深入HBase:原理剖析与优化实战
一、引言
在大数据时代,数据量呈指数级增长,传统的关系型数据库在处理海量数据时逐渐显露出瓶颈,如扩展性差、读写性能不足等。HBase 作为 Hadoop 生态系统中的分布式非关系型数据库,基于 Google 的 Bigtable 论文设计而来,专为海量数据的存储和实时读写而打造,能够在普通硬件集群上实现高并发、低延迟的数据访问,满足大数据场景下的复杂需求,在互联网、金融、物联网等众多领域得到了广泛应用。本文将深入探讨 HBase 的原理、架构及使用方法,并结合实际案例分享 HBase 的优化实践经验,旨在帮助读者全面了解 HBase 并掌握其优化技巧,提升在大数据项目中应用 HBase 的能力 。
二、HBase 基础全面解析
2.1 HBase 是什么
HBase 是一个构建在 Hadoop 分布式文件系统(HDFS)之上的分布式、可扩展的 NoSQL 数据库,其设计灵感源自 Google 的 Bigtable 论文 。它以表格形式组织数据,能够存储海量的结构化和半结构化数据,并提供实时的读写访问能力。与传统关系型数据库不同,HBase 采用了基于列族的存储方式,适合处理大规模、高并发的大数据场景,如日志分析、实时监控、物联网数据存储等。HBase 依赖于 Hadoop 的 HDFS 来实现数据的分布式存储和高可靠性,利用 MapReduce 进行批量数据处理,通过 Zookeeper 实现集群的协调和管理,是 Hadoop 生态系统中的重要组件 。
2.2 关键特性深入探究
高可靠性:基于 HDFS 的多副本机制,HBase 确保数据在节点故障时不丢失,通过 WAL(Write-Ahead Log)预写日志,在数据写入内存之前先记录日志,保证数据的持久性和一致性,即使 RegionServer 宕机,也能通过日志恢复数据。
大规模数据处理:HBase 能够轻松应对 PB 级别的数据存储和处理,通过水平扩展 RegionServer 节点,实现存储容量和处理能力的线性扩展,满足不断增长的数据需求。
实时读写:HBase 支持高效的随机读写操作,通过内存缓存(MemStore)和磁盘存储(HFile)的协同工作,能够在毫秒级到秒级的时间内返回查询结果,满足实时数据分析和业务决策的需求。
灵活模式:与关系型数据库严格的模式定义不同,HBase 的模式非常灵活,表创建时只需定义列族,列限定符可以在数据插入时动态添加,适应了半结构化和非结构化数据的存储需求 。
与 Hadoop 生态紧密集成:作为 Hadoop 生态系统的一部分,HBase 可以无缝集成 Hadoop 的其他组件,如 HDFS、MapReduce、Spark 等,方便进行数据的存储、处理和分析,形成完整的大数据处理解决方案 。
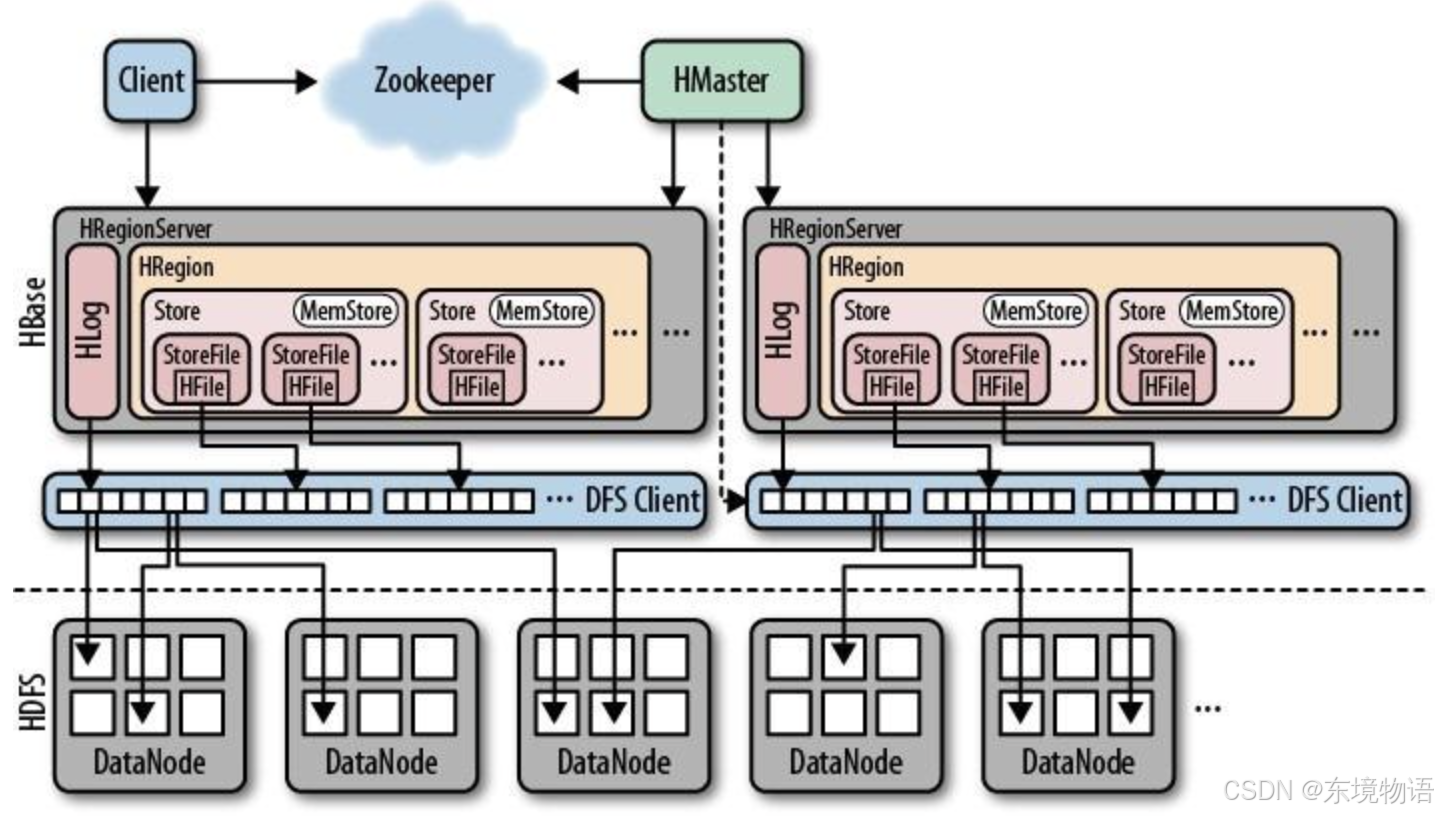
2.3 核心架构深度剖析
HBase 的核心架构由多个组件协同工作,共同实现分布式数据存储和管理:
HMaster:HBase 集群的主节点,负责管理元数据,包括表的创建、删除、修改等操作;监控 RegionServer 的状态,处理节点故障转移;进行 Region 的分配和负载均衡,确保集群资源的合理利用。在生产环境中,通常会配置多个 HMaster 节点,通过 Zookeeper 实现主备选举,提高集群的可用性 。
HRegionServer:实际的数据存储和处理节点,负责管理多个 Region,每个 Region 包含了表中一部分连续行的数据。HRegionServer 处理客户端的读写请求,将数据存储到 HDFS 中,并维护 MemStore(内存缓存)和 HFile(磁盘存储文件),通过 WAL 保证数据的可靠性。当 Region 数据量增长到一定阈值时,会自动进行分裂,以均衡负载。
HDFS:HBase 的数据最终存储在 HDFS 上,利用 HDFS 的分布式存储和多副本机制,实现数据的高可靠存储和容错。HDFS 为 HBase 提供了底层的文件系统支持,确保数据的持久化和安全性 。
Zookeeper:在 HBase 架构中扮演着重要的协调角色,负责维护集群的状态信息,如 HMaster 的选举、RegionServer 的注册和心跳监测;存储元数据表(.META.)的位置,帮助客户端快速定位数据所在的 RegionServer;提供分布式锁服务,保证数据操作的一致性和并发控制 。
2.4 数据模型与存储机制揭秘
数据模型:HBase 的数据模型基于表、行、列族、列限定符和时间戳构建。表是数据的逻辑容器,由多个行组成,每一行通过唯一的行键(RowKey)标识。列族是一组相关列的集合,在表创建时定义,列族下的列限定符可以动态添加,每个列限定符对应一个具体的列。单元格(Cell)是数据存储的最小单元,由行键、列族、列限定符和时间戳共同确定,同一单元格可以存储多个版本的数据,通过时间戳进行区分 。
存储机制:HBase 的数据存储主要涉及 HFile、Store、MemStore 和 HLog。MemStore 是内存中的写缓存,数据写入时先存储在 MemStore 中,当 MemStore 达到一定大小(如 128MB)时,会触发刷写(flush)操作,将数据写入磁盘上的 HFile 文件。HFile 是 HBase 的底层存储文件,以有序、压缩的格式存储数据,多个 HFile 组成一个 Store,每个列族对应一个 Store。HLog 是预写日志,记录所有的写操作,用于数据恢复和故障处理 。当进行数据读取时,首先在 MemStore 中查找,如果未找到则在 BlockCache(读缓存)中查找,最后才从磁盘上的 HFile 中读取数据,通过这种多层缓存机制,提高数据的读取效率 。
三、HBase 在实际场景中的应用案例
3.1 社交媒体平台用户行为分析
某大型社交媒体平台拥有数十亿活跃用户,每天产生海量的用户行为数据,如点赞、评论、分享、发布内容、关注与被关注等操作记录 。这些数据对于平台优化用户体验、精准推送内容、开展广告业务至关重要。传统关系型数据库在存储和处理如此大规模、高并发的数据时面临巨大挑战,而 HBase 凭借其独特优势成为理想之选 。
在数据存储方面,平台将用户行为数据按用户 ID 作为 RowKey 进行存储,不同的行为类型(点赞、评论等)作为列限定符,列族可分为基本行为信息和扩展行为信息等 。例如,对于用户 “user12345” 在 2024 年 10 月 10 日 10:00:00 点赞了一篇文章的行为,RowKey 为 “user12345_20241010100000”,在 “basic_behavior” 列族下,“like” 列限定符的值记录点赞文章的 ID,同时在 “extended_behavior” 列族下,可记录点赞来源设备、地理位置等扩展信息 。通过这种方式,HBase 能够高效存储稀疏的用户行为数据,避免存储空间的浪费 。
在实时分析方面,借助 HBase 的实时读写能力,结合 Spark Streaming 等实时流处理框架,平台可以实时捕获用户行为数据并进行分析 。比如,实时统计热门话题标签,通过监控用户对不同话题标签内容的互动频率,及时发现当前热门话题,将相关内容推送给更多感兴趣的用户 。同时,利用机器学习算法对用户行为数据进行建模,分析用户兴趣偏好,实现个性化内容推荐,提高用户留存率和活跃度 。 在广告投放方面,基于对用户行为数据的深度分析,平台可以实现精准广告投放 。通过分析用户的浏览历史、兴趣爱好和购买意向等行为特征,将合适的广告推送给目标用户群体 。例如,对于经常浏览健身相关内容的用户,推送健身器材、运动服装等广告,大大提高广告点击率和转化率,为平台带来可观的广告收益 。
3.2 物联网设备监控系统
某工业制造企业拥有大量的生产设备,这些设备分布在不同厂区,且每个设备上都部署了多个传感器,用于采集设备的运行状态数据,如温度、压力、振动、转速等 。数据量随时间不断累积,对数据存储和处理的要求极高 。HBase 在该企业的物联网设备监控系统中发挥了关键作用。
数据存储上,企业以设备 ID 和时间戳作为 RowKey,例如 “device001_20241010100000”,表示设备 “device001” 在 2024 年 10 月 10 日 10:00:00 时刻的数据 。不同类型的传感器数据作为不同的列限定符,存储在 “sensor_data” 列族下 。同时,为了便于设备管理和状态查询,还可在 “device_info” 列族下记录设备的基本信息,如设备型号、所属生产线等 。这种设计使得 HBase 能够高效存储海量的传感器数据,并且方便根据设备 ID 和时间范围快速查询设备历史数据 。
在设备状态监控方面,通过实时读取 HBase 中的数据,结合实时数据分析平台,企业可以实时监控设备的运行状态 。一旦发现设备数据超出正常阈值范围,如温度过高、振动异常等,系统立即发出警报,通知维护人员进行检查和维修 。例如,当某台关键设备的振动值连续 5 分钟超过正常范围,系统自动触发警报,并通过短信和邮件通知相关人员,有效避免设备故障导致的生产中断 。
在故障预测方面,利用机器学习算法对 HBase 中存储的历史设备数据进行分析建模,企业可以预测设备可能出现的故障 。通过分析设备运行数据的趋势和模式,建立故障预测模型,提前发现设备潜在问题,安排预防性维护,降低设备故障率,提高生产效率 。例如,通过对某类设备历史故障数据和运行数据的分析,建立了基于深度学习的故障预测模型,提前 72 小时预测设备故障的准确率达到 85% 以上,为企业节省了大量的设备维修成本和生产停机损失 。
3.3 金融服务交易记录存储
某银行每天要处理数百万笔交易,包括存款、取款、转账、支付等业务,这些交易记录对于银行的业务运营、风险控制和合规审计至关重要 。HBase 以其高可靠性、高并发处理能力和灵活的数据存储方式,成为银行存储交易记录的核心技术 。
数据存储上,银行以交易 ID 作为 RowKey,确保每笔交易的唯一性 。在列族设计上,“transaction_info” 列族用于存储交易的基本信息,如交易金额、交易时间、交易类型、交易双方账号等;“transaction_detail” 列族用于存储交易的详细信息,如手续费、交易备注等 。同时,为了满足合规审计要求,对于每笔交易记录,HBase 利用时间戳特性保存多个版本,记录交易的修改历史 。例如,当一笔转账交易出现信息修正时,HBase 会保存修改前和修改后的交易记录版本,便于审计人员追溯 。
在风险控制方面,通过实时读取 HBase 中的交易数据,结合风险评估模型,银行可以实时监控交易风险 。一旦发现异常交易行为,如大额资金短时间内频繁转移、异地登录异常交易等,系统立即启动风险预警机制,采取冻结账户、短信通知用户等措施,保障客户资金安全 。例如,当系统检测到某账户在 1 小时内从不同地区发起 10 笔 50 万元以上的转账交易时,立即触发风险警报,银行客服人员第一时间联系客户核实情况,成功阻止了一起潜在的诈骗交易 。
在合规审计方面,HBase 强大的数据存储和查询能力为银行合规审计提供了有力支持 。审计人员可以根据各种条件快速查询交易记录,如按照时间范围、交易类型、客户账号等查询特定交易信息,生成审计报告 。同时,HBase 的数据一致性和持久性保证了交易记录的准确性和完整性,满足监管机构对银行数据合规性的严格要求 。例如,在应对监管机构的年度审计时,银行利用 HBase 快速查询并导出过去一年所有超过 100 万元的大额交易记录,顺利通过审计检查 。

四、HBase 优化实践策略
4.1 表结构设计优化
预分区设计:在创建 HBase 表时,合理的预分区能使数据均匀分布在不同的 Region 中,避免数据集中在少数 Region 导致热点问题。可以根据业务数据的特征,如按时间范围、哈希值等进行预分区。例如,对于时间序列数据,可以按时间区间进行预分区,每个分区对应一个时间段的数据 。以电商订单数据为例,可按月份对订单表进行预分区,每个月的数据存储在一个独立的 Region 中,这样在查询和写入时,数据能均衡地分布到各个 RegionServer 上,提高系统的并发处理能力 。
避免递增 RowKey:如果使用递增的 RowKey,如时间戳,新写入的数据会集中在同一个 Region 的末尾,导致该 Region 成为热点,影响读写性能。应采用随机数或哈希算法生成 RowKey,使数据均匀分布在不同节点和 Region 中 。比如,使用 MD5 哈希算法对业务主键进行处理,生成一个随机分布的 RowKey 前缀,再结合业务主键构成最终的 RowKey,有效避免数据热点 。以用户行为数据存储为例,将用户 ID 和时间戳拼接后进行 MD5 哈希,得到的哈希值作为 RowKey 前缀,再加上用户 ID 和时间戳,这样写入的数据会分散到不同的 Region,提升系统性能 。
4.2 内存配置优化
RegionServer 的内存配置对 HBase 性能至关重要,需要合理设置 MemStore 和 BlockCache 的内存比例 。MemStore 用于缓存写入的数据,当 MemStore 达到一定大小(如 128MB)时,会触发刷写操作,将数据持久化到磁盘 。BlockCache 则用于缓存读取的数据,提高数据的读取命中率 。 一般情况下,可将 RegionServer 堆内存的 40% 分配给 MemStore,40% 分配给 BlockCache,剩余 20% 作为其他用途 。但实际应用中,需根据读写业务的比例进行动态调整 。如果写操作频繁,可适当增大 MemStore 的比例;如果读操作频繁,则增大 BlockCache 的比例 。例如,在一个以实时监控数据写入为主的场景中,将 MemStore 比例提高到 50%,减少刷写次数,提升写入性能;而在一个以历史数据分析查询为主的场景中,将 BlockCache 比例提高到 50%,提高查询缓存命中率,加快查询速度 。在 hbase-site.xml 文件中,可以通过以下配置调整内存比例:
<property><name>hbase.regionserver.global.memstore.size</name><value>0.5</value>
</property>
<property><name>hbase.regionserver.global.blockcache.size</name><value>0.4</value>
</property>4.3 压缩技术应用
HBase 支持多种压缩算法,如 GZIP、SNAPPY、LZO 等,选择合适的压缩算法可以有效减少磁盘存储空间占用,并降低 I/O 开销 。
GZIP:具有较高的压缩率,能大幅减少数据存储量,但压缩和解压缩速度相对较慢,CPU 消耗较高,适用于对存储空间要求极高且对读写性能要求不是特别严格的场景,如离线数据存储 。
SNAPPY:压缩和解压缩速度快,CPU 消耗较低,但压缩率相对较低,适用于对读写性能要求高,对存储空间节省要求相对较低的实时读写场景,如实时监控数据存储 。
LZO:压缩和解压缩速度也较快,压缩率介于 GZIP 和 SNAPPY 之间,且支持切片,适用于需要进行 MapReduce 处理的大数据集场景,如日志分析 。 在创建表时,可以为列族指定压缩算法,示例代码如下:
HColumnDescriptor columnDescriptor = new HColumnDescriptor("cf");
columnDescriptor.setCompressionType(Compression.Algorithm.SNAPPY);
HTableDescriptor tableDescriptor = new HTableDescriptor(TableName.valueOf("my_table"));
tableDescriptor.addFamily(columnDescriptor);
admin.createTable(tableDescriptor);4.4 Compaction 策略优化
HBase 中的数据是以 StoreFile 的形式存储在磁盘上的,随着数据的不断写入,会产生大量的小 StoreFile,这会影响查询效率 。Compaction 操作就是将多个小的 StoreFile 合并成一个大的 StoreFile,减少 StoreFile 的数量,提高查询性能 。 Compaction 分为 Minor Compaction 和 Major Compaction 。Minor Compaction 会将多个较小的 StoreFile 合并成一个较大的 StoreFile,这个过程不会删除过期数据;Major Compaction 则会将一个 Store 下的所有 StoreFile 合并成一个大的 StoreFile,并删除过期数据 。 为了优化 Compaction 策略,可以定期执行 Major Compaction,例如每周或每月执行一次 。可以通过 HBase Shell 命令来执行 Major Compaction:
echo "major_compact 'table_name'" | hbase shell同时,合理调整 Compaction 的触发条件,如通过配置 hbase.hstore.compaction.min 和 hbase.hstore.compaction.max 参数,控制每次 Minor Compaction 合并的最小和最大文件数,避免 Compaction 过于频繁或合并文件过多导致系统性能下降 。在 hbase-site.xml 文件中,可以进行如下配置:
<property><name>hbase.hstore.compaction.min</name><value>3</value>
</property>
<property><name>hbase.hstore.compaction.max</name><value>10</value>
</property>4.5 Block Size 调整
HFile 中的 Block 是数据读取和缓存的基本单位,Block Size 的大小直接影响 I/O 性能和内存占用 。如果 Block Size 设置过小,会增加 I/O 次数,降低读取性能;如果设置过大,虽然可以减少 I/O 次数,但会占用更多内存,并且在读取少量数据时,会读取过多不必要的数据 。 一般情况下,推荐将 Block Size 设置为 64KB 到 128KB 之间 。对于顺序访问较多的数据,可以适当增大 Block Size,提高顺序读取性能;对于随机访问较多的数据,应适当减小 Block Size,减少内存占用和不必要的数据读取 。在创建表时,可以通过以下代码设置 Block Size:
HColumnDescriptor columnDescriptor = new HColumnDescriptor("cf");
columnDescriptor.setBlocksize(64 * 1024); // 设置为64KB
HTableDescriptor tableDescriptor = new HTableDescriptor(TableName.valueOf("my_table"));
tableDescriptor.addFamily(columnDescriptor);
admin.createTable(tableDescriptor);4.6 Region 大小配置优化
Region 是 HBase 中数据分布和负载均衡的基本单位,Region 的大小直接影响负载均衡和数据访问效率 。如果 Region 过大,会导致单个 RegionServer 的负载过高,影响读写性能;如果 Region 过小,则会增加管理开销,并且在 Region 分裂和合并时会产生额外的性能开销 。 根据数据量和访问模式,合理配置 Region 的大小,一般推荐范围为 5GB 到 20GB 。对于数据量增长较快、写入频繁的表,可以适当减小 Region 大小,以便更快地进行 Region 分裂,实现负载均衡;对于数据量相对稳定、读取频繁的表,可以适当增大 Region 大小,减少 Region 数量,降低管理开销 。在 hbase-site.xml 文件中,可以通过以下配置设置 Region 的最大大小:
<property><name>hbase.hregion.max.filesize</name><value>10737418240</value> <!-- 设置为10GB -->
</property>当一个 Region 的大小达到 hbase.hregion.max.filesize 配置的值时,HBase 会自动将该 Region 分裂成两个子 Region,从而实现负载均衡 。
五、优化效果展示与总结
在完成上述 HBase 优化实践后,通过实际测试和生产环境的运行监测,取得了显著的性能提升效果 。以某电商平台的 HBase 集群为例,优化前,在高并发读写场景下,写入延迟平均达到 50ms,读取延迟平均为 30ms,且随着数据量的不断增长,性能逐渐下降,出现明显的热点问题和频繁的 GC 暂停 。优化后,写入延迟降低至 10ms 以内,读取延迟稳定在 15ms 左右,整体读写性能提升了数倍 。具体性能指标对比如下:
性能指标 | 优化前 | 优化后 |
写入延迟(ms) | 50 | 10 |
读取延迟(ms) | 30 | 15 |
写入吞吐量(TPS) | 5000 | 15000 |
读取吞吐量(QPS) | 8000 | 20000 |
通过本次 HBase 优化实践,我们深刻认识到合理的表结构设计、优化的内存配置、恰当的压缩技术应用、有效的 Compaction 策略调整以及精准的 Block Size 和 Region 大小配置,对于提升 HBase 性能至关重要 。在实际应用中,需要根据业务场景和数据特点,综合运用这些优化策略,并不断进行测试和调整,以达到最佳的性能表现 。同时,随着业务的发展和数据量的持续增长,HBase 的性能优化是一个持续的过程,需要我们密切关注系统运行状态,及时发现并解决潜在的性能问题,确保 HBase 能够稳定、高效地支撑业务发展 。
