京东测开面经整理(日常实习)
1.部门-零售
1.1自我介绍
1.2测试的生命周期分哪几个阶段?
(1)需求分析阶段
目的:理解被测系统的功能和需求
- 阅读、分析软件需求规格说明书
- 识别哪些部分需要测试,哪些不需要
- 查找需求中的歧义或不一致并提出疑问
- 确定测试类型(功能、性能、安全等)
最后输出成果《需求可测性分析报告》
(2)测试计划阶段
目的:制定整体测试策略和计划
- 明确测试范围、目标、方法和资源
- 分配测试人员、确定时间表
- 选择测试工具和环境
- 评估风险和应对策略
最后输出成果《测试计划书》
(3)测试用例设计阶段
目的:根据需求和计划编写详细的测试用例
- 编写测试用例、测试数据
- 评审测试用例以确保覆盖全面
- 建立需求与测试用例的对应关系
最后输出结果《测试用例文档》
(4)测试环境搭建阶段
目的:为测试准备合适的运行环境
- 搭建软硬件环境、部署应用系统
- 准备数据库、网络配置
- 验证环境可用性
输出成果《环境搭建验证报告》
(5)测试执行阶段
目的:实际运行测试用例,记录测试结果
- 执行测试用例,记录实际结果
- 对比预期结果,标记通过/失败
- 提交缺陷报告
- 回归测试
输出成果《测试执行记录》、《缺陷报告》
(6)测试结束阶段
目的:评估测试工作并归档
- 确认测试目标是否达成
- 汇总测试指标
- 编写《测试总结报告》
- 归档测试文档及数据
输出成果《测试总结报告》
“需——计——用——环——执——结”
1.3测试用例的设计方法
主要分为“黑盒测试方法”和“白盒测试方法”两大类
1.3.1黑盒测试方法
不关注程序内部结构,只关注输入和输出

1.3.2白盒测试方法
关注程序内部逻辑结构,通过代码路径设计测试

1.3.3灰盒测试方法
综合黑盒与白盒思想:测试者了解部分系统结构信息
常用于:Web接口测试(知道接口逻辑,但不看底层代码)、数据库一致性测试(了解数据结构和约束)、模块间接口测试(掌握输入输出结构)
1.4正向测试和负向测试
1.4.1正向测试
使用正确的、合法的输入数据去验证系统是否可以按照预期正常工作
目的是为了验证系统的功能是否能正常实现
举例:
- 用户名输入正确、密码正确——>登录成功
- 购物车功能:添加有效商品——>商品应成功加入购物车
- 输入年龄在1-120范围内——>系统应该正确保存
1.4.2负向测试
用错误、异常、非法或边界外的数据去测试系统,看系统是否可以正确处理错误并保持稳定
目的是为了验证系统的鲁棒性和错性
1.5场景题:京东商品的价格如何测试
针对京东商品价格测试,我会从五个维度考虑:
一是功能正确性,比如价格展示、结算金额和后台一致;
二是业务逻辑,比如不同用户等级、促销活动、地区差异价;
三是接口与数据库一致性,比如接口数据是否实时、精度是否正确;
四是性能并发,比如秒杀场景下价格显示是否延迟;
五是安全性,比如防止篡改或越权修改价格。
我会结合等价类、边界值和判定表等方法来设计具体测试用例。
1.6算法题
1.6.1 求数组中不重复元素的个数
算法思想:使用HashSet去重,因为HashSet是一种只有KEY没有具体value的哈希表
import java.util.*;
public class UniqueCount{public static void main (String args[]){int[]arr={1,2,2,3,4,5};Set<Integer>set=new Hash<>();for(int num:arr){set.add(num);}System.out.println(set,size());}
}一变:求数组中重复元素的个数
import java.util.*;public class DuplicateKinds {public static void main(String[] args) {int[] arr = {1, 2, 2, 3, 3, 3, 4};Map<Integer, Integer> map = new HashMap<>();for (int num : arr) {map.put(num, map.getOrDefault(num, 0) + 1);}int kinds = 0;for (int value : map.values()) {if (value > 1) kinds++;}System.out.println(kinds); // 输出 2}
}
二变:求数组中每个元素出现的次数
import java.util.*;public class CountElements {public static void main(String[] args) {int[] arr = {1, 2, 2, 3, 3, 3, 4};Map<Integer, Integer> map = new HashMap<>();for (int num : arr) {map.put(num, map.getOrDefault(num, 0) + 1);}for (Map.Entry<Integer, Integer> entry : map.entrySet()) {System.out.println(entry.getKey() + " 出现了 " + entry.getValue() + " 次");}}
}
1.6.2判断两个二叉树相等
class TreeNode{int val;TreeNode left;TreeNode right;TreeNode(int val){this.val=val;}//构造函数}public class SameTree {public boolean isSame(TreeNode p,TreeNode q){if(p==null&&q==null)return true;if(p==null||q==null)return false;if(p.val!=q.val)return false;return isSame(p.left,q.left)&&isSame(p.right,q.right);}public static void main (String[] args){SameTree st=new SameTree();TreeNode p=new TreeNode(1);p.left=new TreeNode(2);p.right=new TreeNode(3);TreeNode q=new TreeNode(1);q.left=new TreeNode(2);q.right=new TreeNode(3);System.out.println(st.isSame(p,q));}}
2.部门-工业(日常实习)
2.1谈谈对测开的认识
首先,我理解的测试开发是结合测试思维和开发能力,通过代码和自动化的手段去提升测试效率进而保障软件的质量
其次,相比较传统测试侧重于关注功能的正确性,测试开发则更加偏向于工程化,会参与到自动化测试框架的搭建和自动化测试脚本的开发。比如我在上一段实习中使用到了基于pytest自动化测试框架的脚本进行自动化压测,这个过程就是用技术手段来验证软件的稳定性和健壮性,大大节约了人力资源
最后我认为测试开发的核心是:用开发的思维去提升测试效率,用测试的思维来保障软件的质量
2.2测试的生命周期(已有)
2.3实习过程中遇到最具有挑战性的难点、解决思路、收获
2.4如何优化自动化脚本
第一是结构优化,把用例分开写,方便维护
第二是提高稳定性,加入等待时间
第三是提高效率,并行执行
2.5业务需求一直在迭代,如何提升测试脚本更改的效率
我把易变内容从脚本里抽出去(数据/配置/选择器集中),在中间加一层稳定的业务封装,用契约校验抗接口小改,再配合 OpenAPI 生成、标签选择集和 CI 冒烟回归。这样需求迭代时,多数情况下只改数据或封装层,用例基本不用动,改得少、跑得快、风险可控
2.6写测试脚本有什么提高效率的方法吗
2.7用大模型生成过测试用例吗
有的。在实习中尝试使用大语言模型(比如 ChatGPT)来辅助生成测试用例。
我会先把接口文档或函数描述提供给模型,让它帮我生成初步的 pytest 测试脚本和断言模板,再根据实际业务逻辑做修改和补充。
这样能明显提高编写测试用例的效率,大概能节省 40% 左右的时间。
不过生成的用例我都会人工复查,因为模型有时会忽略边界条件或写错断言。
2.8面对开发不认可的bug如何处理
首先会排查是否由于自己的操作失误导致的问题,其次查看需求规格说明书和接口文档,确保该功能是在需求里提出的并且按照接口文档去测试的,然后复现问题记录问题,保存日志记录,最后拉会(开发和产品)一起讨论问题该如何处理
2.9测试报告包含哪些内容
所测系统的版本号,测试日期,测试人,测试用例名称,测试步骤,预期结果,测试结果
2.10测试用例执行情况包含哪些维度
1.执行数量维度:总的用例条数,已执行和未执行的个数
2.结果维度:成功和失败,NA(需求规格书里没有提到该功能需实现,开发没有进行该功能的实现导致的失败)
3.模块维度:不同功能模块执行的情况
4.阶段维度:冒烟测试、回归测试等阶段
5.人员维度:每个测试人员的执行进度和通过率
6.时间维度:每日/周测试的进度
2.11回归测试的作用
验证修改后的代码没有影响到系统原有功能,确保修复 bug 或新增功能不会引入新的缺陷
3.一面+二面
3.1数据结构
3.1.1数组和链表的区别,分别适用于什么场景
数组和链表的主要区别在于存储方式和访问效率不同
数组在内存中是连续存储,支持复杂度为O(1)的随机访问,但是插入和删除的代价高
链表是通过指针连接的离散的节点,插入删除效率高,但是随机访问慢,需要O(n)
因此数组适合频繁查找、固定长度的场景
链表适合频繁插入、删除或数据量动态变化的场景
3.1.2处理哈希地址冲突的方法
分离链接和开放寻址。分离链接在每个桶放链表/树,删除简单、对高负载更稳;开放寻址把元素放表内,用线性/二次/双重散列等探查,缓存友好但对装载因子敏感、删除需墓碑。进阶方法有 Robin Hood(均衡探查距离、查找更稳)和 Cuckoo(查询常数小、插入可能搬移)。具体选型看负载因子、删除频率、查询延迟、内存局部性和是否并发。
3.2计算机网络
3.2.1http和tcp在TCP/IP模型的哪一层
IP在网络层,TCP/UDP在传输层,HTTP在应用层
3.2.2HTTP状态码,http和https的区别,https的加密过程
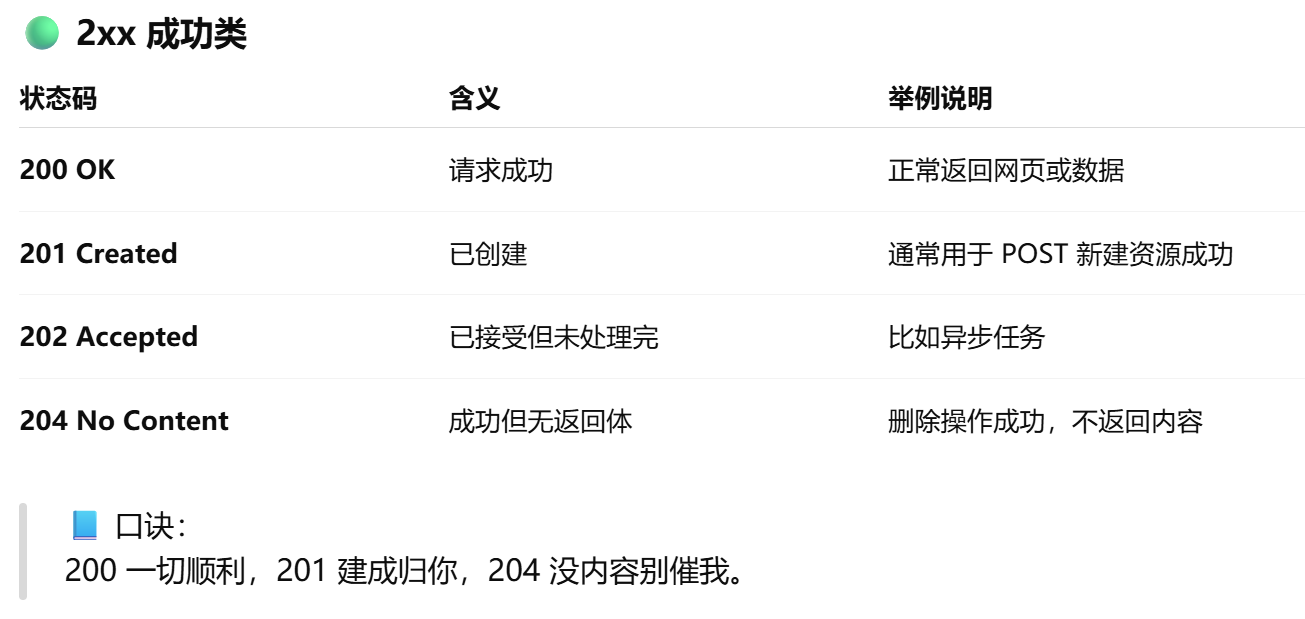
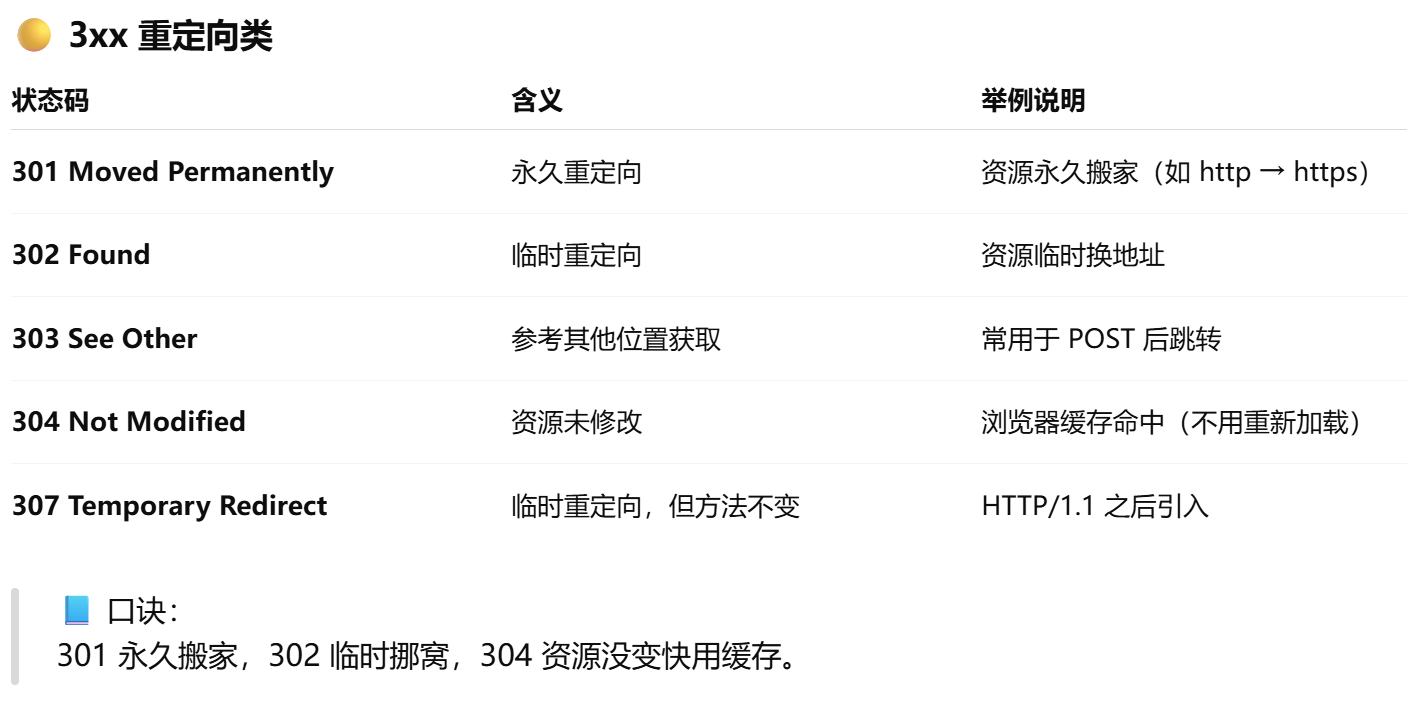
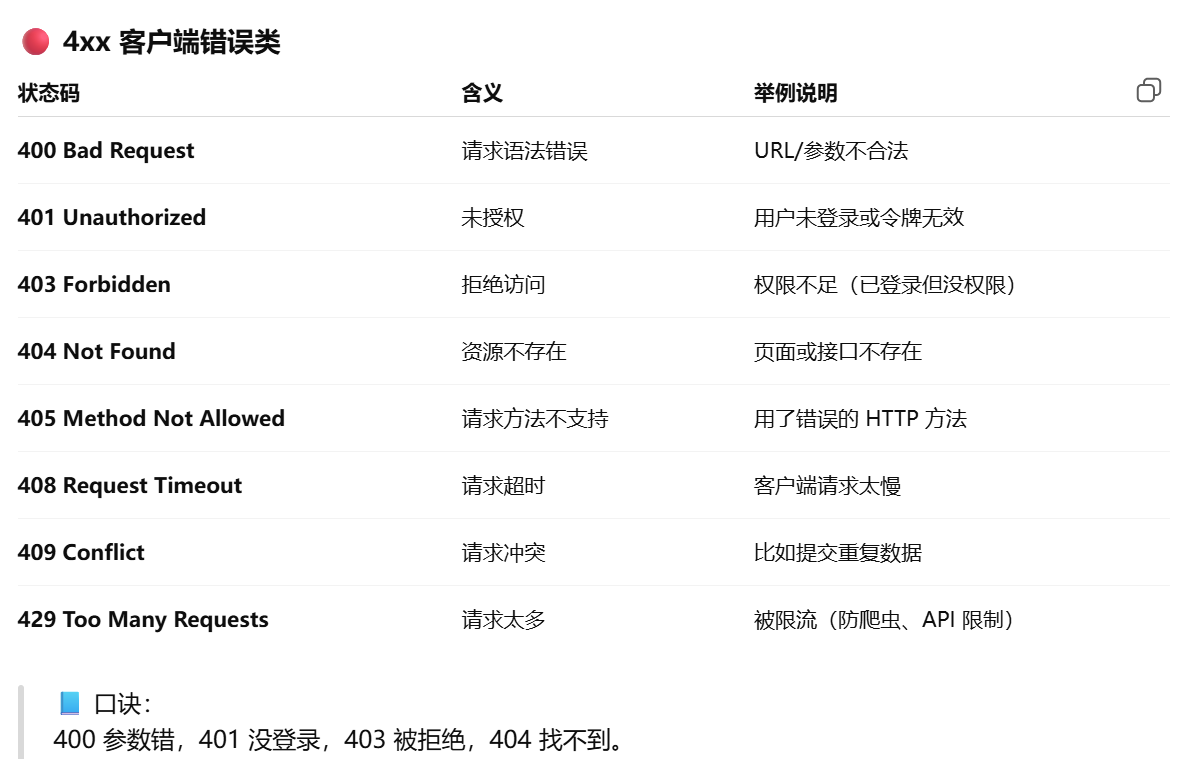
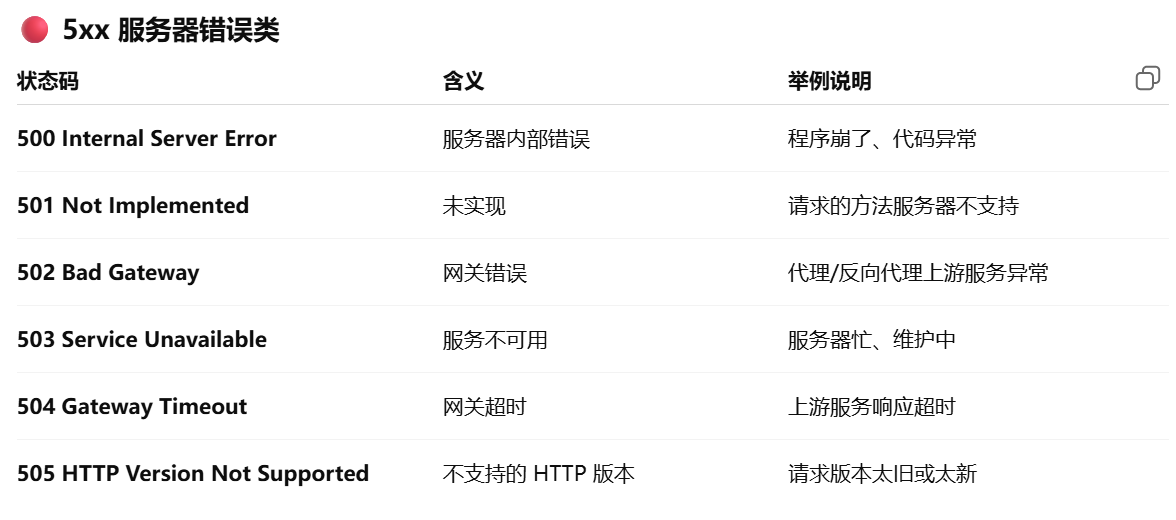
安全性:HTTP 是明文传输的超文本协议,数据容易被窃听或篡改;
HTTPS 在 HTTP 的基础上加入了 SSL/TLS 加密层,通过 加密、校验、身份认证 来保证数据传输的机密性与完整性;
端口:Http默认80端口,https默认使用 443 端口,
证书:http不需要SSL证书,https需要使用SSL证书来对服务器进行身份验证
URL:http是以http://开头,https是以https://开头
性能:http由于数据传输过程中没有加密过程,相对来说性能较好,https由于数据传输过程中需要加密解密过程,性能稍微降低一点
3.2.3TCP的三次握手的过程
由客户端向服务器端发送请求SYN,服务器端收到请求后给出响应SYN+ACK,客户端收到来自服务器端给的响应发送ACK
3.2.4浏览器的跨域访问,跨域限制,原因
什么是跨域访问?当浏览器从一个源去请求另一个源的资源时就发生了跨域
一个源由三部分组成:协议+域名+端口,只要其中任意一项不同,就算跨域
跨域限制是由浏览器的同源策略引起的,为了保护用户数据安全,放置被恶意网站读取或操作其他网站的敏感数据
比如:如果没有同源策略,用户登录了银行网站,然后访问其他恶意网站,那么恶意网站的JS就可以直接读取银行网站的cookie和账户信息
同源策略是浏览器最重要的安全机制之一
跨域限制被限制的主要是JS发起的跨域请求和数据读取
3.3操作系统
3.3.1进程和线程的区别
进程:是程序在操作系统中的一次运行实例,拥有独立的内存空间和系统资源
线程:是进程内的一个执行单元,是操作系统能调度的最小单位,同一进程的多个线程共享该进程的资源
3.3.2死锁产生的条件,如何避免,具体的做法
死锁是两个或多个进程在执行过程中,因竞争资源或互相等待的过程中,导致程序永久阻塞无法继续执行的现象
产生条件:互斥、循环等待、占有并等待、不可剥夺,只有这四个条件都满足的时候死锁才能产生,破坏其中一条,死锁就可解除
比如:
统一加锁顺序(破坏循环等待)
一次性申请所有资源(破坏占有并等待)
加锁超时机制(破坏不可剥夺)
使用可重入锁或读写锁(破坏互斥)
3.4数据库
3.4.1索引的作用和优缺点
索引是数据库中一种用于加速数据检索的数据结构,常见实现是 B+ 树。
它的作用是减少磁盘 I/O,提高查询、排序、分组、关联查询的性能。
优点包括:
查询速度快、排序效率高、JOIN 性能好、能保证唯一性。
缺点包括:
占用存储空间、插入/更新/删除性能下降、维护成本高。
3.4.2Where和Having的区别
WHERE 是在分组前对原始数据行进行过滤,不能使用聚合函数;
HAVING 是在分组后对分组结果进行过滤,可以使用聚合函数。
4.场景题:针对添加购物车设计测试用例
我会先明确测试目标:验证“添加购物车”功能在不同商品类型、用户状态、库存条件下是否能正确执行,确保数据一致、提示准确、体验正常。
从测试维度上,我会分为六类:
① 功能用例:
正常添加单个商品
多规格商品选择正确后加入
同商品多次添加数量累加
限购/无库存商品无法加入
② 边界用例:
数量 = 0、负数、超过库存、超过最大限购
商品刚好售罄或下架
③ 异常用例:
用户未登录
接口参数缺失或非法
网络异常、服务异常重试逻辑
④ 性能并发:
并发加购同一 SKU 时数据一致性
高峰期响应时间(如 <300ms)
⑤ 安全性:
越权加购(修改 userId)
篡改商品价格、库存参数
⑥ 用户体验:
成功提示 toast、购物车角标变化
错误提示文案是否清晰
举个例子,比如:
用例1:库存10件,用户加购数量11 → 提示“库存不足”。
用例2:同一商品重复点击“加入购物车” → 数量正确累加,未重复创建行项。
最后,我会补充接口层验证(响应码、错误码、幂等性)和数据库层校验(数量更新、日志记录)。
这样的设计能保证从功能到异常、从性能到安全全覆盖,也体现系统化测试思维。
口诀:“功边异性安体层”
功能、边界、异常、性能、安全、体验、层次验证(接口+数据层)
5.算法题
5.1判断字符串是否为有效IPV4地址
public class IPValidator {public static String validIPAddress(String queryIP) {if (isValidIPv4(queryIP)) return "IPv4";if (isValidIPv6(queryIP)) return "IPv6";return "Neither";}// ===== IPv4: A.B.C.D,4 段,0~255,无前导零 =====private static boolean isValidIPv4(String s) {String[] parts = s.split("\\.", -1); // -1 保留空段if (parts.length != 4) return false;for (String p : parts) {// 非空、长度 1~3、全数字if (p.length() == 0 || p.length() > 3) return false;for (char c : p.toCharArray()) if (!Character.isDigit(c)) return false;// 前导零规则if (p.length() > 1 && p.charAt(0) == '0') return false;// 数值范围int val;try { val = Integer.parseInt(p); } catch (NumberFormatException e) { return false; }if (val < 0 || val > 255) return false;}return true;}// ===== IPv6: 8 组,1~4 位十六进制,不允许压缩“::” =====private static boolean isValidIPv6(String s) {String[] parts = s.split(":", -1); // -1 保留空组if (parts.length != 8) return false;for (String p : parts) {if (p.length() == 0 || p.length() > 4) return false;for (char c : p.toCharArray()) {boolean hex = (c >= '0' && c <= '9') ||(c >= 'a' && c <= 'f') ||(c >= 'A' && c <= 'F');if (!hex) return false;}}return true;}// demopublic static void main(String[] args) {System.out.println(validIPAddress("172.16.254.1")); // IPv4System.out.println(validIPAddress("256.256.256.256")); // NeitherSystem.out.println(validIPAddress("2001:0db8:85a3:0:0:8A2E:0370:7334")); // IPv6System.out.println(validIPAddress("2001:db8:85a3::8A2E:0370:7334")); // Neither(严格模式)}
}
5.2字符串中第一个不重复的字母
//[a,a,b,b,b,c,d,e]
//思路1:引入第二个整数数组用来存放字符串中每个字符出现的次数,然后遍历第二个数组输出第一个为1的
public class StringNotSame {public static void main(String[] args) {String s="aabbcde";char[]arr=s.toCharArray();//arr[]={a,a,b,b,b,c,d,e}int [] b=new int[26];for (int i = 0; i < arr.length; i++) {b[arr[i] - 'a']++;}for (int i = 0; i < arr.length; i++) {if (b[arr[i] - 'a'] == 1) {System.out.println(arr[i]);break;//如果要求找出字符串中所有不重复的字母就不用加break,当然如果//找出所有不重复的字符可以使用哈希表}}}
}