langchain基础

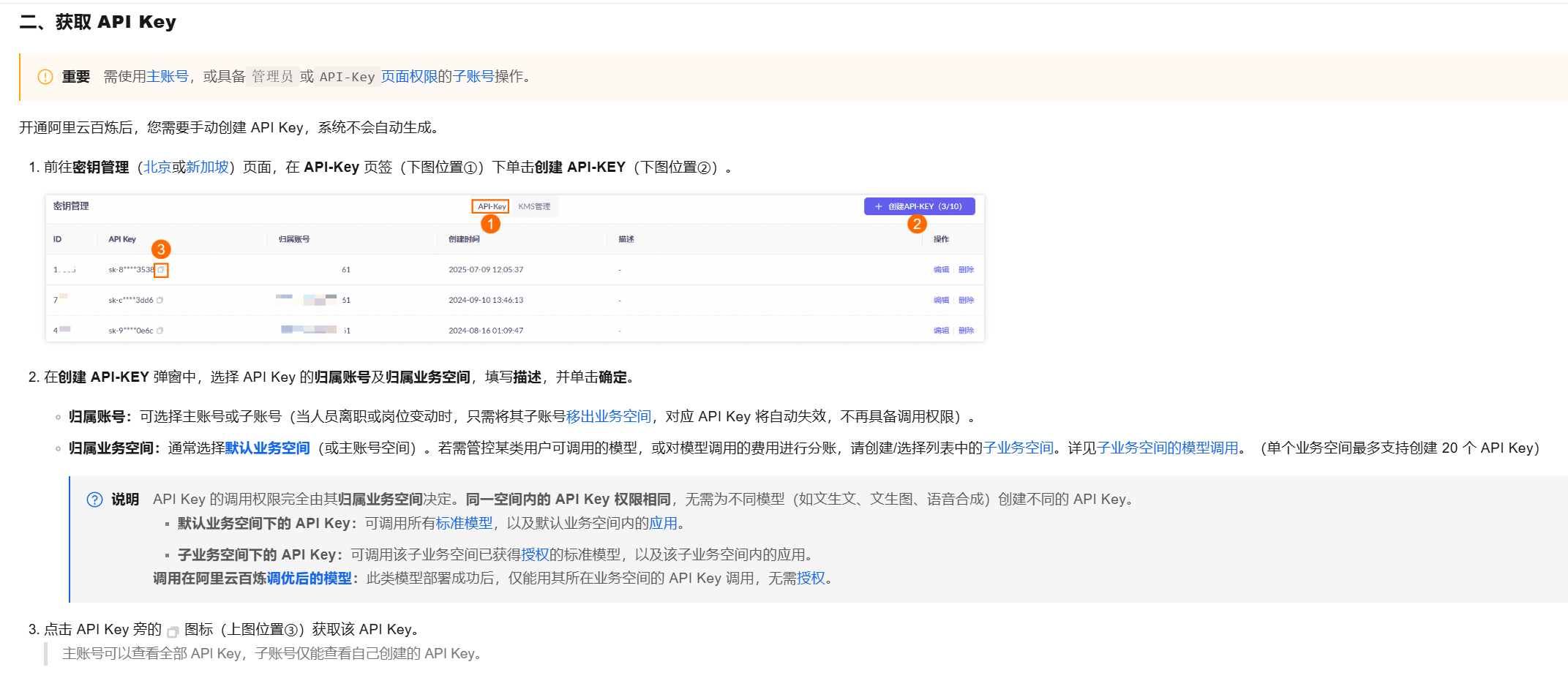
1 获取阿里云的api
这部分主要是就是关于提示词,有用户语言,系统语言,ai语言。下面我来用例子来学习这些
2 HumanMessage, SystemMessage
from langchain_openai import ChatOpenAI
model = ChatOpenAI(model="qwen-plus",openai_api_key="你的阿里云api",openai_api_base="https://dashscope.aliyuncs.com/compatible-mode/v1")这一步就是初始化一个模型调用的阿里云的qwen-plus,这部分我们可以直接在阿里云的文档中学习。
然后下面我们就设置提示词
from langchain.schema.messages import HumanMessage, SystemMessage
messages = [SystemMessage(content="请你作为我的数学课助教,用通俗易懂且间接的语言帮我解释数学原理。"),HumanMessage(content="什么是勾股定理?"),
]
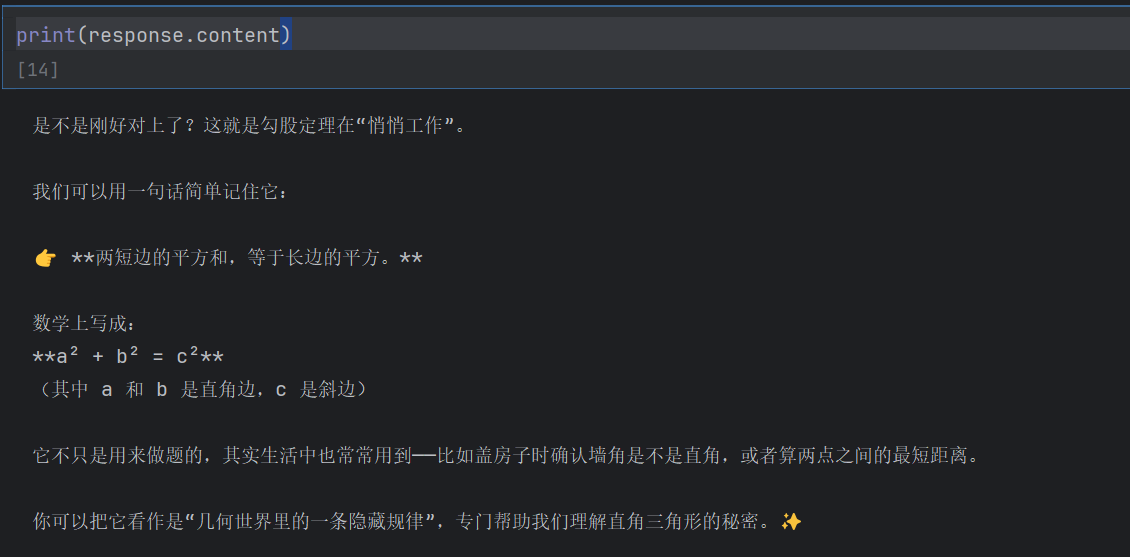
response = model.invoke(messages)print(response.content)这里我们设置系统提示词为“请你作为我的数学课助教,用通俗易懂且间接的语言帮我解释数学原理”,那么回答的问题就有关于我们的数学问题。
3 Prompt Template
from langchain.prompts import (SystemMessagePromptTemplate,AIMessagePromptTemplate,HumanMessagePromptTemplate,
)这里导入了三个类,就是用户信息模板,ai信息模板,系统模板。就是说我们先写好一个模板后面只需要补全其中的信息就好了。如下
system_template_text="你是一位专业的翻译,能够将{input_language}翻译成{output_language},并且输出文本会根据用户要求的任何语言风格进行调整。请只输出翻译后的文本,不要有任何其它内容。"
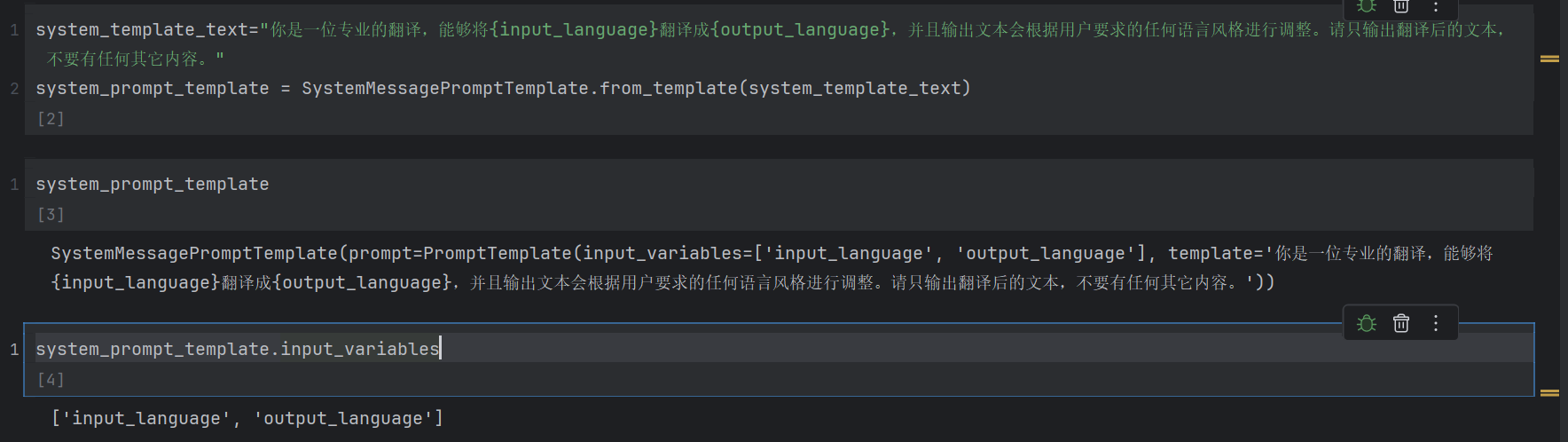
system_prompt_template = SystemMessagePromptTemplate.from_template(system_template_text)现在我就写了一个系统提示词模板,下面我们看看系统提示词模板长啥样
下面我们再创建一个用户提示词模板
human_template_text="文本:{text}\n语言风格:{style}"
human_prompt_template = HumanMessagePromptTemplate.from_template(human_template_text)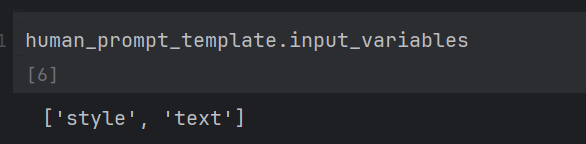
下面我们看下怎么往里面传入参数
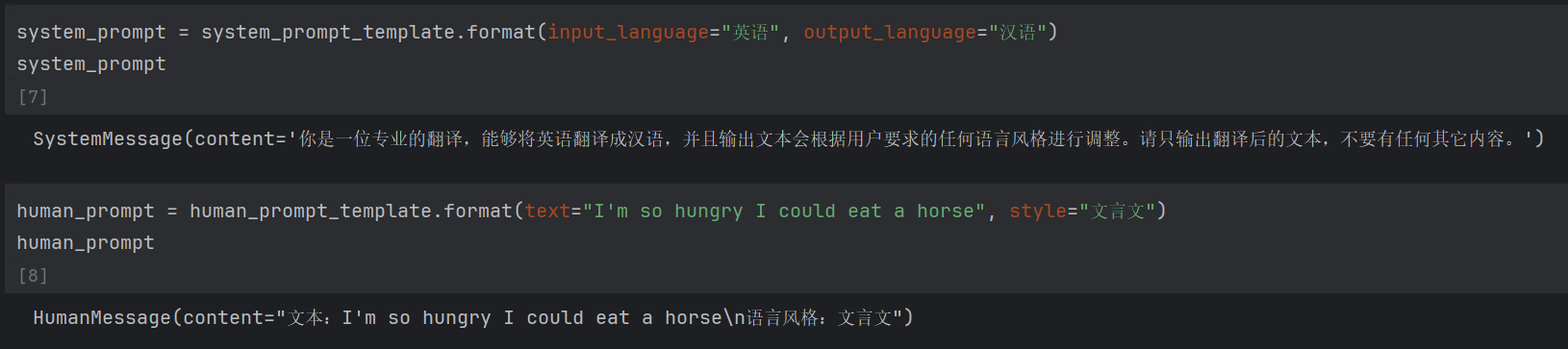
就这样,我们创建一个模板之后,只需要改变关键词就可以了,不用全部改变了。
print('你好,{0},{1}'.format('小狗','小猫'))
# 你好,小狗,小猫这里会不会发现和我们的输出时的format差不多的。
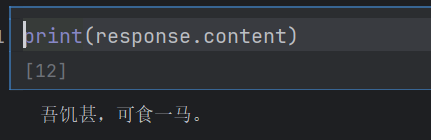
下面就是创建一个模型示例,然后传入参数(model.invoke()就是传入参数)
model = ChatOpenAI(model="qwen-plus",openai_api_key="你的阿里云api",openai_api_base="https://dashscope.aliyuncs.com/compatible-mode/v1")
response = model.invoke([system_prompt,human_prompt
])
4 ChatPromptTemplate
这个就是前面的优化版本,把原本的多句,要传入参数两次,集合了一下,传一次,但是一次传好几个。
from langchain.prompts import ChatPromptTemplate
prompt_template = ChatPromptTemplate.from_messages([("system", "你是一位专业的翻译,能够将{input_language}翻译成{output_language},并且输出文本会根据用户要求的任何语言风格进行调整。请只输出翻译后的文本,不要有任何其它内容。"),("human", "文本:{text}\n语言风格:{style}"),]
)
prompt_template.input_variables
prompt_value = prompt_template.invoke({"input_language": "汉语", "output_language": "汉语","text":"勿以善小而不为,勿以恶小而为之。", "style": "白话文"})
prompt_value
prompt_value.messages
model = ChatOpenAI(model="qwen-plus",openai_api_key="你的阿里云api",openai_api_base="https://dashscope.aliyuncs.com/compatible-mode/v1")
response = model.invoke(prompt_value)
print(response)
4 ai提示词模板
from langchain_openai import ChatOpenAI
from langchain.schema import HumanMessage
from langchain.prompts import FewShotChatMessagePromptTemplate, ChatPromptTemplate
example_prompt = ChatPromptTemplate.from_messages([("human", "格式化以下学生信息:\n姓名 -> {customer_name}\n年龄 -> {customer_age}\n 城市 -> {customer_city}"),("ai", "##学生信息\n- 学生姓名:{formatted_name}\n- 学生年龄:{formatted_age}\n- 学籍所在地:{formatted_city}")]
)这里我们先写了一个样例模板,类似与训练出一个模型一样,让他就这样输出。
然后初始化一些信息
examples = [{"customer_name": "张三", "customer_age": "7","customer_city": "郑州","formatted_name": "张三","formatted_age": "7岁","formatted_city": "河南省郑州市"},{"customer_name": "李四", "customer_age": "9","customer_city": "广州","formatted_name": "李四","formatted_age": "9岁","formatted_city": "广东省广州市"},
]再使用函数传入进去
few_shot_template = FewShotChatMessagePromptTemplate(example_prompt=example_prompt,examples=examples,
)然后再定义一个模板,这个模板就用于后面传入参数了。前面模板只是传入一个example
final_prompt_template = ChatPromptTemplate.from_messages([few_shot_template,("human", "{input}"),]
)定义一个模板,这个模板就是传入上面那个。
final_prompt = final_prompt_template.invoke({"input": "格式化以下学生信息:\n姓名 -> 王五\n年龄 -13\n 城市 -> 南昌'"})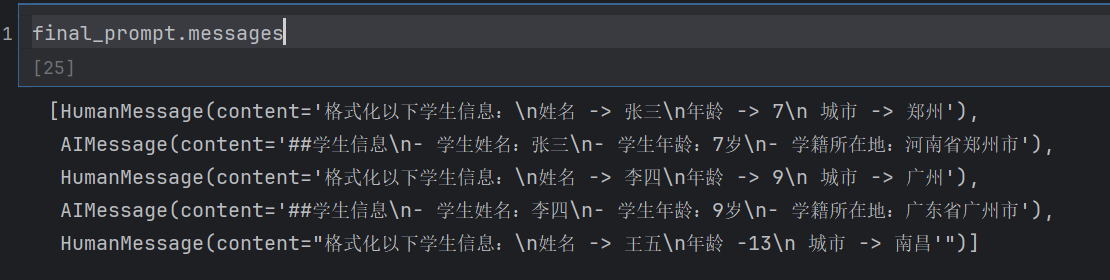
这里我查看了一下我们已经有的信息,和最后一次问的信息。
然后初始化model,传入信息,再输出
model = ChatOpenAI(model="qwen-plus",openai_api_key="你的阿里云api",openai_api_base="https://dashscope.aliyuncs.com/compatible-mode/v1")
response = model.invoke(final_prompt)
print(response.content)输出
5 CommaSeparatedListOutputParser
这个就是别人已经定义好的东西,我们直接调用就好了,例如
from langchain_openai import ChatOpenAI
from langchain.output_parsers import CommaSeparatedListOutputParser
from langchain.prompts import ChatPromptTemplate
prompt = ChatPromptTemplate.from_messages([("system", "{parser_instructions}"),("human", "列出5个{subject}国家的汽车品牌。")
])
output_parser = CommaSeparatedListOutputParser()
parser_instructions = output_parser.get_format_instructions()
print(parser_instructions)输出 Your response should be a list of comma separated values, eg: `foo, bar, baz`
意思就是输出的格式是以,分隔的
final_prompt = prompt.invoke({"subject": "美国", "parser_instructions": parser_instructions})model = ChatOpenAI(model="qwen-plus",openai_api_key="你的阿里云api",openai_api_base="https://dashscope.aliyuncs.com/compatible-mode/v1")
response = model.invoke(final_prompt)
print(response.content)传入参数,初始化模型,输出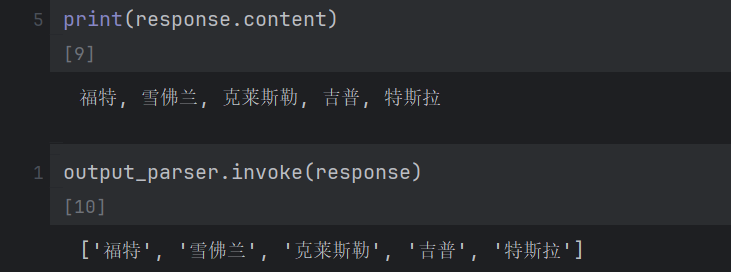
6 转化为json格式
from typing import Listfrom langchain.output_parsers import PydanticOutputParser
from langchain.prompts import ChatPromptTemplate
from langchain.schema import HumanMessage
from langchain_core.pydantic_v1 import BaseModel, Field
from langchain_openai import ChatOpenAI
#%%
class FilmInfo(BaseModel):film_name: str = Field(description="电影的名字", example="拯救大兵瑞恩")author_name: str = Field(description="电影的导演", example="斯皮尔伯格")genres: List[str] = Field(description="电影的题材", example=["历史", "战争"])#BaseModel用于创建数据模式,也就是数据的说明书,Field是字段,用于为Basemodel里的属性提供额外的信息和验证条件
#%%
output_parser = PydanticOutputParser(pydantic_object=FilmInfo)
#%%
print(output_parser.get_format_instructions())这个就是定义了一个模板,然后可以输出按照我们的要求的json格式
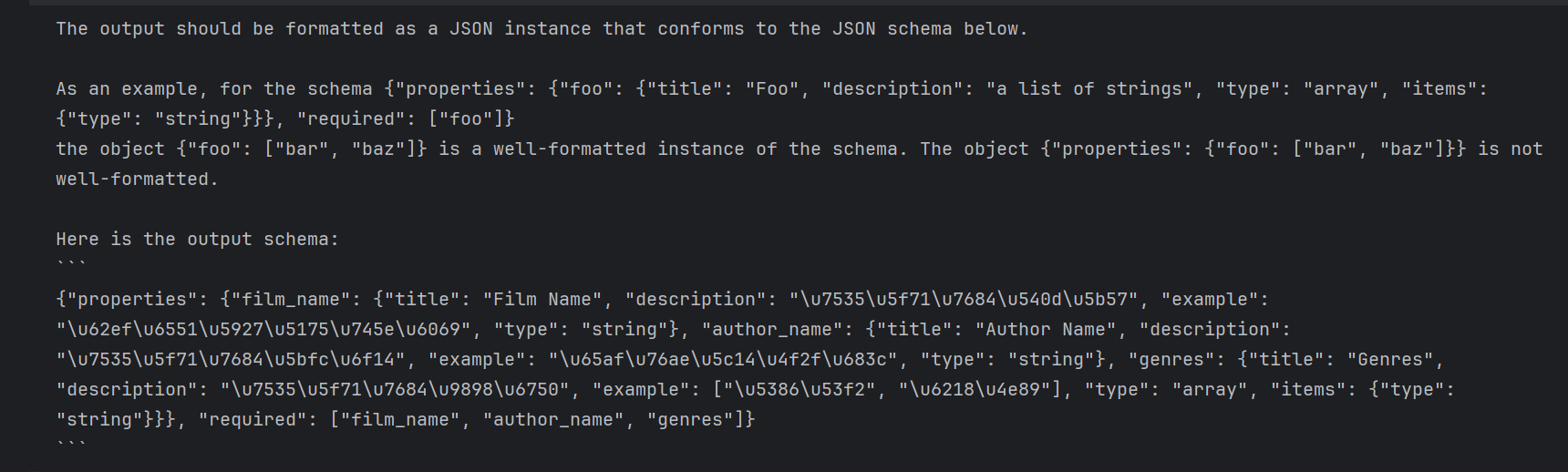
定义提示词
prompt = ChatPromptTemplate.from_messages([("system", "{parser_instructions} 你输出的结果请使用中文。"),("human", "请你帮我从电影概述中,提取电影名、导演,以及电影的体裁。电影概述会被三个#符号包围。\n###{film_introduction}###")
])
#%%
film_introduction = """《复仇者联盟4:终局之战》(Avengers: Endgame)是美国科幻电影,改编自美国漫威漫画,漫威电影宇宙(Marvel Cinematic Universe,缩写为MCU)第22部影片。影片由安东尼·罗素和乔·罗素执导,小罗伯特·唐尼、克里斯·埃文斯、马克·鲁法洛、克里斯·海姆斯沃斯、斯嘉丽·约翰逊、杰瑞米·雷纳、保罗·路德、布丽·拉尔森、乔什·布洛林、汤姆·希德勒斯顿、汤姆·赫兰德等主演。讲述《复仇者联盟3:无限战争》的毁灭性事件过后,宇宙由于疯狂泰坦灭霸的行动而变得满目疮痍。无论前方将遭遇怎样的后果,复仇者联盟都必须在剩余盟友的帮助下再一次集结,以逆转灭霸的所作所为,彻底恢复宇宙的秩序。该片于2019年4月26日在美国上映,4月24日在中国上映。截止2019年7月21日,《复仇者联盟4》全球票房达27.89亿美元,获全球影史票房总冠军。
"""
final_prompt = prompt.invoke({"film_introduction": film_introduction,"parser_instructions": output_parser.get_format_instructions()})
print(final_prompt)加载模型,传入参数,输出结构。
model = ChatOpenAI(model="qwen-plus",openai_api_key="你的阿里云api",openai_api_base="https://dashscope.aliyuncs.com/compatible-mode/v1")
response = model.invoke(final_prompt)
print(response.content)
7 链式传播
from langchain_openai import ChatOpenAI
from langchain.output_parsers import CommaSeparatedListOutputParser
from langchain.prompts import ChatPromptTemplate
#%%
prompt = ChatPromptTemplate.from_messages([("system", "{parser_instructions}"),("human", "列出5个{subject}生产的汽车的品牌。")
])
#%%
output_parser = CommaSeparatedListOutputParser()
parser_instructions = output_parser.get_format_instructions()
#%%
model = ChatOpenAI(model="qwen-plus",openai_api_key="你的阿里云api",openai_api_base="https://dashscope.aliyuncs.com/compatible-mode/v1")这里还是和前面一样,定义了一个系统和用户提示词模板,然后输出提示词模板用逗号分隔。
然后我们可以这样传输
result = output_parser.invoke(model.invoke(prompt.invoke({"subject": "中国", "parser_instructions": parser_instructions})))
result
这里我们可以使用chain特殊的传入格式
chat_model_chain = prompt | model | output_parser
result = chat_model_chain.invoke({"subject": "中国", "parser_instructions": parser_instructions})
result