Learning Transferable Visual Models From Natural Language Supervision 学习笔记
CLIP(Contrastive Language-Image Pre-training)是 OpenAI 于 2021 年提出的跨模态预训练模型,核心目标是打破传统计算机视觉模型依赖 “固定类别标签” 的局限,通过自然语言监督学习可迁移的视觉表征,实现零样本(Zero-Shot)迁移到多种下游任务。以下从核心背景、方法设计、实验结果、局限性与影响等维度,全面拆解论文核心内容。
CLIP 的核心思想是:利用图像和文本的配对数据,训练一个模型来理解图像和文本之间的关联,从而学习到强大的视觉表示,并能够实现零样本(zero-shot)迁移到多种视觉任务中。
一、研究背景与动机
传统计算机视觉模型(如 ResNet、EfficientNet)存在两大关键局限:
- 监督信号单一:依赖人工标注的 “固定类别标签”(如 ImageNet 的 1000 类),无法泛化到未预定义的视觉概念,新增任务需重新标注数据。
- 泛化能力弱:模型易过拟合训练数据的分布(如 ImageNet 的图像风格),面对自然分布偏移(如手绘、低分辨率图像)时性能大幅下降。
而 NLP 领域通过 “文本预训练 + 零样本迁移”(如 GPT 系列)实现了任务无关的泛化能力。CLIP 的核心动机是:将 NLP 的 “文本监督泛化范式” 迁移到计算机视觉,利用互联网上海量的 “图像 - 文本对” 作为监督信号,学习同时理解视觉与语言的跨模态表征,无需任务特定训练即可适配新任务。
二、核心方法设计
CLIP 的方法围绕 “数据构建 - 预训练目标 - 模型架构 - 零样本迁移逻辑” 四部分展开,整体流程如图 1 所示:
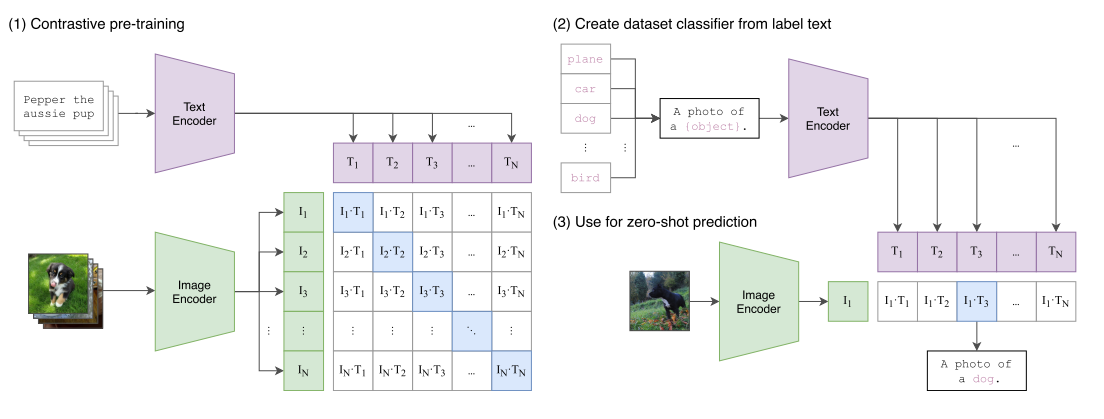
1. 构建大规模图像 - 文本数据集(WIT)
为解决现有数据集(如 MS-COCO、YFCC100M)规模小、文本质量低的问题,CLIP 构建了WebImageText(WIT)数据集:
- 来源:从互联网公开渠道收集,覆盖 50 万个查询词(基于 Wikipedia 高频词、短语、词条等),确保视觉概念的广度。
- 规模:包含 4 亿个 “图像 - 文本对”,文本涵盖标题、描述、标签等自然语言,总词量与 GPT-2 的训练数据(WebText)相当。
- 过滤:仅保留含英文自然语言描述的图像,剔除自动生成的无意义文本(如相机参数、文件名)。
2. 对比学习预训练目标(InfoNCE 变体)
CLIP 摒弃传统 “预测文本具体单词” 的生成式目标,采用更高效的对比学习目标,核心是 “判断图像与文本是否为匹配对”:
- 输入:一批(N 个)“图像 - 文本对”,构成 N×N 个可能的配对组合(N 个正样本:真实匹配对;N²-N 个负样本:虚假匹配对)。
- 目标:训练图像编码器与文本编码器,使正样本的余弦相似度最大化,负样本的余弦相似度最小化。
- 损失:对称交叉熵损失(同时从 “图像→文本” 和 “文本→图像” 两个方向计算损失,确保双向一致性)。
该目标的优势是:无需学习文本生成的细粒度细节,只需捕捉图像与文本的全局关联,训练效率提升显著(如图 2 所示,对比目标比生成式目标效率高 4 倍)。
翻译成人话:传统方法(比如让模型 “看图写句子”)就像让学生 “背完整课文”,难度高、效率低;CLIP 用 “对比学习”,相当于让学生 “判断两个句子是不是一对”,难度低、见效快。
3. 双编码器模型架构
有了原材料和学习目标,还需要 “工具” 来处理 “图” 和 “话”—— 就像工厂需要 “机器” 来加工原材料,CLIP 的 “双编码器” 就是它的 “核心机器”:一个处理图像,一个处理文本,最终把两者都变成 “数字串”(嵌入向量),这样才能计算相似度。
CLIP 包含图像编码器和文本编码器,两者独立训练但共享统一的嵌入空间:
| 模块 | 可选架构与优化 |
|---|---|
| 图像编码器 | - ResNet 系列:基于 ResNet-50/101,加入抗锯齿模糊池化、注意力池化(替换全局平均池化),按 EfficientNet 思路缩放宽度 / 深度 / 分辨率(如 RN50x4、RN50x16)。- Vision Transformer(ViT)系列:采用 ViT-B/32、ViT-B/16、ViT-L/14,对输入图像分块编码,部分模型额外在 336px 高分辨率下微调(如 ViT-L/14@336px,性能最优)。 |
| 文本编码器 | 基于 Transformer 的 12 层模型(63M 参数),采用 Byte Pair Encoding(BPE)分词(词汇量 49152),最大序列长度 76,以 [EOS] token 的输出作为文本表征,经线性投影到跨模态嵌入空间。 |
共享嵌入空间:让 “图” 和 “话” 能比较
两个编码器的输出会被 “投影” 到同一个 “数字空间”(比如都是 1024 维)—— 就像把 “中文” 和 “英文” 都翻译成 “ Esperanto(世界语)”,这样才能计算 “图的数字串” 和 “话的数字串” 的相似度(用余弦相似度)。
为什么需要双编码器?
如果没有专门的编码器,模型无法把 “图” 和 “话” 这两种完全不同的信息,转化成 “可比较的格式”—— 就像你没法直接比较 “一幅画” 和 “一句话”,但如果把画变成 “关键词标签”、把话也变成 “关键词标签”,就能比较它们的相似度了。
4. 零样本迁移逻辑
前面三步都是 “让模型学本事”,这一步是 “让模型用本事”—— 而且是 “不用额外训练,直接用”(零样本)。传统模型学完后,要解决新任务(比如 “分猫品种”),必须重新标注数据、训练新分类器;CLIP 则用 “自然语言定义任务”,直接生成分类器。
CLIP 的零样本能力核心是 “用自然语言生成分类器”,无需任何下游数据训练:
- 任务适配:对下游任务的每个类别,用自然语言模板构建描述(如 “A photo of a {label}.”,针对细粒度任务可优化模板,如 “A photo of a {label}, a type of pet.”)。
- 生成分类器:将类别描述输入文本编码器,得到每个类别的嵌入向量 —— 这些向量构成 “零样本线性分类器” 的权重。
- 预测:将图像输入图像编码器得到视觉嵌入,计算其与所有类别文本嵌入的余弦相似度,相似度最高的类别即为预测结果。
本质上,文本编码器扮演 “超网络” 角色,根据自然语言动态生成任务所需的分类器权重,实现任务无关的泛化。
三、关键实验结果
CLIP 在 30 + 计算机视觉任务上验证了零样本与表征学习能力,核心结果如下:
1. 零样本迁移性能
- ImageNet 突破:最优模型(ViT-L/14@336px)在 ImageNet 上零样本准确率达 76.2%,与全监督训练的 ResNet-50(76.1%)持平,且无需使用 ImageNet 的 128 万训练样本;Top-5 准确率达 95%,与 Inception-V4 相当。
- 跨任务泛化:在 27 个数据集上,零样本 CLIP 优于 “ResNet-50 特征 + 全监督逻辑回归” 的基线(16/27 任务),尤其在细粒度分类(Stanford Cars 准确率 + 28.9%、Food101+22.5%)、视频动作识别(Kinetics700+14.5%、UCF101+7.7%)、OCR(Rendered SST2 准确率 67.9%)等任务上表现突出。
- 数据效率:零样本 CLIP 的效果相当于 “4-shot 线性分类器”(如图 6),部分任务(如 Country211)等效于 184 个标注样本的监督学习(如图 7)。
2. 表征学习能力(线性探针评估)
线性探针(在预训练特征上训练线性分类器)是衡量表征质量的经典指标:
- 泛化性优势:在 Kornblith 等人的 12 数据集套件中,CLIP 的 ViT-L/14@336px 模型平均准确率超现有最优模型(Noisy Student EfficientNet-L2)2.6%;扩展到 27 个数据集(含地理定位、OCR、医学影像等)后,优势扩大到 5%,且所有 CLIP 模型的计算效率均优于其他架构(如图 10)。
- 任务覆盖广度:CLIP 的表征天然支持 OCR、地理定位(Country211 准确率 63.0%)、面部情感识别(FER2013 准确率 63.8%)等传统模型需特殊设计的任务,证明跨模态监督的泛化性。
3. 对分布偏移的鲁棒性
传统 ImageNet 模型在自然分布偏移(如手绘、低分辨率、真实场景)下性能骤降,而 CLIP 表现出显著优势:
- 如图 13 所示,零样本 CLIP 在 7 个分布偏移数据集(ImageNet-V2、ImageNet-Sketch、ObjectNet 等)上的平均准确率比 ResNet-101 高 51.2%,将 “鲁棒性差距” 缩小 75%。
- 例如,在 ImageNet-Sketch(手绘图像)上,CLIP 准确率 60.2%,而 ResNet-101 仅 25.2%;在 ObjectNet(真实场景杂乱物体)上,CLIP 准确率 72.3%,ResNet-101 仅 32.6%。
4. 与人类学习的对比
在 Oxford-IIIT Pets 数据集(37 类猫狗品种)上对比人类与 CLIP 的零样本 / 少样本学习:
- 人类零样本准确率 53.7%,1-shot 后提升至 75.7%(依赖样本修正认知);CLIP 零样本准确率 93.5%,但 1-shot 提升不明显。
- 差异表明:CLIP 的零样本优势源于海量数据预训练,而人类的少样本学习能力(“知其不知” 并快速修正)仍是当前算法的短板。
四、局限性与挑战
CLIP 虽实现突破,但仍存在显著局限:
- 任务能力不均衡:在抽象任务(如计数 CLEVRCounts、医学影像 PatchCamelyon)、细粒度分类(如飞机型号 FGVCAircraft、花种 Flowers102)上性能较弱,部分任务准确率接近随机。
- 数据效率差:虽无需下游数据,但预训练依赖 4 亿 “图像 - 文本对”,若按每秒 1 张图像的速度浏览,需 405 年遍历完 32 个训练 epoch 的所有数据,无法解决深度学习 “数据饥渴” 的根本问题。
- 极端分布偏移鲁棒性不足:对预训练中极少出现的场景(如手写数字 MNIST),零样本准确率仅 88.4%,甚至低于 “像素逻辑回归” 的简单基线。
- 社会偏见:在 FairFace 数据集上,零样本 CLIP 将黑人图像误分类为 “非人类”(如大猩猩)的概率达 14%(其他种族 < 8%),将男性图像误分类为 “犯罪相关” 的概率(16.5%)显著高于女性(9.8%),反映训练数据中的社会偏见被模型习得。
五、 broader impacts(广泛影响)
- 技术范式影响:CLIP 开创了 “视觉 - 语言跨模态预训练 + 零样本迁移” 的新范式,推动后续模型(如 ALBEF、FLAVA)的发展,使 “用自然语言定义视觉任务” 成为可能。
- 应用潜力与风险:
- 积极方向:低代码视觉任务开发(如自定义分类器)、图像检索、辅助残障人士(如实时图像描述)。
- 风险方向:易被用于监控场景(如零样本行人识别、行为分类),且偏见可能加剧社会不公(如种族 / 性别歧视的自动化决策)。
- 研究启示:强调 “零样本 / 少样本基准” 的重要性 —— 传统全监督基准可能高估模型泛化能力,而零样本评估更能反映模型的真实任务学习能力。
六、核心结论
CLIP 证明了 “自然语言监督 + 大规模对比预训练” 是学习通用视觉表征的高效路径 :
- 无需任务特定标注,即可零样本迁移到 30 + 视觉任务,部分性能媲美全监督模型;
- 跨模态表征具有更强的分布偏移鲁棒性,缓解传统模型 “过拟合训练分布” 的问题;
- 为 “通用计算机视觉” 提供了可行方向,但需解决数据效率、任务均衡性、社会偏见等关键挑战。