微服务面试题(14题)
微服务面试题
1. SpringCloud 常用组件及作用
- 服务注册发现:Eureka/Nacos/Consul,管理服务地址,实现服务动态注册与发现,让消费者能找到提供者。
- 负载均衡:Ribbon/Spring Cloud LoadBalancer,客户端层面分配请求到不同服务实例,避免单实例过载。
- 远程调用:OpenFeign,声明式 HTTP 客户端,通过接口注解简化服务间调用(底层集成负载均衡组件)。
- API 网关:Gateway,统一入口,处理路由转发、限流、认证、跨域等,屏蔽服务内部细节。
- 服务容错:Hystrix/Sentinel,解决服务雪崩,提供熔断(故障断连)、降级(非核心功能关闭)、限流(控制请求量)能力。
- 分布式配置:Config/Nacos Config,集中管理多环境配置,支持动态刷新,避免修改配置后重启服务。
- 链路追踪:Sleuth+Zipkin,监控服务调用链路,定位慢查询、异常节点,排查跨服务问题。
2. 服务注册发现的基本流程
- 服务注册:服务启动时,将自身信息(IP、端口、服务名)主动注册到注册中心(如 Nacos)。
- 服务续约:服务定期向注册中心发送心跳(Nacos 默认 5 秒一次),证明自身存活,防止被误判为故障并剔除。
- 服务发现:消费者启动后,从注册中心拉取目标服务的实例列表,缓存到本地,用于后续调用。
- 动态更新:注册中心检测到服务实例上下线(如宕机、新增)时,主动推送更新后的实例列表给消费者,或消费者定期拉取,保证地址最新。
- 服务下线:服务正常关闭时,主动通知注册中心删除自身信息;若意外宕机,注册中心超时(Nacos 默认 30 秒)后剔除该实例。
3. Eureka 和 Nacos 的区别
| 对比维度 | Eureka | Nacos |
|---|---|---|
| 核心功能 | 仅支持服务注册发现 | 注册发现 + 分布式配置中心(一站式) |
| 健康检测机制 | 客户端 30 秒发一次心跳,90 秒未收到则标记疑似故障 | 客户端 5 秒发一次心跳,15 秒超时、30 秒剔除;支持服务端主动检测 |
| 服务列表更新 | 消费者 30 秒主动拉取,无推送 | 消费者定期拉取 + 注册中心主动推送(更新更及时) |
| 集群数据一致性 | 仅支持 AP(优先可用性,允许短暂不一致) | 支持 AP/CP 切换(默认 AP,满足不同场景) |
| 实例清理频率 | 60 秒执行一次清理任务 | 5 秒执行一次,故障实例剔除更快 |
| 附加能力 | 无 | 支持环境隔离(namespace)、分级存储(cluster)、权重配置 |
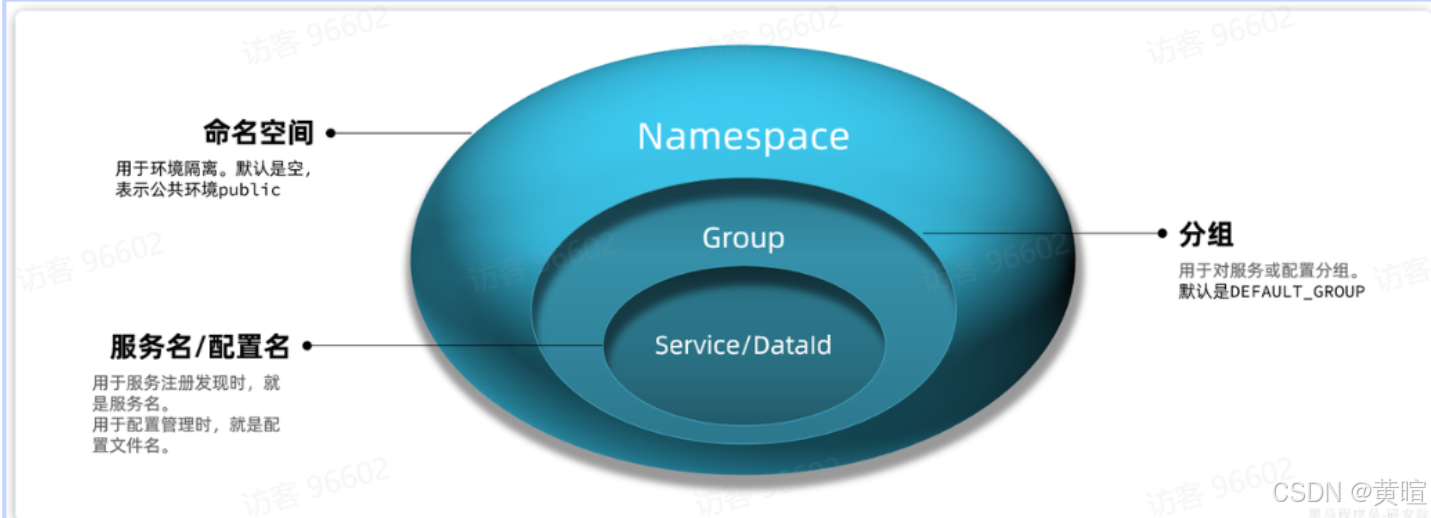
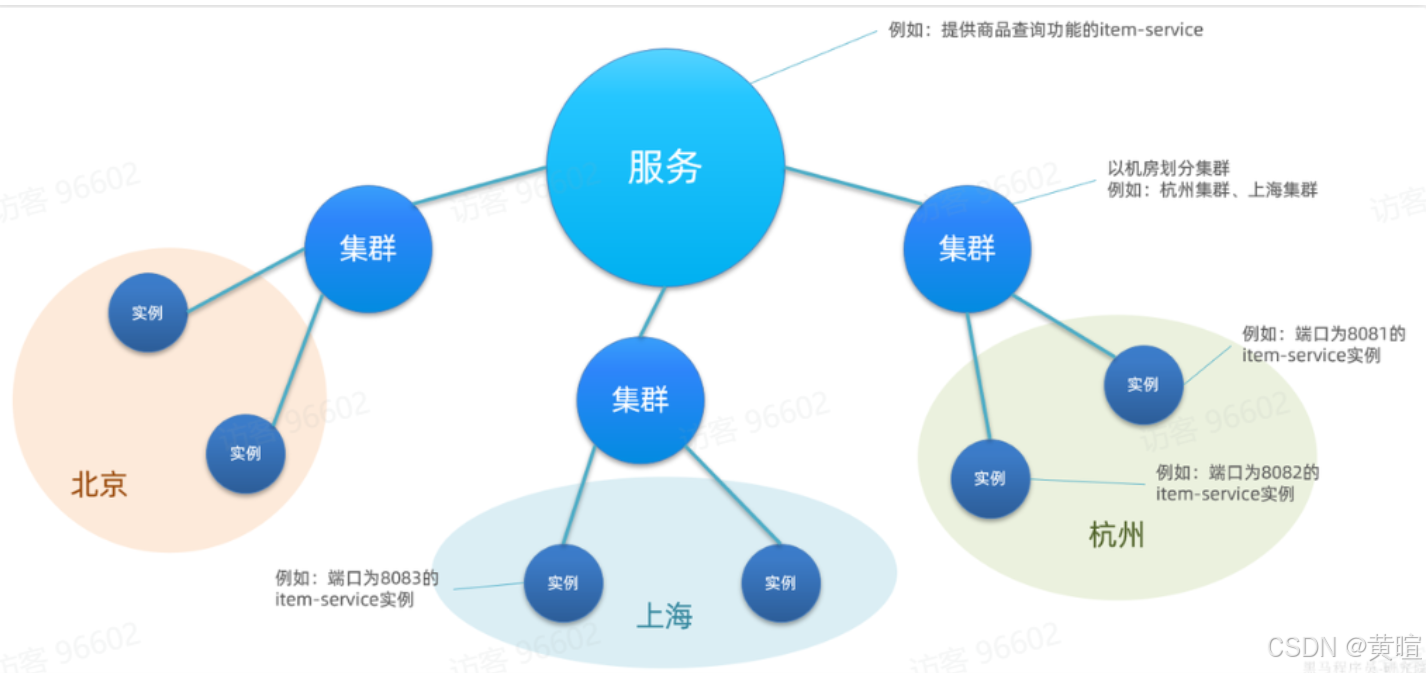
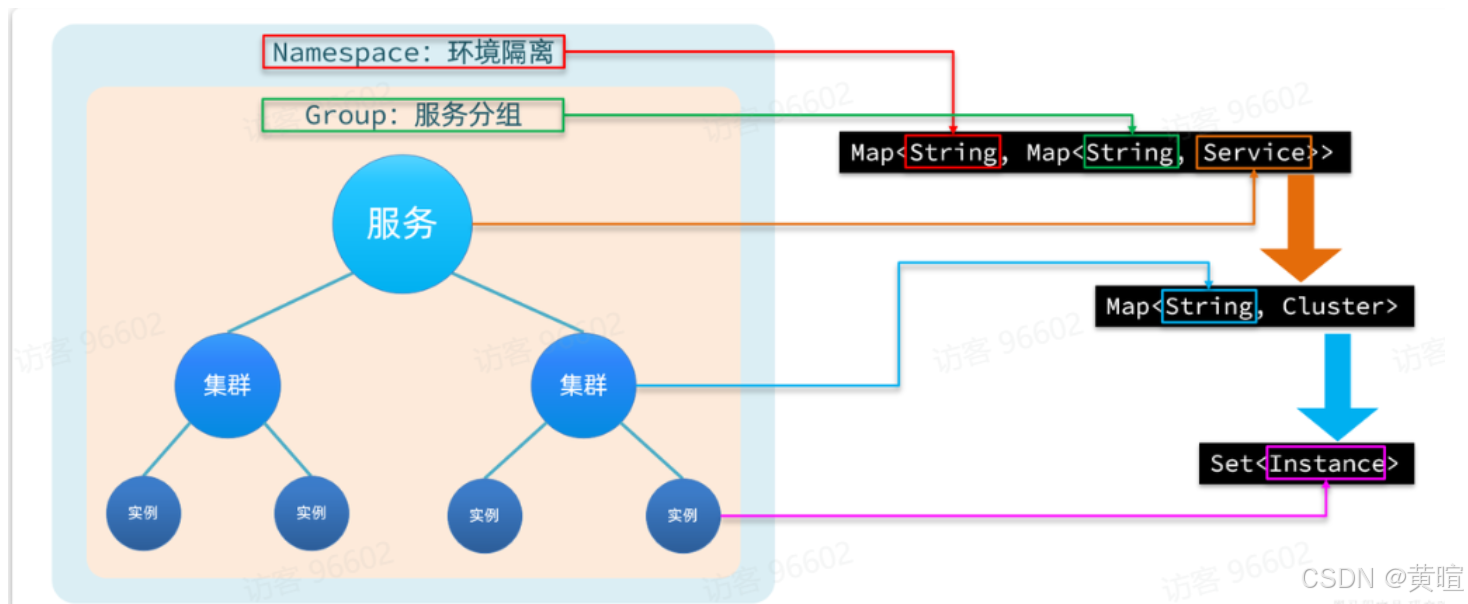
4. Nacos 的分级存储模型
Nacos 的服务存储按 “namespace(命名空间)→ group(分组)→ service(服务)→ cluster(集群)→ instance(实例) ” 五级结构组织,核心是通过分级实现精细化管理:
- namespace:用于环境 / 项目隔离,如开发、测试、生产环境用不同 namespace,相互不可访问。
- group:同一 namespace 下的服务分组,如将 “支付相关服务” 归为 “pay-group”,默认分组为 DEFAULT_GROUP。
- service:具体微服务名称,如 “user-service”“order-service”,是服务注册发现的核心标识。
- cluster:同一服务部署在不同机房的分组,如 “北京集群”“上海集群”,用于优先调用同机房实例,减少跨地域延迟。
- instance:集群下的具体服务节点(IP + 端口),是实际处理请求的单元。
作用:实现环境隔离、跨机房优化、服务分组管理,提升大型分布式系统的可用性和维护性。
5. OpenFeign 是如何实现负载均衡的
OpenFeign 自身不实现负载均衡,而是集成 Spring Cloud LoadBalancer(SpringCloud 2020 后替代 Ribbon)完成,核心流程如下:
- 定义调用接口:通过
@FeignClient("服务名")注解声明远程调用接口,指定目标服务名(如 “item-service”)。 - 获取服务实例列表:调用接口时,OpenFeign 底层通过 Spring Cloud LoadBalancer 的
LoadBalancerClient,从注册中心拉取目标服务的实例列表(并缓存,减少重复拉取)。 - 执行负载均衡算法:
LoadBalancerClient根据配置的算法(默认轮询,可切换为 Nacos 权重、随机等),从实例列表中选择一个可用实例。 - 重构请求 URL:将接口中声明的 “服务名 + 路径”,替换为选中实例的 “IP + 端口 + 路径”,生成真实请求地址。
- 发起 HTTP 请求:通过底层 HTTP 客户端(如 OKHttp)向真实地址发送请求,获取响应并封装返回。
6. 什么是服务雪崩?常见的解决方案有哪些
- 服务雪崩:当一个服务故障(如超时、宕机),依赖它的下游服务会因等待响应而阻塞,进而导致下游的下游服务也故障,最终整个调用链路崩溃的连锁反应。
- 常见解决方案:
- 熔断:当服务调用失败率达到阈值(如 50%),自动 “断开” 调用,直接返回降级结果(如 Hystrix 熔断、Sentinel 熔断),避免阻塞扩散。
- 降级:服务压力过大时,关闭非核心功能(如商品详情页不展示推荐列表),返回默认数据(如缓存数据),保证核心功能可用。
- 限流:限制单位时间内的请求量(如每秒 1000 次),超出部分拒绝或排队,避免服务被过载请求压垮(如 Sentinel 滑动窗口限流)。
- 超时控制:给服务调用设置超时时间(如 2 秒),超时直接返回失败,避免线程长期阻塞。
- 线程隔离:给不同服务的调用分配独立线程池(Hystix)或信号量(Sentinel),一个服务故障不会耗尽整个应用的线程资源。
7. Hystrix 和 Sentinel 的区别和联系
两者都是微服务的服务容错组件,核心作用是通过熔断、降级、限流解决服务雪崩问题,保护系统稳定性。
区别:
- 维护状态:Hystrix 已停止维护;Sentinel 活跃更新,功能更全。
- 隔离方式:Hystrix 默认用线程池隔离(重但稳定);Sentinel 默认用信号量隔离(轻量高效)。
- 配置灵活性:Hystrix 靠注解,改配置需重启;Sentinel 支持控制台动态配置,实时生效。
- 监控能力:Sentinel 自带强大控制台,能实时看流量、改规则;Hystrix 监控较简单。
8. 限流的常见算法有哪些
-
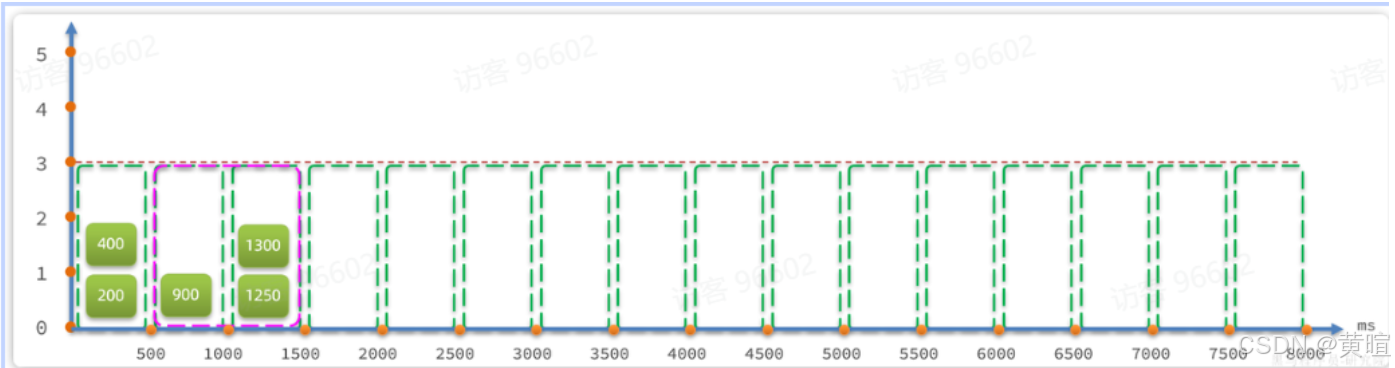
固定窗口算法:将时间划分为固定窗口(如 1 秒),统计窗口内请求数,超过阈值则限流。优点是简单,缺点是存在 “临界问题”(如 59 秒和 1 秒的请求叠加,超出阈值)。
-
滑动窗口算法:将固定窗口拆分为多个小格子(如 1 秒拆为 2 个 500ms 格子),窗口随时间滑动,统计当前窗口内所有格子的请求数。解决固定窗口的临界问题,统计更精准(Sentinel 默认使用)。
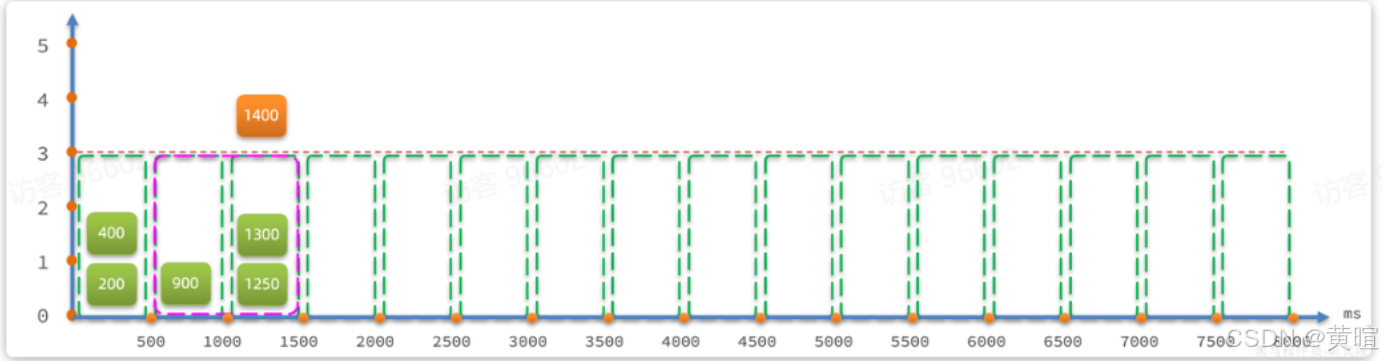
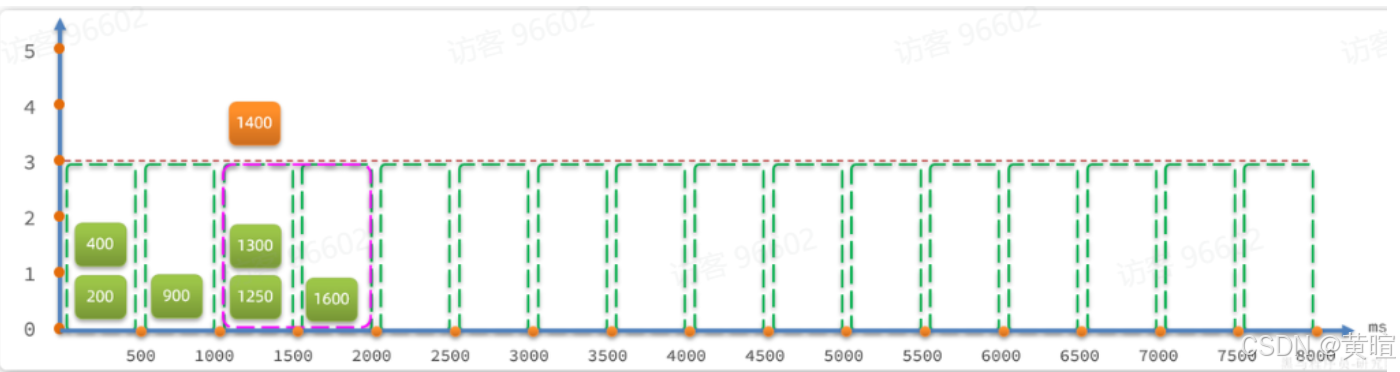
-
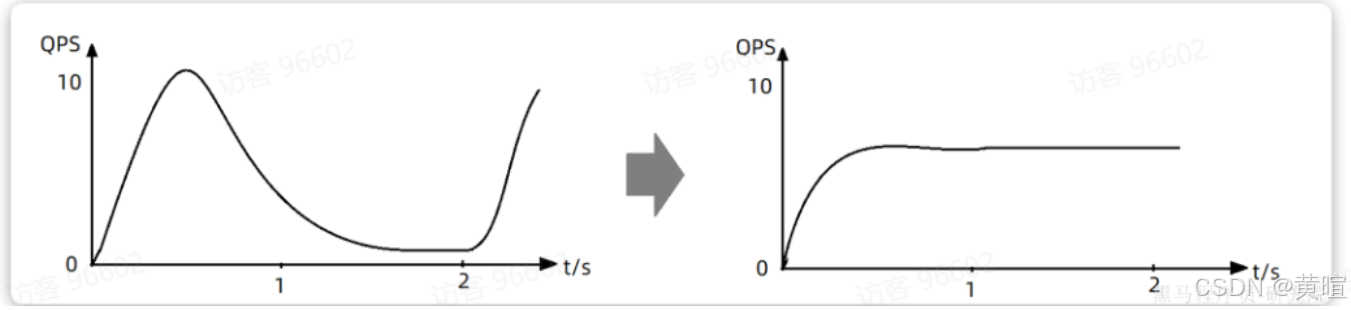
令牌桶算法:以固定速率(如每秒 100 个)生成令牌存入桶中,桶满则丢弃多余令牌;请求需获取令牌才能执行。支持突发流量(桶内缓存的令牌可应对短时间高请求),Sentinel 热点参数限流基于此实现。
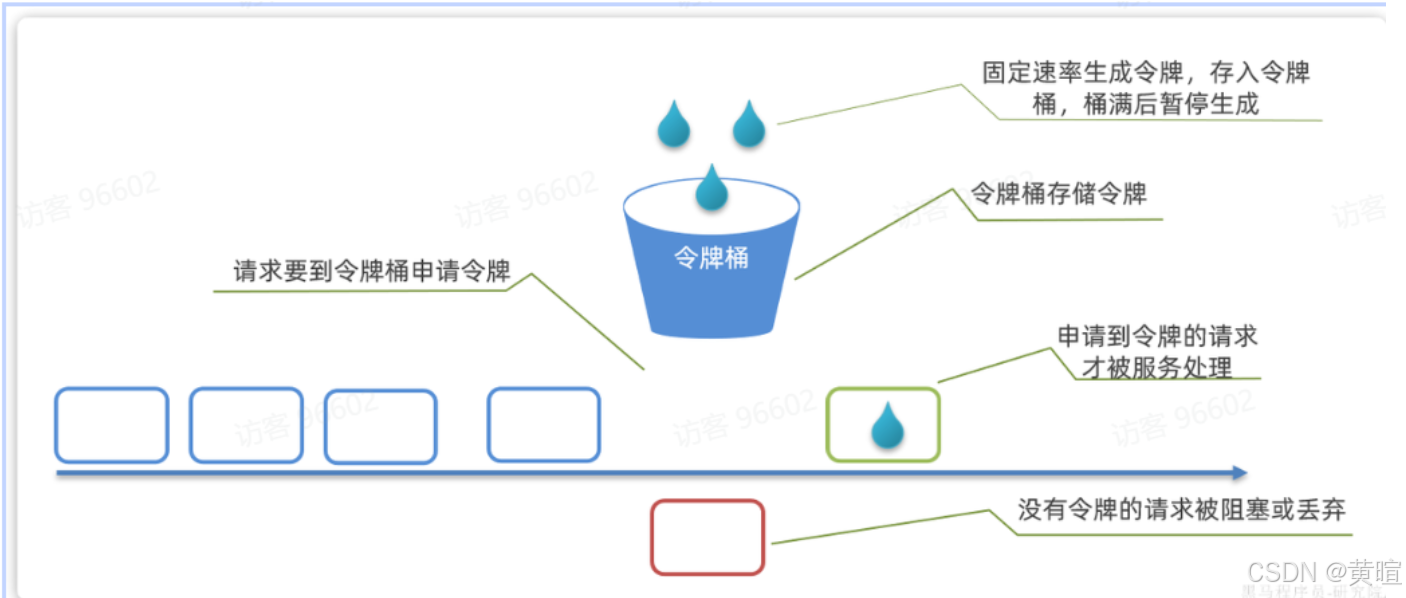
-
漏桶算法:请求先进入 “漏桶”(队列),桶以固定速率(如每秒 50 个)“漏水”(处理请求),桶满则丢弃新请求。优点是流量整型(输出速率平稳),Sentinel 排队等待功能基于此实现。
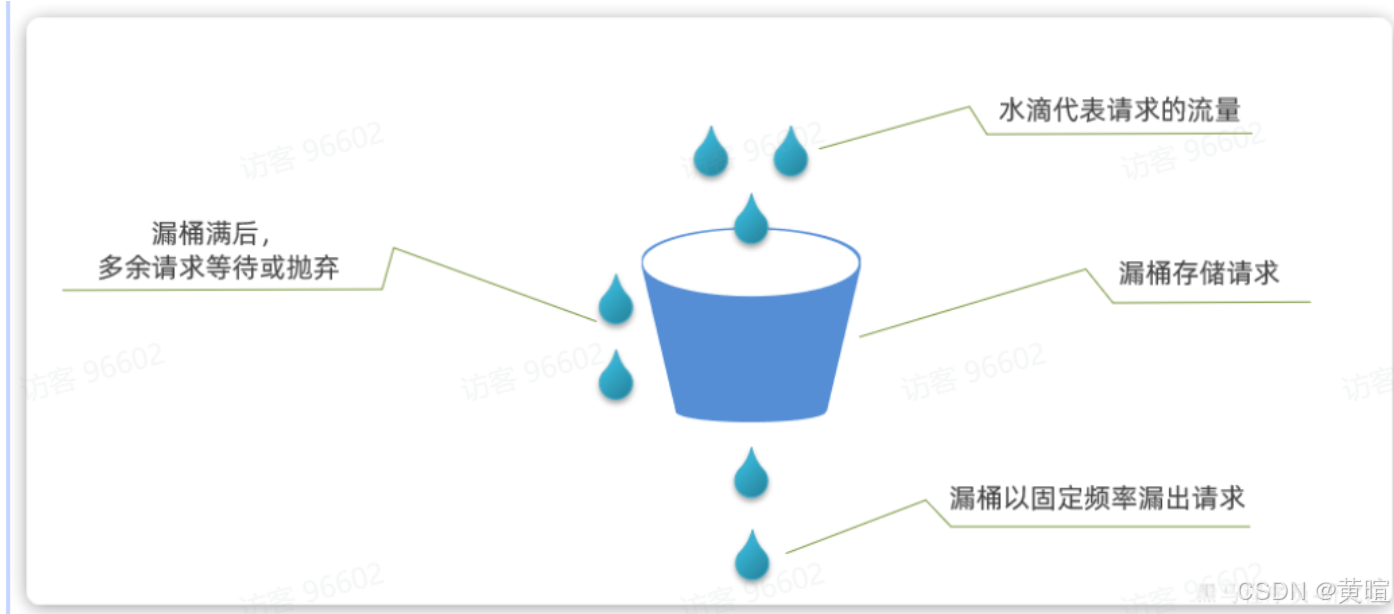
-
计数器算法:简单累计请求数,达到阈值则限流(本质是固定窗口的简化版),适用于对精度要求不高的场景。
9. 什么是 CAP 理论和 BASE 思想
-
CAP 理论:1998 年由 Eric Brewer 提出,分布式系统中,一致性(C)、可用性(A)、分区容错性(P) 三者无法同时满足,且分区容错性(P)是分布式系统的硬性要求(网络故障必然存在),因此需在 C 和 A 之间权衡:
-
一致性(C):所有节点访问到的数据完全一致(如修改后,所有节点立即同步最新数据)。
-
可用性(A):服务始终能正常响应请求(读 / 写操作不超时、不失败)。
-
分区容错性(P)网络分区(部分节点断连)时,系统仍能对外提供服务。
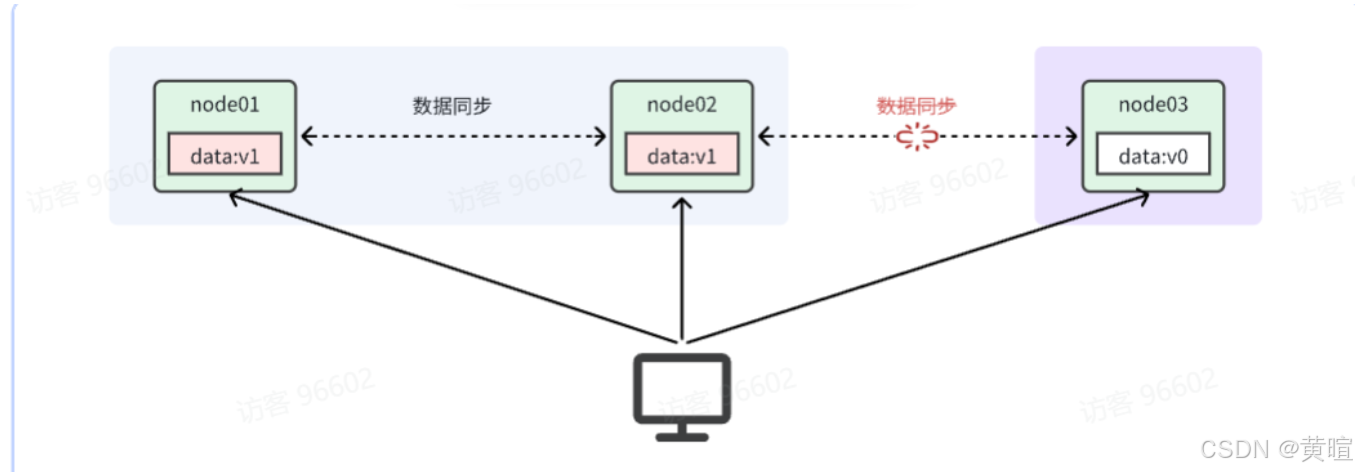
举例:Eureka 选 AP(优先可用性,允许短暂数据不一致),ZooKeeper 选 CP(优先一致性,分区时服务可能不可用)。
-
-
BASE 思想:是 CAP 理论的妥协方案,针对分布式系统 “无法同时满足 C 和 A” 的问题,提出 “放弃强一致性,追求最终一致性”:
- 基本可用(Basically Available):故障时允许损失部分可用性(如响应变慢、关闭非核心功能),但核心功能可用。
- 软状态(Soft State):允许数据存在临时不一致状态(如服务同步延迟),无需实时同步。
- 最终一致性(Eventually Consistent):经过一段时间(软状态结束),数据最终会达到一致(如分布式数据库同步、Nacos 服务列表更新)。
10. 项目中碰到过分布式事务问题吗?怎么解决的?
碰到过,例如 “下单扣库存” 场景:订单服务创建订单(操作订单库)、库存服务扣减库存(操作库存库),需保证两个操作要么都成功,要么都失败,否则会出现 “有订单无库存” 或 “无订单扣库存” 的问题。
解决方案:优先使用 Seata 框架,根据业务场景选择模式:
- AT 模式(默认):适用于简单 CRUD 场景,无需手动写补偿逻辑。Seata 会自动生成 undo log(回滚日志)和全局锁,第一阶段各服务本地提交事务,第二阶段成功则删除 undo log,失败则通过 undo log 回滚。
- TCC 模式:适用于复杂业务(如转账、分账),需手动实现 Try(资源检查 + 预留,如冻结库存)、Confirm(确认操作,如扣减冻结库存)、Cancel(回滚操作,如释放冻结库存)三个方法,灵活性高但开发成本高。
- 本地消息表:非事务场景(如日志同步),通过 “本地事务 + 消息队列” 实现最终一致。例如订单服务创建订单后,写 “扣库存消息” 到本地消息表(与订单操作同事务),再异步发送消息到 MQ,库存服务消费消息扣库存,失败则重试。
11. AT 模式如何解决脏读和脏写问题的?
Seata AT 模式通过 “全局锁 + undo log(回滚日志)+ 快照读” 解决脏读和脏写:
我们先回顾一下AT模式的流程,AT模式也分为两个阶段:
第一阶段是记录数据快照,执行并提交事务:
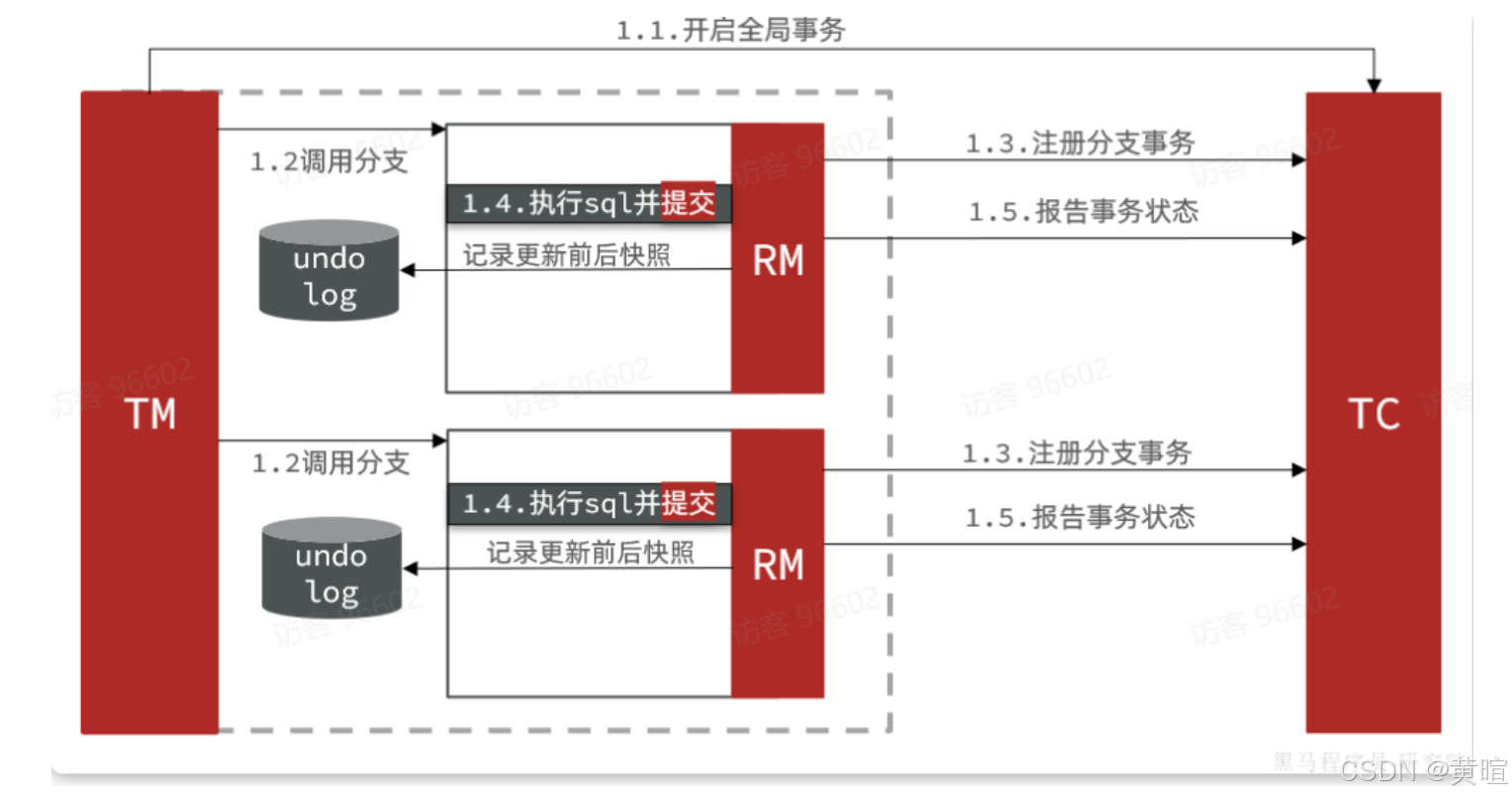
第二阶段根据阶段一的结果来判断:
- 如果每一个分支事务都成功,则事务已经结束(因为阶段一已经提交),因此删除阶段一的快照即可
- 如果有任意分支事务失败,则需要根据快照恢复到更新前数据。然后删除快照
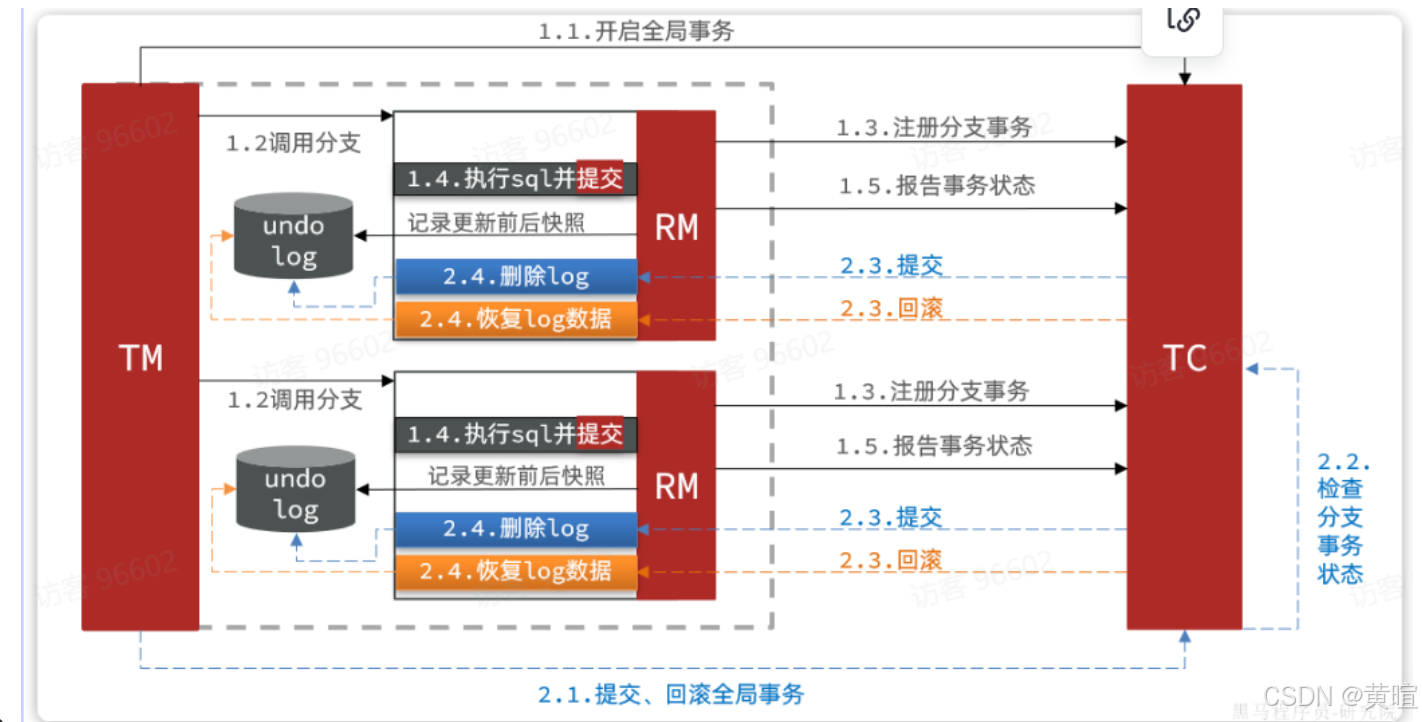
这种模式在大多数情况下(99%)并不会有什么问题,不过在极端情况下,特别是多线程并发访问AT模式的分布式事务时,有可能出现脏写问题,如图:

解决思路就是引入了全局锁的概念。在释放DB锁之前,先拿到全局锁。避免同一时刻有另外一个事务来操作当前数据。

- 脏写问题:多个事务同时修改同一数据导致的覆盖问题。解决:AT 模式在本地事务提交前,会先向 Seata Server 申请该数据的 “全局锁”,只有拿到全局锁的事务才能提交;未拿到则阻塞,直到全局锁释放。避免多个事务同时修改同一数据,防止脏写。
- 脏读问题:一个事务读取到另一个事务未提交的中间数据,后续该事务回滚导致读取的数据无效。解决:AT 模式在事务开始时,会记录数据的 “快照”(undo log 中的 before image,即修改前的原始数据);本地事务提交前,会对比当前数据与快照是否一致(检查是否被其他事务修改)。若一致则提交,若不一致则回滚,避免读取到未提交的脏数据。
12. TCC 模式与 AT 模式对比,有哪些优缺点
| 对比维度 | TCC 模式 | AT 模式 |
|---|---|---|
| 优点 | 1. 一阶段本地提交,释放数据库资源快,性能高;2. 不依赖数据库事务,支持非关系型数据库(如 Redis);3. 无全局锁,避免锁等待 | 1. 无代码侵入,Seata 自动生成补偿逻辑(undo log),开发成本低;2. 无需手动处理幂等、空回滚,易用性高 |
| 缺点 | 1. 代码侵入强,需手动实现 Try/Confirm/Cancel;2. 需处理特殊场景(幂等、空回滚、事务悬挂);3. 软状态,依赖最终一致 | 1. 依赖数据库事务,不支持非关系型数据库;2. 需全局锁,高并发下可能有锁等待,性能略低;3. 仅支持 CRUD 场景,复杂业务不适用 |
| 适用场景 | 复杂业务(转账、分账)、非关系型数据库 | 简单 CRUD 场景(订单、库存)、关系型数据库 |
事务悬挂和空回滚是什么?假如一个分布式事务中包含两个分支事务,try阶段,一个分支成功执行,另一个分支事务阻塞: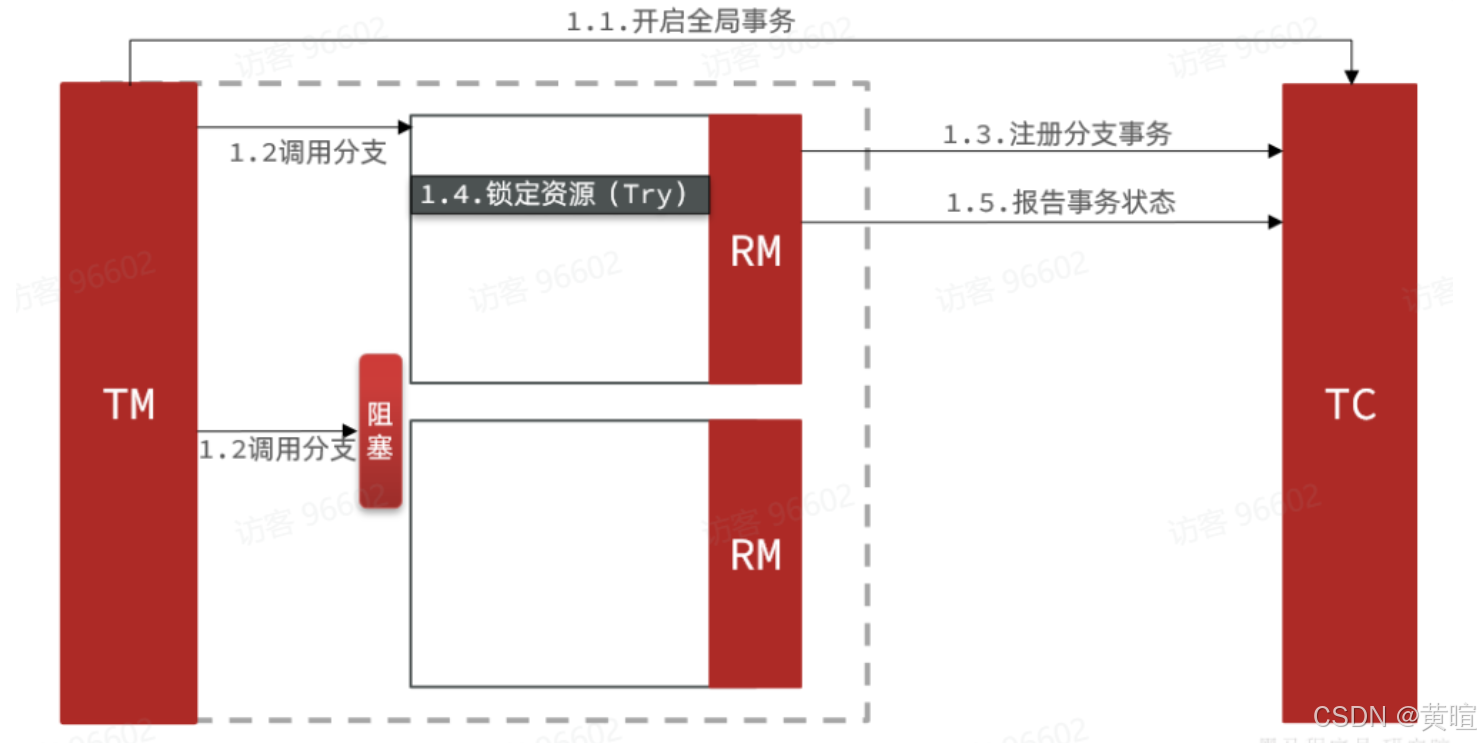
如果阻塞时间太长,可能导致全局事务超时而触发二阶段的cancel操作。两个分支事务都会执行cancel操作:
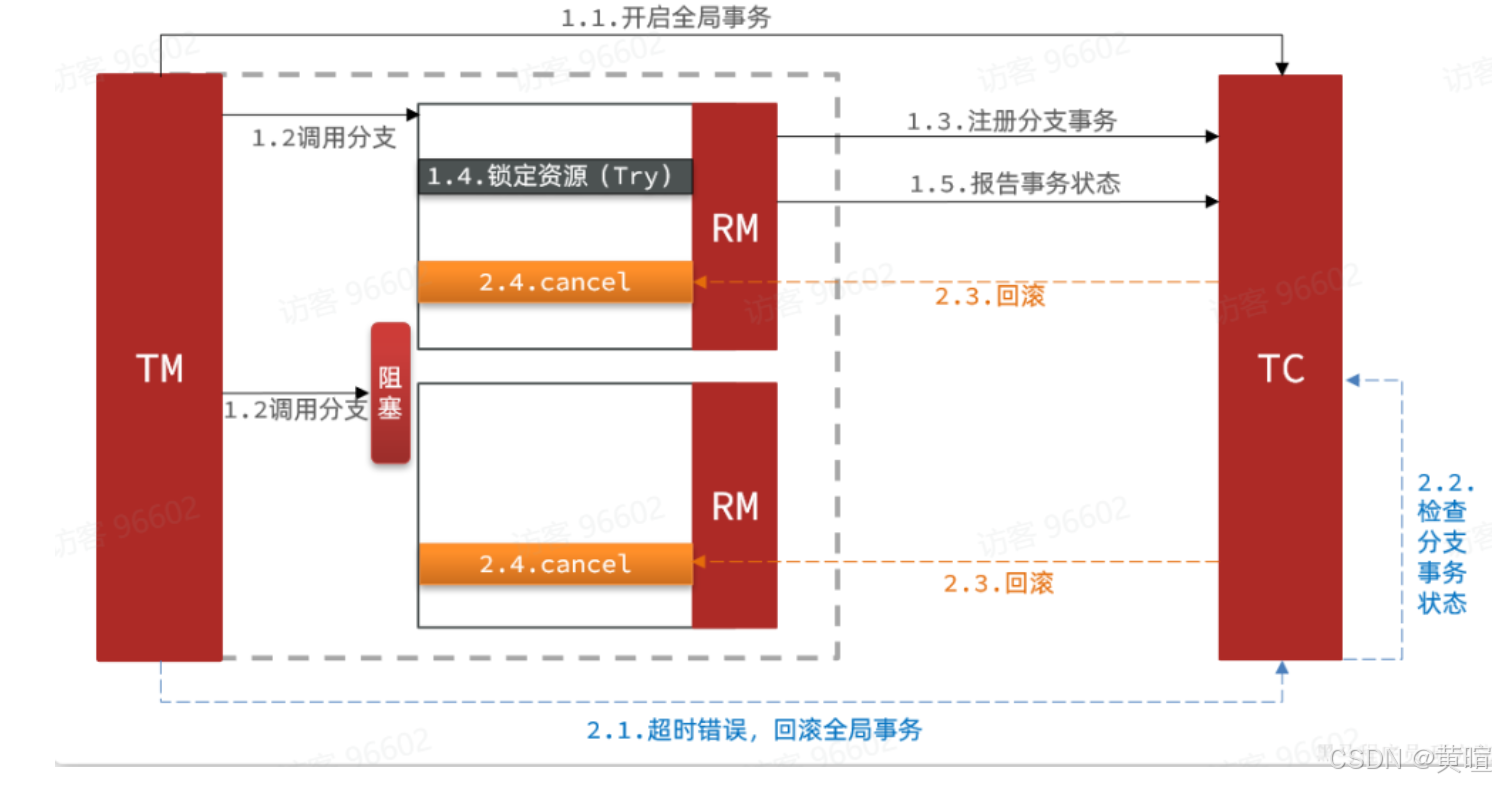
要知道,其中一个分支是未执行try操作的,直接执行了cancel操作,反而会导致数据错误。因此,这种情况下,尽管cancel方法要执行,但其中不能做任何回滚操作,这就是空回滚。
对于整个空回滚的分支事务,将来try方法阻塞结束依然会执行。但是整个全局事务其实已经结束了,因此永远不会再有confirm或cancel,也就是说这个事务执行了一半,处于悬挂状态,这就是业务悬挂问题。
以上问题都需要我们在编写try、cancel方法时处理。
13. RabbitMQ 是如何确保消息的可靠性的?
需从 “生产者→交换机→队列→消费者” 全链路保障,核心措施如下:
- 生产者端:确保消息成功发送到交换机。
- 开启
confirm机制:消息发送到交换机后,RabbitMQ 会回调confirmCallback,生产者根据回调结果判断是否发送成功,失败则重试。 - 开启
return机制:消息到达交换机但未路由到队列(如路由键错误),RabbitMQ 会回调returnCallback,生产者可捕获并处理(如重新发送、记录日志)。 - 消息持久化:通过
deliveryMode=2标记消息为持久化,避免 RabbitMQ 宕机导致消息丢失。
- 开启
- Broker 端(RabbitMQ 服务器):确保消息在交换机和队列中不丢失。
- 交换机持久化:创建交换机时指定
durable=true,避免交换机因 RabbitMQ 重启而消失。 - 队列持久化:创建队列时指定
durable=true,避免队列及队列中的消息因 RabbitMQ 重启而丢失。
- 交换机持久化:创建交换机时指定
- 消费者端:确保消息成功消费且不重复消费。
- 关闭自动 ACK(
autoAck=false):消费者处理完消息后,手动调用channel.basicAck()确认,未处理完则basicNack()拒绝,RabbitMQ 会重新投递消息。 - 避免重复消费:通过业务唯一 ID(如订单 ID)做幂等处理(如消费前查数据库,存在则跳过)。
- 关闭自动 ACK(
14. RabbitMQ 是如何解决消息堆积问题的?
消息堆积通常是 “消费速度<生产速度” 或 “消费者故障” 导致,解决方案如下:
- 临时扩容消费者:增加消费者实例数量(同一队列支持多消费者),分摊消费压力,快速消化堆积消息(需确保消费者逻辑线程安全)。
- 优化消费逻辑:简化消费流程(如减少数据库操作、异步处理非核心步骤)、批量消费(如一次拉取 10 条消息批量处理),提升单消费者处理速度。
- 死信队列 + 延迟重试:将堆积超时的消息(设置
x-message-ttl)转入死信队列,避免阻塞正常队列;后续通过独立消费者处理死信队列,或定时重试消费。 - 生产者限流:通过
channel.basicQos()设置生产者每次发送的消息数量,避免短时间内大量消息涌入队列(从源头控制消息生产速度)。
、批量消费(如一次拉取 10 条消息批量处理),提升单消费者处理速度。 - 死信队列 + 延迟重试:将堆积超时的消息(设置
x-message-ttl)转入死信队列,避免阻塞正常队列;后续通过独立消费者处理死信队列,或定时重试消费。 - 生产者限流:通过
channel.basicQos()设置生产者每次发送的消息数量,避免短时间内大量消息涌入队列(从源头控制消息生产速度)。 - 队列拆分:将单个大队列拆分为多个小队列(如按用户 ID 哈希分片),每个小队列分配独立消费者,实现 “并行消费”,提升整体消费能力。