mysql数据库的sql优化以及explain周期字段详解案例【爽文】
目录
一 慢sql优化
1.1 策略
1.1.1 对于in语句的优化
1.1.2 索引字段使用函数或计算,索引功能失效
1.1.3 为高频建立索引
1.1.4 批量操作:大幅减少IO次数
1.1.5 谨慎设置null值
1.2 案例
1.3 慢sql的开启
1.4 数据库:定期检查
二 explain执行周期分析
2.1 sql执行效率分析
2.2 执行周期字段分析
2.3 字段分析
2.3.1 Extra为NULL
2.3.2 Extra为using where
2.3.3 Extra为MRR
2.3.4 extra:using join buffer
2.3.5 extra:using temporay
2.3.6 extra:using filesort
2.3.7 extra:range checked for each record
2.4 案例讲解
2.5 设置索引后数据量大失效
一 慢sql优化
1.1 策略
1.1.1 对于in语句的优化
MySQL 的优化器在处理IN时,会先把子查询结果放到一个临时表,然后在外层表里逐行对比。这个过程相当于你拿着5万人的名单挨个查。优化方法
1.使用exits 代替in;2.使用left join+is null代替 not in
https://mp.weixin.qq.com/s/8MBt_MxywSB3v3caARIeHg
1.1.2 索引字段使用函数或计算,索引功能失效
对索引字段使用函数会使索引失效,变成全表扫描
| SELECT * FROM orders WHERE DATE_FORMAT(create_time, '%Y-%m-%d') = '2024-01-01'; 改为:使用范围查询 SELECT * FROM orders WHERE create_time >= '2024-01-01' AND create_time < '2024-01-02'; SELECT * FROM products WHERE price + 100 > 500;改为: SELECT * FROM products WHERE price > 400; |
1.1.3 为高频建立索引
针对不同场景,设置索引
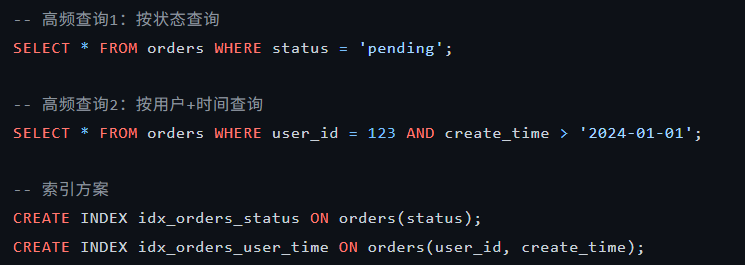
1.1.4 批量操作:大幅减少IO次数
性能提升:插入1000条数据,批量操作比单条插入快50倍!

1.1.5 谨慎设置null值
设置成默认值,不用null

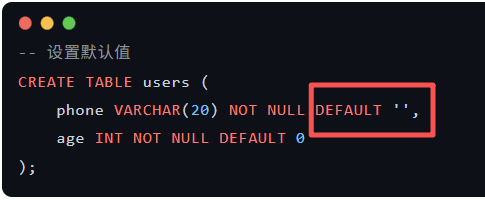
1.2 案例
优化结果: 2.3s → 0.02s
| SELECT * FROM orders |
优化方案:创建复合索引
| CREATE INDEX idx_orders_user_status_time ON orders(user_id, status, create_time); |
1.3 慢sql的开启
1.慢sql的配置
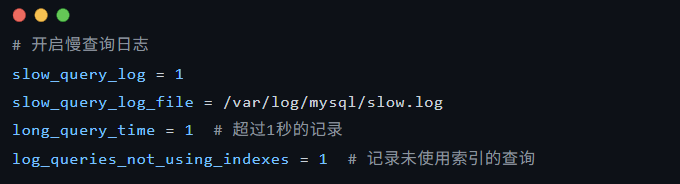
2.慢sql的查看
