进程控制(创建、终止)
一、进程创建
1.1 fork函数初识
在linux中 fork 函数是非常重要的函数,它从已存在进程中创建一个新进程 。 新进程为子进程,而原进程为父进程!!!
想象一下,如果你有一项繁重的工作,自己一个人忙不过来,这时你可以施展 “分身术”,创造出一个和自己一模一样的分身来帮你干活。在 Linux 中,fork函数就拥有这样的 “分身术”,它能从已存在的进程(父进程)中创建一个新进程(子进程)。


当进程调用fork后,内核会完成一系列关键操作:
- 为子进程分配新的内存块和内核数据结构。就像给分身准备一个独立的工作空间和身份档案。
- 将父进程部分数据结构内容拷贝到子进程。让分身拥有和自己相似的初始状态,比如相同的代码和数据。
- 把子进程添加到系统进程列表中。让操作系统知道这个新 “工人” 的存在,以便进行调度。
- 之后,
fork函数返回,父子进程就会被调度器调度,开始各自的 “工作”。
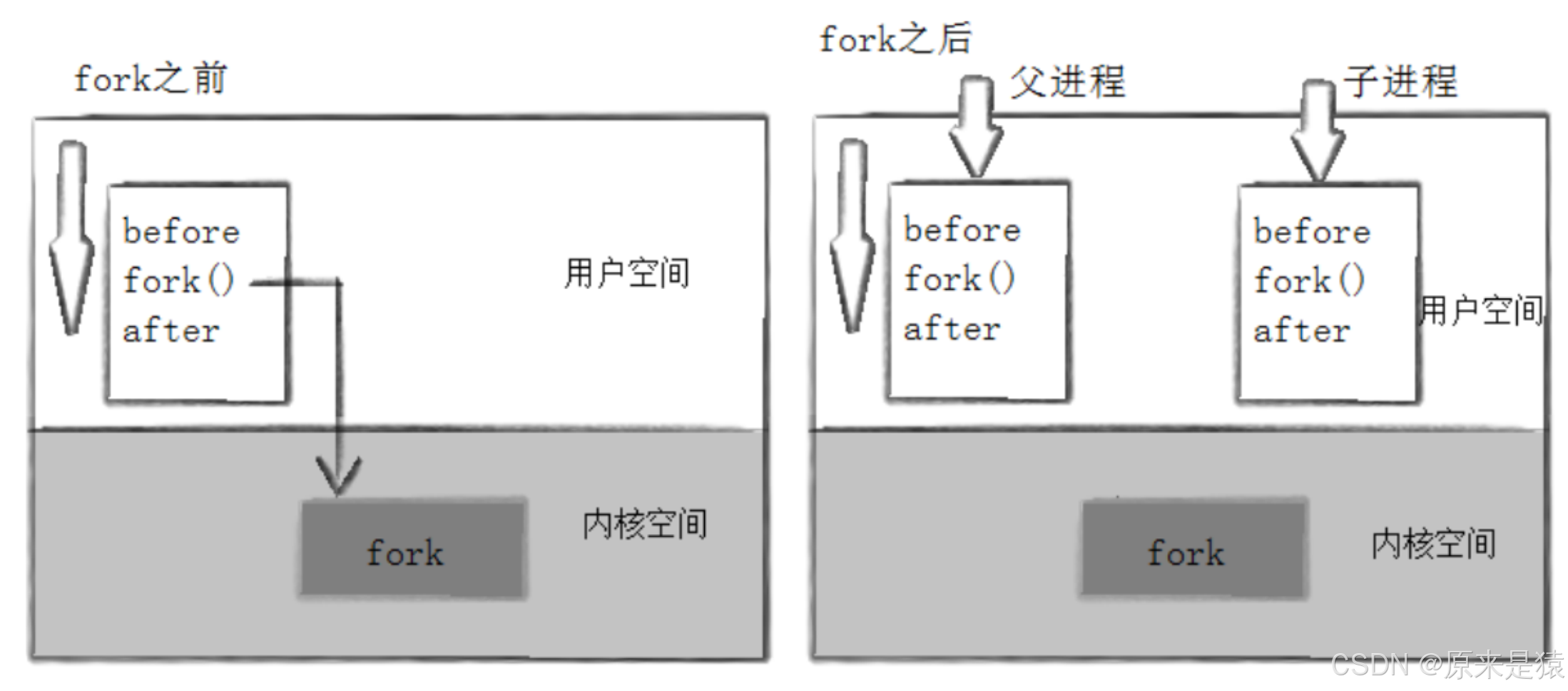
当一个进程调用fork之后 , 就有两个二进制代码相同的进程。而且它们都运行到相同的地方。但每个进程都将开始开始它们自己的进程, 看如下程序:
#include <stdio.h>
#include <unistd.h>
#include <stdlib.h>int main(void)
{pid_t pid;printf("Before: pid is %d\n", getpid());if ((pid = fork()) == -1) {perror("fork()");exit(1);}printf("After: pid is %d, fork return %d\n", getpid(), pid);sleep(1);return 0;
}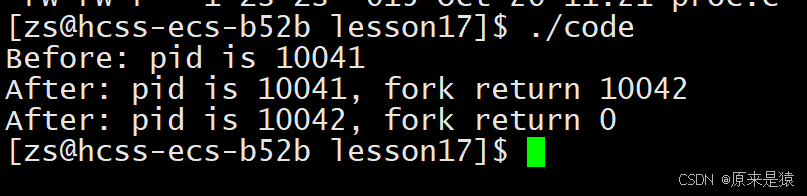
可以看到,“Before” 只打印了一次,而 “After” 打印了两次。这是因为在
fork调用之前,只有父进程在执行,所以 “Before” 只输出一次;fork调用之后,父进程和子进程各自独立执行,所以 “After” 会分别在两个进程中输出。而且,父进程中fork返回的是子进程的 ID(10042),子进程中fork返回的是 0。
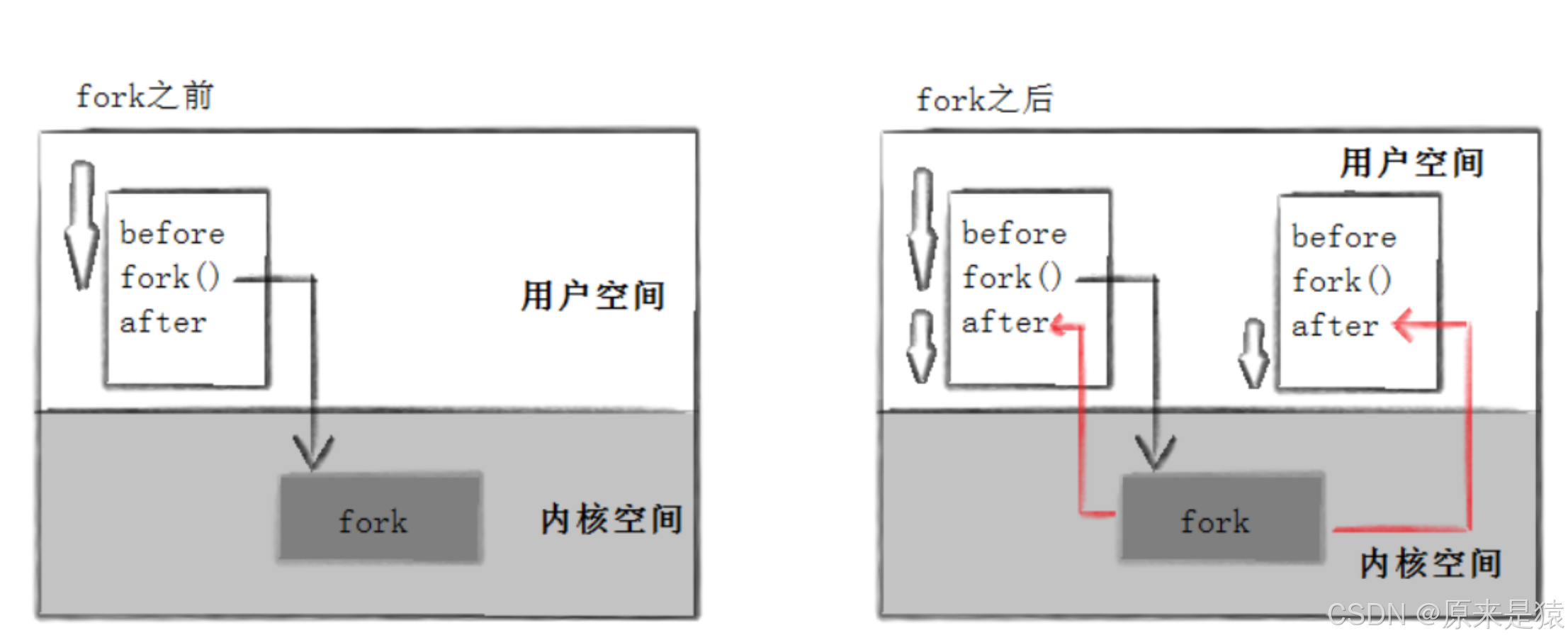
需要注意的是,fork之后, 父进程和子进程谁先执行, 完全由操作系统的调度器决定,我们无法预知。
1.2 fork函数返回值

1.3 写时拷贝
你可能会好奇,fork创建子进程时,会把父进程的数据都拷贝一份,那如果父子进程都不修改这些数据,岂不是浪费了内存空间?Linux 系统采用了 “写时拷贝”(Copy-On-Write)技术来解决这个问题。
通常 , 父子代码共享 , 父子再不写入时 , 数据也是共享的 , 当任意一方试图写入 , 便以写时拷贝的方式各自一份副本 , 具体见下图:
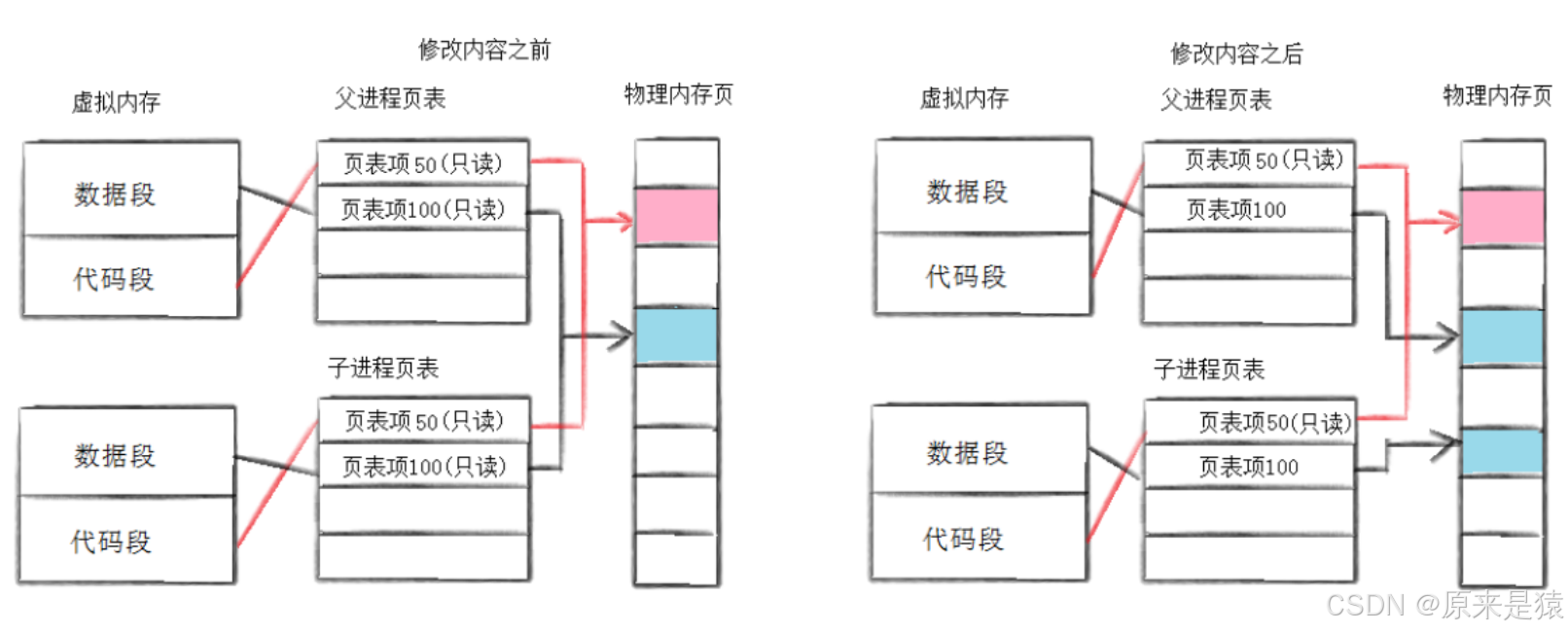
简单来说,在fork创建子进程后,父子进程的代码段和数据段在物理内存中是共享的,它们的页表项都指向相同的物理内存页,并且这些页表项被标记为 只读 。当任意一方试图修改数据时,CPU 会触发一个页错误(Page Fault),这时内核会为修改方拷贝一份新的物理内存页,并更新其页表项,使其指向新的物理内存页。这样一来,只有在真正需要修改数据时才进行拷贝,大大提高了内存的利用率。

就好比你和你的分身共用一份文件,平时你们都只是阅读文件内容,不需要各自拥有一份副本;只有当其中一人想要修改文件时,才会复制一份新的文件进行修改,避免影响到对方。


因为有写时拷贝技术的存在 , 所以父子进程得以彻彻底底分离!!!完成了进程独立性和技术保证!!!写时拷贝,是一种延时申请技术 , 可以提高整机内存的使用率!!!
1.4 fork的常规用法
1. 父进程希望复制自己,让父子进程同时执行不同的代码段。比如,在服务器程序中,父进程负责监听客户端的连接请求,当有新的请求到来时,就创建一个子进程来处理这个请求,父进程则继续监听后续的请求。

2. 一个进程要执行一个全新的程序。这时,子进程在fork返回后,会调用exec系列函数来替换自己的代码和数据,执行新的程序。
1.5 fork 调用失败的原因
1. 系统中已经存在太多的进程,没有足够的资源来创建新的进程。
2. 实际用户的进程数超过了系统规定的限制。

二、进程终止
进程终止的本质 是 释放系统资源 , 就是释放进程申请的相关内核数据结构 和 对应的数据和代码 ~

2.1 进程退出场景
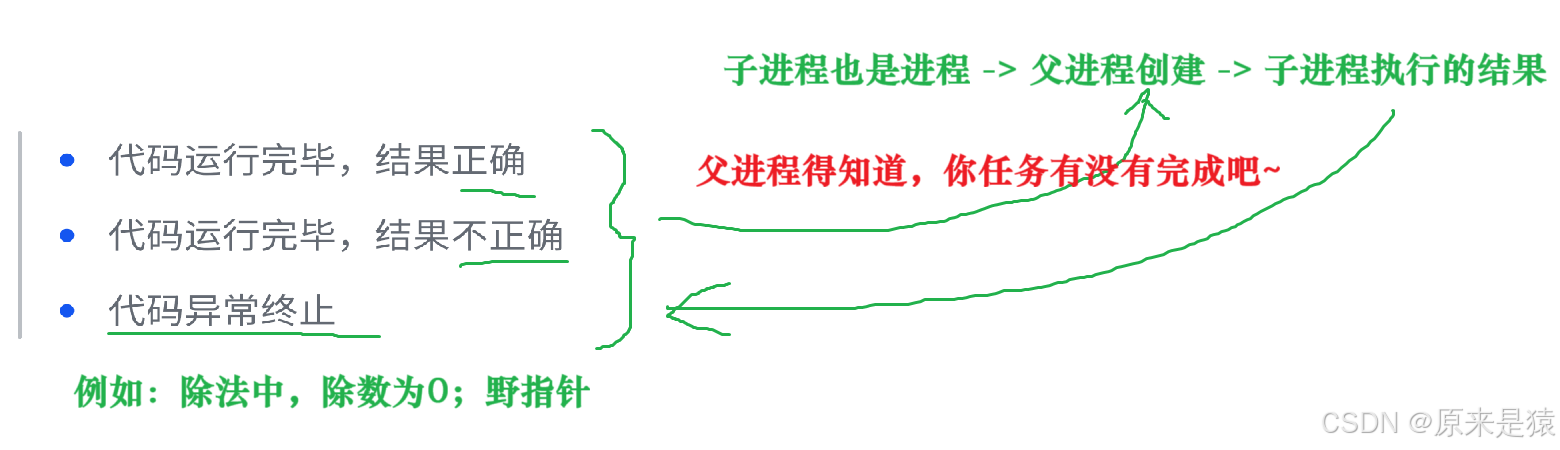
进程退出主要有三种场景:
- 代码运行完毕,结果正确。这是最理想的退出场景,就像 “工人” 高质量地完成了任务。
- 代码运行完毕,结果不正确。比如程序计算出的结果不符合预期,这可能是由于程序逻辑错误导致的。
- 代码异常终止。比如程序运行过程中遇到了除以零、访问非法内存等错误,或者收到了终止信号(如
Ctrl + C)。
2.2 进程常见退出方法
根据进程退出的场景不同,退出方法也有所区别,主要分为正常终止和异常终止两类。
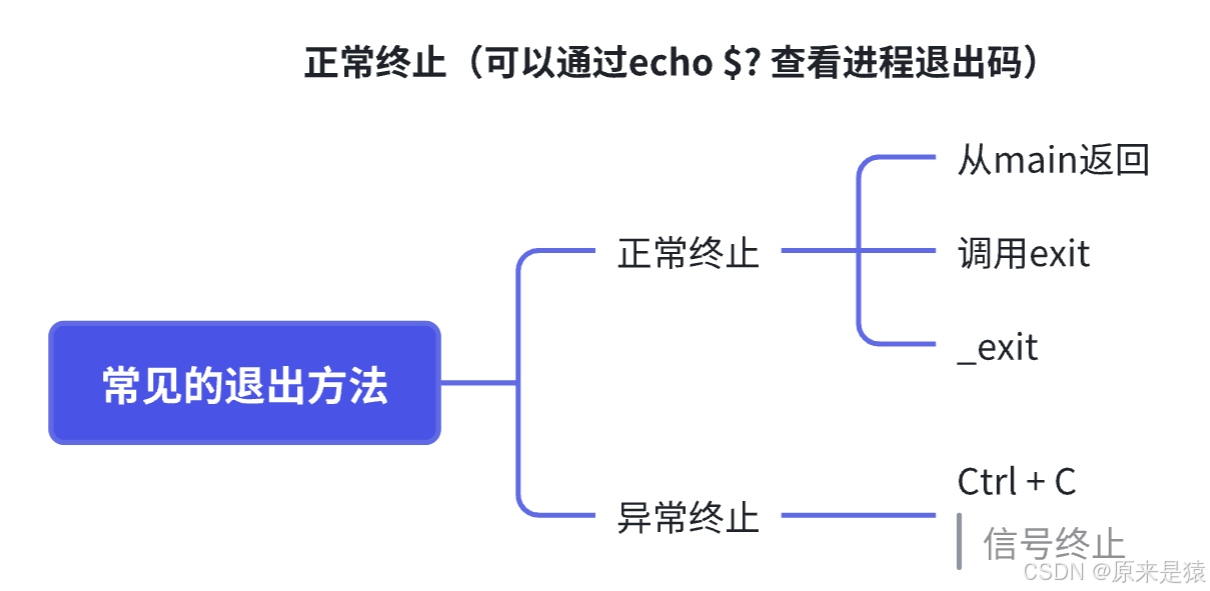
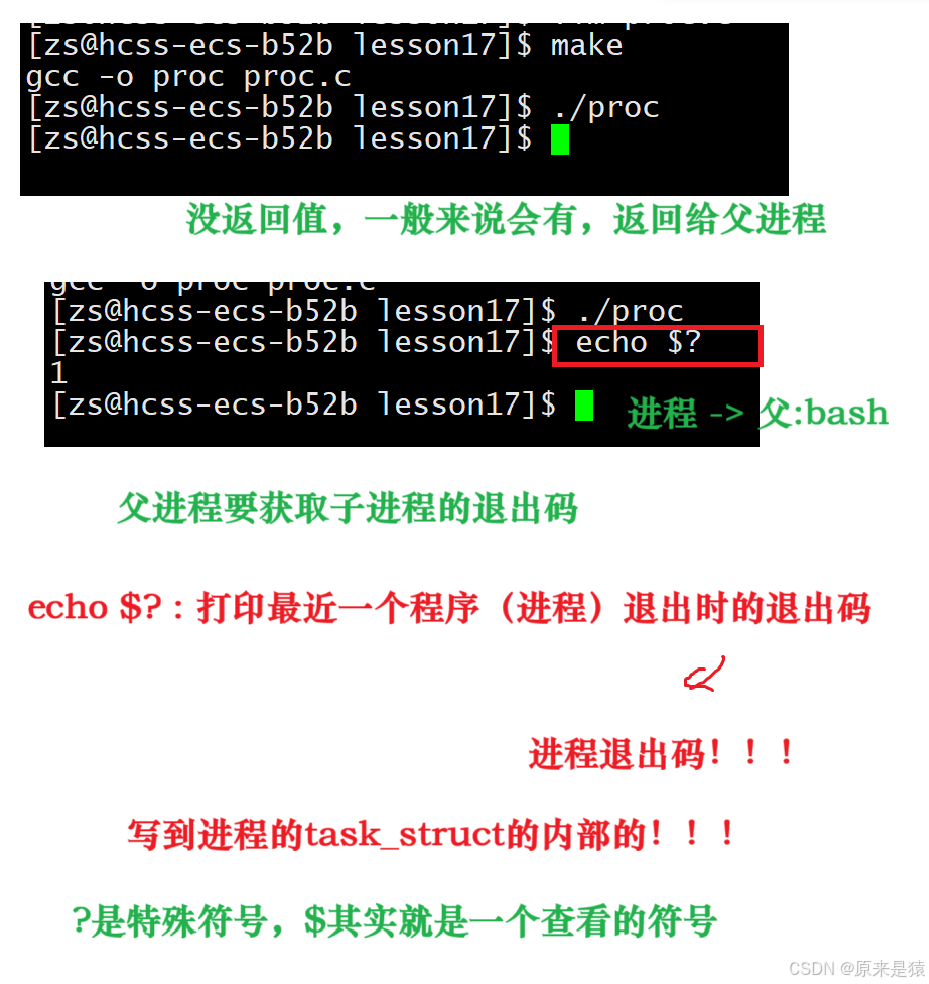
1)main函数中返回 : main函数的返回值就是进程的退出码,比如return 0表示进程正常退出,return 1表示进程异常退出。

为什么代码运行完毕 , 结果不正确 ,为什么返回非 0 ,而正确为什么是0 ?

整数类型函数不写返回值 , 系统默认返回 0
在C语言中 , 如果一个返回值类型为整数 (比如 int )的函数 , 在函数体末尾没有写return 语句 , 编译器会默认让它返回 0


函数内部的变量(比如局部变量)是 “临时” 的 —— 函数执行结束后,这些变量会被销毁,内存会被回收。那return是怎么把值 “传出去” 的呢?
这是因为函数的返回值会被暂存到 CPU 的「寄存器」中(可以理解为 CPU 内部的 “临时小内存”)。当函数执行完
return 数值后,这个数值会被放到寄存器里;函数退出后,调用方再从寄存器中把数值取出来,赋值给外部变量。

“mov语句” 是汇编层面的指令,意思是 “把数值从一个地方移动到另一个地方”。比如函数b()执行return 1,汇编指令会是 mov eax, 1(把1放到eax寄存器里);当a()调用b()后,会执行 mov 0x123, eax(把eax里的1移动到a()里的变量0x123对应的内存中).
2)调用exit函数。exit函数会先执行用户通过atexit或on_exit函数注册的清理函数,然后关闭所有打开的文件流,将缓存数据写入文件,最后调用_exit函数终止进程。它的定义如下:
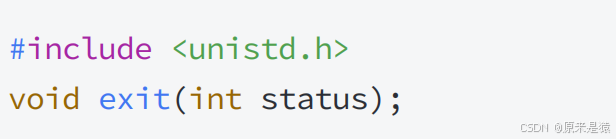
其中,status是进程的退出码。
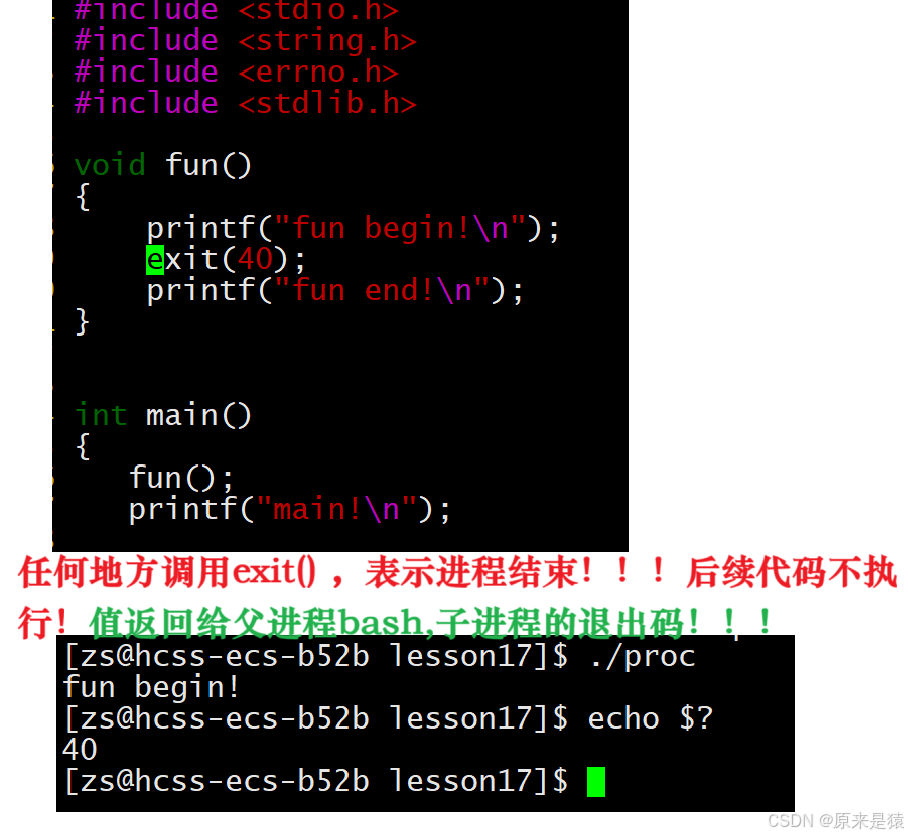
案例解释:深刻理解exit()结束进程的含义!
3)调用_exit()函数:

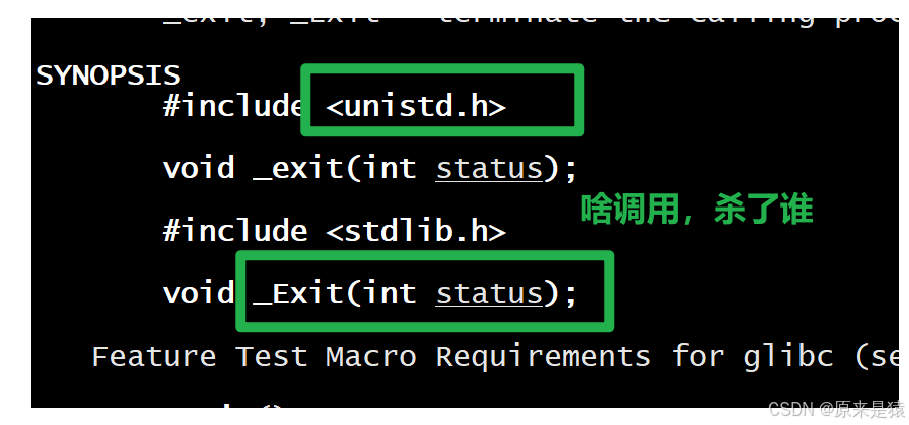
需要注意的是,虽然status是int类型,但只有低 8 位会被父进程通过wait函数获取。所以,如果_exit(-1),在终端执行echo $?会得到 255(因为 - 1 的低 8 位二进制是 11111111,对应的十进制是 255)
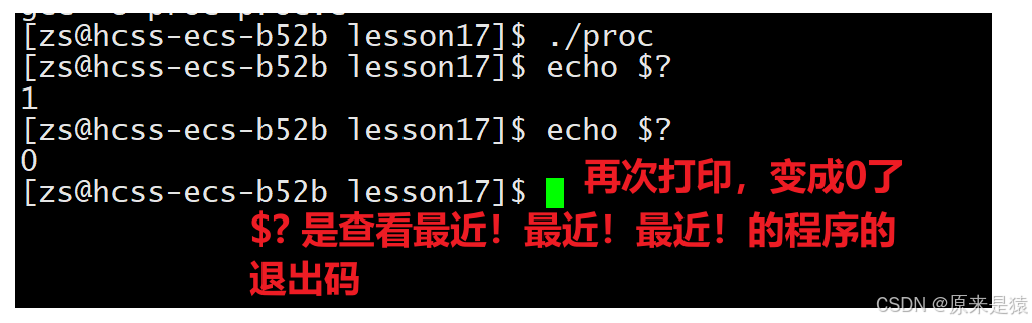
2.3 echo $?
2.4 exit() VS _exit()
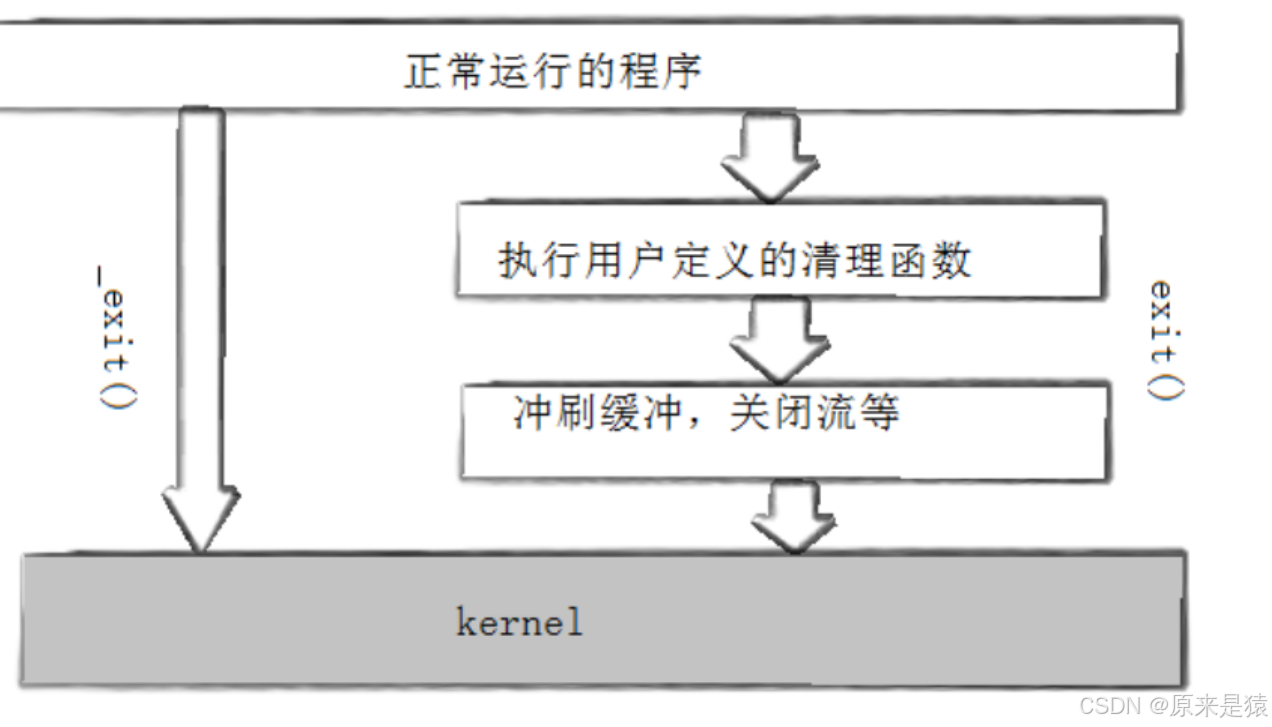
printf字符串,刷新缓冲区,休眠2秒,进程退出
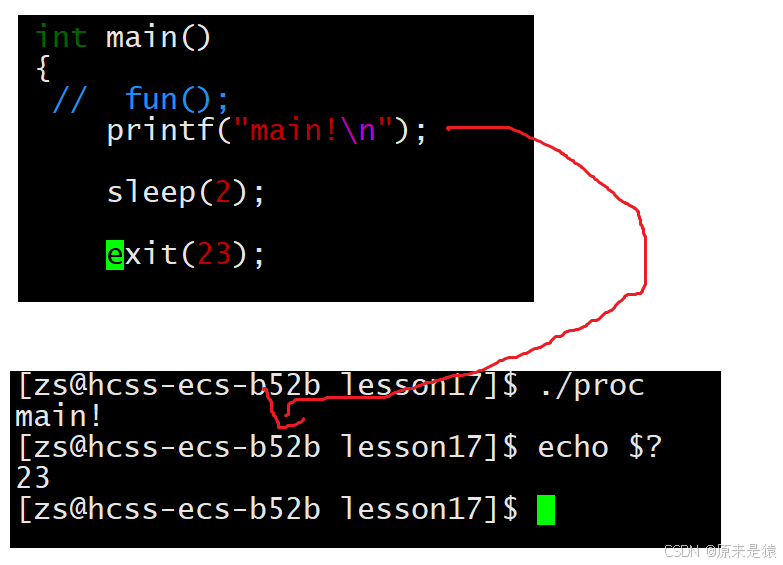
printf字符串 , 但是没有\n去刷新缓冲区 , 休眠 2 秒,等到exit执行的时候,刷新缓冲区
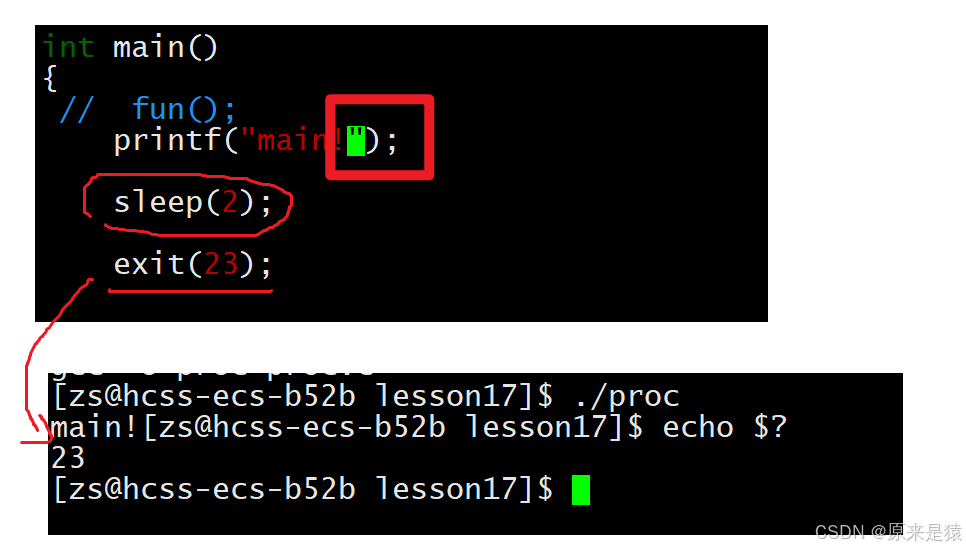
printf字符串,换行符刷新缓冲区 , 休眠2秒 , _exit() 退出进程
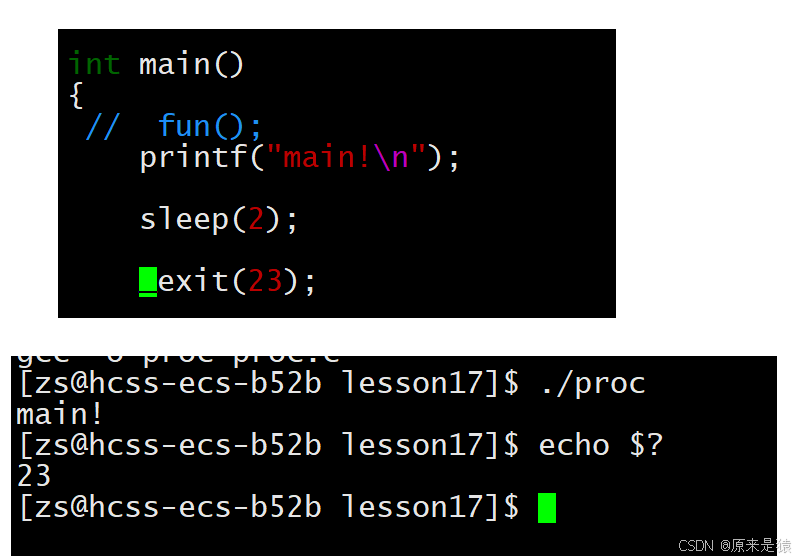
printf字符串,无换行符,字符串在缓冲区,休眠2秒 , _exit()退出进程,但是不会刷新缓冲区!!!
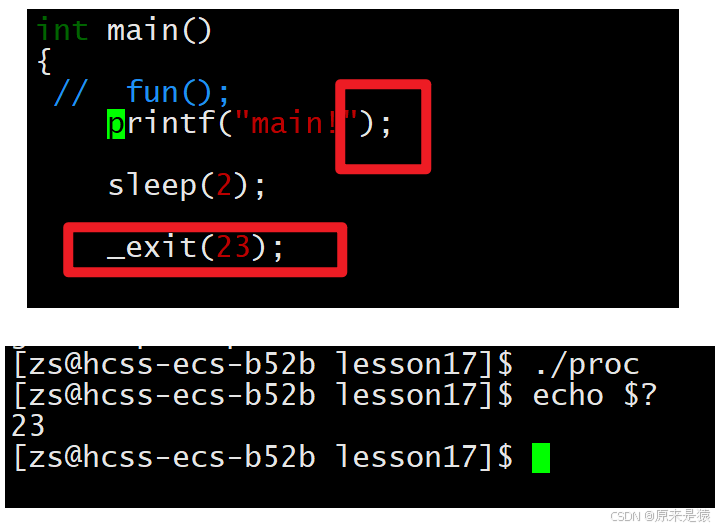
库函数和系统调用其实是上下层的关系(语言上看起来是调用了exit()这个库函数,其实底层有用到_exit()函数,因为这个世界上能真正杀死进程的,就只能有bash!!! 所哟exit()函数内部必然包含了_exit()!!!!)

那么缓冲区在哪里?

所以我们之前谈论的缓冲区一定不在系统层上,而是在库级别的缓冲区(C语言提供的)!!!
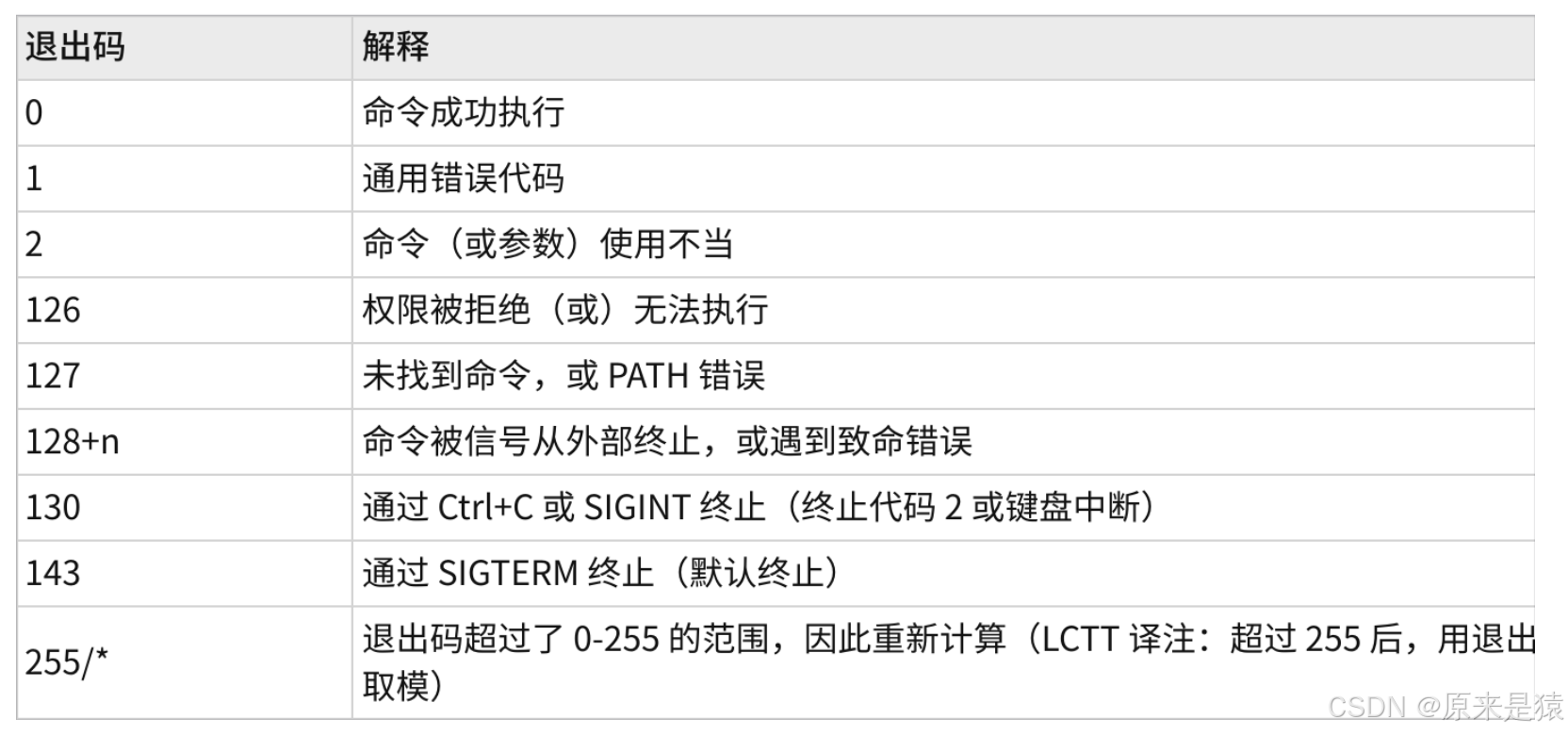
2.6 退出码
退出码就像是进程的 “工作报告”,它可以告诉我们进程的执行状态。在 Linux 系统中,退出码的取值范围是 0-255,其中:
- 0 表示命令成功执行。
- 1 或其他非 0 值表示命令执行失败,不同的非 0 值代表不同的错误类型。
下面是一些常见的 Linux Shell 退出码及其含义:
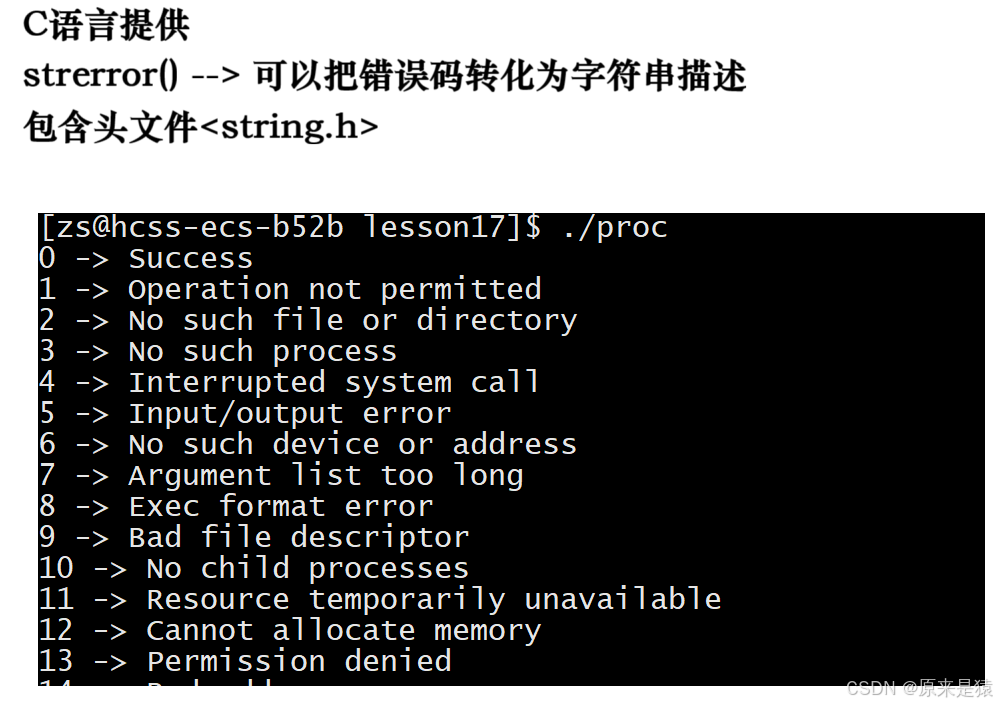
相关代码:
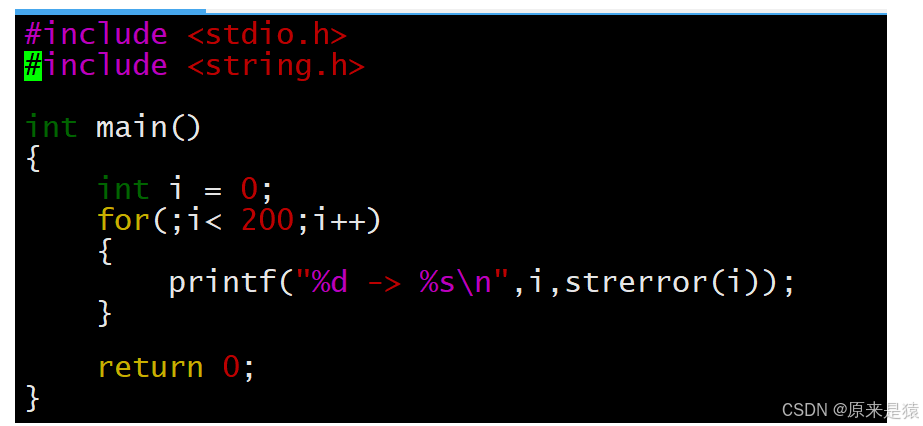
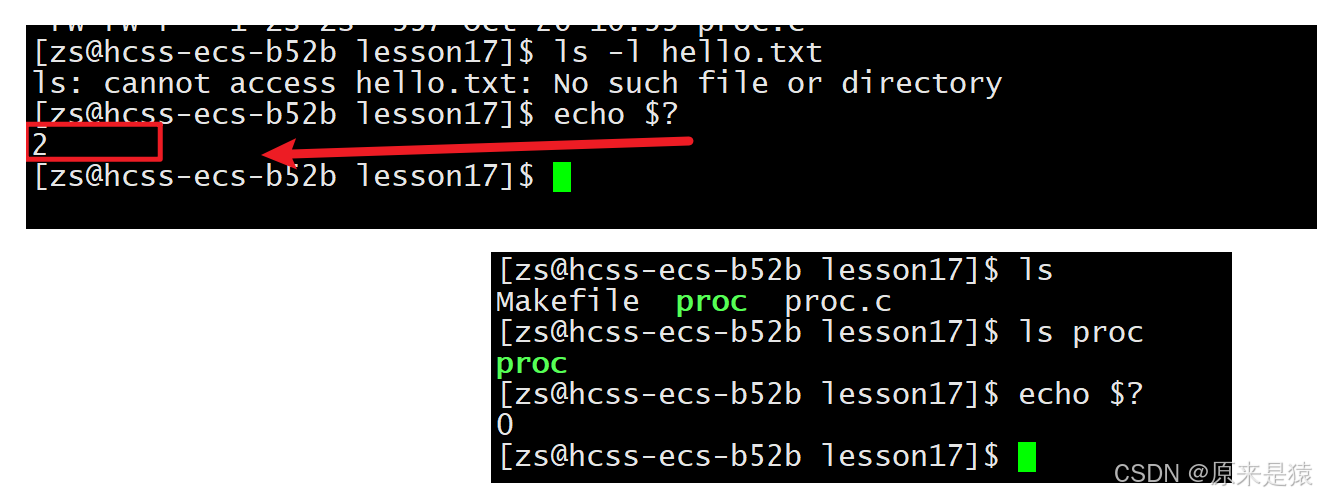
同时我们也可以自己来定制一下退出码~
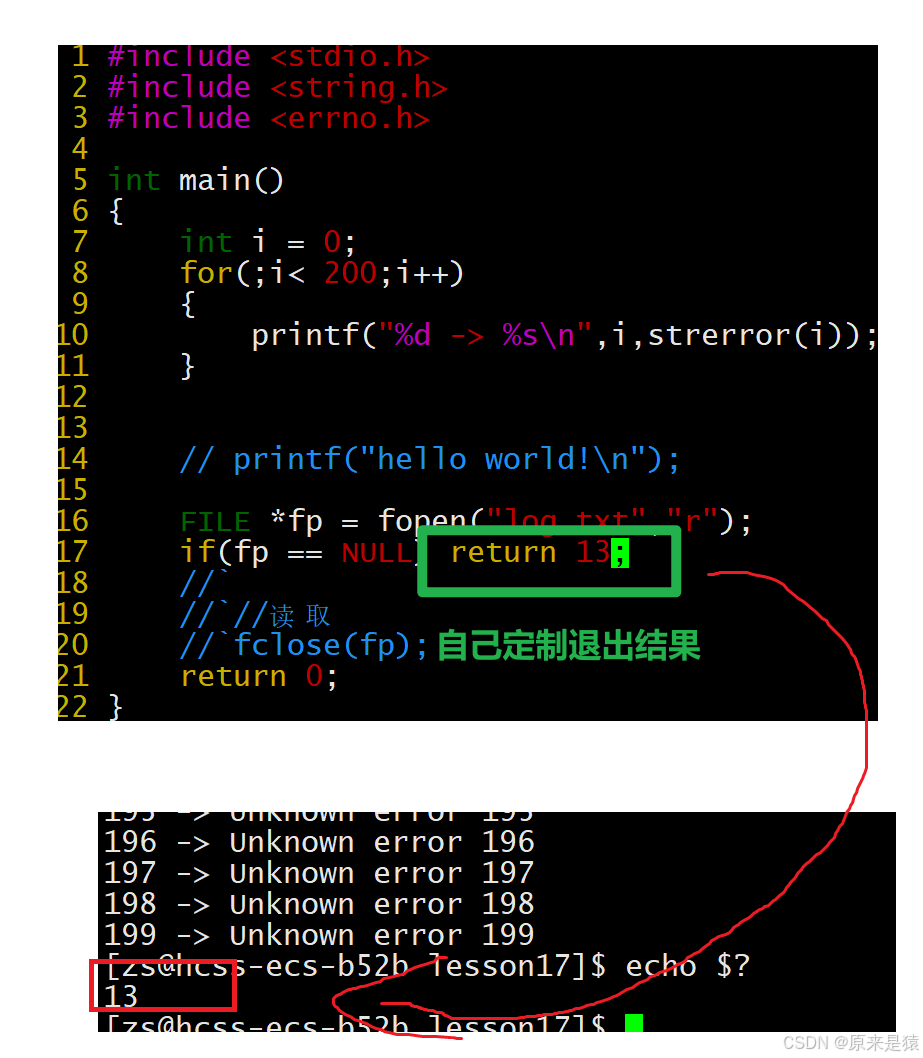
那么异常的退出码是怎么样子的?
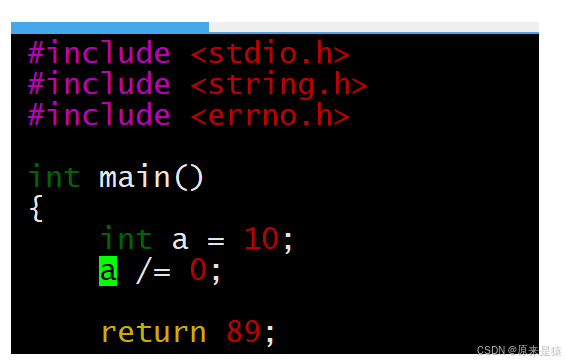
除数不能为0 , 发生除0异常!!!
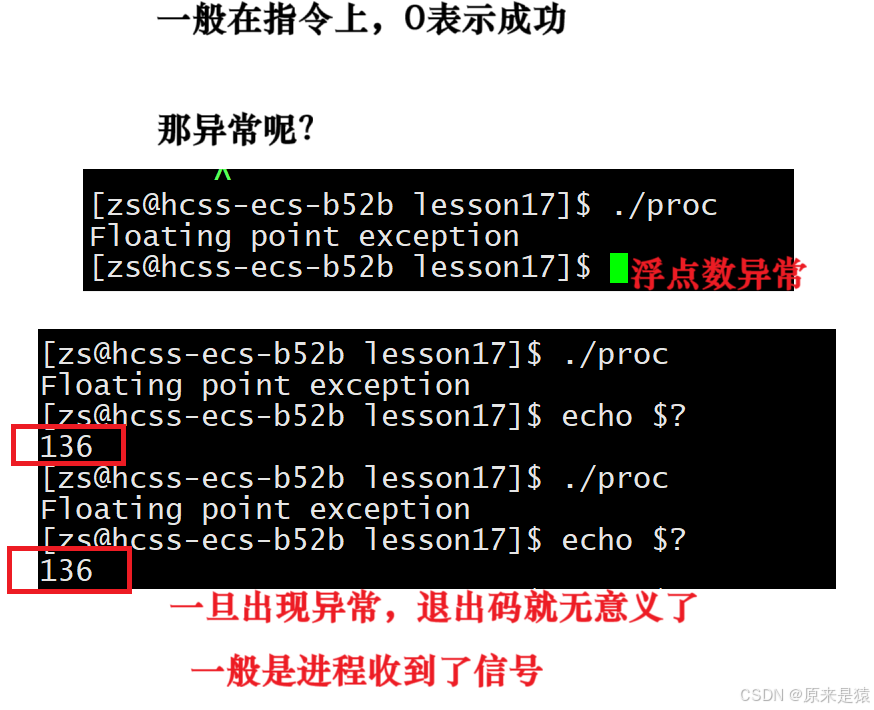

其实进程一旦出现异常,一般是进程收到了信号