网络服务商能删除网站珠海网络网站建设
RAG for AI app的三个阶段
AI应用程序的RAG系统通常遵循三个核心阶段:
- Indexing索引:此阶段涉及预处理外部数据源,并将表示数据的嵌入存储在向量存储器中,以便可以轻松检索。
- Retrieval检索:此阶段涉及根据用户的查询检索存储在向量存储器中的相关嵌入和数据。
- Generation生成:这个阶段涉及将原始提示与检索到的相关文档合成为一个最终提示,发送给模型进行预测。
![![[Pasted image 20250911160251.png|537x315]]](https://i-blog.csdnimg.cn/direct/3b1b7b93d57b4d3cae96bcf7b98a5d95.png)
检索示意图:
![![[Pasted image 20250911160403.png|548x576]]](https://i-blog.csdnimg.cn/direct/7169977ede2a4981b6345b994f615e6a.png)
一旦我们根据用户的查询检索了相关文档,最后一步就是将它们添加到原始提示中作为上下文,然后调用模型生成最终输出:
![![[Pasted image 20250911160630.png]]](https://i-blog.csdnimg.cn/direct/63ab0a8063d54d1588114ed31ff157f2.png)
对应的代码:
from langchain_openai import ChatOpenAI
from langchain_core.prompts
import ChatPromptTemplate retriever = db.as_retriever() prompt = ChatPromptTemplate.from_template("""Answer the question based only on the following context: {context} Question: {question} """) llm = ChatOpenAI(model_name="gpt-3.5-turbo",temperature=0) chain = prompt | llm # fetch relevant documents
docs = retriever.get_relevant_documents("""Who are the key figures in the ancient greek history of philosophy?""") # run
chain.invoke({"context": docs,"question": """Who are the key figures in the ancient greek history of philosophy?"""})
策略总结
然而,多个用户使用的生产就绪的 AI 应用程序需要更高级的 RAG 系统。为了构建一个强大的 RAG 系统,我们需要有效地回答以下问题:
- 我们如何处理用户输入质量的变化?
- 我们如何将查询路由到从各种数据源检索相关数据?
- 我们如何将自然语言转换为目标数据源的查询语言?
- 我们如何优化我们的索引过程,即嵌入、文本分割?
策略总结如图所示:
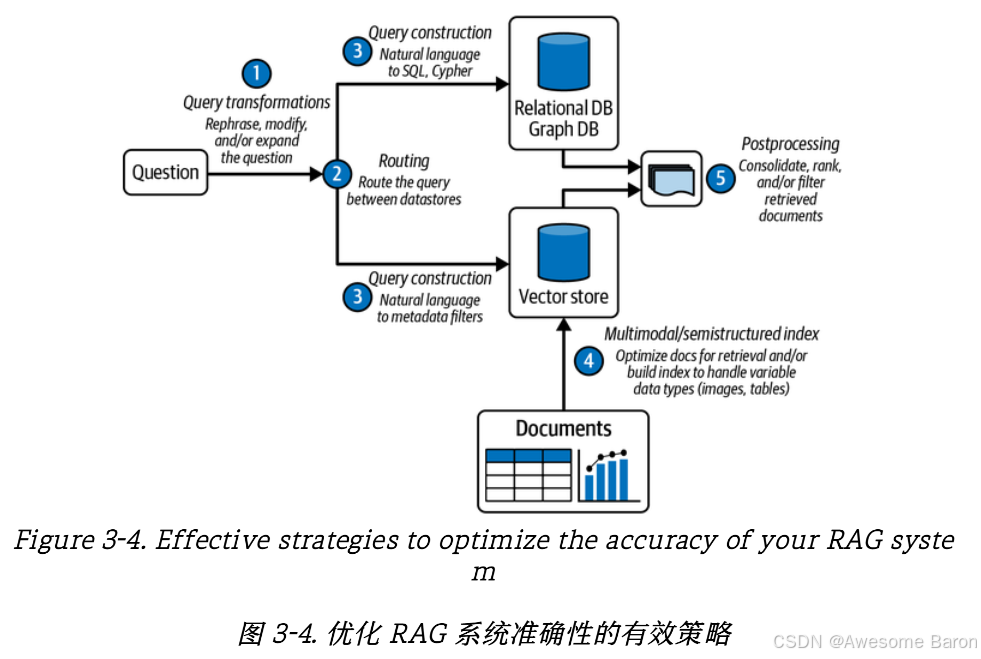
1. Query transformations(查询转换)
在用户提出问题后,第一步是对查询进行加工和优化。
-
目的:确保问题更容易匹配数据库或向量库中的内容。
-
方法:可以对问题进行重写、扩展或修改。例如:
-
同义词替换(“老师”→“教师”)
-
扩展问题(“柏拉图的思想”→“柏拉图在哲学、政治学方面的思想”)
-
改写问题使其更正式或更具体。
-
-
价值:提高检索相关性的同时减少用户模糊提问带来的歧义。
2. Routing(路由选择)
经过转换的问题可能要去不同的数据源中寻找答案。
-
机制:系统会判断问题更适合在哪个数据源里检索,比如:
-
问题涉及结构化数据 → 路由到关系型数据库或图数据库。
-
问题涉及非结构化文本 → 路由到向量数据库。
-
-
智能化:通常会通过分类器、规则或模型来自动决定路由。
-
价值:避免无效搜索,减少延迟,提升检索精准度。
3. Query construction(查询构建)
一旦路由确定,就要把自然语言问题转化为具体的检索指令。
-
针对关系/图数据库:转化为 SQL 或 Cypher 查询,直接操作结构化数据。
-
针对向量数据库:转化为检索条件(如基于向量相似度 + 元数据过滤)。
-
挑战:需要保证自然语言到数据库语法的映射准确,否则会导致“查询偏差”。
-
价值:让 LLM 能够有效利用不同类型的数据存储。
4. Multimodal/semistructured index(多模态/半结构化索引)
不仅仅是文本,文档可能包含图片、表格或其他格式。
-
操作:
-
先对文档进行优化预处理(如分段、清洗)。
-
构建向量索引,支持多模态(文字 + 图像 + 表格)。
-
-
目标:让系统能够处理和检索复杂的数据类型,而不仅仅是纯文本。
-
价值:扩展 RAG 的能力,使得它能回答涉及图表或图片内容的问题。
5. Postprocessing(后处理)
当从多个数据源拿到候选文档后,需要做结果整合。
-
操作:
-
合并:把来自不同数据库的内容组合在一起。
-
排序:根据相关性或置信度重新排名。
-
过滤:去掉冗余或噪声文档。
-
-
价值:提升检索结果的质量,减少无关信息传递给大模型,从而提高最终回答的准确性与简洁度。
总结:
这五个环节构成了一个完整的 RAG 优化闭环:
-
输入端(用户问题)要被智能转化与路由;
-
中间端(数据库查询与索引构建)要精准高效;
-
输出端(后处理)要干净有序。