nlp进阶
1 Rnn
RNN(Recurrent Neural Network),中文称作循环神经网络,它一般以序列数据为输入,通过网络内部的结构段计有效捕捉序列之间的关系特征,一般也是以序列形式进行输出.
单层网络结构 在循环


rnn处理的过程


rnn类别
n - n
n - 1 使用sigmoid 或者softmax处理 应用在分类中
1- n x作用于每一个输入 图片生成文字
n - M 
2传统rnn
内部结构


优缺点 :
计算资源的要求低,短序列表现优异.
缺点 长序列的关联时表现很差,在反向传播时候 梯度消失或者爆炸
2 lstm
能够有效捕捉长序列之间的语义关联,缓解梯度消失或爆炸现象.同时LSTM的结构更复杂,它的核心结构可以分为四个部分去解析: 输入门 遗忘门 输出们 细胞状态 .
遗忘门 代表遗忘过去的多少信息sigmiod




2.1 BI -LSTM

import torch.nn as nn
import torch
lstm = nn.LSTM(input_size=6, hidden_size=8, num_layers=2)
输入的词数量 每次处理样本的数量 维度
input = torch.randn(2,3,6)
# 层数 处理样本数 维度
h0 = torch.randn(2,3,8)
c0 = torch.randn(2,3,8)
output,(h1,c1) = lstm(input,(h0,c0))
print(output,h1,c1)
input 和 h0 的批量大小(batch_size)必须相同。
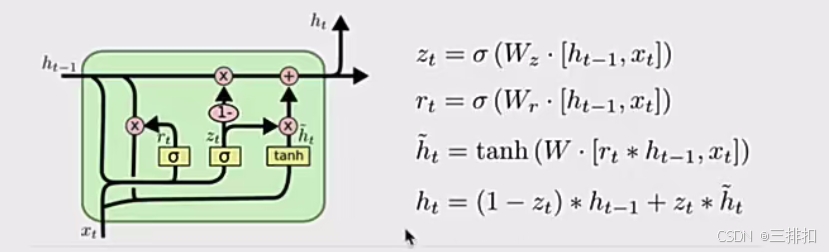
3GRU 门控循环单元
GRU(Gated Recurrent Unit)也称门控循环单元结构,它也是传统RNN的变体,
优点: 同LSTM一样能够有效捕捉长序列之间的语义关联,缓解梯度消失或爆炸现象,同时它的结构和计算要比LSTM更简单,它的核心结构可以分为两个部分去解析:
。更新门z
。重置门 r
缺点 : 与rnn相同不能并行计算
import torch.nn as nn
import torch
gru = nn.GRU(5,8,1)
input = torch.randn(2,5,5)
h1= torch.randn(1,5,8)
output,h0 = gru(input,h1)4注意力机制
注意力:在判断一个问题时,我们直接将注意力去放在具有辨识度的部分上面进行判断,不是全部都看一遍.
注意力机制:指的是用注意力计算规则应用于深度学习网络载体.
在nlp种 注意力机制大多应用与seq2seq(编码器解码器模型)
q k v 计算的三步
query 和 key 进行相似度计算,得到一个query 和 key 相关性的分值将
这个分值进行归一化(softmax),得到一个注意力的分布使用注意力分布
value 进行计算,得到一个融合注意力的更好的 value 值