【文献阅读】Transformer的前馈层是键值记忆系统
发表年份: 2020年
作者: Mor Geva, Roei Schuster, Jonathan Berant, Omer Levy
作者机构: 特拉维夫大学Blavatnik计算机科学学院、艾伦人工智能研究所、康奈尔理工
期刊/会议: 本文发表在 EMNLP 2020 (2020 Conference on Empirical Methods in Natural Language Processing)。
期刊/会议水平: EMNLP是自然语言处理领域的顶级国际会议之一,与ACL、NAACL齐名,属于CCF-B类推荐会议,具有很高的学术声誉和影响力。
1. 研究目的
这篇论文旨在回答一个核心问题:在Transformer架构中,参数占比高达三分之二的前馈层,其实际功能到底是什么?
尽管自注意力机制被广泛研究,但前馈层的作用却一直被忽视。本研究试图揭开这个“黑箱”,探究前馈层在语言模型中扮演的具体角色。
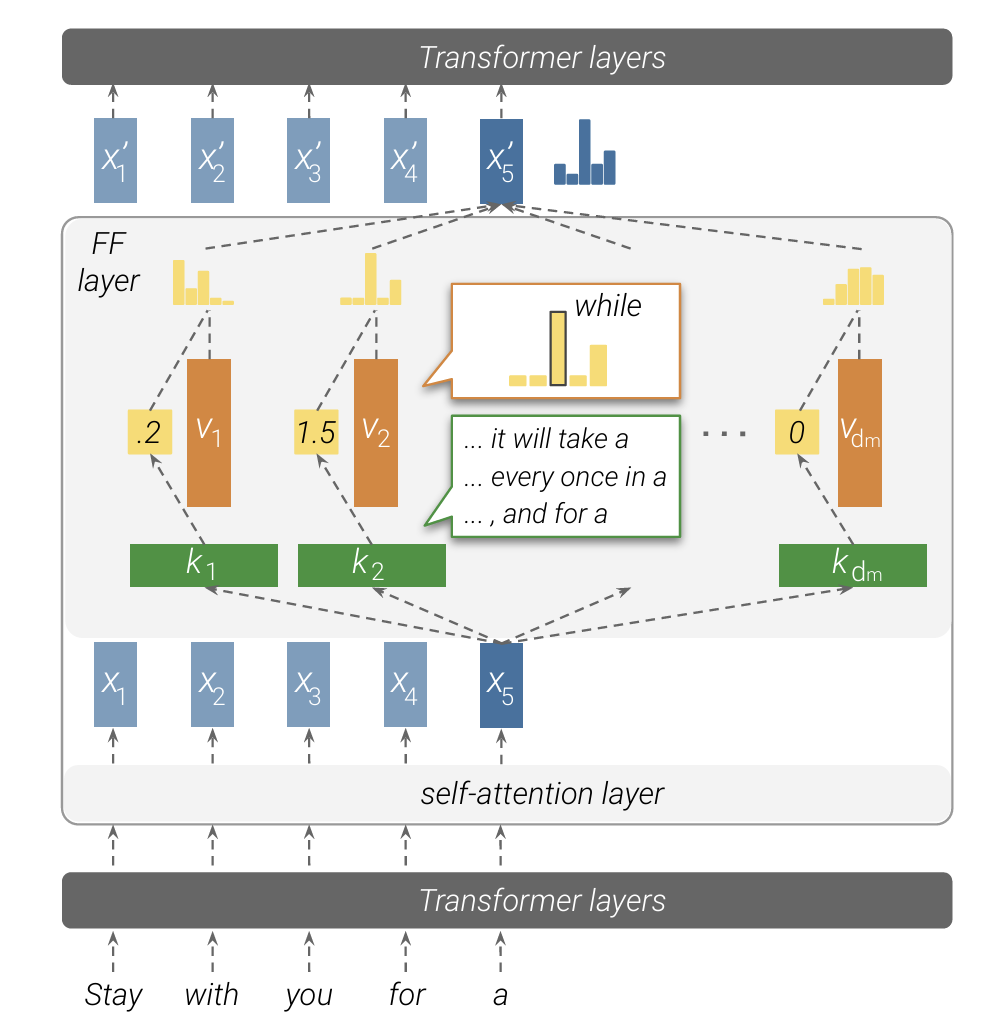
2. 研究方法
作者采用了一种 “逆向工程”式的分析方法,主要步骤包括:
1 理论类比:
首先,从数学形式上论证了前馈层与“键值记忆网络”的等效性。前馈层的第一层权重矩阵可被视为 “键”,用于检测输入模式;第二层权重矩阵可被视为 “值”,用于存储与模式对应的输出信息。
论证的关键在于,只需将标准前馈层的公式稍作改写,其形式就会与键值记忆网络几乎一模一样。
1. 标准Transformer的前馈层
一个Transformer的前馈层通常这样表示(忽略偏置项):
FF(x) = W₂ · ReLU(W₁ · x)
其中:
x是输入向量(例如,经过自注意力层后的表示)。W₁是一个[d_m × d]的矩阵(d_m是中间层的维度,通常比d大,例如d_m = 4d)。ReLU是激活函数。W₂是一个[d × d_m]的矩阵。
现在,我们对其进行一个关键的重新解释:
将
W₁矩阵视为K(键矩阵)。它的每一行k_i都是一个键向量,代表一个模式探测器。将
W₂矩阵的转置W₂ᵀ视为V(值矩阵)。它的每一行v_i都是一个值向量,存储着与键k_i对应的信息。
那么,前馈层的计算可以重写为:
FF(x) = f(x · Kᵀ) · V
其中:
K = W₁(键矩阵)V = W₂ᵀ(值矩阵)f是ReLU函数x · Kᵀ的结果是一个向量,其中的每个元素是输入x与每个键k_i的内积。f(x · Kᵀ)是经过ReLU激活后的向量,我们称之为 记忆系数向量m。它的每个元素m_i表示第i个记忆单元的非负的、未归一化的激活强度。
2. 神经键值记忆网络
一个经典的神经键值记忆网络是这样工作的:
MN(x) = softmax(x · Kᵀ) · V
其中:
K是键矩阵。V是值矩阵。softmax(x · Kᵀ)计算的是一个归一化的注意力分布,表示对于输入x,每个记忆单元的权重是多少。输出是所有值向量的加权和。
3. 等效性对比
现在,将两个公式并列放置:
| 组件 | 前馈层 | 键值记忆网络 | 等效性说明 |
|---|---|---|---|
| 核心操作 | FF(x) = f(x · Kᵀ) · V | MN(x) = softmax(x · Kᵀ) · V | 结构完全一致:都是“计算输入与键的相似度 -> 用相似度加权值 -> 输出加权和”。 |
| 键矩阵 | K = W₁ | K | 完全等效。都是用于检测输入模式的参数。 |
| 值矩阵 | V = W₂ᵀ | V | 完全等效。都是用于存储信息的参数。 |
| 相似度函数 | ReLU (或 GeLU 等) | softmax | 这是唯一的、关键的区别。 |
对“唯一区别”的深入解释
这个区别是否颠覆了它们的等效性?作者认为没有,理由如下:
功能相似性:无论是
ReLU还是softmax,它们都扮演了 “门控”或“选择” 的角色。softmax:通过归一化,产生一个概率性的权重分布,选择“在多大程度上”使用每个记忆。ReLU:通过将负值置零,实现了一个 “赢家通吃”式的稀疏选择。它只激活那些与输入高度正相关的键,并直接使用其(未归一化的)内积作为强度系数。这可以被看作是一种非概率性的、稀疏的注意力机制。
非负性:
ReLU的输出是非负的,这与注意力权重的性质(非负)相符,确保了最终的输出是值向量的一个正向组合,而不是相互抵消。实证支持:论文后续的实验(如发现每个键对应可解释的输入模式,值对应输出分布)为这种数学上的类比提供了强有力的实证支持。如果数学形式上的相似没有功能上的对应,这些发现就不会如此明显。
通过简单的重新参数化(将 W₁ 视为 K,将 W₂ᵀ 视为 V),作者从数学形式上清晰地表明,前馈层与键值记忆网络执行了完全相同的核心操作:基于输入与键的匹配度,从值中读取信息并组合。
唯一的区别在于激活函数(ReLU vs softmax),但这并不影响其作为“基于内容寻址的记忆”的本质。这个简洁而有力的论证,为后续深入分析前馈层中到底“记忆”了什么内容,奠定了坚实的理论基础。
2 模式识别:
针对一个训练好的Transformer语言模型(在WikiText-103上训练),他们为每个前馈层的每个“键”单元,从训练集中找出使其激活值最高的输入文本片段(称为“触发示例”)。
这个方法的核心可以概括为:对于模型中的每一个特定的“键”,在庞大的训练数据中进行一次“海选”,找出最能激活它的那些输入文本。
下面是具体、详细的步骤:
第一步:确定分析目标
模型:一个已经在WikiText-103数据集上预训练好的Transformer语言模型(例如论文中使用的Baevski & Auli, 2019的模型)。
目标组件:模型中的所有前馈层。假设模型有L层(如L=16),每层的前馈网络有d_m个神经元(如d_m=4096),那么总共有 L × d_m 个待分析的“键”(如16 * 4096 = 65,536个)。
第二步:准备数据与输入表示
数据源:使用模型训练时所使用的训练集(WikiText-103的训练集)。这是因为他们假设记忆中的模式来源于训练数据。
数据预处理:将训练文本分割成单个的句子,以简化后续的注释和分析工作。
生成输入前缀:对于一个句子
"I love dogs",模型在训练时会依次处理多个前缀:输入
"I",预测"love"输入
"I love",预测"dogs"输入
"I love dogs",预测下一个词(可能是句号或下一个句子的词)
所有这些前缀["I", "I love", "I love dogs"]都会被考虑在内。
第三步:计算记忆系数(激活值)
这是最核心的计算步骤。对于每一个特定的键(例如,第ℓ层的第i个神经元,记为 kᵢℓ),执行以下操作:
前向传播:将训练集中的每一个句子前缀
x输入模型,并前向传播直到第ℓ层的输出。得到该前缀在第ℓ层的隐藏状态表示x̄ℓ。重要提示:
x̄ℓ是经过该层自注意力机制和层归一化处理后的结果,它包含了上下文信息,是前馈层的输入。
计算内积:计算这个隐藏状态
x̄ℓ与目标键kᵢℓ的内积(dot product)。score = x̄ℓ · kᵢℓ这个内积反映了输入
x̄ℓ与模式kᵢℓ的匹配程度。
应用ReLU:将内积通过ReLU激活函数,得到最终的记忆系数。
activation = ReLU(x̄ℓ · kᵢℓ)ReLU函数将所有负值置零,意味着只有与键向量方向大致相同的输入(正相关)才会被激活。
第四步:排序与检索
在为键
kᵢℓ计算完所有训练集前缀的记忆系数后,系统会将这些前缀按照它们的记忆系数从高到低进行排序。然后,取出排名最靠前的
t个前缀(例如,论文中取 top-25 用于人工分析,top-50 或 top-1 用于其他分析)。这些就是与该键kᵢℓ最相关的 “触发示例”。
总结与要点
简单来说,这个过程就是:
固定一个键,跑遍整个训练集,看看哪些文本片段让它“最兴奋”,然后把让它们最兴奋的片段找出来,看看这些片段有什么共同点。
这个方法的关键之处和优点在于:
数据驱动:它不依赖于人的先验假设,而是让训练数据自己“说话”,揭示模型实际学到的东西。
可解释性:通过观察这些 top-t 的触发示例,研究人员可以归纳出人类能够理解的、重复出现的模式(例如“以单词
press结尾”、“与军事基地相关”)。规模化:尽管他们无法分析全部6万多个键(他们采用了随机采样),但这个方法在原理上可以对整个模型的记忆进行系统的普查。
通过这种方法,论文成功地将模型中难以理解的、高维的权重参数(键 kᵢℓ),转化为了具体、可读的文本模式,从而为“Transformer前馈层是键值记忆”这一论点提供了强有力的证据。
3 人工标注:
邀请专家对这些“触发示例”进行人工分析,识别其中重复出现的、可被人理解的模式(如特定n-gram、语义主题等),并将其分类为“浅层”(语法)或“语义”模式。
第一步:准备材料
选择样本:研究人员从模型的每一层随机抽取一定数量的“键”(如每层10个)。
准备触发示例集:对于每一个被选中的键,将其在训练集中激活值最高的前25个输入文本前缀整理成一个列表。这就是专家需要分析的原材料。
第二步:专家任务与指导原则
研究人员(通常是NLP领域的研究生)会拿到这些触发示例列表,并被要求完成以下任务:
核心任务:识别重复出现的、可解释的模式。
具体指令如下:
寻找模式:仔细阅读这25个触发示例,寻找任何重复出现的规律。为了确保这个规律不是偶然,他们规定:一个模式必须至少在3个不同的触发示例中出现。这大大提高了发现的可信度。
描述模式:用清晰、简洁的自然语言描述每一个识别出的模式。
分类模式:将每一个识别出的模式分类为 “浅层” 或 “语义” 。
浅层模式:主要指基于表面形式、语法结构或词汇的规律。
例子:
以某个特定词结尾(如 ends with
"press")。包含某个特定的n-gram(如
"part of")。具有相同的词性标记序列。
语义模式:主要指基于含义、主题或语境的规律。
例子:
都是关于“军事基地”的文本。
都在描述“电视节目”。
都在表达“一部分”的关系(如
"a member of...","part of...")。
建立映射:对于每一个触发示例,专家需要明确指出它包含了哪一个或哪几个被识别出的模式。一个触发示例可能同时符合多个模式(例如,它既以
"press"结尾,同时又属于“新闻”这个语义主题)。
第三步:一个具体示例
假设专家在分析键 k^5_805 的Top-25触发示例时,看到了如下文本(取自论文附录):
"It requires players to press""The video begins at a press""Ivy, disguised as her former self, interrupts a Wayne Enterprises press""Groening told the press""The company receives bad press""Hard to go back to the game after that news"(注意这个没有“press”)
专家通过观察,可能会总结出两个模式:
| 模式ID | 描述 | 分类 | 符合该模式的示例数量 |
|---|---|---|---|
| 1 | 以单词 "press" 结尾 | 浅层 | 例如前5个和许多其他示例 |
| 2 | 与媒体、新闻或公关相关 | 语义 | 例如第2、4、5、6个示例 |
然后,专家会回去为每一个触发示例打上标签,比如:
"Groening told the press"→ 同时符合 模式1 和 模式2。"Hard to go back to the game after that news"→ 只符合 模式2。
第四步:数据分析与验证
收集完所有专家的标注后,研究人员可以进行定量分析:
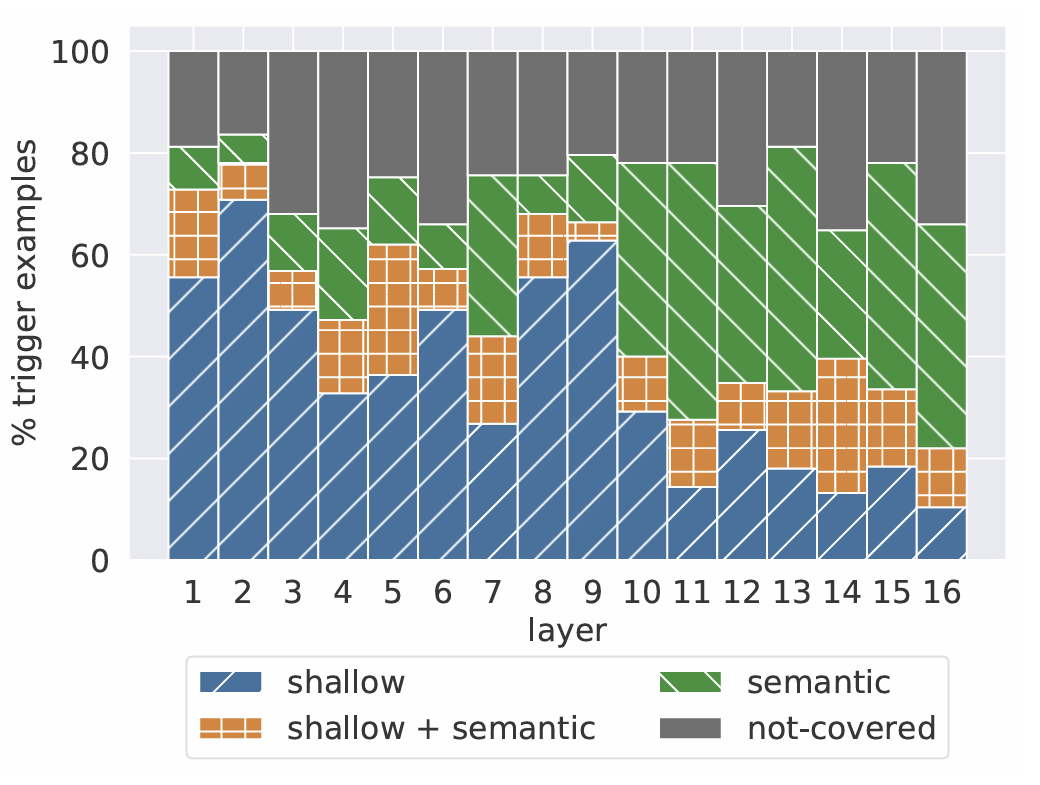
覆盖率:计算有多少百分比的触发示例能够被至少一个已识别的模式所覆盖(见图2)。结果很高(65%-80%),证明这些键确实对应着清晰的模式,而非噪声。
模式类型分布:统计每一层中,“浅层”模式和“语义”模式各自支配了多少触发示例。这直接验证了 “低层抓浅层特征,高层抓语义特征” 的假设(见图2,低层绿色多,高层蓝色多)。
模式数量:计算每个键平均对应多少个人类可识别的模式(论文中约为3.6个)。
总结
这个方法的核心优势在于其系统性和可验证性:
客观锚定:分析基于模型自己选出的、激活值最高的真实数据。
定量标准:要求一个模式至少出现在3个例子中,排除了随机性。
清晰分类:使用“浅层/语义”这一对在语言学中清晰的概念进行分类,使得发现具有理论意义。
产生洞察:这个过程不仅证实了键是模式探测器,更重要的是,它揭示了不同网络层次在学习不同类型的语言知识,这与我们对语言处理层次性的认知完美契合。
通过这种细致的人工分析,论文成功地将模型中抽象的、高维的“键”向量,翻译成了人类可以理解和讨论的具体语言模式。
4 值分析:
将“值”向量通过模型的输出嵌入矩阵投影到词表空间,形成一个概率分布,分析这个分布是否与对应“键”所触发模式的下一个真实词汇相关。
第一步:将"值"向量投影到词汇表空间
获取值向量:对于第ℓ层的第i个记忆单元,我们有其对应的值向量 vᵢℓ。这是一个d维的向量(例如d=1024)。
使用输出嵌入矩阵:语言模型通常有一个输出嵌入矩阵 E,其形状为
[d, vocab_size](例如[1024, 267744])。这个矩阵用于将最终的隐藏状态转换为词汇表上的概率分布。关键假设是:值向量 vᵢℓ 与模型的输出空间是兼容的。计算逻辑值:将值向量与输出嵌入矩阵相乘,得到一个在词汇表大小维度上的向量,可以看作是未归一化的"分数"或"逻辑值"。
logits = vᵢℓ · E这步操作的意义在于,它试探性地回答了这样一个问题:"如果这个值向量 vᵢℓ 是模型的最终输出,它会预测出哪个词?"
转换为概率分布:对得到的逻辑值向量应用softmax函数,将其转换为一个概率分布。
pᵢℓ = softmax(vᵢℓ · E)现在,我们得到了一个假设性的输出分布 pᵢℓ,它表示如果单独由这个记忆单元做决策,它会给词汇表中每个词分配多大的概率。
第二步:获取真实世界的参考答案——"下一个词"
现在,我们需要一个真实世界的参考标准,来判断这个分布 pᵢℓ 是否有意义。这个参考标准就来自第一步中找出的"触发示例"。
选择关键触发示例:对于同一个记忆单元(键 kᵢℓ 和值 vᵢℓ),我们取出其激活值最高的那个触发示例(即Top-1触发示例)。这个示例是一个文本前缀。
获取真实的下一个词:在原始训练数据中,查找这个前缀后面实际出现的下一个词,记为 wᵢℓ。
例如,如果Top-1触发示例是
"He was also a part of the Indian delegation",那么真实的下一个词wᵢℓ可能就是"that"。
第三步:进行比较分析
有了假设分布 pᵢℓ 和真实答案 wᵢℓ,我们就可以进行多种定量比较:
Top-1 匹配率(Agreement Rate):
操作:检查分布
pᵢℓ中概率最高的那个词(即argmax(pᵢℓ))是否等于真实的下一个词wᵢℓ。分析:对每一层,计算所有记忆单元中这种匹配发生的比例。如图4所示,他们发现低层的匹配率几乎为0,但从第11层开始,匹配率显著上升至3.5%。这远高于随机猜测的概率(0.0004%),证明上层的值向量具有非平凡的预测能力。
真实词的排名分析:
操作:不只看Top-1,而是查看真实的下一个词
wᵢℓ在分布pᵢℓ的排序中排在第几位。分析:如图5所示,他们发现随着层数的增加,
wᵢℓ的排名逐渐上升(即排名数字变小)。这意味着在更高层,值向量会赋予其对应模式的实际下一个词更高的概率。
检测高置信度的值向量:
操作:找出所有值向量中,其分布
pᵢℓ的最大概率值最高的那些(即分布非常"尖锐",对其Top-1预测非常有信心)。分析:如图6所示,他们发现这些高置信度的值向量,其Top-1预测与真实下一个词
wᵢℓ的匹配率也更高。并且,这些高置信度的值向量几乎都集中在上层网络(11-16层)。表2展示了一些例子,例如值向量v²²¹⁵,它的Top-1预测是"each",而在其键的Top-50触发示例中,有68%的例子的下一个词确实是"each"。
总结与要点
这个过程的本质是:
我们问值向量:"根据你存储的信息,你觉得接下来应该是什么词?"(通过投影到词表得到分布pᵢℓ)。然后我们拿这个答案去和现实世界中,真正出现在对应模式后面的词(wᵢℓ)进行比对,看它说得准不准。
重要说明:
非精确性:作者强调,这样得到的分布
pᵢℓ是未校准的。因为在真实的前向传播中,值向量vᵢℓ会被一个记忆系数mᵢℓ缩放,这个系数会改变最终分布的形态。但是,分布的排序是不变的,因此比较排名是有效的。空间一致性假设:这个方法假设所有层都在同一个"嵌入空间"中操作,这对于下层网络可能不成立,这也能解释为什么下层的匹配率很低。
通过这一系列分析,论文有力地证明了,尤其是在Transformer的上层,前馈层中的"值"向量确实存储了与"键"模式相对应的下一个词的预测信息,使得每个记忆单元成为一个功能完整的"模式-预测"对。
5 组合性分析:
分析了在真实推理时,单个层内数百个记忆单元如何组合其输出,以及不同层之间如何通过残差连接逐步精炼预测结果。
这是论文中关于模型如何"思考"和"决策"的核心分析。这部分研究揭示了Transformer内部工作的动态过程,具体操作如下:
第一部分:分析单个层内的记忆组合
研究问题:
在前馈层内部,输出是来自单个主导的记忆单元,还是多个记忆单元的组合?
具体分析方法:
量化活跃记忆单元:
从验证集中随机采样4000个文本前缀作为输入
对每个输入,统计每层前馈网络中记忆系数>0的记忆单元数量(即被激活的单元)
发现:每层通常有10%-50%的记忆单元被激活(约400-2000个),证明输出是众多记忆单元的共同贡献(图7)
检测组合性vs主导性:
定义函数:
top(h) = argmax(softmax(h·E)),即向量h对应的最可能词汇对于每个输入,比较:
整个层的输出预测:
top(y^ℓ)每个活跃记忆单元的单独预测:
top(v_i^ℓ)
统计层的预测不同于所有记忆单元预测的案例比例
关键发现(图8):
在任何层,至少68%的输入中,层的最终预测与每一个活跃记忆单元的单独预测都不同
这表明输出是真正的"组合"结果,而非简单复制某个记忆的预测
分析例外情况:
当层的预测确实与某个记忆单元相同时,这些案例往往具有特征:
60%的情况下,预测的是常见停用词("the", "of"等)
43%的情况下,输入前缀很短(<5个词)
这表明:高频、简单的模式可能被"缓存"在单个记忆单元中,无需复杂组合
第二部分:分析层间通过残差连接的精炼过程
研究问题:
多层Transformer如何通过残差连接逐步精炼其预测?
具体分析方法:
跟踪预测的稳定性:
在每一层ℓ,计算残差向量
r^ℓ的top预测:top(r^ℓ)比较它与模型最终输出的top预测:
top(o^L)统计两者匹配的比例
发现(图9):
在底层(1-3层),约30%的预测已经与最终输出一致
从第10层开始,这个比例快速上升
意味着:许多"简单"的预测在早期就已确定,后期主要处理"困难"案例
测量置信度的演化:
对于模型最终输出的词w,计算每一层残差向量
r^ℓ分配给w的概率p = softmax(r^ℓ·E)_w
发现(图10):
随着层数增加,模型对最终预测的置信度逐渐提高
这不仅涉及预测本身,还涉及模型对其决策的确定性
解剖精炼机制:
对每一层,将输入分为四类(图11):Residual:输出预测 = 残差输入的预测 ≠ 前馈层预测
FFN:输出预测 = 前馈层预测 ≠ 残差输入预测
Agreement:输出预测 = 残差输入预测 = 前馈层预测
Composition:输出预测 ≠ 残差输入预测 ≠ 前馈层预测
惊人发现:
当预测发生变化时(Composition+FFN),很少直接采用前馈层的预测(FFN只占很小部分)
大多数变化产生了一个"折衷"预测(Composition),既不是残差输入的预测,也不是前馈层的预测
这表明:前馈层更像一个否决机制,它不直接提出新预测,而是调整概率分布,降低某些候选词的概率,从而提高其他词的概率
手动分析最后层的修正:
随机选择100个在最后一层发生预测变化的案例进行人工分析
发现:
66%:修正为语义遥远的词(如"people"→"same")
34%:修正为语义相关的词(如"later"→"earlier", "gastric"→"stomach")
这表明:即使到最后层,前馈层仍在进行有意义的语义调整
总结:模型如何"思考"
通过这些分析,论文描绘了Transformer的决策过程:
并行激活:每个输入同时激活数百个记忆模式
层内组合:每个前馈层将这些模式的预测组合成一个新的、不同的预测
序列精炼:通过残差连接,模型逐步微调其预测
早期层:处理简单、明显的预测
后期层:处理复杂案例,通过概率重分配而非直接覆盖来精炼预测
否决而非提议:前馈层更多是排除错误选项,而非直接提出正确答案
这个过程类似于人类的推理:我们先有一个初步判断,然后通过考虑更多因素来不断调整和精炼我们的结论,最终可能得出一个与任何单一因素都不相同的综合判断。
3. 主要结论
论文得出了以下几个核心结论:
前馈层是键值记忆系统:证实了前馈层确实扮演着大规模、并行的模式-答案记忆库的角色。
“键”捕获可解释的输入模式:
每个“键”都对应着一组人类可以理解的文本模式。
模型存在层级分工:下层网络更多地捕获浅层模式(如特定的词尾、固定搭配),而上层网络则更多地捕获语义模式(如“电视节目”、“军事基地”等主题)。
“值”代表输出分布(尤其在高层):
在模型的上层,每个“值”向量所诱导出的词汇分布,会高度倾向于出现在其对应“键”模式之后的真实词汇。这表明上层记忆单元存储了直接的“模式-预测”映射。
下层网络的“键”和“值”之间这种关联较弱。
预测通过组合与精炼产生:
层内组合:单个前馈层的输出是其数百个被激活的记忆单元“值”的加权组合,而非由单一单元主导。这种组合会产生全新的预测。
层间精炼:模型通过残差连接进行序列式精炼。许多预测在网络中层就已初步确定,上层网络的作用是对其进行微调和修正(例如,将“后来”修正为“早些时候”),而不是从头生成。
总而言之,这篇论文提供了一个清晰而有力的模型内部工作机制视角:Transformer语言模型通过其庞大的前馈层,记忆了大量的、从浅到深的语言模式及其可能的后续词汇,并通过一种分层、组合的方式,将这些记忆一点点地组装成最终的预测结果。 这项工作极大地提升了我们对Transformer的理解,并为模型可解释性、隐私和安全等后续研究开辟了道路。