【具身智能】ChatVLA 系列:让 VLA 同时具备「多模态理解对话」与「动作执行」能力
本文介绍了 ChatVLA 系列的两篇工作:
- ChatVLA:发表在 EMNLP 2025 Oral,它目标是让 VLA 模型既能保留 VLM 的图像理解与对话能力,让具备控制机器人来执行动作的能力,解决了以往 VLA 微调导致的多模态理解能力严重下降的问题。
- ChatVLA-2:发表在 NeurIPS 2025,它认为一个可泛化的 VLA 模型应当保留并扩展 VLM 的核心能力:(1)开放世界具身推理:能够识别 VLM 所能识别的任何事物,具备解决数学问题的能力,并拥有视觉空间智能;(2)推理跟随:有效地将开放世界推理转化为机器人的可执行步骤。
下面分别对同一团队的两篇工作进行介绍。
更多论文每日解读关注 v 公众号:https://mp.weixin.qq.com/s/Rl3x2-mLohuvYz_JSqIIww
ChatVLA:基于 VLA 的统一多模态理解与机器人控制
关键词:#具身智能 #VLA
- 论文题目:ChatVLA: Unified Multimodal Understanding and Robot Control with Vision-Language-Action Model
- arXiv:2502.14420
- Accepted: EMNLP 2025 Main Oral
- 单位:Midea Group & 华东师范
- https://chatvla.github.io/

🧠 一句话总结:ChatVLA 是一个统一的视觉-语言-动作模型,它既能“看懂”图像并与人对话,也能控制机器人完成复杂任务,解决了现有模型“会看不会动”或“会动不会看”的问题。
研究背景与问题
当前:
- VLM:擅长图像理解、对话、问答,但不能控制机器人。
- VLA:擅长执行动作任务,但失去了对话和理解能力。
➡️ 问题:如何让一个模型既能理解图像和语言,又能控制机器人?
➡️ 挑战:
- 虚假遗忘(Spurious Forgetting):机器人训练会“洗掉”原本的视觉-语言对齐能力。
- 任务干扰(Task Interference):理解和控制任务的参数空间互相冲突,导致性能下降。
问题分析
为了理解现有 VLA 模型「多模态理解」在与「具身控制」方面的能力,我们研究了三种不同的训练范式,每种范式使用不同的数据集:(1)仅使用机器人数据训练,这也是 VLA 最普遍的做法;(2)在机器人数据基础上增加类似思维链的推理信息,旨在提供辅助信息以提升模型泛化能力及机器人任务表现;(3)同时使用视觉-文本数据和机器人数据进行协同训练,该范式首先由 RT-2 提出。
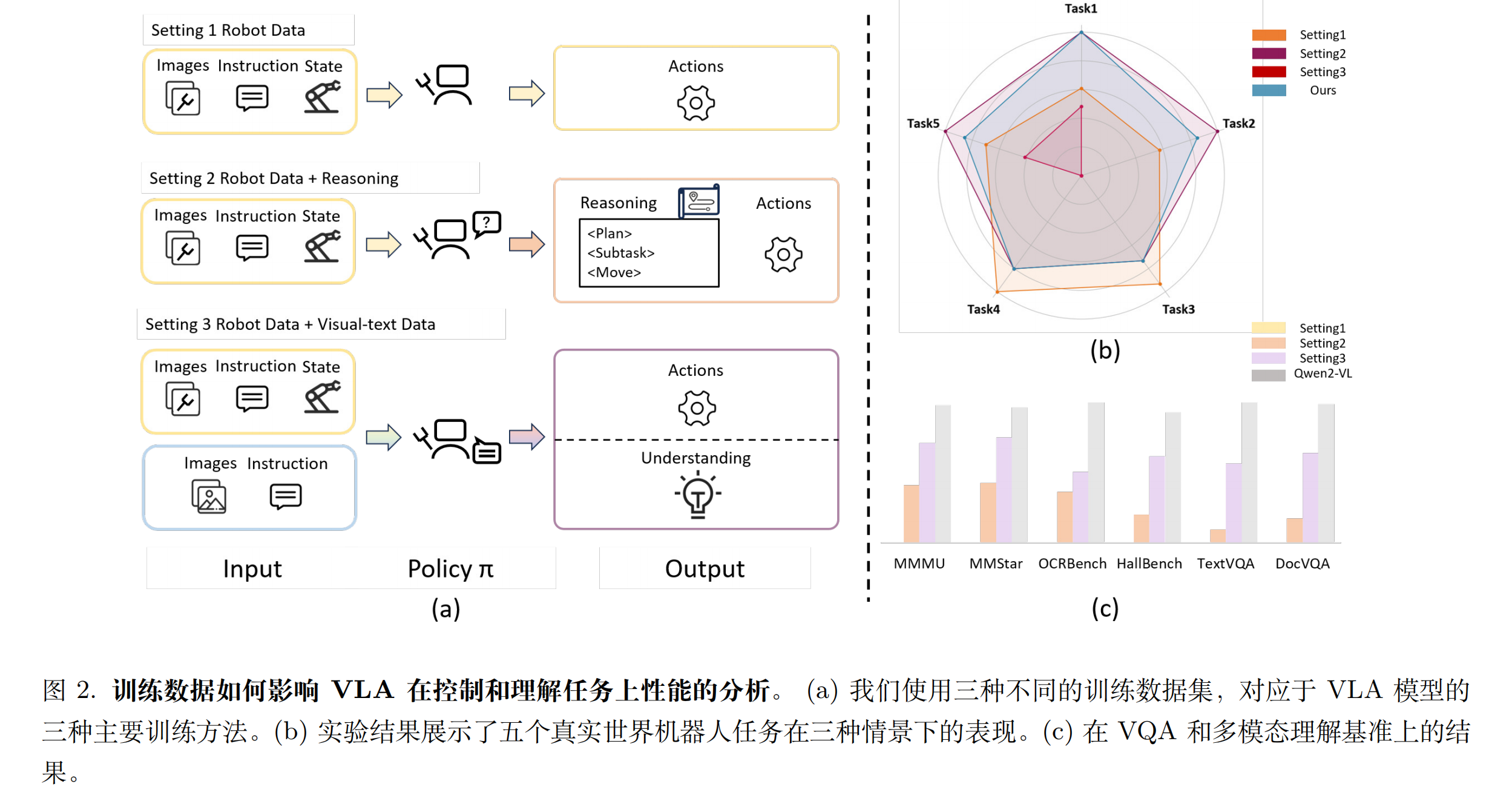
一些分析结论:
- 我们的观察表明,预训练的 VLM 组件似乎遭受了灾难性遗忘。仅使用机器人数据进行训练会导致模型丧失先前获得的对话和理解能力。比如仅在机器人数据训练的模型在所有基准测试中的性能均为 0。然而,我们的实验表明,这并不一定意味着知识的完全丢失,而更可能是由于机器人数据引起的错位。采用固定推理模板进行训练似乎能“重新激活”视觉-文本对齐,使模型能够参与对话并表现出理解能力。论文第 6 节中深入探讨被重新激活的具体知识,并讨论未来工作如何进一步弥合基础 VLM 与 VLA 模型之间的差距。我们将这一现象称为“虚假遗忘”。在真实机器人的表现上,仅使用机器人数据进行训练的性能反而低于引入推理的方法,这一结果证实了先前的研究发现:利用视觉或文本的思维链能够提升机器人模型的泛化能力。有趣的是,将机器人数据与视觉-文本数据进行协同训练,导致真实世界任务成功率显著下降。
- 将推理融入机器人数据可提升性能的初始观察结果与双重编码理论相一致。该理论认为,物理运动技能与视觉-语言理解并非相互排斥,而是相互关联,能够带来重叠的优势。然而,当在训练数据中加入视觉-文本对时,机器人控制性能显著下降。这表明,在共享参数空间中,动作生成与理解所需的独立表示可能存在竞争关系。我们称这种现象为部分任务干扰,需要谨慎解决。
方法:ChatVLA
前面的分析表明:
- 基于机器人策略数据的训练可能会干扰视觉-文本关系的学习。
- 仅使用机器人数据进行训练会削弱视觉-文本对齐,导致模型对话能力下降。
因此,解决这两个挑战对于在单一 VLA 模型中成功融合两种视角至关重要。
分阶段对齐训练:解决“虚假遗忘”
| 阶段 | 目标 | 数据 | 说明 |
|---|---|---|---|
| 第一阶段 | 学控制 | 机器人演示数据 | 先让模型学会“动手” |
| 第二阶段 | 学理解 | 机器人数据 + 图像-文本对 | 再恢复“看懂”和“说话”的能力 |
- 阶段 1:只用水机器人演示数据(含 “图像 + 指令 + 动作轨迹”,比如 “打开抽屉” 的步骤数据)训练,同时加入简单的 “推理文本”(比如 “先握把手,再拉抽屉”),避免模型过早丢失文本关联能力;
- 阶段 2:在阶段 1 基础上,加入少量视觉 - 文本数据(来自 LLaVA-1.5,含图像 + 问答 /caption),“重新激活” 预训练 VLMs 的图像 - 文本对齐能力,同时保留已学会的控制技能。
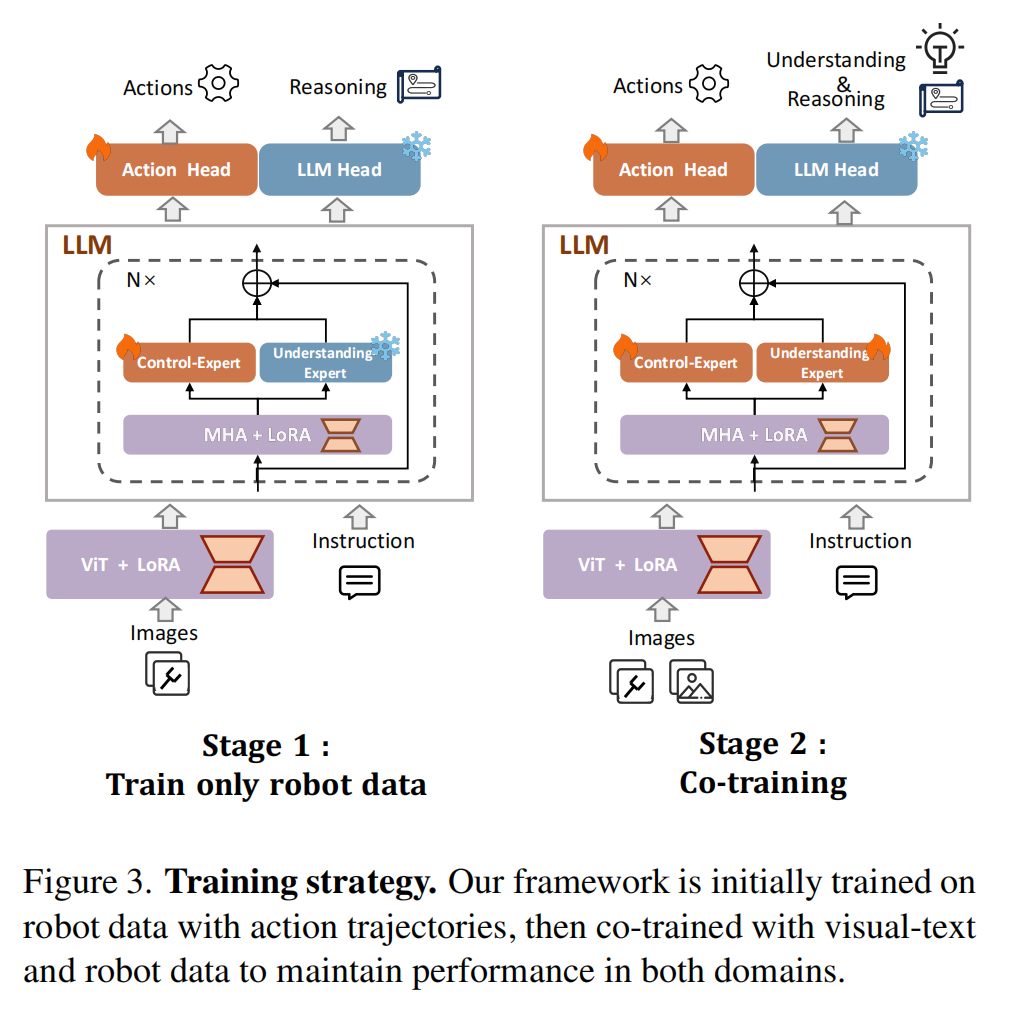
关键逻辑:机器人控制任务更复杂(需要精准动作),先练扎实;多模态理解只需 “少量数据唤醒”(预训练 VLMs 已具备基础能力,不用从头学)。
混合专家架构:解决“任务干扰”
架构上让 “控制” 和 “理解” 共享部分组件、独立部分组件,平衡 “知识迁移” 和 “干扰隔离”:
- 共享存件:注意力层(Self-Attention)。因为两个任务需要共享基础语义(比如 “识别抽屉位置” 既用于 “回答抽屉在哪”,也用于 “控制机器人开抽屉”),共享注意力能避免重复学习;
- 独立组件:MLP 层(专家模块)。设计两个“Expert”:
- 「Control Expert」:处理机器人动作预测(输入 “图像 + 指令”,输出 “关节角度”“抓握力度”);
- 「Understanding Expert」:处理多模态任务(输入 “图像 + 问题”,输出 “文字答案”)。
推理时用 “系统提示” 切换(比如 “Predict robot action” 激活控制专家,“Answer the question” 激活理解专家)。
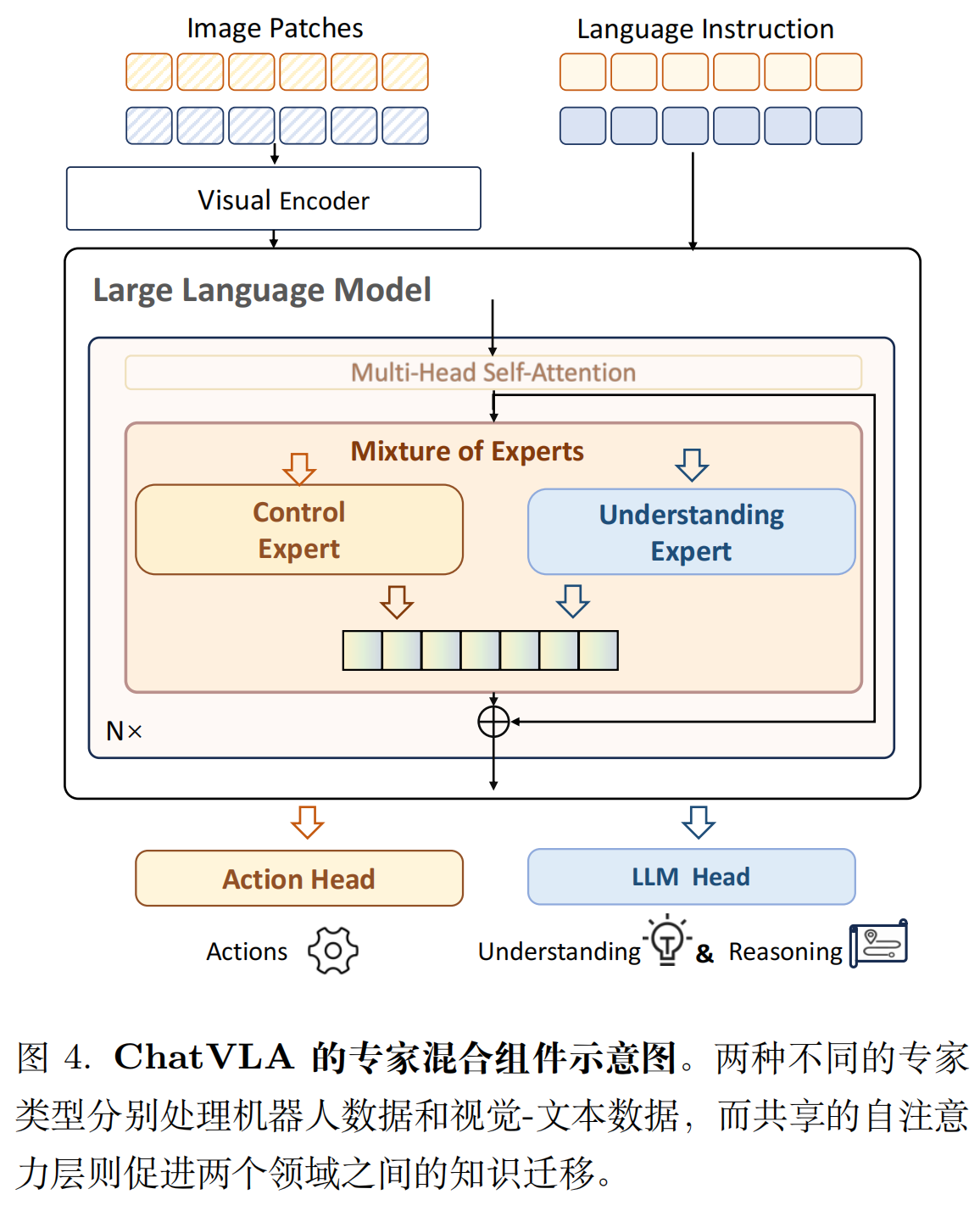
类比:就像一个人既会做饭(控制)又会讲解菜谱(理解)—— 共用 “认识食材” 的知识(共享注意力),但 “翻炒动作” 和 “语言表达” 用不同的技能模块(独立专家)。
实验
论文从多模态理解和机器人控制两大维度测试,对比了传统 VLA(OpenVLA、ECoT)和 VLMs(Qwen2-VL),结果非常显著。
多模态理解能力:碾压传统 VLA,接近专用 VLM
测试了 7 个 VQA 基准(如 TextVQA、DocVQA)和 6 个 MLLM 基准(如 MMMU、MMStar),核心结果:
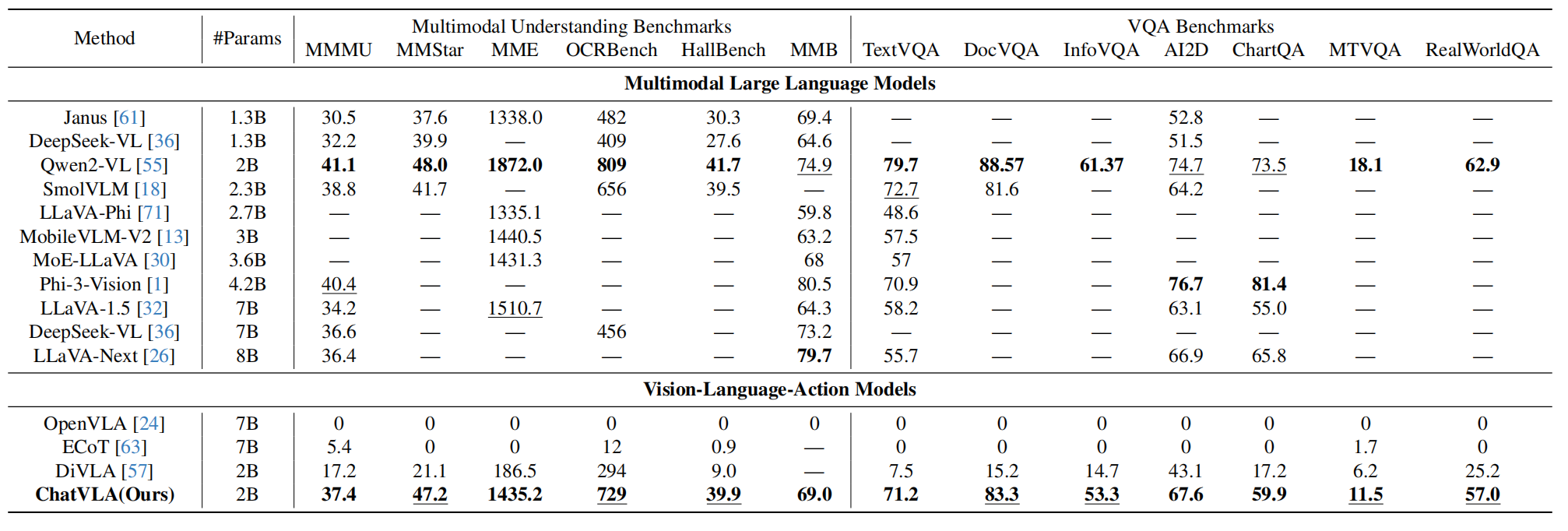
- 关键亮点:ChatVLA 用 2B 参数(比 ECoT 的 7B 少 3.5 倍),在 MMMU 上比 ECoT 高 6 倍,接近同参数 VLMs(Qwen2-VL)的水平,证明 “理解能力未因控制训练丢失”。
机器人控制能力:超越传统 VLA,覆盖 25 个真实任务
测试了 3 类真实机器人任务(共 25 个,涵盖浴室、厨房、桌面场景),核心结果如下:
(1)长周期任务(直接提示):比如 “把蜘蛛侠放进抽屉”
需要分 3 步:打开抽屉→放玩具→关抽屉。ChatVLA 的平均成功步数是 1.0(全程成功),而 OpenVLA 只有 0.15,Octo 只有 0.11(几乎做不完一步)。
(2)长周期任务(高级规划):比如 “准备早餐”
需要分 3 步:拿盘子→翻杯子→放面包。ChatVLA 平均成功步数 0.59,是 OpenVLA(0.10)的 5.9 倍,能处理 “多步骤切换”(比如从 “翻杯子” 到 “放面包” 不混乱)。
(3)跨技能多任务:覆盖抓、挂、推、叠等动作
在浴室(放肥皂、挂杯子)、厨房(拿面包、开冰箱)、桌面(叠方块、放网球)场景中,ChatVLA 的平均成功率是 51.4%(55/107 次成功),而 OpenVLA 只有 18.7%(20/107),Octo 只有 16.8%(18/107)。
消融实验
- 视觉 - 文本数据比例:测试 1:1、3:1、1:3(视觉文本:机器人数据),发现 1:3 效果最好 —— 少量视觉文本就够激活理解能力,多了反而干扰控制;
- MoE 架构必要性:去掉 MoE 后,MMMU 得分从 37.4 降到 22.1,机器人抓握成功率从 51.4% 降到 32.7%,证明 “独立专家模块” 能有效减少干扰。
结论
| 特点 | 说明 |
|---|---|
| 🧠 统一能力 | 看图、说话、控制机器人,三合一 |
| 🔄 抗遗忘 | 用两阶段训练避免“学了动作忘了说话” |
| 🧩 抗干扰 | 用混合专家结构避免任务冲突 |
| 📈 性能强 | 视觉问答和机器人控制都达到SOTA |
| ⚙️ 参数少 | 仅2B参数,比7B的模型效果更好 |
首次实现 “单模型统一多模态理解 + 机器人控制”,解决了传统 VLA 的 “遗忘” 和 “干扰” 问题。
ChatVLA-2:开放世界具身推理 VLA 模型
关键词:#具身智能 #VLA #具身推理
- 论文题目:ChatVLA-2: Vision-Language-Action Model with Open-World Embodied Reasoning from Pretrained Knowledge
- arXiv:2505.21906
- Accepted: NeurIPS 2025
- 单位:Midea Group & 华东师范
- https://chatvla-2.github.io/

论文速读
- 研究问题:这篇文章旨在解决 VLA 模型在机器人控制中如何保持和利用预训练 VLM 的核心能力的问题。具体来说,现有的端到端 VLA 系统在微调过程中往往会失去 VLM 的关键能力,如开放世界的具身推理和推理跟随能力。
- 研究方法:这篇论文提出了 ChatVLA-2,一种新型的混合专家 VLA 模型,结合了专门的两阶段训练流程,旨在保留 VLM 的原始优势并实现可操作的推理。
研究背景:VLA 的“遗忘”问题
现在的机器人学习越来越依赖 VLA,比如 OpenVLA、DexVLA、π0 等。这些模型通常用预训练的 VLM 作为“大脑”,然后再用机器人数据微调。但问题来了:微调后,模型往往“忘了”原来 VLM 的能力,比如数学推理、文字识别、空间理解等。比如,一个 VLA 模型可能连“10+11=?”这种简单题都不会答了,因为它没见过这个具体的算式。
作者提出了两个核心目标:
- 开放世界具身推理:VLA 应继承 VLM 的知识,即识别 VLM 能够识别的任何事物,具备解决数学问题的能力,并拥有视觉空间智能;
- 推理跟随:有效地将开放世界推理转化为机器人的可执行步骤。
为实现这个目标,论文提出两大核心原则:
- 解耦特征空间:多模态理解(VLM 的活)和机器人控制(动作的活)要分开,避免互相 “抢参数” 导致能力丢失;
- 动作跟随推理:机器人的动作必须严格匹配 VLM 的内部推理(比如 VLM 算出 “10+11=21”,机器人就要准确拿起 “21” 的卡片,而不是乱拿)。
ChatVLA-2 模型架构
模型架构包括两个创新点:
- 动作混合专家架构:采用动态混合专家(MoE)架构来处理不同任务中遇到的复杂多模态输入。
- 推理跟随增强模块:引入了一个增强的推理跟随模块,以确保模型在执行动作时能够紧密跟随生成的推理。
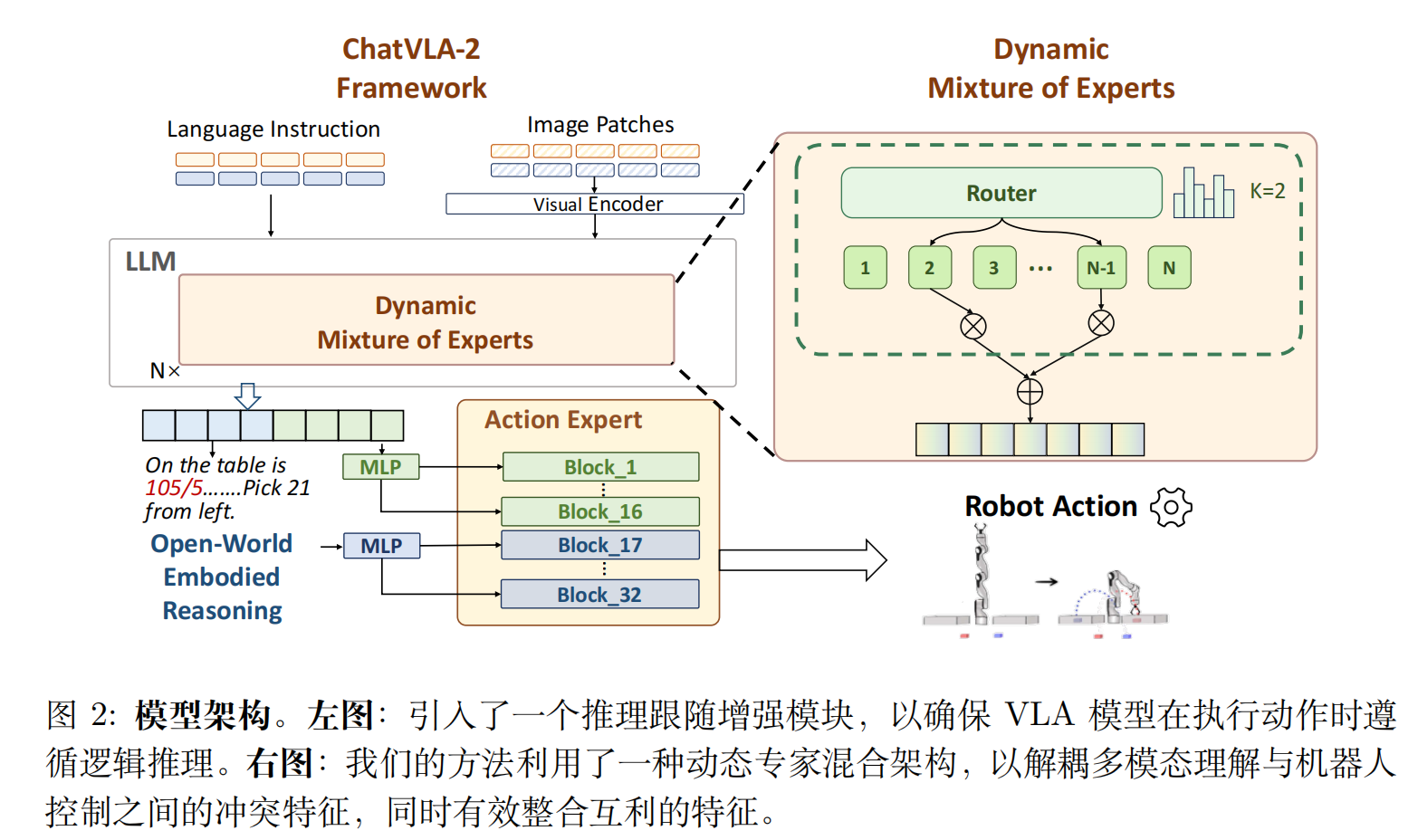
动态混合专家架构(Dynamic MoE)
解决 “多模态理解与机器人控制抢参数” 的问题。
- 把 VLM 的“理解能力”和“动作能力”分开处理,避免互相干扰。
- 用“专家网络”动态选择哪些模块参与当前任务。
- 比如:数学题 → 激活 OCR + 数学专家;抓杯子 → 激活空间 + 动作专家。
通过自适应路由策略,根据输入数据的特性动态选择专家模块。共使用八个专家模块,并在推理时动态选择两个专家。这种方法确保了计算资源的高效分配,减少了不必要的计算。
推理跟随增强模块(Reasoning-Following Enhancement)
解决 “动作不匹配推理” 的问题。
核心逻辑:原本的 VLA 模型用 “观测图像的嵌入” 指导动作,但 ChatVLA-2 替换为 “VLM 生成的推理 tokens”(比如 VLM 推理出 “需要拿起 21 号卡片放在白板右侧”,就用这个推理文本的嵌入指导动作)。
具体而言,我们将原始的观察嵌入替换为通过 MLP 投射的推理 token。随后,这一推理表示与当前时间步的嵌入相结合,用于生成缩放和移位参数,从而有效地将推理上下文注入模型。值得注意的是,我们仅在后半部分层中融入了这一机制,而非均匀地应用于所有层。这一设计选择与先前研究(如 PointVLA 和 GR00T N1)的发现一致,这些研究表明对动作专家深层进行修改对机器人控制的影响较小。我们的结果表明,这种选择性集成使得模型能够在开放世界推理场景中稳健处理,同时不牺牲领域内的准确率。
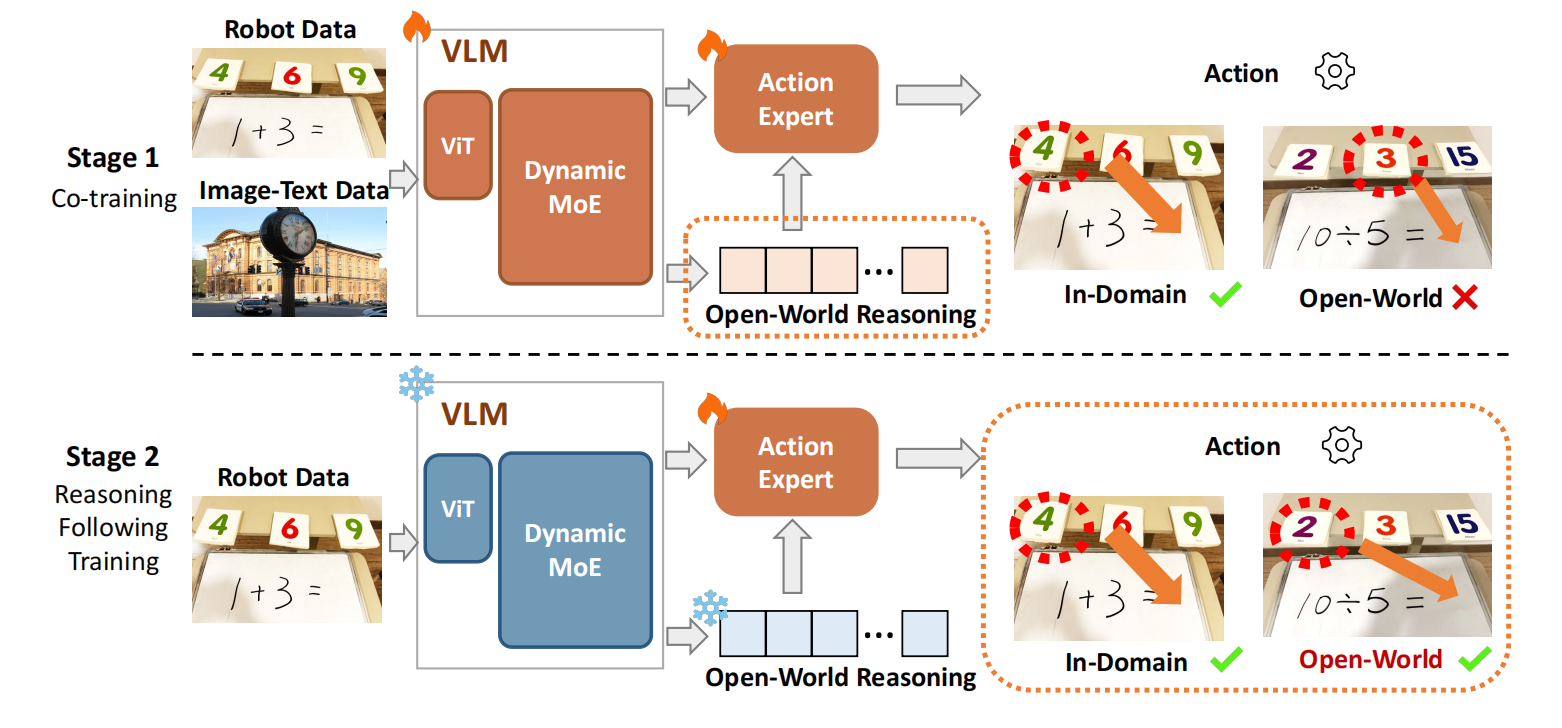
两阶段训练策略
| 阶段 | 目标 | 是否冻结 VLM |
|---|---|---|
| 阶段1 | 联合训练图像-文本 + 机器人数据,保留 VLM 能力 | 不冻结 |
| 阶段2 | 冻结 VLM,只训练动作专家,强化“按推理行动” | 冻结 |
第一阶段:联合训练,建立知识联系
- 数据:同时用 “图文数据”(COCO、TextVQA、GQA 等,共约 11 万样本,练 OCR、数学、空间推理)和 “机器人数据”(600 条数学任务轨迹 + 300 条玩具放置轨迹,练动作基础);
- 目标:保留 VLM 的预训练知识,同时让模型学会 “把图文理解和动作关联起来”(比如看到 “10+11”,先想到 “21”,再知道要找 “21” 的卡片);
- 细节:图文数据和机器人数据比例 1:3,避免动作训练覆盖 VLM 知识。
第二阶段:冻结 VLM,精调动作
- 操作:把 VLM 的所有参数 “冻结”(不准改,确保知识不丢),只训练 “动作专家”;
- 目标:让动作专家严格跟随 VLM 的推理结果(比如 VLM 算对 “21”,动作专家必须精准抓起 “21” 卡片,而不是抓错);
- 关键结果:如果跳过这一步,开放世界动作成功率会从 43/52 降到 12/52—— 证明 “只调动作” 才能让推理落地。
实验
论文没有用仿真 benchmark(因为现有仿真测不出开放世界能力),而是在真实机器人上做了两个核心任务,对比了 8 个基线模型(如 OpenVLA、DexVLA、π₀等)。

任务 1:数学匹配游戏(测数学推理 + OCR)
- 场景:机器人面前有白板(写着方程,如 “10+11=?”)和一堆数字卡片,需要先 “读对方程”(OCR)、“算对结果”(数学推理)、“拿起正确卡片放白板上”(动作);
- 关键变量:开放世界场景下,方程和数字的手写风格都是训练中没见过的;
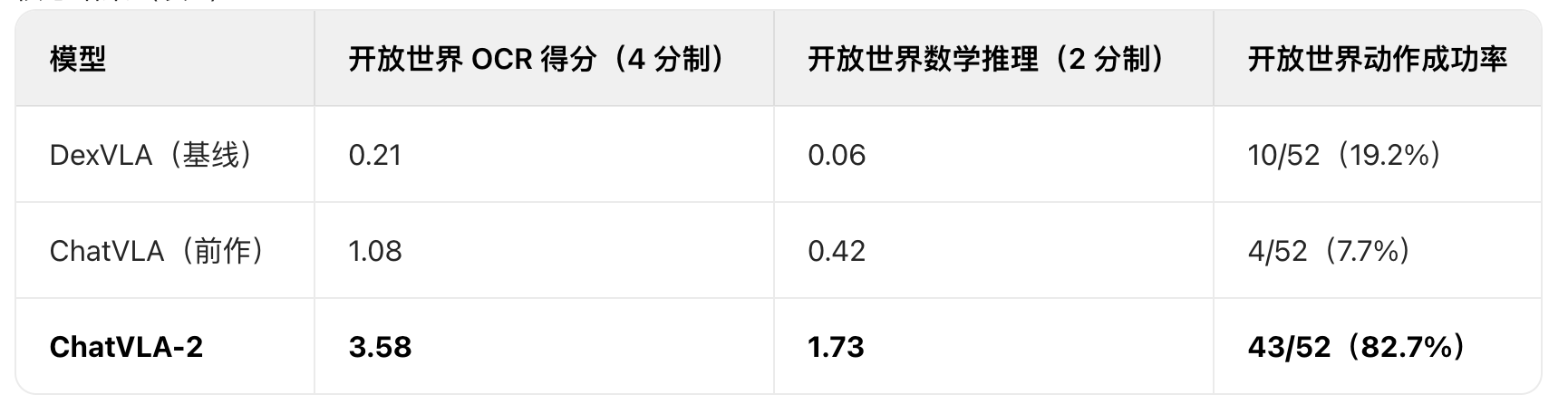
结论:只有 ChatVLA-2 能在 “没见过的方程” 上同时做好 OCR、算题和动作。
任务 2:玩具放置(测空间推理 + 陌生物体识别)
- 场景:让机器人 “把玩具 A 放在玩具 B 的右边 / 上面 / 后面”,其中玩具 A/B 是训练中没见过的(如没训过 “小熊” 和 “汽车”,却要执行 “把小熊放汽车后面”);
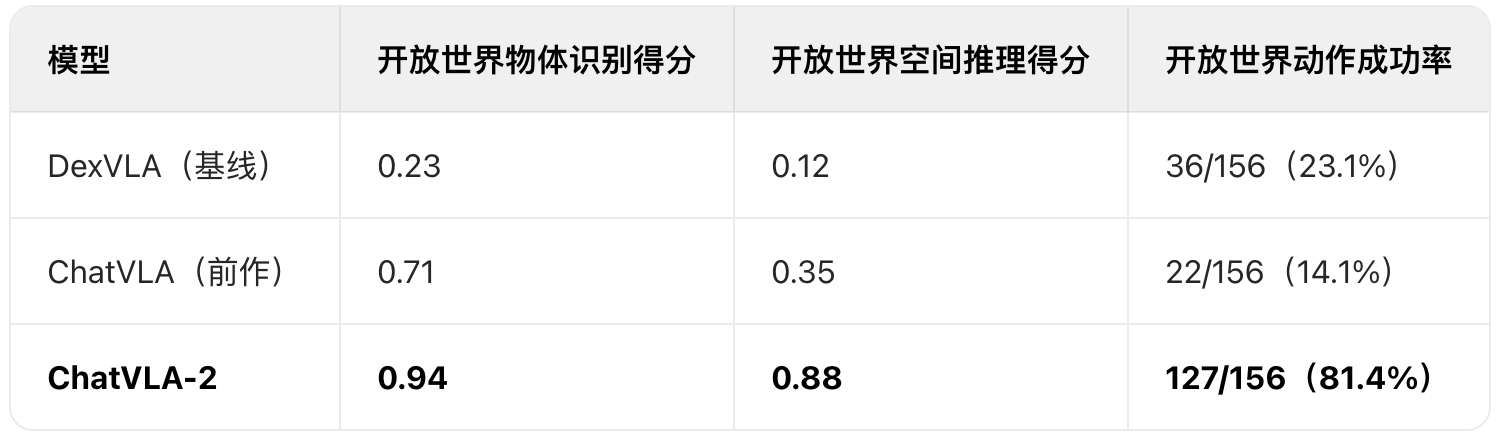
结论:ChatVLA-2 能识别陌生物体、理解陌生空间指令,动作成功率是基线的 3.5 倍。
消融实验
| 模块 | 移除后成功率下降 |
|---|---|
| 动态 MoE | 从 82.7% → 25% |
| 阶段2训练 | 从 82.7% → 23% |
| 推理注入位置(后半层) | 从 82.7% → 44% |
总结
核心结论:
ChatVLA-2 通过 “动态 MoE 解耦特征” 和 “两阶段训练保知识”,首次实现了 VLA 模型在开放世界场景下的 “推理 - 动作闭环”—— 机器人不用专门训练 “解数学题”“认新物体”,就能靠 VLM 的预训练知识应对新任务,这是对现有模仿学习模型(如 OpenVLA、DexVLA)的关键突破。
现有局限:
- 知识保留不彻底:微调时仍会丢失部分 VLM 能力(比如复杂的多步推理),这是未来要解决的核心难点;
- 任务场景有限:目前只做了 “桌面级任务”(抓卡片、放玩具),未来计划扩展到 “移动机器人”(如全屋导航、复杂家务)。