GitHub上Transformers项目中推理函数pipeline的使用
Transformers是文本、计算机视觉、音频、视频和多模态模型(text, computer vision, audio, video, and multimodal model)领域最先进的机器学习模型的模型定义框架(model-definition framework),可用于推理和训练。源码:https://github.com/huggingface/transformers,最新发布版本v4.57.1,license为Apache-2.0。
Transformers集中了模型定义,以便整个生态系统都认可该定义。Transformers是跨框架的枢纽:如果支持某个模型定义,它将与大多数训练框架(Axolotl、Unsloth、DeepSpeed、FSDP、PyTorch-Lightning等)、推理引擎(vLLM、SGLang、TGI等)以及相关建模库(llama.cpp、mlx等)兼容,这些库都利用了Transformers 的模型定义。
Transformers优点:
1.支持三个热门的深度学习库:Jax, PyTorch以及TensorFlow,并与之无缝整合
2.模型易于使用,统一的API可用于所有的预训练模型
3.共享已训练好的模型,无需从头开始训练
4.只需3行代码即可训练模型
5.模型文件可以独立于库使用
Transformers中的Pipeline API是一个高级推理类,支持文本、音频、视觉和多模态任务。它负责预处理输入并返回相应的输出。
函数pipeline的声明在src/transformers/pipelines/__init__.py文件中,声明如下:返回Pipeline类
def pipeline(task: Optional[str] = None,model: Optional[Union[str, "PreTrainedModel", "TFPreTrainedModel"]] = None,config: Optional[Union[str, PretrainedConfig]] = None,tokenizer: Optional[Union[str, PreTrainedTokenizer, "PreTrainedTokenizerFast"]] = None,feature_extractor: Optional[Union[str, PreTrainedFeatureExtractor]] = None,image_processor: Optional[Union[str, BaseImageProcessor]] = None,processor: Optional[Union[str, ProcessorMixin]] = None,framework: Optional[str] = None,revision: Optional[str] = None,use_fast: bool = True,token: Optional[Union[str, bool]] = None,device: Optional[Union[int, str, "torch.device"]] = None,device_map: Optional[Union[str, dict[str, Union[int, str]]]] = None,dtype: Optional[Union[str, "torch.dtype"]] = "auto",trust_remote_code: Optional[bool] = None,model_kwargs: Optional[dict[str, Any]] = None,pipeline_class: Optional[Any] = None,**kwargs: Any,
) -> Pipeline当前支持的task包括:除task参数必须指定外,其它大部分参数都有默认值
"audio-classification": will return a [AudioClassificationPipeline]
"automatic-speech-recognition": will return a [AutomaticSpeechRecognitionPipeline]
"depth-estimation": will return a [DepthEstimationPipeline]
"document-question-answering": will return a [DocumentQuestionAnsweringPipeline]
"feature-extraction": will return a [FeatureExtractionPipeline]
"fill-mask": will return a [FillMaskPipeline]
"image-classification": will return a [ImageClassificationPipeline]
"image-feature-extraction": will return an [ImageFeatureExtractionPipeline]
"image-segmentation": will return a [ImageSegmentationPipeline]
"image-text-to-text": will return a [ImageTextToTextPipeline]
"image-to-image": will return a [ImageToImagePipeline]
"image-to-text": will return a [ImageToTextPipeline]
"keypoint-matching": will return a [KeypointMatchingPipeline]
"mask-generation": will return a [MaskGenerationPipeline]
"object-detection": will return a [ObjectDetectionPipeline]
"question-answering": will return a [QuestionAnsweringPipeline]
"summarization": will return a [SummarizationPipeline]
"table-question-answering": will return a [TableQuestionAnsweringPipeline]
"text2text-generation": will return a [Text2TextGenerationPipeline]
"text-classification" (alias "sentiment-analysis" available): will return a [TextClassificationPipeline]
"text-generation": will return a [TextGenerationPipeline]
"text-to-audio" (alias "text-to-speech" available): will return a [TextToAudioPipeline]
"token-classification" (alias "ner" available): will return a [TokenClassificationPipeline]
"translation": will return a [TranslationPipeline]
"translation_xx_to_yy": will return a [TranslationPipeline]
"video-classification": will return a [VideoClassificationPipeline]
"visual-question-answering": will return a [VisualQuestionAnsweringPipeline]
"zero-shot-classification": will return a [ZeroShotClassificationPipeline]
"zero-shot-image-classification": will return a [ZeroShotImageClassificationPipeline]
"zero-shot-audio-classification": will return a [ZeroShotAudioClassificationPipeline]
"zero-shot-object-detection": will return a [ZeroShotObjectDetectionPipeline]通过Anaconda创建虚拟环境,依次执行如下命令:
conda create --name ollama python=3.10 -y
conda activate ollama
pip install ollama
pip install colorama chromadb tqdm
pip install sentence-transformers
pip install langchain==1.0.0 langchain-huggingface langchain-chroma langchain-ollama jq
pip install torch==2.6.0 transformers==4.57.0 torchvision==0.21.0 opencv-python==4.10.0.84 timm sentencepiece scikit-image以下为测试代码:
from transformers import pipeline
from transformers.utils import logging
import argparse
import colorama
import torch
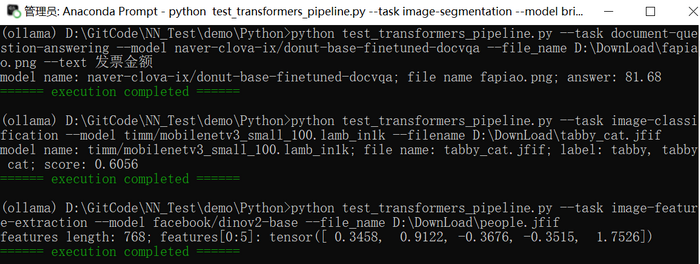
from pathlib import Pathdef parse_args():parser = argparse.ArgumentParser(description="transformers test")parser.add_argument("--task", required=True, type=str, choices=["document-question-answering", "image-classification", "image-feature-extraction", "image-segmentation", "object-detection"], help="specify what kind of task")parser.add_argument("--model", type=str, help="model name, for example: naver-clova-ix/donut-base-finetuned-docvqa")parser.add_argument("--file_name", type=str, help="image or pdf file name")parser.add_argument("--text", type=str, help="text")args = parser.parse_args()return argsdef document_question_answering(model, file_name, text):pipe = pipeline("document-question-answering", model=model)result = pipe(image=file_name, question=text)if result is not None and isinstance(result, list) and len(result) > 0:print(f'model name: {model}; file name {Path(file_name).name}; answer: {result[0]["answer"]}')def image_classification(model, file_name):pipe = pipeline("image-classification", model=model)result = pipe(file_name)if result is not None and isinstance(result, list) and len(result) > 0:print(f'model name: {model}; file name: {Path(file_name).name}; label: {result[0]["label"]}; score: {result[0]["score"]:.4f}')def image_feature_extraction(model, file_name):pipe = pipeline("image-feature-extraction", model=model)result = pipe(file_name)if result is not None and isinstance(result, list) and len(result) > 0:features = torch.tensor(result[0]).mean(dim=0)print(f"features length: {len(features)}; features[0:5]: {features[0:5]}")def image_segmentation(model, file_name):pipe = pipeline("image-segmentation", model=model, trust_remote_code=True)result = pipe(file_name)if result is not None:result.save("result_image_segmentation.png")def object_detection(model, file_name):pipe = pipeline("object-detection", model=model)result = pipe(file_name)if result is not None and isinstance(result, list) and len(result) > 0:print(f'label: {result[0]["label"]}, score: {result[0]["score"]:.4f}, box: {result[0]["box"]}')if __name__ == "__main__":colorama.init(autoreset=True)args = parse_args()logging.set_verbosity_error()if args.task == "document-question-answering":document_question_answering(args.model, args.file_name, args.text)elif args.task == "image-classification":image_classification(args.model, args.file_name)elif args.task == "image-feature-extraction":image_feature_extraction(args.model, args.file_name)elif args.task == "image-segmentation":image_segmentation(args.model, args.file_name)elif args.task == "object-detection":object_detection(args.model, args.file_name)print(colorama.Fore.GREEN + "====== execution completed ======")测试代码中包含的task:document-question-answering(naver-clova-ix/donut-base-finetuned-docvqa)、image-classification(timm/mobilenetv3_small_100.lamb_in1k)、image-feature-extraction(facebook/dinov2-base)、image-segmentation(briaai/RMBG-1.4)、object-detection(hustvl/yolos-small)
注:
(1).并不是Hugging Face上的所有模型都支持pipeline。
(2).除了使用pipeline外,每个task或model都可以调用各自内部类,如:from transformers import YolosFeatureExtractor, YolosForObjectDetection。
部分执行结果如下图所示:
GitHub:https://github.com/fengbingchun/NN_Test