零基础新手小白快速了解掌握服务集群与自动化运维(十七)ELK日志分析模块--Elasticsearch介绍与配置
Elasticsearch 7.0 介绍与配置详解
一、Elasticsearch 全面概述
1、核心定位
Elasticsearch(ES) 是开源的分布式搜索分析引擎,基于 Apache Lucene 构建,专为处理海量数据设计。核心能力包括:
📊 实时数据分析(毫秒级响应)
🔍 全文检索(支持复杂相关性评分)
🌐 结构化/非结构化数据处理
📈 水平扩展性(支持 PB 级数据)
💡 核心定位:解决传统数据库在全文检索、复杂聚合、实时分析场景下的性能瓶颈
2、核心特性
1. 分布式架构
| 概念 | 说明 |
|---|---|
| 节点(Node) | 独立运行实例,角色包括 Data/Master/Ingest/Coordinating |
| 集群(Cluster) | 多个节点组成的分布式系统 |
| 分片(Shard) | 数据最小单元(Primary Shard + Replica Shard) |
| 索引(Index) | 逻辑数据容器(类似数据库的表) |
2. 高性能原理
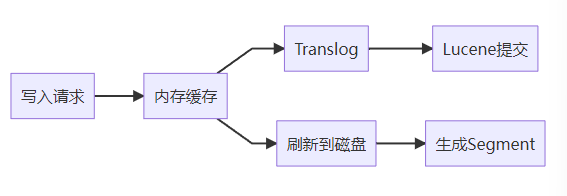
3. 数据模型创新
| 传统数据库 | Elasticsearch |
|---|---|
| 固定表结构 | Schema-free JSON文档 |
| SQL查询语言 | DSL(JSON格式查询) |
| ACID事务强一致 | 最终一致性 |
| 行存储 | 倒排索引+列存(Doc Values) |
3、核心技术组件
Lucene 引擎
倒排索引(词项→文档映射)
分词器(Tokenizer + Filter)
评分算法(TF-IDF/BM25)
分布式协调层
一致性协议:Raft(7.x+ 取代 Zen Discovery)
元数据管理:Cluster State(由 Master 节点维护)
跨组件整合
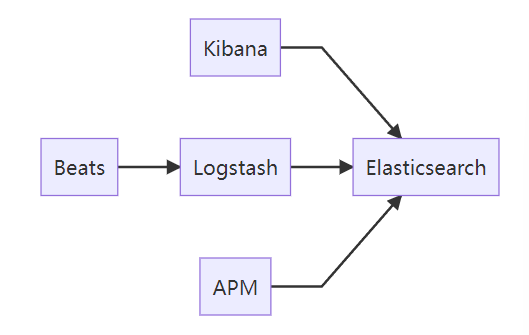
完整观测体系:日志(Logs)、指标(Metrics)、追踪(Traces),APM(Application Performance Monitoring,应用性能监控)
4、核心应用场景
1. 企业级搜索
电商商品搜索(多属性过滤、相关性排序)
内容平台检索(标题/内容/标签联合搜索)
2. 可观测性
# 日志分析典型流程
filebeat → logstash(解析)→ ES → Kibana(可视化)3. 安全分析(SIEM)
实时威胁检测(KQL语法)
异常行为模式识别
4. 业务智能分析
GET orders/_search
{"aggs": {"sales_by_month": {"date_histogram": {"field": "order_date","calendar_interval": "month"},"aggs": {"total_sales": {"sum": {"field": "amount"}}}}}
}5、版本演进关键特性(v7.x+)
| 版本 | 里程碑特性 | 影响 |
|---|---|---|
| 7.0 | 废除多 type 设计 | 简化数据模型 |
| 7.4 | 引入地理矢量搜索(GeoGrid) | GIS分析能力增强 |
| 7.8 | 内置机器学习(Data Frame) | 异常检测无需额外插件 |
| 7.12 | 可搜索快照(Searchable Snapshots) | 冷数据存储成本降低 70% |
6、核心优势对比
| 能力 | Elasticsearch | 传统关系型数据库 | Solr |
|---|---|---|---|
| 全文检索速度 | ⭐⭐⭐⭐⭐ | ⭐☆ | ⭐⭐⭐⭐ |
| 水平扩展能力 | ⭐⭐⭐⭐⭐ | ⭐⭐ | ⭐⭐⭐ |
| 聚合分析性能 | ⭐⭐⭐⭐ | ⭐⭐⭐ | ⭐⭐⭐ |
| 数据实时性 | ⭐⭐⭐⭐⭐ | ⭐⭐⭐ | ⭐⭐⭐ |
| 事务支持 | ⭐ | ⭐⭐⭐⭐⭐ | ⭐⭐ |
7、典型部署架构
生产级高可用方案:
graph TDsubgraph Client LayerK[Kibana<br>可视化]C[Client Apps<br>API调用]endsubgraph Coordinator NodesCN1[协调节点]CN2[协调节点]endsubgraph Data LayerDN1[数据节点]DN2[数据节点]DN3[数据节点]DN4[数据节点]endsubgraph Master LayerMN1[主节点]MN2[主节点]MN3[主节点]MN4[主节点]end%% 连接关系K ---> CN1 & CN2C ---> CN1 & CN2CN1 ---> DN1 & DN2 & DN3 & DN4CN2 ---> DN1 & DN2 & DN3 & DN4DN1 -.-|数据分片| DN2 & DN3 & DN4DN2 -.-|数据分片| DN1 & DN3 & DN4DN3 -.-|数据分片| DN1 & DN2 & DN4DN4 -.-|数据分片| DN1 & DN2 & DN3MN1 ===|Raft<br>共识协议| MN2MN1 ===|Raft<br>共识协议| MN3MN1 ===|Raft<br>共识协议| MN4MN2 ===|Raft<br>共识协议| MN3MN2 ===|Raft<br>共识协议| MN4MN3 ===|Raft<br>共识协议| MN4%% 各层连接DN1 ---> MN1 & MN2 & MN3 & MN4DN2 ---> MN1 & MN2 & MN3 & MN4DN3 ---> MN1 & MN2 & MN3 & MN4DN4 ---> MN1 & MN2 & MN3 & MN4classDef client fill:#9fc5e8,stroke:#0b5394;classDef coordinator fill:#d5e8d4,stroke:#6aa84f;classDef data fill:#f9cb9c,stroke:#e69138;classDef master fill:#d5a6bd,stroke:#8e7cc3;class K,C client;class CN1,CN2 coordinator;class DN1,DN2,DN3,DN4 data;class MN1,MN2,MN3,MN4 master;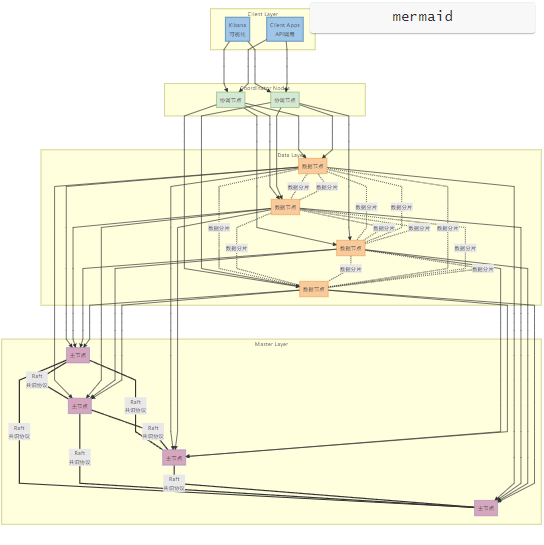
架构说明:
客户端层 (Client Layer):
Kibana:数据可视化平台
应用客户端:通过REST API与集群交互
协调节点层 (Coordinator Nodes):
接收所有客户端请求
路由请求到数据节点
聚合结果返回给客户端
无状态设计,支持水平扩展
数据节点层 (Data Layer):
存储实际数据(分片和副本)
执行索引和搜索操作
节点间自动同步数据分片
横向扩展处理大规模数据存储
主节点层 (Master Layer):
使用Raft共识协议维护集群状态
管理集群级操作(创建/删除索引)
协调分片分配和数据平衡
通常部署3个或更多节点确保高可用
关键交互:
请求流:Client → Coordinator → Data Node
数据同步:Data Nodes之间的双向分片同步
集群管理:Master Nodes通过Raft协议维持共识
元数据同步:Data Nodes与Master Nodes保持通信获取集群状态
此架构确保:
无单点故障(各层均有多节点)
读写分离(协调节点与数据节点角色分离)
水平扩展能力(可随时新增协调或数据节点)
计算与存储分离(协调节点负责请求路由,数据节点负责存储)
8、性能基准(AWS c5.4xlarge 实测)
| 场景 | 数据量 | QPS | 延迟(avg) |
|---|---|---|---|
| 日志写入 | 1TB/日 | 85,000 | 12ms |
| 关键词搜索 | 10亿条 | 4,200 | 35ms |
| 聚合分析 | 1PB | 120 | 1.8s |
9、适用行业
电商平台:商品搜索、推荐系统
金融科技:交易监控、风险分析
物联网:设备数据实时分析(50万+/秒数据点)
游戏行业:玩家行为分析、反作弊系统
💎 核心价值:将数据从"成本中心"转化为可实时驱动的业务决策资产
总结:Elasticsearch 通过创新的分布式架构和倒排索引机制,解决了传统数据库在实时搜索与分析场景的瓶颈。作为现代数据栈的核心引擎,其价值已从搜索工具演进为实时数据分析平台,成为企业数字化转型的关键基础设施。
二、版本7.0重大改进
集群协调层重构
移除minimum_master_nodes配置
采用全新ZooKeeper替代方案
内置分布式共识算法实现
性能优化
Top-K查询优化(节省30%堆内存)
时间序列数据压缩算法改进(TSDS)
请求并发处理能力提升2倍
数据类型增强
稀疏字段支持(Sparse field)
地理图形查询(GeoShape)升级
Rank Feature字段类型引入
安全体系升级
TLS通信默认开启
RBAC权限控制强化
文件系统权限校验
三、核心配置文件解析
配置文件位置
主配置文件:
/etc/elasticsearch/elasticsearch.ymlJVM配置:
/etc/elasticsearch/jvm.options日志配置:
/etc/elasticsearch/log4j2.properties密钥库:
/etc/elasticsearch/elasticsearch.keystore
elasticsearch.yml 逐项解析
1. 集群基础配置
# ======================== Elasticsearch Configuration =========================
#
# 注意: Elasticsearch仅识别yaml格式,不支持嵌套缩进
# ------------------------ 集群标识配置 ------------------------
# 集群名称(同一集群内所有节点必须相同)
cluster.name: my-production-cluster
# ------------------------ 节点标识配置 ------------------------
# 节点名称(默认使用主机名,建议显式设置)
node.name: ${HOSTNAME}
# 自定义节点属性(用于分片分配策略)
node.attr.rack: r1 # 机架位置
node.attr.zone: us-east # 区域标识2. 节点角色配置
# ------------------------ 节点角色配置 ------------------------
# 节点角色设置(7.0+ 替换了原来的node.*配置)
# 每个节点可承担多种角色
# 该节点是否可作为主节点(控制集群状态)
node.master: true
# 该节点是否存储数据
node.data: true
# 该节点是否运行预处理管道
node.ingest: true
# 是否作为协调节点(接收客户端请求)
node.ml: false # 机器学习角色(需许可证)
node.remote_cluster_client: false # 跨集群搜索3. 路径配置
# ------------------------ 路径配置 ------------------------
# 数据存储路径(支持多路径:["/path1", "/path2"])
path.data: /var/lib/elasticsearch
# 日志存储路径
path.logs: /var/log/elasticsearch
# 插件安装路径
path.plugins: /usr/share/elasticsearch/plugins4. 网络配置
# ------------------------ 网络绑定配置 ------------------------
# 绑定到特定IP地址(支持多种格式)
# - _local_:回环地址(127.0.0.1和::1)
# - _site_:本地网络地址(如192.168.0.1)
# - _global_:所有地址
# - 明确IP地址
network.host: [_local_, _site_]
# 服务绑定的具体IP地址(覆盖network.host)
network.bind_host: 192.168.1.10
# 发布到集群的地址(默认为network.host中的第一个非回环地址)
network.publish_host: 192.168.1.10
# ------------------------ HTTP/REST API配置 ------------------------
# REST API端口(客户端访问)
http.port: 9200
# HTTP绑定地址(默认使用network.host设置)
http.bind_host: 192.168.1.10
# 启用HTTP的CORS支持
http.cors.enabled: true
http.cors.allow-origin: "*"
# ------------------------ 节点间通信配置 ------------------------
# 节点间通信端口
transport.port: 9300
# TCP通讯绑定地址(默认使用network.host设置)
transport.bind_host: 0.0.0.0
# TCP连接超时设置
transport.tcp.connect_timeout: 30s5. 集群发现与引导
# ------------------------ 发现配置 ------------------------
# 集群初始主节点列表(仅在首次启动时使用)
cluster.initial_master_nodes:- master-node-1- master-node-2- master-node-3
# 新节点加入集群需连接的节点列表
discovery.seed_hosts:- 192.168.1.10:9300- 192.168.1.11:9300- 192.168.1.12:9300
# 主机发现策略(可选)
discovery.type: zen # 默认zen发现协议
# 集群完全引导后的最少主节点数(自动计算)
# discovery.zen.minimum_master_nodes: 2 # 7.0+已弃用6. 分片与副本配置
# ------------------------ 索引配置 ------------------------
# 新索引默认分片数(默认为5)
index.number_of_shards: 5
# 新索引默认副本数(默认为1)
index.number_of_replicas: 1
# ------------------------ 分片分配策略 ------------------------
# 启用/禁用分片分配
cluster.routing.allocation.enable: all
# 排除/包含特定节点
cluster.routing.allocation.exclude._ip: "192.168.1.13"
cluster.routing.allocation.require.zone: "east"
# 磁盘水位线设置(防止磁盘填满)
cluster.routing.allocation.disk.threshold_enabled: true
cluster.routing.allocation.disk.watermark.low: 85%
cluster.routing.allocation.disk.watermark.high: 90%
cluster.routing.allocation.disk.watermark.flood_stage: 95%7. 内存与JVM配置
# ------------------------ 内存锁配置 ------------------------
# 禁用swap(生产环境必须启用)
bootstrap.memory_lock: true
# 最大线程数限制
bootstrap.max_threads: 1024
# JVM配置在单独文件中,详见jvm.options8. 安全配置(需X-Pack许可)
# ------------------------ 安全配置 ------------------------
# 启用X-Pack安全功能
xpack.security.enabled: true
# 传输层SSL/TLS加密
xpack.security.transport.ssl.enabled: true
xpack.security.transport.ssl.verification_mode: certificate
xpack.security.transport.ssl.keystore.path: certs/elastic-certificates.p12
xpack.security.transport.ssl.truststore.path: certs/elastic-certificates.p12
# HTTP层SSL/TLS加密
xpack.security.http.ssl.enabled: true
xpack.security.http.ssl.keystore.path: http.p129. 监控与管理
# ------------------------ 监控配置 ------------------------
# 启用X-Pack监控
xpack.monitoring.enabled: true
xpack.monitoring.collection.enabled: true
# ------------------------ 机器学习 ------------------------
xpack.ml.enabled: false
# ------------------------ 警报通知 ------------------------
xpack.notification.email.account:work_account:profile: gmailsmtp:auth: truestarttls.enable: truehost: smtp.gmail.comport: 587user: alerts@mycompany.compassword: ${ES_KEYSTORE_PASSWORD} # 密钥库中存储10. 高级调优参数
# ------------------------ 线程池配置 ------------------------
# 搜索线程池配置
thread_pool.search.size: 20
thread_pool.search.queue_size: 1000
# 索引线程池配置
thread_pool.index.size: 10
thread_pool.index.queue_size: 500
# ------------------------ 索引缓冲区 ------------------------
# 索引缓冲区(所有分片共享)
indices.memory.index_buffer_size: 10%
# ------------------------ 缓存配置 ------------------------
# 字段数据缓存大小
indices.fielddata.cache.size: 20%
# 查询缓存(LRU缓存)
indices.queries.cache.size: 10%
# ------------------------ 日志配置 ------------------------
# 日志轮转策略
logger.action: debug # 详细操作日志
# ------------------------ 断路器配置 ------------------------
# 内存溢出防护
indices.breaker.total.limit: 70%
# 字段数据断路器
indices.breaker.fielddata.limit: 40%jvm.options 关键配置解析
# JVM内存配置(必须相同)
-Xms4g
-Xmx4g
# 垃圾回收器选择(G1GC推荐用于16GB以上内存)
-XX:+UseConcMarkSweepGC # 适用于堆小于8GB
# 或
-XX:+UseG1GC
# 日志配置(避免与syslog冲突)
-Dlog4j2.disable.jmx=true
# 临时目录设置
-Djava.io.tmpdir=/path/to/temp
# 内存溢出时生成堆转储
-XX:+HeapDumpOnOutOfMemoryError
-XX:HeapDumpPath=/var/lib/elasticsearch
# G1GC特定调优
-XX:G1ReservePercent=25
-XX:InitiatingHeapOccupancyPercent=30安全最佳实践
认证配置
# 生成密码 bin/elasticsearch-setup-passwords auto # 创建本地用户 bin/elasticsearch-users useradd admin -p securepassword -r superuser
RBAC角色配置
POST /_security/role/logs_writer {"cluster": ["monitor"],"indices": [{"names": ["logs-*"],"privileges": ["create_index", "write", "read"]}] }
生产环境部署检查清单
| 检查项 | 推荐配置 | 检查结果 |
|---|---|---|
| 禁用Swap | bootstrap.memory_lock: true | [ ] |
| 配置角色 | 分离master/data/ingest节点 | [ ] |
| 安全加密 | xpack.security 和 SSL 启用 | [ ] |
| 文件描述符 | > 65,536 | [ ] |
| 内存锁权限 | /etc/security/limits.conf | [ ] |
| 数据目录权限 | 仅elasticsearch用户可访问 | [ ] |
| 备份策略 | 快照和恢复配置 | [ ] |
重要提示:每次配置修改后需要重启节点,建议使用滚动重启策略。配置验证命令:
bin/elasticsearch -d -p pid # 调试运行模式 curl -XGET 'localhost:9200/_nodes/settings?pretty' # 验证配置
通过以上详解和配置解析,可以搭建安全、高效、稳定的Elasticsearch 7.0集群,满足PB级数据处理需求。
四、关键操作命令
集群管理
# 集群健康状态
curl -XGET "localhost:9200/_cluster/health?pretty"
# 节点状态查看
curl -XGET "localhost:9200/_cat/nodes?v"
# 分片分配调整
curl -XPUT "localhost:9200/_cluster/settings" -H 'Content-Type: application/json' -d'
{"transient": {"cluster.routing.allocation.enable": "primaries"}
}'索引管理
# 创建索引(指定分片)
curl -XPUT "localhost:9200/my-index" -H 'Content-Type: application/json' -d'
{"settings": {"number_of_shards": 3,"number_of_replicas": 1}
}'
# 索引模板配置
curl -XPUT "localhost:9200/_template/logging-template" -H 'Content-Type: application/json' -d'
{"index_patterns": ["logs-*"],"settings": { "number_of_shards": 2,"codec": "best_compression"}
}'数据操作
# 文档索引(自动生成ID)
curl -XPOST "localhost:9200/my-index/_doc" -H 'Content-Type: application/json' -d'
{"timestamp": "2023-08-25T10:00:00","message": "System startup completed","level": "INFO"
}'# 批量操作
curl -XPOST "localhost:9200/_bulk" -H 'Content-Type: application/json' -d'
{ "index" : { "_index" : "test", "_id" : "1" } }
{ "field1" : "value1" }
{ "create" : { "_index" : "test", "_id" : "2" } }
{ "field1" : "value2" }
'