【深度强化学习】#6 TRPOPPO:策略优化算法
以Actor-Critic为起点,DDPG和TD3继承DQN的思想,以确定性策略为核心,不断优化价值函数学习的稳定性和准确度。与此同时,还有一条技术路线仍然坚持随机性策略,围绕策略函数训练过程的安全与稳健展开研究,由此诞生了TRPO和PPO两大策略优化算法。
TRPO
在Actor-Critic中,我们会面临策略梯度更新步长的设置问题,即对于策略更新公式
θt+1=θt+αθ∇θlnπθ(at∣st)⋅Vw(st,at) \theta_{t+1}=\theta_t+\alpha_\theta\nabla_\theta\ln\pi_\theta(a_t|s_t)\cdot V_w(s_t,a_t) θt+1=θt+αθ∇θlnπθ(at∣st)⋅Vw(st,at)
如果步长αθ\alpha_\thetaαθ太小,则策略的学习速度极慢,需要大量样本,训练成本高;如果步长αθ\alpha_\thetaαθ太大,则会导致策略更新剧烈变化,可能会带来灾难性的性能下降,一次将策略打回原形的错误更新会浪费之前的所有样本。
TRPO(Trust Region Policy Optimization,信任区域策略优化)致力于避免步长设置过大,其核心思想是确保每次更新,新策略不会和旧策略差异过大,即将新策略限制在旧策略的一个“信任区域”内。
优化目标
策略是一种概率分布,衡量两种概率分布的差异的一个指标是KL散度。如果一个随机变量x\mathrm xx有两个单独的概率分布p(x)p(x)p(x)和q(x)q(x)q(x),则它们以p(x)p(x)p(x)为基准分布的KL散度为
DKL(p∣∣q)=Ex∼p[logp(x)q(x)] \begin{split} D_{\mathrm{KL}}(p||q)&=\mathbb E_{\mathrm x\sim p}\left[\log\frac{p(x)}{q(x)}\right] \end{split} DKL(p∣∣q)=Ex∼p[logq(x)p(x)]
概率分布差异越大,KL散度越大。TRPO的优化目标即在优化策略的同时对新旧策略的KL散度进行约束。TRPO的目标函数为
J(θ)=E(s,a)∼πold[πθ(a∣s)πold(a∣s)Aπold(s,a)] J(\theta)=\mathbb E_{(s,a)\sim\pi_{\mathrm{old}}}\left[\frac{\pi_\theta(a|s)}{\pi_{\mathrm{old}}(a|s)}A_{\pi_{\mathrm{old}}}(s,a)\right] J(θ)=E(s,a)∼πold[πold(a∣s)πθ(a∣s)Aπold(s,a)]
最大化该目标函数的意义是找到一个新的参数θ\thetaθ,使得在新策略下,那些优势高的动作被更大比例地采用。
约束条件为
Es∼πold[DKL(πold(⋅∣s)∣∣πθ(⋅∣s))]≤δ \mathbb E_{s\sim\pi_{\mathrm{old}}}[D_{\mathrm{KL}}(\pi_{\mathrm{old}}(\cdot|s)||\pi_\theta(\cdot|s))]\leq\delta Es∼πold[DKL(πold(⋅∣s)∣∣πθ(⋅∣s))]≤δ
其中δ\deltaδ为KL散度的约束阈值,即信任区域的阈值,防止策略更新过渡。
解决这一优化问题需要泰勒展开、拉格朗日乘子法和共轭梯度法三步骤。
(优化问题的求解过程选择性阅读)
泰勒展开
泰勒展开可以让我们从梯度视角更清晰地把握优化问题。对于目标函数J(θ)J(\theta)J(θ),假设当前策略参数为θold\theta_{\mathrm{old}}θold,新策略参数为θnew=θold+Δθ\theta_{\mathrm{new}}=\theta_{\mathrm{old}}+\Delta\thetaθnew=θold+Δθ,则目标函数可以在θold\theta_{\mathrm{old}}θold附近展开为
J(θnew)≈J(θold)+gTΔθ J(\theta_{\mathrm{new}})\approx J(\theta_{\mathrm{old}})+g^T\Delta\theta J(θnew)≈J(θold)+gTΔθ
其中g=∇θJ(θold)g=\nabla_\theta J(\theta_{\mathrm{old}})g=∇θJ(θold)是目标函数在θold\theta_{\mathrm{old}}θold的梯度,表示当前策略方向上的上升斜率。
对期望KL散度的泰勒展开过程则比较复杂。我们先针对单个KL散度,简记当前策略为p(θ)p(\theta)p(θ),新策略为p(θ+Δθ)p(\theta+\Delta\theta)p(θ+Δθ),将KL散度视为Δθ\Delta\thetaΔθ的函数
DKL(p(θ)∣∣p(θ+Δθ))=Ex∼p(θ)[logp(x∣θ)p(x∣θ+Δθ)] D_{\mathrm{KL}}(p(\theta)||p(\theta+\Delta\theta))=\mathbb E_{x\sim p(\theta)}\left[\log\frac{p(x|\theta)}{p(x|\theta+\Delta\theta)}\right] DKL(p(θ)∣∣p(θ+Δθ))=Ex∼p(θ)[logp(x∣θ+Δθ)p(x∣θ)]
接下来在Δθ=0\Delta\theta=0Δθ=0处对其进行泰勒展开。对于零阶项,即KL散度本身,此时两个分布完全相同,值为零
DKL(θ∣∣θ)=0 D_\mathrm{KL}(\theta||\theta)=0 DKL(θ∣∣θ)=0
一阶项是KL散度在Δθ=0\Delta\theta=0Δθ=0处的梯度
g=∇ΔθDKL(p(θ)∣∣p(θ+Δθ))∣Δθ=0=∇ΔθEx∼p(θ)[logp(x∣θ)p(x∣θ+Δθ)]∣Δθ=0=−Ex∼p(θ)[∇Δθlogp(x∣θ+Δθ)]∣Δθ=0(引入中间变量ϕ=θ+Δθ)=−Ex∼p(θ)[∂ϕ∂Δθ∇ϕlogp(x∣ϕ)]∣Δθ=0=−Ex∼p(θ)[∇ϕlogp(x∣ϕ)]∣Δθ=0=−Ex∼p(θ)[∇θlogp(x∣θ)] \begin{split} g&=\nabla_{\Delta\theta}D_{\mathrm{KL}}(p(\theta)||p(\theta+\Delta\theta))|_{\Delta\theta=0}\\ &=\nabla_{\Delta\theta}\mathbb E_{x\sim p(\theta)}\left[\log\frac{p(x|\theta)}{p(x|\theta+\Delta\theta)}\right]|_{\Delta\theta=0}\\ &=-\mathbb E_{x\sim p(\theta)}[\nabla_{\Delta\theta}\log p(x|\theta+\Delta\theta)]|_{\Delta\theta=0}\\ \text{(引入中间变量}\phi=\theta+\Delta\theta\text{)}&=-\mathbb E_{x\sim p(\theta)}\left[\frac{\partial\phi}{\partial\Delta\theta}\nabla_\phi\log p(x|\phi)\right]|_{\Delta\theta=0}\\ &=-\mathbb E_{x\sim p(\theta)}[\nabla_\phi\log p(x|\phi)]|_{\Delta\theta=0}\\ &=-\mathbb E_{x\sim p(\theta)}[\nabla_\theta\log p(x|\theta)] \end{split} g(引入中间变量ϕ=θ+Δθ)=∇ΔθDKL(p(θ)∣∣p(θ+Δθ))∣Δθ=0=∇ΔθEx∼p(θ)[logp(x∣θ+Δθ)p(x∣θ)]∣Δθ=0=−Ex∼p(θ)[∇Δθlogp(x∣θ+Δθ)]∣Δθ=0=−Ex∼p(θ)[∂Δθ∂ϕ∇ϕlogp(x∣ϕ)]∣Δθ=0=−Ex∼p(θ)[∇ϕlogp(x∣ϕ)]∣Δθ=0=−Ex∼p(θ)[∇θlogp(x∣θ)]
其中∇θlogp(x∣θ)\nabla_\theta\log p(x|\theta)∇θlogp(x∣θ)被称为得分函数,它的一个重要性质即期望为零
Ea∼πθ[∇θlogp(x∣θ)]=∫p(x∣θ)⋅∇θlogp(x∣θ)dx(自然对数导数性质)=∫p(x∣θ)⋅∇θp(x∣θ)p(x∣θ)dx=∫∇θp(x∣θ)dx(梯度变量与积分变量不一致时,梯度算符可提出)=∇θ∫p(x∣θ)dx(概率分布的归一化条件)=∇θ1=0 \begin{split} \mathbb E_{a\sim\pi_\theta}[\nabla_\theta\log p(x|\theta)]&=\int p(x|\theta)\cdot\nabla_\theta\log p(x|\theta)\mathrm dx\\ \text{(自然对数导数性质)}&=\int p(x|\theta)\cdot\frac{\nabla_\theta p(x|\theta)}{p(x|\theta)}\mathrm dx\\ &=\int\nabla_\theta p(x|\theta)\mathrm dx\\ \text{(梯度变量与积分变量不一致时,梯度算符可提出)}&=\nabla_\theta\int p(x|\theta)\mathrm dx\\ \text{(概率分布的归一化条件)}&=\nabla_\theta1=0 \end{split} Ea∼πθ[∇θlogp(x∣θ)](自然对数导数性质)(梯度变量与积分变量不一致时,梯度算符可提出)(概率分布的归一化条件)=∫p(x∣θ)⋅∇θlogp(x∣θ)dx=∫p(x∣θ)⋅p(x∣θ)∇θp(x∣θ)dx=∫∇θp(x∣θ)dx=∇θ∫p(x∣θ)dx=∇θ1=0
因此一阶项也为零。
对于二阶项(黑塞矩阵HHH),目前有
H=∇Δθg=−Ex∼p(θ)[∇θ2logp(x∣θ)] \begin{split} H&=\nabla_{\Delta\theta}g\\ &=-\mathbb E_{x\sim p(\theta)}[\nabla_\theta^2\log p(x|\theta)] \end{split} H=∇Δθg=−Ex∼p(θ)[∇θ2logp(x∣θ)]
我们先简记得分函数∇θlogp(x∣θ)=s(x,θ)\nabla_\theta\log p(x|\theta)=s(x,\theta)∇θlogp(x∣θ)=s(x,θ),则∇θ2logp(x∣θ)=∇θs(x,θ)\nabla_\theta^2\log p(x|\theta)=\nabla_\theta s(x,\theta)∇θ2logp(x∣θ)=∇θs(x,θ)。现在从概率分布的归一化条件开始
∫p(x∣θ)dx=1(两边对θ求梯度)∇θ∫p(x∣θ)dx=0∫∇θp(x∣θ)dx=0(对数求导法则)∫p(x∣θ)∇θlogp(x∣θ)dx=0∫p(x∣θ)s(x,θ)dx=0(两边对θ再次求梯度)∇θ∫p(x∣θ)s(x,θ)dx=0∫∇θ[p(x∣θ)s(x,θ)]dx=0(乘积求导法则)∫[(∇θp(x∣θ))s(x,θ)T+p(x∣θ)∇θs(x,θ)]dx=0(再次对数求导法则)∫[p(x∣θ)s(x,θ)s(x,θ)T+p(x∣θ)∇θs(x,θ)]dx=0∫p(x∣θ)s(x,θ)s(x,θ)Tdx+∫p(x∣θ)∇θs(x,θ)dx=0(期望表示)Ex∼p(θ)[s(x,θ)s(x,θ)T]+Ex∼p(θ)[∇θs(x,θ)]=0 \begin{matrix} &\displaystyle\int p(x|\theta)\mathrm dx=1\\ \text{(两边对}\theta\text{求梯度)}&\displaystyle\nabla_\theta\int p(x|\theta)\mathrm dx=0\\ &\displaystyle\int\nabla_\theta p(x|\theta)\mathrm dx=0\\ \text{(对数求导法则)}&\displaystyle\int p(x|\theta)\nabla_\theta\log p(x|\theta)\mathrm dx=0\\ &\displaystyle\int p(x|\theta)s(x,\theta)\mathrm dx=0\\ \text{(两边对}\theta\text{再次求梯度)}&\displaystyle\nabla_\theta\int p(x|\theta)s(x,\theta)\mathrm dx=0\\ &\displaystyle\int\nabla_\theta[p(x|\theta)s(x,\theta)]\mathrm dx=0\\ \text{(乘积求导法则)}&\displaystyle\int[(\nabla_\theta p(x|\theta))s(x,\theta)^T+p(x|\theta)\nabla_\theta s(x,\theta)]\mathrm dx=0\\ \text{(再次对数求导法则)}&\displaystyle\int[ p(x|\theta)s(x,\theta)s(x,\theta)^T+p(x|\theta)\nabla_\theta s(x,\theta)]\mathrm dx=0\\ &\displaystyle\int p(x|\theta)s(x,\theta)s(x,\theta)^T\mathrm dx+\int p(x|\theta)\nabla_\theta s(x,\theta)\mathrm dx=0\\ \text{(期望表示)}&\displaystyle\mathbb E_{x\sim p(\theta)}[s(x,\theta)s(x,\theta)^T]+\mathbb E_{x\sim p(\theta)}[\nabla_\theta s(x,\theta)]=0\\ \end{matrix} (两边对θ求梯度)(对数求导法则)(两边对θ再次求梯度)(乘积求导法则)(再次对数求导法则)(期望表示)∫p(x∣θ)dx=1∇θ∫p(x∣θ)dx=0∫∇θp(x∣θ)dx=0∫p(x∣θ)∇θlogp(x∣θ)dx=0∫p(x∣θ)s(x,θ)dx=0∇θ∫p(x∣θ)s(x,θ)dx=0∫∇θ[p(x∣θ)s(x,θ)]dx=0∫[(∇θp(x∣θ))s(x,θ)T+p(x∣θ)∇θs(x,θ)]dx=0∫[p(x∣θ)s(x,θ)s(x,θ)T+p(x∣θ)∇θs(x,θ)]dx=0∫p(x∣θ)s(x,θ)s(x,θ)Tdx+∫p(x∣θ)∇θs(x,θ)dx=0Ex∼p(θ)[s(x,θ)s(x,θ)T]+Ex∼p(θ)[∇θs(x,θ)]=0
于是黑塞矩阵
H=Ex∼p(θ)[∇θs(x,θ)]=−Ex∼p(θ)[s(x,θ)s(x,θ)T]=−Ex∼p(θ)[(∇θlogp(x∣θ))(∇θlogp(x∣θ))T] \begin{split} H&=\mathbb E_{x\sim p(\theta)}[\nabla_\theta s(x,\theta)]\\ &=-\mathbb E_{x\sim p(\theta)}[s(x,\theta)s(x,\theta)^T]\\ &=-\mathbb E_{x\sim p(\theta)}[(\nabla_\theta\log p(x|\theta))(\nabla_\theta\log p(x|\theta))^T] \end{split} H=Ex∼p(θ)[∇θs(x,θ)]=−Ex∼p(θ)[s(x,θ)s(x,θ)T]=−Ex∼p(θ)[(∇θlogp(x∣θ))(∇θlogp(x∣θ))T]
结果为负的得分函数外积的期望,即费雪信息矩阵,在统计学中用于度量随机变量样本所能提供的关于多维参数的信息量
F=−Ex∼p(θ)[(∇θlogp(x∣θ))(∇θlogp(x∣θ))T] F=-\mathbb E_{x\sim p(\theta)}[(\nabla_\theta\log p(x|\theta))(\nabla_\theta\log p(x|\theta))^T] F=−Ex∼p(θ)[(∇θlogp(x∣θ))(∇θlogp(x∣θ))T]
最终,期望KL散度的泰勒展开仅包含二阶项
Es∼πold[DKL(πold(⋅∣s)∣∣πθ(⋅∣s))]≈Es∼πold[12ΔθTFs(θold)Δθ]=12ΔθTEs∼πold[Fs(θold)]Δθ=12ΔθTFˉ(θold)Δθ \begin{split} &\mathbb E_{s\sim\pi_{\mathrm{old}}}[D_{\mathrm{KL}}(\pi_{\mathrm{old}}(\cdot|s)||\pi_\theta(\cdot|s))]\\\approx&\mathbb E_{s\sim\pi_{\mathrm{old}}}\left[\frac12\Delta\theta^TF_s(\theta_{\mathrm{old}})\Delta\theta\right]\\ =&\frac12\Delta\theta^TE_{s\sim\pi_{\mathrm{old}}}[F_s(\theta_{\mathrm{old}})]\Delta\theta\\ =&\frac12\Delta\theta^T\bar F(\theta_{\mathrm{old}})\Delta\theta \end{split} ≈==Es∼πold[DKL(πold(⋅∣s)∣∣πθ(⋅∣s))]Es∼πold[21ΔθTFs(θold)Δθ]21ΔθTEs∼πold[Fs(θold)]Δθ21ΔθTFˉ(θold)Δθ
现在,优化问题变为了在KL散度约束的情况下,找到一个参数更新方向Δθ\Delta\thetaΔθ使得目标函数变化量最大
maxΔθgTΔθ, s.t.12ΔθTFˉΔθ≤δ \max_{\Delta\theta}g^T\Delta\theta,\text{ s.t.}\frac12\Delta\theta^T\bar F\Delta\theta\leq\delta ΔθmaxgTΔθ, s.t.21ΔθTFˉΔθ≤δ
拉格朗日乘数法
对于该线性目标函数和二次凸集约束,要达到最优解的约束必然是紧的,即约束条件取边界
12ΔθTFˉΔθ=δ \frac12\Delta\theta^T\bar F\Delta\theta=\delta 21ΔθTFˉΔθ=δ
考虑最简单的二维情况,此时线性函数是一个平面,二次型凸集是以当前点为中心的一个椭球。对于一个平面上的点,除了梯度gT=0g^T=0gT=0的情况,椭球范围内的最大值必然落在边界。
现在我们可以使用拉格朗日乘数法在12ΔθTFˉΔθ−δ=0\displaystyle\frac12\Delta\theta^T\bar F\Delta\theta-\delta=021ΔθTFˉΔθ−δ=0的条件下对gTΔθg^T\Delta\thetagTΔθ求极值。构造拉格朗日函数
L(Δθ,λ)=gTΔθ−λ(12ΔθTFˉΔθ−δ) \mathcal L(\Delta\theta,\lambda)=g^T\Delta\theta-\lambda(\frac12\Delta\theta^T\bar F\Delta\theta-\delta) L(Δθ,λ)=gTΔθ−λ(21ΔθTFˉΔθ−δ)
令其对Δθ\Delta\thetaΔθ的导数为零,得到
∇ΔθL=g−λFˉΔθ=0 \nabla_{\Delta\theta}\mathcal L=g-\lambda\bar F\Delta\theta=0 ∇ΔθL=g−λFˉΔθ=0
解得
Δθ=1λFˉ−1g \Delta\theta=\frac1\lambda\bar F^{-1}g Δθ=λ1Fˉ−1g
共轭梯度法
在巨大的参数量下,对Fˉ\bar FFˉ求逆矩阵在计算和存储上都是难以实现的,我们只能通过迭代法求解。令Δθ=x\Delta\theta=xΔθ=x,且不考虑标量λ\lambdaλ,则要求解的线性方程组为
Fˉx=g \bar Fx=g Fˉx=g
TRPO使用了共轭梯度法。共轭梯度法作为最优化理论的知识,不是TRPO的核心内容,本文仅作通俗介绍。
在此之前,我们先了解更基础的迭代优化算法:最速下降法。它是深度学习中常规梯度下降的理论基础,其核心思想即沿着当前点梯度方向的反方向进行更新以最小化损失函数。不同之处在于,更新的步长在梯度下降中由学习率控制,而在最速下降法中是通过沿着更新方向搜索函数的最小值确定的。
最速下降法的缺点在于迭代过程存在振荡,考虑一个等值线如下的椭圆形山谷,在x轴方向上坡度平缓,而在y轴方向上坡度陡峭
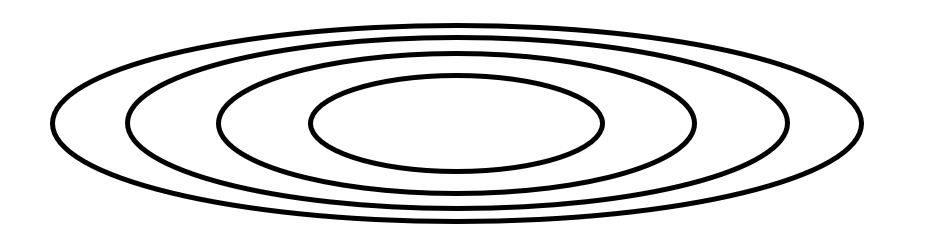
相较于图中任意一条封闭椭圆等值线上的点,椭圆外的点函数值更大,而椭圆内的点函数值更小,因此一条直线上函数值最小的点必然是该直线与某个等值线的切点。这意味着,除非起点的梯度方向与y轴平行,否则最速下降法的迭代结果无法停留在y轴方向上的最低点
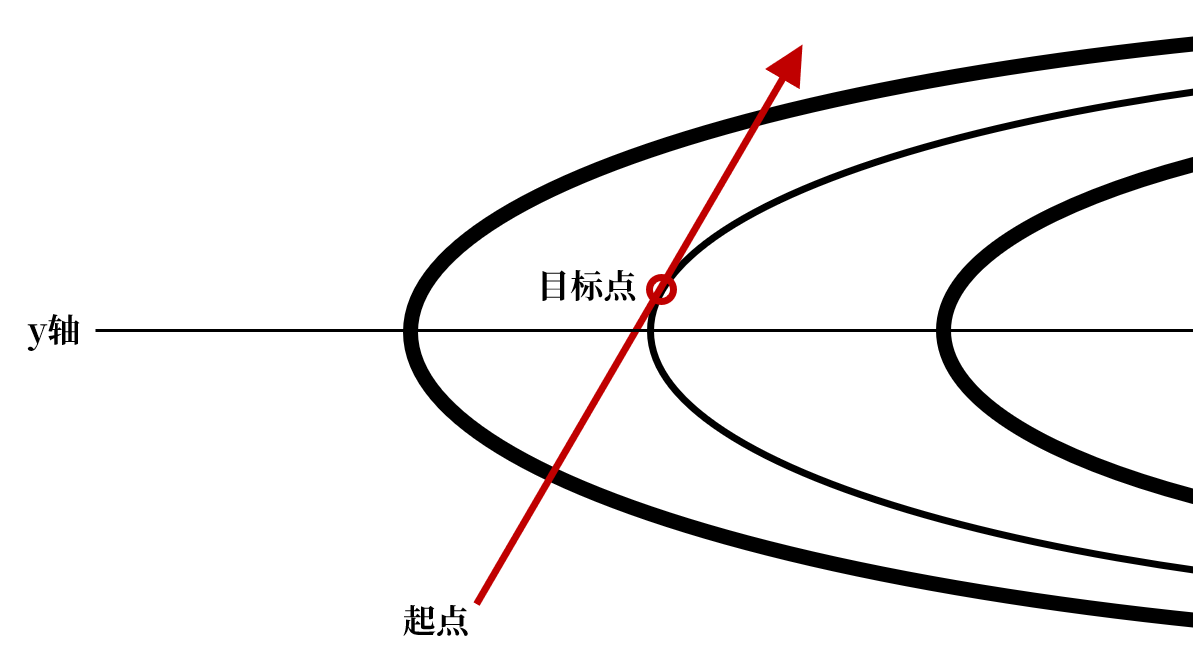
由此,最速下降法的更新便会不断围绕y轴振荡,这将大大降低更新效率。
共轭梯度法的核心在于共轭方向。我们都知道,一对正交向量满足uTv=0u^Tv=0uTv=0,它们在欧氏几何意义下是相互垂直的。如果我们对空间进行一个线性变换AAA,则这对向量将满足uTAv=0u^TAv=0uTAv=0,即关于AAA共轭。根据这一点,如果我们把椭圆视为是由圆经过AAA变换而来的,先按照最速下降法找到等值线上一点及其在该点上的切线方向,再沿着由AAA定义的与之共轭的方向搜索,就能直接到达函数值最小的中心点
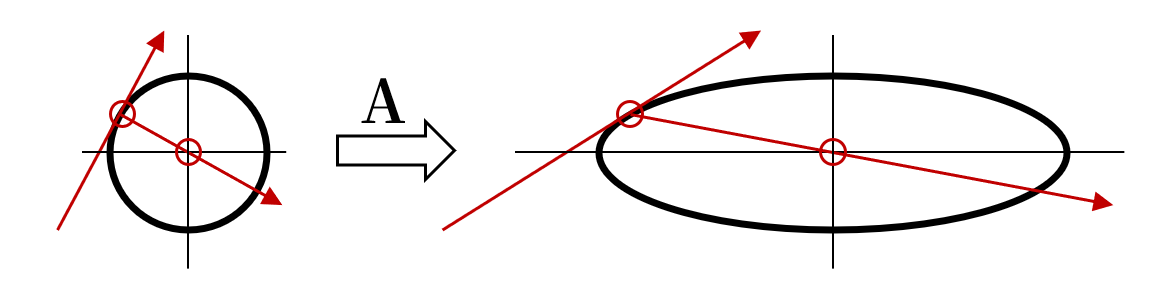
在精确算术运算下,对于nnn维空间,共轭梯度法最多经过nnn次迭代就能得到精确解。本文不进一步展开其具体迭代步骤。最终,对于共轭梯度法给出的更新方向xxx,我们根据KL散度约束计算出一个缩放因子
α=2δxTFˉx \alpha=\sqrt{\frac{2\delta}{x^T\bar Fx}} α=xTFˉx2δ
则参数更新为
θ←θ+α⋅x \theta\leftarrow\theta+\alpha\cdot x θ←θ+α⋅x
广义优势估计
TRPO采用广义优势估计计算优势函数。优势函数的原始定义为
A(s,a)=Q(s,a)−V(s) A(s,a)=Q(s,a)-V(s) A(s,a)=Q(s,a)−V(s)
如果使用nnn步回报对其进行估计,则有
A(n)(st,at)=∑k=0n−1γkrt+k+γnV(st+n)−V(st) A^{(n)}(s_t,a_t)=\sum^{n-1}_{k=0}\gamma^kr_{t+k}+\gamma^nV(s_{t+n})-V(s_t) A(n)(st,at)=k=0∑n−1γkrt+k+γnV(st+n)−V(st)
广义优势估计应用了TD(λ)的思想,即不选择一个固定的nnn,而是将所有nnn步的估计通过一个权重λ\lambdaλ进行指数加权平均,从而结合了所有步长的信息,平衡偏差和方差
A(st,at)=(1−λ)A(1)(st,at)+λA(2)(st,at)+λ2A(3)(st,at)+⋯ A(s_t,a_t)=(1-\lambda)A^{(1)}(s_t,a_t)+\lambda A^{(2)}(s_t,a_t)+\lambda^2A^{(3)}(s_t,a_t)+\cdots A(st,at)=(1−λ)A(1)(st,at)+λA(2)(st,at)+λ2A(3)(st,at)+⋯
我们可以通过单步TD误差对其进行化简
δt=rt+γV(st+1)−V(st)A(st,at)=∑k=0T(γλ)kδt+k \begin{split} \delta_t=r_t+\gamma V(s_{t+1})-V(s_t)\\ A(s_t,a_t)=\sum^T_{k=0}(\gamma\lambda)^k\delta_{t+k} \end{split} δt=rt+γV(st+1)−V(st)A(st,at)=k=0∑T(γλ)kδt+k
算法流程
- 初始化Actor网络参数θ\thetaθ,Critic V网络参数www,信任区域阈值δ\deltaδ;
- 循环:
- 使用当前策略πθ\pi_\thetaπθ与环境交互,收集一组轨迹的数据D\mathcal DD;
- 利用数据D\mathcal DD得到的TD误差更新Critic网络wt+1=wt−αwδt⋅∇wVw(st)w_{t+1}=w_t-\alpha_w\delta_t\cdot\nabla_wV_w(s_t)wt+1=wt−αwδt⋅∇wVw(st);
- 计算数据D\mathcal DD中所有状态-动作对的广义优势估计A(st,at)A(s_t,a_t)A(st,at);
- 构建并求解优化问题以更新Actor网络θ←θ+α⋅x\theta\leftarrow\theta+\alpha\cdot xθ←θ+α⋅x;
- 丢弃数据D\mathcal DD,进入下一轮迭代;
- 直到Actor网络和Critic网络收敛。
PPO
TRPO的弊端显而易见,其求解优化问题的计算过于复杂,而且需要采样整个状态空间来估计KL散度的期望。PPO(Proximal Policy Optimization,近端策略优化)则专注于简化训练过程,在克服TRPO的计算复杂性的同时保证训练效果。
剪辑目标函数
PPO采用了更简单的方法限制策略更新幅度,其主要通过概率比衡量新旧策略的差异
r(θ)=πθ(a∣s)πold(a∣s) r(\theta)=\frac{\pi_\theta(a|s)}{\pi_{\mathrm{old}}(a|s)} r(θ)=πold(a∣s)πθ(a∣s)
PPO在目标函数中直接对其进行裁剪操作
LCLIP(θ)=Eπold[min(r(θ)A,clip(r(θ),1−ϵ,1+ϵ)A)] L_{\mathrm{CLIP}}(\theta)=\mathbb E_{\pi_{\mathrm{old}}}[\min{}(r(\theta)A,\mathrm{clip}(r(\theta),1-\epsilon,1+\epsilon)A)] LCLIP(θ)=Eπold[min(r(θ)A,clip(r(θ),1−ϵ,1+ϵ)A)]
(在PPO上下文中目标函数使用L)
裁剪操作会将r(θ)r(\theta)r(θ)限制在[1−ϵ,1+ϵ][1-\epsilon,1+\epsilon][1−ϵ,1+ϵ]的范围内。如果优势函数A>0A>0A>0,我们则希望增加这个动作的概率,即r(θ)>1r(\theta)>1r(θ)>1,但会被限制在1+ϵ1+\epsilon1+ϵ以下;反之如果A<0A<0A<0,我们则希望r(θ)<1r(\theta)<1r(θ)<1,但会被限制在1−ϵ1-\epsilon1−ϵ以上。
现在我们来计算剪辑目标函数的梯度。如果r(θ)r(\theta)r(θ)没有触发裁剪操作,则其梯度为
∇θLCLIP=∇θEπold[r(θ)A]=Eπold[∇θπθ(a∣s)πold(a∣s)Aπold(s,a)]=Eπold[∇θπθ(a∣s)πold(a∣s)Aπold(s,a)]=Eπold[πθ(a∣s)πold(a∣s)∇θπθ(a∣s)πθ(a∣s)Aπold(s,a)]=Eπold[πθ(a∣s)πold(a∣s)∇θlogπθ(a∣s)Aπold(s,a)] \begin{split} \nabla_\theta L_{\mathrm{CLIP}}&=\nabla_\theta\mathbb E_{\pi_{\mathrm{old}}}[r(\theta)A]\\ &=\mathbb E_{\pi_{\mathrm{old}}}\left[\nabla_\theta\frac{\pi_\theta(a|s)}{\pi_{\mathrm{old}}(a|s)}A_{\pi_{\mathrm{old}}}(s,a)\right]\\ &=\mathbb E_{\pi_{\mathrm{old}}}\left[\frac{\nabla_\theta\pi_\theta(a|s)}{\pi_{\mathrm{old}}(a|s)}A_{\pi_{\mathrm{old}}}(s,a)\right]\\ &=\mathbb E_{\pi_{\mathrm{old}}}\left[\frac{\pi_\theta(a|s)}{\pi_{\mathrm{old}}(a|s)}\frac{\nabla_\theta\pi_\theta(a|s)}{\pi_\theta(a|s)}A_{\pi_{\mathrm{old}}}(s,a)\right]\\ &=\mathbb E_{\pi_{\mathrm{old}}}\left[\frac{\pi_\theta(a|s)}{\pi_{\mathrm{old}}(a|s)}\nabla_\theta\log\pi_\theta(a|s)A_{\pi_{\mathrm{old}}}(s,a)\right] \end{split} ∇θLCLIP=∇θEπold[r(θ)A]=Eπold[∇θπold(a∣s)πθ(a∣s)Aπold(s,a)]=Eπold[πold(a∣s)∇θπθ(a∣s)Aπold(s,a)]=Eπold[πold(a∣s)πθ(a∣s)πθ(a∣s)∇θπθ(a∣s)Aπold(s,a)]=Eπold[πold(a∣s)πθ(a∣s)∇θlogπθ(a∣s)Aπold(s,a)]
如果r(θ)r(\theta)r(θ)超出阈值触发了裁剪操作,则其会被修正为一个常数,因而梯度为零。
熵正则化
为了鼓励策略探索,避免其在学习过程中降低方差,PPO引入了熵正则化项
LENT(θ)=Es∼πθ[H(πθ(⋅∣s))] L_{\mathrm{ENT}}(\theta)=\mathbb E_{s\sim{\pi_\theta}}[\mathcal H(\pi_\theta(\cdot|s))] LENT(θ)=Es∼πθ[H(πθ(⋅∣s))]
其中H(π(⋅∣s))\mathcal H(\pi(\cdot|s))H(π(⋅∣s))是策略π\piπ在状态sss下的熵
H(π(⋅∣s))=−Ea∼π[logπ(a∣s)]=−∫π(a∣s)logπ(a∣s)da \begin{split} \mathcal H(\pi(\cdot|s))&=-\mathbb E_{a\sim\pi}[\log\pi(a|s)]\\ &=-\int\pi(a|s)\log\pi(a|s)\mathrm da \end{split} H(π(⋅∣s))=−Ea∼π[logπ(a∣s)]=−∫π(a∣s)logπ(a∣s)da
观察−xlogx-x\log x−xlogx(以2为底)的函数图像,可知最大化策略的熵的效果就是让动作的概率向“中间”靠拢,即趋于均匀分布。随着底数的增大,函数的极值将变小,最大化目标对策略随机性的激励强度也将变小。
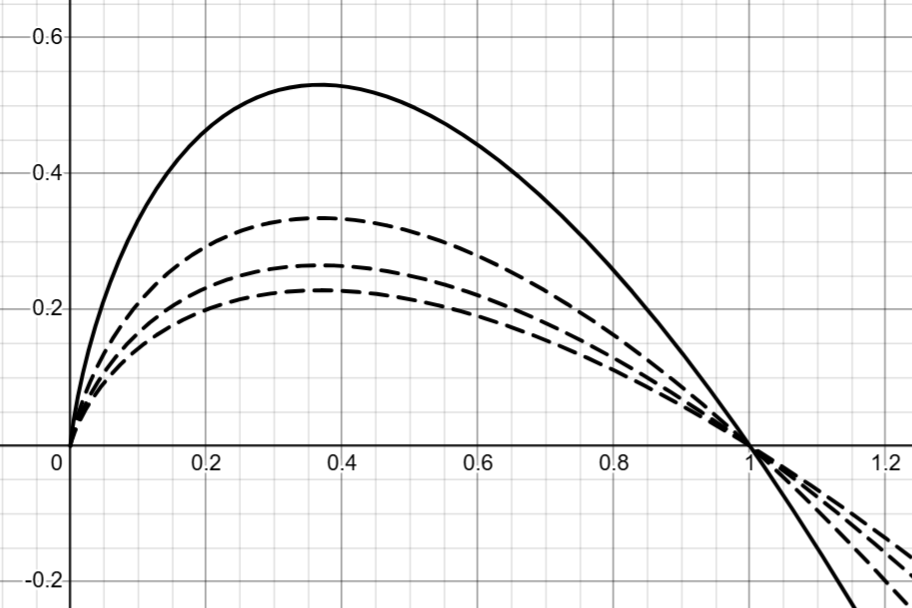
在应用熵正则化项时我们会为其赋予一个权重系数ccc。根据对数换底公式,熵正则化中底数的影响可以被吸收进ccc中。ccc越大,目标越鼓励策略的随机性,而底数在实际实现中通常采用自然常数eee。
现在我们来计算熵正则化的梯度,对于期望内部有
∇θH(πθ(⋅∣s))=−∇θ∫πθ(a∣s)logπθ(a∣s)da=−∫(∇θπθ(a∣s)⋅logπθ(a∣s)+πθ(a∣s)⋅∇θπθ(a∣s))da=−∫(πθ(a∣s)∇θlogπθ(a∣s)⋅logπθ(a∣s)+πθ(a∣s)⋅∇θπθ(a∣s))da=−∫πθ(a∣s)∇θlogπθ(a∣s)(logπθ(a∣s)+1)da=−Ea∼πθ[(1+logπθ(a∣s))∇θlogπθ(a∣s)] \begin{split} \nabla_\theta\mathcal H(\pi_\theta(\cdot|s))&=-\nabla_\theta\int\pi_\theta(a|s)\log\pi_\theta(a|s)\mathrm da\\ &=-\int(\nabla_\theta\pi_\theta(a|s)\cdot\log\pi_\theta(a|s)+\pi_\theta(a|s)\cdot\nabla_\theta\pi_\theta(a|s))\mathrm da\\ &=-\int(\pi_\theta(a|s)\nabla_\theta\log\pi_\theta(a|s)\cdot\log\pi_\theta(a|s)+\pi_\theta(a|s)\cdot\nabla_\theta\pi_\theta(a|s))\mathrm da\\ &=-\int\pi_\theta(a|s)\nabla_\theta\log\pi_\theta(a|s)(\log\pi_\theta(a|s)+1)\mathrm da\\ &=-\mathbb E_{a\sim\pi_\theta}[(1+\log\pi_\theta(a|s))\nabla_\theta\log\pi_\theta(a|s)] \end{split} ∇θH(πθ(⋅∣s))=−∇θ∫πθ(a∣s)logπθ(a∣s)da=−∫(∇θπθ(a∣s)⋅logπθ(a∣s)+πθ(a∣s)⋅∇θπθ(a∣s))da=−∫(πθ(a∣s)∇θlogπθ(a∣s)⋅logπθ(a∣s)+πθ(a∣s)⋅∇θπθ(a∣s))da=−∫πθ(a∣s)∇θlogπθ(a∣s)(logπθ(a∣s)+1)da=−Ea∼πθ[(1+logπθ(a∣s))∇θlogπθ(a∣s)]
则
∇θLENT(θ)=Es∼πθ[∇θH(πθ(⋅∣s))]=−Es∼πθ[Ea∼πθ[(1+logπθ(a∣s))∇θlogπθ(a∣s)]]=−E(s,a)∼πθ[(1+logπθ(a∣s))∇θlogπθ(a∣s)] \begin{split} \nabla_\theta L_{\mathrm ENT}(\theta)&=\mathbb E_{s\sim{\pi_\theta}}[\nabla_\theta\mathcal H(\pi_\theta(\cdot|s))]\\ &=-\mathbb E_{s\sim{\pi_\theta}}[\mathbb E_{a\sim\pi_\theta}[(1+\log\pi_\theta(a|s))\nabla_\theta\log\pi_\theta(a|s)]]\\ &=-\mathbb E_{(s,a)\sim\pi_\theta}[(1+\log\pi_\theta(a|s))\nabla_\theta\log\pi_\theta(a|s)] \end{split} ∇θLENT(θ)=Es∼πθ[∇θH(πθ(⋅∣s))]=−Es∼πθ[Ea∼πθ[(1+logπθ(a∣s))∇θlogπθ(a∣s)]]=−E(s,a)∼πθ[(1+logπθ(a∣s))∇θlogπθ(a∣s)]
总损失函数
PPO值函数的更新方式即最小化均方蒙特卡洛误差
LVF(θ)=Es∼πθ[(Vw(st)−Gt)2] L_{\mathrm{VF}}(\theta)=\mathbb E_{s\sim\pi_\theta}[(V_w(s_t)-G_t)^2] LVF(θ)=Es∼πθ[(Vw(st)−Gt)2]
PPO在实现中将所有损失函数和目标函数合并为一个总损失函数
L=LCLIP+c1LENT−c2LVF L=L_{\mathrm{CLIP}}+c_1L_{\mathrm{ENT}}-c_2L_{\mathrm{VF}} L=LCLIP+c1LENT−c2LVF
其中权重系数c1c_1c1和c2c_2c2用于平衡三者的更新。
由此,代码可以简洁地使用同一个优化器和同一次反向传播来更新所有参数,同时可以实现策略网络和价值网络共享底层的特征提取层,提升学习效率。
算法流程
在其他技术细节上,PPO结合了A2C的多智能体并行和DQN的经验回放,最终完整的算法流程如下:
- 初始化Actor网络参数θ\thetaθ,Critic V网络参数www;
- 超参数:裁剪阈值ϵ\epsilonϵ,权重系数c1c_1c1和c2c_2c2,广义优势估计权重λ\lambdaλ;
- 循环:
- 使用当前策略πθ\pi_\thetaπθ在环境中并行运行NNN个智能体,收集TTT个时间步的数据并存入经验缓冲区;
- 对于缓冲区中的每个时间步ttt,计算累积回报GtG_tGt和广义优势估计A(st,at)A(s_t,a_t)A(st,at);
- 将整个缓冲区视为一个数据集,随机打乱后分成小批量;
- 对每个小批量重复KKK次:
- 计算概率比rt(θ)r_t(\theta)rt(θ);
- 计算组合目标函数L(θ)L(\theta)L(θ);
- 根据梯度同时更新参数θ\thetaθ和www;
- 将参数θ\thetaθ同步到当前策略,进入下一轮迭代;
- 直到Actor网络和Critic网络收敛。