视觉Transformer的介绍即ViT模型的搭建(pytorch版本)
文章目录
- 前言
- 1.核心思想
- 2.模型搭建步骤
- 2.1 图像分块与线性投影
- 2.2位置编码
- 2.3分类标记
- 2.4Transformer 编码器
- 2.5分类头
- 3.完整代码及测试
- 结语
前言
在计算机视觉领域,卷积神经网络(CNN)长期以来占据主导地位。但自 2020 年 Google 团队提出 Vision Transformer(ViT)以来,基于 Transformer 的模型在各类视觉任务上表现出了超越传统 CNN 的潜力。本文将详细解析视觉 Transformer 的工作原理,并通过代码实现一个简化版的 ViT 模型,帮助你深入理解其架构细节。
论文地址:https://arxiv.org/pdf/2010.11929
1.核心思想
视觉 Transformer 的核心创新在于将 NLP 领域大获成功的 Transformer 架构迁移到视觉任务中。其基本思路是:
- 将图像分割成固定大小的 patches
- 将每个 patch 线性投影为向量
- 加入位置编码,保留空间信息
- 使用标准 Transformer 编码器进行处理
- 最后添加分类头完成视觉任务
具体如下图所示,这种方法跳过了 CNN 固有的局部感受野限制,能够学习到更全局的图像特征。
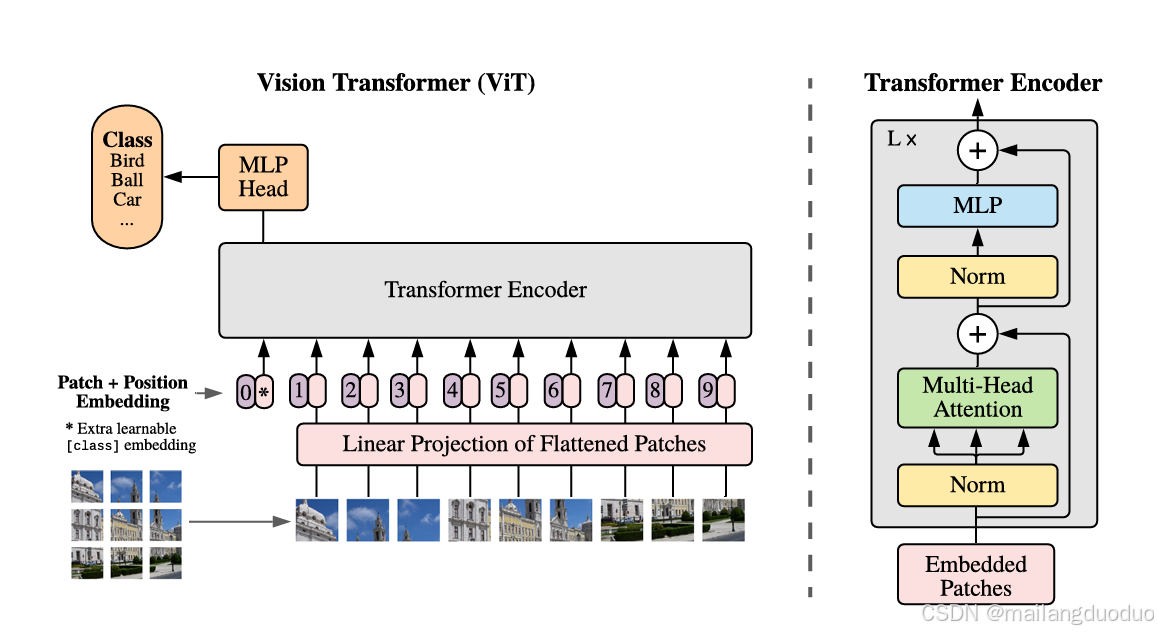
2.模型搭建步骤
2.1 图像分块与线性投影
首先,我们需要将输入图像分割成不重叠的 patches。例如,对于 224×224 的图像,使用 16×16 的 patch 大小,会得到 (224/16)×(224/16)=14×14=196 个 patches。
每个 patch 的维度是 16×16×3(假设是 RGB 图像),我们通过一个线性层将其投影到指定维度(例如 768),得到 196 个维度为 768 的向量。
具体代码如下:
class PatchEmbedding(nn.Module):"""将图像分割为patches并进行线性投影"""def __init__(self, img_size: int = 224, patch_size: int = 16, in_channels: int = 3, embed_dim: int = 768):# def __init__(self, img_size= 224, patch_size = 16, in_channels= 3, embed_dim= 768):super().__init__()self.img_size = img_sizeself.patch_size = patch_size# 计算图像可以分割成多少个patchself.num_patches = (img_size // patch_size) ** 2# 使用卷积层实现分块和投影self.proj = nn.Conv2d(in_channels,embed_dim,kernel_size=patch_size,stride=patch_size)def forward(self, x: Tensor) -> Tensor:# x的形状: (batch_size, in_channels, img_size, img_size)x = self.proj(x) # 形状: (batch_size, embed_dim, num_patches**0.5, num_patches**0.5)x = x.flatten(2) # 形状: (batch_size, embed_dim, num_patches)x = x.transpose(1, 2) # 形状: (batch_size, num_patches, embed_dim)return x
2.2位置编码
由于 Transformer 是置换不变的,即不包含位置信息。我们需要添加位置编码来告诉模型每个 patch 的空间位置。通常有两种实现方式:
- 可学习的位置编码
- 正弦余弦位置编码(类似原始 Transformer)
在 ViT 中,通常使用可学习的位置编码。因此可以直接初始化一组可学习参数即可,可以选择初始化为全零,并使用nn.Parameter(...)函数将其转化为可学习参数。即
nn.Parameter(torch.zeros(1, num_patches, embed_dim))
2.3分类标记
借鉴 BERT 中的 [CLS] 标记,我们在序列的开头添加一个可学习的分类标记。这个标记经过 Transformer 处理后,将被用于最终的分类任务。
之所以使用这个分类主要是因为:视觉 Transformer 会先将图像拆成多个 Patch(如 14×14=196 个),每个 Patch 对应一个特征向量,这些向量主要描述局部图像信息。
而分类标记的核心价值在于:
- 汇总全局特征:在模型前向传播时,分类标记会与所有 Patch 的特征向量通过自注意力机制交互,逐步 “吸收” 整个图像的全局信息(比如 “这张图里有猫的耳朵、尾巴、毛发纹理” 等所有局部特征的综合)。
- 输出分类结果:模型最后只需要提取分类标记经过 Transformer 处理后的特征向量,再输入到分类头(线性层),就能直接输出 “猫”“狗”“汽车” 等分类结果,无需再处理所有 Patch 的向量。
2.4Transformer 编码器
Transformer 编码器由多个相同的层堆叠而成,每个层包含:
- 多头自注意力机制(Multi-Head Self-Attention)
详细的计算过程可参考本篇博客——入门级别的Transformer模型介绍,这里只提供代码部分:
class MultiHeadAttention(nn.Module):"""多头自注意力机制"""def __init__(self, embed_dim: int = 768, num_heads: int = 8, dropout: float = 0.0):super().__init__()self.embed_dim = embed_dimself.num_heads = num_headsself.head_dim = embed_dim // num_headsassert self.head_dim * num_heads == embed_dim, "嵌入维度必须能被头数整除"# Q, K, V投影self.qkv_proj = nn.Linear(embed_dim, embed_dim * 3)# 输出投影self.out_proj = nn.Linear(embed_dim, embed_dim)self.dropout = nn.Dropout(dropout)def forward(self, x: Tensor) -> Tensor:# x的形状: (batch_size, num_patches + 1, embed_dim)batch_size, seq_len, embed_dim = x.shape# 计算Q, K, Vqkv = self.qkv_proj(x).reshape(batch_size, seq_len, 3, self.num_heads, self.head_dim)qkv = qkv.permute(2, 0, 3, 1, 4) # 形状: (3, batch_size, num_heads, seq_len, head_dim)q, k, v = qkv.unbind(0) # 每个的形状: (batch_size, num_heads, seq_len, head_dim)# 计算注意力分数attn_scores = (q @ k.transpose(-2, -1)) / (self.head_dim ** 0.5) # 形状: (batch_size, num_heads, seq_len, seq_len)attn_probs = F.softmax(attn_scores, dim=-1)attn_probs = self.dropout(attn_probs)# 应用注意力attn_output = attn_probs @ v # 形状: (batch_size, num_heads, seq_len, head_dim)attn_output = attn_output.transpose(1, 2).reshape(batch_size, seq_len, embed_dim) # 合并多头# 输出投影output = self.out_proj(attn_output) # 形状: (batch_size, seq_len, embed_dim)return output- 多层感知机(MLP)
多层感知机主要用来增加Transformer模型的非线性拟合能力,由线性层构成,代码如下,此处加入了DropOut机制。
class MLP(nn.Module):"""多层感知机"""def __init__(self, embed_dim: int = 768, hidden_dim: int = 3072, dropout: float = 0.0):super().__init__()self.fc1 = nn.Linear(embed_dim, hidden_dim)self.act = nn.GELU() # 使用GELU激活函数self.fc2 = nn.Linear(hidden_dim, embed_dim)self.dropout = nn.Dropout(dropout)def forward(self, x: Tensor) -> Tensor:x = self.fc1(x)x = self.act(x)x = self.dropout(x)x = self.fc2(x)x = self.dropout(x)return x
- 层归一化(Layer Normalization)
该部分已经非封装成函数,可以直接调用。 - 残差连接(Residual Connection)
因此,编码器部分代码为:
class TransformerEncoderLayer(nn.Module):"""Transformer编码器层"""def __init__(self, embed_dim: int = 768, num_heads: int = 8, mlp_hidden_dim: int = 3072, dropout: float = 0.0):super().__init__()self.norm1 = nn.LayerNorm(embed_dim)self.attn = MultiHeadAttention(embed_dim, num_heads, dropout)self.norm2 = nn.LayerNorm(embed_dim)self.mlp = MLP(embed_dim, mlp_hidden_dim, dropout)def forward(self, x: Tensor) -> Tensor:# 自注意力部分,带残差连接x = x + self.attn(self.norm1(x))# MLP部分,带残差连接x = x + self.mlp(self.norm2(x))return x
2.5分类头
最后,我们取分类标记经过 Transformer 处理后的输出,通过一个线性层得到最终的分类结果。
3.完整代码及测试
基于上述阐述,将各部分的代码进行拼接,即可得到完整的ViT模型,代码如下:
import torch
from torch import nn
import torch.nn.functional as F
from torch import Tensor
class PatchEmbedding(nn.Module):"""将图像分割为patches并进行线性投影"""def __init__(self, img_size: int = 224, patch_size: int = 16, in_channels: int = 3, embed_dim: int = 768):# def __init__(self, img_size= 224, patch_size = 16, in_channels= 3, embed_dim= 768):super().__init__()self.img_size = img_sizeself.patch_size = patch_size# 计算图像可以分割成多少个patchself.num_patches = (img_size // patch_size) ** 2# 使用卷积层实现分块和投影(等价于将每个patch展平后通过线性层)self.proj = nn.Conv2d(in_channels,embed_dim,kernel_size=patch_size,stride=patch_size)def forward(self, x: Tensor) -> Tensor:# x的形状: (batch_size, in_channels, img_size, img_size)x = self.proj(x) # 形状: (batch_size, embed_dim, num_patches**0.5, num_patches**0.5)x = x.flatten(2) # 形状: (batch_size, embed_dim, num_patches)x = x.transpose(1, 2) # 形状: (batch_size, num_patches, embed_dim)return xclass MultiHeadAttention(nn.Module):"""多头自注意力机制"""def __init__(self, embed_dim: int = 768, num_heads: int = 8, dropout: float = 0.0):super().__init__()self.embed_dim = embed_dimself.num_heads = num_headsself.head_dim = embed_dim // num_headsassert self.head_dim * num_heads == embed_dim, "嵌入维度必须能被头数整除"# Q, K, V投影self.qkv_proj = nn.Linear(embed_dim, embed_dim * 3)# 输出投影self.out_proj = nn.Linear(embed_dim, embed_dim)self.dropout = nn.Dropout(dropout)def forward(self, x: Tensor) -> Tensor:# x的形状: (batch_size, num_patches + 1, embed_dim)batch_size, seq_len, embed_dim = x.shape# 计算Q, K, Vqkv = self.qkv_proj(x).reshape(batch_size, seq_len, 3, self.num_heads, self.head_dim)qkv = qkv.permute(2, 0, 3, 1, 4) # 形状: (3, batch_size, num_heads, seq_len, head_dim)q, k, v = qkv.unbind(0) # 每个的形状: (batch_size, num_heads, seq_len, head_dim)# 计算注意力分数attn_scores = (q @ k.transpose(-2, -1)) / (self.head_dim ** 0.5) # 形状: (batch_size, num_heads, seq_len, seq_len)attn_probs = F.softmax(attn_scores, dim=-1)attn_probs = self.dropout(attn_probs)# 应用注意力attn_output = attn_probs @ v # 形状: (batch_size, num_heads, seq_len, head_dim)attn_output = attn_output.transpose(1, 2).reshape(batch_size, seq_len, embed_dim) # 合并多头# 输出投影output = self.out_proj(attn_output) # 形状: (batch_size, seq_len, embed_dim)return outputclass MLP(nn.Module):"""多层感知机"""def __init__(self, embed_dim: int = 768, hidden_dim: int = 3072, dropout: float = 0.0):super().__init__()self.fc1 = nn.Linear(embed_dim, hidden_dim)self.act = nn.GELU() # 使用GELU激活函数self.fc2 = nn.Linear(hidden_dim, embed_dim)self.dropout = nn.Dropout(dropout)def forward(self, x: Tensor) -> Tensor:x = self.fc1(x)x = self.act(x)x = self.dropout(x)x = self.fc2(x)x = self.dropout(x)return xclass TransformerEncoderLayer(nn.Module):"""Transformer编码器层"""def __init__(self, embed_dim: int = 768, num_heads: int = 8, mlp_hidden_dim: int = 3072, dropout: float = 0.0):super().__init__()self.norm1 = nn.LayerNorm(embed_dim)self.attn = MultiHeadAttention(embed_dim, num_heads, dropout)self.norm2 = nn.LayerNorm(embed_dim)self.mlp = MLP(embed_dim, mlp_hidden_dim, dropout)def forward(self, x: Tensor) -> Tensor:# 自注意力部分,带残差连接x = x + self.attn(self.norm1(x))# MLP部分,带残差连接x = x + self.mlp(self.norm2(x))return xclass VisionTransformer(nn.Module):"""完整的视觉Transformer模型"""def __init__(self,img_size: int = 224,patch_size: int = 16,in_channels: int = 3,num_classes: int = 1000,embed_dim: int = 768,depth: int = 12, # Transformer编码器层数num_heads: int = 8,mlp_hidden_dim: int = 3072,dropout: float = 0.0):super().__init__()# 1. Patch嵌入self.patch_embed = PatchEmbedding(img_size, patch_size, in_channels, embed_dim)num_patches = self.patch_embed.num_patches# 2. 分类标记self.class_token = nn.Parameter(torch.zeros(1, 1, embed_dim))# 3. 位置编码self.pos_embed = nn.Parameter(torch.zeros(1, num_patches + 1, embed_dim))self.pos_drop = nn.Dropout(dropout)# 4. Transformer编码器self.encoder_layers = nn.ModuleList([TransformerEncoderLayer(embed_dim, num_heads, mlp_hidden_dim, dropout)for _ in range(depth)])# 5. 分类头self.norm = nn.LayerNorm(embed_dim)self.classifier = nn.Linear(embed_dim, num_classes)# 初始化权重self._init_weights()def _init_weights(self):# 初始化位置编码nn.init.trunc_normal_(self.pos_embed, std=0.02)# 初始化分类标记nn.init.trunc_normal_(self.class_token, std=0.02)# 初始化其他层for m in self.modules():if isinstance(m, nn.Linear):nn.init.trunc_normal_(m.weight, std=0.02)if m.bias is not None:nn.init.zeros_(m.bias)elif isinstance(m, nn.Conv2d):nn.init.kaiming_normal_(m.weight, mode='fan_out')if m.bias is not None:nn.init.zeros_(m.bias)elif isinstance(m, nn.LayerNorm):nn.init.zeros_(m.bias)nn.init.ones_(m.weight)def forward(self, x: Tensor) -> Tensor:# x的形状: (batch_size, in_channels, img_size, img_size)batch_size = x.shape[0]# 1. 图像分块和嵌入x = self.patch_embed(x) # 形状: (batch_size, num_patches, embed_dim)# 2. 添加分类标记class_tokens = self.class_token.expand(batch_size, -1, -1) # 形状: (batch_size, 1, embed_dim)x = torch.cat([class_tokens, x], dim=1) # 形状: (batch_size, num_patches + 1, embed_dim)# 3. 添加位置编码x = x + self.pos_embedx = self.pos_drop(x)# 4. 通过Transformer编码器for layer in self.encoder_layers:x = layer(x)# 5. 分类x = self.norm(x)class_output = x[:, 0] # 取分类标记的输出logits = self.classifier(class_output) # 形状: (batch_size, num_classes)return logits假设我们输入一个批量大小为2,图像大小为224×224的彩色图像,模型输出应该为2(代表批量大小)×10(代表十分类),测试如下:
# 测试模型
if __name__ == "__main__":# 创建一个随机图像张量 (batch_size=2, channels=3, height=224, width=224)dummy_image = torch.randn(2, 3, 224, 224)# 初始化一个小型ViT模型vit = VisionTransformer(img_size=224,patch_size=16,num_classes=10,embed_dim=256,depth=4,num_heads=4,mlp_hidden_dim=1024)# 前向传播output = vit(dummy_image)print(f"输入形状: {dummy_image.shape}")print(f"输出形状: {output.shape}") 运行结果:

结语
本篇博客主要介绍了如何从零搭建一个视觉Transformer(ViT)网络,可以使用该网络结构实现分类问题,可以动手实现利用该网络在CIFAR-10数据集、MINST数据集等公开数据集进一步熟悉,希望能够对你有所帮助!