【软考架构】案例分析-云侧AI与端侧AI
来源2025年5月第4题
随着人工智能技术的发展,AI计算能力的部署方式呈现多样化趋势,主要包括云侧AI与端侧AI两种模式。两种部署模式各具优势,适用于不同的应用场景。
问题一
分值(6分)
请简要说明这两种AI的基本定义,并结合实际应用场景,说明端侧AI相较于云端AI的三项优势。
参考解析
云端AI是指将人工智能模型部署在远程云服务器上,借助强大的算力和海量数据资源完成模型的训练和推理,适用于对计算能力要求高、需集中管理和大规模数据分析的场景,如金融风控、搜索引擎和智能客服等。而端侧AI则是将模型部署在本地终端设备(如手机、摄像头、无人机等)上运行,强调对实时响应、数据隐私和网络独立性的支持。
相较于云端AI,端侧AI在以下三个方面具有显著优势:
一是低延迟,响应更快,因为数据无需上传云端处理,模型在本地即可推理,适用于自动驾驶、智能安防等需要毫秒级响应的场景;
二是数据本地处理,隐私性更强,用户敏感信息(如语音、图像)不经云端传输,有效降低隐私泄露风险,如智能手机中的本地语音识别与人脸解锁功能;
三是离线可用,网络依赖小,即使在无网或弱网环境下也能正常运行,广泛应用于边远地区的农业无人机、巡检机器人等任务中。
下面我将简要说明云侧AI与端侧AI的定义,并重点分析端侧AI的三项核心优势。
一、基本定义
-
云侧AI
- 定义:也称为云计算AI,指的是将数据(如图片、语音、文本)通过网络传输到远程的云计算中心,利用云端强大的计算资源和大型算法模型进行处理与分析,最后将结果返回给终端设备。
- 核心:数据处理在云端完成。终端设备主要扮演“输入”和“输出”的角色。
-
端侧AI
- 定义:也称为边缘AI或设备端AI,指的是将AI算法和模型直接部署在终端设备上(如手机、摄像头、智能音箱、汽车),无需联网即可在本地实时完成数据处理和决策。
- 核心:数据处理在设备本地完成。
二、端侧AI的三项优势(结合实际场景)
端侧AI的优势源于其“本地处理”的特性,主要体现在以下三个方面:
1. 低延迟与高实时性
- 优势:由于数据在设备端本地处理,无需经历“数据上传 -> 云端计算 -> 结果返回”的网络传输过程,响应速度极快,可达毫秒级。
- 应用场景:
- 自动驾驶:车辆摄像头需要实时识别行人、车辆和交通标志。如果每次识别都需上传云端,网络延迟可能导致车祸。端侧AI能瞬间做出避障决策。
- 工业质检:在生产线上,机械臂通过端侧AI视觉系统实时检测产品瑕疵,并能立即将次品剔除。云端AI的延迟无法满足这种高速流水线的节奏。
2. 数据隐私与安全性更高
- 优势:敏感数据(如人脸、语音、健康数据)无需离开用户设备,直接在本地被处理和分析,从根本上避免了数据在传输和云端存储过程中被泄露或窃取的风险。
- 应用场景:
- 手机人脸解锁:你的面部特征数据始终存储在手机本地的安全芯片中,永远不会被发送到苹果或谷歌的服务器。这极大地保护了生物识别信息的安全。
- 智能家居隐私:家庭安防摄像头通过端侧AI识别出家人和陌生人,只有陌生人的入侵行为才会触发报警并上传视频片段到云端,而家人的日常活动视频则保留在本地,保护了家庭隐私。
3. 网络依赖低、节省带宽与成本
- 优势:设备可以在离线环境下正常工作,同时避免了向云端传输大量原始数据(如连续的视频流),极大地节省了网络带宽和云端存储与计算的成本。
- 应用场景:
- 农业无人机巡检:在偏远的农田,网络信号可能很差。搭载端侧AI的无人机可以离线实时识别病虫害区域并生成报告,无需持续传输高清视频。
- 智能手机的语音助手:很多简单的语音指令(如“设置闹钟”)现在都可以在手机端离线处理,无需每次唤醒云端,响应更快且更省流量。
总结而言,端侧AI凭借其低延迟、高隐私和低网络依赖的特性,在需要即时响应、保障数据安全及在恶劣网络环境下运行的应用场景中,提供了云端AI无法替代的价值。 未来,“云边协同” 将是主流模式,云端负责复杂的模型训练和全局分析,端侧负责实时推理和本地决策,二者优势互补。
问题三
请根据下列指标对比三种资源池架构,前3空填写“高”“中”或“低”,后3空填写相应资源池的典型适用场景。
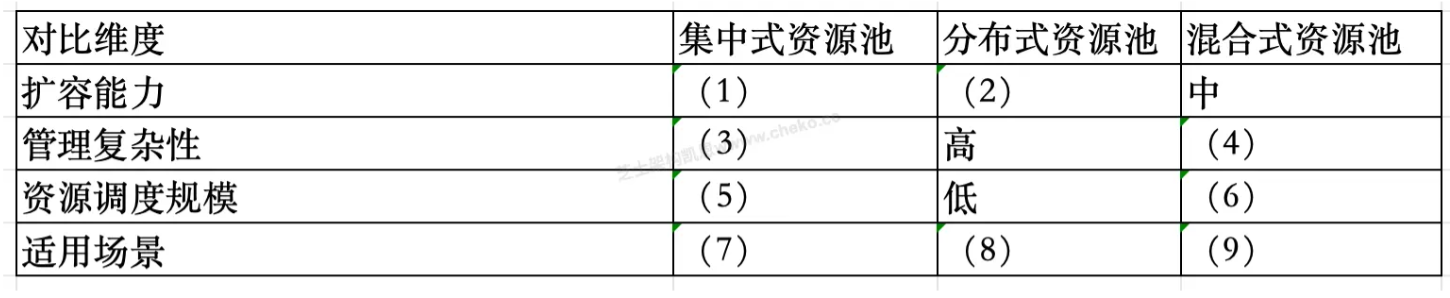
李工在当前项目中基于系统资源实时调度需求高,且系统规模相对固定,决定采用集中式资源池架构。但王工指出该方案存在以下三个潜在缺陷。请结合集中式资源池架构特点,指出这三项可能的缺陷。
参考解析
(1)低(2)高(3)低(4)中(5)高(6)中
(7)集中式资源池适用于系统规模中等、部署集中、资源调度实时性要求高、运维集中化、安全性要求高的场景
(8)分布式资源池适用于多业务、多地域部署或边缘计算等资源分散场景
(9)混合式资源池则适用于需同时支持云端与本地、具备弹性扩展需求的复杂业务系统。
集中式资源池的缺陷主要包括:扩展能力弱,难以灵活应对业务增长;存在单点故障风险,影响系统稳定性;不适用于用户分布广泛的场景,难以满足边缘计算对低延迟的需求。
三种主流资源池架构模式对比
| 模式维度 | 集中式资源池 | 分布式资源池 | 混合式资源池 |
|---|---|---|---|
| 核心架构 | 将所有计算、存储、网络资源集中在一个或少数几个大型数据中心。 | 将资源分散到多个地理位置、规模较小的节点,通常统一管理。 | 结合集中式与分布式,核心资源集中,边缘资源分散。 |
| 性能特点 | 优点:资源利用率高,易于实现资源复用和调度优化。 缺点:网络延迟高(用户距中心远),易成单点瓶颈。 | 优点:低延迟(资源近用户),横向扩展性强,避免单点瓶颈。 缺点:整体资源利用率较低,跨节点数据同步复杂。 | 优点:兼顾低延迟与资源高效利用,灵活性极高。 缺点:架构复杂,管理和运维成本最高。 |
| 部署策略 | 在核心枢纽建设1~2个超大规模数据中心,所有服务集中部署。 | 在用户密集区域(如各省市)部署多个小型资源节点,形成统一资源网络。 | 集中式资源池作为云中心处理核心业务与数据;分布式节点作为边缘节点处理实时业务。 |
| 适用范围 | 1. 对网络延迟不敏感的业务。 2. 需全局强一致性数据的业务。 3. 企业核心IT系统、大数据分析、批量处理。 | 1. 对延迟极其敏感的业务。 2. 内容分发与流媒体服务。 3. 物联网数据采集与实时处理。 | 1. 同时具有低延迟和高算力需求的复杂业务。 2. 需满足数据合规性要求的业务。 3. 从传统架构向云原生演进的过渡阶段。 |
| 典型场景 | - 银行的核心交易系统 - 企业的ERP和财务系统 - AI模型训练平台 | - CDN网络 - 智慧城市路口监控 - 在线视频会议、云游戏 | - 自动驾驶(端侧实时感知、云侧全局路径规划) - 工业互联网(工厂边缘节点实时控制、集团云端分析决策) |
总结与选择
- 集中式资源池 是规模化和成本效率的典范,适用于业务集中、数据处理量大的场景。
- 分布式资源池 是低延迟和业务连续性的保障,适用于用户分散、要求快速响应的场景。
- 混合式资源池 是灵活性与平衡的终极方案,通过“云端协同”来满足现代应用对算力、延迟、成本和安全的综合需求,是目前最主流的演进方向。
指出集中式资源池架构三项可能的缺陷。
基于集中式资源池架构的特点,其三项主要缺陷如下:
1. 单点故障与可用性风险
- 缺陷描述:所有计算、存储和网络资源高度集中于少数几个大型数据中心。一旦某个核心数据中心因自然灾害、电力中断、网络光缆被挖断或重大运维事故而宕机,将导致大范围、甚至全局性的服务中断。
- 架构根源:其“集中”的本质决定了故障影响范围难以隔离。尽管可通过建设同城或异地灾备中心来缓解,但这会显著增加成本和架构复杂性,且主备切换过程本身存在风险和数据丢失可能。
2. 网络延迟与带宽瓶颈
- 缺陷描述:终端用户或边缘设备与集中式资源池之间的物理距离可能非常遥远,数据在网络中传输的延迟较高。这对于需要实时交互的应用(如在线游戏、工业控制、远程手术)是致命的。同时,所有数据都需汇入中心,极易使核心网络链路成为带宽瓶颈,成本高昂。
- 架构根源:计算能力与用户分离。所有请求和数据处理都必须经过长途网络传输到中心节点,无法在数据产生地就近处理,违背了“数据不动计算动”的边缘计算理念。
3. 可扩展性限制与成本问题
- 缺陷描述:
- 纵向扩展瓶颈:集中式架构的扩展主要依赖于向上扩展,即给现有数据中心添加更强大的服务器和存储。这种方式终将遇到物理极限(如机房空间、供电、散热)和经济上限,线性扩展能力差。
- “规模不经济”:当单个数据中心规模过大时,其管理复杂度呈指数级上升,运维团队、电力冷却成本可能超过其规模效益的增益,导致边际效益递减。
- 架构根源:依赖于在固定地点构建超大规模单体资源池,而非采用更灵活、可线性扩展的分布式单元化架构。
总结:集中式资源池架构在可靠性、延迟性能和弹性扩展方面存在固有缺陷。这些缺陷使其难以独立满足现代应用对高可用、低延迟和无限弹性的需求,这也是分布式和混合式资源池架构日益重要的根本原因。
如何解释线性扩展?
这个问题很关键,能帮你理清架构扩展的核心逻辑!线性扩展(Linear Scaling/Scalability)指的是 系统的处理能力(如吞吐量、并发量)与投入的资源(如服务器数量、CPU核心数)成“正比关系”增长,简单说就是“资源翻倍,性能也近似翻倍”。
核心特点
- 增长趋势呈“直线型”:比如1台服务器能处理1000 QPS(每秒查询数),线性扩展下,2台服务器就能处理约2000 QPS,4台就能处理约4000 QPS,无明显性能损耗。
- 扩展成本可控:无需重构核心架构,仅通过增加同质资源(如新增相同配置的服务器)就能提升性能,扩展过程简单直接。
示例说明
- 正面案例:分布式资源池中的无状态服务(如Spring Boot接口服务),新增服务器节点后,通过负载均衡分发请求,性能随节点数近似线性增长,这就是典型的线性扩展。
- 反面案例:集中式数据库(如单节点MySQL),即使增加服务器,核心数据仍存储在单一节点,查询、写入性能无法随资源增加而正比提升,属于“非线性扩展”。
关键前提(实现线性扩展的核心条件)
- 服务无状态:业务逻辑不依赖本地存储(如会话、缓存),任何节点都能处理请求,便于水平扩容。
- 资源可拆分:数据、任务能均匀分配到新增资源中(如分布式缓存Redis Cluster拆分数据分片,分布式任务框架拆分计算任务)。
- 无单点瓶颈:不存在“新增资源也无法突破”的核心瓶颈(如单一数据库、单调度中心)。
与“非线性扩展”的对比
- 非线性扩展:资源增加后,性能增长低于资源增长比例(甚至不增长)。比如单节点Redis,内存从8GB扩容到16GB,QPS可能仅从10万提升到12万(未翻倍),因受限于单节点的CPU、网络带宽瓶颈。
要不要我帮你整理一份实现线性扩展的架构设计要点清单?