本地大模型、本地embeding、本地数据库、本地RAG Flow搭建方式——从显卡驱动开始
RAGFlow是一个大模型应用的大趋势,所以我打算本地搭建一个RAGFlow和配套的本地大模型。
我的配置清单
-
RTX 5080 16 GB
-
48 GB 内存
-
Ubuntu 24.04
显卡驱动
确认显卡型号
打开终端,输入以下命令查看你的 NVIDIA 显卡型号(我的显卡是RTX5080):
lspci | grep -i nvidia查看推荐的驱动版本
ubuntu-drivers devices更新apt库
sudo apt update && sudo apt upgrade -y安装推荐的驱动
由于我尝试了官网安装、nvidia-driver-580的不open版本,都不能正常加载——且不是secure boot的问题,所以我这里还是推荐直接nvidia-driver-580-open,当然想试试还是可以试试的。
sudo apt install nvidia-driver-580-open禁用Nouveau
禁用 Nouveau 驱动 是安装 NVIDIA 官方驱动前必须完成的一步,因为它是 Ubuntu 自带的开源 NVIDIA 驱动,会与官方驱动冲突,导致黑屏、驱动加载失败等问题。
sudo gnome-text-editor /etc/modprobe.d/blacklist-nouveau.conf添加以下内容:
blacklist nouveau
options nouveau modeset=0更新 initramfs
sudo update-initramfs -u重启并测试
sudo reboot
#启动后查看
#前者应该看不到nouveau,后者应该看到nvidia驱动信息
lsmod | grep nouveau
nvidia-smi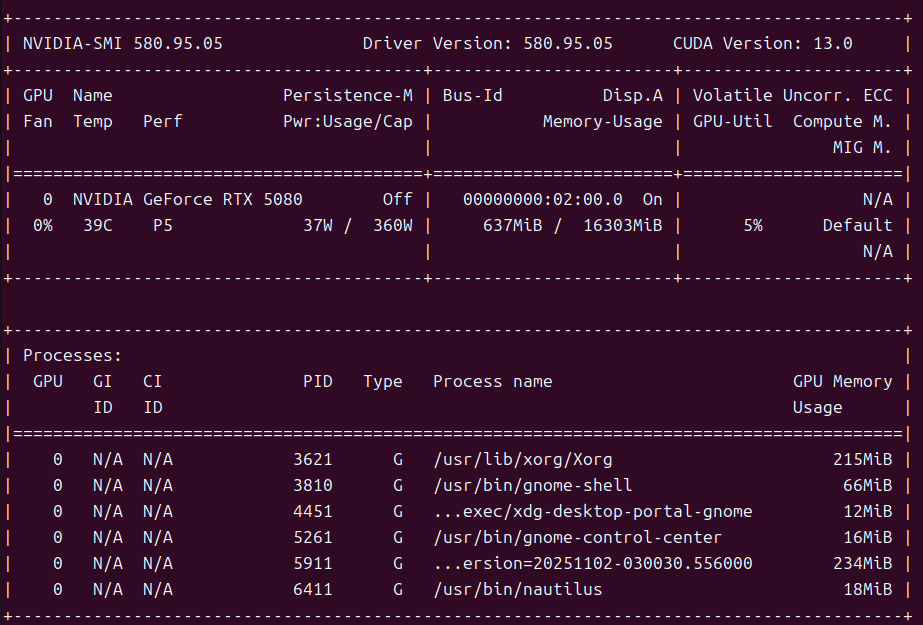
secure boot注册
如果可以接受bios里面关掉secure boot那么本节可以忽略,如果想手动签名一下驱动相关ko,参考我的另一篇博客
https://blog.csdn.net/Mr_liu_666/article/details/154099770?spm=1001.2014.3001.5502
安装docker
由于我们的RAGFlow打算用docker版本,所以需要首先安装docker
有的教程会推荐换源到阿里云,部分时刻阿里云会限速到30K,我这里推荐腾讯云。
安装docker本体和docker的compose插件
# 1. 装依赖
sudo apt update && sudo apt -y install apt-transport-https ca-certificates curl gnupg# 2. 下载 **Docker 官方** GPG 密钥(腾讯云镜像也提供同一文件)
sudo curl -fsSL https://mirrors.cloud.tencent.com/docker-ce/linux/ubuntu/gpg \| sudo gpg --dearmor -o /etc/apt/trusted.gpg.d/docker.gpg# 3. 添加 **腾讯云** apt 源(noble = 24.04)
echo \
"deb [arch=$(dpkg --print-architecture) signed-by=/etc/apt/trusted.gpg.d/docker.gpg] \
https://mirrors.cloud.tencent.com/docker-ce/linux/ubuntu \
noble stable" | sudo tee /etc/apt/sources.list.d/docker.list# 4. 装最新版
sudo apt update
sudo apt -y install docker-ce docker-ce-cli containerd.io docker-buildx-plugin docker-compose-plugin验证
docker --version # 24.x+
docker compose version # v2.29+
ollama

通俗的说:Ollama是一个大模型管理工具,提供了大模型到人、大模型到RAGFlow的接口。
Ollama是一个支持跨平台部署的开源大语言模型(LLM)管理工具,提供本地模型运行、云端模型调用及开发者友好的API接口,适用于代码补全、智能问答等场景。
Ollama核心功能与应用场景
- 跨平台支持:支持Windows/macOS/Linux系统,提供云端模型(如gpt-oss、deepseek-v3.1等)与本地私有模型的混合部署。12
- 开发集成:通过REST API(默认端口11434)与Spring Boot等技术栈无缝对接,支持代码补全、问答系统构建。34
- 模型管理:内置Modelfile格式统一管理模型权重与配置,支持热加载切换模型。3
下载ollama
# 下载官方脚本并替换下载地址为国内镜像
curl -fsSL https://ollama.com/install.sh | \
sed 's|https://github.com/ollama/ollama/releases/download|https://mirror.ccs.tencentyun.com/ollama/releases/download|g' | \
sh关于更新
程序:Win/Mac 默认自动升级,Linux 需手动。
模型:永不自动更新;想换新版,主动 ollama pull <模型名> 即可。使用ollama下载大模型
根据我的配置:
-
RTX 5080 16 GB
-
48 GB 内存
-
新装 Ubuntu 24.04
选型
我选择了Gemma-3:12b-8bit量化 ,量化体积 8 GB ,显存占用9–11 GB,Google 最新,特点是128 k 上下文,速度快,适合场景是长文总结、翻译、高并发 API 。
开启python虚拟环境
由于需要安装modelscope,pip不能直接安装到本地,所以先建立一个python的虚拟环境,可能提示python3需要再下载一个虚拟环境版本,按照提示下载就好了:
# 1. 创建 venv
python3 -m venv ~/venv-ms
# 2. 激活
source ~/venv-ms/bin/activate
启动后命令行会出现括号,在虚拟环境里面安装工具和下载。
下载阿里云镜像的大模型
# 安装下载工具
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple -U modelscope# 一次性拉取 Q8_0 单文件(12.5 GB)
modelscope download \--model=bartowski/google_gemma-3-12b-it-GGUF \--local_dir ./gemma3-q8 \--include="google_gemma-3-12b-it-Q8_0.gguf"编写 Modelfile(锁定参数,后续不更新)
num_ctx 是 Ollama 在加载模型时 一次性给 Transformer 开的“上下文窗口”大小,单位是 token。num_ctx可根据任务调到 16384
temperature 选0.3降低幻觉,想创造力高,就0.7
cat > Modelfile <<'EOF'
FROM "./gemma3-q8/google_gemma-3-12b-it-Q8_0.gguf"
TEMPLATE """<bos><start_of_turn>user
{{ if .System }}{{ .System }}{{ end }}{{ .Prompt }}<end_of_turn>
<start_of_turn>model
{{ .Response }}<end_of_turn>
"""
PARAMETER stop <end_of_turn>
PARAMETER num_ctx 8192
PARAMETER temperature 0.3
EOF导入 Ollama 并启动
# 创建本地模型(永不随官方库更新)
ollama create gemma3-12b-q8 -f Modelfile# 首次验证
ollama run gemma3-12b-q8 \--prompt "用三句话总结量子计算的核心思想。"测试大模型是否正常
我在商用大模型(也就是671b)上,要求给出一个本地的LLM的测试用例:
原始段落(验证用)
2019 年 3 月 14 日,全球市值第 3 的微软宣布以 75 亿美元全现金收购代码托管平台 GitHub;由于后者 2018 年营收仅 3 亿美元且连亏 3 年,外界普遍质疑价格过高,但微软 CEO 纳德拉坚称“这将加速我们的云战略”,交易在 2018 年 10 月 25 日已获双方董事会通过,仅待欧盟反垄断批准即可在 2019 年夏完成交割,届时 GitHub 将保持独立运营,其 2800 万开源仓库和 3100 万开发者数据全部迁入 Azure,成为微软对抗 AWS 的第 4 张王牌。
合格摘要(供对比)
微软 2019-3-14 宣布 75 亿美元现金收购连亏 3 年的 GitHub,2019 夏交割后保持独立,2800 万仓库接入 Azure,补强云战略以对抗 AWS。以下是我的测试结果,看起来不错,671b评价了本地LLM的总结“58 字,数字全对,时间、金额、仓库/开发者量级都没错,也点出了“云战略+抗 AWS”的核心动机——满分。”
ollama run gemma3-12b-q8 "总结下面的内容,重点是数字别搞错,60字以内:2019 年 3 月 14 日,全球市值第 3 的微软宣布以 75 亿美元全现金收购代码托管平台 GitHub;由于后者 2018 年营收仅 3 亿美元且连亏 3 年,外界普遍质疑价格过高,但微软 CEO 纳德拉坚称“这将加速我们的云战略”,交易在 2018 年 10 月 25 日已获双方董事会通过,仅待欧盟反垄断批准即可在 2019 年夏完 成交割,届时 GitHub 将保持独立运营,其 2800 万开源仓库和 3100 万开发者数据全部迁入 Azure,成为微软对抗 AWS 的第 4 张王牌。"
2019年3月,微软以75亿美元全资收购代码托管平台GitHub。尽管GitHub 2018年仅有3亿美元营收,微软仍寄希望于此加速云战略,并将其2800万开源仓库和3100万开
发者数据迁移至Azure,助力对抗AWS。RAGFlow安装
配置环境
# 1. 放大 mmap 计数,否则 ES 启动报错
sudo sysctl -w vm.max_map_count=262144
# 建议写进 /etc/sysctl.conf 永久生效下载RAGFlow
我是github界面
mkdir -p ~/ragflow && cd ~/ragflow修改配置,使docker可以访问显卡
docker不配置是不能访问显卡的,所以验证一下是否配置过,然后进行配置。
验证方法
# 1. 验证驱动
nvidia-smi
# 需能看到 GPU 名称、驱动版本 ≥ 470# 2. 验证 Docker 能调用 GPU
docker run --rm --gpus all nvidia/cuda:12.1-base nvidia-smi
# 同样出现 GPU 列表即 OK配置系统,使得docker可以访问显卡
nvidia-docker(现在叫 NVIDIA Container Toolkit)做了两件事
-
把宿主机的 NVIDIA 驱动“挂载”进容器(字符设备 /dev/nvidia*、内核模块接口)。
-
把宿主机装好的 CUDA 用户态库(libcuda.so、libnvidia-ml.so 等)自动 bind-mount 到容器内部对应路径,版本与宿主机驱动严格匹配。
结果:容器里不需要再装任何驱动,就能调用 CUDA、cuDNN、OpenGL、OptiX 等全套 GPU 功能。
以下方法可以试试,但是我遇到了“
E: 无法定位软件包 nvidia-container-toolkit
”
# 1 安装 NVIDIA Container Toolkit
sudo apt install -y nvidia-container-toolkit
sudo nvidia-ctk runtime configure --runtime=docker
sudo systemctl restart docker如果你也遇到了在个问题,可以直接去https://github.com/NVIDIA/libnvidia-container/releases下载4个deb,安装了就好了
libnvidia-container1_1.15.0-1_amd64.deb
libnvidia-container-tools_1.15.0-1_amd64.deb
nvidia-container-toolkit-base_1.15.0-1_amd64.deb
nvidia-container-toolkit_1.15.0-1_amd64.deb安装
#拷到目标机空目录,一次性装:
sudo dpkg -i *.deb
注册和重启和验证
sudo nvidia-ctk runtime configure --runtime=docker
sudo systemctl restart docker
docker run --rm --gpus all nvidia/cuda:12.4.1-base-ubuntu22.04 nvidia-smi修改RAGFlow配置
cd ~/ragflow/docker
grep -q ^DEVICE=gpu .env || sed -i '1i DEVICE=gpu' .env
# 镜像用带嵌入模型的 full-GPU 版
grep -q ^RAGFLOW_IMAGE=.*v0.21.1$ .env || \sed -i 's/RAGFLOW_IMAGE.*/RAGFLOW_IMAGE=infiniflow\/ragflow:v0.21.1/' .env启动RAGFlow
在ragflow-main/docker目录下
sudo docker compose -f docker-compose.yml up -d
查看log
docker logs -f docker-ragflow-gpu-1访问网页
http://127.0.0.1/login监控系统状态
ollama、RAGFlow跑起来的时候,我希望查看CPU、GPU的占用率、内存、显存的占用率,CPU\GPU温度,所以给出以下方法查看系统状态:
显卡、CPU、内存、显存监控
nvitop工具,有图形化界面。但是看到pip我们就知道必须venv了。
# 先装工具
pip install nvitop
# 运行
nvitopCPU、GPU的利用率、温度以及风扇情况监控
sudo apt install psensor
psensor &一些调试时的常用命令
docker命令
# 看日志(排错第一步)
docker logs -f --tail 200 <container># 实时刷新资源占用
docker stats --no-stream# 进入容器内部 bash
docker exec -it <container> bash# 一键看所有端口映射
docker ps --format "table {{.Names}}\t{{.Ports}}"# 把宿主文件拷进容器(临时打补丁)
docker cp ./my.patch <container>:/app/# 修改向量库密码
docker exec -it docker-es01-1 bash
bin/elasticsearch-reset-password -u elastic -iRAGFlow配置
# 1) 启动
docker compose -f docker-compose.yml up -d
# 2) 看各组件健康状态
docker compose ps
docker logs ragflow-server -f --tail 100 # 3) 确认向量库是否连上
curl -u elastic:infini_rag_flow -X GET localhost:1200/_cluster/health?prettyollama命令
# 看版本 / 升级
ollama --version
curl -fsSL https://ollama.ai/install.sh | sh # Linux 一键重装# 拉模型 & 立即跑交互
ollama pull llama3:8b
ollama run llama3:8b# 列出本地已有
ollama list
ollama ls # 简写# 看模型详细信息(参数、量化、上下文长度)
ollama show llama3:8b --modelfile# 验证 API 通不通
curl http://localhost:11434/api/tags
curl http://localhost:11434/api/generate -d '{"model":"llama3:8b","prompt":"hello"}'