商户查询更新缓存(opsForHash、opsForList、ObjectMapper、@Transactional、@PutMapping)
目录
- 一、缓存定义:
- 二、使用Hash结构缓存商户详情信息:
- 三、使用List结构缓存商户类型列表:
- 四、缓存更新:
- 1.删除缓存还是更新缓存?
- 2.如何保证缓存与数据库的操作同时成功或失败?
- 3.先操作缓存还是先操作数据库?
- 4.缓存更新最佳方案:
- 5.商户详情信息更新:
- 五、缓存穿透:
- 1.缓存空对象:
- 2.布隆过滤:
- 3.缓存空对象解决查看相互详情信息功能:
- 4.主动解决缓存穿透:
- 回顾的知识点:
- @Transactional注解:
- @PutMapping注解:
- null和""(空对象)的区别:
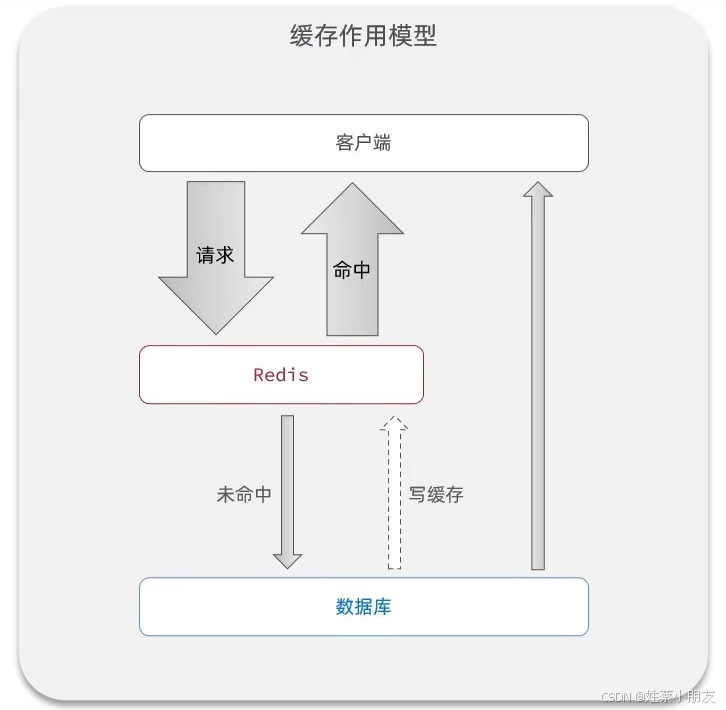
一、缓存定义:
缓存就是数据交换的缓冲区Cache,是存储数据的临时区,读写性能比较高。
二、使用Hash结构缓存商户详情信息:
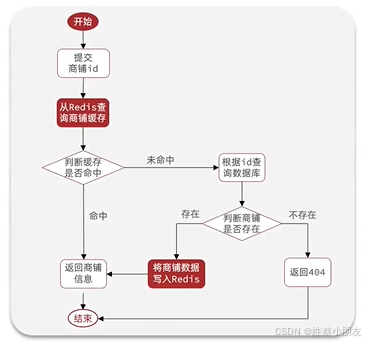
@Service
public class ShopServiceImpl extends ServiceImpl<ShopMapper, Shop> implements IShopService {@Autowiredprivate StringRedisTemplate stringRedisTemplate;public Result queryById(long id){// 先查缓存Map<Object, Object> entries = stringRedisTemplate.opsForHash().entries(String.valueOf(id));// 缓存为空查mysqlif (entries.isEmpty()){Shop shop = getById(id);// mysql为空返回failif (shop == null){return Result.fail("商户信息不存在");}// 写入信息到缓存stringRedisTemplate.opsForHash().putAll(String.valueOf(id), BeanUtil.beanToMap(shop, new HashMap<>(),CopyOptions.create().setIgnoreNullValue(true).setFieldValueEditor((fieldName, fieldValue)-> {if (fieldValue == null) {return null; // 显式处理 null 值}return fieldValue.toString();})));stringRedisTemplate.expire(String.valueOf(id), 30, TimeUnit.MINUTES);return Result.ok(shop);}return Result.ok(BeanUtil.fillBeanWithMap(entries,new Shop(),false));}
}
三、使用List结构缓存商户类型列表:
@Service
public class ShopTypeServiceImpl extends ServiceImpl<ShopTypeMapper, ShopType> implements IShopTypeService {@Autowiredpublic StringRedisTemplate stringRedisTemplate;// SpringMVC中默认使用的JSON处理工具@Autowiredprivate ObjectMapper mapper;@Overridepublic Result queryTypeList() {// 先查redisList<String> shopTypeList = stringRedisTemplate.opsForList().range("shopTypeList", 0, -1);// redis为空if (shopTypeList.isEmpty()){// 查mysql数据库List<ShopType> typeList = query().orderByAsc("sort").list();// mysql数据库也为空if (typeList.isEmpty()){return Result.fail("无商户列表");}// 序列化将List<ShopType>转化为List<String>List<String> list = typeList.stream().map(str->{try {return mapper.writeValueAsString(str);//序列化} catch (JsonProcessingException e) {e.printStackTrace();}return null;//这里没用}).collect(Collectors.toList());// 写入List<String>到redisstringRedisTemplate.opsForList().leftPushAll("shopTypeList",list);// 返回List<ShopType>return Result.ok(typeList);}// 反序列化,输出要求是List<ShopType>List<ShopType> l = shopTypeList.stream().map(str->{try {return mapper.readValue(str, ShopType.class);//反序列化} catch (JsonProcessingException e) {e.printStackTrace();}return null;//这里没用}).collect(Collectors.toList());return Result.ok(l);}
}
四、缓存更新:
缓存更新:由调用者在更新数据库的同时更新缓存。
同时操作缓存和数据库有三个问题需要考虑:
- 删除缓存还是更新缓存?
- 如何保证缓存与数据库的操作同时成功或同时失败?
- 先操作缓存还是先操作数据库?
1.删除缓存还是更新缓存?
更新缓存:每次更新数据库都更新缓存。若更新次数多但是查询次数少,那么频繁的更新redis就是无效的操作,即更新缓存时无效写操作较多。
删除缓存:更新数据库时让缓存失效,查询时再重新更新缓存。不会出现无效写的问题,但是如果频繁交替执行更新和查询操作效率低。
一般使用删除缓存。
2.如何保证缓存与数据库的操作同时成功或失败?
若是单体系统,将缓存与数据库操作放在一个事务中。
若是分布式系统,利用TCC等分布式事务方案。(SpringCloud内容)
3.先操作缓存还是先操作数据库?
两种情况都可能出现线程安全问题:
先删除缓存再操作数据库,可能会出现读脏数据的情况。
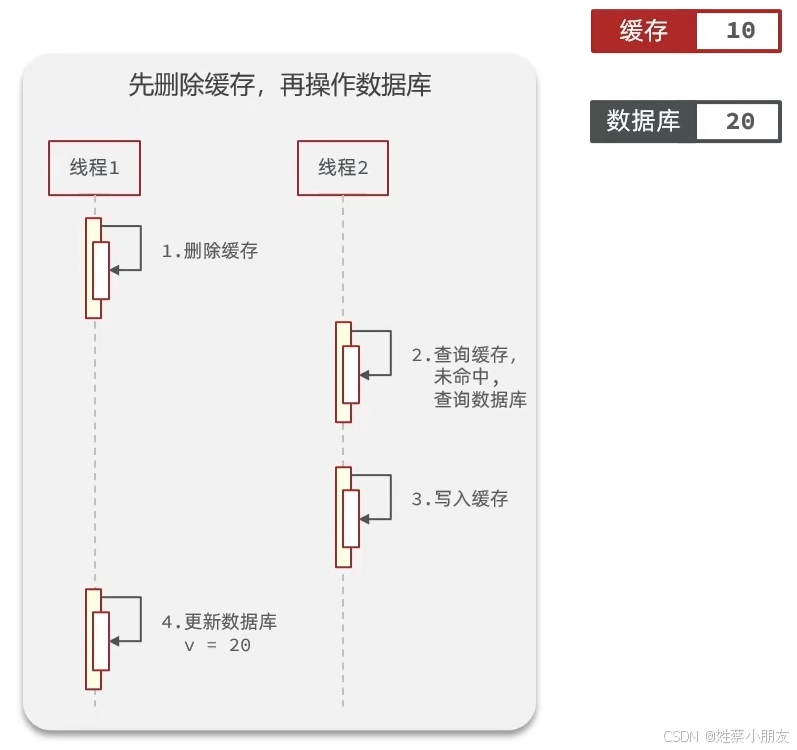
初始缓存和数据库内容都是10。线程1删除缓存后,线程2获得调度查询数据库并写入脏数据到缓存,线程1更新数据库为20。这种情况的发生概率很高,因为删除和查询操作都很快,并且是针对缓存的,更快。但是更新操作就比较慢,而且是针对数据库的,很容易出现脏读的情况。
先操作数据库再删除缓存,出现脏读的几率很低,但不是完全不可能发生:
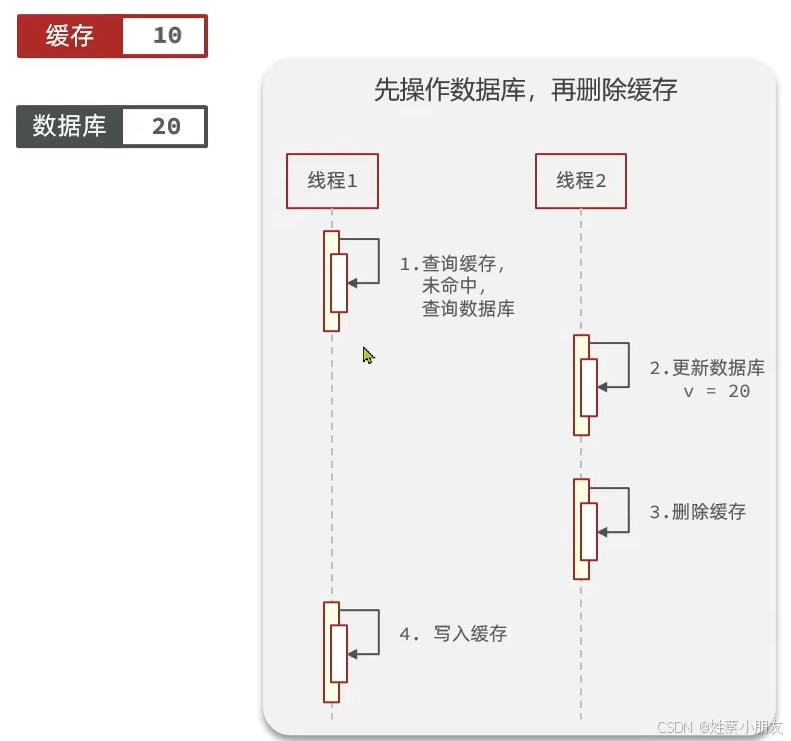
初始缓存和数据库内容都是10。当缓存失效时,线程1会读数据库得到10,此时线程2会更新数据库为20,然后山城1将得到的10写入缓存,才可能会导致脏读。但是更新数据库的操作是比较慢的,所以3小概率才能比4早执行,所以概率低。
4.缓存更新最佳方案:
- 读操作:
- 缓存命中则直接返回
- 缓存未命中则查询数据库,写入缓存
- 写操作:
- 先写数据库后删除缓存 (隔离性)
- 确保数据库与缓存操作要么全执行要么全不执行 (原子性)
5.商户详情信息更新:
@Service
public class ShopServiceImpl extends ServiceImpl<ShopMapper, Shop> implements IShopService {@Autowiredprivate StringRedisTemplate stringRedisTemplate;@Override@Transactional // 事务保障原子性(要么全执行要么全不执行)public Result update(Shop shop) {Long id = shop.getId();if(id == null){return Result.fail("无此商户");}// 更新数据库updateById(shop);// 删除缓存stringRedisTemplate.delete(String.valueOf(id));return Result.ok();}
}
五、缓存穿透:
缓存穿透是指客户端请求的数据在缓存和数据库中都不存在,这样缓存永远不会生效,这些请求都会到达数据库。
如果有人使用无数的线程并发的发起请求来获取数据库和缓存中都不存在的数据,那么所有请求都会到达数据库,从而导致数据库负载过大崩溃。这就是缓存穿透。
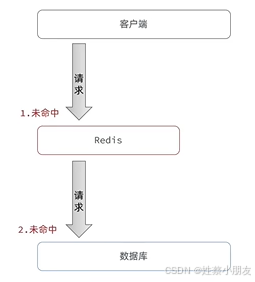
1.缓存空对象:
缓存空对象是指尽管某个请求获取的数据在数据库和缓存中都不存在,那么也会在缓存中缓存一个null值,下次如果还是相同的请求,那么就能在缓存中获取值,不用访问数据库,缓解数据库压力。
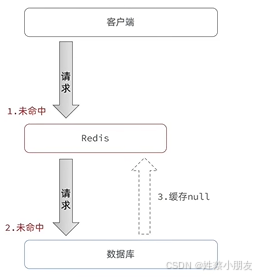
缺点:
- redis中缓存了过多垃圾信息导致额外的内存消耗(可以通过给null缓存设置一个较短的TTL来缓解这个问题)
- 可能会存在短期的数据不一致性。当用户访问时,数据库和缓存中都不存在对应的信息,所以在redis中缓存null,此时如果插入对应信息到数据库,那么用户后续访问时由于redis中有对应值,只能返回null,而对应数据是真实存在数据库中的,只有null的TTL过期后才能查数据库得到真实数据。(当插入数据到数据库时,主动将该数据更新到缓存可以解决这个问题,但是上面学到的更新数据都会先删缓存再更新,就就不会有这个不一致性问题了?)
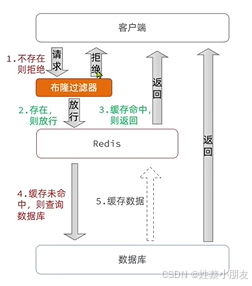
2.布隆过滤:
布隆过滤器通过在redis之前引入一个过滤器,来判断当前请求的数据是否存在于redis或数据库,如果都不存在就直接拒绝访问redis和数据库。 防止负载过大。
布隆过滤是一种算法,是一个byte数组,对于数据库中的数据,给予某种哈希算法计算出哈希值,将哈希值转换成二进制位存储到byte数组中。当判断数据库中的数据是否存在时,通过判断byte数组中对应位置是0还是1以此判断请求的数据是否存在,空间占用小(bitMap数据结构)。
- 当布隆过滤器返回“不存在”时,那么请求的数据100%不存在。
- 当布隆过滤器返回“存在”时,那么请求的数据也不一定存在。(虽然缓解了缓存穿透,但由于不准确还是会有一定的缓存穿透问题)
3.缓存空对象解决查看相互详情信息功能:
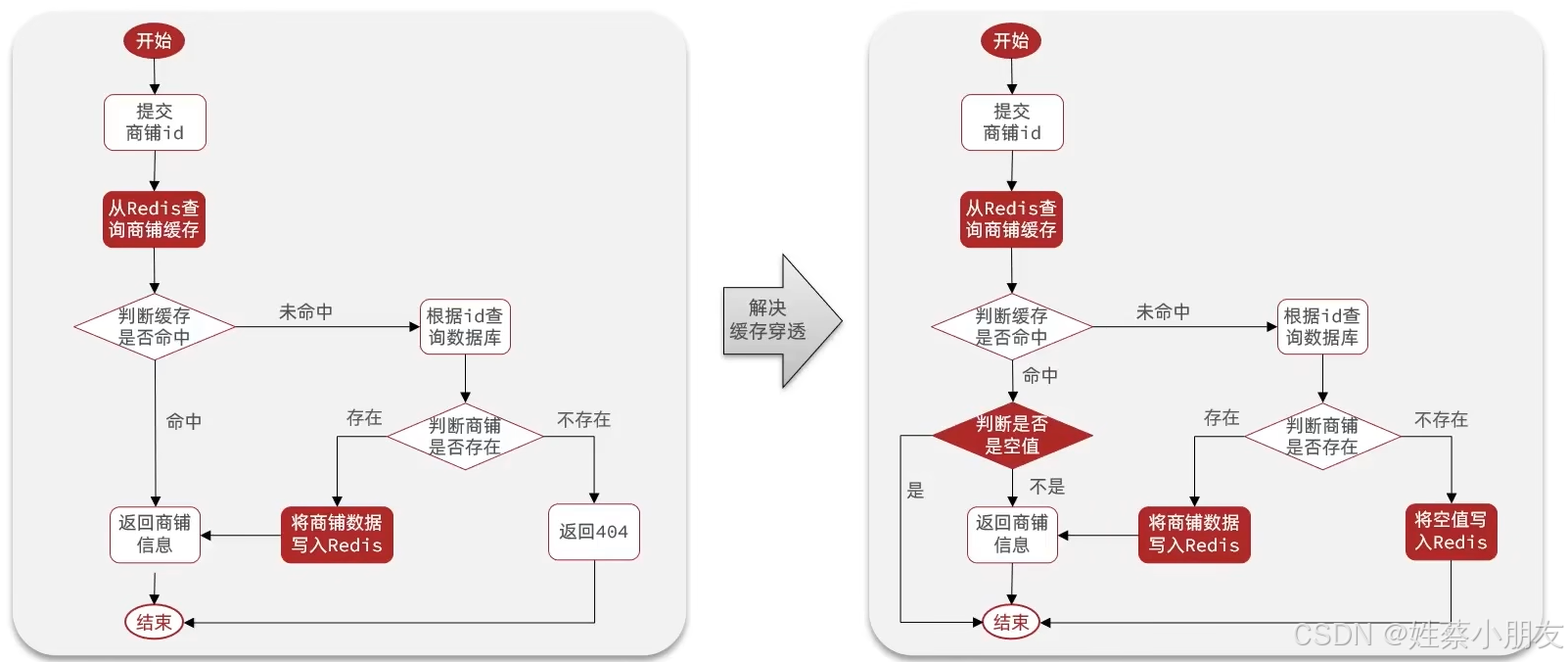
4.主动解决缓存穿透:
缓存空对象和布隆过滤都是出现缓存穿透后被动的进行处理。完全可以通过主动的方式来避免缓存穿透:
- 增强id的复杂度,在此基础上做好数据的基础格式校验,在格式校验阶段就能拦截,接触不到数据库。
- 加强用户权限校验。
- 做好热点参数的限流。