EchoTraffic: Enhancing Traffic Anomaly Understanding with Audio-Visual Insights

标题:EchoTraffic:借助视听洞察提升交通异常理解能力
原文连接:https://openaccess.thecvf.com/content/CVPR2025/papers/Xing_EchoTraffic_Enhancing_Traffic_Anomaly_Understanding_with_Audio-Visual_Insights_CVPR_2025_paper.pdf
源码连接:https://github.com/HarryHsing/EchoTraffic
摘要
交通异常理解(TAU)通过及时检测和响应交通事件,对提升公共安全与交通效率至关重要。现有方法大多依赖视觉数据,本文提出纳入音频线索——这类线索能为碰撞、鸣笛等异常场景提供重要提示。本文的贡献主要有两点:第一,构建了首个面向TAU的大规模视听数据集AV-TAU,包含29,865段交通异常视频和149,325个问答对,支持五项核心TAU任务;第二,提出多模态大型语言模型EchoTraffic,通过音频洞察帧选择器和动态连接器有效提取关键音频线索,结合两阶段训练框架实现交通异常的视听融合理解。在AV-TAU数据集上的实验表明,EchoTraffic刷新了TAU任务的当前最优(SOTA)性能,优于现有多模态大型语言模型。本文的贡献(包括AV-TAU数据集和EchoTraffic模型)为多模态交通异常理解开辟了新方向。
1. 引言
交通异常理解(TAU)正受到越来越多的关注,这源于检测、分析和响应交通事故等异常情况的实际需求。在大型语言模型的支持下,TAU的目标不仅是识别相关实体,还包括理解异常背后的原因并及时做出响应。获取这些信息对于通知应急服务、挽救生命、减少损失、提升公共安全和改善交通效率至关重要[58, 68]。

目前,现有方法[10, 19, 44, 46, 47, 49, 54]主要聚焦于检测交通场景中的异常,往往忽视了其背后的原因。借助大型语言模型,近期的方法[8, 50, 67]已能超越单纯的检测,实现对一般异常事件的上下文理解。然而,这些方法仍局限于视觉输入,忽略了音频这一易于获取且对TAU至关重要的模态。在现实场景中,交通异常通常伴随音频线索,例如碰撞声、刹车声或鸣笛声,这些线索往往发生在摄像头视野之外(如图1(a)所示)。缺少音频数据,很难全面捕捉和解读异常事件,从而限制了有效识别和分析异常的能力(如图1(b)所示)。
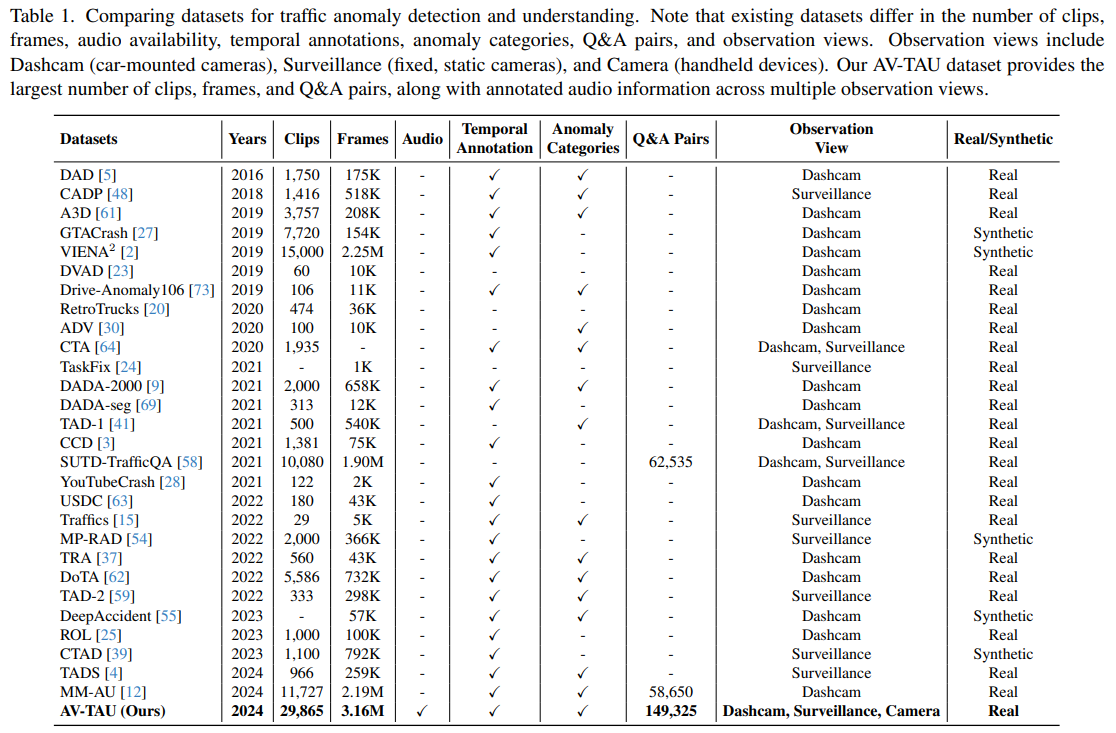
此外,详细的文本标注对于交通异常的准确推理和合理响应至关重要。但如表1所示,现有TAU数据集大多缺乏音频信息和全面的文本标注。重要的是,“如何在深度模型中有效利用和融合音频与视觉信号以实现交通异常理解”仍是一个未解决的挑战。
在本文中,我们首先提出AV-TAU,首个专为视听交通异常理解构建的数据集。AV-TAU包含29,865段真实世界的交通异常视频,附带视听洞察,并以149,325个问答对的形式提供全面标注,支持五项关键TAU任务(如图1©所示):(i)通过多模态数据识别和描述异常;(ii)解释异常的根本原因;(iii)定位异常的时间窗口;(iv)推荐有效的预防策略;(v)提供合适的响应方案。据我们所知,AV-TAU是目前最大的TAU数据集,也是首个整合音频数据的数据集。
其次,我们开发了EchoTraffic,一种专为交通异常理解和解读设计的多模态大型语言模型。EchoTraffic包含多项核心创新:基于音频线索识别关键帧的音频洞察帧选择器、捕捉关键特征的专用视觉和音频编码器,以及自适应融合这些特征以形成均衡表示的视听动态连接器。融合后的多模态输出将由大型语言模型解码器处理,使EchoTraffic能够生成检测到的异常的自然语言描述。
我们通过两阶段训练EchoTraffic:首先利用大规模InternVid-10M数据集[56]对齐视觉、听觉和语言模态;然后在我们的AV-TAU数据集上进行指令微调,以增强模型在不同交通场景中理解异常的适应性和准确性。与其他基线模型相比,EchoTraffic在传统指标和GPT[1]评估指标上均持续取得当前最优(SOTA)性能,突显其在交通异常理解方面的卓越能力。此外,实验结果还证实了融合视听信息的有效性,其性能显著优于单纯依赖视觉模态的方法。以下是本文的贡献总结:
- 构建了首个大规模视听交通异常数据集AV-TAU,包含29,865段视频和149,325个问答对,支持通过视觉和听觉线索进行交通异常理解。
- 开发了多模态大型语言模型EchoTraffic,融合视听洞察以实现不同交通场景下的高级交通异常理解。
- 实验结果表明,EchoTraffic在交通异常理解任务中刷新了SOTA性能,为多模态TAU开辟了新方向。我们的数据集和代码已公开在https://github.com/HarryHsing/EchoTraffic。
2. 相关工作
2.1 交通异常数据集
传统交通异常数据集主要通过识别相关时间帧来检测和定位事故。来自车载摄像头的行车记录仪数据集(如DAD[5]、A3D[61]和CCD[3])会捕捉与事故相关的帧,其中CCD数据集还对事故原因进行了分类。在A3D的基础上,DoTA[62]提供了详细的类别标签并支持无监督检测;DADA2000[9]用于评估事故场景下驾驶员的注意力;ROL[25]则助力早期风险检测。ADV[30]和TRA[37]仅提供视频级别的标签,未包含具体事故细节。
监控数据集虽不常见,但能通过固定摄像头提供更广阔的视野,例如CADP[48]、TAD-2[59]和TADS[4]。混合数据集[41, 58, 64]结合了行车记录仪和监控视频以进行异常分析。合成数据集[2, 27, 39, 54, 55]可补充真实数据,但在弥合与真实场景的差距方面仍面临挑战[11, 12]。总体而言,现有数据集缺乏详细的文本标注,而这类标注对于TAU中的因果推理至关重要。
多模态大型语言模型的兴起催生了新的通用视频异常数据集[8, 50, 67],这些数据集富含文本描述,但针对交通领域的专用数据集仍然有限。部分交通预测数据集[22, 26, 29, 42]虽包含文本标注,但主要聚焦于“近乎事故”的场景,而非实际事故。SUTD-TrafficQA[58]是首个面向TAU的大规模数据集,通过问答形式提供事故推理和预防见解;MM-AU[12]则进一步通过文本标注推动TAU研究。
本文提出的数据集通过整合音频与视觉数据以获取更丰富的洞察,从而推动交通异常研究。作为目前规模最大的数据集,它包含数量最多的视频样本、问答对和独特的响应标注,填补了检测与实际响应策略之间的空白。表1对交通异常数据集进行了详细对比。
2.2 交通异常理解方法
TAU旨在利用视频数据检测交通场景中的意外事件并分析其原因。然而,以往的方法[10, 19, 44, 46, 47, 49, 54]主要聚焦于检测,往往忽视对异常的描述和因果分析。近年来,研究人员开发了多模态大型语言模型(MLLM)以增强异常理解能力[8, 34, 40, 50, 60, 65, 67, 72]。例如,Zanella等人[65]提出LAVAD,这是一种基于语言的无训练方法,利用大型语言模型解读场景描述;Zhang等人[67]提出Holmes-VAD,通过LoRA[21]对多模态大型语言模型进行微调以提升检测性能;Tang等人[50]开发HAWK,整合运动数据以改进多模态大型语言模型对视频异常的理解能力。
然而,这些现有方法均忽略了音频——对于理解许多仅能通过听觉线索检测的异常而言,音频至关重要[14]。为此,本文提出EchoTraffic,通过整合视觉和听觉数据以增强对视频中交通异常的理解。
3. AV-TAU数据集
本文构建了AV-TAU,首个专为提升交通异常理解(TAU)而设计的大规模视听数据集。AV-TAU共包含29,865段交通异常视频和149,325个针对性问答对。据我们所知,AV-TAU是目前规模最大的TAU数据集,其独特之处在于整合了音频与视觉数据,为多模态TAU设立了新基准。
3.1 任务定义
为全面应对TAU任务,本文定义了五项关键子任务,用于识别、分析和响应交通异常。各子任务详细说明如下:
(i)What——多模态理解:评估模型解读视觉和音频信息的能力,目标是准确描述异常、识别涉及的物体、分析环境,并检测碰撞声、鸣笛声等声音。该任务用于衡量模型对交通异常的多模态综合感知能力。
(ii)Why——因果推理:要求模型分析并推断交通异常的原因,检验模型整合视听信息对异常根源进行有效因果推理的能力。
(iii)When——异常时序定位:需模型识别交通视频中异常的起始和结束时间点,考验模型的细粒度检测能力和时间感知能力。
(iv)How——预防策略:促使模型为检测到的异常提出预防策略,挑战模型通过推理和预测分析给出实用安全措施的能力。
(v)How——事件响应:评估模型为检测到的异常制定合理响应方案的能力,要求模型通过高级推理为特定交通事件提出适宜的行动和干预措施。
3.2 数据集构建与统计信息
为打造高质量的TAU研究资源,本文采用严格的多阶段数据集构建流程,并安排65名经过培训的标注人员参与,确保每个阶段的覆盖全面性、标注准确性和验证有效性。
数据收集与筛选
我们通过多个在线平台(YouTube、哔哩哔哩、Twitter、腾讯视频等),利用针对性文本查询获取各类交通异常视频(关键词详见图2(a))。随后,标注人员对初始收集的视频进行人工筛选,仅保留能清晰呈现交通异常且包含相关音频的视频,最终形成聚焦性强、信息丰富的数据集。
标注质量控制
每段视频均经过精细剪辑,以完整呈现异常的起因和结果。标注人员需针对五项关键任务(见图1©)撰写文本答案,形成问答对。此外,为确保标注一致性,我们采用交叉验证流程:每组标签由三名标注人员独立审核,若存在分歧,则由作者团队协商解决。
数据集统计信息
AV-TAU包含29,865段视频,共316万帧,总时长31.17小时,平均每段视频含108.5帧。该数据集涵盖五大异常类别,进一步细分为20个子类别(图2(a))。视频长度(图2(b))和异常时间窗口(图2©)的分布具有多样性,为研发稳健的多模态交通异常分析方法提供了丰富基础。
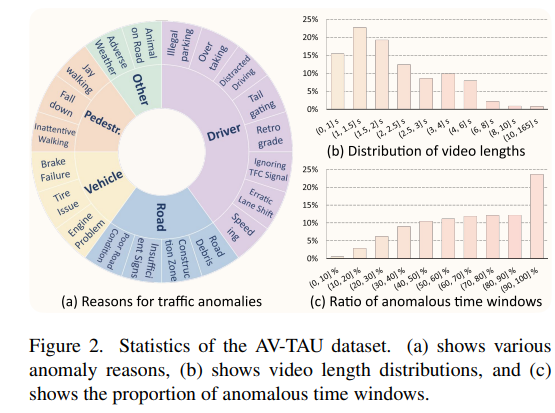
图2. AV-TAU数据集统计信息。(a)展示了各类异常原因,(b)展示了视频长度分布,©展示了异常时间窗口的占比。
4. 方法
现有视频理解模型[35, 66]通常采用均匀帧采样策略,却忽略了一个关键事实:异常场景仅出现在部分关键帧中。通常,这些关键时刻不仅在视觉上具有辨识度,在听觉上也伴随明显的音频信号。为推进交通视频异常理解,本文提出EchoTraffic——一种融合音频线索以增强异常理解能力的新方法。
4.1 音频洞察帧选择器
本文设计音频洞察帧选择器,通过采用谱通量(spectral flux)[7, 53]技术识别交通视频中的异常时刻,以实现TAU任务。谱通量通过对比连续帧来衡量音频信号功率谱的变化,可捕捉突发的信号变化。这些音频变化往往与刹车、碰撞或警报等关键交通事件同步。通过聚焦这类基于音频的线索,本文方法能准确筛选相关视频帧,确保捕捉到关键异常。如图3所示,这种音频与视觉线索的协同,为检测交通事件提供了更高效、更可靠的途径。

图3. 本文提出的音频洞察帧选择器(绿点)采用谱通量捕捉关键交通事件,能有效突出均匀选择器(红点)遗漏的关键帧。
谱通量计算
给定交通异常视频VVV,首先提取其音频时间序列AAA,采样率设为α\alphaα kHz(经实验验证,α\alphaα取CD标准采样率44.1)。随后,采用短时傅里叶变换(STFT)并结合汉明窗ω(m)\omega(m)ω(m),计算音频信号的幅度谱图。若用A^(n,k)\hat{A}(n, k)A^(n,k)表示音频时间序列AAA中第nnn个时间点、第kkk个频率 bin 的幅度值,则STFT的计算式为:
A^(n,k)=∑m=−S2S2−1A(hn+m)w(m)e−2jπmkS,(1)\hat{A}(n, k)=\sum_{m=-\frac{S}{2}}^{\frac{S}{2}-1} A(h n+m) w(m) e^{-\frac{2 j \pi m k}{S}}, (1) A^(n,k)=m=−2S∑2S−1A(hn+m)w(m)e−S2jπmk,(1)
其中,窗口大小SSS设为2048,步长hhh设为512。
谱通量(SF(n)SF(n)SF(n))用于衡量每个频率 bin 的幅度值随时间的变化。通过聚焦正向变化并对所有频率 bin 的变化求和,谱通量的计算式为:
SF(n)=∑k=−S2S2−1H(∣A^(n,k)∣−∣A^(n−1,k)∣),(2)SF(n)=\sum_{k=-\frac{S}{2}}^{\frac{S}{2}-1} H(|\hat{A}(n, k)|-|\hat{A}(n-1, k)|), \quad(2) SF(n)=k=−2S∑2S−1H(∣A^(n,k)∣−∣A^(n−1,k)∣),(2)
其中,H(x)=x+∣x∣2H(x)=\frac{x+|x|}{2}H(x)=2x+∣x∣为半波整流函数,确保仅正向变化参与求和。
帧选择
为捕捉整个音频时长内的关键事件,将谱通量序列划分为TTT个等长时间段。在每个时段内,定位谱通量值最大的点——该点代表最显著的谱变化,即:
ni∗=argmaxn∈[nistart ,niend ]SF(n),(3)n_{i}^{*}=\underset{n \in\left[n_{i}^{\text {start }}, n_{i}^{\text {end }}\right]}{\arg \max } SF(n), (3) ni∗=n∈[nistart ,niend ]argmaxSF(n),(3)
其中,i=1,2,...,Ti=1,2, ..., Ti=1,2,...,T,ni∗n_{i}^{*}ni∗表示第iii个时段内的显著谱变化点。这些ni∗n_{i}^{*}ni∗对应交通场景中的潜在关键时刻,可推断出关键音频异常。对于每个ni∗n_{i}^{*}ni∗,提取对应的视频帧,从而识别原始交通异常视频中的关键帧。最终筛选出的帧集合表示为V={Vt}t=1T∈RT×H×W×3V=\{V^{t}\}_{t=1}^{T} \in \mathbb{R}^{T \times H \times W \times 3}V={Vt}t=1T∈RT×H×W×3,其中HHH和WWW分别表示每帧的高度和宽度。
需注意的是,本文提出的帧选择器并非仅聚焦于音频信号显著的帧。它先将视频均匀分段,再基于音频线索选择最可能包含异常的帧——这一设计确保即使是音频信号微弱或无音频信号的时段,也能为帧选择提供相关信息。
4.2 模型架构
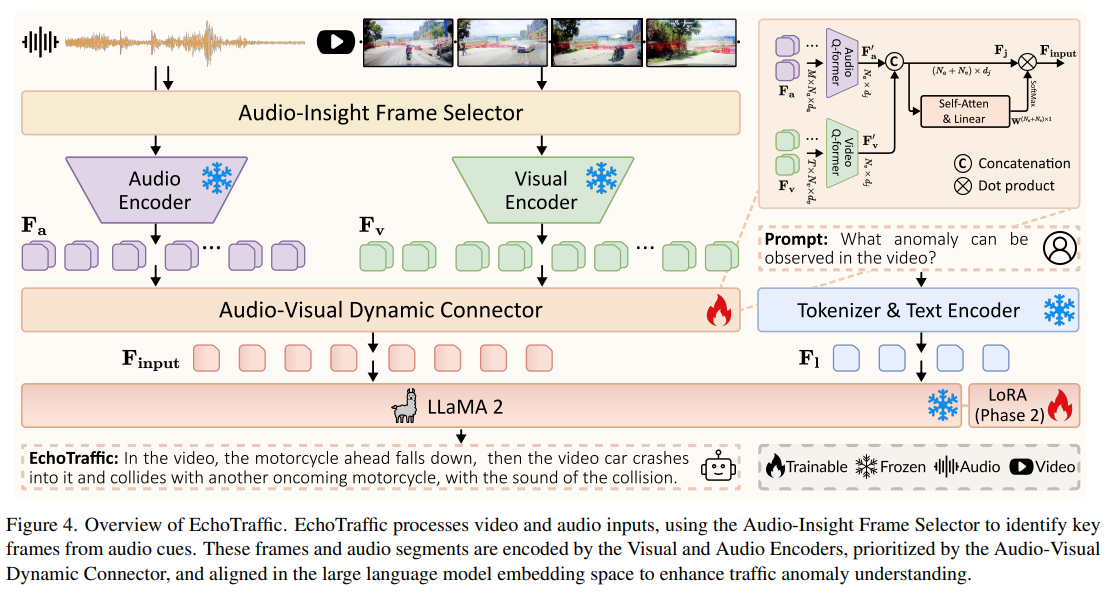
本节详细介绍EchoTraffic的架构,阐述视频与音频数据如何融合以实现交通异常理解。如图4所示,视觉编码器与音频编码器首先分别处理各自模态的数据;随后,视听动态连接器融合这两路数据流,并将其与大型语言模型(LLM)的嵌入空间对齐;最后,LLM解码器生成已检测到的交通异常的文本描述。
图4. EchoTraffic整体架构。EchoTraffic处理视频和音频输入,通过音频洞察帧选择器基于音频线索识别关键帧;这些帧与音频片段分别由视觉编码器和音频编码器编码,经视听动态连接器进行优先级排序后,在大型语言模型的嵌入空间中对齐,从而提升交通异常理解能力。
视觉编码器
采用EVA-CLIP[13]中的ViT-g/14模型作为视觉编码器——该模型在视频理解领域[31, 45, 66]应用广泛。将筛选出的关键帧输入视觉编码器后,通过预训练的图像级Qformer[31]处理 latent 特征,每帧生成NvN_vNv个 tokens。视觉信息表示为Fv={Fvt}t=1T∈RT×Nv×dvF_v=\{F_v^t\}_{t=1}^T \in \mathbb{R}^{T \times N_v \times d_v}Fv={Fvt}t=1T∈RT×Nv×dv,其中dvd_vdv为视觉特征维度。为增强时间结构信息,在FvF_vFv的TTT维度上添加可学习的位置嵌入。
音频编码器
对于从视频中提取的音频时间序列AAA,将其划分为MMM个片段,每个片段时长为2秒。受[17]启发,将这些片段转换为包含128个梅尔频谱 bin 的谱图;随后借鉴[16, 18]的思路,将谱图视为二维信号(类似图像),并采用ViT模型对其进行编码。编码后,音频信息表示为Fa={Fam}m=1M∈RM×Na×daF_a=\{F_a^m\}_{m=1}^M \in \mathbb{R}^{M \times N_a \times d_a}Fa={Fam}m=1M∈RM×Na×da,其中NaN_aNa为每个音频片段的 token 数量,dad_ada为听觉特征维度。为捕捉时间信息,在FaF_aFa的MMM维度上添加可学习的位置嵌入。
视听动态连接器
该模块包含三个核心子组件:视频Qformer、音频Qformer和自注意力机制。视频Qformer与音频Qformer分别处理视觉 tokens FvF_vFv和音频 tokens FaF_aFa,生成固定长度的 token 集合(视频为NvN_vNv,音频为NaN_aNa),并将这些 tokens 投影到LLM的嵌入空间中。
将视频与音频 tokens 拼接,形成Fj∈R(Nv+Na)×dlF_j \in \mathbb{R}^{(N_v+N_a) \times d_l}Fj∈R(Nv+Na)×dl(其中dld_ldl为LLM的隐藏层维度)。考虑到不同视频/音频 tokens 的重要性存在差异,设计自注意力模块为每个 token 分配重要性权重:该模块包含多个自注意力层和一个线性层,以FjF_jFj为输入,生成权重W∈R(Nv+Na)×1W \in \mathbb{R}^{(N_v+N_a) \times 1}W∈R(Nv+Na)×1。最终输入到LLM的特征计算为Finput=Fj×WF_{input}=F_j \times WFinput=Fj×W,通过学习到的权重实现对关键 tokens 的优先级排序。
LLM解码器
采用[52]中的模型作为LLM解码器的骨干网络——该模型在多领域均表现出优异性能。当输入语言指令时,LLaMA2的分词器将其转换为语言特征,表示为Fl∈RNl×dlF_l \in \mathbb{R}^{N_l \times d_l}Fl∈RNl×dl(其中NlN_lNl为语言指令中的 token 数量)。将语言特征与视听输入特征FinputF_{input}Finput拼接,形成LLM的完整输入,最终生成文本形式的异常响应结果。
4.3 训练策略
阶段1:基于InternVid-10M的多模态对齐
首先在大规模InternVid-10M[56]数据集上训练模型——该数据集包含1000万段视频-音频样本,用于生成视频描述。如此庞大的数据集规模对有效对齐视觉、听觉与语言模态至关重要,为更复杂的视频推理任务奠定坚实基础。
为聚焦模态对齐目标,冻结视觉编码器、音频编码器和LLM解码器的参数,仅训练视听动态连接器。此外,采用ImageBind[16]的预训练权重初始化音频编码器,以提升其视听融合能力。
本阶段训练配置:在完整的InternVid-10M数据集上训练1个epoch,批大小(batch size)设为128,采用AdamW优化器;学习率采用余弦衰减调度,初始阶段进行预热,初始学习率为1e-4;训练硬件为8块NVIDIA GTX A6000 GPU,总训练时长约240小时。
阶段2:基于AV-TAU的交通异常理解指令微调
第二阶段训练以交通异常检测为目标,采用本文构建的AV-TAU数据集。输入包含视频、音频和相关问题,输出为用于理解和响应交通异常的答案。
本阶段训练视听动态连接器和基于LoRA[21]的LLM,保持视觉编码器与音频编码器参数冻结——通过指令微调提升模型识别和解读异常的准确性。
本阶段训练配置:在AV-TAU数据集上训练1个epoch,批大小设为16,采用AdamW优化器;学习率采用余弦衰减调度,初始阶段进行预热,初始学习率为2e-5;LoRA参数设置为r=64r=64r=64和α=128\alpha=128α=128;训练硬件为8块NVIDIA GTX A6000 GPU,总训练时长约3小时。
5. 实验结果
本文在AV-TAU数据集上进行实验,采用90%/10%的训练-测试划分:测试集包含3000段视频和15000个问答对,为评估EchoTraffic在交通异常理解(TAU)任务中的性能(与可比模型对比)提供了可靠基础。
5.1 实验设置
评估指标
为评估模型对交通异常的理解性能,采用五项文本级指标:BLEU[43]、ROUGE[36]、MoverScore[71]、BERTScore[70]和GPT-Eval。前三项为传统文本评估方法,基于Ngram[43]匹配;对于GPT-Eval,参考[38, 50]中的方法,向GPT-4o[1]输入问题和参考答案,由其对模型输出进行评估——该评估聚焦三个核心维度:合理性、细节完整性和一致性。
基线模型
目前尚无专门针对TAU任务设计的方法,因此本文将EchoTraffic与两个相关领域的当前最优模型进行对比:(i)通用视频理解模型,包括Video-LLaVA[35]、LLaMA-VID[33]、TimeChat[45]、VideoChat2[32]、InternVideo2[57]和VideoLLaMA2[6];(ii)通用视频异常理解模型,以AGuardian[8]和Holmes-VAD[67]为代表。通过这一对比,可评估这些基线模型在解读和理解交通场景视频异常方面的能力。
5.2 定量比较
表2显示,EchoTraffic在所有评估指标上均表现出卓越性能,突显其在交通异常理解方面的先进能力。核心发现如下:(i)在描述(Description)、原因推理(Causation)、预防策略(Prevention)和响应方案(Response)四项子任务中,EchoTraffic在文本级指标BLEU、ROUGE、MoverScore、BERTScore和GPT-Eval上均持续取得最高分数,确立了其优势地位;(ii)VideoLLaMA2和Holmes-VAD表现出一定竞争力——VideoLLaMA2得益于整合的音频信号,Holmes-VAD则凭借在异常视频上的大量训练。此外,本文还在EchoTraffic的实验设置下对Video-LLaMA2进行了微调并评估其性能,相关结果及与Gemini 2.0[51]的额外对比详见补充材料。
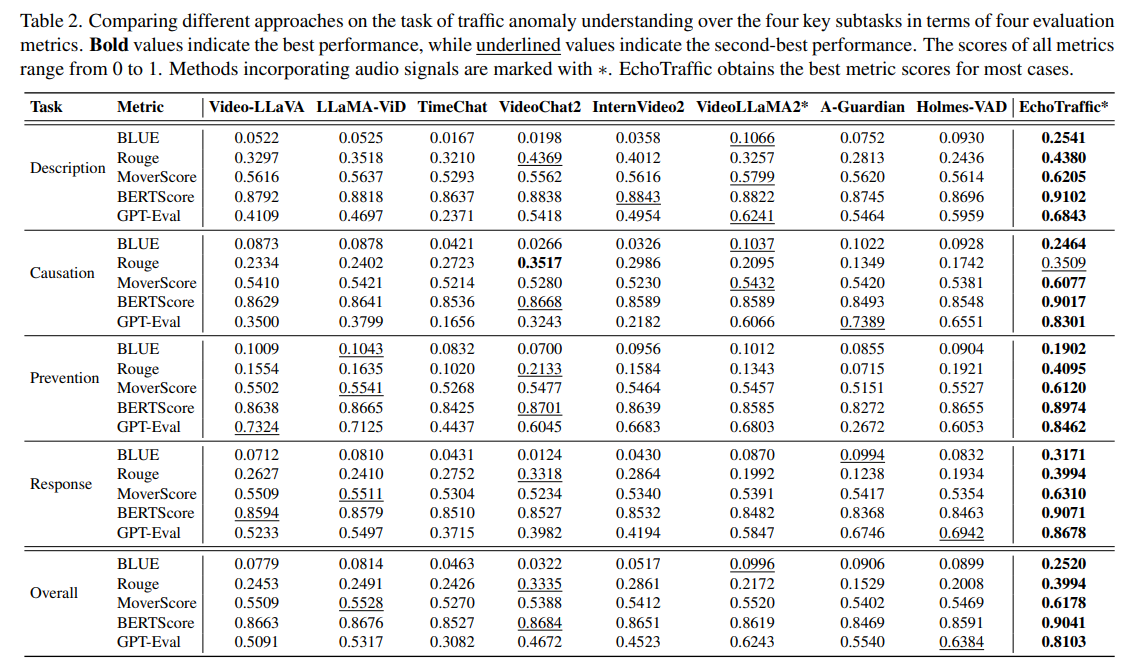
表2. 不同方法在交通异常理解任务的四项关键子任务上的性能对比(基于四项评估指标)。加粗值表示最优性能,下划线值表示次优性能。所有指标得分范围为0-1。含音频信号的方法标注为∗。EchoTraffic在多数情况下取得最优指标得分。
5.3 定性比较
为深入分析EchoTraffic的性能,本文将其与VideoLLaMA2和Holmes-VAD进行定性对比。图5展示了一个具有挑战性的场景:由于碰撞发生在盲区且未引发摄像头抖动,视觉线索有限,难以检测到碰撞事件。尽管如此,EchoTraffic仍能精准检测、解读并聚焦交通异常。例如,在图5(a)中,VideoLLaMA2和Holmes-VAD仅依靠视觉线索无法识别异常,进而产生幻觉输出;而EchoTraffic通过音频线索准确推断出主车与前方白色车辆发生碰撞。在图5(b)和(d)中,事件发生后,VideoLLaMA2和Holmes-VAD未能提供正确的响应建议或准确的因果解读;在图5©中,Holmes-VAD仅部分提出预防策略,VideoLLaMA2则聚焦于无关信息。这些观察结果证实,EchoTraffic能够有效利用视听洞察,精准感知并分析复杂的交通异常。

表4. EchoTraffic框架的定性评估。红色标注语义不一致,绿色标注与真值高度对齐,[黄色]标注文本问题。

图5. TAU任务的定性对比。红色标注关键语义不一致,绿色标注与真值高度对齐,[黄色]标注文本问题。更多示例详见补充材料。
5.4 消融实验
为评估EchoTraffic中各组件的作用及音频信息的重要性,本文通过逐一移除关键组件开展消融实验,结果如表3所示。若移除音频信息,模型对音频相关异常的描述能力会受损,导致描述不完整,进而影响整体性能(见表4中“无音频信息(w/o Audio Information)”的示例);缺少音频洞察帧选择器会降低模型对视觉信息的描述准确性(见表4中“无音频洞察帧选择器(w/o Audio-Insight Frame Selector)”的示例),这突显了关键帧选择的作用;若移除视听动态连接器,模型难以学习视觉与听觉信息的相对重要性,可能遗漏视频中的某些异常(见表4中“无视听动态连接器(w/o Audio-Visual Dynamic Connector)”的示例)。
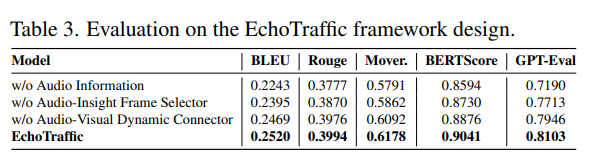
表3. EchoTraffic框架设计的评估结果。
6. 结论
本文提出了 EchoTraffic—— 一种用于交通异常理解(TAU)的视听融合模型。该模型通过整合视觉 - only 方法常忽略的关键音频线索,提升了交通事件的检测与分析能力。EchoTraffic 在 AV-TAU 数据集上进行指令微调,而 AV-TAU 是首个专为视听交通异常理解设计的大规模数据集;同时,EchoTraffic 借助音频洞察帧选择器和视听动态连接器,实现了对交通异常的精细化分析。评估结果表明,该模型在理解复杂交通事件和提升城市交通安全性方面具有显著效果。此外,本文还指出,长视频理解是未来 TAU 研究中的关键挑战。
思考:
1.这篇论文的任务除了时间区间,还需要得到场景描述、原因、如何预防、如何应对。任务更倾向于异常检测的可解释性。
2. 提出音频洞察帧选择器,通过比较相邻帧的音频功率谱的变化,来捕捉异常帧。
但是,如果出现音画不同步的问题,比如在车祸前的刹车声或者尖叫声,会不会导致帧的错误选择,从而识别出错?
在我之前的论文中,我认为音频中可能存在很多无关的噪声,所以我将视觉和语义的相似度作为音频的先验引导,并且关注包含高相似度帧的窗口,而不局限于单帧,来缓解音画不同步的问题。
3.提出的数据集的分布上看,视频基本都在6秒以内,并且异常事件都占据整个视频的大部分时间。但是在实际场景中,异常事件属于小概率事件,在短视频中训练会不会导致模型倾向于将正常事件识别成异常事件。