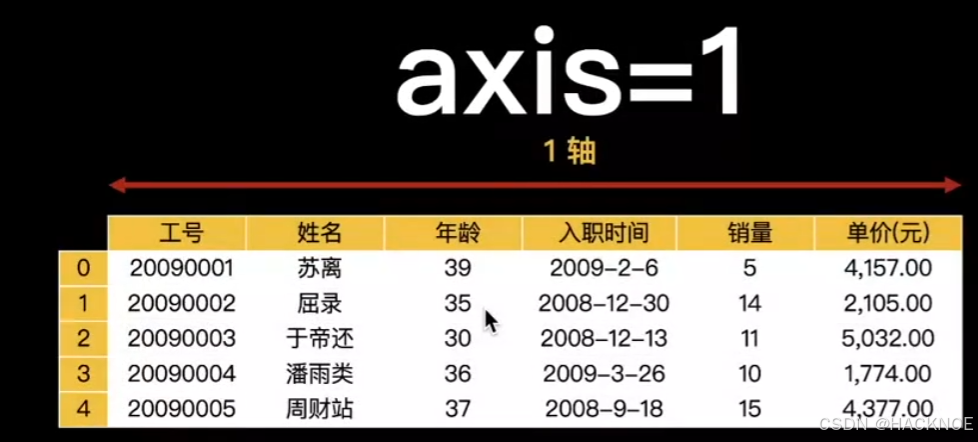
pd.concat([dfl,df2],axis=0) #axis=0 上下拼接 删除 0-5 4-10
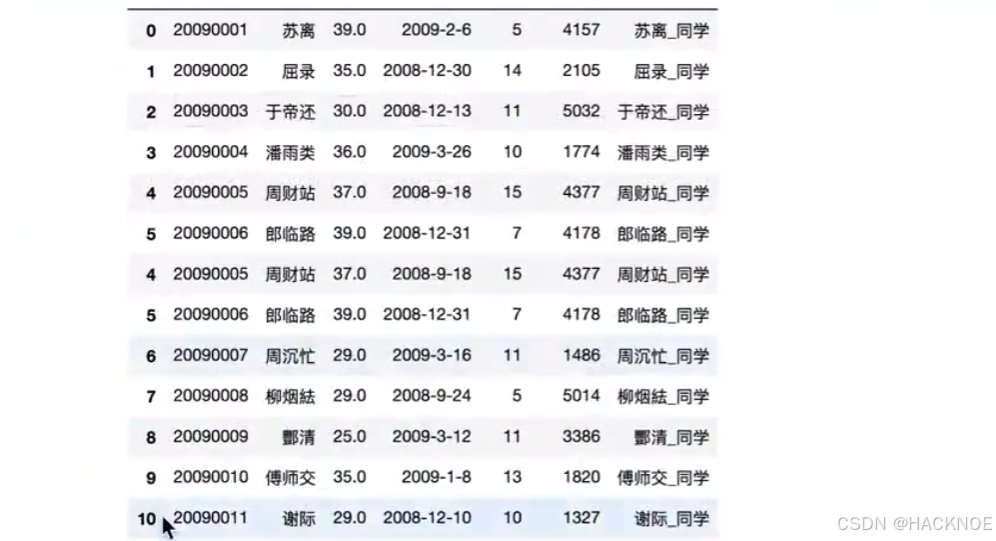
pd.concat([dfl,df2],axis=0,ignore_index=True ) #ignore_index重新生成index,拼接的index是乱的
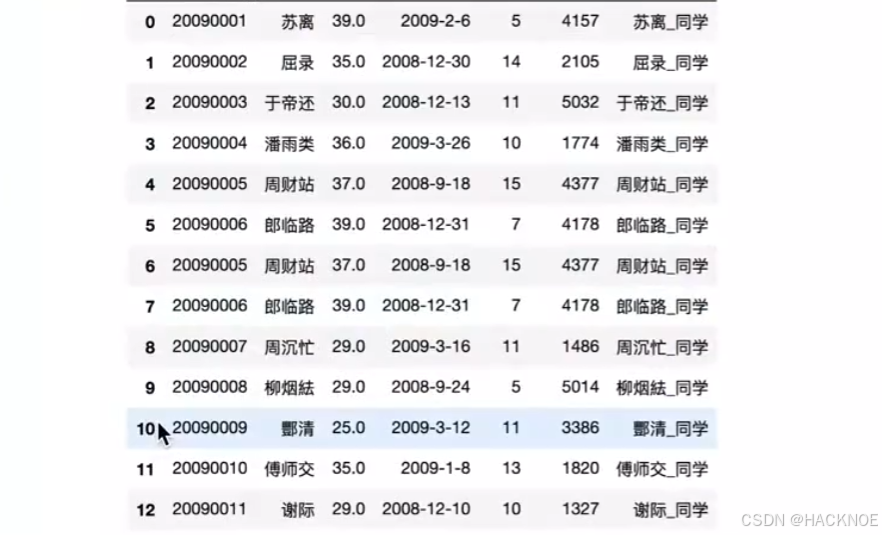
df4 =pd.concat([dfl,df2],axis=1) #axis=1 横向拼接
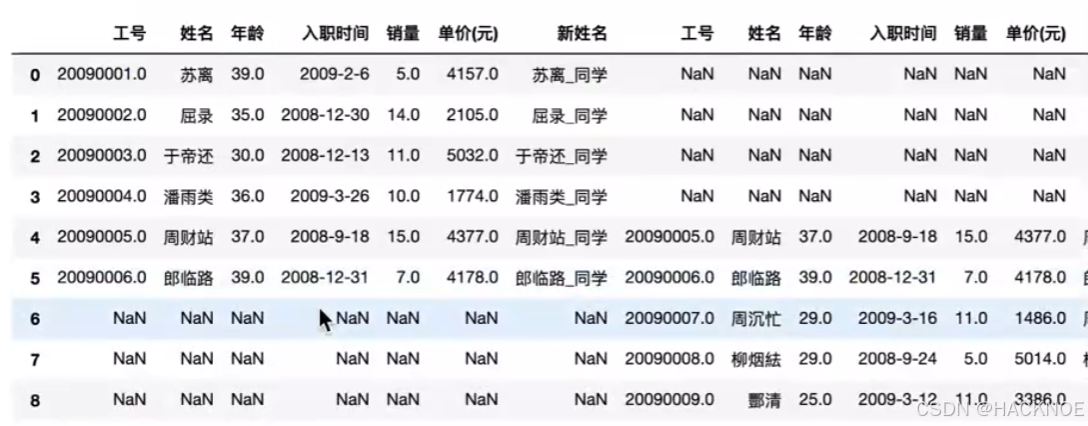
2.4.6.3 Pandas数据删除
数据清洗是对一些没有用的数据进行处理的过程,很多数据集存在数据缺失、数据格式错误、错误数据或重复数据的情况,如果要使数据分析更加准确,就需要对这些没有用的数据进行处理
在这个教程中,我们将利用 Pandas包来进行数据清洗。
请观察下面表格
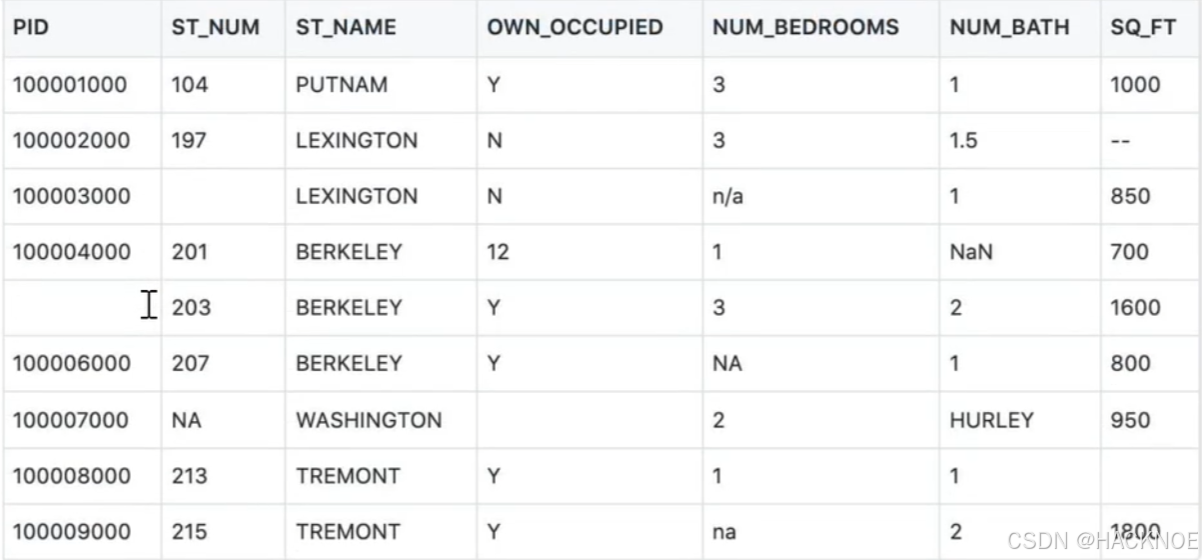
表包含了四种空数据
- n/a
- NA
- na
- - -
2.4.6.3.1 删除空值数据
如果我们要删除包含空字段的行,可以使用 dropna()方法语法格式如下:
DataFrame.dropna(axis=0,how='any',thresh=None,subset=None,inplace=False)
- axis:默认为 0,表示逢空值剔除整行,如果设置参数 axis=1表示逢空值去掉整列。
- how:默认为’any’如果一行(或一列)里任何一个数据有出现 NA 就去掉整行,如果设置 how=‘all’ 一行(或列)都是 NA 才去掉这整行。
- thresh:设置需要多少非空值的数据才可以保留下来的。
- subset:设置想要检查的列。如果是多个列,可以使用列名的 list 作为参数。
- inplace:如果设置 True,将计算得到的值直接覆盖之前的值并返回 None,修改的是源数据
我们可以通过 isnull()判断各个单元格是否为空
df['年龄'].isnull()

df[df['年龄'].isnull()] #取出空值的行
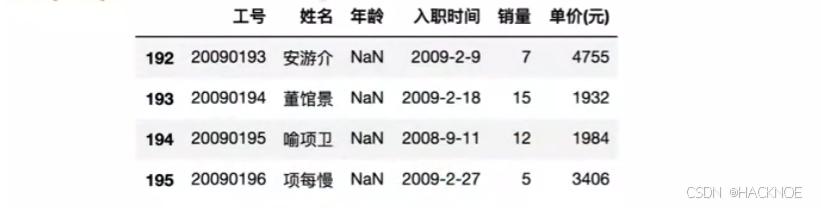
df[df['年龄'].isnu1l()| df['入职时间'].isnu11()]
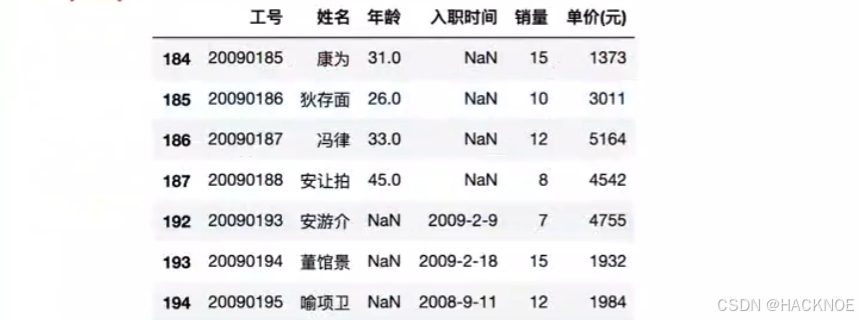
以上例子中我们看到 Pandas 把 n/a 和 NA 当作空数据,na 不是空数据,不符合我们要求,我们可以指定空数据类型:
import pandas as pd
missing_values =['n/a","na',"--"]
df = pd.read_csv('property-data.csv',na_values = missing_values)
print(df['NUM_BRDROOMS'])
print(df['NUM_BRDROOMS'].isnull())
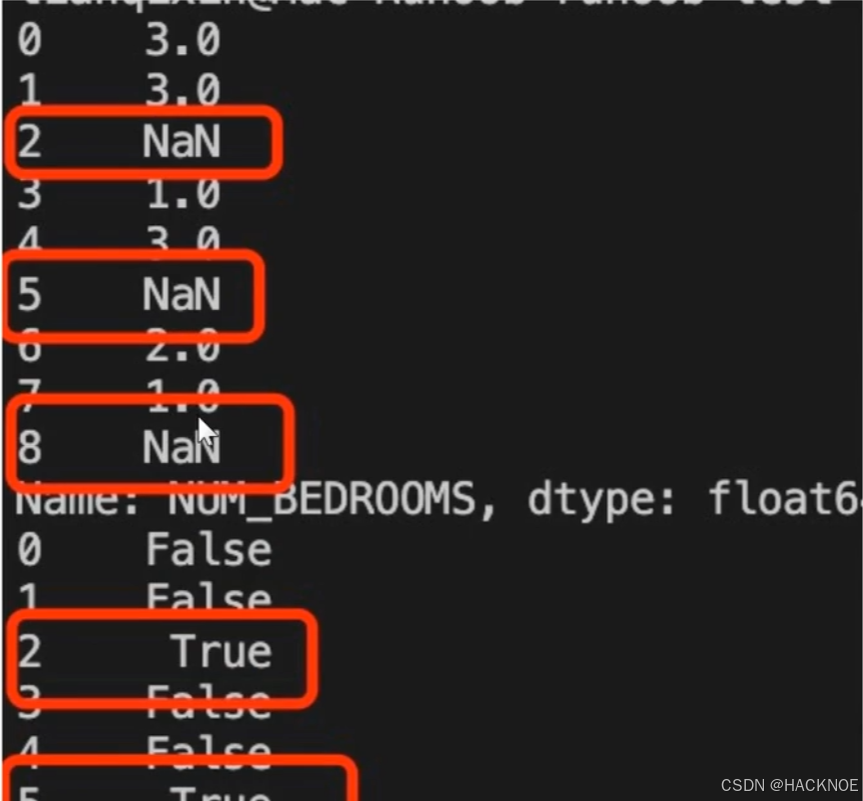
接下来的实例演示了删除包含空数据的行
df.dropna(axis=1,how='any')
'any':只要存在NaN 就 drop 掉:'al1'必须全部是 NaN 才 drop
import pandas as pd
df = pd.read_csv('property-data.csv')
new_df = df.dropna()
print(new_df.to_string())

注意:默认情况下,dropna()方法返回一个新的DataFrame,不会修改源数据。
如果你要修改源数据 DataFrame,可以使用 inplace =True 参数:
import pandas as pd
df = pd.read_csv('property-data.csv')
df.dropna(inplace=True)
print(df.to_string())
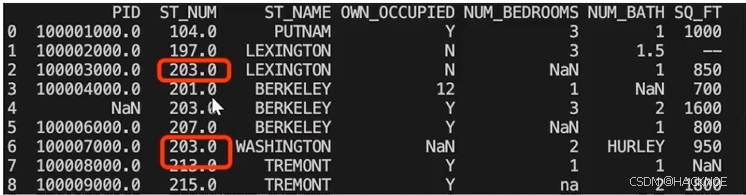
我们也可以移除指定列有空值的行:移除 ST NUM 列中字段值为空的行
import pandas as pd
df = pd.read_csv('property-data.csv')
df.dropna(subset=['ST NUM'],inplace=True)
print(df.to_string())
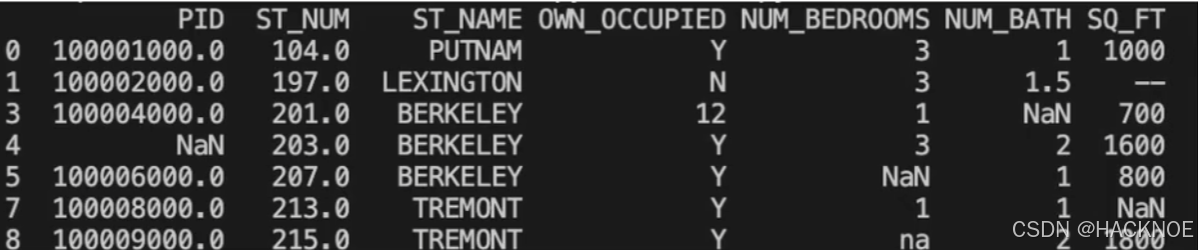
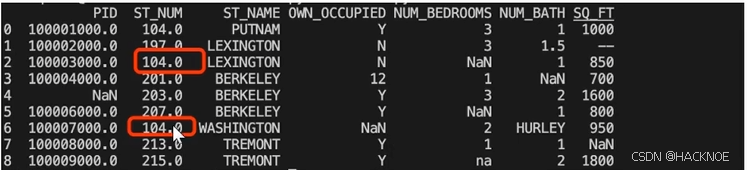
我们也可以 filna() 方法来替换一些空字段,使用 12345 替换空字段
import pandas as pd
df = pd.read_csv('property-data.csv')
df.fillna(12345,inplace =True)
print(df.to_string())
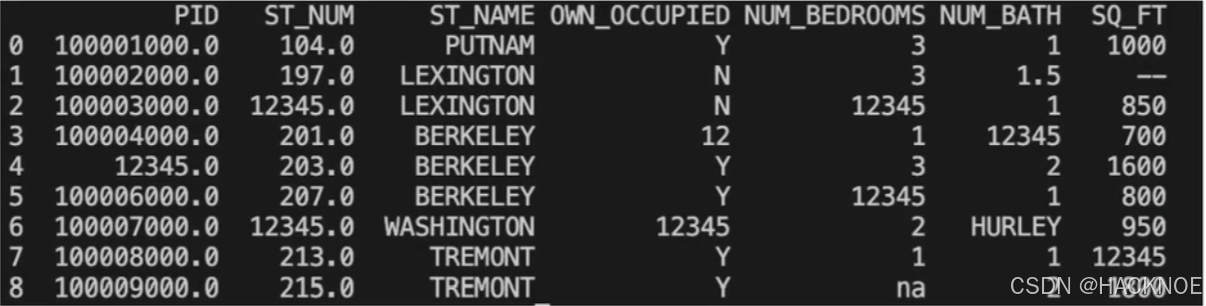
我们也可以指定某一个列来替换数据,使用 12345 替换 PID 为空数据:
import pandas as pd
df = pd.read_csv('property-data.csv')
df['PID'].fillna(12345,inplace = True)
print(df.to_string())
替换空单元格的常用方法是计算列的均值、中位数值或众数。
Pandas使用 mean()、median()和 mode()方法计算列的均值(所有值加起来的平均值)、中位数值(排序后排在中间的数)和众数(出现频率最高的数)
使用 mean()方法计算列的均值并替换空单元格
import pandas as pd
df = pd.read_csv('property-data.csv')
x= df["ST NUM"].mean()
df["ST NUM"].fillna(x,inplace = True)
print(df.to_string())
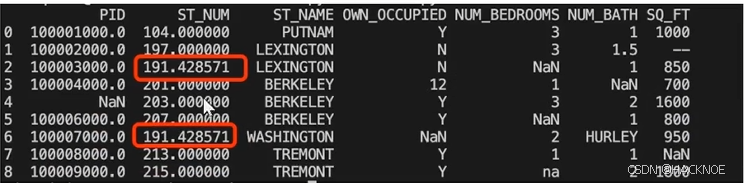
使用 median()方法计算列的中位数并替换空单元格
import pandas as pd
df = pd.read_csv('property-data.csv')
x= df["ST NUM"].median()
df["ST NUM"].fillna(x,inplace = True)
print(df.to_string())
使用 mode()方法计算列的众数并替换空单元格
import pandas as pd
df = pd.read_csv('property-data.csv')
x= df["ST NUM"].mode()
df["ST NUM"].fillna(x,inplace = True)
print(df.to_string())
2.4.6.3.2 删除格式错误数据
数据格式错误的单元格会使数据分析变得困难,甚至不可能,我们可以通过包含空单元格的行,或者将列中的所有单元格转换为相同格式的数据。
以下实例会格式化日期
import pandas as pd
#第三个日期格式错误
data ={
"Date":['2020/12/01','2020/12/02','2020/12/26'],
"duration":[50,40,45]
}
df = pd.DataFrame(data,index=["day1","day2","day3"])
df["Date"] = pd.to_datetime(df["Date"])
print(df)
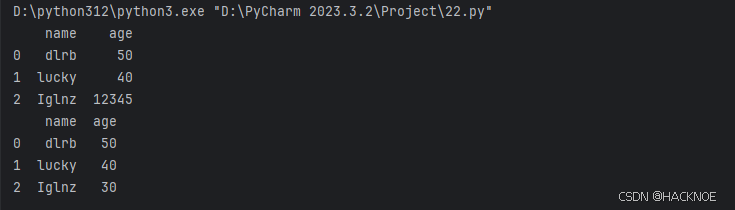
2.4.6.3.3 删除错误数据
数据错误也是很常见的情况,我们可以对错误的数据进行替换或移除。
以下实例会替换错误年龄的数据
import pandas as pd
person = {
"name":['dlrb','lucky','Iglnz'],
"age":[50,40,12345]# 12345 年龄数据是错误的
}
df = pd.DataFrame(person)
print(df)
df.loc[2,'age']=30 # 修改数据
print(df.to_string())
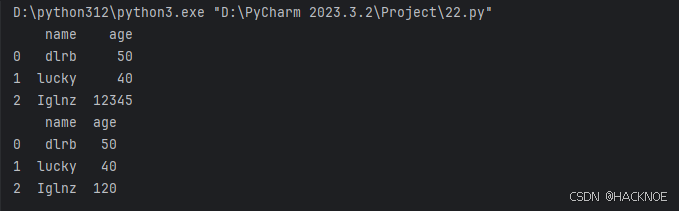
也可以设置条件语句:
将 age 大于 120 的设置为 120:
import pandas as pd
person = {
"name":['dlrb','lucky','Iglnz'],
"age":[50,40,12345]# 12345 年龄数据是错误的
}
df = pd.DataFrame(person)
print(df)
for i in df.index:
if df.loc[i,'age'] > 120 :
df.loc[i,'age'] = 120
print(df.to_string())
将 age 大于 120 的删除:
import pandas as pd
person = {
"name":['dlrb','lucky','Iglnz'],
"age":[50,40,12345]# 12345 年龄数据是错误的
}
df = pd.DataFrame(person)
print(df)
for i in df.index:
if df.loc[i,'age'] > 120 :
df.drop(i,inplace=True)
print(df.to_string())
2.4.6.3.4 删除重复数据
如果我们要清洗重复数据,可以使用 duplicated()和drop_duplicates()方法。
如果对应的数据是重复的,duplicated()会返回 True,否则返回 False。
import pandas as pd
person ={
"name":['dlrb','lucky','lucky','glnz'],
"age":[50,0,40,23]
}
df = pd.DataFrame(person)
print(df)
print(df.duplicated())
df.drop duplicates()
print(df)
df.drop duplicates() #快速删除重复数据

按列删除
df.drop(labels='工号',axis=1)
按行删除
df.drop(labels=1,axis=0)
2.4.6.4 Pandas数据排序
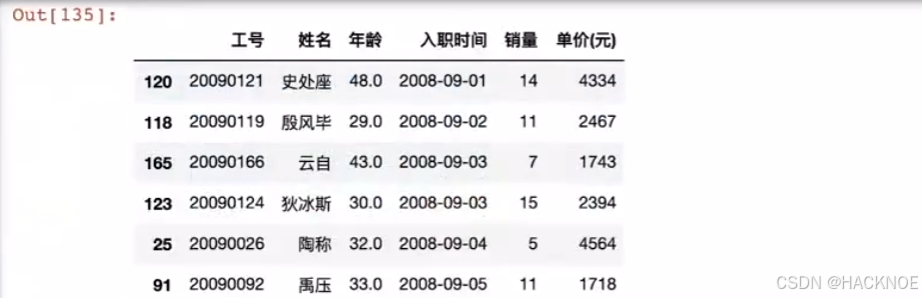
df.sort_values(by=['入职时间'],ascepding = 1) # by参数指定按照什么进行排 acsending参数指定是顺序还是逆序,1顺序,0逆序
df.sort _values(by=['入职时间','销量','年龄'],ascending=[1,1,1])