什么是LLM?
什么是大型语言模型?
LLM 是一种擅长理解和生成人类语言的人工智能模型。它们通过海量的文本数据进行训练,从而能够学习到语言的模式、结构,甚至是细微差别。这些模型通常包含数百万,甚至数千亿参数。
如今大多数 LLM 都是基于 Transformer 架构构建的,这是一种基于注意力的深度学习架构。
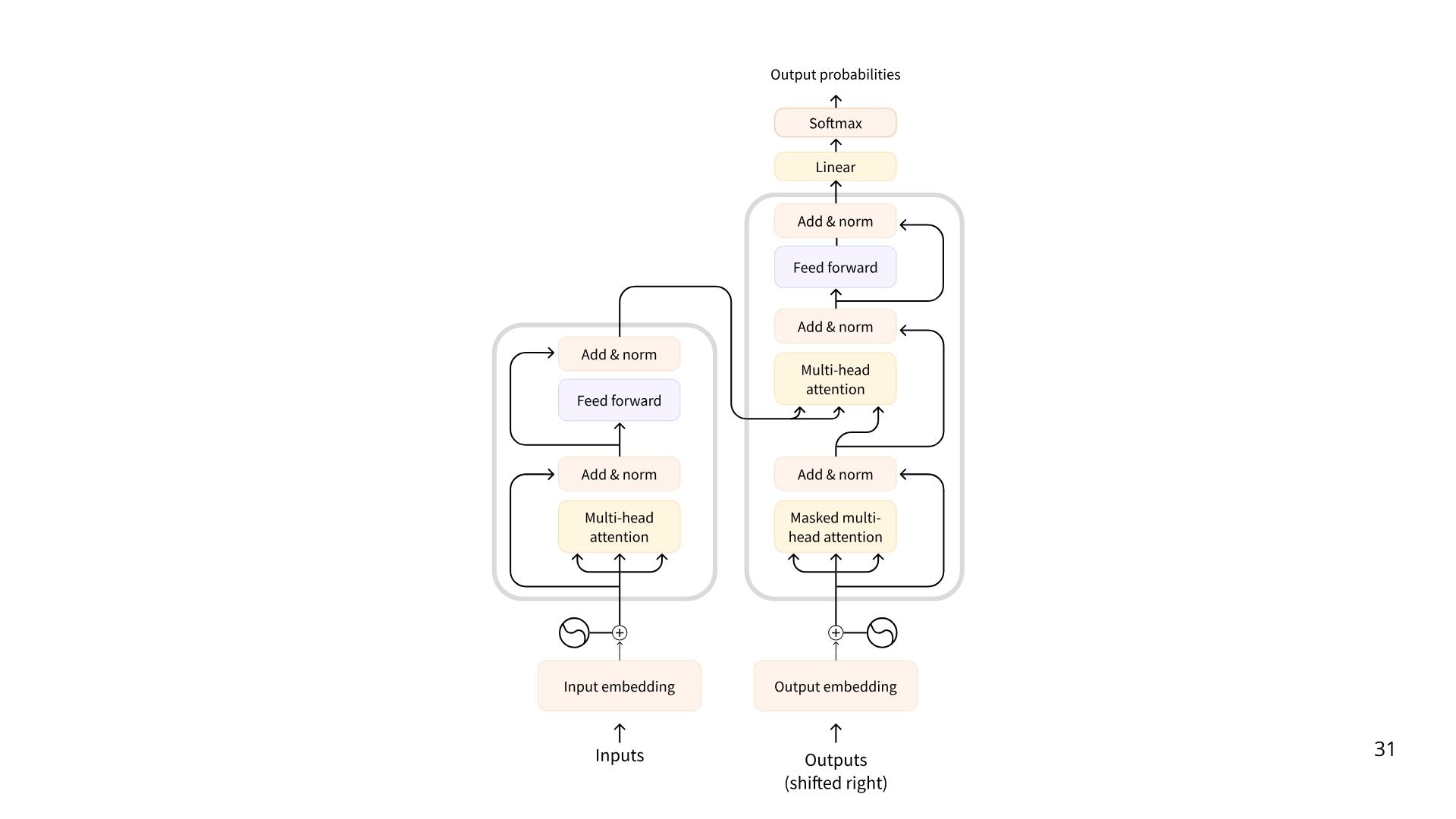
最初的 Transformer 架构是这样的,左边是编码器,右边是解码器。
三种 transformer 类型:
- Encoders 编码器
基于编码器的 Transformer 以文本(或其他数据)作为输入,并输出该文本的密集表示。
例如谷歌的 BERT
应用场景:文本分类、予以搜索、命名实体识别
典型规模:数百万个参数 - Decoders 解码器
基于解码器的 Transformer 专注于生成新的 token 来完成序列,一次生成一个 token
示例:Llama
应用场景:文本生成、聊天机器人、代码生成
典型规模:数十亿百亿千亿参数 - Seq2Seq(Encoder-Decoder )
序列到序列 Transformer 结合了编码器和解码器。编码器首先将输入序列处理成上下文表示,然后解码器生成输出序列。
示例:T5,BART
应用场景:翻译、摘要、释义
典型规模:数百万参数
LLM 的基本原理很简单:就是根据已有的 token 序列,预测下一个 token。token 是 LLM 处理的信息单位,可以理解为“词”,但可能不是完整的词,这是基于分词器的切割策略。
每个 LLM 都有一些模型特有的特殊标记。 LLM 使用这些标记来开启和关闭其生成的结构化组件。例如,指示序列、消息、响应的开始或结束。最重要的是序列结束标记 end of sequence token(EOS)
不同的模型的 EOS 也不尽相同,如下图
| Model | EOS Token | Functionality |
|---|---|---|
| GPT4 | < | endoftest | > | end of message test |
| Llam 3 | < | eot_id |> | end of sequence |
| DeepSeek-R1 | < | end_of_sentence | > | end of message text |
这些标记不需要记住,只是为了更好理解 LLM 预测 token 时何时会结束。
LLM 如何预测下一个 token?
LLM 是自回归的,也就是说一次迭代的输出会成为下一次迭代的输入。这个循环会一直持续,直到模型预测下一个 token 是 EOS 为止,此时模型就可以停止运行了。

LLM 会一直解码文本直到到达 EOS(结束符)。但是,在单个解码循环中会发生什么呢?这里作简要概述:
- 输入文本被分词之后,模型会计算序列的向量表示,该表示能捕获有关输入序列中每个 token 的语义以及位置信息。
- 这种向量表示被输入到模型中,模型输出分数,该分数对词汇表中每个 token 作为序列中下一个 token 的可能性进行排名

根据这些分数,我们有多种策略选择 token 来完成句子。
- 最简单的就是选择得分最高的 token 作为句子的下一个 token
- 还有更高级的解码策略。例如束搜索会查找多个候选序列,找到总分最高的序列。
Attention is all you need
Transformer 架构的一个关键部分是注意力机制。在预测下一个 token 时,句子中的每个 token 并非都很重要。例如“中国的首都是…”这个句子,我们只需要关注“中国”“首都”就能准确的预测下一个词“北京”了。
《Attention is all you need》这篇论文也证实通过识别相关词语来预测下一个 token 的方法是有效的。
尽管 LLM 的基本原理,即预测下一个 token,自 GPT-2 以来一直如此,但在扩展神经网络和使用注意力机制适用于越来越长的序列方面已经取得重大进展,也就是能帮助提升大模型处理更长上下文长度的能力。
LLM 的提示词
由于 LLM 的唯一任务就是通过已有的输入序列预测下一个 token,并选择哪些 token 是重要的,因此输入序列的内容非常重要。
我们提供给 LLM 的输入序列,称为提示词。如果提示词设计的比较好,可以更轻松的引导 LLM 输出我们需要的输出。
LLM 是如何训练的?
LLM 在大型文本数据集上进行训练,通过自监督或掩码语言建模目标来学习预测序列中的下一个词。
通过这种无监督学习,该模型学习语言结构和文本中的潜在模式,从而使模型能够推广到未见过的数据,也即训练模型的泛化能力。
经过初始的预训练后, LLM 可以根据监督学习目标进行微调,以执行特定任务。例如,有些模型针对对话结构或工具使用进行训练,有些模型则专注于分类,或者代码生成。